

量化分析
Ptrade获取历史涨停的股票|python代码
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 2523 次浏览 • 2024-11-01 18:41
下面的程序用于监控可转债的正股,在过去10天里是否出现涨停。
下面的ptrade的代码片段。需要完整代码,可关注公众号私信获取。
def hit_limit_recent():
# 选出最近N天正股有涨停的可转债
N =10
scale = 5
latest_price = 160
bond_name_dict, bond_zg_dict = get_all_bond_info(scale=scale,latest_price=latest_price)
zg_list = list(bond_zg_dict.values())
panel_info = get_history(N, frequency='1d', field=['close','high_limit'], security_list=zg_list, fq='pre', include=False, fill='nan')
df = panel_info.swapaxes("minor_axis", "items")
target_list = []
for code in zg_list:
stock_df = df[code]
hit_high = stock_df[stock_df['close']==stock_df['high_limit']]
if len(hit_high) > 0:
# print(hit_high.index)
target_list.append(code)
zz_target_list = []
for code,zg_code in bond_zg_dict.items():
if zg_code in target_list:
print(code, bond_name_dict[code])
zz_target_list.append(code)
return zz_target_list当然,会有一个情形,就是实际最后是开板状态,但是收盘价格和涨停价格一样。
这种属于涨停开板状态,需要利用tick的委卖买来判断。
查看全部
下面的程序用于监控可转债的正股,在过去10天里是否出现涨停。
下面的ptrade的代码片段。需要完整代码,可关注公众号私信获取。
def hit_limit_recent():当然,会有一个情形,就是实际最后是开板状态,但是收盘价格和涨停价格一样。
# 选出最近N天正股有涨停的可转债
N =10
scale = 5
latest_price = 160
bond_name_dict, bond_zg_dict = get_all_bond_info(scale=scale,latest_price=latest_price)
zg_list = list(bond_zg_dict.values())
panel_info = get_history(N, frequency='1d', field=['close','high_limit'], security_list=zg_list, fq='pre', include=False, fill='nan')
df = panel_info.swapaxes("minor_axis", "items")
target_list = []
for code in zg_list:
stock_df = df[code]
hit_high = stock_df[stock_df['close']==stock_df['high_limit']]
if len(hit_high) > 0:
# print(hit_high.index)
target_list.append(code)
zz_target_list = []
for code,zg_code in bond_zg_dict.items():
if zg_code in target_list:
print(code, bond_name_dict[code])
zz_target_list.append(code)
return zz_target_list
这种属于涨停开板状态,需要利用tick的委卖买来判断。

哪些股票突破了10月8日的最高点?
股票 • 李魔佛 发表了文章 • 0 个评论 • 2868 次浏览 • 2024-10-25 10:28
本文继续贴一下股票从10月8日的最高,到目前的涨跌分布。
数据包含北交所数据。
当前价格相对10月8日高点,涨幅前面的基本是北交所,创业板的股票。天马新材涨幅高达284%,一路涨停板30%,45度角冲上来。
创业板的光智科技8连板,20%一个板,最终今天开板后又封住,录得相对8号高点到目前的涨幅为258%
这些不知名的股票,要么处于亏损状态,要么四五百的市盈率,日后大概率会遵循怎么上去就怎么下来的规律。
比如像下面跌幅榜排名前面的,从高点跌去80%的股票。
长联科技节前最后一天上市,上市当天就吸引了足够的关注,涨了足足17倍。打新中签者,一签浮盈17万。而节后第一天该股冲高回落,依然大涨收盘。
而该股后面就开启了暴跌模式。
跌到今天之后,相对高点跌幅达到81%。
10月8日高点下来的A股个股数据统计
平均跌幅为-8.73%,中位数跌幅为-11%。当天开盘前,散户幻觉认为牛市来了,股票高开后,肯定不能轻易被买到,纷纷挂高价,甚至涨停价。(当时氛围太火爆,当时我也有这种牛市冲冲冲的幻觉)
而截至昨日收盘价,依然有652只股票,突破了10月8日的最高点,相对10日8日的最高点获得了正涨幅,比例为12%,比例比转债的稍微大一些。
A股的股票看起来暴富机会比转债要大的多,但同样会伴随更大的概率,让你一贫如洗,盈亏同源。
查看全部
本文继续贴一下股票从10月8日的最高,到目前的涨跌分布。
数据包含北交所数据。

