通知设置 新通知
获取可转债历史分时tick数据 【python】
可转债 • 李魔佛 发表了文章 • 0 个评论 • 2659 次浏览 • 2022-06-25 12:29
对于想做日内回测的朋友,是一件很痛苦的事情。
那么,接下来,本文结束一种通过第三方平台的数据,来把可转债的分时tick数据获取下来,并保存到本地数据库。
2022-07-05 更新:
如果直接拿历史数据,可以拿到1分钟级别的数据,如上图所示。
如果要拿秒级别的,需要实时采集。
笔者使用sqlite做为内存缓存,盘后统一入到mysql中。
如果盘中每隔3秒使用mysql储存,显然会造成不必要的io阻塞(开个线程存数据也是一个方案)。
使用sqlite的时候,设置为memeory模式,速度比存文件要快很多倍。
待续 查看全部
对于想做日内回测的朋友,是一件很痛苦的事情。
那么,接下来,本文结束一种通过第三方平台的数据,来把可转债的分时tick数据获取下来,并保存到本地数据库。

2022-07-05 更新:
如果直接拿历史数据,可以拿到1分钟级别的数据,如上图所示。
如果要拿秒级别的,需要实时采集。
笔者使用sqlite做为内存缓存,盘后统一入到mysql中。

如果盘中每隔3秒使用mysql储存,显然会造成不必要的io阻塞(开个线程存数据也是一个方案)。
使用sqlite的时候,设置为memeory模式,速度比存文件要快很多倍。
待续
最近几天的有道云笔记保存的笔记全部丢失了
Linux • 李魔佛 发表了文章 • 0 个评论 • 1399 次浏览 • 2022-06-21 09:46
最近几天记录了几篇笔记,基本全部都不见了,最新日期的还是6月17日的。中间这几天保存的笔记被狗吃了。
搜索功能也越做越垃圾,建议用一个 云文件同步+typora 做笔记就可以。
最近几天记录了几篇笔记,基本全部都不见了,最新日期的还是6月17日的。中间这几天保存的笔记被狗吃了。
搜索功能也越做越垃圾,建议用一个 云文件同步+typora 做笔记就可以。
golang 插入redis 集合,并判断元素是否存在
Golang • 李魔佛 发表了文章 • 0 个评论 • 1383 次浏览 • 2022-06-20 17:26
1. "server/service" 是当前的报名
2. 用的go-redis这个库
判断元素是否在集合中:
conn.SIsMember("User", sign).Result()
完整代码:
package cache
import (
"server/service"
"fmt"
"github.com/go-redis/redis"
)
type Cache struct {
conn *redis.Client
}
func (this *Cache) CacheInit() {
this.connect()
}
func (this *Cache) connect() {
conf := service.ReadRedisConfig()
this.conn = redis.NewClient(&redis.Options{
Addr: conf.Addr,
Password: conf.Password,
DB: conf.DB,
})
}
func (this *Cache) Get(id string) (string, bool) {
result, err := this.conn.Get(id).Result()
if err != nil {
fmt.Println(err)
return "", false
}
return result, true
}
func (this *Cache) Set(id string, content string) bool {
_, err := this.conn.Set(id, content, 0).Result()
if err != nil {
fmt.Println(err)
return false
} else {
return true
}
}
func (this *Cache) CheckUserExist(sign string) bool {
result, err := this.conn.SIsMember("User", sign).Result()
if err != nil {
fmt.Println(err)
return false
}
return result
}
func (this *Cache) AddUser(name string) bool {
_, err := this.conn.SAdd("User", name).Result()
if err != nil {
fmt.Println(err)
return false
} else {
return true
}
}
github地址:
https://github.com/Rockyzsu/BondInfoServer.git
查看全部
1. "server/service" 是当前的报名
2. 用的go-redis这个库
判断元素是否在集合中:
conn.SIsMember("User", sign).Result()
完整代码:
package cache
import (
"server/service"
"fmt"
"github.com/go-redis/redis"
)
type Cache struct {
conn *redis.Client
}
func (this *Cache) CacheInit() {
this.connect()
}
func (this *Cache) connect() {
conf := service.ReadRedisConfig()
this.conn = redis.NewClient(&redis.Options{
Addr: conf.Addr,
Password: conf.Password,
DB: conf.DB,
})
}
func (this *Cache) Get(id string) (string, bool) {
result, err := this.conn.Get(id).Result()
if err != nil {
fmt.Println(err)
return "", false
}
return result, true
}
func (this *Cache) Set(id string, content string) bool {
_, err := this.conn.Set(id, content, 0).Result()
if err != nil {
fmt.Println(err)
return false
} else {
return true
}
}
func (this *Cache) CheckUserExist(sign string) bool {
result, err := this.conn.SIsMember("User", sign).Result()
if err != nil {
fmt.Println(err)
return false
}
return result
}
func (this *Cache) AddUser(name string) bool {
_, err := this.conn.SAdd("User", name).Result()
if err != nil {
fmt.Println(err)
return false
} else {
return true
}
}
github地址:
https://github.com/Rockyzsu/BondInfoServer.git
可转债交易新规什么时候实施,利好股市
券商万一免五 • 绫波丽 发表了文章 • 0 个评论 • 1240 次浏览 • 2022-06-18 15:23
昨天才看到可转债投资新规 今日和券商确认就已落地实施了(6.18日前开户的不受影响)来势汹汹,没有任何时间缓冲
但如果已满2年交易年限的老铁们,现在还有如下最低可转债费率(新规),需要的赶紧,
即使可转债降温,那又将利好股票,需要股票万一免五的也赶紧,不然又不知道哪天新规突然杀到,再想要也没有了
广发可转债:沪十万分之4.1,深十万分之4.1
银河股票:万一免五 ;可转债:沪十万分之5,深十万分之5
需要开户请扫码联系,备注:开户
查看全部
上交所发布关于可转换公司债券适当性管理相关事项的通知,个人投资者参与向不特定对象发行的可转债申购、交易,应当同时符合下列条件:申请权限开通前20个交易日证券账户及资金账户内的资产日均不低于人民币10万元(不包括该投资者通过融资融券融入的资金和证券);参与证券交易24个月以上。
昨天才看到可转债投资新规 今日和券商确认就已落地实施了(6.18日前开户的不受影响)来势汹汹,没有任何时间缓冲

但如果已满2年交易年限的老铁们,现在还有如下最低可转债费率(新规),需要的赶紧,
即使可转债降温,那又将利好股票,需要股票万一免五的也赶紧,不然又不知道哪天新规突然杀到,再想要也没有了
广发可转债:沪十万分之4.1,深十万分之4.1
银河股票:万一免五 ;可转债:沪十万分之5,深十万分之5
需要开户请扫码联系,备注:开户

不同券商的ptrade的异同
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 2409 次浏览 • 2022-06-17 16:36
1. 湘财无法访问外网,国盛的可以
2.
get_cb_list 获取可转债列表 的 国盛没有
get_history 获取历史数据函数
get_history(5, frequency='1d', field='close', security_list=['123084.SZ'], fq=None, include=False, fill='nan')国盛是没有fill参数的。
持续更新。。。待续
Ptrade开户联系:
查看全部
1. 湘财无法访问外网,国盛的可以
2.

