
通知设置 新通知
国盛Ptrade又可以重新开了,需要的小伙伴抓紧开啦
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1158 次浏览 • 2023-06-14 11:34
而目前又可以重新开启这个量化业务了。
如果不太懂的小伙伴,笔者这里可以稍加详细解释。
这里的外网,指的外部网络,相对券商部署的服务器内网而言的,并不是指墙外的网络哈,这里小伙伴们注意一下哈。
在大部分券商里,Ptrade是封闭环境下运行的,Ptrade是在券商的内部服务器上执行,所以它无法把数据传出外部的服务器,同样也不能访问外面服务器的数据。比如我想获取同花顺的热门概念,由于Ptrade无法访问外部网络,如果内置的Ptrade数据没有提供,就没有办法了。或者用Ptrade想要搞点可转债溢价率,规模的数据,如果没办法联通外网,实际你的策略就无法下手,因为基础数据已经缺乏了。
好在国盛的Ptrade支持外网联通,可以用爬虫的方式,读取mysql的方式,读取MQ队列的方式的等等获取外部数据,弥补内置数据的不足。
具体可以看这个文章:
http://30daydo.com/article/44453
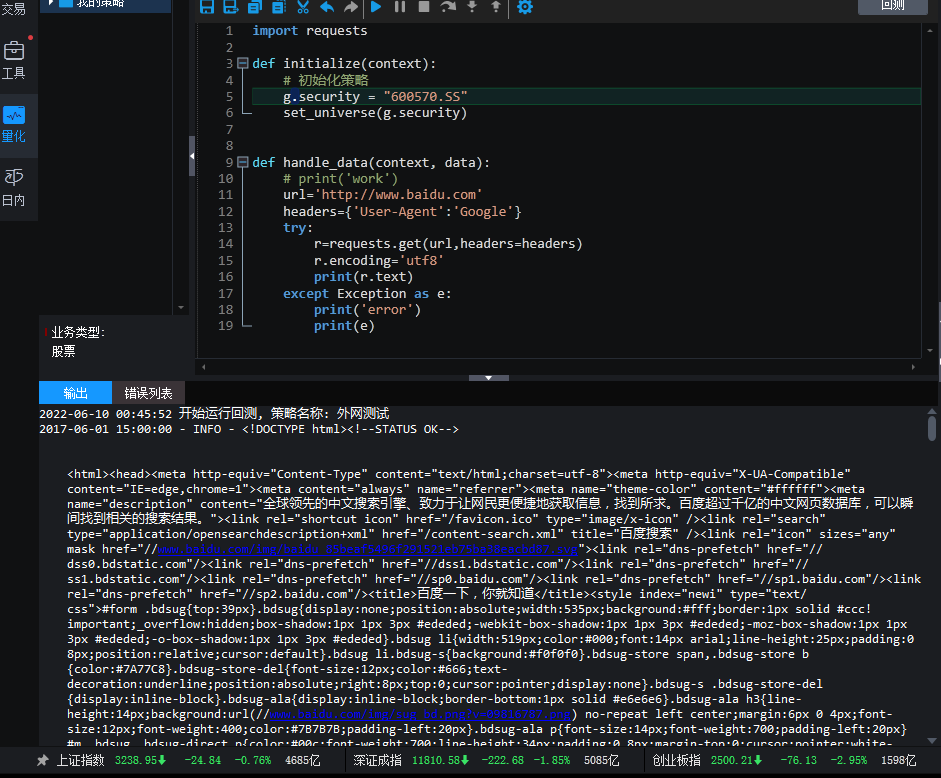
比如下面代码是在ptrade里面访问百度的:
import requests
def initialize(context):
# 初始化策略
g.security = "600570.SS"
set_universe(g.security)
def handle_data(context, data):
url='http://www.baidu.com'
headers={'User-Agent':'Google'}
try:
r=requests.get(url,headers=headers)
r.encoding='utf8'
print(r.text)
except Exception as e:
print('error')
print(e)
可以看到能够使用requests这个库正常获取数据的,当然requests库是ptrade本身就有的,不需要你再pip安装,当然ptrade也无法pip安装第三方库。
ptrade支持的内置库名单:
http://www.30daydo.com/article/44458
APScheduler (3.3.1)
arch (3.2)
bcolz (1.2.1)
beautifulsoup4 (4.6.0)
bleach (1.5.0)
boto (2.43.0)
Bottleneck (1.0.0)
bz2file (0.98)
cachetools (3.1.0)
click (4.0)
contextlib2 (0.4.0)
crypto (1.4.1)
cvxopt (1.1.8)
cx-Oracle (8.0.1)
cycler (0.10.0)
cyordereddict (0.2.2)
Cython (0.22.1)
decorator (4.0.10)
entrypoints (0.2.2)
fastcache (1.0.2)
gensim (0.13.3)
h5py (2.6.0)
hmmlearn (0.2.0)
hs-udata (0.3.6)
html5lib (0.9999999)
ipykernel (4.5.0)
ipython (5.1.0)
ipython-genutils (0.1.0)
ipywidgets (5.2.2)
jieba (0.38)
Jinja2 (2.8)
jsonpickle (1.0)
jsonschema (2.5.1)
jupyter (1.0.0)
jupyter-client (4.4.0)
jupyter-console (5.0.0)
jupyter-core (4.2.0)
jupyter-kernel-gateway (1.1.1)
Keras (2.3.1)
Keras-Applications (1.0.8)
Keras-Preprocessing (1.1.0)
line-profiler (2.1.2)
Logbook (1.4.3)
lxml (4.5.0)
Markdown (2.2.0)
MarkupSafe (0.23)
matplotlib (1.5.3)
mistune (0.7.3)
Naked (0.1.31)
nbconvert (4.2.0)
nbformat (4.1.0)
networkx (1.9.1)
nose (1.3.6)
notebook (4.2.3)
numexpr (2.6.1)
numpy (1.11.2)
pandas (0.23.4)
patsy (0.4.0)
pexpect (4.2.1)
pickleshare (0.7.4)
pip (9.0.1)
pkgconfig (1.0.0)
prompt-toolkit (1.0.8)
protobuf (3.3.0)
ptvsd (2.2.0)
ptyprocess (0.5.1)
PyBrain (0.3)
pycrypto (2.6.1)
Pygments (2.1.3)
PyMySQL (0.9.3)
pyparsing (2.1.10)
python-dateutil (2.7.5)
pytz (2015.4)
PyWavelets (0.4.0)
PyYAML (5.3.1)
pyzmq (16.1.0.dev0)
qtconsole (4.2.1)
requests (2.7.0)
retrying (1.3.3)
scikit-learn (0.18)
scipy (0.18.0)
seaborn (0.7.1)
setuptools (28.7.1)
setuptools-scm (3.1.0)
shellescape (3.4.1)
simplegeneric (0.8.1)
simplejson (3.17.0)
six (1.10.0)
sklearn (0.0)
smart-open (1.3.5)
SQLAlchemy (1.0.8)
statsmodels (0.10.2)
TA-Lib (0.4.10)
tables (3.3.0)
tabulate (0.7.5)
tensorflow (1.3.0rc1)
tensorflow-tensorboard (0.1.2)
terminado (0.6)
Theano (0.8.2)
toolz (0.7.4)
tornado (4.4.2)
traitlets (4.3.1)
tushare (1.2.48)
tzlocal (1.3)
wcwidth (0.1.7)
Werkzeug (0.12.2)
wheel (0.29.0)
widgetsnbextension (1.2.6)
xcsc-tushare (1.0.0)
xgboost (0.6a2)
xlrd (1.1.0)
xlwt (1.3.0)
zipline (0.8.3)
You are using pip version 9.0.1, however version 22.1.2 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
需要开户可以关注微信公众号
费率优惠多多(万一免五)
后台回复:ptrade开通
查看全部
而目前又可以重新开启这个量化业务了。
如果不太懂的小伙伴,笔者这里可以稍加详细解释。
这里的外网,指的外部网络,相对券商部署的服务器内网而言的,并不是指墙外的网络哈,这里小伙伴们注意一下哈。
在大部分券商里,Ptrade是封闭环境下运行的,Ptrade是在券商的内部服务器上执行,所以它无法把数据传出外部的服务器,同样也不能访问外面服务器的数据。比如我想获取同花顺的热门概念,由于Ptrade无法访问外部网络,如果内置的Ptrade数据没有提供,就没有办法了。或者用Ptrade想要搞点可转债溢价率,规模的数据,如果没办法联通外网,实际你的策略就无法下手,因为基础数据已经缺乏了。
好在国盛的Ptrade支持外网联通,可以用爬虫的方式,读取mysql的方式,读取MQ队列的方式的等等获取外部数据,弥补内置数据的不足。
具体可以看这个文章:
http://30daydo.com/article/44453
比如下面代码是在ptrade里面访问百度的:
import requests
def initialize(context):
# 初始化策略
g.security = "600570.SS"
set_universe(g.security)
def handle_data(context, data):
url='http://www.baidu.com'
headers={'User-Agent':'Google'}
try:
r=requests.get(url,headers=headers)
r.encoding='utf8'
print(r.text)
except Exception as e:
print('error')
print(e)
可以看到能够使用requests这个库正常获取数据的,当然requests库是ptrade本身就有的,不需要你再pip安装,当然ptrade也无法pip安装第三方库。
ptrade支持的内置库名单:
http://www.30daydo.com/article/44458
APScheduler (3.3.1)
arch (3.2)
bcolz (1.2.1)
beautifulsoup4 (4.6.0)
bleach (1.5.0)
boto (2.43.0)
Bottleneck (1.0.0)
bz2file (0.98)
cachetools (3.1.0)
click (4.0)
contextlib2 (0.4.0)
crypto (1.4.1)
cvxopt (1.1.8)
cx-Oracle (8.0.1)
cycler (0.10.0)
cyordereddict (0.2.2)
Cython (0.22.1)
decorator (4.0.10)
entrypoints (0.2.2)
fastcache (1.0.2)
gensim (0.13.3)
h5py (2.6.0)
hmmlearn (0.2.0)
hs-udata (0.3.6)
html5lib (0.9999999)
ipykernel (4.5.0)
ipython (5.1.0)
ipython-genutils (0.1.0)
ipywidgets (5.2.2)
jieba (0.38)
Jinja2 (2.8)
jsonpickle (1.0)
jsonschema (2.5.1)
jupyter (1.0.0)
jupyter-client (4.4.0)
jupyter-console (5.0.0)
jupyter-core (4.2.0)
jupyter-kernel-gateway (1.1.1)
Keras (2.3.1)
Keras-Applications (1.0.8)
Keras-Preprocessing (1.1.0)
line-profiler (2.1.2)
Logbook (1.4.3)
lxml (4.5.0)
Markdown (2.2.0)
MarkupSafe (0.23)
matplotlib (1.5.3)
mistune (0.7.3)
Naked (0.1.31)
nbconvert (4.2.0)
nbformat (4.1.0)
networkx (1.9.1)
nose (1.3.6)
notebook (4.2.3)
numexpr (2.6.1)
numpy (1.11.2)
pandas (0.23.4)
patsy (0.4.0)
pexpect (4.2.1)
pickleshare (0.7.4)
pip (9.0.1)
pkgconfig (1.0.0)
prompt-toolkit (1.0.8)
protobuf (3.3.0)
ptvsd (2.2.0)
ptyprocess (0.5.1)
PyBrain (0.3)
pycrypto (2.6.1)
Pygments (2.1.3)
PyMySQL (0.9.3)
pyparsing (2.1.10)
python-dateutil (2.7.5)
pytz (2015.4)
PyWavelets (0.4.0)
PyYAML (5.3.1)
pyzmq (16.1.0.dev0)
qtconsole (4.2.1)
requests (2.7.0)
retrying (1.3.3)
scikit-learn (0.18)
scipy (0.18.0)
seaborn (0.7.1)
setuptools (28.7.1)
setuptools-scm (3.1.0)
shellescape (3.4.1)
simplegeneric (0.8.1)
simplejson (3.17.0)
six (1.10.0)
sklearn (0.0)
smart-open (1.3.5)
SQLAlchemy (1.0.8)
statsmodels (0.10.2)
TA-Lib (0.4.10)
tables (3.3.0)
tabulate (0.7.5)
tensorflow (1.3.0rc1)
tensorflow-tensorboard (0.1.2)
terminado (0.6)
Theano (0.8.2)
toolz (0.7.4)
tornado (4.4.2)
traitlets (4.3.1)
tushare (1.2.48)
tzlocal (1.3)
wcwidth (0.1.7)
Werkzeug (0.12.2)
wheel (0.29.0)
widgetsnbextension (1.2.6)
xcsc-tushare (1.0.0)
xgboost (0.6a2)
xlrd (1.1.0)
xlwt (1.3.0)
zipline (0.8.3)
You are using pip version 9.0.1, however version 22.1.2 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
需要开户可以关注微信公众号
费率优惠多多(万一免五)

后台回复:ptrade开通
ChatGPT开启GPT4不限次数使用插件
深度学习 • 马化云 发表了文章 • 0 个评论 • 1502 次浏览 • 2023-06-07 17:50
一个ChatGPT开启GPT4不限次数使用插件:
ChatGPT开启不限次数的GPT4-Mobile,是一个油猴插件,取自iOS客户端的GPT4模型,
因为目前iOS上的客户端GPT4使用次数没有限制,而这个插件就是利用了这个特性实现的GPT4不限次数使用,
不过前提是你也是开通ChatGPT Plus的用户才可以的,不过目前插件无法和ChatGPT增强插件:KeepChatGPT同时启用。
感兴趣的同学可以下载体验。
ChatGPT开启GPT4不限次数使用插件下载
地址:ChatGPT开启不限次数的GPT4-Mobile
其他ChatGPT插件
1、ChatGPT增强插件 解决各种报错-KeepChatGPT
2、更多ChatGPT工具资源
查看全部
一个ChatGPT开启GPT4不限次数使用插件:
ChatGPT开启不限次数的GPT4-Mobile,是一个油猴插件,取自iOS客户端的GPT4模型,
因为目前iOS上的客户端GPT4使用次数没有限制,而这个插件就是利用了这个特性实现的GPT4不限次数使用,
不过前提是你也是开通ChatGPT Plus的用户才可以的,不过目前插件无法和ChatGPT增强插件:KeepChatGPT同时启用。
感兴趣的同学可以下载体验。

ChatGPT开启GPT4不限次数使用插件下载
地址:ChatGPT开启不限次数的GPT4-Mobile
其他ChatGPT插件
1、ChatGPT增强插件 解决各种报错-KeepChatGPT
2、更多ChatGPT工具资源
国金证券QMT量化新人培训教程
QMT • 李魔佛 发表了文章 • 0 个评论 • 3187 次浏览 • 2023-05-29 00:37
视频已经整理放到B站:
https://space.bilibili.com/73827743/channel/seriesdetail?sid=3326385&ctype=0
视频目录:
量化新人用QMT+chat GPT快速上手量化策略(一)QMT基础介绍
量化新人用QMT+chat GPT快速上手量化策略(二)QMT均线盘后选股
量化新人用QMT+chat GPT快速上手量化策略(三)一个基本的回测策略代码
量化新人用QMT+chat GPT快速上手量化策略(四) QMT运行一个策略的整体流程
量化新人用QMT+chat GPT快速上手量化策略(五) 获取股票数据
量化新人用QMT+chat GPT快速上手量化策略(六) tablib计算指标
量化新人用QMT+chat GPT快速上手量化策略(七) 下单代码编写
欢迎观看并提出疑问。
公众号:可转债量化分析 查看全部
视频已经整理放到B站:
https://space.bilibili.com/73827743/channel/seriesdetail?sid=3326385&ctype=0
视频目录:

量化新人用QMT+chat GPT快速上手量化策略(一)QMT基础介绍
量化新人用QMT+chat GPT快速上手量化策略(二)QMT均线盘后选股
量化新人用QMT+chat GPT快速上手量化策略(三)一个基本的回测策略代码
量化新人用QMT+chat GPT快速上手量化策略(四) QMT运行一个策略的整体流程
量化新人用QMT+chat GPT快速上手量化策略(五) 获取股票数据
量化新人用QMT+chat GPT快速上手量化策略(六) tablib计算指标
量化新人用QMT+chat GPT快速上手量化策略(七) 下单代码编写
欢迎观看并提出疑问。
公众号:可转债量化分析
akshare 官网地址
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 2838 次浏览 • 2023-05-25 21:50
不明白为啥百度前面几页都显示不到akshare的官网。对这个搜索结果实在有点无语。