当前价格相对10月8日高点,涨幅前面的基本是北交所,创业板的股票。天马新材涨幅高达284%,一路涨停板30%,45度角冲上来。

创业板的光智科技8连板,20%一个板,最终今天开板后又封住,录得相对8号高点到目前的涨幅为258%

这些不知名的股票,要么处于亏损状态,要么四五百的市盈率,日后大概率会遵循怎么上去就怎么下来的规律。
比如像下面跌幅榜排名前面的,从高点跌去80%的股票。

长联科技节前最后一天上市,上市当天就吸引了足够的关注,涨了足足17倍。打新中签者,一签浮盈17万。而节后第一天该股冲高回落,依然大涨收盘。
而该股后面就开启了暴跌模式。
跌到今天之后,相对高点跌幅达到81%。

10月8日高点下来的A股个股数据统计

平均跌幅为-8.73%,中位数跌幅为-11%。当天开盘前,散户幻觉认为牛市来了,股票高开后,肯定不能轻易被买到,纷纷挂高价,甚至涨停价。(当时氛围太火爆,当时我也有这种牛市冲冲冲的幻觉)
而截至昨日收盘价,依然有652只股票,突破了10月8日的最高点,相对10日8日的最高点获得了正涨幅,比例为12%,比例比转债的稍微大一些。
A股的股票看起来暴富机会比转债要大的多,但同样会伴随更大的概率,让你一贫如洗,盈亏同源。
可转债现金替代策略 | QMT | Ptrade
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 2426 次浏览 • 2024-10-15 11:05
适合大资金,求稳。
挑选低价格的AAA可转债,比如 正股是 银行,高分红的国企股,比如 大秦铁路的转债,大秦转债等,且到期收益为正。作为标的池。
然后 先 在标的池里挑选出一个价格最低的转债,1/3 仓位 买入,其余仓位买入银华日利。
程序每分钟监控。或者不用那么频繁,可以设置每小时,每天都可以。
如果转债价格下跌了X,就卖出银华日利(1/10仓位),买入转债; (这里仓位随意举例)
如果转债价格上涨了Y,就卖出转债(1/5仓位),买入银华日利;(这里仓位随意举例)
一般AAA的大规模转债,其波动比较小,很少会遇到趋势上涨。 所以大部分的时间是做有波动的高抛低吸。
但,一旦遇到趋势上涨,或者突破,那么按照策略 会不断卖出转债;
一旦转债仓位为0,就可以在标的池买入另外一只标的(1/3仓位),从而继续下一轮的高抛低吸。
如果转债价格一直跌,但由于AAA的转债有保底,且有回售,转股,下修等各种手段,来兜底,
所以一般遇到跌幅行情,下跌不会超过10%,所以策略可以一直在卖出银华日利,买入转债;
如果中途,出现了其他好的标的,你需要手动交易,那么可以手动卖出银华日利或者可转债,腾出仓位,来操作。
也就是这个策略的可转债,纯粹当做现金来替代来使用。
接着就是使用QMT和Ptrade实现。
待续............
查看全部
适合大资金,求稳。
挑选低价格的AAA可转债,比如 正股是 银行,高分红的国企股,比如 大秦铁路的转债,大秦转债等,且到期收益为正。作为标的池。
然后 先 在标的池里挑选出一个价格最低的转债,1/3 仓位 买入,其余仓位买入银华日利。
程序每分钟监控。或者不用那么频繁,可以设置每小时,每天都可以。
如果转债价格下跌了X,就卖出银华日利(1/10仓位),买入转债; (这里仓位随意举例)
如果转债价格上涨了Y,就卖出转债(1/5仓位),买入银华日利;(这里仓位随意举例)
一般AAA的大规模转债,其波动比较小,很少会遇到趋势上涨。 所以大部分的时间是做有波动的高抛低吸。
但,一旦遇到趋势上涨,或者突破,那么按照策略 会不断卖出转债;
一旦转债仓位为0,就可以在标的池买入另外一只标的(1/3仓位),从而继续下一轮的高抛低吸。
如果转债价格一直跌,但由于AAA的转债有保底,且有回售,转股,下修等各种手段,来兜底,
所以一般遇到跌幅行情,下跌不会超过10%,所以策略可以一直在卖出银华日利,买入转债;
如果中途,出现了其他好的标的,你需要手动交易,那么可以手动卖出银华日利或者可转债,腾出仓位,来操作。
也就是这个策略的可转债,纯粹当做现金来替代来使用。
接着就是使用QMT和Ptrade实现。
待续............
python Ptrade获取热门板块,连板股票 python代码
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 6093 次浏览 • 2024-08-23 16:57
Ptrade API文档:https://ptradeapi.com/#get_sort_msg
get_sort_msg – 获取板块、行业的涨幅排名
get_sort_msg(sort_type_grp=None, sort_field_name=None, sort_type=1, data_count=100)
接口说明
该接口用于获取板块、行业的涨幅排名。
参数 sort_type_grp: 板块或行业的代码(list[str]/str);
(暂时只支持XBHS.DY地域、XBHS.GN概念、XBHS.ZJHHY证监会行业、XBHS.ZS指数、XBHS.HY行业等)
示例代码:按概念板块涨幅倒序排名
import datetime
START_TIME = (datetime.datetime.now() + datetime.timedelta(minutes=1)).strftime('%H:%M')
def execution(context):
#获取XBHS.GN的概念排名信息
sort_data = get_sort_msg(sort_type_grp='XBHS.GN', sort_field_name='px_change_rate', sort_type=1, data_count=100)
for data in sort_data:
log.info('板块: {} '.format(data['prod_name']))
for sub_stock in data['rise_first_grp']:
log.info('{} 涨幅 :{}'.format(sub_stock['prod_name'],sub_stock['px_change_rate']))