get_cb_list 获取可转债列表 的 国盛没有
get_history 获取历史数据函数
get_history(5, frequency='1d', field='close', security_list=['123084.SZ'], fq=None, include=False, fill='nan')国盛是没有fill参数的。持续更新。。。待续
Ptrade开户联系:
Ptrade内置的第三方库查看
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 1833 次浏览 • 2022-06-17 10:19
APScheduler (3.3.1)
arch (3.2)
bcolz (1.2.1)
beautifulsoup4 (4.6.0)
bleach (1.5.0)
boto (2.43.0)
Bottleneck (1.0.0)
bz2file (0.98)
cachetools (3.1.0)
click (4.0)
contextlib2 (0.4.0)
crypto (1.4.1)
cvxopt (1.1.8)
cx-Oracle (8.0.1)
cycler (0.10.0)
cyordereddict (0.2.2)
Cython (0.22.1)
decorator (4.0.10)
entrypoints (0.2.2)
fastcache (1.0.2)
gensim (0.13.3)
h5py (2.6.0)
hmmlearn (0.2.0)
hs-udata (0.3.6)
html5lib (0.9999999)
ipykernel (4.5.0)
ipython (5.1.0)
ipython-genutils (0.1.0)
ipywidgets (5.2.2)
jieba (0.38)
Jinja2 (2.8)
jsonpickle (1.0)
jsonschema (2.5.1)
jupyter (1.0.0)
jupyter-client (4.4.0)
jupyter-console (5.0.0)
jupyter-core (4.2.0)
jupyter-kernel-gateway (1.1.1)
Keras (2.3.1)
Keras-Applications (1.0.8)
Keras-Preprocessing (1.1.0)
line-profiler (2.1.2)
Logbook (1.4.3)
lxml (4.5.0)
Markdown (2.2.0)
MarkupSafe (0.23)
matplotlib (1.5.3)
mistune (0.7.3)
Naked (0.1.31)
nbconvert (4.2.0)
nbformat (4.1.0)
networkx (1.9.1)
nose (1.3.6)
notebook (4.2.3)
numexpr (2.6.1)
numpy (1.11.2)
pandas (0.23.4)
patsy (0.4.0)
pexpect (4.2.1)
pickleshare (0.7.4)
pip (9.0.1)
pkgconfig (1.0.0)
prompt-toolkit (1.0.8)
protobuf (3.3.0)
ptvsd (2.2.0)
ptyprocess (0.5.1)
PyBrain (0.3)
pycrypto (2.6.1)
Pygments (2.1.3)
PyMySQL (0.9.3)
pyparsing (2.1.10)
python-dateutil (2.7.5)
pytz (2015.4)
PyWavelets (0.4.0)
PyYAML (5.3.1)
pyzmq (16.1.0.dev0)
qtconsole (4.2.1)
requests (2.7.0)
retrying (1.3.3)
scikit-learn (0.18)
scipy (0.18.0)
seaborn (0.7.1)
setuptools (28.7.1)
setuptools-scm (3.1.0)
shellescape (3.4.1)
simplegeneric (0.8.1)
simplejson (3.17.0)
six (1.10.0)
sklearn (0.0)
smart-open (1.3.5)
SQLAlchemy (1.0.8)
statsmodels (0.10.2)
TA-Lib (0.4.10)
tables (3.3.0)
tabulate (0.7.5)
tensorflow (1.3.0rc1)
tensorflow-tensorboard (0.1.2)
terminado (0.6)
Theano (0.8.2)
toolz (0.7.4)
tornado (4.4.2)
traitlets (4.3.1)
tushare (1.2.48)
tzlocal (1.3)
wcwidth (0.1.7)
Werkzeug (0.12.2)
wheel (0.29.0)
widgetsnbextension (1.2.6)
xcsc-tushare (1.0.0)
xgboost (0.6a2)
xlrd (1.1.0)
xlwt (1.3.0)
zipline (0.8.3)
You are using pip version 9.0.1, however version 22.1.2 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
由于内置了pymysql,所以可以直接读取你的数据库内容。这个需要你的ptrade具有连接外网功能才可以。
注:据个人经验,券商的开发能力约等于0,所以这一行为是恒生电子开放的,并非券商所为,券商并没有这么强的魔改能力,或者不敢做一些大的改动。
需要开通Ptrade的投资者可以联系微信:
股票费率万一免五 查看全部
APScheduler (3.3.1)
arch (3.2)
bcolz (1.2.1)
beautifulsoup4 (4.6.0)
bleach (1.5.0)
boto (2.43.0)
Bottleneck (1.0.0)
bz2file (0.98)
cachetools (3.1.0)
click (4.0)
contextlib2 (0.4.0)
crypto (1.4.1)
cvxopt (1.1.8)
cx-Oracle (8.0.1)
cycler (0.10.0)
cyordereddict (0.2.2)
Cython (0.22.1)
decorator (4.0.10)
entrypoints (0.2.2)
fastcache (1.0.2)
gensim (0.13.3)
h5py (2.6.0)
hmmlearn (0.2.0)
hs-udata (0.3.6)
html5lib (0.9999999)
ipykernel (4.5.0)
ipython (5.1.0)
ipython-genutils (0.1.0)
ipywidgets (5.2.2)
jieba (0.38)
Jinja2 (2.8)
jsonpickle (1.0)
jsonschema (2.5.1)
jupyter (1.0.0)
jupyter-client (4.4.0)
jupyter-console (5.0.0)
jupyter-core (4.2.0)
jupyter-kernel-gateway (1.1.1)
Keras (2.3.1)
Keras-Applications (1.0.8)
Keras-Preprocessing (1.1.0)
line-profiler (2.1.2)
Logbook (1.4.3)
lxml (4.5.0)
Markdown (2.2.0)
MarkupSafe (0.23)
matplotlib (1.5.3)
mistune (0.7.3)
Naked (0.1.31)
nbconvert (4.2.0)
nbformat (4.1.0)
networkx (1.9.1)
nose (1.3.6)
notebook (4.2.3)
numexpr (2.6.1)
numpy (1.11.2)
pandas (0.23.4)
patsy (0.4.0)
pexpect (4.2.1)
pickleshare (0.7.4)
pip (9.0.1)
pkgconfig (1.0.0)
prompt-toolkit (1.0.8)
protobuf (3.3.0)
ptvsd (2.2.0)
ptyprocess (0.5.1)
PyBrain (0.3)
pycrypto (2.6.1)
Pygments (2.1.3)
PyMySQL (0.9.3)
pyparsing (2.1.10)
python-dateutil (2.7.5)
pytz (2015.4)
PyWavelets (0.4.0)
PyYAML (5.3.1)
pyzmq (16.1.0.dev0)
qtconsole (4.2.1)
requests (2.7.0)
retrying (1.3.3)
scikit-learn (0.18)
scipy (0.18.0)
seaborn (0.7.1)
setuptools (28.7.1)
setuptools-scm (3.1.0)
shellescape (3.4.1)
simplegeneric (0.8.1)
simplejson (3.17.0)
six (1.10.0)
sklearn (0.0)
smart-open (1.3.5)
SQLAlchemy (1.0.8)
statsmodels (0.10.2)
TA-Lib (0.4.10)
tables (3.3.0)
tabulate (0.7.5)
tensorflow (1.3.0rc1)
tensorflow-tensorboard (0.1.2)
terminado (0.6)
Theano (0.8.2)
toolz (0.7.4)
tornado (4.4.2)
traitlets (4.3.1)
tushare (1.2.48)
tzlocal (1.3)
wcwidth (0.1.7)
Werkzeug (0.12.2)
wheel (0.29.0)
widgetsnbextension (1.2.6)
xcsc-tushare (1.0.0)
xgboost (0.6a2)
xlrd (1.1.0)
xlwt (1.3.0)
zipline (0.8.3)
You are using pip version 9.0.1, however version 22.1.2 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
由于内置了pymysql,所以可以直接读取你的数据库内容。这个需要你的ptrade具有连接外网功能才可以。
注:据个人经验,券商的开发能力约等于0,所以这一行为是恒生电子开放的,并非券商所为,券商并没有这么强的魔改能力,或者不敢做一些大的改动。
需要开通Ptrade的投资者可以联系微信:
股票费率万一免五
在中国网络环境下获取Golang.org上的Golang Packages
Golang • 李魔佛 发表了文章 • 0 个评论 • 1308 次浏览 • 2022-06-16 10:26
背景
目前在中国网络环境下无法访问Golang.org。
问题
不能运行go get golang.org/x/XX来获取Golang packages。
解决方案
方案 A: 使用github 上的镜像
获取Golang Package在github镜像上的路径: golang.org/x/PATH_TO_PACKAGE --> github.com/golang/PATH_TO_PACKAGE.
// Ex:
golang.org/x/net/context --> github.com/golang/net/context
运行go get来安装github镜像的Golang packages。
// Ex:
go get github.com/golang/net/context
你会碰到如下错误提示:
package github.com/golang/net/context:
code in directory /go/src/github.com/golang/net/context
expects import "golang.org/x/net/context"
忽略错误。 Golang的Package的源代码已经成功下载于:
$GOPATH/src/github.com/golang/PATH_TO_PACKAGE.
复制 $GOPATH/src/github.com/golang/PATH_TO_PACKAGE 到 $GOPATH/src/golang.org/x/PATH_TO_PACKAGE.
// Ex:
mkdir $GOPATH/src/golang.org/x -p
cp $GOPATH/src/github.com/golang/net $GOPATH/src/golang.org/x/ -rf
运行 go build 来编译。
方案 B: 使用第三方网站 - https://gopm.io/download
输入包路径即可下载zip文件。 查看全部
在中国网络环境下获取Golang.org上的Golang Packages
背景
目前在中国网络环境下无法访问Golang.org。
问题
不能运行go get golang.org/x/XX来获取Golang packages。
解决方案
方案 A: 使用github 上的镜像
获取Golang Package在github镜像上的路径: golang.org/x/PATH_TO_PACKAGE --> github.com/golang/PATH_TO_PACKAGE.
// Ex:
golang.org/x/net/context --> github.com/golang/net/context
运行go get来安装github镜像的Golang packages。
// Ex:
go get github.com/golang/net/context
你会碰到如下错误提示:
package github.com/golang/net/context:
code in directory /go/src/github.com/golang/net/context
expects import "golang.org/x/net/context"
忽略错误。 Golang的Package的源代码已经成功下载于:
$GOPATH/src/github.com/golang/PATH_TO_PACKAGE.
复制 $GOPATH/src/github.com/golang/PATH_TO_PACKAGE 到 $GOPATH/src/golang.org/x/PATH_TO_PACKAGE.
// Ex:
mkdir $GOPATH/src/golang.org/x -p
cp $GOPATH/src/github.com/golang/net $GOPATH/src/golang.org/x/ -rf
运行 go build 来编译。
方案 B: 使用第三方网站 - https://gopm.io/download
输入包路径即可下载zip文件。
控制pymysql的链接超时
python • 李魔佛 发表了文章 • 0 个评论 • 1492 次浏览 • 2022-06-14 23:39
conn = pymysql.connect(host=host, port=port, user=user, password=password, db=db, charset='utf8',timeout=3)
结果运行的时候直接报错的。好家伙。
难道都是东家抄西家,西家抄东家?
直接点进去源码:
这里直接有一个connect_timeout 的参数,这个才是最新的常数名。 查看全部
conn = pymysql.connect(host=host, port=port, user=user, password=password, db=db, charset='utf8',timeout=3)
结果运行的时候直接报错的。好家伙。
难道都是东家抄西家,西家抄东家?
直接点进去源码:

这里直接有一个connect_timeout 的参数,这个才是最新的常数名。
华宝证券app的行情数据很慢很慢
券商万一免五 • 绫波丽 发表了文章 • 0 个评论 • 2154 次浏览 • 2022-06-14 09:43
一个用了2年的手机,就被一个华宝智投的app卡死。
如果一个股票开盘高开,用华宝挂单,你怎么都不会卖得出去。 你只有羡慕别人的份。
脉冲冲高,用华宝,千万不能用现价卖出! 一定要往低压,因为行情慢,当前价格是未知。。
随便搜了下,是一个普遍现象。。
最主要的是,我按照实时下单,卖出,按照买一价, 10次有8次不是马上成交的。 说明你这个行情数据延误有多严重!!!!
至少,同样的操作习惯,在银河,国金上也没遇到过这么高的成交不了的概率。
查看全部
一个用了2年的手机,就被一个华宝智投的app卡死。
如果一个股票开盘高开,用华宝挂单,你怎么都不会卖得出去。 你只有羡慕别人的份。
脉冲冲高,用华宝,千万不能用现价卖出! 一定要往低压,因为行情慢,当前价格是未知。。
随便搜了下,是一个普遍现象。。


最主要的是,我按照实时下单,卖出,按照买一价, 10次有8次不是马上成交的。 说明你这个行情数据延误有多严重!!!!
至少,同样的操作习惯,在银河,国金上也没遇到过这么高的成交不了的概率。
linux下好用的git gui工具 推荐!
Linux • 李魔佛 发表了文章 • 0 个评论 • 2385 次浏览 • 2022-06-11 17:37
ubuntu下最好的图形git管理工具kranken (免费版本)
用了一个月之后,发现免费版不支持私有仓库,这。。。。。
那自己的私有仓库还得专门找软件管理。
突然看到ubuntu下平时用的不多的vs code,发现里面git的插件可真多。
把最多星的git相关插件装上后,它的功能基本大部分都可以覆盖了95%kraken的可视化功能了!
查看全部
ubuntu下最好的图形git管理工具kranken (免费版本)
用了一个月之后,发现免费版不支持私有仓库,这。。。。。
那自己的私有仓库还得专门找软件管理。
突然看到ubuntu下平时用的不多的vs code,发现里面git的插件可真多。
把最多星的git相关插件装上后,它的功能基本大部分都可以覆盖了95%kraken的可视化功能了!


