通知设置 新通知
小市值轮动-量化交易-程序化交易-Ptrade实盘
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1163 次浏览 • 2023-10-07 14:14
当前策略持有30只。
点击查看大图
点击查看大图
基于股票的策略不敢多买,属于试验阶段,后期仍然会不断根据市场调仓; 主仓依然在可转债。
公众号:可转债量化分析
如果需要策略代写,(ptrade、qmt,其他量化平台)
可以公众号后台回复:
策略代写
查看全部
当前策略持有30只。


基于股票的策略不敢多买,属于试验阶段,后期仍然会不断根据市场调仓; 主仓依然在可转债。
公众号:可转债量化分析

如果需要策略代写,(ptrade、qmt,其他量化平台)
可以公众号后台回复:
策略代写
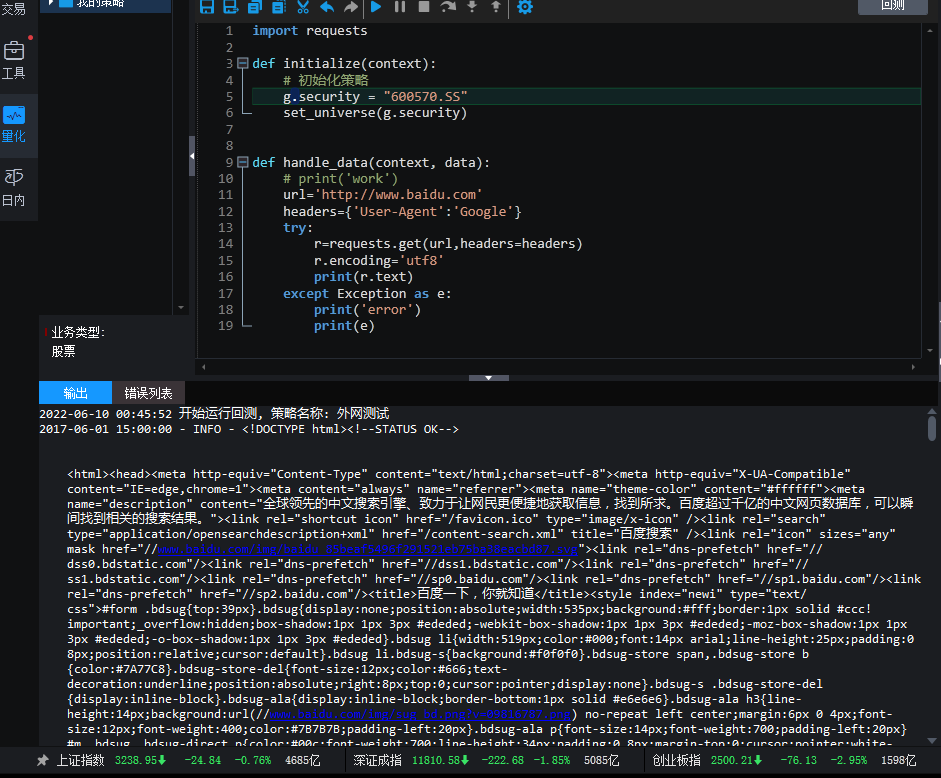
一个因为蓝盾退债引起的报错【Ptrade/QMT】
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 597 次浏览 • 2023-09-25 02:49
上去一看。
每一个tick都在报错:
好家伙? 怎么会有个 404001.SS的可转债代码的?
于是顺着代码去调试。 这个代码是从我的接口传过去的。
于是我看了下数据库。
赫然发现了一个蓝盾退债的玩意, 代码正是 404001, 无语中。 怎么这个代码不按常理来的呢。 虽说是三板的股票,可是转债代码改成4字头, 也是奇葩。
刚好也碰巧我的拼接后缀代码:
def modify_code(self, x):
return x + '.SZ' if x.startswith('12') else x + '.SS'
401开头,于是拼接了个.SS 后缀,导致ptrade无法正确识别这个代码行情。
可能用401001.SZ 可以拿到行情呢。
查看全部
上去一看。
每一个tick都在报错:

好家伙? 怎么会有个 404001.SS的可转债代码的?
于是顺着代码去调试。 这个代码是从我的接口传过去的。
于是我看了下数据库。

赫然发现了一个蓝盾退债的玩意, 代码正是 404001, 无语中。 怎么这个代码不按常理来的呢。 虽说是三板的股票,可是转债代码改成4字头, 也是奇葩。
刚好也碰巧我的拼接后缀代码:
def modify_code(self, x):
return x + '.SZ' if x.startswith('12') else x + '.SS'
401开头,于是拼接了个.SS 后缀,导致ptrade无法正确识别这个代码行情。
可能用401001.SZ 可以拿到行情呢。
ptrade最多支持同时运行多少个策略?
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 775 次浏览 • 2023-09-21 17:16
但同时运行的策略只有5个。
如果不需要的策略,可以把它暂停了,记住,不要随意暂停。 因为暂停了,重启后你的日志就会随之被清空。
平时也应该做好日志备份的习惯。 部分券商可以连接mysql,可以把数据导出,也可以顺便把日志也导出。
需要开通Ptrade或者代写的朋友可以咨询:
查看全部

但同时运行的策略只有5个。

如果不需要的策略,可以把它暂停了,记住,不要随意暂停。 因为暂停了,重启后你的日志就会随之被清空。
平时也应该做好日志备份的习惯。 部分券商可以连接mysql,可以把数据导出,也可以顺便把日志也导出。

需要开通Ptrade或者代写的朋友可以咨询:

Ptrade跟踪雪球组合自动调仓
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 846 次浏览 • 2023-09-19 20:25
根据指定的雪球组合, 自动跟踪组合的调仓与比例.
图随便截取的,具体跟踪的组合,客户自己可以直接配置.
目前是每10分钟刷新一次 组合数据,如果有更新就马上根据调仓.
盘前和收盘前2分钟, 会定期扫码, 以免到了收盘来不及成交, 留够足够的时间下单与撤单.
PS:图片与策略无关
耗时地方仍然是调试.
查看全部
根据指定的雪球组合, 自动跟踪组合的调仓与比例.

图随便截取的,具体跟踪的组合,客户自己可以直接配置.
目前是每10分钟刷新一次 组合数据,如果有更新就马上根据调仓.
盘前和收盘前2分钟, 会定期扫码, 以免到了收盘来不及成交, 留够足够的时间下单与撤单.
PS:图片与策略无关
耗时地方仍然是调试.
ptrade量化策略:低位首板启动板-首板+低吸+单阳不破
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 909 次浏览 • 2023-09-05 22:44
Ptrade实现实盘自动交易代码。
(图片截图非本策略,随意贴的)
里面细节比较多。
得慢慢调。
国金QMT测试版|模拟盘 安装程序 下载
QMT • 李魔佛 发表了文章 • 0 个评论 • 2167 次浏览 • 2023-09-02 12:16
登录账号:******* 登录密码:*********
QMT交易测试客户端下载链接 链接:https://download.gjzq.com.cn/temp/organ/gjzqqmt_ceshi.rar
在线接口文档:
https://qmt.ptradeapi.com
需要开通QMT的视频的朋友可以扫码咨询开通,目前国金开通门槛是入金2W就可以了。费率万一,可半年后免五。
开户后可提供技术相关解答。
查看全部

国金证券QMT测试账号信息:
登录账号:******* 登录密码:*********
QMT交易测试客户端下载链接 链接:https://download.gjzq.com.cn/temp/organ/gjzqqmt_ceshi.rar

在线接口文档:
https://qmt.ptradeapi.com
需要开通QMT的视频的朋友可以扫码咨询开通,目前国金开通门槛是入金2W就可以了。费率万一,可半年后免五。
开户后可提供技术相关解答。
七牛提示:源站域名ICP备案异常和冻结通知。
网络 • 马化云 发表了文章 • 0 个评论 • 701 次浏览 • 2023-09-02 11:32
如下:
您的账号 xxxxxx@qq.com 在七牛云对象存储有以下源站域名没有备案记录或备案已失效,七牛云对象存储无法支持未备案域名在含有中国大陆的区域访问数据,我们即将对域名发起冻结操作。
域名 空间
30daydo.com
根据《互联网信息服务管理办法》(国务院令第292号)等相关法律法规要求,未取得许可或未履行备案手续的,不得从事互联网信息服务。
若备案信息查询有误,请提供相关备案证明,并与销售或技术支持联系。您在使用过程中如有遇到任何问题,可通过 提交工单 解决,我们会尽快回复。感谢您对我们的理解与支持!
然后去官网查询了一下是什么回事:
为什么域名之前备案过了还会被未备案冻结?
备案吊销是指对备案信息做收回并注销,由有管辖权力的部门停止原来准许进行某项活动的对象停止该项活动并收回准许文本的执行过程,一般带有强制性。起因基本是由于该对象违背或违反了发放文本时的约定所致,七牛检测到备案信息失效后,会对域名执行冻结操作。
然后查了下 备案信息,一切都是正常的。不过备案官网上提示:
CP/IP地址/域名信息备案管理系统升级通知ICP/IP地址/域名信息备案管理系统将于2023年9月2日至3日进行系统升级,期间系统停止对外服务,对您带来的不便敬请谅解。
会不会因为这个原因触发了七牛系统的警告呢?
咨询了一番之后才发现还真是这个原因。。
过了3个小时之后,才收到七牛的更正通知:
尊敬的七牛云用户,您好!
因工信部备案查询停服,导致七牛云对象存储的源站域名备案检查异常,如果您在9月2日收到七牛源站域名备案异常冻结的相关通知,您可以忽略,系统也不会执行域名冻结操作。
如果您未收到相关信息,可忽略本条消息。
由此给您带来的不便,深感抱歉,祝您工作顺利,生活愉快!
此致
七牛云团队
还真是虚惊一场。
不过实际的文件存储服务应该不受影响的,图片服务一直还是正常的。只是多了个警告,怪吓人的。
七牛服务还是很赞的,会一直用下去,比腾讯云的要好用。
查看全部
如下:
您的账号 xxxxxx@qq.com 在七牛云对象存储有以下源站域名没有备案记录或备案已失效,七牛云对象存储无法支持未备案域名在含有中国大陆的区域访问数据,我们即将对域名发起冻结操作。
域名 空间
30daydo.com
根据《互联网信息服务管理办法》(国务院令第292号)等相关法律法规要求,未取得许可或未履行备案手续的,不得从事互联网信息服务。
若备案信息查询有误,请提供相关备案证明,并与销售或技术支持联系。您在使用过程中如有遇到任何问题,可通过 提交工单 解决,我们会尽快回复。感谢您对我们的理解与支持!
然后去官网查询了一下是什么回事:
为什么域名之前备案过了还会被未备案冻结?然后查了下 备案信息,一切都是正常的。不过备案官网上提示:
备案吊销是指对备案信息做收回并注销,由有管辖权力的部门停止原来准许进行某项活动的对象停止该项活动并收回准许文本的执行过程,一般带有强制性。起因基本是由于该对象违背或违反了发放文本时的约定所致,七牛检测到备案信息失效后,会对域名执行冻结操作。

CP/IP地址/域名信息备案管理系统升级通知ICP/IP地址/域名信息备案管理系统将于2023年9月2日至3日进行系统升级,期间系统停止对外服务,对您带来的不便敬请谅解。
会不会因为这个原因触发了七牛系统的警告呢?
咨询了一番之后才发现还真是这个原因。。
过了3个小时之后,才收到七牛的更正通知:

尊敬的七牛云用户,您好!
因工信部备案查询停服,导致七牛云对象存储的源站域名备案检查异常,如果您在9月2日收到七牛源站域名备案异常冻结的相关通知,您可以忽略,系统也不会执行域名冻结操作。
如果您未收到相关信息,可忽略本条消息。
由此给您带来的不便,深感抱歉,祝您工作顺利,生活愉快!
此致
七牛云团队

还真是虚惊一场。
不过实际的文件存储服务应该不受影响的,图片服务一直还是正常的。只是多了个警告,怪吓人的。
七牛服务还是很赞的,会一直用下去,比腾讯云的要好用。
国盛证券Ptrade测试版下载 Ptrade模拟客户端 模拟账号
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1226 次浏览 • 2023-09-01 22:53
国盛证券Ptrade测试版下载 Ptrade模拟客户端 模拟账号
仿真客户端
国盛Ptrade测试版 模拟账户下载:
https://download.gszq.com/ptrade/PTrade1.0-Client-V201906-00-000.zip
仿真账户: ***** / ****** 量化回测:支持1分钟、日线回测。 量化交易:支持LEVEL1 tick股票交易。 量化研究:提供云Ipython Notebook研究环境、行情数据2005年至今、可使用全市场金融数据。
虽然ptrade有测试版本,但是个人还是非常不推荐使用测试版本。 以前在上面写过回测或者模拟盘,发现问题非常多,一个是数据缺了,数据错乱。以前被它坑过,后面基本都就不敢用了。 群里的兄弟大部分也被坑过,进群公告就是告诫他们,远离测试版。。。哈
实盘版本的需要开通才能申请,不同券商的门槛不一样。需要的朋友可以扫码咨询:
查看全部
国盛证券Ptrade测试版下载 Ptrade模拟客户端 模拟账号
仿真客户端


国盛Ptrade测试版 模拟账户下载:
https://download.gszq.com/ptrade/PTrade1.0-Client-V201906-00-000.zip
仿真账户: ***** / ****** 量化回测:支持1分钟、日线回测。 量化交易:支持LEVEL1 tick股票交易。 量化研究:提供云Ipython Notebook研究环境、行情数据2005年至今、可使用全市场金融数据。

虽然ptrade有测试版本,但是个人还是非常不推荐使用测试版本。 以前在上面写过回测或者模拟盘,发现问题非常多,一个是数据缺了,数据错乱。以前被它坑过,后面基本都就不敢用了。 群里的兄弟大部分也被坑过,进群公告就是告诫他们,远离测试版。。。哈
实盘版本的需要开通才能申请,不同券商的门槛不一样。需要的朋友可以扫码咨询:
万0.854 免5 量化开户|QMT|Ptrade|掘金量化|国盛证券
券商万一免五 • 李魔佛 发表了文章 • 0 个评论 • 1724 次浏览 • 2023-09-01 22:25
为贯彻落实7月24日中央政治局会议精神和国务院相关会议部署,进一步活跃资本市场,提振投资者信心,形成推动经济持续回升向好的工作合力,证监会指导上海证券交易所、深圳证券交易所、北京证券交易所自8月28日起进一步降低证券交易经手费。沪深交易所此次将A股、B股证券交易经手费从按成交金额的0.00487%双向收取下调为按成交金额的0.00341%双向收取,降幅达30%;北交所在2022年12月调降证券交易经手费50%的基础上,再次将证券交易经手费标准降低50%,由按成交金额的0.025%双边收取下调至按成交金额的0.0125%双边收取。同时,将引导证券公司稳妥做好与客户合同变更及相关交易参数的调整,依法降低经纪业务佣金费率,切实将此次证券交易经手费下降的政策效果传导至广大投资者
在今年8月的时候,交易所下调经手费,经手费是交易所收取的。 所以国盛证券响应国家号召,第一时间下调经手费。
从原来的万1免5,下降到现在的万0.854 免5
对于量化交易Ptrade,QMT,交易费率也是一样,下调到万0.854 免五 !!! 简直良心证券呀,有木有!
目前国盛证券的QMT,miniQMT的开通门槛是入金50W, Ptrade的入金门槛也是50W,而且国盛的Ptrade是可以访问外部数据的。比如你的自己的mysql数据库,还有爬虫获取问财数据等等。 开ptrade的我一般推荐你们开通国盛证券的。 而其他 的湘财证券ptrade,是无法获取外部数据,外部网络的。
需要开通的可以扫码微信开通:
备注: 量化开户
非诚勿扰,欢迎其他券商合作!
查看全部
为贯彻落实7月24日中央政治局会议精神和国务院相关会议部署,进一步活跃资本市场,提振投资者信心,形成推动经济持续回升向好的工作合力,证监会指导上海证券交易所、深圳证券交易所、北京证券交易所自8月28日起进一步降低证券交易经手费。沪深交易所此次将A股、B股证券交易经手费从按成交金额的0.00487%双向收取下调为按成交金额的0.00341%双向收取,降幅达30%;北交所在2022年12月调降证券交易经手费50%的基础上,再次将证券交易经手费标准降低50%,由按成交金额的0.025%双边收取下调至按成交金额的0.0125%双边收取。同时,将引导证券公司稳妥做好与客户合同变更及相关交易参数的调整,依法降低经纪业务佣金费率,切实将此次证券交易经手费下降的政策效果传导至广大投资者

在今年8月的时候,交易所下调经手费,经手费是交易所收取的。 所以国盛证券响应国家号召,第一时间下调经手费。
从原来的万1免5,下降到现在的万0.854 免5
对于量化交易Ptrade,QMT,交易费率也是一样,下调到万0.854 免五 !!! 简直良心证券呀,有木有!