log.info('\n')
def initialize(context):
# 初始化策略
run_daily(context, execution, time=START_TIME) # 扫描
log.info("公众号:可转债量化分析\n")
def handle_data(context, data):
pass
上面代码在ptrade启动后一分钟拿到结果。不限制要求开盘时间的。其实Ptrade可以在24小时任意时刻启动。
get_sort_msg 返回的数据结构体如下:
具体字段的含义:
prod_code: 行业代码(str:str);
prod_name: 行业名称(str:str);
hq_type_code: 行业板块代码(str:str);
time_stamp: 时间戳毫秒级(str:int);
trade_mins: 交易分钟数(str:int);
trade_status: 交易状态(str:str);
preclose_px: 昨日收盘价(str:float);
open_px: 今日开盘价(str:float);
last_px: 最新价(str:float);
high_px: 最高价(str:float);
low_px: 最低价(str:float);
wavg_px: 加权平均价(str:float);
business_amount: 总成交量(str:int);
business_balance: 总成交额(str:int);
px_change: 涨跌额(str:float);
amplitude: 振幅(str:int);
px_change_rate: 涨跌幅(str:float);
circulation_amount: 流通股本(str:int);
total_shares: 总股本(str:int);
market_value: 市值(str:int);
circulation_value: 流通市值(str:int);
vol_ratio: 量比(str:float);
shares_per_hand: 每手股数(str:int);
rise_count: 上涨家数(str:int);
fall_count: 下跌家数(str:int);
member_count: 成员个数(str:int);
rise_first_grp: 领涨股票(其包含以下五个字段)(str:list[dict{str:int,str:str,str:str,str:float,str:float},...]);
prod_code: 股票代码(str:str);
prod_name: 证券名称(str:str);
hq_type_code: 类型代码(str:str);
last_px: 最新价(str:float);
px_change_rate: 涨跌幅(str:float);
fall_first_grp: 领跌股票(其包含以下五个字段)(str:list[dict{str:int,str:str,str:str,str:float,str:float},...]);
prod_code: 股票代码(str:str);
prod_name: 证券名称(str:str);
hq_type_code: 类型代码(str:str);
last_px: 最新价(str:float);
px_change_rate: 涨跌幅(str:float);
这个返回数据是实时的,可以用来选股,选择热门股,热门板块,涨停板块,昨日涨停,昨日连板板块。
比如上面运行结果里就有 昨日连板的板块个股,有9个,在rise_first_grp 字段里面:
需要开通Ptrade的读者朋友可以后天联系哦,提供不同券商ptrade,低门槛,低费率,还有技术支持群!
查看全部
Ptrade API文档:https://ptradeapi.com/#get_sort_msg
get_sort_msg – 获取板块、行业的涨幅排名
get_sort_msg(sort_type_grp=None, sort_field_name=None, sort_type=1, data_count=100)
接口说明
该接口用于获取板块、行业的涨幅排名。
参数 sort_type_grp: 板块或行业的代码(list[str]/str);
(暂时只支持XBHS.DY地域、XBHS.GN概念、XBHS.ZJHHY证监会行业、XBHS.ZS指数、XBHS.HY行业等)
示例代码:按概念板块涨幅倒序排名
import datetime
START_TIME = (datetime.datetime.now() + datetime.timedelta(minutes=1)).strftime('%H:%M')
def execution(context):
#获取XBHS.GN的概念排名信息
sort_data = get_sort_msg(sort_type_grp='XBHS.GN', sort_field_name='px_change_rate', sort_type=1, data_count=100)
for data in sort_data:
log.info('板块: {} '.format(data['prod_name']))
for sub_stock in data['rise_first_grp']:
log.info('{} 涨幅 :{}'.format(sub_stock['prod_name'],sub_stock['px_change_rate']))
log.info('\n')
def initialize(context):
# 初始化策略
run_daily(context, execution, time=START_TIME) # 扫描
log.info("公众号:可转债量化分析\n")
def handle_data(context, data):
pass
上面代码在ptrade启动后一分钟拿到结果。不限制要求开盘时间的。其实Ptrade可以在24小时任意时刻启动。