Ptrade可以连接外网了!
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 2 个评论 • 2922 次浏览 • 2022-06-10 00:51
测试代码:import requests
def initialize(context):
# 初始化策略
g.security = "600570.SS"
set_universe(g.security)
def handle_data(context, data):
url='http://www.baidu.com'
headers={'User-Agent':'Google'}
try:
r=requests.get(url,headers=headers)
r.encoding='utf8'
print(r.text)
except Exception as e:
print('error')
print(e)
代码复制到回测那里,然后点击回测就可以看到结果了。
这下可以把之前的qmt的接口 搬到ptrade。 比如集思录接口,tushare接口,宁稳的接口,太多了。
笔者用的ptrade是国盛证券的,亲测可用~
PS:Ptrade是运行在券商机房,下单速度还是行情获取,都要比本地的qmt要快。且稳定,至少你家里断电断网的概率比人家机房断电断网的概率要大得多。
需要开通的投资者可以联系微信:
股票费率万一免五
备注:Ptrade 查看全部

测试代码:
import requests
def initialize(context):
# 初始化策略
g.security = "600570.SS"
set_universe(g.security)
def handle_data(context, data):
url='http://www.baidu.com'
headers={'User-Agent':'Google'}
try:
r=requests.get(url,headers=headers)
r.encoding='utf8'
print(r.text)
except Exception as e:
print('error')
print(e)
代码复制到回测那里,然后点击回测就可以看到结果了。
这下可以把之前的qmt的接口 搬到ptrade。 比如集思录接口,tushare接口,宁稳的接口,太多了。
笔者用的ptrade是国盛证券的,亲测可用~
PS:Ptrade是运行在券商机房,下单速度还是行情获取,都要比本地的qmt要快。且稳定,至少你家里断电断网的概率比人家机房断电断网的概率要大得多。
需要开通的投资者可以联系微信:
股票费率万一免五
备注:Ptrade
腾讯云上的rshim进程是什么作用
网络安全 • 李魔佛 发表了文章 • 0 个评论 • 3175 次浏览 • 2022-06-08 19:35
kill -9 pid
之后又会重新启动一个新的进程。 看着就像病毒或者木马的特征。
而且百度出来的结果都是csdn式的抄袭:
问了腾讯云的技术人员,居然他们也不知道是什么。
因为笔者的3台腾讯云的轻量服务器都有这个进程:
因为占用的CPU不高,所以笔者认为这个不是病毒。
然后google了一下:
这才发现,这个只是linux底层的一个驱动。
The rshim driver provides a way to access the rshim resources on the BlueField target from external host machine 查看全部
kill -9 pid
之后又会重新启动一个新的进程。 看着就像病毒或者木马的特征。
而且百度出来的结果都是csdn式的抄袭:

问了腾讯云的技术人员,居然他们也不知道是什么。
因为笔者的3台腾讯云的轻量服务器都有这个进程:


因为占用的CPU不高,所以笔者认为这个不是病毒。
然后google了一下:

这才发现,这个只是linux底层的一个驱动。
The rshim driver provides a way to access the rshim resources on the BlueField target from external host machine
golang gin ajax post 前端与后端的正确写法
Golang • 李魔佛 发表了文章 • 0 个评论 • 2099 次浏览 • 2022-06-08 18:42
前端是一个页面html页面
<script type="text/javascript">
var submitBTN = document.getElementById("url_update");
submitBTN.onclick = function (event) {
// 注意这里是 onclick 函数
console.log("click");
$.ajax({
url: "/update-site1",
type: "POST",
data: {value:1},
cache: false,
contentType: "application/x-www-form-urlencoded",
success: function (data) {
console.log(data);
if (data.code !== 0) {
alert('更新失败')
} else {
new_str = data.res + " " + data.count
$("#txt_content").val(new_str);
alert('更新资源成功!')
}
},
fail: function (data) {
alert("更新失败!");
}
});
$.ajax({
url: "/update-site1",
type: "POST",
data: {value:2},
cache: false,
contentType: "application/x-www-form-urlencoded",
success: function (data) {
console.log(data);
if (data.code !== 0) {
alert('更新失败')
} else {
new_str = data.res + " " + data.count
$("#txt_content").val(new_str);
alert('更新资源成功!')
}
},
fail: function (data) {
alert("更新失败!");
}
})
}
</script>
效果大体上这样的:
有几个按钮,然后每个按钮绑定一个点击事件
submitBTN.onclick = function (event) {
.....
同上面代码
然后在代码里面执行post操作,使用的是ajax封装的方法:
注意,contentType用下面的:
contentType: "application/x-www-form-urlencoded",
还有不要把
processData: false,这个设置为false,否则gin的后端解析不到数据
写完前端之后,就去后端
路由方法:
绑定上面的url update-site1
router.POST("/update-site1", controllers.BaiduSite1)
然后就是实现
controllers.BaiduSite1 这个方法:
func BaiduSite1(ctx *gin.Context) {
if ctx.Request.Method == "POST" {
value := ctx.PostForm("value")
fmt.Println(value)
int_value, err := strconv.Atoi(value)
if err != nil {
ctx.JSON(http.StatusOK, gin.H{
"code": 1,
"res": "",
"count": 0,
})
return
}
res, count := webmaster.PushProcess(1, int_value)
ctx.JSON(http.StatusOK, gin.H{
"code": 0,
"res": res,
"count": count,
})
}
}
获取ajax里面的字段,
使用:context 中的PostForm方法
value := ctx.PostForm("value")
剩下的就是一些常规的操作方法
最后需要设置json的返回数据
ctx.JSON(http.StatusOK, gin.H{
"code": 0,
"res": res,
"count": count,
完整代码可以到公众号里面获取:
查看全部
前端是一个页面html页面
<script type="text/javascript">
var submitBTN = document.getElementById("url_update");
submitBTN.onclick = function (event) {
// 注意这里是 onclick 函数
console.log("click");
$.ajax({
url: "/update-site1",
type: "POST",
data: {value:1},
cache: false,
contentType: "application/x-www-form-urlencoded",
success: function (data) {
console.log(data);
if (data.code !== 0) {
alert('更新失败')
} else {
new_str = data.res + " " + data.count
$("#txt_content").val(new_str);
alert('更新资源成功!')
}
},
fail: function (data) {
alert("更新失败!");
}
});
$.ajax({
url: "/update-site1",
type: "POST",
data: {value:2},
cache: false,
contentType: "application/x-www-form-urlencoded",
success: function (data) {
console.log(data);
if (data.code !== 0) {
alert('更新失败')
} else {
new_str = data.res + " " + data.count
$("#txt_content").val(new_str);
alert('更新资源成功!')
}
},
fail: function (data) {
alert("更新失败!");
}
})
}
</script>
效果大体上这样的:

有几个按钮,然后每个按钮绑定一个点击事件
submitBTN.onclick = function (event) {
.....
同上面代码
然后在代码里面执行post操作,使用的是ajax封装的方法:
注意,contentType用下面的:
contentType: "application/x-www-form-urlencoded",
还有不要把
processData: false,这个设置为false,否则gin的后端解析不到数据
写完前端之后,就去后端
路由方法:
绑定上面的url update-site1
router.POST("/update-site1", controllers.BaiduSite1)然后就是实现
controllers.BaiduSite1 这个方法:
func BaiduSite1(ctx *gin.Context) {
if ctx.Request.Method == "POST" {
value := ctx.PostForm("value")
fmt.Println(value)
int_value, err := strconv.Atoi(value)
if err != nil {
ctx.JSON(http.StatusOK, gin.H{
"code": 1,
"res": "",
"count": 0,
})
return
}
res, count := webmaster.PushProcess(1, int_value)
ctx.JSON(http.StatusOK, gin.H{
"code": 0,
"res": res,
"count": count,
})
}
}获取ajax里面的字段,
使用:context 中的PostForm方法
value := ctx.PostForm("value")剩下的就是一些常规的操作方法
最后需要设置json的返回数据
ctx.JSON(http.StatusOK, gin.H{
"code": 0,
"res": res,
"count": count,
完整代码可以到公众号里面获取:

轻量服务器原来都只是一个docker出来给你的应用
Linux • 李魔佛 发表了文章 • 0 个评论 • 1140 次浏览 • 2022-06-07 01:50
之前的服务器好歹还给你弄个虚拟机,现在就是一个进程隔离而已,CPU 跑到 100%一段时间以后就开始失去响应了,没有强制进程调度,跑重负载肯定是不行的,所以叫:“轻量”,诚不欺我也……
之前的服务器好歹还给你弄个虚拟机,现在就是一个进程隔离而已,CPU 跑到 100%一段时间以后就开始失去响应了,没有强制进程调度,跑重负载肯定是不行的,所以叫:“轻量”,诚不欺我也……
python安装demjson报错:error in setup command: use_2to3 is invalid.
python • 李魔佛 发表了文章 • 0 个评论 • 2104 次浏览 • 2022-06-06 19:23
随便整一个
pip install setuptools==57.5.0
原因:在setuptools 58之后的版本已经废弃了use_2to3所以安装一个旧版本的setuptools就可以了
随便整一个
pip install setuptools==57.5.0
美股指数成分股历史数据
股票 • 李魔佛 发表了文章 • 0 个评论 • 1222 次浏览 • 2022-06-06 12:53
找到的都是当前日期的数据。
所以搞了个程序定期获取。
每隔一个月获取一次。
图中数据为纳指100ETF成分股的历史数据
需要数据的可以关注公众号获取
后台回复:纳指100
查看全部