目前国盛证券的QMT,miniQMT的开通门槛是入金50W, Ptrade的入金门槛也是50W,而且国盛的Ptrade是可以访问外部数据的。比如你的自己的mysql数据库,还有爬虫获取问财数据等等。 开ptrade的我一般推荐你们开通国盛证券的。 而其他 的湘财证券ptrade,是无法获取外部数据,外部网络的。
需要开通的可以扫码微信开通:
备注: 量化开户
非诚勿扰,欢迎其他券商合作!
沪深交易所下调经手费后,不少券商费率可以做到 万0.85 免五 了啊
券商万一免五 • 绫波丽 发表了文章 • 0 个评论 • 1382 次浏览 • 2023-08-29 20:06
而且之前是万一免五的券商,现在也还是可以免五的,所以目前的费率是万0.85免5了。
万一免5券商如下:
华宝证券 入金1万 万1.3免五 0.5起步
国泰君安 入金100w 0.1元起步
长江证券1 入金50w,0起步
国信证券 入金50w,0.1元起
银河证券1 入金1万,1元起
安信证券 入金2w,0.5元起步
国盛证券 入金10w,0.1元起步
国金证券 入金2w 0.1元起步
国元证券,入金1w,0.2元起步
长江证券2 入金1w,0.01元起步
银河2 入金1w, 0.1元起步
国元2 入金1万, 0.1元起步
安信证券2 入金2w,0.1元起步 如果有个后缀的,比如银河2,表示多个营业部,2表示第2个营业部。
目前接到的通知是已有的老客户,原来是万一免五的,都可以降万0.146,也就是万0.85 免五的费率!!
对于股票交易者来说,这费率降的算不少了,而且印花税也从原来的千1,减半,降为千0.5了。喜大普奔。
那些注册了万一免五ID的用户估计要血亏了。
需要开通低费率免五的朋友,可以扫码添加微信:
备注:开户
查看全部
其中沪深交易所,涉及A股、B股、存托凭证品种的交易佣金,将在投资者原有佣金基础上统一下调0.00146%就是说原来的股票原来的万1的费率,可以减去 0.00146%, 万0.146, 万1减去 万0.146,等于万0.85左右。
而且之前是万一免五的券商,现在也还是可以免五的,所以目前的费率是万0.85免5了。

万一免5券商如下:如果有个后缀的,比如银河2,表示多个营业部,2表示第2个营业部。
华宝证券 入金1万 万1.3免五 0.5起步
国泰君安 入金100w 0.1元起步
长江证券1 入金50w,0起步
国信证券 入金50w,0.1元起
银河证券1 入金1万,1元起
安信证券 入金2w,0.5元起步
国盛证券 入金10w,0.1元起步
国金证券 入金2w 0.1元起步
国元证券,入金1w,0.2元起步
长江证券2 入金1w,0.01元起步
银河2 入金1w, 0.1元起步
国元2 入金1万, 0.1元起步
安信证券2 入金2w,0.1元起步
目前接到的通知是已有的老客户,原来是万一免五的,都可以降万0.146,也就是万0.85 免五的费率!!
对于股票交易者来说,这费率降的算不少了,而且印花税也从原来的千1,减半,降为千0.5了。喜大普奔。
那些注册了万一免五ID的用户估计要血亏了。


需要开通低费率免五的朋友,可以扫码添加微信:
备注:开户
ETF最低费率! ETF万0.4 免五,0.1元起步
券商万一免五 • 绫波丽 发表了文章 • 0 个评论 • 962 次浏览 • 2023-08-26 09:50
以目前见过的所有券商里面,这个ETF费率最为逆天了。 没有比它还低。(有的话你可以提交给我,发你大红包)
它的股票也是万一的费率,可以免五,不过股票免5的条件高一些,要等半年,入金50w.
ETF免五则低一些,入金10W就可以马上调好。
其他费率参考:
需要的朋友可以咨询微信开通:
查看全部
以目前见过的所有券商里面,这个ETF费率最为逆天了。 没有比它还低。(有的话你可以提交给我,发你大红包)
它的股票也是万一的费率,可以免五,不过股票免5的条件高一些,要等半年,入金50w.
ETF免五则低一些,入金10W就可以马上调好。
其他费率参考:

需要的朋友可以咨询微信开通:
国金QMT实盘版本下载地址
QMT • 李魔佛 发表了文章 • 0 个评论 • 2057 次浏览 • 2023-08-22 22:00
QMT实盘版下载地址:
https://download.gjzq.com.cn/gjty/organ/gjzqqmt.rar
安装路径最好不要有中文,和空格。
实盘版里面可以切换模拟和实盘。
在线接口文档:
https://qmt.ptradeapi.com
需要开通QMT的朋友可以扫码咨询开通,目前国金开通门槛是入金2W就可以了。
开户后可提供技术相关解答。
附一个国金Ptrade的下载地址:
Ptrade实盘版下载地址:
https://download.gjzq.com.cn/gjty/organ/gjzqptd.rar
查看全部
QMT实盘版下载地址:
https://download.gjzq.com.cn/gjty/organ/gjzqqmt.rar
安装路径最好不要有中文,和空格。
实盘版里面可以切换模拟和实盘。

在线接口文档:
https://qmt.ptradeapi.com
需要开通QMT的朋友可以扫码咨询开通,目前国金开通门槛是入金2W就可以了。
开户后可提供技术相关解答。
附一个国金Ptrade的下载地址:
Ptrade实盘版下载地址:
https://download.gjzq.com.cn/gjty/organ/gjzqptd.rar
股票|可转债|基金|股指期货 数据白嫖 之 掘金量化版
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 714 次浏览 • 2023-08-21 10:23
一些刚刚入门的星友可能会缺乏一些股票数据,转债数据或者接口源。之前星球分享不过不同的数据源:tushare,akshare,通达信pytdx,miniqmt,ptrade等等。
今天为大家介绍一个新的数据源,可以白嫖不用开户,只需要简单注册一个账号就可以拉取数据,注册过程花费30秒都不到。
https://www.myquant.cn/terminal
掘金量化
注册后用掘金量化终端登录,账号管理里有你的token,后续的数据调用都需要用的这个token,用于区分不同的用户。
有了token我们就可以开始白嫖数据了。from __future__ import print_function, absolute_import
from gm.api import *
set_token(juejin_token)
获取可转债的分钟数据
就这么简单,没有多余的参数。
不过分钟数据只能拿到最近180天的数据。而日线则可以拿到所有的数据。
另外一个获取历史数据的函数:
get_history_instruments
除了拿到开盘,收盘,最低,最高加和成交量等数据,还可以获取可转债特性的数据,比如转股价,正股标的,上市日期,退市日期等。
剩余规模可以通过另外一个函数获取:
bnd_get_amount_change
获取指数成分股get_constituents(index='SHSE.000300', fields='symbol, weight', df=True)比如上面实例代码获取的是沪深300指数当前的成分股,以及每个个股的权重。
数据文档
期货数据
除此之外还有一些期货,指数数据可以获取的。比如获取中证1000股指期货IM2212合约数据im_data = get_history_symbol(symbol='CFFEX.IM2212', start_date='2022-12-12', end_date='2022-12-16', df=True)
目前掘金量化也支持实盘交易,目前费率和门槛最低的是国盛证券,只需要入金5W就可以开通实盘版本,费率也是非常低的,最低可以到万一免五! 实盘掘金交易,股票需要再万一的基础上加0.2%,ETF,可转债这些品种还是原来的万0.5,简直良心券商!
需要开通的可以扫码咨询开通:
查看全部
一些刚刚入门的星友可能会缺乏一些股票数据,转债数据或者接口源。之前星球分享不过不同的数据源:tushare,akshare,通达信pytdx,miniqmt,ptrade等等。
今天为大家介绍一个新的数据源,可以白嫖不用开户,只需要简单注册一个账号就可以拉取数据,注册过程花费30秒都不到。
https://www.myquant.cn/terminal
掘金量化
注册后用掘金量化终端登录,账号管理里有你的token,后续的数据调用都需要用的这个token,用于区分不同的用户。

有了token我们就可以开始白嫖数据了。
from __future__ import print_function, absolute_import
from gm.api import *
set_token(juejin_token)
获取可转债的分钟数据

就这么简单,没有多余的参数。
不过分钟数据只能拿到最近180天的数据。而日线则可以拿到所有的数据。
另外一个获取历史数据的函数:
get_history_instruments
除了拿到开盘,收盘,最低,最高加和成交量等数据,还可以获取可转债特性的数据,比如转股价,正股标的,上市日期,退市日期等。

剩余规模可以通过另外一个函数获取:
bnd_get_amount_change

获取指数成分股get_constituents(index='SHSE.000300', fields='symbol, weight', df=True)比如上面实例代码获取的是沪深300指数当前的成分股,以及每个个股的权重。

数据文档

期货数据
除此之外还有一些期货,指数数据可以获取的。比如获取中证1000股指期货IM2212合约数据
im_data = get_history_symbol(symbol='CFFEX.IM2212', start_date='2022-12-12', end_date='2022-12-16', df=True)
目前掘金量化也支持实盘交易,目前费率和门槛最低的是国盛证券,只需要入金5W就可以开通实盘版本,费率也是非常低的,最低可以到万一免五! 实盘掘金交易,股票需要再万一的基础上加0.2%,ETF,可转债这些品种还是原来的万0.5,简直良心券商!
需要开通的可以扫码咨询开通:
QMT iQuant miniQMT它们有什么区别?
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 1270 次浏览 • 2023-08-18 15:46
对于第一次接触的朋友来说,经常会问到几个问题,QMT和iQuant,miniQMT有什么区别。
首先,QMT和iQuant都是有迅投开发的。miniQMT是在QMT底下的运行的一个极简模式。
接下来将详细的讲讲。
QMT vs iQuant
一般券商采购了迅投的QMT,接入行情数据服务器和交易服务器,和用户资金账户,就可以让他成为自己的量化交易软件。
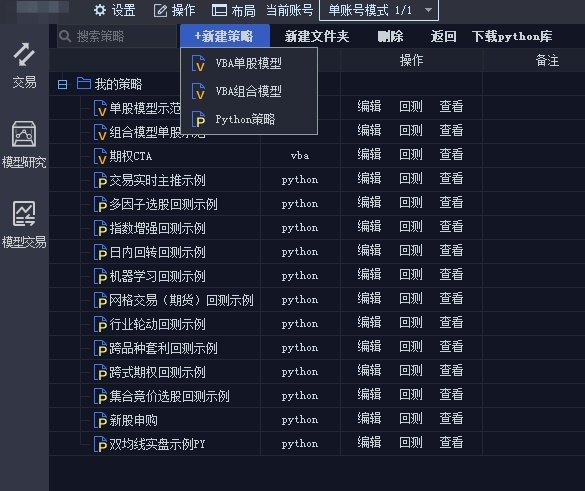
而iQuant是有国信定制开发的。iQuant它的大部分券商的QMT的功能基本一样。 不同的地方有:
iQuant移除了VBA模型
下图是国金QMT,在新建策略下面,有VBA模型和python模型
而在国信的iQuant的策略开发模式下,只支持python模型,VBA编写模型的功能被移除了。
对于VBA而言,实际是一门古老的语言,至少在互联网领域,已经没见过几个人在用的了。
不过我在查询了一下它的在QMT里面的实盘交易代码,其实它还是挺适合熟悉通达信公式的朋友使用,很多语法是从通达信的公式演变而来的。
iQuant支持投资研究,使用jupyter notebook逐行运行,为了便于调试。
而其他的QMT均没有这个功能。 不过这个功能我试了下,它只是调用我系统的jupyter notebook,而且它有严重的bug,居然运行不了任何代码。(ptrade也有个类似这样的功能,可以逐行调用内置的获取行情的函数,ptrade的是可以正常运行的)
少数券商的QMT无法在虚拟机运行
QMT可以在虚拟机运行,大部分券商的QMT可以在虚拟机里面运行,这也意味这可以云主机服务器运行,比如阿里云,腾讯云这种,在云服务器上网络和系统稳定性都要比你在家里放的主机要好,因为QMT需要一台正在运行的Windows系统,且网络畅通。
只有少数券商的QMT无法在虚拟机里面运行。
之前笔者粗略地对比了下QMT读取的系统信息,异同点字在于磁盘序列号,想要硬刚的读者朋友在可以尝试修改虚拟机的硬盘序列号。
在python编写策略的代码层面,QMT和iQuant的接口文档也基本一致的,可能在一些功能函数上会有些少出入。二者写的python代码可互相在彼此上运行。
QMT 与 miniQMT
miniQMT属于QMT的一个子功能,一个精简功能下的自动交易框架,只支持实盘交易,不支持回测。在miniQMT模式下,你的策略代码将不在固定在自带的那个QMT软件下编写,而是可以自由地使用pycharm,vscode等编辑器,运行的时候直接使用 python xxxx.py 这样的形式启动。
只是券商很少对它进行宣传,以至于用它的人不多。
进入miniQMT的方法: 点击QMT程序,登录时勾选极简模式
注意:极简模式下,需要一直保持者这个miniQMT的登录程序在运行,意味者miniQMT也只能在windows系统下运行。
XtQuant
miniQMT的核心是XtQuant,XtQuant能提供哪些服务?
XtQuant是基于迅投MiniQMT衍生出来的一套完善的Python策略运行框架,对外以Python库的形式提供策略交易所需要的行情和交易相关的API接口。
XtQuant运行依赖环境
XtQuant目前提供的库包括Python3.6、3.7、3.8版本,不同版本的python导入时会自动切换。根据群友反馈,最新的版本可以支持到python3.11。
在运行使用XtQuant的程序前需要先启动MiniQMT客户端。
然后把你的QMT目录下的\bin.x64\Lib\site-packages\xtquant复制到你系统python目录下的site-packages。
然后就可以在你的代码里面导入QMT的函数,包括获取行情数据,下单函数。
它的帮助文档在bin.x64\Lib\site-packages\xtquant\doc 目录下。
从它的帮助文档来看,它是一套和QMT接口函数完全不一样的交易框架。
所以QMT的代码,无法直接拷贝到miniQMT中使用。虽然名字叫miniQMT,但感觉它提供的很多函数功能,要比QMT更为丰富,用户可以掌控的流程更多,更灵活。
iQuant版虽然也有精简版的miniQMT,但它对个人用户不提供下单功能呢,只有获取行情数据,财务数据等的数据权限。
还有一个与之配套的xtdata库,是专门用来获取行情数据的,而xttrade是专门用来交易下单的。
因为xtdata可以获取很多股票,可转债,ETF等等历史数据,所以即使你不用miniQMT做交易,你也可以白嫖它的数据,这比用积分的tushare简直不要太爽。比如可以获取到股票或可转债的日线,分钟线,甚至tick数据。
比如下面的代码就可以获取 众信转债 的某个时间的历史tick数据,并保存到文件。 只要稍微改造下,就可以获取全市场的转债的tick数据。
import pandas as pd
import datetime
def get_tick(code, start_time, end_time, period='tick'):
from xtquant import xtdata
xtdata.download_history_data(code, period=period, start_time=start_time, end_time=end_time)
data = xtdata.get_local_data(field_list=, stock_code=, period=period, count=10)
result_list = data df = pd.DataFrame(result_list)
df['time_str'] = df['time'].apply(lambda x: datetime.datetime.fromtimestamp(x / 1000.0))
return df
def process_timestamp(df, filename):
df = df.set_index('time_str')
result = df.resample('3S').first().ffill()
result = result[(result.index >= '2022-07-20 09:30') & (result.index <= '2022-07-20 15:00')]
result = result.reset_index()
result.to_csv(filename + '.csv')
def dump_single_code_tick():
# 导出单个转债的tick数据
code='128022'
start_date = '20210113'
end_date = '20210130'
post_fix = 'SZ' if code.startswith('12') else 'SH'
code = '{}.{}'.format(code,post_fix)
filename = '{}'.format(code)
df = get_tick(code, start_date, end_date)
dump_single_code_tick()
把上面保存为main.py, 然后执行python main.py , 片刻就可以看到生成的文件数据了。
结语
为了便于读者快速浏览帮助文档,可以在公众号后台回复对应的关键词获取对应的帮助文档:
qmt文档
miniqmt文档
如果想要体验qmt或者miniqmt自动交易的朋友,可以后台回复:开通qmt
即可获取低门槛低费率的开通qmt/iQuant的券商开户方式。
知识星球: 查看全部
对于第一次接触的朋友来说,经常会问到几个问题,QMT和iQuant,miniQMT有什么区别。
首先,QMT和iQuant都是有迅投开发的。miniQMT是在QMT底下的运行的一个极简模式。