get_sort_msg 返回的数据结构体如下:

具体字段的含义:
prod_code: 行业代码(str:str);
prod_name: 行业名称(str:str);
hq_type_code: 行业板块代码(str:str);
time_stamp: 时间戳毫秒级(str:int);
trade_mins: 交易分钟数(str:int);
trade_status: 交易状态(str:str);
preclose_px: 昨日收盘价(str:float);
open_px: 今日开盘价(str:float);
last_px: 最新价(str:float);
high_px: 最高价(str:float);
low_px: 最低价(str:float);
wavg_px: 加权平均价(str:float);
business_amount: 总成交量(str:int);
business_balance: 总成交额(str:int);
px_change: 涨跌额(str:float);
amplitude: 振幅(str:int);
px_change_rate: 涨跌幅(str:float);
circulation_amount: 流通股本(str:int);
total_shares: 总股本(str:int);
market_value: 市值(str:int);
circulation_value: 流通市值(str:int);
vol_ratio: 量比(str:float);
shares_per_hand: 每手股数(str:int);
rise_count: 上涨家数(str:int);
fall_count: 下跌家数(str:int);
member_count: 成员个数(str:int);
rise_first_grp: 领涨股票(其包含以下五个字段)(str:list[dict{str:int,str:str,str:str,str:float,str:float},...]);
prod_code: 股票代码(str:str);
prod_name: 证券名称(str:str);
hq_type_code: 类型代码(str:str);
last_px: 最新价(str:float);
px_change_rate: 涨跌幅(str:float);
fall_first_grp: 领跌股票(其包含以下五个字段)(str:list[dict{str:int,str:str,str:str,str:float,str:float},...]);
prod_code: 股票代码(str:str);
prod_name: 证券名称(str:str);
hq_type_code: 类型代码(str:str);
last_px: 最新价(str:float);
px_change_rate: 涨跌幅(str:float);
这个返回数据是实时的,可以用来选股,选择热门股,热门板块,涨停板块,昨日涨停,昨日连板板块。
比如上面运行结果里就有 昨日连板的板块个股,有9个,在rise_first_grp 字段里面:

需要开通Ptrade的读者朋友可以后天联系哦,提供不同券商ptrade,低门槛,低费率,还有技术支持群!
python量化分析教程 | 最近几年A股养老基金整体盈亏情况分析
股票 • 李魔佛 发表了文章 • 0 个评论 • 2641 次浏览 • 2024-07-25 17:30
不仅是散户被深套,很多基金也都大幅亏损。甚至前阵子看到证券时报报道,养老目标基金都出现不是清盘的现象。
于是笔者好奇心驱使,想看看这些养老基金最近几年的盈利情况,会不会把长辈老人们的下半辈子养老金都亏空了。
作为一名授人以渔的公众号博主,不仅仅贴个收益率图出来这么简单的啦。如果只是想看数据,直接跳过前面的操作即可。
笔者手把手教大家做数据分析,学会后不仅仅只对养老基金这一类别的基金做分析,还可以对不同类型的基金做分析。
前提:电脑按照了python已经相关库(jupyter notebook,pandas,akshare)
数据源:天天基金网
打开东财的天天基金网(https://fund.eastmoney.com/),在基金搜索页面输入:养老
总共有515个与养老相关的公募基金。如果没显示全,点击下图里面的“点击展开更多”按钮
抓包就找到对应的URL地址了,如下:https://fundsuggest.eastmoney.com/FundSearch/api/FundSearchPageAPI.ashx?callback=jQuery18306906210160165065_1721823304653&m=1&key=养老&pageindex=0&pagesize=515&_=1721823360126
如果你想分析其他类型的主题基金,只需要把上面的url里面的key=养老,换成其他的就可以了,比如 key=芯片
浏览器输入上面的URL就可以拿到数据了。
简单起见,我就不写爬取数据的代码,直接复制粘贴浏览器返回的内容就好了。
然后把前面起始的jQuery18306906210160165065_1721823304653( 和最后的括号去掉,就得到一个json数据了。
js_data = {
"ErrCode": 0,
"ErrMsg": "0",
"Datas": [
{
"_id": "001171",
"CODE": "001171",
"NAME": "工银养老产业股票A",
"STOCKMARKET": "",
"NEWTEXCH": ""
},
......... # 省略若干
]
}
(文末提供这个数据文件的获取方式)
接着写一个函数获取某个基金的当前收益率:目前就获取最近3年的收益率。
import akshare as ak
def get_fund_info(code,name):
fund_open_fund_info_em_df = ak.fund_open_fund_info_em(symbol=code, indicator="累计收益率走势",period="3年")
latest_perf = fund_open_fund_info_em_df.iloc[-1]['累计收益率']
return {'code':code,'profit':latest_perf,'name':name}
可以改动period='5年', ’10年‘,’成立以来',从而获取不同区间的收益率
接着把500多个基金遍历一遍就OK了。
fund_perf_list = []
for item in js_data['Datas']:
print('processing code {}'.format(item['CODE']))
try:
fund_perf_list.append(get_fund_info(item['CODE'],item['NAME']))
time.sleep(0.5)
except Exception as e:
print('error in processing code {}'.format(item['CODE']))
print(e)
然后去倒杯茶,慢慢等它跑完。
数据分析
把数据转为dataframe,按照收益率排名
import pandas as pd
df = pd.DataFrame(fund_perf_list)
rank_df = df.sort_values(by='profit')
也可以导出到excel
rank_df.to_excel('亏麻的养老基金.xlsx')
亏损最多的鹏华养老产业股票,最近3年亏损了-53%,不过它应该也不属于养老基金范畴,只是买的养老产业的股票。
而华夏养老2055五年持有混合(FOF)A 011745,这种才是标准的养老基金,这些养老基金大部分是FOF(它们持有标的是基金,而不是股票)
2021年成立,买入后还要锁定5年,期间不可卖出,老人们被套牢了也无法割肉了。成立以来亏损了-34%,近3年亏损了-41%。
于是笔者继续过滤一下,找出里面的全部FOF基金
fof_fund_df = rank_df[rank_df['name'].str.contains('FOF')]
得到下面的养老基金FOF全部数据
然后使用describe函数看看大体的涨跌幅情况:
总共有484个数据,平均涨幅为-8.38%
中位数是-6.13%。
涨幅最大的是4.85%,中欧预见平衡养老三年持有混合发起(FOF)Y
打开详情一看,原来是得益于成立得晚的缘故,而该基金是今年2月成立的。
最近3年沪深300指数跌了32%,而这个跌幅可以在485只养老基金里面排到了477名。聊以慰藉的是,绝大部分的养老基金在下跌行情下是跑赢了沪深300的。
绘制直方图
直方图可以一览数据得养老基金涨跌幅分布情况:
fof_fund_df.plot(kind='hist',bins=20,y='profit',width=2,grid=True)
从图可以看到,大部分养老基金的涨跌幅落在-20到0之间。
亏损达到-30%以上的其实也不是很多。
整体来说,养老基金FOF比买入主流宽基波动要小一些,但并非保本的理财工具,对于风险接受能力低的老一辈朋友,需要慎重考虑的。
原文数据可在公众号:
可转债量化分析
获取
查看全部
不仅是散户被深套,很多基金也都大幅亏损。甚至前阵子看到证券时报报道,养老目标基金都出现不是清盘的现象。