QMT获取实时分笔委托数据用哪个函数?
QMT • 李魔佛 发表了文章 • 0 个评论 • 1205 次浏览 • 2023-05-24 15:31
现在官方更加推荐使用第二版,速度要比第一版的要快,也就是推荐使用 .get_market_data_ex。
具体怎么使用呢?
def init(ContextInfo):
ContextInfo.run_time('execution', '3nSecond', '2019-10-14 13:20:00',)
def execution(ContextInfo):
if not ContextInfo.is_last_bar():
return
data = ContextInfo.get_market_data_ex(
[], ['123136.SZ'], period='tick'
, start_time='', end_time='', count=1
, dividend_type='follow', fill_data=True
, subscribe=True)
print(data)
def handlebar(ContextInfo):
#计算当前主图的cci
pass上面代码是每个3秒获取一次 城市转债 的分笔/逐笔数据。
然后在实盘重运行得到下面的结果:
(点击放大)
可以拿到分笔委托的价格,委卖1到5,委托量也可以看到,买和卖的5挡数据。
更多QMT的知识分享: 查看全部
现在官方更加推荐使用第二版,速度要比第一版的要快,也就是推荐使用 .get_market_data_ex。
具体怎么使用呢?
def init(ContextInfo):上面代码是每个3秒获取一次 城市转债 的分笔/逐笔数据。
ContextInfo.run_time('execution', '3nSecond', '2019-10-14 13:20:00',)
def execution(ContextInfo):
if not ContextInfo.is_last_bar():
return
data = ContextInfo.get_market_data_ex(
[], ['123136.SZ'], period='tick'
, start_time='', end_time='', count=1
, dividend_type='follow', fill_data=True
, subscribe=True)
print(data)
def handlebar(ContextInfo):
#计算当前主图的cci
pass
然后在实盘重运行得到下面的结果:

(点击放大)
可以拿到分笔委托的价格,委卖1到5,委托量也可以看到,买和卖的5挡数据。
更多QMT的知识分享:

QMT委托对象orderInfo的属性以及对应的值
QMT • 李魔佛 发表了文章 • 0 个评论 • 1203 次浏览 • 2023-05-18 15:43
官网给出了来的oderInfo里面的字段以及简单的介绍(已经简单得不能再简单了,连对应的是什么类型都不写,懒的一笔)
m_strAccountID: 资金账号,账号,账号,资金账号
m_strExchangeID: 证券市场
m_strExchangeName: 交易市场
m_strProductID: 品种代码
m_strProductName: 品种名称
m_strInstrumentID: 证券代码
m_strInstrumentName: 证券名称,合约名称
m_strOrderRef: 内部委托号,下单引用等于股票的内部委托号
m_nOrderPriceType: EBrokerPriceType 类型,例如市价单、限价单
m_nDirection: EEntrustBS 类型,操作,多空,期货多空,股票买卖永远是 48,其他的 dir 同理
m_nOffsetFlag: EOffset_Flag_Type类型,买卖/开平,用此字段区分股票买卖,期货开、平仓,期权买卖等
m_nHedgeFlag: EHedge_Flag_Type 类型,投保
m_dLimitPrice: 委托价格,限价单的限价,就是报价
m_nVolumeTotalOriginal: 委托量,最初委托量
m_nOrderSubmitStatus: EEntrustSubmitStatus 类型,报单状态,提交状态,股票中不需要报单状态
m_strOrderSysID: 合同编号,委托号
m_nOrderStatus: EEntrustStatus,委托状态
m_nVolumeTraded: 成交数量,已成交量
m_nVolumeTotal: 委托剩余量,当前总委托量,股票的含义是总委托量减去成交量
m_nErrorID: 状态信息
m_strErrorMsg: 状态信息
m_nTaskId:任务号
m_dFrozenMargin: 冻结金额,冻结保证金
m_dFrozenCommission: 冻结手续费
m_strInsertDate: 委托日期,报单日期
m_strInsertTime: 委托时间
m_dTradedPrice: 成交均价(股票)
m_dCancelAmount: 已撤数量
m_strOptName: 买卖标记,展示委托属性的中文
m_dTradeAmount: 成交金额,成交额,期货 = 均价 * 量 * 合约乘数
m_eEntrustType: EEntrustTypes,委托类别
m_strCancelInfo: 废单原因
m_strUnderCode: 标的证券代码
m_eCoveredFlag: ECoveredFlag,备兑标记 '0' - 非备兑,'1' - 备兑
m_dOrderPriceRMB: 委托价格(人民币),目前用于港股通
m_dTradeAmountRMB: 成交金额(人民币),目前用于港股通
m_dReferenceRate: 汇率,目前用于港股通
m_strCompactNo: 合约编号
m_eCashgroupProp: EXTCompactBrushSource类型,头寸来源
m_dShortOccupedMargin: 预估在途占用保证金,用于期权
m_strXTTrade: 是否是迅投交易
m_strAccountKey: 账号key,唯一区别不同账号的key
m_strRemark:投资备注但我们可以直接使用枚举的方法,把上面的属性和对应的值列出来。
attr EBrokerPriceType value <class 'EBrokerPriceType'>
attr ECoveredFlag value <class 'ECoveredFlag'>
attr EEntrustBS value <class 'EEntrustBS'>
attr EEntrustStatus value <class 'EEntrustStatus'>
attr EEntrustSubmitStatus value <class 'EEntrustSubmitStatus'>
attr EEntrustTypes value <class 'EEntrustTypes'>
attr EFutureTradeType value <class 'EFutureTradeType'>
attr EHedge_Flag_Type value <class 'EHedge_Flag_Type'>
attr EOffset_Flag_Type value <class 'EOffset_Flag_Type'>
attr ESideFlag value <class 'ESideFlag'>
attr EXTCompactBrushSource value <class 'EXTCompactBrushSource'>
attr EXTCompactStatus value <class 'EXTCompactStatus'>
attr EXTCompactType value <class 'EXTCompactType'>
attr EXTSloTypeQueryMode value <class 'EXTSloTypeQueryMode'>
attr EXTSubjectsStatus value <class 'EXTSubjectsStatus'>
attr __class__ value <class 'COrderDetail'>
attr __delattr__ value <method-wrapper '__delattr__' of COrderDetail object at 0x000000004AD59A60>
attr __dict__ value {}
attr __dir__ value <built-in method __dir__ of COrderDetail object at 0x000000004AD59A60>
attr __doc__ value None
attr __eq__ value <method-wrapper '__eq__' of COrderDetail object at 0x000000004AD59A60>
attr __format__ value <built-in method __format__ of COrderDetail object at 0x000000004AD59A60>
attr __ge__ value <method-wrapper '__ge__' of COrderDetail object at 0x000000004AD59A60>
attr __getattribute__ value <method-wrapper '__getattribute__' of COrderDetail object at 0x000000004AD59A60>
attr __gt__ value <method-wrapper '__gt__' of COrderDetail object at 0x000000004AD59A60>
attr __hash__ value <method-wrapper '__hash__' of COrderDetail object at 0x000000004AD59A60>
attr __init__ value <bound method __init__ of <COrderDetail object at 0x000000004AD59A60>>
attr __init_subclass__ value <built-in method __init_subclass__ of Boost.Python.class object at 0x0000000044C55368>
attr __instance_size__ value 1088
attr __le__ value <method-wrapper '__le__' of COrderDetail object at 0x000000004AD59A60>
attr __lt__ value <method-wrapper '__lt__' of COrderDetail object at 0x000000004AD59A60>
attr __ne__ value <method-wrapper '__ne__' of COrderDetail object at 0x000000004AD59A60>
attr __new__ value <built-in method __new__ of Boost.Python.class object at 0x000007FEDCF525C0>
attr __reduce__ value <bound method <unnamed Boost.Python function> of <COrderDetail object at 0x000000004AD59A60>>
attr __reduce_ex__ value <built-in method __reduce_ex__ of COrderDetail object at 0x000000004AD59A60>
attr __repr__ value <method-wrapper '__repr__' of COrderDetail object at 0x000000004AD59A60>
attr __setattr__ value <method-wrapper '__setattr__' of COrderDetail object at 0x000000004AD59A60>
attr __sizeof__ value <built-in method __sizeof__ of COrderDetail object at 0x000000004AD59A60>
attr __str__ value <method-wrapper '__str__' of COrderDetail object at 0x000000004AD59A60>
attr __subclasshook__ value <built-in method __subclasshook__ of Boost.Python.class object at 0x0000000044C55368>
attr __weakref__ value None
attr j value j
attr m_bEnable value True
attr m_dCancelAmount value 0.0
attr m_dFrozenCommission value 0.15
attr m_dFrozenMargin value 1000.0
attr m_dLimitPrice value 2.3
具体的获取方式,可以到个人的知识星球获取。
星球也会不定时更新一些QMT常见的坑和问题,也可以提问:
这里简单介绍一下几个常用的字段:
attr m_nOrderStatus value 50
委托状态: 50代表已报, 注意,这里有个坑, 委托状态会返回2次,一次是先显示49,下一次是显示50,状态从待报-变成已报。
查看全部
官网给出了来的oderInfo里面的字段以及简单的介绍(已经简单得不能再简单了,连对应的是什么类型都不写,懒的一笔)
m_strAccountID: 资金账号,账号,账号,资金账号但我们可以直接使用枚举的方法,把上面的属性和对应的值列出来。
m_strExchangeID: 证券市场
m_strExchangeName: 交易市场
m_strProductID: 品种代码
m_strProductName: 品种名称
m_strInstrumentID: 证券代码
m_strInstrumentName: 证券名称,合约名称
m_strOrderRef: 内部委托号,下单引用等于股票的内部委托号
m_nOrderPriceType: EBrokerPriceType 类型,例如市价单、限价单
m_nDirection: EEntrustBS 类型,操作,多空,期货多空,股票买卖永远是 48,其他的 dir 同理
m_nOffsetFlag: EOffset_Flag_Type类型,买卖/开平,用此字段区分股票买卖,期货开、平仓,期权买卖等
m_nHedgeFlag: EHedge_Flag_Type 类型,投保
m_dLimitPrice: 委托价格,限价单的限价,就是报价
m_nVolumeTotalOriginal: 委托量,最初委托量
m_nOrderSubmitStatus: EEntrustSubmitStatus 类型,报单状态,提交状态,股票中不需要报单状态
m_strOrderSysID: 合同编号,委托号
m_nOrderStatus: EEntrustStatus,委托状态
m_nVolumeTraded: 成交数量,已成交量
m_nVolumeTotal: 委托剩余量,当前总委托量,股票的含义是总委托量减去成交量
m_nErrorID: 状态信息
m_strErrorMsg: 状态信息
m_nTaskId:任务号
m_dFrozenMargin: 冻结金额,冻结保证金
m_dFrozenCommission: 冻结手续费
m_strInsertDate: 委托日期,报单日期
m_strInsertTime: 委托时间
m_dTradedPrice: 成交均价(股票)
m_dCancelAmount: 已撤数量
m_strOptName: 买卖标记,展示委托属性的中文
m_dTradeAmount: 成交金额,成交额,期货 = 均价 * 量 * 合约乘数
m_eEntrustType: EEntrustTypes,委托类别
m_strCancelInfo: 废单原因
m_strUnderCode: 标的证券代码
m_eCoveredFlag: ECoveredFlag,备兑标记 '0' - 非备兑,'1' - 备兑
m_dOrderPriceRMB: 委托价格(人民币),目前用于港股通
m_dTradeAmountRMB: 成交金额(人民币),目前用于港股通
m_dReferenceRate: 汇率,目前用于港股通
m_strCompactNo: 合约编号
m_eCashgroupProp: EXTCompactBrushSource类型,头寸来源
m_dShortOccupedMargin: 预估在途占用保证金,用于期权
m_strXTTrade: 是否是迅投交易
m_strAccountKey: 账号key,唯一区别不同账号的key
m_strRemark:投资备注
attr EBrokerPriceType value <class 'EBrokerPriceType'>
attr ECoveredFlag value <class 'ECoveredFlag'>
attr EEntrustBS value <class 'EEntrustBS'>
attr EEntrustStatus value <class 'EEntrustStatus'>
attr EEntrustSubmitStatus value <class 'EEntrustSubmitStatus'>
attr EEntrustTypes value <class 'EEntrustTypes'>
attr EFutureTradeType value <class 'EFutureTradeType'>
attr EHedge_Flag_Type value <class 'EHedge_Flag_Type'>
attr EOffset_Flag_Type value <class 'EOffset_Flag_Type'>
attr ESideFlag value <class 'ESideFlag'>
attr EXTCompactBrushSource value <class 'EXTCompactBrushSource'>
attr EXTCompactStatus value <class 'EXTCompactStatus'>
attr EXTCompactType value <class 'EXTCompactType'>
attr EXTSloTypeQueryMode value <class 'EXTSloTypeQueryMode'>
attr EXTSubjectsStatus value <class 'EXTSubjectsStatus'>
attr __class__ value <class 'COrderDetail'>
attr __delattr__ value <method-wrapper '__delattr__' of COrderDetail object at 0x000000004AD59A60>
attr __dict__ value {}
attr __dir__ value <built-in method __dir__ of COrderDetail object at 0x000000004AD59A60>
attr __doc__ value None
attr __eq__ value <method-wrapper '__eq__' of COrderDetail object at 0x000000004AD59A60>
attr __format__ value <built-in method __format__ of COrderDetail object at 0x000000004AD59A60>
attr __ge__ value <method-wrapper '__ge__' of COrderDetail object at 0x000000004AD59A60>
attr __getattribute__ value <method-wrapper '__getattribute__' of COrderDetail object at 0x000000004AD59A60>
attr __gt__ value <method-wrapper '__gt__' of COrderDetail object at 0x000000004AD59A60>
attr __hash__ value <method-wrapper '__hash__' of COrderDetail object at 0x000000004AD59A60>
attr __init__ value <bound method __init__ of <COrderDetail object at 0x000000004AD59A60>>
attr __init_subclass__ value <built-in method __init_subclass__ of Boost.Python.class object at 0x0000000044C55368>
attr __instance_size__ value 1088
attr __le__ value <method-wrapper '__le__' of COrderDetail object at 0x000000004AD59A60>
attr __lt__ value <method-wrapper '__lt__' of COrderDetail object at 0x000000004AD59A60>
attr __ne__ value <method-wrapper '__ne__' of COrderDetail object at 0x000000004AD59A60>
attr __new__ value <built-in method __new__ of Boost.Python.class object at 0x000007FEDCF525C0>
attr __reduce__ value <bound method <unnamed Boost.Python function> of <COrderDetail object at 0x000000004AD59A60>>
attr __reduce_ex__ value <built-in method __reduce_ex__ of COrderDetail object at 0x000000004AD59A60>
attr __repr__ value <method-wrapper '__repr__' of COrderDetail object at 0x000000004AD59A60>
attr __setattr__ value <method-wrapper '__setattr__' of COrderDetail object at 0x000000004AD59A60>
attr __sizeof__ value <built-in method __sizeof__ of COrderDetail object at 0x000000004AD59A60>
attr __str__ value <method-wrapper '__str__' of COrderDetail object at 0x000000004AD59A60>
attr __subclasshook__ value <built-in method __subclasshook__ of Boost.Python.class object at 0x0000000044C55368>
attr __weakref__ value None
attr j value j
attr m_bEnable value True
attr m_dCancelAmount value 0.0
attr m_dFrozenCommission value 0.15
attr m_dFrozenMargin value 1000.0
attr m_dLimitPrice value 2.3
具体的获取方式,可以到个人的知识星球获取。
星球也会不定时更新一些QMT常见的坑和问题,也可以提问:

这里简单介绍一下几个常用的字段:
attr m_nOrderStatus value 50
委托状态: 50代表已报, 注意,这里有个坑, 委托状态会返回2次,一次是先显示49,下一次是显示50,状态从待报-变成已报。
vim配置运行node.js快捷键
Linux • 马化云 发表了文章 • 0 个评论 • 736 次浏览 • 2023-05-17 11:55
这样的方式来运行nodejs程序,这样就可以不用再开一个窗口去输入命令,运行。
不过手动输入那么多,显然是不符合vim的用法的。
那么我们使用一个快捷键定义,把按键次数减少。
打开.vimrc
加入一行
nnoremap nr :!node %<CR>
这样就是设置一个快捷键 nr
每次在命令行模式下,按下nr,
就可以运行当前的node文件了。快捷不?
查看全部
这样的方式来运行nodejs程序,这样就可以不用再开一个窗口去输入命令,运行。
不过手动输入那么多,显然是不符合vim的用法的。
那么我们使用一个快捷键定义,把按键次数减少。
打开.vimrc
加入一行
nnoremap nr :!node %<CR>
这样就是设置一个快捷键 nr
每次在命令行模式下,按下nr,
就可以运行当前的node文件了。快捷不?
技术大佬@haoel 一路走好,RIP
网络 • 李魔佛 发表了文章 • 0 个评论 • 832 次浏览 • 2023-05-16 01:14
希望技术大佬的文章能够常驻。
RIP
走好~ 查看全部

Cloudflare上貌似已经访问不了源站,克隆了一个源站( http://rip.30daydo.com )。曾经得到技术大佬的一个邮件回复,给与的技术支持与鼓励,永不忘。
希望技术大佬的文章能够常驻。
RIP
走好~
QMT运行后的历史日志保存在哪个位置?
QMT • 李魔佛 发表了文章 • 0 个评论 • 1214 次浏览 • 2023-05-11 14:10
PS: 知乎上这位是抄袭我的:
https://zhuanlan.zhihu.com/p/650119640
我这里有很多QMT的文章,都是没有原创没有加水印的
如果想要找回以前的历史日志,可以到下面的路径寻找;
以国信证券的iquant为例:
C:\iquant_gx\userdata\log
具体以你的券商路径安装名字为准
个人的日志输出在文件名:
XtClient_FormulaOutput_20230426 (后面的是日期,具体根据你要查找的时间来找)
看到没?
上面的日志就是记录当时的策略输出。
国信证券iQuant, 万一免五 开户,无门槛开通,
需要的可以联系:
可开通miniqmt 查看全部
PS: 知乎上这位是抄袭我的:
https://zhuanlan.zhihu.com/p/650119640
我这里有很多QMT的文章,都是没有原创没有加水印的

如果想要找回以前的历史日志,可以到下面的路径寻找;
以国信证券的iquant为例:
C:\iquant_gx\userdata\log
具体以你的券商路径安装名字为准

个人的日志输出在文件名:
XtClient_FormulaOutput_20230426 (后面的是日期,具体根据你要查找的时间来找)

看到没?
上面的日志就是记录当时的策略输出。
国信证券iQuant, 万一免五 开户,无门槛开通,
需要的可以联系:
可开通miniqmt

拼多多上的台式主机坑真多
Linux • 李魔佛 发表了文章 • 0 个评论 • 3298 次浏览 • 2023-05-10 16:49
(pdd上面的价格虽然价格很低,但是要相信一分价钱一分货)
首先是CPU
比如常见的i7 11800H , 11代的i7, 可能性能很炸裂。
可是H后缀的CPU,不是给台式机的! 它是属于笔记本系列的弱鸡CPU! 性能上比同样台式机的要秒飞不少。
比如下面的这张图:
什么i5 12500H,i7 11800H,都是笔记本CPU。
比如11代的i7.
正常上京东的主板+cpu。
价格要3000多。
而带H后缀的CPU+主板
1500不到,价格比台式机的要腰斩一半哦。
然后还有显卡。
有些显卡带有Laptop后缀的。
比如这样的。
这个显卡的核心 GPU,是Laptop的, 不懂英文的可以百度词典一下, 这个是笔记本的意思,
也就是说这个显卡的核心,也是给笔记本的。
同样,京东或者pdd上也有卖这样的移动端核心的显卡。3060的laptop版本的显卡,只要1000多。
而台式机版本的要2000多。
我就说,我在京东上用京东装机,自己搞下来了,无论怎么搞,价格都无法比拼多多的要低,主要是他们的价格还低很多,低到让人怀疑。
查看全部
(pdd上面的价格虽然价格很低,但是要相信一分价钱一分货)
首先是CPU
比如常见的i7 11800H , 11代的i7, 可能性能很炸裂。
可是H后缀的CPU,不是给台式机的! 它是属于笔记本系列的弱鸡CPU! 性能上比同样台式机的要秒飞不少。
比如下面的这张图:

什么i5 12500H,i7 11800H,都是笔记本CPU。
比如11代的i7.
正常上京东的主板+cpu。

价格要3000多。
而带H后缀的CPU+主板

1500不到,价格比台式机的要腰斩一半哦。
然后还有显卡。
有些显卡带有Laptop后缀的。
比如这样的。

这个显卡的核心 GPU,是Laptop的, 不懂英文的可以百度词典一下, 这个是笔记本的意思,
也就是说这个显卡的核心,也是给笔记本的。
同样,京东或者pdd上也有卖这样的移动端核心的显卡。3060的laptop版本的显卡,只要1000多。
而台式机版本的要2000多。
我就说,我在京东上用京东装机,自己搞下来了,无论怎么搞,价格都无法比拼多多的要低,主要是他们的价格还低很多,低到让人怀疑。
用户问的比较多的关于ptrade基础问题
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1463 次浏览 • 2023-05-04 01:19
1. 国金的Ptrade 实盘交易客户端是无法进行回测的,在任何时间段;
而模拟客户端可以,可以找自己的经理申请一个Ptrade模拟客户端账户;
2. 国盛的Ptrade实盘交易客户端仅在交易时间无法回测,但非交易时间可以回测;
主要是因为实盘回测和交易在同一个服务器,回测占用过多资源会影响实盘交易;模拟客户端没有这个问题;
任何时间段均可以回测; (之前某个券商的ptrade实盘服务器,因为某个用户开了40多个回测策略,一直在后台运行,而且是关于运算密集型的,导致实盘交易的程序也崩溃了)
3. 国金Ptrade无法回测星球上面的可转债实盘代码,实盘代码是基于当前的实时数据,用来进行回测没有意义,因为获取不到可转债的历史数据(溢价率,规模等),只有历史的价格数据;
4. 国金Ptrade无法使用星球上的可转债代码进行实盘,因为无法访问外网,无法访问我部署的接口数据; 而国盛的Ptrade可以;如果国金Ptrade需要实盘交易可转债,需要手工上传一些基础数据,Ptrade提供上传功能,具体操作可查找星球相关文章;
5. 在共享的Ptrade模拟试用账户上,不要保留个人代码记录,跑完后记得删除,否则其他共有同一个账户的人可以进去修改复制你的策略和代码;如果是单独的个人模拟账户,则没有这个问题。
查看全部
1. 国金的Ptrade 实盘交易客户端是无法进行回测的,在任何时间段;
而模拟客户端可以,可以找自己的经理申请一个Ptrade模拟客户端账户;
2. 国盛的Ptrade实盘交易客户端仅在交易时间无法回测,但非交易时间可以回测;
主要是因为实盘回测和交易在同一个服务器,回测占用过多资源会影响实盘交易;模拟客户端没有这个问题;
任何时间段均可以回测; (之前某个券商的ptrade实盘服务器,因为某个用户开了40多个回测策略,一直在后台运行,而且是关于运算密集型的,导致实盘交易的程序也崩溃了)
3. 国金Ptrade无法回测星球上面的可转债实盘代码,实盘代码是基于当前的实时数据,用来进行回测没有意义,因为获取不到可转债的历史数据(溢价率,规模等),只有历史的价格数据;
4. 国金Ptrade无法使用星球上的可转债代码进行实盘,因为无法访问外网,无法访问我部署的接口数据; 而国盛的Ptrade可以;如果国金Ptrade需要实盘交易可转债,需要手工上传一些基础数据,Ptrade提供上传功能,具体操作可查找星球相关文章;
5. 在共享的Ptrade模拟试用账户上,不要保留个人代码记录,跑完后记得删除,否则其他共有同一个账户的人可以进去修改复制你的策略和代码;如果是单独的个人模拟账户,则没有这个问题。
如何下载Ptrade上的数据?
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1236 次浏览 • 2023-04-29 02:40
部分券商的Ptrade可以连通外网,只需要部署一个mysql服务器,或者rabbitMQ,就可以快捷的接受数据了。为啥是这两个,而不是mongodb?
因为ptrade内置的pip装好的库就有pymysql和pyzmq,可以配置下就可以直接开箱使用。如果需要开通有外网功能的Ptrade券商,可以关注公众号:可转债量化分析,后台留言:ptrade外网,即可咨询开通。
1. 首先,我们把数据保存到ptrade的服务端,保存方法多样,比如csv,excel,sql文件等,比如df.to_csv, df.to_excel等等。这里要注意一下,保存的路径。需要指定,/home/fly/notebookimport pickle
from collections import defaultdict
NOTEBOOK_PATH = '/home/fly/notebook/'
'''
持仓N日后卖出,仓龄变量每日pickle进行保存,重启策略后可以保证逻辑连贯
'''
def initialize(context):
#尝试启动pickle文件
try:
with open(NOTEBOOK_PATH+'hold_days.pkl','rb') as f:
g.hold_days = pickle.load(f)
2. 文件保存了之后,接着就可以下载了。
数据在研究的页面那里。
然后点击某个文件,
如果是非纯文本文件,比如excel文件,会显示:Error! not UTF-8 encoded
Saving disable
See console for more details
不用理会,直接点击左上角的文件,下载,选择本地的路径,然后文件就可以下载下来了。 查看全部
部分券商的Ptrade可以连通外网,只需要部署一个mysql服务器,或者rabbitMQ,就可以快捷的接受数据了。为啥是这两个,而不是mongodb?
因为ptrade内置的pip装好的库就有pymysql和pyzmq,可以配置下就可以直接开箱使用。如果需要开通有外网功能的Ptrade券商,可以关注公众号:可转债量化分析,后台留言:ptrade外网,即可咨询开通。
1. 首先,我们把数据保存到ptrade的服务端,保存方法多样,比如csv,excel,sql文件等,比如df.to_csv, df.to_excel等等。这里要注意一下,保存的路径。需要指定,/home/fly/notebook
import pickle
from collections import defaultdict
NOTEBOOK_PATH = '/home/fly/notebook/'
'''
持仓N日后卖出,仓龄变量每日pickle进行保存,重启策略后可以保证逻辑连贯
'''
def initialize(context):
#尝试启动pickle文件
try:
with open(NOTEBOOK_PATH+'hold_days.pkl','rb') as f:
g.hold_days = pickle.load(f)
2. 文件保存了之后,接着就可以下载了。
数据在研究的页面那里。

然后点击某个文件,
如果是非纯文本文件,比如excel文件,会显示:
Error! not UTF-8 encoded
Saving disable
See console for more details
不用理会,直接点击左上角的文件,下载,选择本地的路径,然后文件就可以下载下来了。

迅投QMT修改编辑器字体大小,4个空格缩进(默认是TAB),背景颜色
QMT • 李魔佛 发表了文章 • 0 个评论 • 1345 次浏览 • 2023-04-25 12:22
而且在菜单里面也找不到设置的地方。
其实用户是可以修改这个编辑器的配置的。
找到QMT的安装目录,找到config文件夹,里面有个editor.xml 的文件,用记事本或者notepad++等文本编辑器打开。
如果要修改字体大小,可以修改:
<font FamilyName="Courier New" IsBold="false" size="16"/>
把size设置大一点,字体即可变大。
如果要把tab缩进改为空格缩进(主流IDE,pycharm vscode都是4个空格缩进的),可以改成下面的
<font FamilyName="Courier New" IsBold="false" size="20"/>
<align TabStop="4" AutoIndent="true" IndentationsUseTabs="false" WrapWord="false"/>
如果需要修改背景色:
同理:
<color bgcolor="255,255,255"/>
修改这一行,
比如变成黑色背景
<color bgcolor="0,0,0"/>
PS: 上述配置部分券商可以在QMT的IDE上设置,比如字体大小等,而在这个xml里面修改却生效不了
改为后记得重启QMT生效
公众号后台回复:
qmt配置文件
可以获取修改为tab缩进的配置文件
查看全部
而且在菜单里面也找不到设置的地方。
其实用户是可以修改这个编辑器的配置的。
找到QMT的安装目录,找到config文件夹,里面有个editor.xml 的文件,用记事本或者notepad++等文本编辑器打开。

如果要修改字体大小,可以修改:
<font FamilyName="Courier New" IsBold="false" size="16"/>
把size设置大一点,字体即可变大。
如果要把tab缩进改为空格缩进(主流IDE,pycharm vscode都是4个空格缩进的),可以改成下面的
<font FamilyName="Courier New" IsBold="false" size="20"/>
<align TabStop="4" AutoIndent="true" IndentationsUseTabs="false" WrapWord="false"/>