接下来将详细的讲讲。
QMT vs iQuant
一般券商采购了迅投的QMT,接入行情数据服务器和交易服务器,和用户资金账户,就可以让他成为自己的量化交易软件。
而iQuant是有国信定制开发的。iQuant它的大部分券商的QMT的功能基本一样。 不同的地方有:
iQuant移除了VBA模型
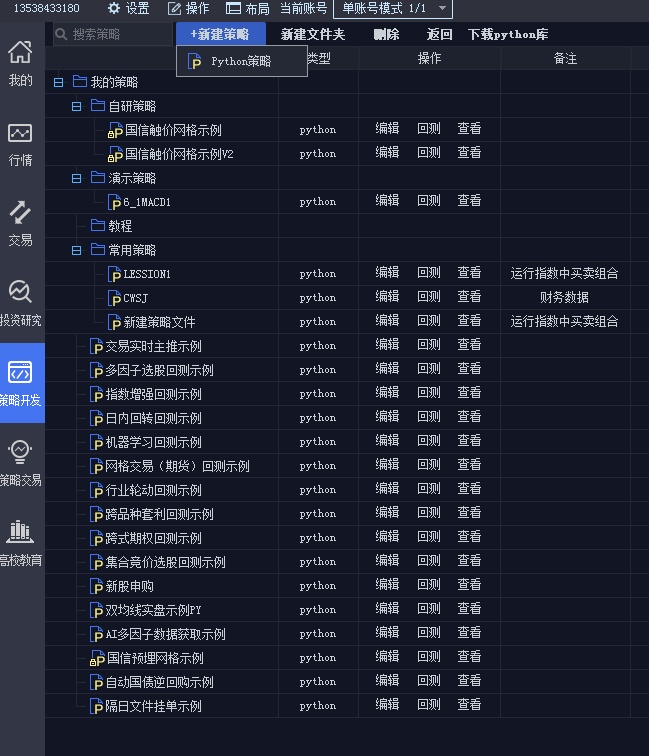
下图是国金QMT,在新建策略下面,有VBA模型和python模型
而在国信的iQuant的策略开发模式下,只支持python模型,VBA编写模型的功能被移除了。
对于VBA而言,实际是一门古老的语言,至少在互联网领域,已经没见过几个人在用的了。
不过我在查询了一下它的在QMT里面的实盘交易代码,其实它还是挺适合熟悉通达信公式的朋友使用,很多语法是从通达信的公式演变而来的。
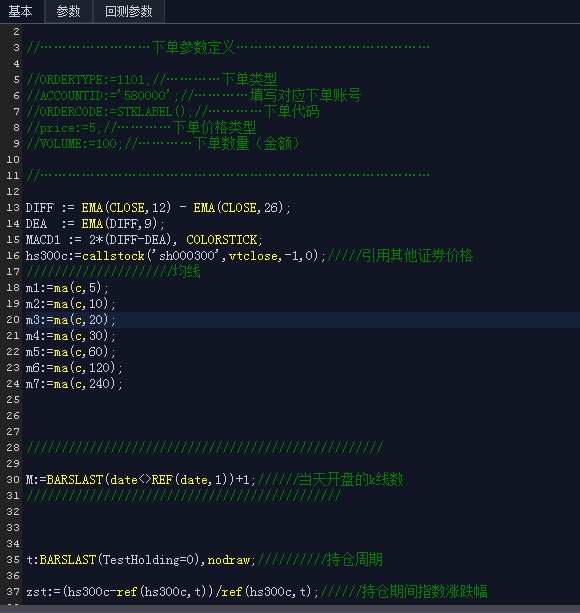
iQuant支持投资研究,使用jupyter notebook逐行运行,为了便于调试。
而其他的QMT均没有这个功能。 不过这个功能我试了下,它只是调用我系统的jupyter notebook,而且它有严重的bug,居然运行不了任何代码。(ptrade也有个类似这样的功能,可以逐行调用内置的获取行情的函数,ptrade的是可以正常运行的)
少数券商的QMT无法在虚拟机运行
QMT可以在虚拟机运行,大部分券商的QMT可以在虚拟机里面运行,这也意味这可以云主机服务器运行,比如阿里云,腾讯云这种,在云服务器上网络和系统稳定性都要比你在家里放的主机要好,因为QMT需要一台正在运行的Windows系统,且网络畅通。
只有少数券商的QMT无法在虚拟机里面运行。
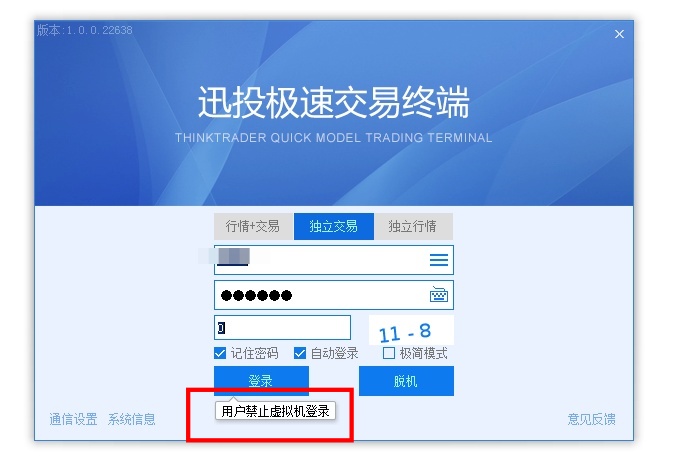
之前笔者粗略地对比了下QMT读取的系统信息,异同点字在于磁盘序列号,想要硬刚的读者朋友在可以尝试修改虚拟机的硬盘序列号。
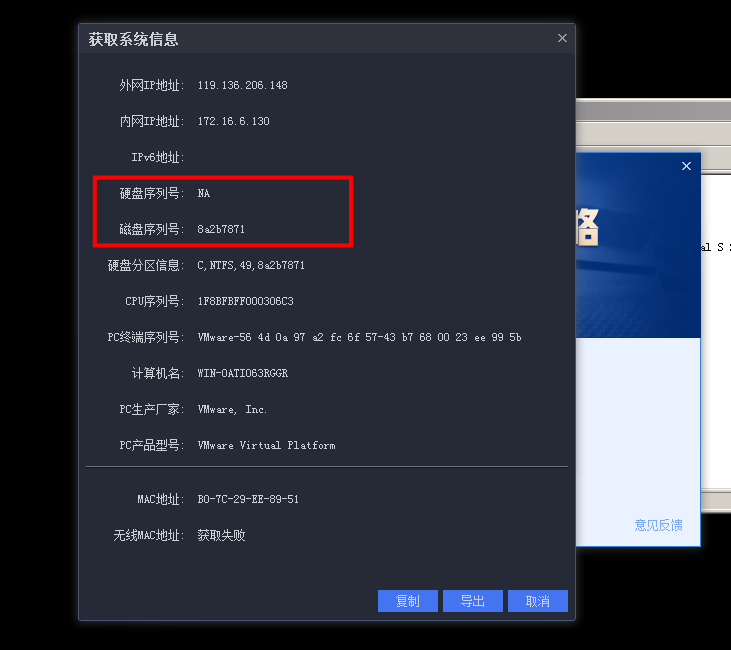
在python编写策略的代码层面,QMT和iQuant的接口文档也基本一致的,可能在一些功能函数上会有些少出入。二者写的python代码可互相在彼此上运行。
QMT 与 miniQMT
miniQMT属于QMT的一个子功能,一个精简功能下的自动交易框架,只支持实盘交易,不支持回测。在miniQMT模式下,你的策略代码将不在固定在自带的那个QMT软件下编写,而是可以自由地使用pycharm,vscode等编辑器,运行的时候直接使用 python xxxx.py 这样的形式启动。
只是券商很少对它进行宣传,以至于用它的人不多。
进入miniQMT的方法: 点击QMT程序,登录时勾选极简模式

注意:极简模式下,需要一直保持者这个miniQMT的登录程序在运行,意味者miniQMT也只能在windows系统下运行。
XtQuant
miniQMT的核心是XtQuant,XtQuant能提供哪些服务?
XtQuant是基于迅投MiniQMT衍生出来的一套完善的Python策略运行框架,对外以Python库的形式提供策略交易所需要的行情和交易相关的API接口。
XtQuant运行依赖环境
XtQuant目前提供的库包括Python3.6、3.7、3.8版本,不同版本的python导入时会自动切换。根据群友反馈,最新的版本可以支持到python3.11。
在运行使用XtQuant的程序前需要先启动MiniQMT客户端。
然后把你的QMT目录下的\bin.x64\Lib\site-packages\xtquant复制到你系统python目录下的site-packages。
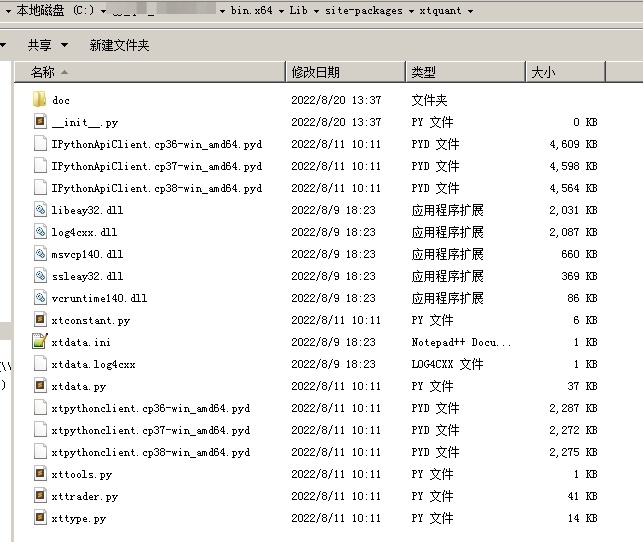
然后就可以在你的代码里面导入QMT的函数,包括获取行情数据,下单函数。

它的帮助文档在bin.x64\Lib\site-packages\xtquant\doc 目录下。
从它的帮助文档来看,它是一套和QMT接口函数完全不一样的交易框架。
所以QMT的代码,无法直接拷贝到miniQMT中使用。虽然名字叫miniQMT,但感觉它提供的很多函数功能,要比QMT更为丰富,用户可以掌控的流程更多,更灵活。
iQuant版虽然也有精简版的miniQMT,但它对个人用户不提供下单功能呢,只有获取行情数据,财务数据等的数据权限。
还有一个与之配套的xtdata库,是专门用来获取行情数据的,而xttrade是专门用来交易下单的。

因为xtdata可以获取很多股票,可转债,ETF等等历史数据,所以即使你不用miniQMT做交易,你也可以白嫖它的数据,这比用积分的tushare简直不要太爽。比如可以获取到股票或可转债的日线,分钟线,甚至tick数据。
比如下面的代码就可以获取 众信转债 的某个时间的历史tick数据,并保存到文件。 只要稍微改造下,就可以获取全市场的转债的tick数据。
import pandas as pd
import datetime
def get_tick(code, start_time, end_time, period='tick'):
from xtquant import xtdata
xtdata.download_history_data(code, period=period, start_time=start_time, end_time=end_time)
data = xtdata.get_local_data(field_list=, stock_code=
, period=period, count=10)
result_list = data
df = pd.DataFrame(result_list)
df['time_str'] = df['time'].apply(lambda x: datetime.datetime.fromtimestamp(x / 1000.0))
return df
def process_timestamp(df, filename):
df = df.set_index('time_str')
result = df.resample('3S').first().ffill()
result = result[(result.index >= '2022-07-20 09:30') & (result.index <= '2022-07-20 15:00')]
result = result.reset_index()
result.to_csv(filename + '.csv')
def dump_single_code_tick():
# 导出单个转债的tick数据
code='128022'
start_date = '20210113'
end_date = '20210130'
post_fix = 'SZ' if code.startswith('12') else 'SH'
code = '{}.{}'.format(code,post_fix)
filename = '{}'.format(code)
df = get_tick(code, start_date, end_date)
dump_single_code_tick()
把上面保存为main.py, 然后执行python main.py , 片刻就可以看到生成的文件数据了。
结语
为了便于读者快速浏览帮助文档,可以在公众号后台回复对应的关键词获取对应的帮助文档:
qmt文档
miniqmt文档
如果想要体验qmt或者miniqmt自动交易的朋友,可以后台回复:开通qmt
即可获取低门槛低费率的开通qmt/iQuant的券商开户方式。
知识星球:

github.com/lestrrat-go/libxml2 这个xpath包在windows下无法使用
Golang • 马化云 发表了文章 • 0 个评论 • 575 次浏览 • 2023-08-18 12:11
(base) PS C:\git\qiniu_web_gin> go run .\main.go
# github.com/lestrrat-go/libxml2/xpath
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:40:35: undefined: clib.XMLXPathObjectType
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:45:14: undefined: clib.XMLXPathObjectFloat64
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:50:14: undefined: clib.XMLXPathObjectBool
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:74:18: undefined: clib.XMLXPathObjectNodeList
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:91:18: undefined: clib.XMLXPathObjectNodeList
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:124:7: undefined: clib.XMLXPathFreeObject
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:129:19: undefined: clib.XMLXPathCompile
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:149:7: undefined: clib.XMLXPathFreeCompExpr
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:163:22: undefined: clib.XMLXPathNewContext
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:179:14: undefined: clib.XMLXPathContextSetContextNode
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:179:14: too many errors
(base) PS C:\git\qiniu_web_gin> go get github.com/lestrrat-go/libxml2
(base) PS C:\git\qiniu_web_gin>
然后到作者的官网上逛了一圈,出现这个问题,需要自己编译一个libxml2 windows版本的
官方给出的是源码:
libxml2-2.11.5-win-build Latest
Corresponding to official release version 2.11.5.
然后编译C的源码,需要很多的工具链和依赖。
windows至少需要Visual Studio, 不是vs code呢。 Visual Studio安装完,至少要被占用10GB的空间。
libxml2 + iconv + msvc 在windows下生成使用库
为了跨平台的解析xml,偶然获得Linux下比较好用的一个xml的解析库libxml2,使用起来确实比较简单,方便;但移植到windows下后发下使用上存在问题:
无法解析格式位GB2312类型的XML文件,但由于一些外部因素,Windows下必须使用GB2312格式
在网上查看了诸多教程,有很多编译生成libxml2库的文章,但都不支持iconv,仔细阅读README后,终于生成了可用的libxml2.lib库,记录下来备用
操作系统:windows 7 x64
版本:libiconv-1.15, libxml2 Github版本
Visual Studio版本:vs2015
Cygwin:x64
以下操作皆为生成x64位库,32位的基本类似,可以查看具体的README。
所以想想还是算了,直接切换到ubuntu开发了。惹不起,还躲不起吗 :(
我:@lestrrat Hi, is that mean it can't work on windows if i dont build it with visual studio or cgywin like?
作者:It's the same as when you are building a C program. You build in the same arch/os as the where you intend to run the program.
我:Thanks a lot. Instsall vs environment taks lots of time, so i switch to the ubuntu to "quick fix this issue" :(
逃-》
查看全部
(base) PS C:\git\qiniu_web_gin> go run .\main.go
# github.com/lestrrat-go/libxml2/xpath
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:40:35: undefined: clib.XMLXPathObjectType
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:45:14: undefined: clib.XMLXPathObjectFloat64
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:50:14: undefined: clib.XMLXPathObjectBool
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:74:18: undefined: clib.XMLXPathObjectNodeList
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:91:18: undefined: clib.XMLXPathObjectNodeList
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:124:7: undefined: clib.XMLXPathFreeObject
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:129:19: undefined: clib.XMLXPathCompile
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:149:7: undefined: clib.XMLXPathFreeCompExpr
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:163:22: undefined: clib.XMLXPathNewContext
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:179:14: undefined: clib.XMLXPathContextSetContextNode
C:\Users\xda\go\pkg\mod\github.com\lestrrat-go\libxml2@v0.0.0-20201123224832-e6d9de61b80d\xpath\xpath.go:179:14: too many errors
(base) PS C:\git\qiniu_web_gin> go get github.com/lestrrat-go/libxml2
(base) PS C:\git\qiniu_web_gin>
然后到作者的官网上逛了一圈,出现这个问题,需要自己编译一个libxml2 windows版本的
官方给出的是源码:
libxml2-2.11.5-win-build Latest
Corresponding to official release version 2.11.5.