找到的都是当前日期的数据。
所以搞了个程序定期获取。
每隔一个月获取一次。
图中数据为纳指100ETF成分股的历史数据

需要数据的可以关注公众号获取

后台回复:纳指100
ubuntu用非root用户 无法启用80端口web服务
Linux • 李魔佛 发表了文章 • 0 个评论 • 1804 次浏览 • 2022-06-05 00:19
默认情况下,1024以下的端口,只有root用户可以使用,例如想用python3启动一个在80端口上的web服务,只能切换到root用户再启动。如果想不用root用户启动,怎么办呢?
解决办法
记录一种测试了的办法:
Linux 内核从 2.6.24 版本开始就有了能力的概念,这使得普通用户也能够做只有超级用户才能完成的工作。
使用 setcap 命令让指定程序拥有绑定端口的能力,这样即使程序运行在普通用户下,也能够绑定到 1024 以下的特权端口上。
# 给指定程序设置 CAP_NET_BIND_SERVICE 能力
$ sudo setcap cap_net_bind_service=+eip /home/xda/miniconda3/bin/python3.9
注意赋给的程序目标不能是软链接
注意 conda的python一般都是软链接
比如:
/home/xda/miniconda3/bin/python
很可能是指向
/home/xda/miniconda3/bin/python3.9的
如果使用的python路径
/home/xda/miniconda3/bin/python
给
setcap cap_net_bind_service=+eip
会报错的。 查看全部
需求 conda python
默认情况下,1024以下的端口,只有root用户可以使用,例如想用python3启动一个在80端口上的web服务,只能切换到root用户再启动。如果想不用root用户启动,怎么办呢?
解决办法
记录一种测试了的办法:
Linux 内核从 2.6.24 版本开始就有了能力的概念,这使得普通用户也能够做只有超级用户才能完成的工作。
使用 setcap 命令让指定程序拥有绑定端口的能力,这样即使程序运行在普通用户下,也能够绑定到 1024 以下的特权端口上。
# 给指定程序设置 CAP_NET_BIND_SERVICE 能力
$ sudo setcap cap_net_bind_service=+eip /home/xda/miniconda3/bin/python3.9
注意赋给的程序目标不能是软链接
注意 conda的python一般都是软链接
比如:
/home/xda/miniconda3/bin/python
很可能是指向
/home/xda/miniconda3/bin/python3.9的
如果使用的python路径
/home/xda/miniconda3/bin/python
给
setcap cap_net_bind_service=+eip
会报错的。
强赎日期计数 excel文件
可转债 • 李魔佛 发表了文章 • 0 个评论 • 1324 次浏览 • 2022-06-04 22:54
代码 名称 当前满足天数 强赎目标数 周期 以公告
113568 新春转债 已公告强赎
127043 川恒转债 暂不强赎
123086 海兰转债 暂不强赎
113548 石英转债 暂不强赎
128107 交科转债 已公告强赎
110071 湖盐转债 12 15 30
128111 中矿转债 暂不强赎
127013 创维转债 14 15 30
123092 天壕转债 暂不强赎
128046 利尔转债 19 20 30
127027 靖远转债 暂不强赎
113541 荣晟转债 公告要强赎
123085 万顺转2 暂不强赎
123083 朗新转债 12 15 30
128128 齐翔转2 暂不强赎
128106 华统转债 暂不强赎
113537 文灿转债 暂不强赎
128095 恩捷转债 已满足强赎条件
127007 湖广转债 暂不强赎
123012 万顺转债 暂不强赎
123057 美联转债 暂不强赎
113585 寿仙转债 暂不强赎
110061 川投转债 暂不强赎
113626 伯特转债 暂不强赎
113025 明泰转债 暂不强赎
123078 飞凯转债 暂不强赎
113567 君禾转债 暂不强赎
128017 金禾转债 暂不强赎
128040 华通转债 暂不强赎
128029 太阳转债 暂不强赎
123073 同和转债 暂不强赎
110055 伊力转债 暂不强赎
113525 台华转债 暂不强赎
123060 苏试转债 暂不强赎
127038 国微转债 暂不强赎
123046 天铁转债 暂不强赎
123098 一品转债 暂不强赎
110074 精达转债 暂不强赎
123114 三角转债 暂不强赎
113051 节能转债 暂不强赎
128140 润建转债 暂不强赎
123071 天能转债 暂不强赎
113027 华钰转债 暂不强赎
128091 新天转债 暂不强赎
128085 鸿达转债 暂不强赎
113620 傲农转债 暂不强赎
123052 飞鹿转债 暂不强赎
118000 嘉元转债 暂不强赎
128082 华锋转债 暂不强赎
128109 楚江转债 暂不强赎
113016 小康转债 暂不强赎
123027 蓝晓转债 暂不强赎
128137 洁美转债 暂不强赎
128101 联创转债 暂不强赎
123031 晶瑞转债 暂不强赎
128078 太极转债 暂不强赎
128030 天康转债 暂不强赎
123034 通光转债 暂不强赎
excel原文件:
http://xximg.30daydo.com/webupload/2022-06-04-redeem-info.xlsx
或者关注公众号:可转债量化分析
后台回复:
强赎20220604 查看全部


代码 名称 当前满足天数 强赎目标数 周期 以公告
113568 新春转债 已公告强赎
127043 川恒转债 暂不强赎
123086 海兰转债 暂不强赎
113548 石英转债 暂不强赎
128107 交科转债 已公告强赎
110071 湖盐转债 12 15 30
128111 中矿转债 暂不强赎
127013 创维转债 14 15 30
123092 天壕转债 暂不强赎
128046 利尔转债 19 20 30
127027 靖远转债 暂不强赎
113541 荣晟转债 公告要强赎
123085 万顺转2 暂不强赎
123083 朗新转债 12 15 30
128128 齐翔转2 暂不强赎
128106 华统转债 暂不强赎
113537 文灿转债 暂不强赎
128095 恩捷转债 已满足强赎条件
127007 湖广转债 暂不强赎
123012 万顺转债 暂不强赎
123057 美联转债 暂不强赎
113585 寿仙转债 暂不强赎
110061 川投转债 暂不强赎
113626 伯特转债 暂不强赎
113025 明泰转债 暂不强赎
123078 飞凯转债 暂不强赎
113567 君禾转债 暂不强赎
128017 金禾转债 暂不强赎
128040 华通转债 暂不强赎
128029 太阳转债 暂不强赎
123073 同和转债 暂不强赎
110055 伊力转债 暂不强赎
113525 台华转债 暂不强赎
123060 苏试转债 暂不强赎
127038 国微转债 暂不强赎
123046 天铁转债 暂不强赎
123098 一品转债 暂不强赎
110074 精达转债 暂不强赎
123114 三角转债 暂不强赎
113051 节能转债 暂不强赎
128140 润建转债 暂不强赎
123071 天能转债 暂不强赎
113027 华钰转债 暂不强赎
128091 新天转债 暂不强赎
128085 鸿达转债 暂不强赎
113620 傲农转债 暂不强赎
123052 飞鹿转债 暂不强赎
118000 嘉元转债 暂不强赎
128082 华锋转债 暂不强赎
128109 楚江转债 暂不强赎
113016 小康转债 暂不强赎
123027 蓝晓转债 暂不强赎
128137 洁美转债 暂不强赎
128101 联创转债 暂不强赎
123031 晶瑞转债 暂不强赎
128078 太极转债 暂不强赎
128030 天康转债 暂不强赎
123034 通光转债 暂不强赎
excel原文件:
http://xximg.30daydo.com/webupload/2022-06-04-redeem-info.xlsx
或者关注公众号:可转债量化分析
后台回复:
强赎20220604
星球文章 获取所有文章 爬虫
python爬虫 • 李魔佛 发表了文章 • 0 个评论 • 1421 次浏览 • 2022-06-03 13:49
群里没有人没有吐槽过这个搜索功能的。
所以只好自己写个程序把自己的文章抓下来,作为文章目录:
生成的markdown文件
每次只需要运行python main.py 就可以拿到最新的星球文章链接了。
需要源码可以在公众号联系~
查看全部

群里没有人没有吐槽过这个搜索功能的。
所以只好自己写个程序把自己的文章抓下来,作为文章目录:


生成的markdown文件

每次只需要运行python main.py 就可以拿到最新的星球文章链接了。
需要源码可以在公众号联系~
网站状态码 514 Frequency Capped
网络 • 李魔佛 发表了文章 • 0 个评论 • 3354 次浏览 • 2022-06-02 00:18
原来问题出云服务器的限速问题上。
如果你在阿里云腾讯云设置了IP访问限频配置,假如设置了10QPS,
那么每秒不能超过10次访问速率。
如果你的网站图片多,很可能你的图片不会被正常加载,你的JS也可能不会被加载进来。
所以你可以把这个值稍微设大一点。
查看全部

网站出现这个报错,是什么原因?
原来问题出云服务器的限速问题上。
如果你在阿里云腾讯云设置了IP访问限频配置,假如设置了10QPS,

那么每秒不能超过10次访问速率。
如果你的网站图片多,很可能你的图片不会被正常加载,你的JS也可能不会被加载进来。
所以你可以把这个值稍微设大一点。
NFT的邀请送藏品 机制
量化交易 • 绫波丽 发表了文章 • 0 个评论 • 995 次浏览 • 2022-05-31 20:16
发现里面就是群加群,互相拉人头,拉够了人头,就会送藏品。
发几张图感受下:
是不是有点传销的感觉?
哈哈。
比如注册下面的二维码:
然后在里面拉10个人,最后送一个未上市的藏品。
等上市后就卖出。 白嫖。
菜鸟入坑,想玩的可以注册白嫖试试,注意不要买,不要买,不要买,这样保证不会亏。
加好友一起研究哈 查看全部
发现里面就是群加群,互相拉人头,拉够了人头,就会送藏品。
发几张图感受下:


是不是有点传销的感觉?
哈哈。
比如注册下面的二维码:

然后在里面拉10个人,最后送一个未上市的藏品。
等上市后就卖出。 白嫖。
菜鸟入坑,想玩的可以注册白嫖试试,注意不要买,不要买,不要买,这样保证不会亏。
加好友一起研究哈
华林证券场内基金免五
券商万一免五 • 绫波丽 发表了文章 • 0 个评论 • 1763 次浏览 • 2022-05-31 12:59
其他完整费率:
股票: 万1免五
ETF/LOF: 万0.6免五,场内基金ETF,LOF免五
可转债:沪市:万0.6免五 深市:万0.6免五
两融:万1,利率6.5%起(可根据资金调整)
期权:2元/张 港股:万2
支持腾讯自选股,海豚股票APP。
需要的朋友可以联系微信扫码开通:
备注;开户 查看全部
其他完整费率:
股票: 万1免五
ETF/LOF: 万0.6免五,场内基金ETF,LOF免五
可转债:沪市:万0.6免五 深市:万0.6免五
两融:万1,利率6.5%起(可根据资金调整)
期权:2元/张 港股:万2
支持腾讯自选股,海豚股票APP。


需要的朋友可以联系微信扫码开通:
备注;开户
百度seo 索引量下降后如何自查
网络 • 马化云 发表了文章 • 0 个评论 • 1222 次浏览 • 2022-05-31 11:59
2、会不会是Robost协议出了问题,导致大批保密页面被百度抓取
3、大幅增加的url会不会占用有限的抓取配额,导致重要优质内容未被抓取
如果是因为百度误判,可以对其进行申诉
关于申诉,除了再一次播报申诉地址(http://ziyuan.baidu.com/feedback)外,我们给各位站长提个醒,在撰写申诉内容时应该尽量将问题描述具体,引用SEO爱好者痞子瑞的经验:“网站索引量异常,可以使用百度搜索资源平台(原百度站长平台)的索引量查询工具,一级一级的遍历一下自己网站的主要子域名或目录,以确定到底是哪个子域名或目录的索引量出现了异常。”“每个频道选取一些页面,在百度网页搜索中直接搜索这样页面的URL,以定位被删除快照网页的最小范围。”“然后在投诉内容中明确给出“病体”的URL,并附上相应的数据变动截图。”这样才便于处理投诉的百度工作人员快速寻找问题症结。 查看全部
2、会不会是Robost协议出了问题,导致大批保密页面被百度抓取
3、大幅增加的url会不会占用有限的抓取配额,导致重要优质内容未被抓取

如果是因为百度误判,可以对其进行申诉
关于申诉,除了再一次播报申诉地址(http://ziyuan.baidu.com/feedback)外,我们给各位站长提个醒,在撰写申诉内容时应该尽量将问题描述具体,引用SEO爱好者痞子瑞的经验:“网站索引量异常,可以使用百度搜索资源平台(原百度站长平台)的索引量查询工具,一级一级的遍历一下自己网站的主要子域名或目录,以确定到底是哪个子域名或目录的索引量出现了异常。”“每个频道选取一些页面,在百度网页搜索中直接搜索这样页面的URL,以定位被删除快照网页的最小范围。”“然后在投诉内容中明确给出“病体”的URL,并附上相应的数据变动截图。”这样才便于处理投诉的百度工作人员快速寻找问题症结。
数字藏品NFT 的常见术语 入门必备
量化交易 • 绫波丽 发表了文章 • 0 个评论 • 1739 次浏览 • 2022-05-31 11:48
你和NFT老藏家的距离就像是“魔法师”和“麻瓜”之间的差距,那么接下来的20个术语,
一、基础平台和应用软件
1. OS:
Opensea的简称,国际NFT交易平台,是目前全球最多用户使用,市场份额占比最高,交易量最大的NFT交易平台。
2. DC
Discord的简称,功能强大的社群通讯软件。目前绝大部分NFT项目的社群聚集地,项目方通常在DC发布重要通道,进社群推广等等。也是目前许多自发NFT社群的根据地。
3. MetaMask (狐狸钱包):
以太坊生态系统中最受欢迎,用户数量最大的NFT钱包。
二、入门级必备术语
1. White List (白名单):
简称WL,也就是NFT项目的白名单。拥有白名单可以在项目公开发售前提前购买NFT,不用和大批人比网速比手速。尤其是在目前大火项目二级市场价格都偏高,而首发作品都处于上架秒空的情况下,白名单可以是“拿到即赚到”。
2. Blue Chips (蓝筹项目):
原指赌场上的蓝色筹码(赌场桌上最基础的筹码组合是1美元的白色筹码、5美元的红色筹码和25美元的蓝色筹码),蓝色筹码为最具有价值的筹码。延伸到蓝筹项目就是指有价值、建议长期持有的优质NFT。
3. Airdrop (空投):
你的钱包会免费收到一个NFT。目前空投被项目方广泛用来激励长期持有者,在国内大多用“转赠”来代替“空投”用法。
4. Mint(铸造) :
翻译成中文,做名词有薄荷的意思,做动词则是铸造。也就是生成NFT的过程,某一个NFT项目的首次铸造。
5. Gas Fee (燃料费):
燃料费, 也可理解成手续费。从技术层面来说,区块链的每一个节点都是需要维护的,而在以太坊中的每笔交易都需要“矿工们”帮你完成,而你则要支付一定的报酬给矿工们。在海外你需要使用eth等虚拟货币进行支付,而在国内则支持RMB支付。因而Gas Fee 也称作“矿工费”。
6. DAO
Decentralized Autonomous Organization的首字母缩写,也就是“去中心化自治组织”。目前多数NFT项目方都会有自己的DAO, 当你持有该项目的NFT时你就有资质成为DAO成员,DAO群成员拥有对该项目未来发展整体方向的治理权。通过DAO,项目方可以凝聚社群,从而提升项目的发展长驱动力。
7. Roadmap(路线图):
路线图,专门指某个NFT项目计划为社群增加价值而进行的一系列活动。路线图目前已经成为许多藏家入手新项目之前必须考察的一点,一个NFT项目是否拥有路线图在一定程度上决定了该项目的规划能力以及运营能力。
8. Floor Price (地板价):
地板价,指某一NFT项目在交易市场中的最低入手价格,Floor Price的价格越高,代表该NFT项目的整体价格走向明朗。抄底也是指在该项目处于Floor Price的时候大量购入,等待其后续的爆发时机。
三、进阶级术语
1. 10k project
指由约10000个头像组成的NFT项目,10k project 以Bored Ape Yacht Club 以及 Croptofunks 为代表。但值得注意的是,这里的10k并不是固定的,该术语仅指代这一类型的头像合集,并未规定10k 的具体数量。
2. PFP
PFP在不同的行业有着不同的含义,在NFT界的PFP特指[Profile Picture],也就是“个人资料图片”。不少10 projet 都是PFP项目,比如库里购入了Cryptofunk,并将它用作自己社交媒体的头像。目前,PFP仍然广收藏家的欢迎,拥有一个价值极高的NFT,可以彰显自己的财力和投资眼光。
3. FOMO:
Fear of Missing Out的首字母缩写——错失恐惧症,意思是害怕错过的情绪。类似于担心抢不到心仪的商品或怕比别人手慢而盲目跟风下单看到什么买什么。(这里建议大家理智购买藏品,不要过分FOMO)
4. Cope:
跟 FOMO 相反的意思,意识是后悔做了某事。比如因为之前没有在地板价的时候购入,目前价格一路飙升非常的Cope。又比如之前FOMO过头,买了太多现在积仓过多,非常后悔。
5. Apeing (into something):
这里的Apein和任何Ape项目都无关。是指,出于FOMO情绪,大量投入超出自己经济承受能力的资金,也指没有对NFT项目进行一个调研和了解就盲目进行投资。
6. Rug:
Rug pull 的缩写,原意为拉地毯,在NFT行业中延伸指:在项目方或者平台卷款潜逃事件。具体指:NFT项目的创建者争取到投资,然后突然放弃项目,骗取项目投资者的资金。比如Frosties项目创始人因Rug pull就被美国司法部指控欺诈和洗钱。
7.1:1 Art:
意思是指每件作品都是独一无二的(1 of 1),10k project中多数都是1:1 ART,这也是PFP项目容易受到市场追捧的一个原因。
8.McDonald's:
字面意思: 麦当劳。当有人在Discord中说 McDonald's则意味着没钱了,吃土,去搬砖的意思。国内社群更多用美团来代替。 查看全部
你和NFT老藏家的距离就像是“魔法师”和“麻瓜”之间的差距,那么接下来的20个术语,
一、基础平台和应用软件
1. OS:
Opensea的简称,国际NFT交易平台,是目前全球最多用户使用,市场份额占比最高,交易量最大的NFT交易平台。
2. DC
Discord的简称,功能强大的社群通讯软件。目前绝大部分NFT项目的社群聚集地,项目方通常在DC发布重要通道,进社群推广等等。也是目前许多自发NFT社群的根据地。
3. MetaMask (狐狸钱包):
以太坊生态系统中最受欢迎,用户数量最大的NFT钱包。
二、入门级必备术语
1. White List (白名单):
简称WL,也就是NFT项目的白名单。拥有白名单可以在项目公开发售前提前购买NFT,不用和大批人比网速比手速。尤其是在目前大火项目二级市场价格都偏高,而首发作品都处于上架秒空的情况下,白名单可以是“拿到即赚到”。
2. Blue Chips (蓝筹项目):
原指赌场上的蓝色筹码(赌场桌上最基础的筹码组合是1美元的白色筹码、5美元的红色筹码和25美元的蓝色筹码),蓝色筹码为最具有价值的筹码。延伸到蓝筹项目就是指有价值、建议长期持有的优质NFT。
3. Airdrop (空投):
你的钱包会免费收到一个NFT。目前空投被项目方广泛用来激励长期持有者,在国内大多用“转赠”来代替“空投”用法。
4. Mint(铸造) :
翻译成中文,做名词有薄荷的意思,做动词则是铸造。也就是生成NFT的过程,某一个NFT项目的首次铸造。
5. Gas Fee (燃料费):
燃料费, 也可理解成手续费。从技术层面来说,区块链的每一个节点都是需要维护的,而在以太坊中的每笔交易都需要“矿工们”帮你完成,而你则要支付一定的报酬给矿工们。在海外你需要使用eth等虚拟货币进行支付,而在国内则支持RMB支付。因而Gas Fee 也称作“矿工费”。
6. DAO
Decentralized Autonomous Organization的首字母缩写,也就是“去中心化自治组织”。目前多数NFT项目方都会有自己的DAO, 当你持有该项目的NFT时你就有资质成为DAO成员,DAO群成员拥有对该项目未来发展整体方向的治理权。通过DAO,项目方可以凝聚社群,从而提升项目的发展长驱动力。
7. Roadmap(路线图):
路线图,专门指某个NFT项目计划为社群增加价值而进行的一系列活动。路线图目前已经成为许多藏家入手新项目之前必须考察的一点,一个NFT项目是否拥有路线图在一定程度上决定了该项目的规划能力以及运营能力。
8. Floor Price (地板价):
地板价,指某一NFT项目在交易市场中的最低入手价格,Floor Price的价格越高,代表该NFT项目的整体价格走向明朗。抄底也是指在该项目处于Floor Price的时候大量购入,等待其后续的爆发时机。
三、进阶级术语
1. 10k project
指由约10000个头像组成的NFT项目,10k project 以Bored Ape Yacht Club 以及 Croptofunks 为代表。但值得注意的是,这里的10k并不是固定的,该术语仅指代这一类型的头像合集,并未规定10k 的具体数量。
2. PFP
PFP在不同的行业有着不同的含义,在NFT界的PFP特指[Profile Picture],也就是“个人资料图片”。不少10 projet 都是PFP项目,比如库里购入了Cryptofunk,并将它用作自己社交媒体的头像。目前,PFP仍然广收藏家的欢迎,拥有一个价值极高的NFT,可以彰显自己的财力和投资眼光。
3. FOMO:
Fear of Missing Out的首字母缩写——错失恐惧症,意思是害怕错过的情绪。类似于担心抢不到心仪的商品或怕比别人手慢而盲目跟风下单看到什么买什么。(这里建议大家理智购买藏品,不要过分FOMO)
4. Cope:
跟 FOMO 相反的意思,意识是后悔做了某事。比如因为之前没有在地板价的时候购入,目前价格一路飙升非常的Cope。又比如之前FOMO过头,买了太多现在积仓过多,非常后悔。
5. Apeing (into something):
这里的Apein和任何Ape项目都无关。是指,出于FOMO情绪,大量投入超出自己经济承受能力的资金,也指没有对NFT项目进行一个调研和了解就盲目进行投资。
6. Rug:
Rug pull 的缩写,原意为拉地毯,在NFT行业中延伸指:在项目方或者平台卷款潜逃事件。具体指:NFT项目的创建者争取到投资,然后突然放弃项目,骗取项目投资者的资金。比如Frosties项目创始人因Rug pull就被美国司法部指控欺诈和洗钱。
7.1:1 Art:
意思是指每件作品都是独一无二的(1 of 1),10k project中多数都是1:1 ART,这也是PFP项目容易受到市场追捧的一个原因。
8.McDonald's:
字面意思: 麦当劳。当有人在Discord中说 McDonald's则意味着没钱了,吃土,去搬砖的意思。国内社群更多用美团来代替。
ubuntu下最好的图形git管理工具kranken (免费版本)
Linux • 李魔佛 发表了文章 • 0 个评论 • 3516 次浏览 • 2022-05-30 19:06
不过最新的版本已经要收费了。
但是如果你用回以前的旧版本,还是可以依然免费的。[url]https://release.axocdn.com/lin ... 1.deb[/url]
[url]https://release.axocdn.com/lin ... 1.rpm[/url]
[url]https://release.axocdn.com/lin ... ar.gz[/url]
[url]https://release.axocdn.com/win ... 1.exe[/url]
如果上面链接下载不了,可以换一个源。我在本地ip下似乎下不了,跑到腾讯云上的云服务器 就可以正常下载。
反正多试几次就可以。
不要点击安装,不然出错了,也不知道是什么问题。
使用命令行安装:sudo dpkg -i gitkraken-amd64.deb
如果报错,依赖出错,那么可以这样操作:sudo apt --fix-broken install
搞定 查看全部