于是笔者好奇心驱使,想看看这些养老基金最近几年的盈利情况,会不会把长辈老人们的下半辈子养老金都亏空了。
作为一名授人以渔的公众号博主,不仅仅贴个收益率图出来这么简单的啦。如果只是想看数据,直接跳过前面的操作即可。
笔者手把手教大家做数据分析,学会后不仅仅只对养老基金这一类别的基金做分析,还可以对不同类型的基金做分析。
前提:电脑按照了python已经相关库(jupyter notebook,pandas,akshare)
数据源:天天基金网
打开东财的天天基金网(https://fund.eastmoney.com/),在基金搜索页面输入:养老

总共有515个与养老相关的公募基金。如果没显示全,点击下图里面的“点击展开更多”按钮

抓包就找到对应的URL地址了,如下:https://fundsuggest.eastmoney.com/FundSearch/api/FundSearchPageAPI.ashx?callback=jQuery18306906210160165065_1721823304653&m=1&key=养老&pageindex=0&pagesize=515&_=1721823360126
如果你想分析其他类型的主题基金,只需要把上面的url里面的key=养老,换成其他的就可以了,比如 key=芯片
浏览器输入上面的URL就可以拿到数据了。

简单起见,我就不写爬取数据的代码,直接复制粘贴浏览器返回的内容就好了。
然后把前面起始的jQuery18306906210160165065_1721823304653( 和最后的括号去掉,就得到一个json数据了。
js_data = {
"ErrCode": 0,
"ErrMsg": "0",
"Datas": [
{
"_id": "001171",
"CODE": "001171",
"NAME": "工银养老产业股票A",
"STOCKMARKET": "",
"NEWTEXCH": ""
},
......... # 省略若干
]
}(文末提供这个数据文件的获取方式)
接着写一个函数获取某个基金的当前收益率:目前就获取最近3年的收益率。
import akshare as ak
def get_fund_info(code,name):
fund_open_fund_info_em_df = ak.fund_open_fund_info_em(symbol=code, indicator="累计收益率走势",period="3年")
latest_perf = fund_open_fund_info_em_df.iloc[-1]['累计收益率']
return {'code':code,'profit':latest_perf,'name':name}
可以改动period='5年', ’10年‘,’成立以来',从而获取不同区间的收益率
接着把500多个基金遍历一遍就OK了。
fund_perf_list = []
for item in js_data['Datas']:
print('processing code {}'.format(item['CODE']))
try:
fund_perf_list.append(get_fund_info(item['CODE'],item['NAME']))
time.sleep(0.5)
except Exception as e:
print('error in processing code {}'.format(item['CODE']))
print(e)

然后去倒杯茶,慢慢等它跑完。

数据分析
把数据转为dataframe,按照收益率排名
import pandas as pd
df = pd.DataFrame(fund_perf_list)
rank_df = df.sort_values(by='profit')

也可以导出到excel
rank_df.to_excel('亏麻的养老基金.xlsx')
亏损最多的鹏华养老产业股票,最近3年亏损了-53%,不过它应该也不属于养老基金范畴,只是买的养老产业的股票。
而华夏养老2055五年持有混合(FOF)A 011745,这种才是标准的养老基金,这些养老基金大部分是FOF(它们持有标的是基金,而不是股票)

2021年成立,买入后还要锁定5年,期间不可卖出,老人们被套牢了也无法割肉了。成立以来亏损了-34%,近3年亏损了-41%。
于是笔者继续过滤一下,找出里面的全部FOF基金
fof_fund_df = rank_df[rank_df['name'].str.contains('FOF')]
得到下面的养老基金FOF全部数据


然后使用describe函数看看大体的涨跌幅情况:

总共有484个数据,平均涨幅为-8.38%
中位数是-6.13%。
涨幅最大的是4.85%,中欧预见平衡养老三年持有混合发起(FOF)Y
打开详情一看,原来是得益于成立得晚的缘故,而该基金是今年2月成立的。

最近3年沪深300指数跌了32%,而这个跌幅可以在485只养老基金里面排到了477名。聊以慰藉的是,绝大部分的养老基金在下跌行情下是跑赢了沪深300的。
绘制直方图
直方图可以一览数据得养老基金涨跌幅分布情况:
fof_fund_df.plot(kind='hist',bins=20,y='profit',width=2,grid=True)