然后编译C的源码,需要很多的工具链和依赖。
windows至少需要Visual Studio, 不是vs code呢。 Visual Studio安装完,至少要被占用10GB的空间。

libxml2 + iconv + msvc 在windows下生成使用库
为了跨平台的解析xml,偶然获得Linux下比较好用的一个xml的解析库libxml2,使用起来确实比较简单,方便;但移植到windows下后发下使用上存在问题:
无法解析格式位GB2312类型的XML文件,但由于一些外部因素,Windows下必须使用GB2312格式
在网上查看了诸多教程,有很多编译生成libxml2库的文章,但都不支持iconv,仔细阅读README后,终于生成了可用的libxml2.lib库,记录下来备用
操作系统:windows 7 x64
版本:libiconv-1.15, libxml2 Github版本
Visual Studio版本:vs2015
Cygwin:x64
以下操作皆为生成x64位库,32位的基本类似,可以查看具体的README。
所以想想还是算了,直接切换到ubuntu开发了。惹不起,还躲不起吗 :(
我:@lestrrat Hi, is that mean it can't work on windows if i dont build it with visual studio or cgywin like?
作者:It's the same as when you are building a C program. You build in the same arch/os as the where you intend to run the program.
我:Thanks a lot. Instsall vs environment taks lots of time, so i switch to the ubuntu to "quick fix this issue" :(
逃-》
Ptrade无法获取lof基金的历史数据
量化交易-Ptrade-QMT • 李魔佛 回复了问题 • 2 人关注 • 1 个回复 • 789 次浏览 • 2023-08-17 01:41
哪些券商有miniqmt? 门槛如何
QMT • 李魔佛 发表了文章 • 0 个评论 • 1490 次浏览 • 2023-08-11 12:04
它属于一个精简版的QMT,把回测功能,UI界面操作功能去除。
你可以把miniqmt导入到你的项目里面,直接操作下单。
from xtquant import xtdata
data = xtdata.get_market_data(field_list=['time', 'open', 'close', 'high', 'low', 'volume', 'amount'], stock_list=['603000.SH'], period='1d', start_time='20230101')
print(data)上面代码 可以直接在你的pycharm里面运行, 提前把 xtquant 这个包复制到系统路径,site-packages,或者自己加到环境变量。
MiniQMT支持新版本的Python
最新已经支持python3.6-3.11
更新方式:主QMT-设置-交易设置-模型设置里更新Python库
目前支持miniQTM的券商有哪些?
其实miniqmt是附属在QMT上的,正常有QMT的,默认就可以使用miniqmt,除非券商作妖,阉割了。
国金,国盛支持miniqmt,开通QMT后 miniqmt就是直接可以使用的。
而国信的miniqmt默认被阉割了,需要额外去申请。(可能还有些经理不敬业的,会和你说不支持miniqmt,曾经遇到过),不过国信的miniqmt开通后,个人只能拉取行情数据,是没有下单权限,下单券商是需要机构才可以申请。
国金的QMT,miniqmt的开通门槛会低一些,有入金2W就可以开通的营业部; 也有入金50W开通的营业部。 需要的盆友可以扫码咨询开通。
国盛的QMT,目前门槛比较高,需要资产100W才能开通。本身之前门槛还只是入金30W就可以的了,后面他们不断地提高门槛,提到50W,后面提高到100W,不过最近几天,营业部的经理和我说目前我这边开通只需要50W即可。
所以平时有优惠费率的时候就不要犹犹豫豫,把账户和权限开了再说,因为好事不常有,过了这个桥就没有这个店。
需要开户的盆友可以扫码咨询
查看全部
它属于一个精简版的QMT,把回测功能,UI界面操作功能去除。
你可以把miniqmt导入到你的项目里面,直接操作下单。
from xtquant import xtdata上面代码 可以直接在你的pycharm里面运行, 提前把 xtquant 这个包复制到系统路径,site-packages,或者自己加到环境变量。
data = xtdata.get_market_data(field_list=['time', 'open', 'close', 'high', 'low', 'volume', 'amount'], stock_list=['603000.SH'], period='1d', start_time='20230101')
print(data)
MiniQMT支持新版本的Python
最新已经支持python3.6-3.11
更新方式:主QMT-设置-交易设置-模型设置里更新Python库
目前支持miniQTM的券商有哪些?
其实miniqmt是附属在QMT上的,正常有QMT的,默认就可以使用miniqmt,除非券商作妖,阉割了。
国金,国盛支持miniqmt,开通QMT后 miniqmt就是直接可以使用的。

而国信的miniqmt默认被阉割了,需要额外去申请。(可能还有些经理不敬业的,会和你说不支持miniqmt,曾经遇到过),不过国信的miniqmt开通后,个人只能拉取行情数据,是没有下单权限,下单券商是需要机构才可以申请。
国金的QMT,miniqmt的开通门槛会低一些,有入金2W就可以开通的营业部; 也有入金50W开通的营业部。 需要的盆友可以扫码咨询开通。
国盛的QMT,目前门槛比较高,需要资产100W才能开通。本身之前门槛还只是入金30W就可以的了,后面他们不断地提高门槛,提到50W,后面提高到100W,不过最近几天,营业部的经理和我说目前我这边开通只需要50W即可。
所以平时有优惠费率的时候就不要犹犹豫豫,把账户和权限开了再说,因为好事不常有,过了这个桥就没有这个店。
需要开户的盆友可以扫码咨询
5 个在线 AI 字幕生成器,让字幕生成变得更简单
深度学习 • 马化云 发表了文章 • 0 个评论 • 1388 次浏览 • 2023-08-08 18:29
磨刀不误砍柴工,现在chatGPT等AI工具逐渐在每一个领域里面,慢慢地替代人类的繁琐工作,添加字幕的任务也不例外。本文分享5款在线的字幕AI生成工具,能够大大地提高用户的视频编辑效率。
一、录咖-AI 字幕
https://reccloud.cn/ai-subtitle
第一个字幕生成器是录咖-AI 字幕。它的主要功能是在线使用、操作简单、精准识别,并支持 AI 生成和 AI 翻译双语字幕。
下面是使用录咖-AI 字幕的简单步骤:
打开录咖-AI 字幕的官方网站。
添加您要为其生成字幕的视频文件。
等待录咖-AI 字幕完成语音识别和字幕生成的过程。
如果需要双语字幕,您可以选择 AI 翻译功能,将生成的字幕自动翻译为另一种语言。
您可以选择导出字幕或直接保存字幕到视频中。
优势:
● 操作简单:无需复杂的设置和技术要求,用户可以轻松上手。
● 精准识别:采用先进的语音识别技术,能够准确地将语音内容转换为文字。
● 支持 AI 生成:支持使用 AI 生成字幕,可以快速生成准确的字幕内容。
● 支持 AI 翻译:支持将生成的字幕自动翻译为另一种语言,提供双语字幕的功能。
劣势:
● 依赖网络:由于是在线使用,录咖-AI 字幕的使用需要保持网络连接。
二、EasySub
https://easyssub.com/zh/
第二个字幕生成器是 EasySub 。EasySub 是一个在线字幕生成器,提供免费试用选项,但并非完全免费。免费试用仅限于 30 分钟内生成字幕,超过时限则需要付费。EasySub 支持多语言,但处理速度较慢。
使用步骤:
1. 打开 EasySub 的官方网站。
2. 创建账户。
3. 上传视频文件或提供视频的 URL 。
4. 等待 EasySub 完成语音识别和字幕生成。
5. 对生成的字幕进行基本的编辑和调整。
6. 选择合适的视频格式然后导出视频。
优势:
● 多语言支持:EasySub 可以为不同语种的视频生成对应的字幕。
● 免费试用:虽然不是完全免费,但 30 分钟内可以免费生成字幕。
劣势:
● 处理速度较慢:EasySub 生成字幕的速度相对较慢。
● 需要付费:超过 30 分钟的使用时限后,需要付费继续使用。
三、FlexClip
https://www.flexclip.com/cn/tools/auto-subtitle/
第三个字幕生成器是 FlexClip 。FlexClip 是一个免费在线使用的字幕生成器,它支持翻译多语言,但处理速度较慢,加载时间较长,并且有广告显示。使用 FlexClip 需要登录账号,免费账户可以使用 5 分钟时长。需要注意的是,新生成的字幕会覆盖当前字幕,而且 FlexClip 不支持双语字幕。此外,FlexClip 的界面不太易用,而且识别精准度方面可能存在一定的问题。
使用步骤:
1. 打开 FlexClip 的官方网站并登录账号。
2. 上传视频文件。
3. 等待 FlexClip 完成语音识别和字幕生成的过程。
4. 编辑和调整生成的字幕内容。
5. 将字幕保存或导出到视频中。
优势:
- 免费在线使用:FlexClip 提供免费的在线字幕生成服务。
- 多语言翻译:支持将字幕翻译为多种语言,满足不同语言需求。
劣势:
- 处理速度较慢:FlexClip 的处理速度相对较慢,可能需要较长的等待时间。
- 广告显示:使用 FlexClip 时会显示广告,可能对用户体验造成一定影响。
识别精准度较低:由于识别技术的限制,FlexClip 的识别精准度可能不如其他字幕生成器。
四、Sonix
https://sonix.ai/zh/automated-subtitles-and-captions
第四个字幕生成器是 Sonix 。Sonix 是一个提供 30 分钟内免费使用的字幕生成器,用户可以自定义、拆分和编辑字幕,并支持导出到 SRT 和 VTT 格式。然而,Sonix 的注册过程相对较复杂。
使用步骤:
1. 在 Sonix 的官方网站上注册账号并登录。
2. 上传音频或视频文件。
3. Sonix 会对文件进行语音识别,生成相应的字幕文本。
4. 对生成的字幕进行自定义编辑,可以进行拆分、合并、修正等操作。
5. 在编辑完成后,选择导出字幕的格式,如 SRT 或 VTT 。 6. 完成导出后,可以将字幕应用到相应的视频或使用在其他平台上。
优势:
- 30 分钟内免费使用:Sonix 提供了 30 分钟内的免费使用,方便用户进行快速的字幕生成和编辑。
- 自定义编辑:用户可以对生成的字幕进行自定义编辑,以满足个性化的需求。
- 多种导出格式:Sonix 支持将字幕导出为常见的 SRT 和 VTT 格式,方便在不同平台和播放器上使用。 劣势:
注册过程较复杂:Sonix 的注册过程可能相对复杂,可能需要填写一些个人信息或进行身份验证。
五、Auris
https://aurisai.io/zh/add-subtitles-to-video/
第五个字幕生成器是 Auris 。Auris 是一个在线使用的字幕生成器,提供 30 分钟内的免费使用。它支持翻译多种语言,并且可以处理多种视频格式。
使用步骤:
1. 打开 Auris 的官方网站。
2. 选择音频语言,即选择你要生成字幕的音频语言。
3. 点击上传按钮,选择你要生成字幕的视频文件。
4. 等待一段时间,直到字幕生成完成。
5. 在字幕生成完成后,你可以看到生成的字幕文本。
优势:
- 在线使用:Auris 是一个在线字幕生成器,无需下载和安装额外的软件。
- 多语言翻译:支持将字幕文本进行多语言翻译,满足不同语种之间的转换需求。 - 支持 Facebook 和 Google 账号登陆:用户可以通过自己的 Facebook 或 Google 账号登录 Auris ,方便快捷。
劣势:
- 30 分钟内免费限制:Auris 的免费使用时长限制为 30 分钟,超过时长需要购买付费账户或进行其他付费方式。 查看全部
磨刀不误砍柴工,现在chatGPT等AI工具逐渐在每一个领域里面,慢慢地替代人类的繁琐工作,添加字幕的任务也不例外。本文分享5款在线的字幕AI生成工具,能够大大地提高用户的视频编辑效率。
一、录咖-AI 字幕
https://reccloud.cn/ai-subtitle
第一个字幕生成器是录咖-AI 字幕。它的主要功能是在线使用、操作简单、精准识别,并支持 AI 生成和 AI 翻译双语字幕。

下面是使用录咖-AI 字幕的简单步骤:
打开录咖-AI 字幕的官方网站。
添加您要为其生成字幕的视频文件。
等待录咖-AI 字幕完成语音识别和字幕生成的过程。
如果需要双语字幕,您可以选择 AI 翻译功能,将生成的字幕自动翻译为另一种语言。
您可以选择导出字幕或直接保存字幕到视频中。
优势:
● 操作简单:无需复杂的设置和技术要求,用户可以轻松上手。
● 精准识别:采用先进的语音识别技术,能够准确地将语音内容转换为文字。
● 支持 AI 生成:支持使用 AI 生成字幕,可以快速生成准确的字幕内容。
● 支持 AI 翻译:支持将生成的字幕自动翻译为另一种语言,提供双语字幕的功能。
劣势:
● 依赖网络:由于是在线使用,录咖-AI 字幕的使用需要保持网络连接。
二、EasySub
https://easyssub.com/zh/
第二个字幕生成器是 EasySub 。EasySub 是一个在线字幕生成器,提供免费试用选项,但并非完全免费。免费试用仅限于 30 分钟内生成字幕,超过时限则需要付费。EasySub 支持多语言,但处理速度较慢。

使用步骤:
1. 打开 EasySub 的官方网站。
2. 创建账户。
3. 上传视频文件或提供视频的 URL 。
4. 等待 EasySub 完成语音识别和字幕生成。
5. 对生成的字幕进行基本的编辑和调整。
6. 选择合适的视频格式然后导出视频。
优势:
● 多语言支持:EasySub 可以为不同语种的视频生成对应的字幕。
● 免费试用:虽然不是完全免费,但 30 分钟内可以免费生成字幕。
劣势:
● 处理速度较慢:EasySub 生成字幕的速度相对较慢。
● 需要付费:超过 30 分钟的使用时限后,需要付费继续使用。
三、FlexClip
https://www.flexclip.com/cn/tools/auto-subtitle/
第三个字幕生成器是 FlexClip 。FlexClip 是一个免费在线使用的字幕生成器,它支持翻译多语言,但处理速度较慢,加载时间较长,并且有广告显示。使用 FlexClip 需要登录账号,免费账户可以使用 5 分钟时长。需要注意的是,新生成的字幕会覆盖当前字幕,而且 FlexClip 不支持双语字幕。此外,FlexClip 的界面不太易用,而且识别精准度方面可能存在一定的问题。

使用步骤:
1. 打开 FlexClip 的官方网站并登录账号。
2. 上传视频文件。
3. 等待 FlexClip 完成语音识别和字幕生成的过程。
4. 编辑和调整生成的字幕内容。
5. 将字幕保存或导出到视频中。
优势:
- 免费在线使用:FlexClip 提供免费的在线字幕生成服务。
- 多语言翻译:支持将字幕翻译为多种语言,满足不同语言需求。
劣势:
- 处理速度较慢:FlexClip 的处理速度相对较慢,可能需要较长的等待时间。
- 广告显示:使用 FlexClip 时会显示广告,可能对用户体验造成一定影响。
识别精准度较低:由于识别技术的限制,FlexClip 的识别精准度可能不如其他字幕生成器。
四、Sonix
https://sonix.ai/zh/automated-subtitles-and-captions
第四个字幕生成器是 Sonix 。Sonix 是一个提供 30 分钟内免费使用的字幕生成器,用户可以自定义、拆分和编辑字幕,并支持导出到 SRT 和 VTT 格式。然而,Sonix 的注册过程相对较复杂。