如果需要修改背景色:
同理:
<color bgcolor="255,255,255"/>
修改这一行,
比如变成黑色背景
<color bgcolor="0,0,0"/>
PS: 上述配置部分券商可以在QMT的IDE上设置,比如字体大小等,而在这个xml里面修改却生效不了
改为后记得重启QMT生效
公众号后台回复:
qmt配置文件
可以获取修改为tab缩进的配置文件
QMT vs Ptrade 速度对比 (二)实时行情速度对比
QMT • 李魔佛 发表了文章 • 0 个评论 • 1368 次浏览 • 2023-04-23 00:33
本文以获取市场所有可转债的实时行情为例子,比较二者的速度。
Ptrade获取所有可转债实时行情
目前市场上有480多只可转债,由于Ptrade内置的数据源不足以支撑可转债的大部分策略,所以需要调用外部数据源,因此使用国盛证券的Ptrade进行交易,因为目前只有它可以链接外网,你可以把可转债的数据写入到数据库或者写成自己的接口,传递给Ptrade就可以了。
比如下面的基础数据接口。
【目前星球用户可以提供数据接口免费调用功能,提供实时数据功能,强赎倒数多个API接口】
然后调用端使用python的requests库请求下就有了。下面代码可以在Ptrade里面部署运行,用于获取可转债溢价率,剩余规模等数据。
然后在Ptrade的定时执行函数里面获取实时tick数据,使用get_snapshot,把所有的转债代码传入get_snapshot就可以拿到可转债的行情数据了,行情数据3秒更新一次。
在Ptrade里面的运行情况
红框的地方是几个时间点要关注的。
481:获取的转债个数有481
红色数字1的位置: time used
获取行情数据所用的时间,大概在17毫秒(ms)左右,数据一直比较稳定。返回的数据里面字段除了价格,还有昨收价,委买卖1队列,涨停价,成交量等多个数据,参考上图里面的那个字典格式的数据。 具体可以参考接口文档(http://ptradeapi.com)
红色数字2的位置:日志输出时候的时间,也就是程序当前所在时刻,在目前程序在14:42:51,红色数字3的时间,是当前价格的里面的时间,也就tick对应的时间,当前的tick时间是hsTimeStamp: 20230419144251000, 也就是 2023-04-19 14:42:51:000, 所以当前时间程序获取的tick时间是一致的。为什么这里要强调这个呢? 假如当前程序时刻是14:42:51, 而获取的tick timestamp数据是14:42:48,那么说明当前程序拿到的最新tick数据却是在48秒时的数据,也就是数据延时了3秒。所以Ptrade里面的tick数据并没有出现延时滞后。
QMT 实时行情
同样QMT提供的可转债基础也是少的可怜,几乎为零。所以同样调用个人部署的可转债接口数据,如法炮制。PS:通过数据解耦的方式,不同数据可以在不同的量化软件里面使用,省去很多重复编写的代码,即使后面接入掘金,聚宽等平台,你只需要编写下单接口逻辑即可。
QMT取实时行情代码如下:
Bond是一个类,和ptrade里面的一样的,用来获取转债基础数据。
同样在QMT的实盘模式下执行:
网络环境:500M宽带网络,PC:CPU I7 - 内存24GB
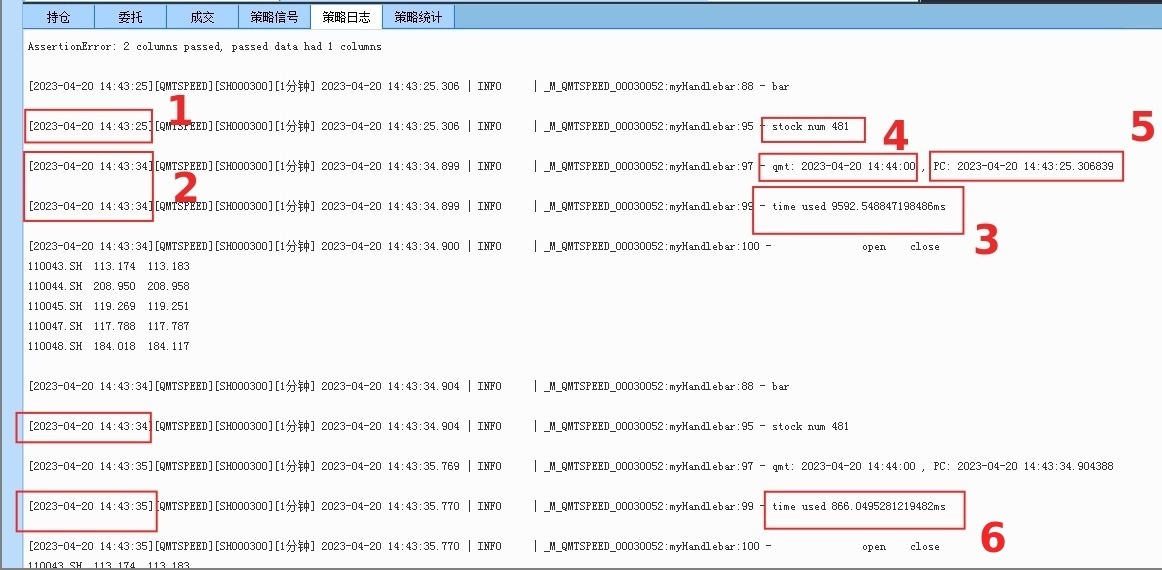
stock num : 481 同样获取的是481个转债实时行情数据
红色数字1时间:日志输出的当前时间,获取行情数据前的时间14:43:25
红色数字2时间:日志输出的当前时间,此时为已经获取行情数据后的时间:14:43:34
红色数字3:第一次获取行情数据时间差,达到了9.5秒! 这个数字简直惊呆了。 反复测试几次后,依然如此,使用get_market_data获取实时行情数据,第一次数据到达的时候都要挺久的。
新人刚使用这个函数获取实时行情的时候,往往会以为自己代码出bug,等待很久没数据出来,尤其是获取超过1000个股票代码的行情的时候,等待时候更久,等待时间随着输入的个数增加而增加; 同时QMT占用内存也会稳步增加,如果机子的内存太小,可能还会卡死了。(qmt里面的坑还挺多的)
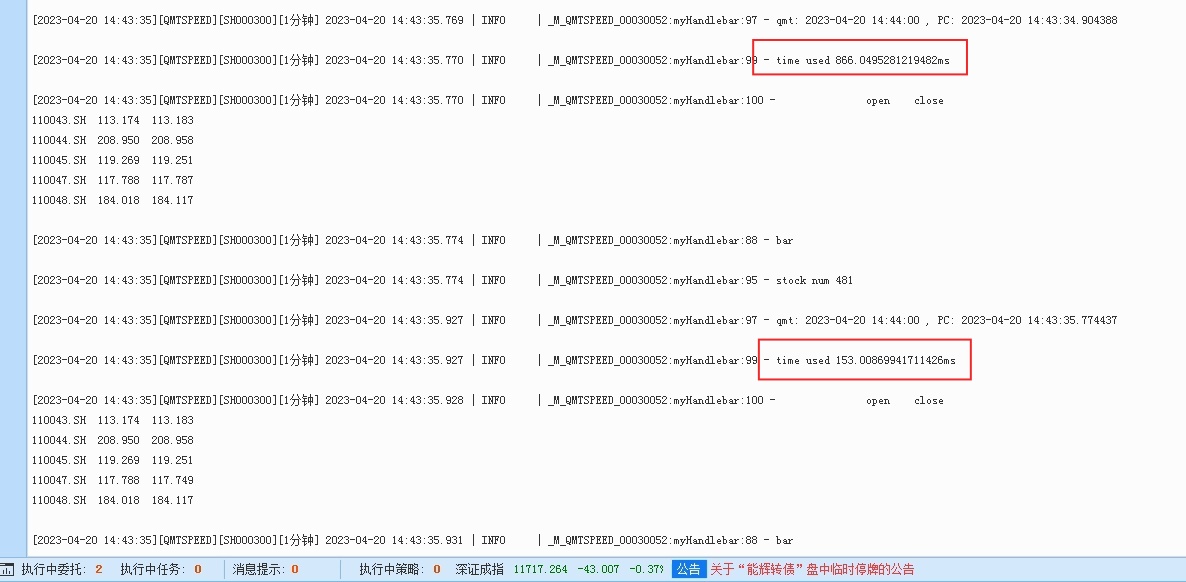
红色数字6,第二次获取实时行情所用的时间,这一次就快很多了,只用了800毫秒。
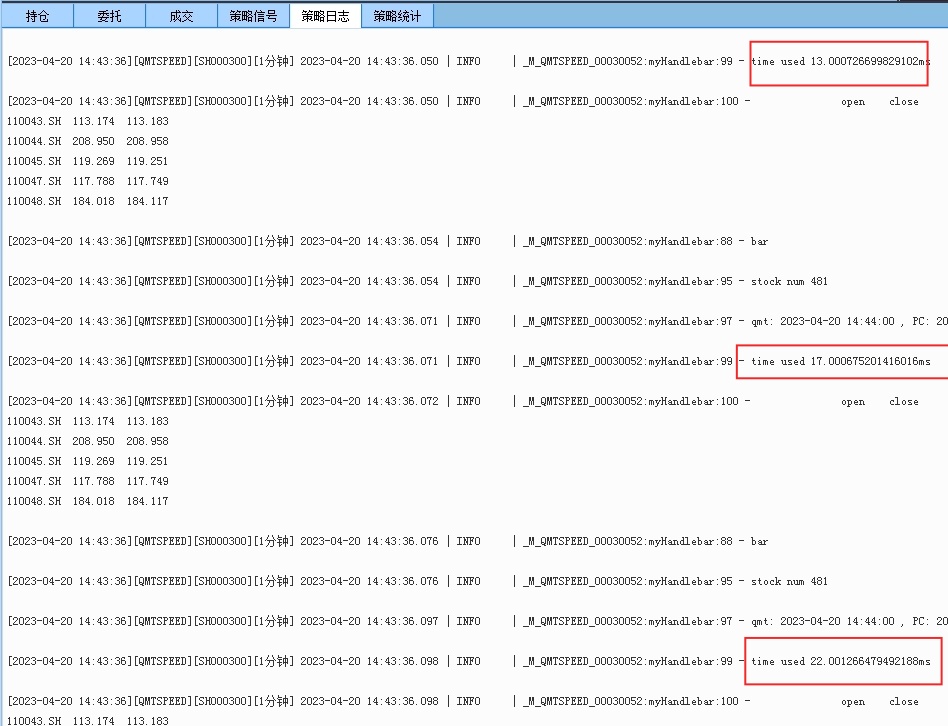
随着后续运行,获取实时行情的时间就趋于稳定,从800毫秒慢慢降到150毫秒,最后到13-20毫秒,基本和ptrade差不多级别了。
实时行情延时方面,对比通达信
取110048.SH 这个转债的行情数据作为参考,因为QMT返回字段里面没有带tick的时间戳,所以拿通达信作的分时数据作为的对比,没有用L2,所以框住的位置时间约在14:47:03 ~ 14:47:06
图片上半部分通达信的分时数据,左下角的数据时间是14:47:06,所以数据并没有出现很大的延时。
总结
QMT稳定运行的时候,实时行情基本和Ptrade同一级别水平。但QMT的行情波动性大一些。而在初始启动获取数据时,QMT会非常耗费资源,且等待时间较长,而Ptrade则不存在这种问题。
QMT可以随意获取外部数据,所以对券商没有很高要求;而Ptrade目前只有一家券商(国盛证券)可以自由访问外部数据,如果缺少需要的数据或者指标,将无法实现相应的策略。
参考API接口文档:
Ptrade: http://ptradeapi.com/
QMT: http://qmt.ptradeapi.com/
公众号: 查看全部
上一篇文章(QMT vs Ptrade 速度对比 (一) 历史行情获取速度)对了了QMT和Ptrade的获取历史行情速度,本篇文章继续对它俩的实时行情速度。
本文以获取市场所有可转债的实时行情为例子,比较二者的速度。
Ptrade获取所有可转债实时行情
目前市场上有480多只可转债,由于Ptrade内置的数据源不足以支撑可转债的大部分策略,所以需要调用外部数据源,因此使用国盛证券的Ptrade进行交易,因为目前只有它可以链接外网,你可以把可转债的数据写入到数据库或者写成自己的接口,传递给Ptrade就可以了。
比如下面的基础数据接口。
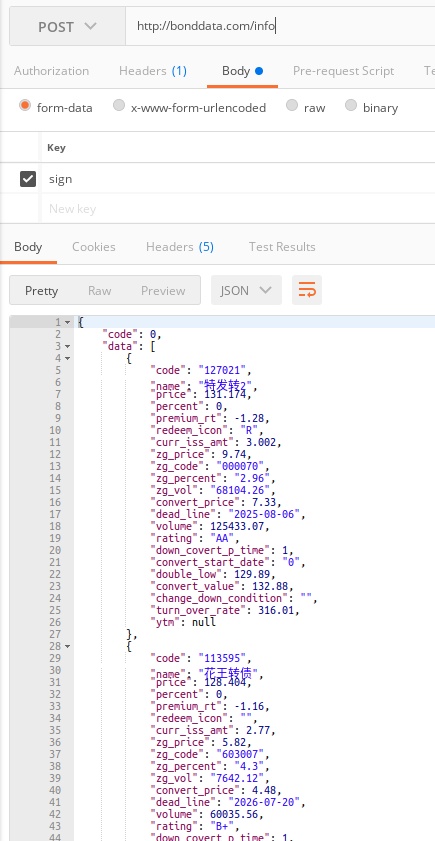
【目前星球用户可以提供数据接口免费调用功能,提供实时数据功能,强赎倒数多个API接口】
然后调用端使用python的requests库请求下就有了。下面代码可以在Ptrade里面部署运行,用于获取可转债溢价率,剩余规模等数据。
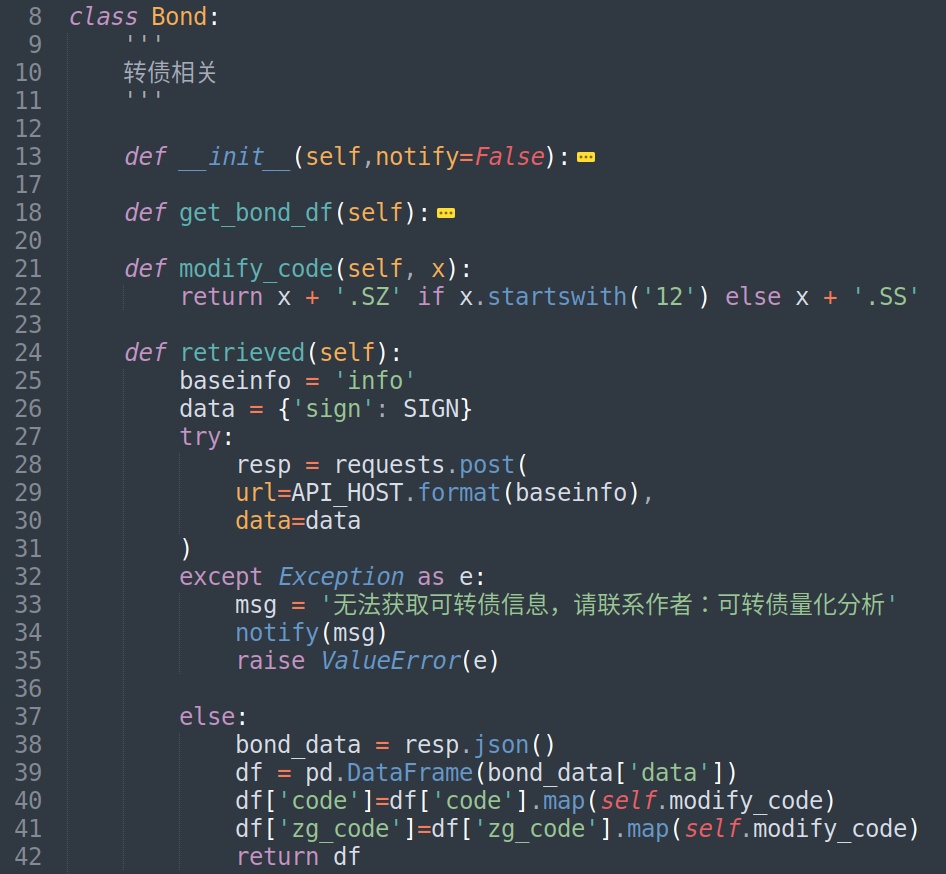
然后在Ptrade的定时执行函数里面获取实时tick数据,使用get_snapshot,把所有的转债代码传入get_snapshot就可以拿到可转债的行情数据了,行情数据3秒更新一次。
在Ptrade里面的运行情况
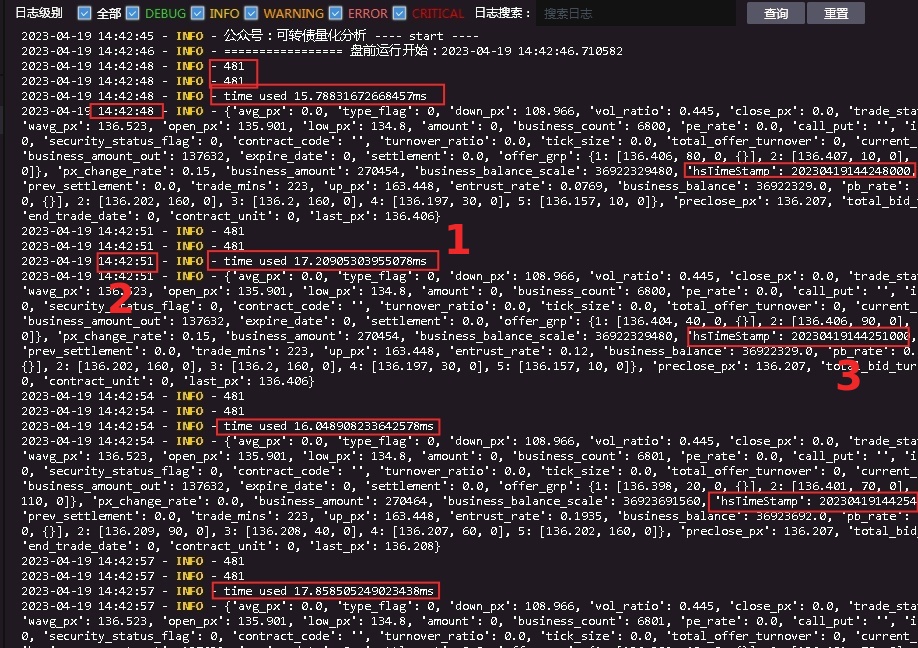
红框的地方是几个时间点要关注的。
481:获取的转债个数有481
红色数字1的位置: time used
获取行情数据所用的时间,大概在17毫秒(ms)左右,数据一直比较稳定。返回的数据里面字段除了价格,还有昨收价,委买卖1队列,涨停价,成交量等多个数据,参考上图里面的那个字典格式的数据。 具体可以参考接口文档(http://ptradeapi.com)
红色数字2的位置:日志输出时候的时间,也就是程序当前所在时刻,在目前程序在14:42:51,红色数字3的时间,是当前价格的里面的时间,也就tick对应的时间,当前的tick时间是hsTimeStamp: 20230419144251000, 也就是 2023-04-19 14:42:51:000, 所以当前时间程序获取的tick时间是一致的。为什么这里要强调这个呢? 假如当前程序时刻是14:42:51, 而获取的tick timestamp数据是14:42:48,那么说明当前程序拿到的最新tick数据却是在48秒时的数据,也就是数据延时了3秒。所以Ptrade里面的tick数据并没有出现延时滞后。
QMT 实时行情
同样QMT提供的可转债基础也是少的可怜,几乎为零。所以同样调用个人部署的可转债接口数据,如法炮制。PS:通过数据解耦的方式,不同数据可以在不同的量化软件里面使用,省去很多重复编写的代码,即使后面接入掘金,聚宽等平台,你只需要编写下单接口逻辑即可。
QMT取实时行情代码如下:

Bond是一个类,和ptrade里面的一样的,用来获取转债基础数据。
同样在QMT的实盘模式下执行:
网络环境:500M宽带网络,PC:CPU I7 - 内存24GB
stock num : 481 同样获取的是481个转债实时行情数据
红色数字1时间:日志输出的当前时间,获取行情数据前的时间14:43:25
红色数字2时间:日志输出的当前时间,此时为已经获取行情数据后的时间:14:43:34
红色数字3:第一次获取行情数据时间差,达到了9.5秒! 这个数字简直惊呆了。 反复测试几次后,依然如此,使用get_market_data获取实时行情数据,第一次数据到达的时候都要挺久的。
新人刚使用这个函数获取实时行情的时候,往往会以为自己代码出bug,等待很久没数据出来,尤其是获取超过1000个股票代码的行情的时候,等待时候更久,等待时间随着输入的个数增加而增加; 同时QMT占用内存也会稳步增加,如果机子的内存太小,可能还会卡死了。(qmt里面的坑还挺多的)


红色数字6,第二次获取实时行情所用的时间,这一次就快很多了,只用了800毫秒。
随着后续运行,获取实时行情的时间就趋于稳定,从800毫秒慢慢降到150毫秒,最后到13-20毫秒,基本和ptrade差不多级别了。
实时行情延时方面,对比通达信

取110048.SH 这个转债的行情数据作为参考,因为QMT返回字段里面没有带tick的时间戳,所以拿通达信作的分时数据作为的对比,没有用L2,所以框住的位置时间约在14:47:03 ~ 14:47:06
图片上半部分通达信的分时数据,左下角的数据时间是14:47:06,所以数据并没有出现很大的延时。
总结
QMT稳定运行的时候,实时行情基本和Ptrade同一级别水平。但QMT的行情波动性大一些。而在初始启动获取数据时,QMT会非常耗费资源,且等待时间较长,而Ptrade则不存在这种问题。
QMT可以随意获取外部数据,所以对券商没有很高要求;而Ptrade目前只有一家券商(国盛证券)可以自由访问外部数据,如果缺少需要的数据或者指标,将无法实现相应的策略。
参考API接口文档:
Ptrade: http://ptradeapi.com/
QMT: http://qmt.ptradeapi.com/
公众号:
【100行python代码实现可转债日内网格-成交驱动】 自定义买卖步长
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1380 次浏览 • 2023-04-19 13:27
## 2023-04-19 更新: 部分成交的需要等待全部成交才触发下一轮挂单
简单的可转债日内网格策略,自定义买卖步长,基准价格,买入与卖出数量,保留底仓张数
开始同时挂买入和卖出委托,如果买入成交后,撤掉委卖(如果是卖出先成交,则撤掉委买),继续挂入下一个步长的委买与委卖,不断循环。
把注释和空格去了100行不到。
代码仅供参考学习具体用法:
用于实盘亏损盈亏自负
后续如果有需要再贴个升级版:多标的网格
或者,额,qmt版本。。。
部分代码截图:
实盘交易日志:点击查看大图
完整代码请参见知识星球.
知识无价,请尊重知识。
查看全部
## 2023-04-19 更新: 部分成交的需要等待全部成交才触发下一轮挂单
简单的可转债日内网格策略,自定义买卖步长,基准价格,买入与卖出数量,保留底仓张数
开始同时挂买入和卖出委托,如果买入成交后,撤掉委卖(如果是卖出先成交,则撤掉委买),继续挂入下一个步长的委买与委卖,不断循环。
把注释和空格去了100行不到。
代码仅供参考学习具体用法:
用于实盘亏损盈亏自负
后续如果有需要再贴个升级版:多标的网格
或者,额,qmt版本。。。
部分代码截图:

实盘交易日志:点击查看大图


完整代码请参见知识星球.
知识无价,请尊重知识。
本地CPU部署的stable diffusion webui 环境,本地不受限,还可以生成色图黄图
深度学习 • 马化云 发表了文章 • 0 个评论 • 3655 次浏览 • 2023-04-17 00:27
需要不断调节词汇(英语),打造你想要的人物设定
由于本地使用的词汇不限制,还能够生成细节丰富的黄图。(宅男福音)
提供一个语法给你们用用:prompt: beautiful, masterpiece, best quality, extremely detailed face, perfect lighting, (1girl, solo, 1boy, 1girl, NemoNelly, Slight penetration, lying, on back, spread legs:1.5), street, crowd, ((skinny)), ((puffy eyes)), brown hair, medium hair, cowboy shot, medium breasts, swept bangs, walking, outdoors, sunshine, light_rays, fantasy, rococo, hair_flower,low tied hair, smile, half-closed eyes, dating, (nude), nsfw, (heavy breathing:1.5), tears, crying, blush, wet, sweat, <lora:koreanDollLikeness_v15:0.4>, <lora:povImminentPenetration_ipv1:0>, <lora:breastinclassBetter_v14:0.1>
整体来说,现在的AI技术和效果就像跃迁了一个台阶。
查看全部

.jpeg")
需要不断调节词汇(英语),打造你想要的人物设定

由于本地使用的词汇不限制,还能够生成细节丰富的黄图。(宅男福音)
提供一个语法给你们用用:
prompt: beautiful, masterpiece, best quality, extremely detailed face, perfect lighting, (1girl, solo, 1boy, 1girl, NemoNelly, Slight penetration, lying, on back, spread legs:1.5), street, crowd, ((skinny)), ((puffy eyes)), brown hair, medium hair, cowboy shot, medium breasts, swept bangs, walking, outdoors, sunshine, light_rays, fantasy, rococo, hair_flower,low tied hair, smile, half-closed eyes, dating, (nude), nsfw, (heavy breathing:1.5), tears, crying, blush, wet, sweat, <lora:koreanDollLikeness_v15:0.4>, <lora:povImminentPenetration_ipv1:0>, <lora:breastinclassBetter_v14:0.1>

整体来说,现在的AI技术和效果就像跃迁了一个台阶。

Stable Diffusion WebUI 模型下载速度很慢,但挂上梯子后速度狂飙
深度学习 • 马化云 发表了文章 • 0 个评论 • 2920 次浏览 • 2023-04-16 00:38
$ cd stable-diffusion-webui
$ git checkout 22bcc7be428c94e9408f589966c2040187245d81
# 我们需要 CPU 版本的 torch
$ export TORCH_COMMAND="pip install torch==1.13.1 torchvision==0.14.1 --index-url https: //download.pytorch.org/whl/cpu"
$ export USE_NNPACK=0
# 前 4 个参数是为了让其运行在 CPU 上, 最后一个参数是让 WebUI 可以远程访问
$ bash webui.sh --skip-torch-cuda-test --no-half --precision full --use-cpu all --listen
不过安装实在太慢了。而且安装好了之后,如果下载模型,还要单独下载,也是奇慢。
试了下把梯子代理挂上,模型下载就飞快了
除了模型,还有一些checkpoint文件
Stable diffusion v1.4
stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt
Stable diffusion v1.5
stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt
lora模型
koreanDollLikeness_v15.safetensors
等等。
查看全部
$ git clone https ://github.com/AUTOMATIC1111/stable-diffusion-webui.git
$ cd stable-diffusion-webui
$ git checkout 22bcc7be428c94e9408f589966c2040187245d81
# 我们需要 CPU 版本的 torch
$ export TORCH_COMMAND="pip install torch==1.13.1 torchvision==0.14.1 --index-url https: //download.pytorch.org/whl/cpu"
$ export USE_NNPACK=0
# 前 4 个参数是为了让其运行在 CPU 上, 最后一个参数是让 WebUI 可以远程访问
$ bash webui.sh --skip-torch-cuda-test --no-half --precision full --use-cpu all --listen
不过安装实在太慢了。而且安装好了之后,如果下载模型,还要单独下载,也是奇慢。
试了下把梯子代理挂上,模型下载就飞快了


除了模型,还有一些checkpoint文件
Stable diffusion v1.4
stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt
Stable diffusion v1.5
stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt
lora模型
koreanDollLikeness_v15.safetensors
等等。
没有显卡GPU,想用CPU玩Stable Diffusion 本地部署AI绘图吗? 手把手保姆教程
深度学习 • 马化云 发表了文章 • 0 个评论 • 1899 次浏览 • 2023-04-15 13:16
在网上看到那些美cry的AI生成的美女图片 ,你是不是也蠢蠢欲动想要按照自己的想法生成一副属于自己的女神照呢?
什么?你的电脑显卡没有显卡? 没关系,今天笔者带大家手把手在本地电脑上使用CPU部署Stable Diffusion+Lora AI绘画 模型。
什么是Stable Diffusion ?
Stable Diffusion 是一种通过文字描述创造出图像的 AI 模型. 它是一个开源软件, 有许多人愿意在网络上免费分享他们的计算资源, 使得新手可以在线尝试.
安装
本地部署的 Stable Diffusion 有更高的可玩性, 例如允许您替换模型文件, 细致的调整参数, 以及突破线上服务的道德伦理检查等. 鉴于我目前没有可供霍霍的 GPU, 因此我将在一台本地ubuntu上部署,因为Stable Diffusion 在运行过程中大概需要吃掉 12G 内存。如果你的电脑或者服务器没有16GB以上的内存,需要配置一个虚拟内存来扩展你的内存容量,当然,性能也打个折扣,毕竟是在硬盘上扩展的内存空间。
如果你的电脑内存大小大于16GB,可以忽略以下的操作:$ dd if=/dev/zero of=/mnt/swap bs=64M count=256
$ chmod 0600 /mnt/swap
$ mkswap /mnt/swap
$ swapon /mnt/swap笔者的电脑配置:
然后直接安装下载并安装 Stable Diffusion WebUI:
稍等片刻(依赖你的网速)
由于需要连接到github下载源码,所以如果网络不稳定掉线,需要重新运行安装命令就可以了。
重新运行:bash webui.sh --skip-torch-cuda-test --no-half --precision full --use-cpu all --listen
这个脚本会自动创建python的虚拟环境,并安装对应的pip依赖,一键到位,可谓贴心。果断要到github上给原作者加星
等待一段时间, 在浏览器中打开 127.0.0.1:7860 即可见到 UI 界面.
下载更多模型
模型, 有时称为检查点文件(checkpoint), 是预先训练的 Stable Diffusion 权重, 用于生成一般或特定的图像类型. 模型可以生成的图像取决于用于训练它们的数据. 如果训练数据中没有猫, 模型将无法产生猫的形象. 同样, 如果您仅使用猫图像训练模型, 则只会产生猫.
Stable Diffusion WebUI 运行时会自动下载 Stable Diffusion v1.5 模型. 下面提供了一些快速下载其它模型的命令.$ cd models/Stable-diffusion# Stable diffusion v1.4
# 下面的URL超链接过长有省略号,需要右键复制url$ wget https://huggingface.co/CompVis ... .ckpt
# Stable diffusion v1.5$ wget https://huggingface.co/runwaym ... .ckpt# F222$ wget https://huggingface.co/acheong ... .ckpt# Anything V3$ wget
https://huggingface.co/Linaqru ... nsors
# Open Journey$ wget https://huggingface.co/prompth ... .ckpt# DreamShaper$ wget https://civitai.com/api/download/models/5636 -O dreamshaper_331BakedVae.safetensors# ChilloutMix$ wget https://civitai.com/api/download/models/11745 -O chilloutmix_NiPrunedFp32Fix.safetensors# Robo Diffusion$ wget
https://huggingface.co/nousr/r ... .ckpt
# Mo-di-diffusion$ wget
https://huggingface.co/nitroso ... .ckpt
# Inkpunk Diffusion$ wget
https://huggingface.co/Envvi/I ... .ckpt
修改配置文件
ui-config.json 内包含众多的设置项, 可按照个人的习惯修改部分默认值. 例如我的配置部分如下:{
"txt2img/Batch size/value": 4,
"txt2img/Width/value": 480,
"txt2img/Height/value": 270
}提示语示例model: chilloutmix_NiPrunedFp32Fix.safetensors
prompt: beautiful, masterpiece, best quality, extremely detailed face, perfect lighting, (1girl, solo, 1boy, 1girl, NemoNelly, Slight penetration, lying, on back, spread legs:1.5), street, crowd, ((skinny)), ((puffy eyes)), brown hair, medium hair, cowboy shot, medium breasts, swept bangs, walking, outdoors, sunshine, light_rays, fantasy, rococo, hair_flower,low tied hair, smile, half-closed eyes, dating, (nude), nsfw, (heavy breathing:1.5), tears, crying, blush, wet, sweat, <lora:koreanDollLikeness_v15:0.4>, <lora:povImminentPenetration_ipv1:0>, <lora:breastinclassBetter_v14:0.1>
prompt: paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.331), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), bad hands, missing fingers, extra digit, bad body, pubic
上述提示词结尾引用了 3 个 Lora 模型, 需提前下载至 models/Lora 目录.$ cd models/Lora
$ wget
https://huggingface.co/amornln ... nsors
$ wget
https://huggingface.co/samle/s ... nsors
$ wget https://huggingface.co/jomcs/N ... nsors生成的效果图:
查看全部






在网上看到那些美cry的AI生成的美女图片 ,你是不是也蠢蠢欲动想要按照自己的想法生成一副属于自己的女神照呢?
什么?你的电脑显卡没有显卡? 没关系,今天笔者带大家手把手在本地电脑上使用CPU部署Stable Diffusion+Lora AI绘画 模型。
什么是Stable Diffusion ?
Stable Diffusion 是一种通过文字描述创造出图像的 AI 模型. 它是一个开源软件, 有许多人愿意在网络上免费分享他们的计算资源, 使得新手可以在线尝试.
安装
本地部署的 Stable Diffusion 有更高的可玩性, 例如允许您替换模型文件, 细致的调整参数, 以及突破线上服务的道德伦理检查等. 鉴于我目前没有可供霍霍的 GPU, 因此我将在一台本地ubuntu上部署,因为Stable Diffusion 在运行过程中大概需要吃掉 12G 内存。如果你的电脑或者服务器没有16GB以上的内存,需要配置一个虚拟内存来扩展你的内存容量,当然,性能也打个折扣,毕竟是在硬盘上扩展的内存空间。
如果你的电脑内存大小大于16GB,可以忽略以下的操作:
$ dd if=/dev/zero of=/mnt/swap bs=64M count=256笔者的电脑配置:
$ chmod 0600 /mnt/swap
$ mkswap /mnt/swap
$ swapon /mnt/swap

然后直接安装下载并安装 Stable Diffusion WebUI:
稍等片刻(依赖你的网速)

由于需要连接到github下载源码,所以如果网络不稳定掉线,需要重新运行安装命令就可以了。

重新运行:
bash webui.sh --skip-torch-cuda-test --no-half --precision full --use-cpu all --listen
这个脚本会自动创建python的虚拟环境,并安装对应的pip依赖,一键到位,可谓贴心。果断要到github上给原作者加星