从图可以看到,大部分养老基金的涨跌幅落在-20到0之间。
亏损达到-30%以上的其实也不是很多。
整体来说,养老基金FOF比买入主流宽基波动要小一些,但并非保本的理财工具,对于风险接受能力低的老一辈朋友,需要慎重考虑的。
原文数据可在公众号:
可转债量化分析
获取
python识别股票K线形态,准确率回测(一)
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 1 个评论 • 13531 次浏览 • 2022-05-22 01:13
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)
做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
# pip install akshare
import akshare as ak
def get_k_line(code="sz002241"): #
df = ak.stock_zh_a_daily(symbol=code, start_date="20220101", end_date="20220515",
adjust="qfq")
# 这个函数只适合取股票数据,转债会报错,转债的日线数据可以使用其他函数,这里选择股价前复权
df.to_excel("同和药业k.xlsx")
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
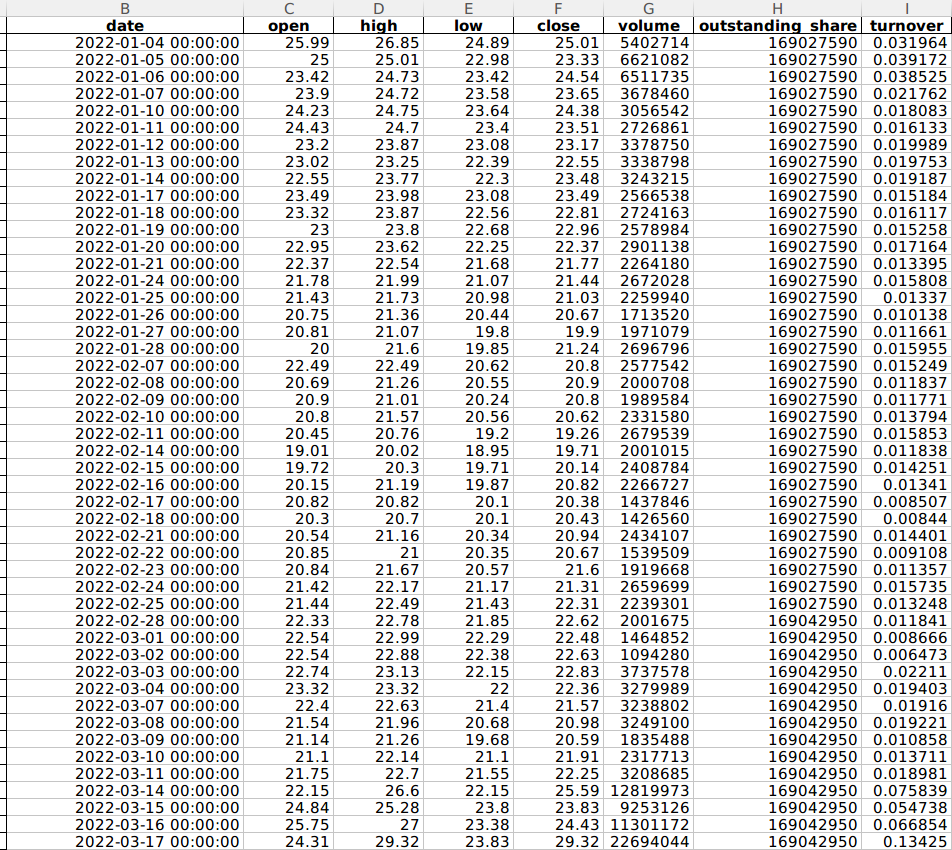
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
date:交易日期
open:代表开盘价
high:当天最高价
low:当天最低价
close:当天收盘价
volume:当天成交量(元)
outstanding_share:流动股本(股)
turnover:换手率
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
#显示出来
plt.show()
运行此段代码后,会显示如下效果图:
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
import matplotlib.ticker as ticker
#将股票时间转换为标准时间,不带时分秒的数据
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.strptime(date, '%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
ax.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线
根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。
那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
def long_up_shadow(o,c,h,l):
return True if (h-c)/c >=0.07 and (h-o)/o>=0.07 else False
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
df = pd.read_excel("同和药业k.xlsx")
count_num = []
for row,item in df.iterrows():
if long_up_shadow(item['open'],item['close'],item['high'],item['low']):
count_num.append(row)
plot_image(df,count_num)
图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。
截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
df['tow_crows'] = talib.CDL2CROWS(df['open'].values, df['high'].values, df['low'].values, df['close'].values)
pattern = df[(df['tow_crows'] == 100) | (df['tow_crows'] == -100)]
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续) 查看全部
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)