使用步骤:
1. 在 Sonix 的官方网站上注册账号并登录。
2. 上传音频或视频文件。
3. Sonix 会对文件进行语音识别,生成相应的字幕文本。
4. 对生成的字幕进行自定义编辑,可以进行拆分、合并、修正等操作。
5. 在编辑完成后,选择导出字幕的格式,如 SRT 或 VTT 。 6. 完成导出后,可以将字幕应用到相应的视频或使用在其他平台上。
优势:
- 30 分钟内免费使用:Sonix 提供了 30 分钟内的免费使用,方便用户进行快速的字幕生成和编辑。
- 自定义编辑:用户可以对生成的字幕进行自定义编辑,以满足个性化的需求。
- 多种导出格式:Sonix 支持将字幕导出为常见的 SRT 和 VTT 格式,方便在不同平台和播放器上使用。 劣势:
注册过程较复杂:Sonix 的注册过程可能相对复杂,可能需要填写一些个人信息或进行身份验证。
五、Auris
https://aurisai.io/zh/add-subtitles-to-video/
第五个字幕生成器是 Auris 。Auris 是一个在线使用的字幕生成器,提供 30 分钟内的免费使用。它支持翻译多种语言,并且可以处理多种视频格式。

使用步骤:
1. 打开 Auris 的官方网站。
2. 选择音频语言,即选择你要生成字幕的音频语言。
3. 点击上传按钮,选择你要生成字幕的视频文件。
4. 等待一段时间,直到字幕生成完成。
5. 在字幕生成完成后,你可以看到生成的字幕文本。
优势:
- 在线使用:Auris 是一个在线字幕生成器,无需下载和安装额外的软件。
- 多语言翻译:支持将字幕文本进行多语言翻译,满足不同语种之间的转换需求。 - 支持 Facebook 和 Google 账号登陆:用户可以通过自己的 Facebook 或 Google 账号登录 Auris ,方便快捷。
劣势:
- 30 分钟内免费限制:Auris 的免费使用时长限制为 30 分钟,超过时长需要购买付费账户或进行其他付费方式。
ptrade qmt无法登录问题
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 977 次浏览 • 2023-08-08 14:44
实际上这是在周五晚上和周末出现的问题,这是计划内的维护。部分券商没有技术服务支持,用户可能连服务器日常维护服务通知都无法及时得到通知。
PS:其实,大部分券商基本也就那样,ptrade和qmt的技术支持基本等于0,不敢说全部,至少90%的情况是这样的。 以至于我自己维护了一个ptrade,qmt的技术群(审核才可以加),日常有空就在里面解决群友的问题。基本都是些基础问题,部分可能是券商数据问题,大部分是用户的代码问题。 查看全部


实际上这是在周五晚上和周末出现的问题,这是计划内的维护。部分券商没有技术服务支持,用户可能连服务器日常维护服务通知都无法及时得到通知。
PS:其实,大部分券商基本也就那样,ptrade和qmt的技术支持基本等于0,不敢说全部,至少90%的情况是这样的。 以至于我自己维护了一个ptrade,qmt的技术群(审核才可以加),日常有空就在里面解决群友的问题。基本都是些基础问题,部分可能是券商数据问题,大部分是用户的代码问题。
银河证券万一免五 0.1元起 基金LOF申购一折 活动优惠
券商万一免五 • 绫波丽 发表了文章 • 0 个评论 • 1002 次浏览 • 2023-07-28 20:08
股票万1,最低0.1元
ETF/LOF万0.5,最低0.1元
可转债万0.5,最低0.1元
逆回购一天期,1折
两融5%-5.8%
佣金查询(收盘后):
银河APP-交易-其他查询-交割单-佣金
活动有截至时间,需要开的迅速咨询开通。 银河是套利必备的利器。没有之一。
集思录人员人手必备的热门券商。而且还是免5的。
PS: 那些说面五违规的,你们自己把那交易的五元乖乖交给券商就好了。 我一个银河用了5年了,免5用到现在,帮我省下不知道多少钱了。
再说一次,你们喜欢交5元就自己交,不要也让其他人也和你一样多交这无谓的5元。
需要开户的联系:
查看全部

统一佣金标准:
股票万1,最低0.1元
ETF/LOF万0.5,最低0.1元
可转债万0.5,最低0.1元
逆回购一天期,1折
两融5%-5.8%
佣金查询(收盘后):
银河APP-交易-其他查询-交割单-佣金
活动有截至时间,需要开的迅速咨询开通。 银河是套利必备的利器。没有之一。
集思录人员人手必备的热门券商。而且还是免5的。

PS: 那些说面五违规的,你们自己把那交易的五元乖乖交给券商就好了。 我一个银河用了5年了,免5用到现在,帮我省下不知道多少钱了。
再说一次,你们喜欢交5元就自己交,不要也让其他人也和你一样多交这无谓的5元。
需要开户的联系:
20行代码实现Ptrade一键清仓
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 825 次浏览 • 2023-07-28 02:16
万一遇到特殊情况要核的话,管快,1秒清空
def func(context):
pos_dict = get_positions()
for code,pos in pos_dict.items():
enable_amount = pos.enable_amount
if enable_amount>0:
order_target(code, 0)
# 标准
def initialize(context):
# 初始化策略
run_daily(context, func, time='9:25')
def handle_data(context, data):
pass
实际只用11行代码。
如果只清除转债或者股票某个品种,可以在code那里加个判断def func(context):
pos_dict = get_positions()
for code,pos in pos_dict.items():
enable_amount = pos.enable_amount
if enable_amount>0 and code.startswith(('12','11')): # 只清除转债
order_target(code, 0) 查看全部
万一遇到特殊情况要核的话,管快,1秒清空
def func(context):
pos_dict = get_positions()
for code,pos in pos_dict.items():
enable_amount = pos.enable_amount
if enable_amount>0:
order_target(code, 0)
# 标准
def initialize(context):
# 初始化策略
run_daily(context, func, time='9:25')
def handle_data(context, data):
pass
实际只用11行代码。
如果只清除转债或者股票某个品种,可以在code那里加个判断
def func(context):
pos_dict = get_positions()
for code,pos in pos_dict.items():
enable_amount = pos.enable_amount
if enable_amount>0 and code.startswith(('12','11')): # 只清除转债
order_target(code, 0)
ptrade重启策略后日志被清空,正常的操作方式
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 761 次浏览 • 2023-07-25 04:36
然后就心满意足的退出Ptrade。
然后想起来有个日志想要查一下的。再进去一看,里面的几个月的日志就被清除了。 OMG
这个清除日志的操作虽然说是软件设置的。但是产品经理应该也要评估一下,哪怕我只是改一个时间,比如我把策略从9:15分执行改成9:16执行,只要改动,策略就需要被重启,才能生效。
试问,哪个策略能够几年不出错,不修改,一直在上面运行的呢? 退一万步讲,其实如果我知道我即将修改后重启策略,面对这几百个按时间切割的日志,我用什么工具导出呢?
软件自带的导出功能只能按照天数的。
所以对于运行很久的策略,如果需要修改里面的内容,我的建议是,直接停止程序,而不是重启。
然后把你的策略复制到一个新的策略里面,在新的策略里面改动参数。
然后直接运行这个新的策略,这样之前那个策略因为没有被重启,只是停止了,它的日志依然保存在ptrade的日历里面,你只需要选择指定的日期,就可以看到对应的历史数据。
更多ptrade、qmt,掘金的量化交易技巧,请查看星球。
查看全部

然后就心满意足的退出Ptrade。
然后想起来有个日志想要查一下的。再进去一看,里面的几个月的日志就被清除了。 OMG
这个清除日志的操作虽然说是软件设置的。但是产品经理应该也要评估一下,哪怕我只是改一个时间,比如我把策略从9:15分执行改成9:16执行,只要改动,策略就需要被重启,才能生效。
试问,哪个策略能够几年不出错,不修改,一直在上面运行的呢? 退一万步讲,其实如果我知道我即将修改后重启策略,面对这几百个按时间切割的日志,我用什么工具导出呢?
软件自带的导出功能只能按照天数的。
所以对于运行很久的策略,如果需要修改里面的内容,我的建议是,直接停止程序,而不是重启。
然后把你的策略复制到一个新的策略里面,在新的策略里面改动参数。
然后直接运行这个新的策略,这样之前那个策略因为没有被重启,只是停止了,它的日志依然保存在ptrade的日历里面,你只需要选择指定的日期,就可以看到对应的历史数据。

更多ptrade、qmt,掘金的量化交易技巧,请查看星球。
ptrade批量获取股票的昨天的收盘价,转为字典json【一】
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 874 次浏览 • 2023-07-17 19:50
ptrade接口文档:https://ptradeapi.com
笔者这里接写几个最简单的方式,供读者朋友参考。
下面代码适用于实盘,回测。
code_list = ['113578.SS','123014.SZ'] # 股票池,这里可以填几千个股票也没问题的
zz_df_price = get_price(code_list, start_date=None, end_date=None, frequency='1d', fields='close', fq=None, count=1)
yesterday_price_dict = zz_df_price.iloc[0].to_json()
讲解:
1.
code_list = ['113578.SS','123014.SZ'] # 股票池,这里可以填几千个股票也没问题的,比如你可以先拿沪深300指数的成分股,然后传入这个函数。
2.
zz_df_price = get_price(code_list, start_date=None, end_date=None, frequency='1d', fields='close', fq=None, count=1)
get_price: 获取历史数据。 这里不用get_history,因为这个函数太多bug了,主要是券商数据可能是缺的。拿历史数据我基本不敢用get_history。
因为我拿昨天的收盘价,所以我就不指定日期,只用count=1,获取1条数据,因为数据是从最新开始的,那么这一条数据肯定是上一个交易日的。
正常情况返回的数据是一个Pannel,三维的。不过因为filed=‘close',单个字段,特殊情况,这里返回的是一个dataframe
输出:
zz_df_price.iloc[0].to_json()
index 113578.SS 123014.SZ
2023-07-14 93.036 118.36
所以接下来要做的是,获取dataframe的第一行数据,直接转为json
得到:
'{"113578.SS":93.036,"123014.SZ":118.36}'
更多技术支持与解答,欢迎加入星球。
查看全部
ptrade接口文档:https://ptradeapi.com
笔者这里接写几个最简单的方式,供读者朋友参考。
下面代码适用于实盘,回测。
code_list = ['113578.SS','123014.SZ'] # 股票池,这里可以填几千个股票也没问题的
zz_df_price = get_price(code_list, start_date=None, end_date=None, frequency='1d', fields='close', fq=None, count=1)
yesterday_price_dict = zz_df_price.iloc[0].to_json()
讲解:
1.
code_list = ['113578.SS','123014.SZ'] # 股票池,这里可以填几千个股票也没问题的,比如你可以先拿沪深300指数的成分股,然后传入这个函数。
2.
zz_df_price = get_price(code_list, start_date=None, end_date=None, frequency='1d', fields='close', fq=None, count=1)
get_price: 获取历史数据。 这里不用get_history,因为这个函数太多bug了,主要是券商数据可能是缺的。拿历史数据我基本不敢用get_history。
因为我拿昨天的收盘价,所以我就不指定日期,只用count=1,获取1条数据,因为数据是从最新开始的,那么这一条数据肯定是上一个交易日的。
正常情况返回的数据是一个Pannel,三维的。不过因为filed=‘close',单个字段,特殊情况,这里返回的是一个dataframe

输出:
zz_df_price.iloc[0].to_json()
index 113578.SS 123014.SZ
2023-07-14 93.036 118.36
所以接下来要做的是,获取dataframe的第一行数据,直接转为json
得到:
'{"113578.SS":93.036,"123014.SZ":118.36}'
更多技术支持与解答,欢迎加入星球。
投资海外市场,有哪些标的可以考虑?| 多个QDII基金数据分析
股票 • 李魔佛 发表了文章 • 0 个评论 • 680 次浏览 • 2023-07-10 23:21
这是过去十几年纳斯达克指数的月K线走势。
去年2022年回调了一年,下跌了33%,而今年截至到今天,已经涨了31%。
以前老司机曾经说过,对于纳指的每次回调都是买入的机会。老司机果诚不欺我也!
2016年的时候不少大V就在喊美股冲顶风险很大泡沫要破云云之类。再来看看我们那低估的沪深300。
最近十五年来的月K线。上涨的时光总是短暂的。如果十多年前山顶位置买的投资者,熬到现在也可能未解套。
怪不得网友们的吐槽
所以放眼全球,可选标的更为丰富,那投资标的就可以更为分散,篮子里的品种相关性就会越低,那么遭遇系统性风险的概率就越低。好比买了一揽子基于A股的基金,然后A股大盘崩了,覆巢之下无完卵,那一篮子的鸡蛋也碎了。而投资全球基金,就是把鸡蛋装到不同的篮子,甚至不同的车子里。
本期雪球老司基评测选出了8只全球市场主题基金,我们来对其进行评测,来看看各自的风格,哪一只的风格适合你。
本次评测的8个全球基金如下:
其中,易方达标普消费品,广发全球医疗保健,华安标普全球石油,诺安全球黄金这4个基金为跟踪指数型基金,主要考察基金经理对指数跟踪误差的控制能力。
工银全球精选股票,国富全球科技互联,富国全球科技互联,银华抗通胀主题主要考验基金经理的选股,择时能力。
同为投资标的为科技互联网的国富全球科技互联和富国全球科技互联,名字很像,只不过是两个基金公司发行的基金。不过它俩最近三年的收益率差距很大,国富全球科技互联(006373)最近三年的收益率为32%,而富国全球科技互联(100055)的最近三年的收益率却为-7%, 同为全球科技型股票基金,为何二者差距会有这么大呢?
根据最新的季报信息,二者的规模与持仓比较如下:
二者都属于小规模基金,规模小于3个亿,而国富全球科技互联(006373)其基金规模更加低于一个亿。国富全球科技互联(006373)的持仓股票占比比富国全球科技互联(100055)要高近20%(79% vs 61%)
而对比一下二者的十大持仓股,黄色标注的为中概股(港股),富国全球科技(100055)十大持仓里有8个中概股。
这种情况下,很难躲过中概股的这一轮下跌的。
而最近2年的中概股走势你们也是有目共睹的。
就这样跌跌跌的走势,还想着赚钱? 能保本不亏已经算是人上人了。
因此富国全球科技(100055)在评测的这8个海外基金里面,最近3年的收益率是最低的。见最上面的近三年收益率图
而这两只海外QDII基金的规模有点小,尤其是国富全球科技互联(006373),当前规模只有8千万,遇到暴跌行情时会有赎回的流动性问题,且有触发低于规定规模(一般3千万)而清盘的风险。
在这8只全球海外基金里,还有一只重仓科技互联网的基金,工银全球精选股票,目前该基金经理为林念。而且它的基金规模接近4个亿,比富国全球科技和国富全球科技互联的规模要大。
其十大持仓股:
工银全球精选股票
从上图可以看到该基金的十大持仓里基本囊括了微软谷歌META这种美国优秀互联网企业,也有国内腾讯,台积电这样的互联网,芯片龙头企业。
而该基金从成立到现在,该基金的累计收益率为200%,最大回撤为-28%, 回撤控制得相当不错。对于厌恶风险的朋友,又想投资互联网科技股的朋友可以考虑考虑此基金。
工银全球精选最大回撤
如果你想像买国内贵州茅台股票那样的消费品,来对标买入全球范围内类似茅台此类优秀的股票,那么买入跟踪全球的消费指数的基金----易方达标普消费品,是一个很不错的选择。
从它的跟踪标的来看,它的确如茅台一样,在国内看来,持有的都是些奢华的消费品。
易方达标普消费品十大持仓
国内百姓日常能买的,这里面也只有耐克了。。。。。
这些公司的奢侈品如茅台一样具有很高的溢价,为了维持品牌形象,它们的定价策略是不轻易走降价路线的,况且也不愁卖不出。
正如雪球上的主流投资理念,买股票就是买公司;买入易方达标普消费品QDII基金,等于一篮子买入了这些奢侈品公司,何不美哉?
如何选择适合我的QDII基金?
先看最近5年每年度的收益率以及近5年的收益率:
最近5年的年度收益率
5年累计收益
石油,黄金,抗通胀类的基金,属于周期性的品种,个人觉得是不能长持的,一旦在上涨周期的冲顶阶段迈入了,很可能就是要被套个几年了。如果一直持有会一直坐过山车;这类基金适合在周期底部开始买入;一般而言,底部要比顶部要好判断的多。有反弹了,可以继续持有,等待上涨周期的到来;而且不能买入过早,不然前期会比较煎熬,比较考验耐心。
而医疗和消费是可以长期持有并穿越牛熊的。从最近5年的广发全球医疗和易方达标普消费的每年收益率和近5年总收益率来看,绝大部分年份都不是涨幅最大的,但跌幅也不是最大的,波动不如其他几个科技,石油来的大,但累计收益却是最大的2个。这其实和股票交易的很像,每天上蹿下跳的,实际几年下来可能还是原地踏步甚至倒退。
广发全球医疗成立以来的业绩曲线
广发全球医疗
波动率和最大回撤都要比沪深300低,截止当前的累计收益率为141%,高于沪深300的56%,典型的长牛走势。
虽然石油类QDII具有强周期属性,但作为基金市场上场内外购买渠道里,直接对标全球原油的基金只有华安标普全球石油和广发石油指数,人气更高的华宝油气挂钩的则是上游油气开采的企业,和石油价格相关性比华安石油和广发石油要低不少。原来的银行渠道的可以直接购买的原油宝等高风险产品,因负油价事件已经被暂停了。
华安标普全球石油跟踪的石油指数为标普全球石油指数,其指数走势如下:
标普全球石油指数
从这近10年的走势图,2014-2015的高点在2022年中才被收复。
该指数的成分股为全球内石油巨头。
标普全球石油指数成分股
由于跟踪的是石油公司,而非石油本身,且分散买入这些石油公司,所以指数波动要比石油价格要小得多,但也是和油价呈现出强相关关系。
2020年5月的负油价事件,把该指数和跟踪它的华安标普全球石油砸了个大坑。但不会像石油期货交割那样亏完本金还要倒亏。毕竟基金持有的石油公司的资产,品牌等各类资源还在。
下图为华安标普全球石油160416场内的月K线图。
华安标普全球石油
所以华安标普全球石油这种QDII基金是普通投资者参与国际大宗商品最便捷,最简单的方式,没有换汇的繁琐和每年5W美刀的限制,不需要开通复杂的商品期货账户,只要有个雪球账户或支付宝账户就可以直接参与国际原油的交易当中了。
## 总结
在这8个全球QDII基金里,如果想参与到当下的chatGPT等AI科技浪潮中,看好AI继续引领全球经济,可以选择科技型QDII基金工银全球精选股票;
如果要长持稳妥能有够硬的抵御风险能力的QDII基金,那么可以选择易方达标普消费品和广发全球医疗保健;
如果对俄乌战事继续悲观,平时对国际时事战争比较关心,那么可以根据事件预测,适时埋伏华安标普全球石油和诺安全球黄金,做一波事件驱动的短线操作。 查看全部
这是过去十几年纳斯达克指数的月K线走势。