等待一段时间, 在浏览器中打开 127.0.0.1:7860 即可见到 UI 界面.
下载更多模型
模型, 有时称为检查点文件(checkpoint), 是预先训练的 Stable Diffusion 权重, 用于生成一般或特定的图像类型. 模型可以生成的图像取决于用于训练它们的数据. 如果训练数据中没有猫, 模型将无法产生猫的形象. 同样, 如果您仅使用猫图像训练模型, 则只会产生猫.
Stable Diffusion WebUI 运行时会自动下载 Stable Diffusion v1.5 模型. 下面提供了一些快速下载其它模型的命令.
$ cd models/Stable-diffusion
# Stable diffusion v1.4
# 下面的URL超链接过长有省略号,需要右键复制url
$ wget https://huggingface.co/CompVis ... .ckpt
# Stable diffusion v1.5
$ wget https://huggingface.co/runwaym ... .ckpt
# F222
$ wget https://huggingface.co/acheong ... .ckpt
# Anything V3
$ wget
https://huggingface.co/Linaqru ... nsors
# Open Journey
$ wget https://huggingface.co/prompth ... .ckpt
# DreamShaper
$ wget https://civitai.com/api/download/models/5636 -O dreamshaper_331BakedVae.safetensors
# ChilloutMix
$ wget https://civitai.com/api/download/models/11745 -O chilloutmix_NiPrunedFp32Fix.safetensors
# Robo Diffusion
$ wget
https://huggingface.co/nousr/r ... .ckpt
# Mo-di-diffusion
$ wget
https://huggingface.co/nitroso ... .ckpt
# Inkpunk Diffusion
$ wget修改配置文件
https://huggingface.co/Envvi/I ... .ckpt
ui-config.json 内包含众多的设置项, 可按照个人的习惯修改部分默认值. 例如我的配置部分如下:
{
"txt2img/Batch size/value": 4,
"txt2img/Width/value": 480,
"txt2img/Height/value": 270
}提示语示例model: chilloutmix_NiPrunedFp32Fix.safetensors
prompt: beautiful, masterpiece, best quality, extremely detailed face, perfect lighting, (1girl, solo, 1boy, 1girl, NemoNelly, Slight penetration, lying, on back, spread legs:1.5), street, crowd, ((skinny)), ((puffy eyes)), brown hair, medium hair, cowboy shot, medium breasts, swept bangs, walking, outdoors, sunshine, light_rays, fantasy, rococo, hair_flower,low tied hair, smile, half-closed eyes, dating, (nude), nsfw, (heavy breathing:1.5), tears, crying, blush, wet, sweat, <lora:koreanDollLikeness_v15:0.4>, <lora:povImminentPenetration_ipv1:0>, <lora:breastinclassBetter_v14:0.1>
prompt: paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.331), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), bad hands, missing fingers, extra digit, bad body, pubic
上述提示词结尾引用了 3 个 Lora 模型, 需提前下载至 models/Lora 目录.
$ cd models/Lora
$ wget
https://huggingface.co/amornln ... nsors
$ wget
https://huggingface.co/samle/s ... nsors
$ wget https://huggingface.co/jomcs/N ... nsors生成的效果图:

QMT vs Ptrade 速度对比 (一) 历史行情获取速度
QMT • 李魔佛 发表了文章 • 0 个评论 • 1819 次浏览 • 2023-04-11 16:45
Ptrade(恒生电子)则是在券商部署的服务器上执行,你下载的Ptrade在你的本地电脑,只是负责写代码,把代码部署到券商服务器,然后在券商服务其执行你的策略,当然你的代码在券商服务器运行时是被加密的。行情获取,计算指标,下单委托都在券商机房内部执行,属于云策略的类型,策略部署好了,就不需要开着本地电脑观察它的状态。
对比环境均为同一个券商下的QMT和Ptrade,均为生产环境的实盘版本。(PS:温馨提示,平时少用模拟版本,bug多,交易不准,还浪费时间。我平时调试都直接在实盘上调试的,要对自己的策略有信心哈,至少回测过了的嘛O(∩_∩)O~~)
历史行情数据获取
目标:获取2022年到昨天的沪深300所有股票的日线收盘价数据。
QMT
获取行情数据 使用这个函数:ContextInfo.get_market_data()用法: ContextInfo.get_market_data(fields, stock_code = , start_time = '',
end_time = '', skip_paused = True, period = 'follow',
dividend_type = 'follow', count = -1)
open -- 开盘价(str:numpy.float64);
high -- 最高价(str:numpy.float64);
low --最低价(str:numpy.float64);
close -- 收盘价(str:numpy.float64);
volume -- 交易量(str:numpy.float64);
money -- 交易金额(str:numpy.float64);
price -- 最新价(str:numpy.float64);
preclose -- 昨收盘价(str:numpy.float64)(仅日线返回);
high_limit -- 涨停价(str:numpy.float64)(仅日线返回);
low_limit -- 跌停价(str:numpy.float64)(仅日线返回);
unlimited -- 判断查询日是否无涨跌停限制(1:该日无涨跌停限制;0:该日有涨跌停限制)(str:numpy.float64)(仅日线返回);
在fields里面指定只获取close价格即可。
QMT测试代码如下:(需要的也可以后台留言回复获取)
[vscode里面的代码,需要复制到qmt里面执行]
把代码复制到QMT里面,然后切换到模型交易,在中间切换到实盘模式,就会运行上面代码。
注意,这里需要第一次运行上面的代码来计算时间,因为QMT会有个cache缓存机制,它会把曾经跑过的历史数据自动下载下来,保存到你的电脑硬盘里,从而加快QMT后续的读取速度,同样的数据没有必要每次再去网络上拉。
大部分情况下网络IO都会是任何一个量化交易系通最大的性能瓶颈。
运行得到下面的结果:
上面运行时间是22秒。不要惊讶哦,首次获取历史行情数据都是挺慢的。如果你的电脑网速够快,或者但在阿里云,腾讯云之类的云服务上跑,获取历史行情速度会有所提高。
在你运行了上面的代码之后,QMT会在某个时刻,在后台把数据下载到本地QMT安装目录下。
文件按照股票代码作为文件名存储。当然里面不是txt格式,而是QMT做了相应的封装的。上面按照修改日期排序,4月11日多了很多新的DAT数据文件,显然是刚刚生成的。
QMT在获取历史行情数据后,会有个触发器,在后台一次性保存大量的文件,所以QMT会在某一个瞬间,界面会出现卡顿,甚至无响应,而看任务管理器会看到内存飙升甚至爆满100%,有些新人菜鸟就认为QMT太占内存,太垃圾的结论,这也是片面的。实际上在数据完备的情况下,QMT需要的内存4GB就够的了。如果你经常会有扫描全市场股票代码历史数据的话,内存还是尽量选大一点的。如果无法避免内存突然飙升,可以每次把获取行情的股票代码列表减少,细分多几批获取,用时间换空间。
当然 QMT也提供了一个下载历史数据的一个菜单入口,用于在图形界面下手动下载历史行情,从而加速历史行情读取速度。
等数据下载完成后,
第二次跑上面的同一个代码,运行时间明显快了。
但用时还是要7.9秒,反复测试几次,获取时间依然是在6-8秒之间波动。 因为程序读取历史行情数据的一个个独立的文件,所以这里硬盘的性能因素对获取行情影响还是很大的。
笔者感觉7.9秒这个速度还是很慢的,换了台性能好一点的的windows机子,下载了历史数据后再跑了一次:
但用时依然在6秒左右。
所以个人是不推荐大家在tick策略里面,在盘中去获取历史数据的,这个动作应该在盘前就应该完成,把数据保存到内存列表或者dataframe变量中,盘中用的时候去取就可以了。 当然低频策略就无所谓啦。
Ptrade
操作上ptrade相对而言更加简洁,容易上手。
它的API设计和它对应的API文档更加规范,可读性更好。
直接把代码复制到量化->策略,新建策略,然后在交易里面添加策略,直接启动策略。代码设置定时运行,在启动策略后的一分钟后运行。
同样获取沪深300的日线数据,2022年1月到2023年4月10日。
get_price - 获取历史数据 get_price(security, start_date=None, end_date=None, frequency='1d', fields=None, fq=None, count=None)
运行
上面的结果显示,Ptrade获取同样的历史数据耗时只有700毫秒,0.7秒左右。测试多几次,获取时间基本每次都比较平稳,在0.6-0.8秒之间。(下面打印的306不是沪深300的个数,而是获取到的日期的天数,它返回的结构虽然都是panel,但和QMT的轴有点不同)。
结论
总的来说,获取历史行情数据的速度,Ptrade是秒杀了QMT的,不在一个量级上的。
本来想继续对比实时行情,下单延时对比等等,但开盘时间有限,写了一下时间就不够用了。所以把教程拆分为多个系列,下一篇再对比QMT和PTrade的实时行情数据,下单回调等等啦。
如果想要自己测试文中的数据,可以获取代码,公众号 后台回复: 历史行情数据代码
参考API接口文档:
Ptrade: http://ptradeapi.com/
QMT: http://qmt.ptradeapi.com/
公众号: 查看全部
Ptrade(恒生电子)则是在券商部署的服务器上执行,你下载的Ptrade在你的本地电脑,只是负责写代码,把代码部署到券商服务器,然后在券商服务其执行你的策略,当然你的代码在券商服务器运行时是被加密的。行情获取,计算指标,下单委托都在券商机房内部执行,属于云策略的类型,策略部署好了,就不需要开着本地电脑观察它的状态。
对比环境均为同一个券商下的QMT和Ptrade,均为生产环境的实盘版本。(PS:温馨提示,平时少用模拟版本,bug多,交易不准,还浪费时间。我平时调试都直接在实盘上调试的,要对自己的策略有信心哈,至少回测过了的嘛O(∩_∩)O~~)
历史行情数据获取
目标:获取2022年到昨天的沪深300所有股票的日线收盘价数据。
QMT
获取行情数据 使用这个函数:ContextInfo.get_market_data()
用法: ContextInfo.get_market_data(fields, stock_code = , start_time = '',
end_time = '', skip_paused = True, period = 'follow',
dividend_type = 'follow', count = -1)
open -- 开盘价(str:numpy.float64);
high -- 最高价(str:numpy.float64);
low --最低价(str:numpy.float64);
close -- 收盘价(str:numpy.float64);
volume -- 交易量(str:numpy.float64);
money -- 交易金额(str:numpy.float64);
price -- 最新价(str:numpy.float64);
preclose -- 昨收盘价(str:numpy.float64)(仅日线返回);
high_limit -- 涨停价(str:numpy.float64)(仅日线返回);
low_limit -- 跌停价(str:numpy.float64)(仅日线返回);
unlimited -- 判断查询日是否无涨跌停限制(1:该日无涨跌停限制;0:该日有涨跌停限制)(str:numpy.float64)(仅日线返回);
在fields里面指定只获取close价格即可。
QMT测试代码如下:(需要的也可以后台留言回复获取)
[vscode里面的代码,需要复制到qmt里面执行]
把代码复制到QMT里面,然后切换到模型交易,在中间切换到实盘模式,就会运行上面代码。
注意,这里需要第一次运行上面的代码来计算时间,因为QMT会有个cache缓存机制,它会把曾经跑过的历史数据自动下载下来,保存到你的电脑硬盘里,从而加快QMT后续的读取速度,同样的数据没有必要每次再去网络上拉。
大部分情况下网络IO都会是任何一个量化交易系通最大的性能瓶颈。
运行得到下面的结果:

上面运行时间是22秒。不要惊讶哦,首次获取历史行情数据都是挺慢的。如果你的电脑网速够快,或者但在阿里云,腾讯云之类的云服务上跑,获取历史行情速度会有所提高。
在你运行了上面的代码之后,QMT会在某个时刻,在后台把数据下载到本地QMT安装目录下。

文件按照股票代码作为文件名存储。当然里面不是txt格式,而是QMT做了相应的封装的。上面按照修改日期排序,4月11日多了很多新的DAT数据文件,显然是刚刚生成的。
QMT在获取历史行情数据后,会有个触发器,在后台一次性保存大量的文件,所以QMT会在某一个瞬间,界面会出现卡顿,甚至无响应,而看任务管理器会看到内存飙升甚至爆满100%,有些新人菜鸟就认为QMT太占内存,太垃圾的结论,这也是片面的。实际上在数据完备的情况下,QMT需要的内存4GB就够的了。如果你经常会有扫描全市场股票代码历史数据的话,内存还是尽量选大一点的。如果无法避免内存突然飙升,可以每次把获取行情的股票代码列表减少,细分多几批获取,用时间换空间。
当然 QMT也提供了一个下载历史数据的一个菜单入口,用于在图形界面下手动下载历史行情,从而加速历史行情读取速度。

等数据下载完成后,
第二次跑上面的同一个代码,运行时间明显快了。

但用时还是要7.9秒,反复测试几次,获取时间依然是在6-8秒之间波动。 因为程序读取历史行情数据的一个个独立的文件,所以这里硬盘的性能因素对获取行情影响还是很大的。
笔者感觉7.9秒这个速度还是很慢的,换了台性能好一点的的windows机子,下载了历史数据后再跑了一次:

但用时依然在6秒左右。
所以个人是不推荐大家在tick策略里面,在盘中去获取历史数据的,这个动作应该在盘前就应该完成,把数据保存到内存列表或者dataframe变量中,盘中用的时候去取就可以了。 当然低频策略就无所谓啦。
Ptrade
操作上ptrade相对而言更加简洁,容易上手。
它的API设计和它对应的API文档更加规范,可读性更好。
直接把代码复制到量化->策略,新建策略,然后在交易里面添加策略,直接启动策略。代码设置定时运行,在启动策略后的一分钟后运行。

同样获取沪深300的日线数据,2022年1月到2023年4月10日。
get_price - 获取历史数据 get_price(security, start_date=None, end_date=None, frequency='1d', fields=None, fq=None, count=None)
运行

上面的结果显示,Ptrade获取同样的历史数据耗时只有700毫秒,0.7秒左右。测试多几次,获取时间基本每次都比较平稳,在0.6-0.8秒之间。(下面打印的306不是沪深300的个数,而是获取到的日期的天数,它返回的结构虽然都是panel,但和QMT的轴有点不同)。
结论
总的来说,获取历史行情数据的速度,Ptrade是秒杀了QMT的,不在一个量级上的。
本来想继续对比实时行情,下单延时对比等等,但开盘时间有限,写了一下时间就不够用了。所以把教程拆分为多个系列,下一篇再对比QMT和PTrade的实时行情数据,下单回调等等啦。
如果想要自己测试文中的数据,可以获取代码,公众号 后台回复: 历史行情数据代码
参考API接口文档:
Ptrade: http://ptradeapi.com/
QMT: http://qmt.ptradeapi.com/
公众号:
Ptrade QMT实盘策略记录 - 不定期更新
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 1733 次浏览 • 2023-04-03 15:27
写出来的是已经实现且实盘稳定运行的;
涨停板;依赖ptrade的高速行情自动配合手动;两融账户的股票日内做T,持有底仓;股票小市值轮动+多因子可转债多因子(有N个版本+不同的排除因子 组合)可转债日内高频股票趋势动量ETF轮动套利脉冲卖出扫描
纯粹自己做的记录,便于自己平时复盘。
有兴趣的朋友可以关注公众号交流。 查看全部
写出来的是已经实现且实盘稳定运行的;
- 涨停板;依赖ptrade的高速行情自动配合手动;
- 两融账户的股票日内做T,持有底仓;
- 股票小市值轮动+多因子
- 可转债多因子(有N个版本+不同的排除因子 组合)
- 可转债日内高频
- 股票趋势动量
- ETF轮动套利
- 脉冲卖出扫描
纯粹自己做的记录,便于自己平时复盘。