不过最新的版本已经要收费了。
但是如果你用回以前的旧版本,还是可以依然免费的。
[url]https://release.axocdn.com/lin ... 1.deb[/url]
[url]https://release.axocdn.com/lin ... 1.rpm[/url]
[url]https://release.axocdn.com/lin ... ar.gz[/url]
[url]https://release.axocdn.com/win ... 1.exe[/url]
如果上面链接下载不了,可以换一个源。我在本地ip下似乎下不了,跑到腾讯云上的云服务器 就可以正常下载。
反正多试几次就可以。
不要点击安装,不然出错了,也不知道是什么问题。
使用命令行安装:
sudo dpkg -i gitkraken-amd64.deb
如果报错,依赖出错,那么可以这样操作:
sudo apt --fix-broken install
搞定
忠告:千万不要在集思录开银河证券(中关村营业部) 有图为证
券商万一免五 • 绫波丽 发表了文章 • 0 个评论 • 2661 次浏览 • 2022-05-30 15:47
就是这样的帖子,真TM害人。 直接扫描开户后,后面连经理都找不到,打电话,一直忙音,我的天。
上面是家人的中关村营业部的账户(并非随意喷这个垃圾营业部的,是确实开到这个营业部的)。
这个账户是很久前开的(大概3年前吧,疫情刚开始的时候),当时银河证券在集思录的页面是上宣传的是万一免五开户。所以当时也没有留意就开了。
开了之后由于一直做的基金套利和可转债交易。 股票没有交易过。
然后今天居然银行板块非常低估,所以打算入点银行股,定投计划。
结果上周买了一点苏州银行。
今天开交割单。
股票的费率是万3
现在都什么年代了,居然股票还能开出万3的费率。这个不确定他们是不是在背地里暗自把我这个账户的费率提高上去了。
然后打电话过去他们的营业部:
全程就一个字,拽。(当然手机也有自动录音)
我们营业部都是服务百万级别的大户,你爱用不用,现在北京疫情办事不方便,现在也没有免五,调不了免五了。
销户的话随意啦。
巴拉巴拉。
听完后,第二天就把账户清理了,预约了销户。
然后找了另外一个朋友,轻松开了费率万一免五的银河。
狗日的中关村银河。886
查看全部

就是这样的帖子,真TM害人。 直接扫描开户后,后面连经理都找不到,打电话,一直忙音,我的天。

上面是家人的中关村营业部的账户(并非随意喷这个垃圾营业部的,是确实开到这个营业部的)。
这个账户是很久前开的(大概3年前吧,疫情刚开始的时候),当时银河证券在集思录的页面是上宣传的是万一免五开户。所以当时也没有留意就开了。
开了之后由于一直做的基金套利和可转债交易。 股票没有交易过。
然后今天居然银行板块非常低估,所以打算入点银行股,定投计划。
结果上周买了一点苏州银行。
今天开交割单。

股票的费率是万3
现在都什么年代了,居然股票还能开出万3的费率。这个不确定他们是不是在背地里暗自把我这个账户的费率提高上去了。
然后打电话过去他们的营业部:

全程就一个字,拽。(当然手机也有自动录音)
我们营业部都是服务百万级别的大户,你爱用不用,现在北京疫情办事不方便,现在也没有免五,调不了免五了。
销户的话随意啦。
巴拉巴拉。
听完后,第二天就把账户清理了,预约了销户。
然后找了另外一个朋友,轻松开了费率万一免五的银河。
狗日的中关村银河。886
python seo 小工具 查询百度权重,备案信息
python • 李魔佛 发表了文章 • 0 个评论 • 1099 次浏览 • 2022-05-28 14:29
还有百度的收录情况:
对于经常操作的朋友,需要使用程序查询,还可以批量查询,并保存到excel或者数据库。
上图为入库到mongodb的数据
源码实现:
main.py 入口函数:from baidu_collection import baidu_site_collect
from seo_info import crawl_info
from configure.settings import DBSelector
import datetime
import argparse
client = DBSelector().mongo('qq')
doc = client['db_parker']['seo']
def main():
parser = argparse.ArgumentParser()
'''
Command line options
'''
parser.add_argument(
'-n',
'--name', type=str,
help='input web domain'
)
parser.add_argument(
'-f',
'--file', type=str,
help='input web site domain file name'
)
FLAGS = parser.parse_args()
site_list=
if FLAGS.name:
print(FLAGS.name)
if '.' in FLAGS.name:
site_list.append(FLAGS.name)
elif FLAGS.file:
print(FLAGS.file)
with open(FLAGS.file,'r') as fp:
webs=fp.readlines()
site_list.extend(list(map(lambda x:x.strip(),webs)))
if site_list:
run(site_list=site_list)
else:
print("please input correct web domain")
def run(site_list):
# TODO: 改为命令行形式
for site in site_list:
count = baidu_site_collect(site)
info = crawl_info(site)
print(info)
print(count)
info['site'] = site
info['baidu_count'] = count
info['update_time'] = datetime.datetime.now()
doc.insert_one(info)
if __name__ == '__main__':
main()
其他具体实现的文件:
baidu_collection.py from parsel import Selector
import requests
def baidu_site_collect(site):
# 百度收录
headers = {'User-Agent': 'Chrome Google FireFox IE'}
url = 'https://www.baidu.com/s?wd=site:{}&rsv_spt=1&rsv_iqid=0xf8b7b7e50006c034&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=0&rsv_dl=ib&rsv_sug3=14&rsv_sug1=7&rsv_sug7=100&rsv_n=2&rsv_btype=i&inputT=8238&rsv_sug4=8238'.format(site)
resp = requests.get(
url=url,
headers=headers
)
resp.encoding='utf8'
html = resp.text
selector = Selector(text=html)
count = selector.xpath('//div[@class="op_site_domain c-row"]/div/p/span/b/text()').extract_first()
if count:
count=int(count.replace(',',''))
return count
if __name__=='__main__':
site='30daydo.com'
print(baidu_site_collect(site))
seo_info.pyimport argparse
from atexit import register
import sys
import requests
import re
from parsel import Selector
#参数自定义
# parser = argparse.ArgumentParser()
# parser.add_argument('-r', dest='read', help='path file')
# parser.add_argument('-u',dest='read',help='targetdomain')
# parser_args = parser.parse_args()
#爬虫模块查询
VERBOSE = True
def askurl(target_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
#baidu权重
baidu_url=f"https://rank.chinaz.com/{target_url}"
baidu_txt=requests.get(url=baidu_url,headers=headers)
baidu_html=baidu_txt.content.decode('utf-8')
baidu_PC=re.findall('PC端</i><img src="//csstools.chinaz.com/tools/images/rankicons/baidu(.*?).png"></a></li>',baidu_html,re.S)
baidu_moblie=re.findall('移动端</i><img src="//csstools.chinaz.com/tools/images/rankicons/bd(.*?).png"></a></li>',baidu_html,re.S)
#分割线
print("*"*60)
#如果查询html中有正则出来到权重关键字就输出,否则将不输出
result={}
baidu_pc_weight = None
baidu_mobile_weight = None
if len(baidu_PC) > 0:
print('百度_PC:', baidu_PC[0])
baidu_pc_weight=baidu_PC[0]
if len(baidu_moblie) > 0:
print('百度_moblie:', baidu_moblie[0])
baidu_mobile_weight = baidu_moblie[0]
else:
print("百度无权重")
result['baidu_pc_weight']=baidu_pc_weight
result['baidu_mobile_weight']=baidu_mobile_weight
#360权重
url=f"https://rank.chinaz.com/sorank/{target_url}/"
text = requests.get(url=url,headers=headers)
html=text.content.decode('utf-8')
sorank360_PC=re.findall('PC端</i><img src="//csstools.chinaz.com/tools/images/rankicons/360(.*?).png"></a><',html,re.S)
sorank360_Mobile=re.findall('移动端</i><img src="//csstools.chinaz.com/tools/images/rankicons/360(.*?).png"',html,re.S)
_360_pc_weight=None
_360_mobile_weight=None
# 如果查询html中有正则出来到权重关键字就输出,否则将不输出
if len(sorank360_PC) > 0:
_360_pc_weight=sorank360_PC[0]
print("360_PC:", sorank360_PC[0])
if len(sorank360_Mobile) > 0:
_360_mobile_weight=sorank360_Mobile[0]
print("360_moblie:", sorank360_Mobile[0])
else:
print("360无权重")
result['360_pc_weight']=_360_pc_weight
result['360_mobile_weight']=_360_mobile_weight
#搜狗权重
sogou_pc_weight=None
sogou_mobile_weight=None
sogou_url = f"https://rank.chinaz.com/sogoupc/{target_url}"
sougou_txt = requests.get(url=sogou_url, headers=headers)
sougou_html = sougou_txt.content.decode('utf-8')
sougou_PC = re.findall('PC端</i><img src="//csstools.chinaz.com/tools/images/rankicons/sogou(.*?).png"></a></li>',sougou_html, re.S)
sougou_mobile = re.findall('移动端</i><img src="//csstools.chinaz.com/tools/images/rankicons/sogou(.*?).png"></a></li>',sougou_html, re.S)
# 如果查询html中有正则出来到权重关键字就输出,否则将不输出
if len(sougou_PC) > 0:
print('搜狗_PC:', sougou_PC[1])
sogou_pc_weight=sougou_PC[1]
if len(sougou_mobile) > 0 :
print('搜狗_moblie:', sougou_mobile[1])
sogou_mobile_weight=sougou_mobile[1]
else:
print('搜狗无权重')
result['sogou_pc_weight']=sogou_pc_weight
result['sogou_mobile_weight']=sogou_mobile_weight
#神马权重
shenma_pc_weight =None
shenma_url=f'https://rank.chinaz.com/smrank/{target_url}'
shenma_txt=requests.get(url=shenma_url,headers=headers)
shenma_html=shenma_txt.content.decode('utf-8')
shenma_PC=re.findall('class="tc mt5"><img src="//csstools.chinaz.com/tools/images/rankicons/shenma(.*?).png"></a></li>',shenma_html,re.S)
# 如果查询html中有正则出来到权重关键字就输出,否则将不输出
if len(shenma_PC) > 0:
print('神马权重为:', shenma_PC[1])
shenma_pc_weight=shenma_PC[1]
else:
print("神马无权重")
result['shenma_pc_weight']=shenma_pc_weight
# result['shenma_mobile_weight']=None
#头条权重
toutiao_pc_weight=None
toutiao_url=f'https://rank.chinaz.com/toutiao/{target_url}'
toutiao_txt=requests.get(url=toutiao_url,headers=headers)
toutiao_html=toutiao_txt.content.decode('utf-8')
toutiao_PC=re.findall('class="tc mt5"><img src="//csstools.chinaz.com/tools/images/rankicons/toutiao(.*?).png"></a></li>',toutiao_html,re.S)
# 如果查询html中有正则出来到权重关键字就输出,否则将不输出
if len(toutiao_PC) > 0:
print('头条权重为:', toutiao_PC[1])
toutiao_pc_weight=toutiao_PC[1]
else:
print("头条无权重")
result['toutiao_pc_weight']=toutiao_pc_weight
# result['toutiao_mobile_weight']=None
#备案信息、title、企业性质
beian_url=f"https://seo.chinaz.com/{target_url}"
beian_txt=requests.get(url=beian_url,headers=headers)
beian_html=beian_txt.content.decode('utf-8')
with open('beian_html.html','w') as fp:
fp.write(beian_html)
title,beian_no,name,ip,nature,register,years=parse_info(beian_html)
result['name']=name
result['title']=title
result['beian_no']=beian_no
result['ip']=ip
result['nature']=nature
result['register']=register
result['years']=years
try:
print("备案信息:",beian_no,"名称:",name,"网站首页Title:",title,"企业性质:",nature,"IP地址为:",ip)
print("*"*60)
except:
print("没有查询到有效信息!")
return result
strip_fun = lambda x:x.strip() if x is not None else ""
def parse_info(html):
resp = Selector(text=html)
title = strip_fun(resp.xpath('//div[@class="_chinaz-seo-t2l ellipsis"]/text()').extract_first())
table = resp.xpath('//table[@class="_chinaz-seo-newt"]/tbody')
if table[0].xpath('.//tr[4]/td[2]/span[1]/i'):
beian_num=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[1]/i/a/text()').extract_first())
else:
beian_num=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[1]/a/text()').extract_first())
name=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[2]/i/text()').extract_first())
if not name:
print('---->',name)
name=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[2]/i/a/text()').extract_first())
nature=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[3]/i/text()').extract_first())
ip=strip_fun(table[0].xpath('.//tr[5]/td[2]/div/span[1]/i/a/text()').extract_first())
register=strip_fun(table[0].xpath('.//tr[3]/td[2]/div[1]/span[1]/i/text()').extract_first())
years=strip_fun(table[0].xpath('.//tr[3]/td[2]/div[2]/span[1]/i/text()').extract_first())
return title,beian_num,name,ip,nature,register,years
def crawl_info(site):
return askurl(site)
if __name__ == '__main__':
main()
运行效果:
需要完整代码,可关注公众号联系: 查看全部

还有百度的收录情况:

对于经常操作的朋友,需要使用程序查询,还可以批量查询,并保存到excel或者数据库。

上图为入库到mongodb的数据
源码实现:
main.py 入口函数:
from baidu_collection import baidu_site_collect
from seo_info import crawl_info
from configure.settings import DBSelector
import datetime
import argparse
client = DBSelector().mongo('qq')
doc = client['db_parker']['seo']
def main():
parser = argparse.ArgumentParser()
'''
Command line options
'''
parser.add_argument(
'-n',
'--name', type=str,
help='input web domain'
)
parser.add_argument(
'-f',
'--file', type=str,
help='input web site domain file name'
)
FLAGS = parser.parse_args()
site_list=
if FLAGS.name:
print(FLAGS.name)
if '.' in FLAGS.name:
site_list.append(FLAGS.name)
elif FLAGS.file:
print(FLAGS.file)
with open(FLAGS.file,'r') as fp:
webs=fp.readlines()
site_list.extend(list(map(lambda x:x.strip(),webs)))
if site_list:
run(site_list=site_list)
else:
print("please input correct web domain")
def run(site_list):
# TODO: 改为命令行形式
for site in site_list:
count = baidu_site_collect(site)
info = crawl_info(site)
print(info)
print(count)
info['site'] = site
info['baidu_count'] = count
info['update_time'] = datetime.datetime.now()
doc.insert_one(info)
if __name__ == '__main__':
main()
其他具体实现的文件:
baidu_collection.py
from parsel import Selector
import requests
def baidu_site_collect(site):
# 百度收录
headers = {'User-Agent': 'Chrome Google FireFox IE'}
url = 'https://www.baidu.com/s?wd=site:{}&rsv_spt=1&rsv_iqid=0xf8b7b7e50006c034&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=0&rsv_dl=ib&rsv_sug3=14&rsv_sug1=7&rsv_sug7=100&rsv_n=2&rsv_btype=i&inputT=8238&rsv_sug4=8238'.format(site)
resp = requests.get(
url=url,
headers=headers
)
resp.encoding='utf8'
html = resp.text
selector = Selector(text=html)
count = selector.xpath('//div[@class="op_site_domain c-row"]/div/p/span/b/text()').extract_first()
if count:
count=int(count.replace(',',''))
return count
if __name__=='__main__':
site='30daydo.com'
print(baidu_site_collect(site))
seo_info.py
import argparse
from atexit import register
import sys
import requests
import re
from parsel import Selector
#参数自定义
# parser = argparse.ArgumentParser()
# parser.add_argument('-r', dest='read', help='path file')
# parser.add_argument('-u',dest='read',help='targetdomain')
# parser_args = parser.parse_args()
#爬虫模块查询
VERBOSE = True
def askurl(target_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
#baidu权重
baidu_url=f"https://rank.chinaz.com/{target_url}"
baidu_txt=requests.get(url=baidu_url,headers=headers)
baidu_html=baidu_txt.content.decode('utf-8')
baidu_PC=re.findall('PC端</i><img src="//csstools.chinaz.com/tools/images/rankicons/baidu(.*?).png"></a></li>',baidu_html,re.S)
baidu_moblie=re.findall('移动端</i><img src="//csstools.chinaz.com/tools/images/rankicons/bd(.*?).png"></a></li>',baidu_html,re.S)
#分割线
print("*"*60)
#如果查询html中有正则出来到权重关键字就输出,否则将不输出
result={}
baidu_pc_weight = None
baidu_mobile_weight = None
if len(baidu_PC) > 0:
print('百度_PC:', baidu_PC[0])
baidu_pc_weight=baidu_PC[0]
if len(baidu_moblie) > 0:
print('百度_moblie:', baidu_moblie[0])
baidu_mobile_weight = baidu_moblie[0]
else:
print("百度无权重")
result['baidu_pc_weight']=baidu_pc_weight
result['baidu_mobile_weight']=baidu_mobile_weight
#360权重
url=f"https://rank.chinaz.com/sorank/{target_url}/"
text = requests.get(url=url,headers=headers)
html=text.content.decode('utf-8')
sorank360_PC=re.findall('PC端</i><img src="//csstools.chinaz.com/tools/images/rankicons/360(.*?).png"></a><',html,re.S)
sorank360_Mobile=re.findall('移动端</i><img src="//csstools.chinaz.com/tools/images/rankicons/360(.*?).png"',html,re.S)
_360_pc_weight=None
_360_mobile_weight=None
# 如果查询html中有正则出来到权重关键字就输出,否则将不输出
if len(sorank360_PC) > 0:
_360_pc_weight=sorank360_PC[0]
print("360_PC:", sorank360_PC[0])
if len(sorank360_Mobile) > 0:
_360_mobile_weight=sorank360_Mobile[0]
print("360_moblie:", sorank360_Mobile[0])
else:
print("360无权重")
result['360_pc_weight']=_360_pc_weight
result['360_mobile_weight']=_360_mobile_weight
#搜狗权重
sogou_pc_weight=None
sogou_mobile_weight=None
sogou_url = f"https://rank.chinaz.com/sogoupc/{target_url}"
sougou_txt = requests.get(url=sogou_url, headers=headers)
sougou_html = sougou_txt.content.decode('utf-8')
sougou_PC = re.findall('PC端</i><img src="//csstools.chinaz.com/tools/images/rankicons/sogou(.*?).png"></a></li>',sougou_html, re.S)
sougou_mobile = re.findall('移动端</i><img src="//csstools.chinaz.com/tools/images/rankicons/sogou(.*?).png"></a></li>',sougou_html, re.S)
# 如果查询html中有正则出来到权重关键字就输出,否则将不输出
if len(sougou_PC) > 0:
print('搜狗_PC:', sougou_PC[1])
sogou_pc_weight=sougou_PC[1]
if len(sougou_mobile) > 0 :
print('搜狗_moblie:', sougou_mobile[1])
sogou_mobile_weight=sougou_mobile[1]
else:
print('搜狗无权重')
result['sogou_pc_weight']=sogou_pc_weight
result['sogou_mobile_weight']=sogou_mobile_weight
#神马权重
shenma_pc_weight =None
shenma_url=f'https://rank.chinaz.com/smrank/{target_url}'
shenma_txt=requests.get(url=shenma_url,headers=headers)
shenma_html=shenma_txt.content.decode('utf-8')
shenma_PC=re.findall('class="tc mt5"><img src="//csstools.chinaz.com/tools/images/rankicons/shenma(.*?).png"></a></li>',shenma_html,re.S)
# 如果查询html中有正则出来到权重关键字就输出,否则将不输出
if len(shenma_PC) > 0:
print('神马权重为:', shenma_PC[1])
shenma_pc_weight=shenma_PC[1]
else:
print("神马无权重")
result['shenma_pc_weight']=shenma_pc_weight
# result['shenma_mobile_weight']=None
#头条权重
toutiao_pc_weight=None
toutiao_url=f'https://rank.chinaz.com/toutiao/{target_url}'
toutiao_txt=requests.get(url=toutiao_url,headers=headers)
toutiao_html=toutiao_txt.content.decode('utf-8')
toutiao_PC=re.findall('class="tc mt5"><img src="//csstools.chinaz.com/tools/images/rankicons/toutiao(.*?).png"></a></li>',toutiao_html,re.S)
# 如果查询html中有正则出来到权重关键字就输出,否则将不输出
if len(toutiao_PC) > 0:
print('头条权重为:', toutiao_PC[1])
toutiao_pc_weight=toutiao_PC[1]
else:
print("头条无权重")
result['toutiao_pc_weight']=toutiao_pc_weight
# result['toutiao_mobile_weight']=None
#备案信息、title、企业性质
beian_url=f"https://seo.chinaz.com/{target_url}"
beian_txt=requests.get(url=beian_url,headers=headers)
beian_html=beian_txt.content.decode('utf-8')
with open('beian_html.html','w') as fp:
fp.write(beian_html)
title,beian_no,name,ip,nature,register,years=parse_info(beian_html)
result['name']=name
result['title']=title
result['beian_no']=beian_no
result['ip']=ip
result['nature']=nature
result['register']=register
result['years']=years
try:
print("备案信息:",beian_no,"名称:",name,"网站首页Title:",title,"企业性质:",nature,"IP地址为:",ip)
print("*"*60)
except:
print("没有查询到有效信息!")
return result
strip_fun = lambda x:x.strip() if x is not None else ""
def parse_info(html):
resp = Selector(text=html)
title = strip_fun(resp.xpath('//div[@class="_chinaz-seo-t2l ellipsis"]/text()').extract_first())
table = resp.xpath('//table[@class="_chinaz-seo-newt"]/tbody')
if table[0].xpath('.//tr[4]/td[2]/span[1]/i'):
beian_num=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[1]/i/a/text()').extract_first())
else:
beian_num=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[1]/a/text()').extract_first())
name=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[2]/i/text()').extract_first())
if not name:
print('---->',name)
name=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[2]/i/a/text()').extract_first())
nature=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[3]/i/text()').extract_first())
ip=strip_fun(table[0].xpath('.//tr[5]/td[2]/div/span[1]/i/a/text()').extract_first())
register=strip_fun(table[0].xpath('.//tr[3]/td[2]/div[1]/span[1]/i/text()').extract_first())
years=strip_fun(table[0].xpath('.//tr[3]/td[2]/div[2]/span[1]/i/text()').extract_first())
return title,beian_num,name,ip,nature,register,years
def crawl_info(site):
return askurl(site)
if __name__ == '__main__':
main()
运行效果:

需要完整代码,可关注公众号联系:
ubuntu下虚拟机对比virtualbox 和 vmware
Linux • 李魔佛 发表了文章 • 0 个评论 • 2106 次浏览 • 2022-05-28 01:27
virtual box当时选择的是在snap store安装的,不过安装完成之后系统依赖不满足,需要下载系统内核开发库。kernel-headers, kernel-devel. 这个整下来,需要800MB,并且很多系统依赖库可能要被重新安装,因为对应的版本可能对不上。
看到这,想起以前基本每年一次ubuntu重装经历,心有余悸。 思考略1秒,果断关闭,卸载virtual box。选择vmware的怀抱。
vmware的安装包是bundle格式,设置x 可执行权限后,直接安装就可以了。
一路顺畅。
查看全部
virtual box当时选择的是在snap store安装的,不过安装完成之后系统依赖不满足,需要下载系统内核开发库。kernel-headers, kernel-devel. 这个整下来,需要800MB,并且很多系统依赖库可能要被重新安装,因为对应的版本可能对不上。

看到这,想起以前基本每年一次ubuntu重装经历,心有余悸。 思考略1秒,果断关闭,卸载virtual box。选择vmware的怀抱。
vmware的安装包是bundle格式,设置x 可执行权限后,直接安装就可以了。

一路顺畅。
Got recursion not available from 8.8.8.8
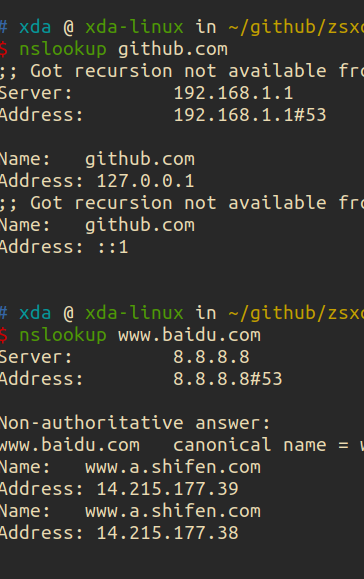
网络 • 李魔佛 发表了文章 • 0 个评论 • 1820 次浏览 • 2022-05-26 12:18
返回的报错:Got recursion not available from 8.8.8.8
返回的github的ip地址还是为127.0.0.1
只能直接修改hosts文件了 查看全部
返回的报错:
Got recursion not available from 8.8.8.8
返回的github的ip地址还是为127.0.0.1
只能直接修改hosts文件了