去年2022年回调了一年,下跌了33%,而今年截至到今天,已经涨了31%。
以前老司机曾经说过,对于纳指的每次回调都是买入的机会。老司机果诚不欺我也!
2016年的时候不少大V就在喊美股冲顶风险很大泡沫要破云云之类。再来看看我们那低估的沪深300。

最近十五年来的月K线。上涨的时光总是短暂的。如果十多年前山顶位置买的投资者,熬到现在也可能未解套。
怪不得网友们的吐槽

所以放眼全球,可选标的更为丰富,那投资标的就可以更为分散,篮子里的品种相关性就会越低,那么遭遇系统性风险的概率就越低。好比买了一揽子基于A股的基金,然后A股大盘崩了,覆巢之下无完卵,那一篮子的鸡蛋也碎了。而投资全球基金,就是把鸡蛋装到不同的篮子,甚至不同的车子里。
本期雪球老司基评测选出了8只全球市场主题基金,我们来对其进行评测,来看看各自的风格,哪一只的风格适合你。
本次评测的8个全球基金如下:

其中,易方达标普消费品,广发全球医疗保健,华安标普全球石油,诺安全球黄金这4个基金为跟踪指数型基金,主要考察基金经理对指数跟踪误差的控制能力。
工银全球精选股票,国富全球科技互联,富国全球科技互联,银华抗通胀主题主要考验基金经理的选股,择时能力。

同为投资标的为科技互联网的国富全球科技互联和富国全球科技互联,名字很像,只不过是两个基金公司发行的基金。不过它俩最近三年的收益率差距很大,国富全球科技互联(006373)最近三年的收益率为32%,而富国全球科技互联(100055)的最近三年的收益率却为-7%, 同为全球科技型股票基金,为何二者差距会有这么大呢?
根据最新的季报信息,二者的规模与持仓比较如下:

二者都属于小规模基金,规模小于3个亿,而国富全球科技互联(006373)其基金规模更加低于一个亿。国富全球科技互联(006373)的持仓股票占比比富国全球科技互联(100055)要高近20%(79% vs 61%)
而对比一下二者的十大持仓股,黄色标注的为中概股(港股),富国全球科技(100055)十大持仓里有8个中概股。

这种情况下,很难躲过中概股的这一轮下跌的。
而最近2年的中概股走势你们也是有目共睹的。

就这样跌跌跌的走势,还想着赚钱? 能保本不亏已经算是人上人了。
因此富国全球科技(100055)在评测的这8个海外基金里面,最近3年的收益率是最低的。见最上面的近三年收益率图
而这两只海外QDII基金的规模有点小,尤其是国富全球科技互联(006373),当前规模只有8千万,遇到暴跌行情时会有赎回的流动性问题,且有触发低于规定规模(一般3千万)而清盘的风险。
在这8只全球海外基金里,还有一只重仓科技互联网的基金,工银全球精选股票,目前该基金经理为林念。而且它的基金规模接近4个亿,比富国全球科技和国富全球科技互联的规模要大。
其十大持仓股:

工银全球精选股票
从上图可以看到该基金的十大持仓里基本囊括了微软谷歌META这种美国优秀互联网企业,也有国内腾讯,台积电这样的互联网,芯片龙头企业。
而该基金从成立到现在,该基金的累计收益率为200%,最大回撤为-28%, 回撤控制得相当不错。对于厌恶风险的朋友,又想投资互联网科技股的朋友可以考虑考虑此基金。

工银全球精选最大回撤
如果你想像买国内贵州茅台股票那样的消费品,来对标买入全球范围内类似茅台此类优秀的股票,那么买入跟踪全球的消费指数的基金----易方达标普消费品,是一个很不错的选择。
从它的跟踪标的来看,它的确如茅台一样,在国内看来,持有的都是些奢华的消费品。

易方达标普消费品十大持仓
国内百姓日常能买的,这里面也只有耐克了。。。。。
这些公司的奢侈品如茅台一样具有很高的溢价,为了维持品牌形象,它们的定价策略是不轻易走降价路线的,况且也不愁卖不出。
正如雪球上的主流投资理念,买股票就是买公司;买入易方达标普消费品QDII基金,等于一篮子买入了这些奢侈品公司,何不美哉?
如何选择适合我的QDII基金?
先看最近5年每年度的收益率以及近5年的收益率:

最近5年的年度收益率

5年累计收益
石油,黄金,抗通胀类的基金,属于周期性的品种,个人觉得是不能长持的,一旦在上涨周期的冲顶阶段迈入了,很可能就是要被套个几年了。如果一直持有会一直坐过山车;这类基金适合在周期底部开始买入;一般而言,底部要比顶部要好判断的多。有反弹了,可以继续持有,等待上涨周期的到来;而且不能买入过早,不然前期会比较煎熬,比较考验耐心。
而医疗和消费是可以长期持有并穿越牛熊的。从最近5年的广发全球医疗和易方达标普消费的每年收益率和近5年总收益率来看,绝大部分年份都不是涨幅最大的,但跌幅也不是最大的,波动不如其他几个科技,石油来的大,但累计收益却是最大的2个。这其实和股票交易的很像,每天上蹿下跳的,实际几年下来可能还是原地踏步甚至倒退。
广发全球医疗成立以来的业绩曲线

广发全球医疗
波动率和最大回撤都要比沪深300低,截止当前的累计收益率为141%,高于沪深300的56%,典型的长牛走势。
虽然石油类QDII具有强周期属性,但作为基金市场上场内外购买渠道里,直接对标全球原油的基金只有华安标普全球石油和广发石油指数,人气更高的华宝油气挂钩的则是上游油气开采的企业,和石油价格相关性比华安石油和广发石油要低不少。原来的银行渠道的可以直接购买的原油宝等高风险产品,因负油价事件已经被暂停了。
华安标普全球石油跟踪的石油指数为标普全球石油指数,其指数走势如下:

标普全球石油指数
从这近10年的走势图,2014-2015的高点在2022年中才被收复。
该指数的成分股为全球内石油巨头。

标普全球石油指数成分股
由于跟踪的是石油公司,而非石油本身,且分散买入这些石油公司,所以指数波动要比石油价格要小得多,但也是和油价呈现出强相关关系。
2020年5月的负油价事件,把该指数和跟踪它的华安标普全球石油砸了个大坑。但不会像石油期货交割那样亏完本金还要倒亏。毕竟基金持有的石油公司的资产,品牌等各类资源还在。
下图为华安标普全球石油160416场内的月K线图。

华安标普全球石油
所以华安标普全球石油这种QDII基金是普通投资者参与国际大宗商品最便捷,最简单的方式,没有换汇的繁琐和每年5W美刀的限制,不需要开通复杂的商品期货账户,只要有个雪球账户或支付宝账户就可以直接参与国际原油的交易当中了。
## 总结
在这8个全球QDII基金里,如果想参与到当下的chatGPT等AI科技浪潮中,看好AI继续引领全球经济,可以选择科技型QDII基金工银全球精选股票;
如果要长持稳妥能有够硬的抵御风险能力的QDII基金,那么可以选择易方达标普消费品和广发全球医疗保健;
如果对俄乌战事继续悲观,平时对国际时事战争比较关心,那么可以根据事件预测,适时埋伏华安标普全球石油和诺安全球黄金,做一波事件驱动的短线操作。
Ptrade几个order下单接口 order_target order_value order_target_value order_market的不同
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 856 次浏览 • 2023-07-10 02:23
https://ptradeapi.com
注意:大部分函数自适用于交易模块,回测模式不支持部分order函数。
order_target :
接口通过持仓数量比较将入参的目标数量转换成需要交易的成交,传入 order
接口
order_value:
接口通过 金额/限价 或者 金额/默认最新价 两种方式转换成需要交易的数量,
传入 order 接口
order_target_value:
接口通过持仓金额比较得到需要交易的金额, 金额/限价 或者 金额/默
认最新价 两种方式转换成需要交易的数量,传入 order 接口
order 接口:
一、
先判断 limit_price 是否传入,传入则用传入价格限价,不传入则最新价代替,都是
限价方式报单。
二、
判断隔夜单和交易时间,交易时间(9:10(系统可配)~15:00)范围的订单会马上
加入未处理订单队列,其他订单先放到一个队列,等时间到交易时间就放到未处理订单
队列
三、
未处理订单队列的订单会进行限价判断,如果没有传入限价就按当前最新价处理,
然后报柜台。
order_market 接口:
一、
按照传入的 market_type 参数,市价委托方式报单。
二、
判断隔夜单和交易时间,交易时间(9:10(系统可配)~15:00)范围的订单会马上
加入未处理订单队列,其他订单先放到一个队列,等时间到交易时间就翻到未处理订单
队列
三、
未处理订单队列的订单会进行限价判断,如果没有传入限价就按当前最新价处理,
之后买单和卖单处理有所不同,买单直接报柜台,卖单会校验持仓最大可卖然后调整数
量再报柜台。
tick_order:
一、
先判断 limit_price 是否传入,传入则用传入价格限价,不传入则取档位价格(默
认第一档)
,都是限价方式报单。
二、
直接放到未处理订单队列
三、
未处理订单队列的订单会进行限价判断,如果没有传入限价就按当前最新价处理,
然后报柜台。
低门槛入金(2W)开通Ptrade量化API,扫码联系: 查看全部
https://ptradeapi.com

注意:大部分函数自适用于交易模块,回测模式不支持部分order函数。
order_target :
接口通过持仓数量比较将入参的目标数量转换成需要交易的成交,传入 order
接口
order_value:
接口通过 金额/限价 或者 金额/默认最新价 两种方式转换成需要交易的数量,
传入 order 接口
order_target_value:
接口通过持仓金额比较得到需要交易的金额, 金额/限价 或者 金额/默
认最新价 两种方式转换成需要交易的数量,传入 order 接口
order 接口:
一、
先判断 limit_price 是否传入,传入则用传入价格限价,不传入则最新价代替,都是
限价方式报单。
二、
判断隔夜单和交易时间,交易时间(9:10(系统可配)~15:00)范围的订单会马上
加入未处理订单队列,其他订单先放到一个队列,等时间到交易时间就放到未处理订单
队列
三、
未处理订单队列的订单会进行限价判断,如果没有传入限价就按当前最新价处理,
然后报柜台。
order_market 接口:
一、
按照传入的 market_type 参数,市价委托方式报单。
二、
判断隔夜单和交易时间,交易时间(9:10(系统可配)~15:00)范围的订单会马上
加入未处理订单队列,其他订单先放到一个队列,等时间到交易时间就翻到未处理订单
队列
三、
未处理订单队列的订单会进行限价判断,如果没有传入限价就按当前最新价处理,
之后买单和卖单处理有所不同,买单直接报柜台,卖单会校验持仓最大可卖然后调整数
量再报柜台。
tick_order:
一、
先判断 limit_price 是否传入,传入则用传入价格限价,不传入则取档位价格(默
认第一档)
,都是限价方式报单。
二、
直接放到未处理订单队列
三、
未处理订单队列的订单会进行限价判断,如果没有传入限价就按当前最新价处理,
然后报柜台。
低门槛入金(2W)开通Ptrade量化API,扫码联系:
QMT vs PTrade资金更新速度|高频中如何处理
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 986 次浏览 • 2023-07-06 17:35
平时在手动交易中,下单委托后,再切换回去持仓页面,可以看到你的可用资金变少了。而在QMT和PTrade里面,却可能会表现得不一样。本文用代码和实盘来作对比。希望本文对量化新手有所帮助,记得收藏哦! 公众号首页链接了视频号,里面也有不少的新手入门教程和进阶教程,欢迎观看。
了解量化交易程序里面的资金更新速度,无论对量化T+0日内交易(可转债,T+0 ETF),还是轮动策略调仓,都是必须的。
Ptrade
以交易逆回购为例,这也便于量化新手也可以实践,可以放心跑,不会亏钱。
代码很简单,每个tick_data行情更新时间(3秒)里打印当前的可用资金。中途买入(借出)逆回购后,看看当面打印的可用资金什么时候发生变化。
import datetime
def initialize(context):
# 初始化策略
g.already_run = False
def handle_data(context, data):
pass
def get_available_cash(context):
# 读取变量protfolio里的可用资金的值
return context.portfolio.cash
def current_time():
return datetime.datetime.now().strftime('%H:%M:%S.%f')
def tick_data(context, data):
log.info('可用资金{}'.format(get_available_cash(context)))
if not g.already_run:
g.already_run = True
# 卖出100手 R-001
ret = order_tick('131810.SZ', -10, priceGear='1', limit_price=None)
def on_order_response(context, trade_list):
# 委托回调函数,有委托出现就调用此函数
log.info('已委托下单 {}'.format(current_time()))
放到Ptrade的实盘里执行,得到下面日志
下单前可用资金为17902,程序启动后下单时间在10:41:08,卖出10张R-001,市值1000元;间隔3s后打印可用资金,在10:41:13的时候,可用资金依然是17902,此时时间已经过去了5秒;
在10:41:18打印的时候资产才发生了变化,此时可用资金为16902,此时距离下单时的10:41:08,已经过去了10秒。所以如果在高频下单时,使用读取内置的context.portfolio.cash 来获取可用资金,那就寄了。那是不是意味着Ptrade无法进行高频率的交易了呢?当然不是的,此时可以使用内置的成交主推函数来更新可用资金,后面下面再介绍。
QMT
而qmt的代码如下,把打印的可用资金的操作放到handlebar里面,它和上面的Ptrade作用一样,每隔3s执行一次。
# encoding:gbk
import datetime
ACCOUNT = '你的账户ID'
start = True
def init(ContextInfo):
ContextInfo.set_account(ACCOUNT)
def current_time():
return datetime.datetime.now().strftime('%H:%M:%S.%f')
def get_available_cash(ContextInfo):
acct_info = get_trade_detail_data(ACCOUNT, 'stock', 'account')
return acct_info[0].m_dAvailable
def deal_callback(ContextInfo, dealInfo):
print('before')
print(dealInfo.m_strProductID)
print(dealInfo.m_nDirection)
print(dealInfo.m_dTradeAmount)
print(dealInfo.m_nVolume)
print(dealInfo.m_dPrice)
print('call back --- ')
print(current_time())
def buy_action(ContextInfo):
opType = 24
orderType = 1101
accountID = ACCOUNT
orderCode = '131810.SZ'
prType = 11
price = 1.8
volume = 10
quickTrade = 2
passorder(opType, orderType, accountID, orderCode, prType, price, volume, quickTrade, ContextInfo)
def handlebar(ContextInfo):
global start
if ContextInfo.is_last_bar():
cash = get_available_cash(ContextInfo)
print('{} 可用资金{}'.format(current_time(),cash))
if start:
print('下单逆回购 131810 ')
buy_action(ContextInfo)
start = False
部署到QMT实盘后,执行。
得到下面的运行日志:
从上面的日志看出,程序在14:35:11启动,马上使用passorder下单,卖出1000元的R-001,此时时间14:35:12,马上成交了。而可用资金在下单后的0.47秒后,14:35:12,显示少了1000元。此时的资金状态已经被更新了。
所以QMT的资金持仓更新速度要比Ptrade快出不少的,如果不是追求毫秒级别的话,这个速度足够满足大部分的轮动和T+0操作了。
虽然QMT的资金持仓更新很快,但如果你的策略是高频或偏高频运行,比如你这一个时刻刚刚买入,下一个tick来到时就要卖出,或者采用驱动成交型的网格交易,你无法知道挂单是在哪一个时刻成交的,此时也亦不能一直循环读取你的可以资金或者持仓来判断是否成交,因为这样会阻塞QMT无法进行下一步的操作(除非你本身就是一直在等待成交,成交后才进行下程序一步)。
委托、成交回调函数
Ptrade和QMT都有对应的委托成交回调函数,用于应对需要即时获取成交状态的情景下。
接口文档介绍如下
Ptrade http://ptradeapi.com/#on_trade_response
QMT:http://qmt.ptradeapi.com/QMT_Python_API_Doc.html#deal-callback
里面就说明了,“该函数会在成交主推回调时响应,比引擎和get_trades()函数更新Order状态的速度更快,适合对速度要求比较高的策略。”
Ptrade的部分代码片段如下:
# 交易回调
def on_trade_response(context, trade_list):
# 成交主推
now = context.blotter.current_dt.strftime("%H:%M:%S")
for trade_info in trade_list:
if trade_info['order_id'] == '':
# 不是本策略跳过
log.info('非本策略订单')
continue
code = trade_info['stock_code']
code = post_fix_convert(code)
business_time = trade_info['business_time']
business_amount = trade_info['business_amount'] # 这个是负数,如果卖出
business_price = trade_info['business_price']
g.total_cash -= business_amount # 马上更新资金状态
g.total_cash -= business_amount # 马上更新资金状态g.total_cash是一个全局的可用资金, 可以提前设定好,亦可以是开盘前读取一次你的账户可用资金。
每次成交的那一刻,on_trade_response这个函数就会被动触发,在这里就可以简单的更新你的资金状态了。上面的例子是最基础的更新资金。
实际可以使用其他的诸如dict或类对象来更新仓位。
上面代码是把仓位更新放到一个全局dict里面,key是股票代码,value也是一个dict,里面包含交易时间,持仓数目,价格等等。
好了,时间有限,今天的教程就到这里了,码字不易,欢迎点赞+收藏哦~
查看全部
平时在手动交易中,下单委托后,再切换回去持仓页面,可以看到你的可用资金变少了。而在QMT和PTrade里面,却可能会表现得不一样。本文用代码和实盘来作对比。希望本文对量化新手有所帮助,记得收藏哦! 公众号首页链接了视频号,里面也有不少的新手入门教程和进阶教程,欢迎观看。
了解量化交易程序里面的资金更新速度,无论对量化T+0日内交易(可转债,T+0 ETF),还是轮动策略调仓,都是必须的。
Ptrade
以交易逆回购为例,这也便于量化新手也可以实践,可以放心跑,不会亏钱。
代码很简单,每个tick_data行情更新时间(3秒)里打印当前的可用资金。中途买入(借出)逆回购后,看看当面打印的可用资金什么时候发生变化。
import datetime
def initialize(context):
# 初始化策略
g.already_run = False
def handle_data(context, data):
pass
def get_available_cash(context):
# 读取变量protfolio里的可用资金的值
return context.portfolio.cash
def current_time():
return datetime.datetime.now().strftime('%H:%M:%S.%f')
def tick_data(context, data):
log.info('可用资金{}'.format(get_available_cash(context)))
if not g.already_run:
g.already_run = True
# 卖出100手 R-001
ret = order_tick('131810.SZ', -10, priceGear='1', limit_price=None)
def on_order_response(context, trade_list):
# 委托回调函数,有委托出现就调用此函数
log.info('已委托下单 {}'.format(current_time()))
放到Ptrade的实盘里执行,得到下面日志