有兴趣的朋友可以关注公众号交流。
ptrade担保品买卖,融资买入,融券卖出,卖券还款,买券还券 下单后回调函数里面的结构
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 946 次浏览 • 2023-03-31 21:44
而对于不能安装第三方库的原因,不少菜鸟转而选择了QMT。有点可惜了ptrade。ptrade其实也可以联通外部数据。
ptrade软件设计层面和体验是企业级的,而QMT就呵呵哒,0售后技术支持,软件bug层出不穷。里面的某个别的工程师(袁姓)素质也是底下,我星球上的代码他也抄过去,抄过去后呢 放到他自己付费星球,而且还不止一篇。】
而ptrade相对而言,恒生电子的工程师服务就很到位,发送日志给他们,会在一天内分析结果告知你哪些出现问题了。
题外话说多了。
ptrade支持两融账户的量化操作。
如:担保品买卖,融资买入,融券卖出,卖券还款,买券还券margin_trade - 担保品买卖
margincash_open - 融资买入
margincash_close - 卖券还款
margincash_direct_refund - 直接还款
marginsec_open - 融券卖出
marginsec_close - 买券还券
它们之间的参数都比较相近:
margin_xxxx(security, amount, limit_price=None)
security:股票代码(str);
amount:交易数量,输入正数(int);
limit_price:买卖限价(float);
而用它们进行买卖操作后,在on_trade_response回调函数里面的机构提如下:
担保品买入:2023-03-31 14:41:02 - INFO - 生成订单,订单号:cd25d27f39854721aac99db13c9e9b73股票代码:601328.SS 数量:信用买入1000
2023-03-31 14:41:02 - INFO - {'error_info': '', 'stock_code': '601328.SS', 'order_id': 'cd25d27f39854721aac99db13c9e9b73', 'status': '2', 'price': 5.1, 'entrust_type': '9', 'amount': 1000, 'business_amount': 0.0, 'entrust_prop': '0', 'entrust_no': '1', 'order_time': '2023-03-31 14:35:53.776'}
2023-03-31 14:41:02 - INFO - {'business_amount': 1000, 'order_id': 'cd25d27f39854721aac99db13c9e9b73', 'stock_code': '601328.SS', 'entrust_bs': '1', 'entrust_no': '1', 'status': '8', 'business_balance': 5100.0, 'business_price': 5.1, 'business_id': '2', 'business_time': '2023-03-31 14:39:17'}
融资买入:2023-03-31 14:52:00 - INFO - 生成订单,订单号:01b7851d37014709bde3ec6ebe9e89c3股票代码:601328.SS 数量:融资买入100
2023-03-31 14:52:00 - INFO - {'price': 5.1, 'entrust_prop': '0', 'status': '2', 'entrust_type': '6', 'stock_code': '601328.SS', 'business_amount': 0.0, 'entrust_no': '3', 'order_time': '2023-03-31 14:46:51.620', 'error_info': '', 'amount': 100, 'order_id': '01b7851d37014709bde3ec6ebe9e89c3'}
2023-03-31 14:52:00 - INFO - {'business_id': '4', 'business_balance': 509.99999999999994, 'business_price': 5.1, 'order_id': '01b7851d37014709bde3ec6ebe9e89c3', 'business_time': '2023-03-31 14:50:14', 'status': '8', 'entrust_bs': '1', 'business_amount': 100, 'entrust_no': '3', 'stock_code': '601328.SS'}
卖券还款2023-03-31 14:58:20 - INFO - start
2023-03-31 14:59:00 - INFO - 生成订单,订单号:20cef28ec52c4d41b09c80fc49167497股票代码:600269.SS 数量:卖券还款-200
2023-03-31 14:59:00 - INFO - {'business_amount': 0.0, 'amount': -200, 'stock_code': '600269.SS', 'error_info': '', 'order_time': '2023-03-31 14:53:51.375', 'price': 3.38, 'entrust_type': '6', 'status': '2', 'order_id': '20cef28ec52c4d41b09c80fc49167497', 'entrust_prop': '0', 'entrust_no': '5'}
2023-03-31 14:59:00 - INFO - {'status': '8', 'business_time': '2023-03-31 14:57:14', 'stock_code': '600269.SS', 'entrust_bs': '2', 'business_id': '6', 'business_balance': -676.0, 'business_amount': -200, 'order_id': '20cef28ec52c4d41b09c80fc49167497', 'business_price': 3.38, 'entrust_no': '5'}
返回的结构体和那个普通账户交易的回调函数基本一致的。
查看全部
【ptrade的稳定性,获取行情速度,实盘交易,回测速度无意不秒杀QMT的。
而对于不能安装第三方库的原因,不少菜鸟转而选择了QMT。有点可惜了ptrade。ptrade其实也可以联通外部数据。
ptrade软件设计层面和体验是企业级的,而QMT就呵呵哒,0售后技术支持,软件bug层出不穷。里面的某个别的工程师(袁姓)素质也是底下,我星球上的代码他也抄过去,抄过去后呢 放到他自己付费星球,而且还不止一篇。】
而ptrade相对而言,恒生电子的工程师服务就很到位,发送日志给他们,会在一天内分析结果告知你哪些出现问题了。
题外话说多了。
ptrade支持两融账户的量化操作。
如:担保品买卖,融资买入,融券卖出,卖券还款,买券还券
margin_trade - 担保品买卖它们之间的参数都比较相近:
margincash_open - 融资买入
margincash_close - 卖券还款
margincash_direct_refund - 直接还款
marginsec_open - 融券卖出
marginsec_close - 买券还券
margin_xxxx(security, amount, limit_price=None)
security:股票代码(str);
amount:交易数量,输入正数(int);
limit_price:买卖限价(float);
而用它们进行买卖操作后,在on_trade_response回调函数里面的机构提如下:
担保品买入:
2023-03-31 14:41:02 - INFO - 生成订单,订单号:cd25d27f39854721aac99db13c9e9b73股票代码:601328.SS 数量:信用买入1000
2023-03-31 14:41:02 - INFO - {'error_info': '', 'stock_code': '601328.SS', 'order_id': 'cd25d27f39854721aac99db13c9e9b73', 'status': '2', 'price': 5.1, 'entrust_type': '9', 'amount': 1000, 'business_amount': 0.0, 'entrust_prop': '0', 'entrust_no': '1', 'order_time': '2023-03-31 14:35:53.776'}
2023-03-31 14:41:02 - INFO - {'business_amount': 1000, 'order_id': 'cd25d27f39854721aac99db13c9e9b73', 'stock_code': '601328.SS', 'entrust_bs': '1', 'entrust_no': '1', 'status': '8', 'business_balance': 5100.0, 'business_price': 5.1, 'business_id': '2', 'business_time': '2023-03-31 14:39:17'}
融资买入:
2023-03-31 14:52:00 - INFO - 生成订单,订单号:01b7851d37014709bde3ec6ebe9e89c3股票代码:601328.SS 数量:融资买入100
2023-03-31 14:52:00 - INFO - {'price': 5.1, 'entrust_prop': '0', 'status': '2', 'entrust_type': '6', 'stock_code': '601328.SS', 'business_amount': 0.0, 'entrust_no': '3', 'order_time': '2023-03-31 14:46:51.620', 'error_info': '', 'amount': 100, 'order_id': '01b7851d37014709bde3ec6ebe9e89c3'}
2023-03-31 14:52:00 - INFO - {'business_id': '4', 'business_balance': 509.99999999999994, 'business_price': 5.1, 'order_id': '01b7851d37014709bde3ec6ebe9e89c3', 'business_time': '2023-03-31 14:50:14', 'status': '8', 'entrust_bs': '1', 'business_amount': 100, 'entrust_no': '3', 'stock_code': '601328.SS'}
卖券还款
2023-03-31 14:58:20 - INFO - start
2023-03-31 14:59:00 - INFO - 生成订单,订单号:20cef28ec52c4d41b09c80fc49167497股票代码:600269.SS 数量:卖券还款-200
2023-03-31 14:59:00 - INFO - {'business_amount': 0.0, 'amount': -200, 'stock_code': '600269.SS', 'error_info': '', 'order_time': '2023-03-31 14:53:51.375', 'price': 3.38, 'entrust_type': '6', 'status': '2', 'order_id': '20cef28ec52c4d41b09c80fc49167497', 'entrust_prop': '0', 'entrust_no': '5'}
2023-03-31 14:59:00 - INFO - {'status': '8', 'business_time': '2023-03-31 14:57:14', 'stock_code': '600269.SS', 'entrust_bs': '2', 'business_id': '6', 'business_balance': -676.0, 'business_amount': -200, 'order_id': '20cef28ec52c4d41b09c80fc49167497', 'business_price': 3.38, 'entrust_no': '5'}
返回的结构体和那个普通账户交易的回调函数基本一致的。
Ptrade融资融券双均线 代码 讲解
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1181 次浏览 • 2023-03-31 02:08
def initialize(context):
# 初始化策略
# 设置我们要操作的股票池, 这里我们只操作一支股票
g.security = "600300.SS"
set_universe(g.security)
def before_trading_start(context, data):
# 买入标识
g.order_buy_flag = False
# 卖出标识
g.order_sell_flag = False
#当五日均线高于十日均线时买入,当五日均线低于十日均线时卖出
def handle_data(context, data):
# 得到十日历史价格
df = get_history(10, "1d", "close", g.security, fq=None, include=False)
# 得到五日均线价格
ma5 = round(df["close"][-5:].mean(), 3)
# 得到十日均线价格
ma10 = round(df["close"][-10:].mean(), 3)
# 取得昨天收盘价
price = data[g.security]["close"]
# 如果五日均线大于十日均线
if ma5 > ma10:
if not g.order_buy_flag:
# 获取最大可融资数量
amount = get_margincash_open_amount(g.security).get(g.security)
# 进行融资买入操作
margincash_open(g.security, amount)
# 记录这次操作
log.info("Buying %s Amount %s" % (g.security, amount))
# 当日已融资买入
g.order_buy_flag = True
# 如果五日均线小于十日均线,并且目前有头寸
elif ma5 < ma10 and get_position(g.security).amount > 0:
if not g.order_sell_flag:
# 获取标的卖券还款最大可卖数量
amount = get_margincash_close_amount(g.security).get(g.security)
# 进行卖券还款操作
margincash_close(g.security, -amount)
# 记录这次操作
log.info("Selling %s Amount %s" % (g.security, amount))
# 当日已卖券还款
g.order_sell_flag = True 查看全部
def initialize(context):
# 初始化策略
# 设置我们要操作的股票池, 这里我们只操作一支股票
g.security = "600300.SS"
set_universe(g.security)
def before_trading_start(context, data):
# 买入标识
g.order_buy_flag = False
# 卖出标识
g.order_sell_flag = False
#当五日均线高于十日均线时买入,当五日均线低于十日均线时卖出
def handle_data(context, data):
# 得到十日历史价格
df = get_history(10, "1d", "close", g.security, fq=None, include=False)
# 得到五日均线价格
ma5 = round(df["close"][-5:].mean(), 3)
# 得到十日均线价格
ma10 = round(df["close"][-10:].mean(), 3)
# 取得昨天收盘价
price = data[g.security]["close"]
# 如果五日均线大于十日均线
if ma5 > ma10:
if not g.order_buy_flag:
# 获取最大可融资数量
amount = get_margincash_open_amount(g.security).get(g.security)
# 进行融资买入操作
margincash_open(g.security, amount)
# 记录这次操作
log.info("Buying %s Amount %s" % (g.security, amount))
# 当日已融资买入
g.order_buy_flag = True
# 如果五日均线小于十日均线,并且目前有头寸
elif ma5 < ma10 and get_position(g.security).amount > 0:
if not g.order_sell_flag:
# 获取标的卖券还款最大可卖数量
amount = get_margincash_close_amount(g.security).get(g.security)
# 进行卖券还款操作
margincash_close(g.security, -amount)
# 记录这次操作
log.info("Selling %s Amount %s" % (g.security, amount))
# 当日已卖券还款
g.order_sell_flag = True
Ptrade担保品买入卖出
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 949 次浏览 • 2023-03-31 01:31
实际上是买卖股票,但在信用账户上,用只有资金买卖股票。
ptrade支持两融操作。
比如下面的示例代告诉我们,担保品买入股票的3个不同参数的效果:def initialize(context):
g.security = '600570.SS'
set_universe(g.security)
def handle_data(context, data):
# 以系统最新价委托
margin_trade(g.security, 100)
# 以72块价格下一个限价单
margin_trade(g.security, 100, limit_price=72)
# 以最优五档即时成交剩余撤销委托
margin_trade(g.security, 200, market_type=4) security:股票代码(str);
amount:交易数量,正数表示买入,负数表示卖出(int);
limit_price:买卖限价(float);
market_type:市价委托类型,上证非科创板股票支持参数1、4,上证科创板股票支持参数0、1、2、4,深证股票支持参数0、2、3、4、5(int);
0:对手方最优价格;
1:最优五档即时成交剩余转限价;
2:本方最优价格;
3:即时成交剩余撤销;
4:最优五档即时成交剩余撤销;
5:全额成交或撤单; 查看全部
担保品卖出指的是融资融券交易当中,用自有资金进行买卖的行为
实际上是买卖股票,但在信用账户上,用只有资金买卖股票。
ptrade支持两融操作。
比如下面的示例代告诉我们,担保品买入股票的3个不同参数的效果:
def initialize(context):
g.security = '600570.SS'
set_universe(g.security)
def handle_data(context, data):
# 以系统最新价委托
margin_trade(g.security, 100)
# 以72块价格下一个限价单
margin_trade(g.security, 100, limit_price=72)
# 以最优五档即时成交剩余撤销委托
margin_trade(g.security, 200, market_type=4)
security:股票代码(str);
amount:交易数量,正数表示买入,负数表示卖出(int);
limit_price:买卖限价(float);
market_type:市价委托类型,上证非科创板股票支持参数1、4,上证科创板股票支持参数0、1、2、4,深证股票支持参数0、2、3、4、5(int);
0:对手方最优价格;
1:最优五档即时成交剩余转限价;
2:本方最优价格;
3:即时成交剩余撤销;
4:最优五档即时成交剩余撤销;
5:全额成交或撤单;
anaconda安装python报错 缺少:api-ms-win-core-path-l1-1-0.dll
python • 马化云 发表了文章 • 0 个评论 • 1468 次浏览 • 2023-03-30 18:16
少了dll文件。
于是学网上(csdn)的方法进行修复,把缺的dll下载下来复制到system32的目录。
但是后面还是报错。
Python path configuration:
PYTHONHOME = (not set)
PYTHONPATH = (not set)
program name = 'python'
isolated = 0
environment = 1
user site = 1
import site = 1
sys._base_executable = '\u0158\x06'
sys.base_prefix = '.'
sys.base_exec_prefix = '.'
sys.executable = '\u0158\x06'
sys.prefix = '.'
sys.exec_prefix = '.'
sys.path = [
'C:\\anaconda\\python38.zip',
'.\\DLLs',
'.\\lib',
'',
]
Fatal Python error: init_fs_encoding: failed to get the Python codec of the filesystem encodin
Python runtime state: core initialized
ModuleNotFoundError: No module named 'encodings'
Current thread 0x000013a8 (most recent call first):
后面才发现,win7的机子只能安装python3.8以下的版本,高版本会报错。
查看全部