下单前可用资金为17902,程序启动后下单时间在10:41:08,卖出10张R-001,市值1000元;间隔3s后打印可用资金,在10:41:13的时候,可用资金依然是17902,此时时间已经过去了5秒;
在10:41:18打印的时候资产才发生了变化,此时可用资金为16902,此时距离下单时的10:41:08,已经过去了10秒。所以如果在高频下单时,使用读取内置的context.portfolio.cash 来获取可用资金,那就寄了。那是不是意味着Ptrade无法进行高频率的交易了呢?当然不是的,此时可以使用内置的成交主推函数来更新可用资金,后面下面再介绍。
QMT
而qmt的代码如下,把打印的可用资金的操作放到handlebar里面,它和上面的Ptrade作用一样,每隔3s执行一次。
# encoding:gbk
import datetime
ACCOUNT = '你的账户ID'
start = True
def init(ContextInfo):
ContextInfo.set_account(ACCOUNT)
def current_time():
return datetime.datetime.now().strftime('%H:%M:%S.%f')
def get_available_cash(ContextInfo):
acct_info = get_trade_detail_data(ACCOUNT, 'stock', 'account')
return acct_info[0].m_dAvailable
def deal_callback(ContextInfo, dealInfo):
print('before')
print(dealInfo.m_strProductID)
print(dealInfo.m_nDirection)
print(dealInfo.m_dTradeAmount)
print(dealInfo.m_nVolume)
print(dealInfo.m_dPrice)
print('call back --- ')
print(current_time())
def buy_action(ContextInfo):
opType = 24
orderType = 1101
accountID = ACCOUNT
orderCode = '131810.SZ'
prType = 11
price = 1.8
volume = 10
quickTrade = 2
passorder(opType, orderType, accountID, orderCode, prType, price, volume, quickTrade, ContextInfo)
def handlebar(ContextInfo):
global start
if ContextInfo.is_last_bar():
cash = get_available_cash(ContextInfo)
print('{} 可用资金{}'.format(current_time(),cash))
if start:
print('下单逆回购 131810 ')
buy_action(ContextInfo)
start = False
部署到QMT实盘后,执行。
得到下面的运行日志:

从上面的日志看出,程序在14:35:11启动,马上使用passorder下单,卖出1000元的R-001,此时时间14:35:12,马上成交了。而可用资金在下单后的0.47秒后,14:35:12,显示少了1000元。此时的资金状态已经被更新了。
所以QMT的资金持仓更新速度要比Ptrade快出不少的,如果不是追求毫秒级别的话,这个速度足够满足大部分的轮动和T+0操作了。
虽然QMT的资金持仓更新很快,但如果你的策略是高频或偏高频运行,比如你这一个时刻刚刚买入,下一个tick来到时就要卖出,或者采用驱动成交型的网格交易,你无法知道挂单是在哪一个时刻成交的,此时也亦不能一直循环读取你的可以资金或者持仓来判断是否成交,因为这样会阻塞QMT无法进行下一步的操作(除非你本身就是一直在等待成交,成交后才进行下程序一步)。
委托、成交回调函数
Ptrade和QMT都有对应的委托成交回调函数,用于应对需要即时获取成交状态的情景下。
接口文档介绍如下
Ptrade http://ptradeapi.com/#on_trade_response
QMT:http://qmt.ptradeapi.com/QMT_Python_API_Doc.html#deal-callback

里面就说明了,“该函数会在成交主推回调时响应,比引擎和get_trades()函数更新Order状态的速度更快,适合对速度要求比较高的策略。”
Ptrade的部分代码片段如下:
# 交易回调
def on_trade_response(context, trade_list):
# 成交主推
now = context.blotter.current_dt.strftime("%H:%M:%S")
for trade_info in trade_list:
if trade_info['order_id'] == '':
# 不是本策略跳过
log.info('非本策略订单')
continue
code = trade_info['stock_code']
code = post_fix_convert(code)
business_time = trade_info['business_time']
business_amount = trade_info['business_amount'] # 这个是负数,如果卖出
business_price = trade_info['business_price']
g.total_cash -= business_amount # 马上更新资金状态
g.total_cash -= business_amount # 马上更新资金状态g.total_cash是一个全局的可用资金, 可以提前设定好,亦可以是开盘前读取一次你的账户可用资金。
每次成交的那一刻,on_trade_response这个函数就会被动触发,在这里就可以简单的更新你的资金状态了。上面的例子是最基础的更新资金。
实际可以使用其他的诸如dict或类对象来更新仓位。

上面代码是把仓位更新放到一个全局dict里面,key是股票代码,value也是一个dict,里面包含交易时间,持仓数目,价格等等。
好了,时间有限,今天的教程就到这里了,码字不易,欢迎点赞+收藏哦~
目前支持量化接口的万一免五的券商有哪些?
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 2105 次浏览 • 2023-07-04 22:52
其中能够股票免五的有国金证券,国盛证券,国信证券,安信证券。
其中,国金证券,国盛证券支持QMT、MiniQMT、Ptrade。
国信证券,安信证券支持QMT。
东莞证券支持Ptrade
可转债默认免五。
开户后可加入量化技术交流群,可获得编程技术指导。
【提问者需要把问题描述清楚即可,PS: 有些人动不动就说:“Ptrade不行呀”,“QMT垃圾呀”,结果让他贴代码上来瞅瞅,是他本身代码写的拉垮,目前贴出来的已知的问题,90%是个人代码问题。】
扫码添加微信咨询开户:
查看全部

其中能够股票免五的有国金证券,国盛证券,国信证券,安信证券。
其中,国金证券,国盛证券支持QMT、MiniQMT、Ptrade。
国信证券,安信证券支持QMT。
东莞证券支持Ptrade
可转债默认免五。

开户后可加入量化技术交流群,可获得编程技术指导。
【提问者需要把问题描述清楚即可,PS: 有些人动不动就说:“Ptrade不行呀”,“QMT垃圾呀”,结果让他贴代码上来瞅瞅,是他本身代码写的拉垮,目前贴出来的已知的问题,90%是个人代码问题。】
扫码添加微信咨询开户:
Ptrade/QMT 可转债转股操作 python代码
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 1341 次浏览 • 2023-06-19 18:14
而这个转股操作是要在交易时间,也就是盘中时间下一个债转股的命令,然后盘后交易所会更会你盘中下的转股指令,将对应的可转债转为对应的股票,这是,持仓里面的可转债会消失,变成该可转债对应的正股。
(当然这是在全部转股的前提下的情况,也有可能有部分人转债只转一部分,这样持仓里面还仍然会有部分可转债没有被转为股票)
那么在Ptrade和QMT里面,如何调用API接口进行可转债转股呢?
Ptrade:
def initialize(context):
g.security = "600570.SS"
set_universe(g.security)
def before_trading_start(context, data):
g.count = 0
def handle_data(context, data):
if g.count == 0:
# 对持仓内的贝斯进行转股操作
debt_to_stock_order("123075.SZ", -1000)
g.count += 1
# 查看委托状态
log.info(get_orders())
g.count += 1
主要是上面的函数,
debt_to_stock_order 传入可转债代码和转股的数量,注意数量用加一个负号。
QMT可转债转股操作
#coding:gbk
c = True
account = '11111111' # 个人账户
def init(ContextInfo):
pass
def handlebar(ContextInfo):
if not ContextInfo.is_last_bar():
#历史k线不应该发出实盘信号 跳过
return
if c:
passorder(80,1101,account,s,5,0,-100,'1',2,'tzbz',ContextInfo)
c=False
passorder 里面的 80是 普通账户可转债转股
更多Ptrade,qmt知识,可以关注公众号
查看全部
而这个转股操作是要在交易时间,也就是盘中时间下一个债转股的命令,然后盘后交易所会更会你盘中下的转股指令,将对应的可转债转为对应的股票,这是,持仓里面的可转债会消失,变成该可转债对应的正股。
(当然这是在全部转股的前提下的情况,也有可能有部分人转债只转一部分,这样持仓里面还仍然会有部分可转债没有被转为股票)
那么在Ptrade和QMT里面,如何调用API接口进行可转债转股呢?
Ptrade:
def initialize(context):
g.security = "600570.SS"
set_universe(g.security)
def before_trading_start(context, data):
g.count = 0
def handle_data(context, data):
if g.count == 0:
# 对持仓内的贝斯进行转股操作
debt_to_stock_order("123075.SZ", -1000)
g.count += 1
# 查看委托状态
log.info(get_orders())
g.count += 1
主要是上面的函数,
debt_to_stock_order 传入可转债代码和转股的数量,注意数量用加一个负号。
QMT可转债转股操作
#coding:gbk
c = True
account = '11111111' # 个人账户
def init(ContextInfo):
pass
def handlebar(ContextInfo):
if not ContextInfo.is_last_bar():
#历史k线不应该发出实盘信号 跳过
return
if c:
passorder(80,1101,account,s,5,0,-100,'1',2,'tzbz',ContextInfo)
c=False
passorder 里面的 80是 普通账户可转债转股
更多Ptrade,qmt知识,可以关注公众号
宁稳可转债全表数据 - 历史数据更新至2023年06-18日
可转债 • 李魔佛 发表了文章 • 0 个评论 • 986 次浏览 • 2023-06-19 11:16
转债代码 转债名称 满足 发行日期 股票代码 股票名称 行业 子行业 转债价格 本息 涨跌 日内套利 股价 正股涨跌 剩余本息 转股价格 转股溢价率 转股价值 距离转股日 剩余年限 回售年限 剩余余额 成交额(百万) 转债换手率 余额/市值 余额/股本 股票市值(亿) P/B 税前收益率 税后收益率 税前回售收益 税后回售收益 回售价值 纯债价值 弹性 信用 折现率 老式双低 老式排名 新式双低 新式排名 热门度
点击查看大图
点击查看大图
数据会定期更新,目前更新到本文发文日期,2023-06-18
查看全部
转债代码 转债名称 满足 发行日期 股票代码 股票名称 行业 子行业 转债价格 本息 涨跌 日内套利 股价 正股涨跌 剩余本息 转股价格 转股溢价率 转股价值 距离转股日 剩余年限 回售年限 剩余余额 成交额(百万) 转债换手率 余额/市值 余额/股本 股票市值(亿) P/B 税前收益率 税后收益率 税前回售收益 税后回售收益 回售价值 纯债价值 弹性 信用 折现率 老式双低 老式排名 新式双低 新式排名 热门度

点击查看大图

点击查看大图
数据会定期更新,目前更新到本文发文日期,2023-06-18
高效操作!linux在终端里快速跳转到文件管理器对应的目录下
Linux • 马化云 发表了文章 • 0 个评论 • 777 次浏览 • 2023-06-15 19:34
然后你想用chrome打开这个html文件,那么你可能需要打开文件管理器,切换到上述路径,选中上述修改的html文件。
(具体可以参考vs code的打开方式, cd 到某个目录, 然后运行: "code . " 然后就可以直接用vs code打开当前目录 )
你可以使用以下命令在Linux终端中打开文件浏览器并将其设置为当前目录:
- GNOME桌面环境:在终端中输入 `nautilus .`,即可在当前目录下打开Nautilus文件管理器。
- KDE桌面环境:在终端中输入 `dolphin .`,即可在当前目录下打开Dolphin文件管理器。
- Xfce桌面环境:在终端中输入 `thunar .`,即可在当前目录下打开Thunar文件管理器。
- LXDE桌面环境:在终端中输入 `pcmanfm .`,即可在当前目录下打开PCManFM文件管理器。
这些命令都会在当前目录下启动相应的文件管理器,以便您进行文件操作。
当然,手动敲那么多字也是挺累的。
### 如何自动化?
可以做成别名写到启动环境里面vim ~/.bashrc在这个文件里面的最后一行
加入对应的语句alias here="nautilus ."
以后只要你在终端下面输入 here
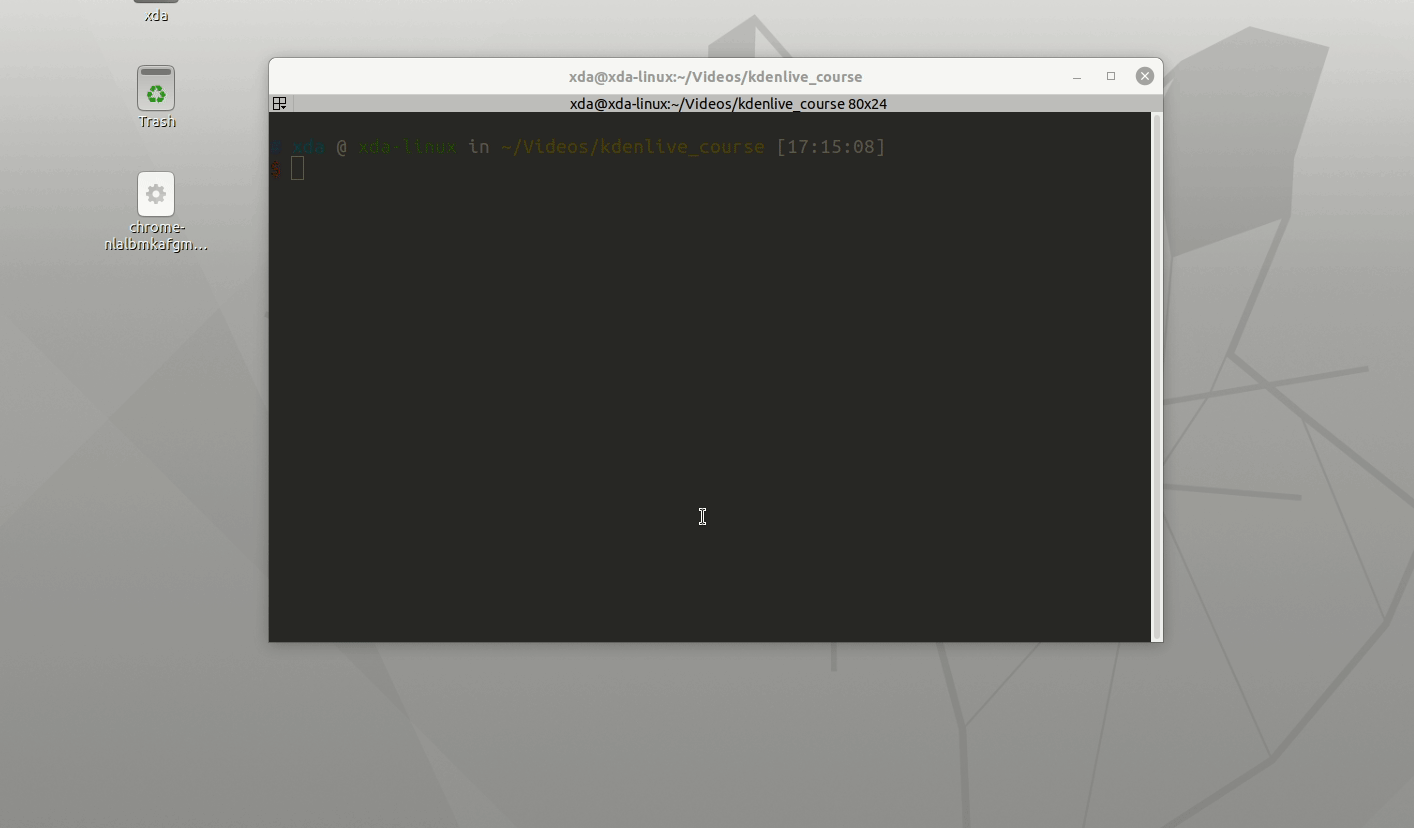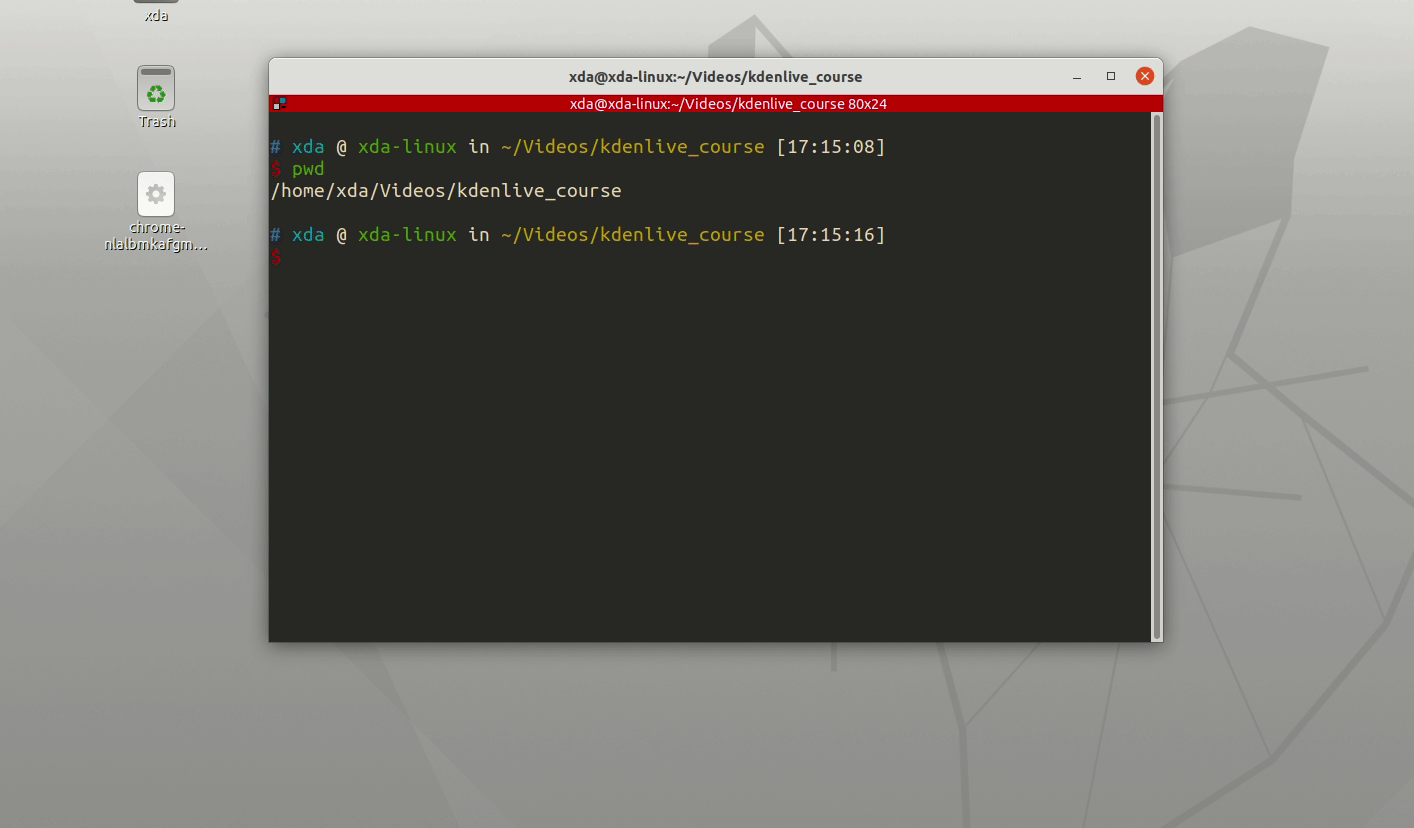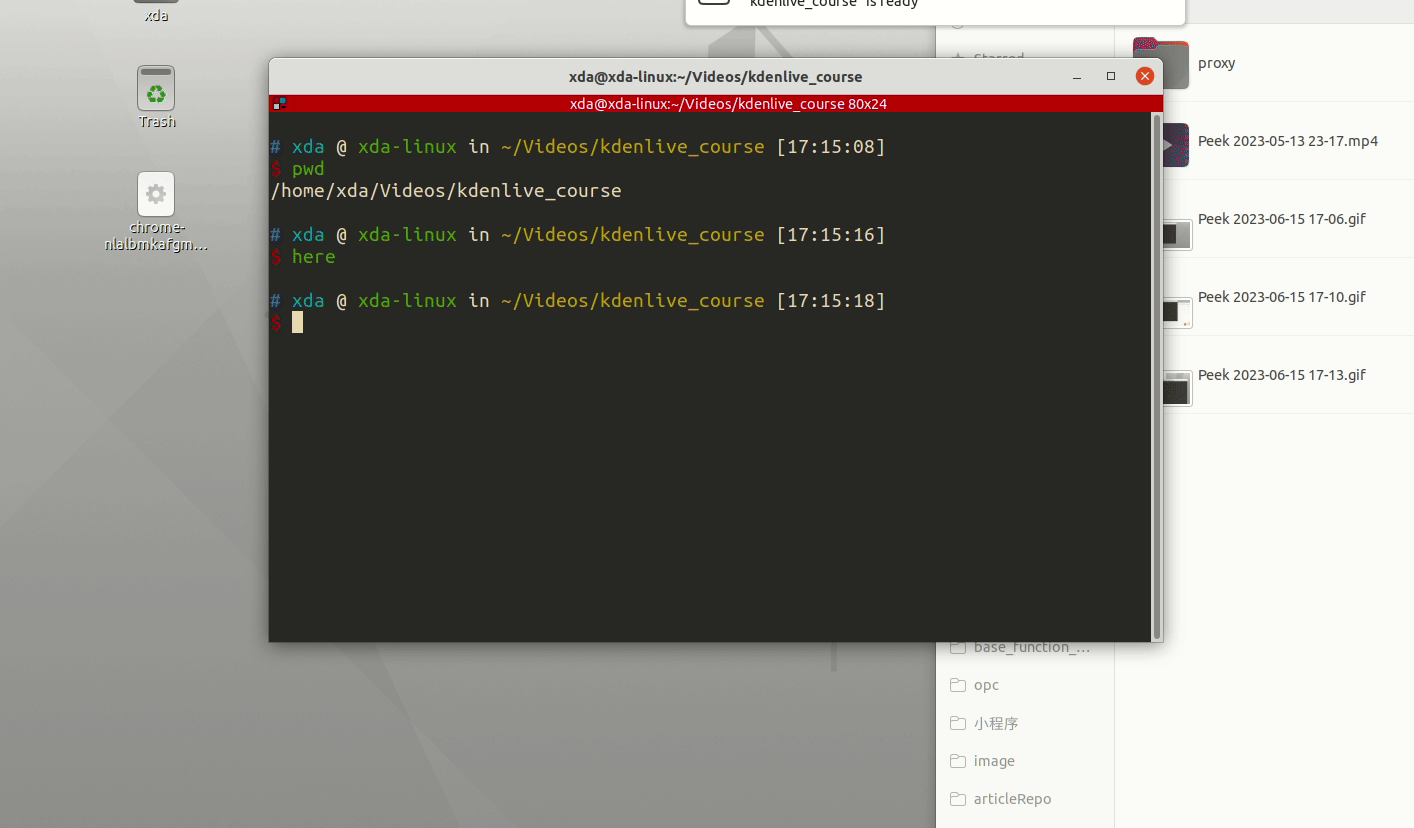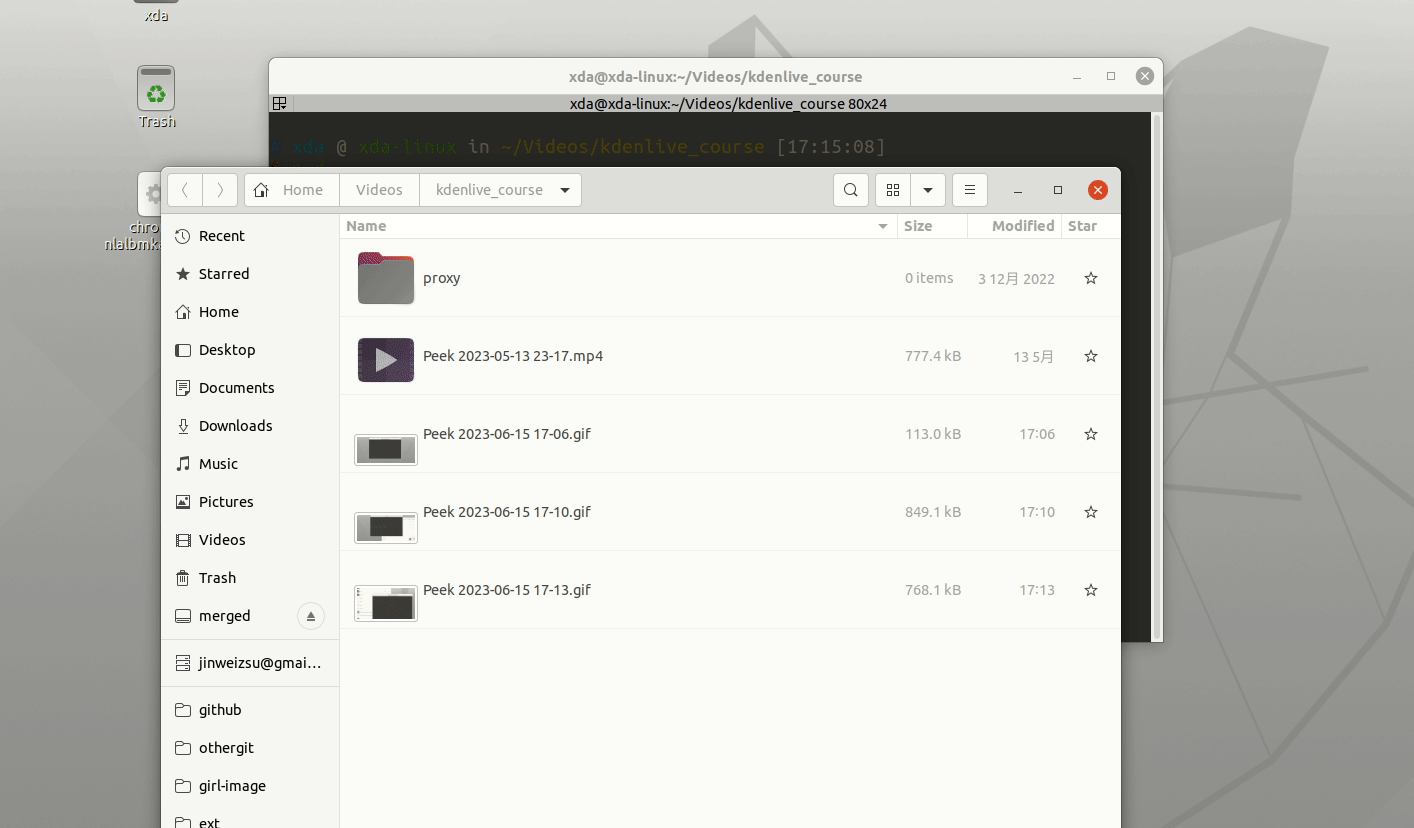
那么就会自动打开文件管理器,然后文件管理器的路径和你的终端路径一样。这样很方便吧? 查看全部
然后你想用chrome打开这个html文件,那么你可能需要打开文件管理器,切换到上述路径,选中上述修改的html文件。
(具体可以参考vs code的打开方式, cd 到某个目录, 然后运行: "code . " 然后就可以直接用vs code打开当前目录 )
你可以使用以下命令在Linux终端中打开文件浏览器并将其设置为当前目录:
- GNOME桌面环境:在终端中输入 `nautilus .`,即可在当前目录下打开Nautilus文件管理器。
- KDE桌面环境:在终端中输入 `dolphin .`,即可在当前目录下打开Dolphin文件管理器。
- Xfce桌面环境:在终端中输入 `thunar .`,即可在当前目录下打开Thunar文件管理器。
- LXDE桌面环境:在终端中输入 `pcmanfm .`,即可在当前目录下打开PCManFM文件管理器。
这些命令都会在当前目录下启动相应的文件管理器,以便您进行文件操作。
当然,手动敲那么多字也是挺累的。
### 如何自动化?
可以做成别名写到启动环境里面
vim ~/.bashrc在这个文件里面的最后一行
加入对应的语句
alias here="nautilus ."
以后只要你在终端下面输入
here
那么就会自动打开文件管理器,然后文件管理器的路径和你的终端路径一样。这样很方便吧?