少了dll文件。
于是学网上(csdn)的方法进行修复,把缺的dll下载下来复制到system32的目录。
但是后面还是报错。
Python path configuration:
PYTHONHOME = (not set)
PYTHONPATH = (not set)
program name = 'python'
isolated = 0
environment = 1
user site = 1
import site = 1
sys._base_executable = '\u0158\x06'
sys.base_prefix = '.'
sys.base_exec_prefix = '.'
sys.executable = '\u0158\x06'
sys.prefix = '.'
sys.exec_prefix = '.'
sys.path = [
'C:\\anaconda\\python38.zip',
'.\\DLLs',
'.\\lib',
'',
]
Fatal Python error: init_fs_encoding: failed to get the Python codec of the filesystem encodin
Python runtime state: core initialized
ModuleNotFoundError: No module named 'encodings'
Current thread 0x000013a8 (most recent call first):
后面才发现,win7的机子只能安装python3.8以下的版本,高版本会报错。
国信如何运行miniQMT
QMT • 李魔佛 发表了文章 • 0 个评论 • 2077 次浏览 • 2023-03-30 02:31
不过它需要额外申请。就看你的经理愿不愿意帮你去申请了。
毕竟申请这个没有资金要求,纯粹看经理的心情了。申请需要打印纸质电子版文件并签字,拍照发给营业部审核。
而且开通了miniQMT后,只能拉取数据,无法进行交易,因为个人是没有交易权限的,只有机构才可以申请miniQMT的交易权限。
这也是经理不愿意帮你开通的原因,他们有可能会说国信目前不支持miniQMT这样的胡话来推搪打发你。如果需要申请开通,可以联系文末二维码开通国信iquant和miniQMT,这位经理比较热心肠,只要申请,就可以帮你开通miniQMT权限。
如何打开国信的miniQMT?
国信的miniQMT并不是和iQuant绑定的,笔者怀疑是因为iQuant定制化过多,甚至把miniQMT给阉割了。以至于为了补回miniQMT,他们还得特意要下载一个QMT的客户端(其实这个就是其他券商的QMT客户端),然后使用这个客户端和xtquant通讯。
输入个人的账户和密码后,登录极速版,对,国信的极速版即使miniQMT了。勾选极简模式。 国信的miniQMT支持自动登录,这个比国金的要好。国金的由于没有自动登录,每天还得自己手动的登录一次。(笔者之前也提供了几个版本的自动登录脚本,需要的可以到星球获取)
行情源这里要注意,如果你选择的获取最新价,那么在获取行情数据的返回值里面,只有最新价格,没有5档委托价格。( 国信iquant并没有这个选择菜单,估计是深度定制了,删除了)。
由于没有交易权限,账户里面没有显示个人的持仓信息,直接是空白一片
然后把xtquant的文件夹复制到本地的python site-package目录下。用以下下载数据的代码测试一下:
import pandas as pd
import datetime
def get_tick(code, start_time, end_time, period='tick'):
from xtquant import xtdata
xtdata.download_history_data(code, period=period, start_time=start_time, end_time=end_time)
data = xtdata.get_local_data(field_list=, stock_code=, period=period, count=10)
result_list = data df = pd.DataFrame(result_list)
df['time_str'] = df['time'].apply(lambda x: datetime.datetime.fromtimestamp(x / 1000.0))
return df
def process_timestamp(df, filename):
df = df.set_index('time_str')
result = df.resample('3S').first().ffill()
# result = result[(result.index >= '2022-07-20 09:30') & (result.index <= '2022-07-20 15:00')]
result = result.reset_index()
result.to_csv(filename + '.csv')
def dump_single_code_tick():
# 导出单个转债的tick数据
code='128022'
start_date = '20210113'
end_date = '20210130'
post_fix = 'SZ' if code.startswith('12') else 'SH'
code = '{}.{}'.format(code,post_fix)
filename = '{}'.format(code)
df = get_tick(code, start_date, end_date)
process_timestamp(df, filename)
dump_single_code_tick()保存上述代码为app.py
运行python app.py
稍等片刻,数据导出到当前路径,名字为:
128022.sz
打开看一下,数据在csv里面的了。
可关注下面关注号; 如需要开通国信,可以后台回复:开通国信证券
查看全部
不过它需要额外申请。就看你的经理愿不愿意帮你去申请了。
毕竟申请这个没有资金要求,纯粹看经理的心情了。申请需要打印纸质电子版文件并签字,拍照发给营业部审核。
而且开通了miniQMT后,只能拉取数据,无法进行交易,因为个人是没有交易权限的,只有机构才可以申请miniQMT的交易权限。
这也是经理不愿意帮你开通的原因,他们有可能会说国信目前不支持miniQMT这样的胡话来推搪打发你。如果需要申请开通,可以联系文末二维码开通国信iquant和miniQMT,这位经理比较热心肠,只要申请,就可以帮你开通miniQMT权限。
如何打开国信的miniQMT?
国信的miniQMT并不是和iQuant绑定的,笔者怀疑是因为iQuant定制化过多,甚至把miniQMT给阉割了。以至于为了补回miniQMT,他们还得特意要下载一个QMT的客户端(其实这个就是其他券商的QMT客户端),然后使用这个客户端和xtquant通讯。
输入个人的账户和密码后,登录极速版,对,国信的极速版即使miniQMT了。勾选极简模式。 国信的miniQMT支持自动登录,这个比国金的要好。国金的由于没有自动登录,每天还得自己手动的登录一次。(笔者之前也提供了几个版本的自动登录脚本,需要的可以到星球获取)


行情源这里要注意,如果你选择的获取最新价,那么在获取行情数据的返回值里面,只有最新价格,没有5档委托价格。( 国信iquant并没有这个选择菜单,估计是深度定制了,删除了)。
由于没有交易权限,账户里面没有显示个人的持仓信息,直接是空白一片

然后把xtquant的文件夹复制到本地的python site-package目录下。用以下下载数据的代码测试一下:
import pandas as pd
import datetime
def get_tick(code, start_time, end_time, period='tick'):
from xtquant import xtdata
xtdata.download_history_data(code, period=period, start_time=start_time, end_time=end_time)
data = xtdata.get_local_data(field_list=, stock_code=
, period=period, count=10)
result_list = data
df = pd.DataFrame(result_list)保存上述代码为app.py
df['time_str'] = df['time'].apply(lambda x: datetime.datetime.fromtimestamp(x / 1000.0))
return df
def process_timestamp(df, filename):
df = df.set_index('time_str')
result = df.resample('3S').first().ffill()
# result = result[(result.index >= '2022-07-20 09:30') & (result.index <= '2022-07-20 15:00')]
result = result.reset_index()
result.to_csv(filename + '.csv')
def dump_single_code_tick():
# 导出单个转债的tick数据
code='128022'
start_date = '20210113'
end_date = '20210130'
post_fix = 'SZ' if code.startswith('12') else 'SH'
code = '{}.{}'.format(code,post_fix)
filename = '{}'.format(code)
df = get_tick(code, start_date, end_date)
process_timestamp(df, filename)
dump_single_code_tick()
运行python app.py
稍等片刻,数据导出到当前路径,名字为:
128022.sz
打开看一下,数据在csv里面的了。
可关注下面关注号; 如需要开通国信,可以后台回复:开通国信证券
golang执行系统shell命令,并获取返回内容
Golang • 马化云 发表了文章 • 0 个评论 • 1190 次浏览 • 2023-03-26 11:42
"fmt"
"os/exec"
)
func runCommand(command string) (string, error) {
cmd := exec.Command("sh", "-c", command)
output, err := cmd.CombinedOutput()
if err != nil {
return "", err
}
return string(output), nil
}
调用 runCommand 函数即可执行 shell 命令,并获取命令的输出结果。如果命令执行成功,则返回输出结果和 nil,否则返回空字符串和错误信息。需要注意的是,由于 CombinedOutput 方法会等待命令执行完毕才返回,因此在执行耗时较长的命令时可能会阻塞程序的执行。可以使用 Start 和 Wait 方法实现异步执行命令的效果。 查看全部
import (
"fmt"
"os/exec"
)
func runCommand(command string) (string, error) {
cmd := exec.Command("sh", "-c", command)
output, err := cmd.CombinedOutput()
if err != nil {
return "", err
}
return string(output), nil
}
调用 runCommand 函数即可执行 shell 命令,并获取命令的输出结果。如果命令执行成功,则返回输出结果和 nil,否则返回空字符串和错误信息。需要注意的是,由于 CombinedOutput 方法会等待命令执行完毕才返回,因此在执行耗时较长的命令时可能会阻塞程序的执行。可以使用 Start 和 Wait 方法实现异步执行命令的效果。
修改正在运行的docker容器,禁用重启自动启动
Linux • 马化云 发表了文章 • 0 个评论 • 1157 次浏览 • 2023-03-26 11:17
可以使用 docker update 命令修改容器的配置,示例命令如下:docker update --restart=no <容器ID或名称>
这条命令会将容器的重启策略设置为不重启,即禁用重启自动启动。如果需要启用自动启动,只需要将 --restart 参数的值改为 always 或 on-failure 等相应的选项即可。
需要注意的是,修改容器的配置并不会立即生效,需要重启容器才能使修改生效。可以使用 docker restart 命令重启容器,示例命令如下:
docker restart <容器ID或名称>
执行这条命令后,容器会被重启并应用新的配置。 查看全部
可以使用 docker update 命令修改容器的配置,示例命令如下:
docker update --restart=no <容器ID或名称>
这条命令会将容器的重启策略设置为不重启,即禁用重启自动启动。如果需要启用自动启动,只需要将 --restart 参数的值改为 always 或 on-failure 等相应的选项即可。
需要注意的是,修改容器的配置并不会立即生效,需要重启容器才能使修改生效。可以使用 docker restart 命令重启容器,示例命令如下:
docker restart <容器ID或名称>
执行这条命令后,容器会被重启并应用新的配置。
国内免登录免注册的chatGPT套壳网站大全【 超全整理】
网络 • 马化云 发表了文章 • 0 个评论 • 63653 次浏览 • 2023-03-20 12:35
还没有体验的朋友可以试试chatGPT的强大
PS: 目前部分可能需要科学上网才能访问了。
ChatGPT 镜像网站汇总
BAI Chat GPT3.5 免登录 https://chat.theb.ai
ChatGPT GPT3.5 免登录 https://www.aitoolgpt.com/
Chat For AI GPT3.5 免登录,限制5次提问 https://chatforai.com/
ChatGPT Web GPT3.5 免登录 https://freechatgpt.chat/
ChatGPT GPT3.5 免登录 https://fastgpt.app/
光速Ai GPT3.5 免登录,限制 https://ai.ls
ChatGPT演示 GPT3.5 免登录 https://chatgpt.ddiu.me/
免费GPT GPT3.5 免登录 https://freegpt.one/
FreeGPT GPT3.5 免登录 https://freegpt.cc
ChatGPT Hub GPT3.5 免费100次,Plus接口 https://www.mulaen.com/
TGGPT GPT3.5 登录很卡 https://chat.tgbot.co/chat
New Chat GPT3.5 需API https://fastgpt.app/
开发交流 GPT3.5 免登录 https://chat.yqcloud.top
Ai117 GPT3.5 免登录 https://ai117.com/
周报通 GPT3.5 写周报专用 https://zhoubaotong.com/zh
Fake ChatGPT 未知 免登录 https://gpt.sheepig.top/chat
AI EDU GPT3.5 需API https://chat.forchange.cn/
中文公益版 免登录 https://gpt.tool00.com/
免费ChatGPT(论坛支持) GPT3 免登录 https://openaizh.com/chatgpt.html
AI Chat Bot GPT3 免登录,不稳定 https://chat.gptocean.com/
Hi icu GPT3 部分付费 https://hi.icu/
Aicodehelper GPT3 免登录 https://aicodehelper.com/
ChatGPT Robot 其他 其他 https://ai.zecoba.cn/
Ai帮个忙 其他 工具箱 https://ai-toolbox.codefuture.top/
GPTZero 内容检测 内容检测 https://gptzero.me/
ChatGPT中文版 GPT3.5 免登录 https://chat35.com/chat另外还有chatGPT共享整理一批 注册好的免费chatGPT账户,从分享群里获取的,亲测有效
查看全部
还没有体验的朋友可以试试chatGPT的强大
PS: 目前部分可能需要科学上网才能访问了。

ChatGPT 镜像网站汇总另外还有chatGPT共享整理一批 注册好的免费chatGPT账户,从分享群里获取的,亲测有效
BAI Chat GPT3.5 免登录 https://chat.theb.ai
ChatGPT GPT3.5 免登录 https://www.aitoolgpt.com/
Chat For AI GPT3.5 免登录,限制5次提问 https://chatforai.com/
ChatGPT Web GPT3.5 免登录 https://freechatgpt.chat/
ChatGPT GPT3.5 免登录 https://fastgpt.app/
光速Ai GPT3.5 免登录,限制 https://ai.ls
ChatGPT演示 GPT3.5 免登录 https://chatgpt.ddiu.me/
免费GPT GPT3.5 免登录 https://freegpt.one/
FreeGPT GPT3.5 免登录 https://freegpt.cc
ChatGPT Hub GPT3.5 免费100次,Plus接口 https://www.mulaen.com/
TGGPT GPT3.5 登录很卡 https://chat.tgbot.co/chat
New Chat GPT3.5 需API https://fastgpt.app/
开发交流 GPT3.5 免登录 https://chat.yqcloud.top
Ai117 GPT3.5 免登录 https://ai117.com/
周报通 GPT3.5 写周报专用 https://zhoubaotong.com/zh
Fake ChatGPT 未知 免登录 https://gpt.sheepig.top/chat
AI EDU GPT3.5 需API https://chat.forchange.cn/
中文公益版 免登录 https://gpt.tool00.com/
免费ChatGPT(论坛支持) GPT3 免登录 https://openaizh.com/chatgpt.html
AI Chat Bot GPT3 免登录,不稳定 https://chat.gptocean.com/
Hi icu GPT3 部分付费 https://hi.icu/
Aicodehelper GPT3 免登录 https://aicodehelper.com/
ChatGPT Robot 其他 其他 https://ai.zecoba.cn/
Ai帮个忙 其他 工具箱 https://ai-toolbox.codefuture.top/
GPTZero 内容检测 内容检测 https://gptzero.me/
ChatGPT中文版 GPT3.5 免登录 https://chat35.com/chat
ptrade QMT 动态止盈卖出 python代码实现
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1025 次浏览 • 2023-03-13 23:53
比如设置20%,那么会每天盘中扫描,可以精确到3S 一格,如果你的持仓股的收益率大于20%,它将会帮你自动卖出。
占坑 待续 》》》
比如设置20%,那么会每天盘中扫描,可以精确到3S 一格,如果你的持仓股的收益率大于20%,它将会帮你自动卖出。
占坑 待续 》》》
linux下自制护眼,久坐提醒 python小程序
python • 李魔佛 发表了文章 • 0 个评论 • 806 次浏览 • 2023-03-09 16:23
保存为app.py
运行; python app.py
然后写到系统的crontab计划任务里面,每个40分钟执行几次,
屏幕会黑屏60s , 60可以自行设置。
挺好用的。import datetime as dt
import tkinter as tk
# Linux 护眼程序
sec = 60 # 休息时间 秒
root = tk.Tk()
root.config(bg='black')
root.wm_attributes('-topmost',1)
root.wm_attributes('-fullscreen',1)
L = tk.Label(root,font=('Consolas', 50), bg='black')
L.place(relx=0.5,rely=0.5,anchor=tk.CENTER)
# 改变的内容
msg = "{}\n 站起来 {} \n 动一动 {}\n{}"
now = dt.datetime.now()
aa = {0:'↑',1:'→',2:'↓',3:'←'}
bb = {0:'~~_↑_~~',1:'~_↑ ↑_~'}
for i in range(sec):
t = msg.format(sec-i,aa[i%4],bb[i%2],(now+dt.timedelta(seconds=i)).ctime())
c = 'Black' # 颜色可以搞随机换
root.after(i*1000,L.config,{'text':t,'fg':c})
root.after(sec*1000,root.destroy)
root.mainloop()
PS: AI生成的image还真心不错呢。 就是太吃显存了
查看全部
保存为app.py
运行; python app.py
然后写到系统的crontab计划任务里面,每个40分钟执行几次,
屏幕会黑屏60s , 60可以自行设置。
挺好用的。
import datetime as dt
import tkinter as tk
# Linux 护眼程序
sec = 60 # 休息时间 秒
root = tk.Tk()
root.config(bg='black')
root.wm_attributes('-topmost',1)
root.wm_attributes('-fullscreen',1)
L = tk.Label(root,font=('Consolas', 50), bg='black')
L.place(relx=0.5,rely=0.5,anchor=tk.CENTER)
# 改变的内容
msg = "{}\n 站起来 {} \n 动一动 {}\n{}"
now = dt.datetime.now()
aa = {0:'↑',1:'→',2:'↓',3:'←'}
bb = {0:'~~_↑_~~',1:'~_↑ ↑_~'}
for i in range(sec):
t = msg.format(sec-i,aa[i%4],bb[i%2],(now+dt.timedelta(seconds=i)).ctime())
c = 'Black' # 颜色可以搞随机换
root.after(i*1000,L.config,{'text':t,'fg':c})
root.after(sec*1000,root.destroy)
root.mainloop()
PS: AI生成的image还真心不错呢。 就是太吃显存了