做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
# pip install akshare
import akshare as ak
def get_k_line(code="sz002241"): #
df = ak.stock_zh_a_daily(symbol=code, start_date="20220101", end_date="20220515",
adjust="qfq")
# 这个函数只适合取股票数据,转债会报错,转债的日线数据可以使用其他函数,这里选择股价前复权
df.to_excel("同和药业k.xlsx")
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
date:交易日期
open:代表开盘价
high:当天最高价
low:当天最低价
close:当天收盘价
volume:当天成交量(元)
outstanding_share:流动股本(股)
turnover:换手率
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
#显示出来
plt.show()
运行此段代码后,会显示如下效果图:
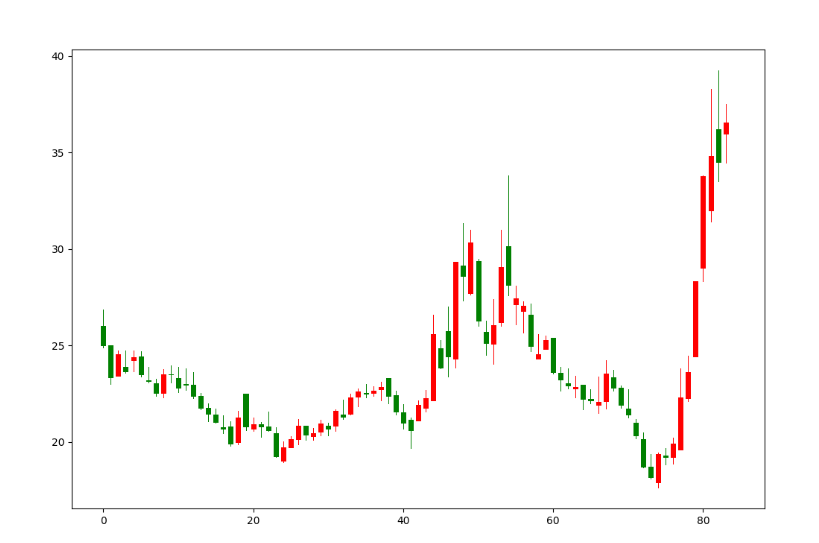
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
import matplotlib.ticker as ticker
#将股票时间转换为标准时间,不带时分秒的数据
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.strptime(date, '%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
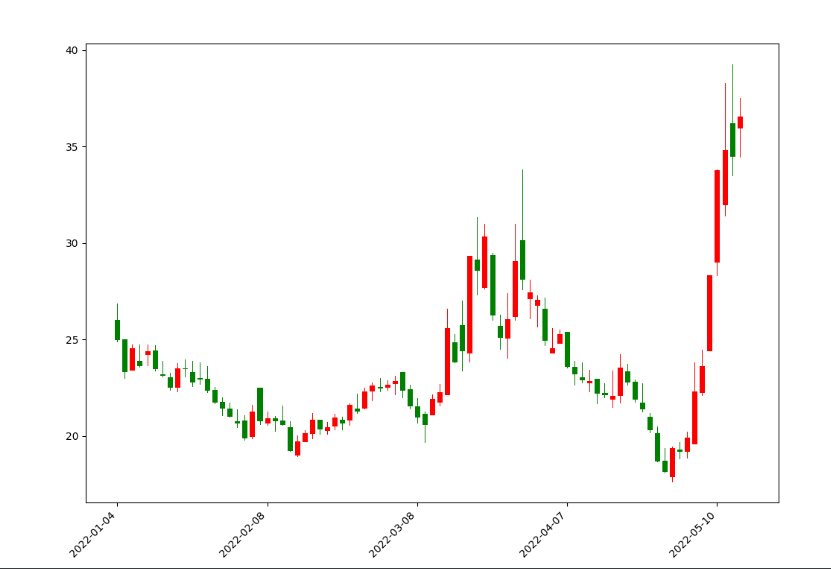
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
ax.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
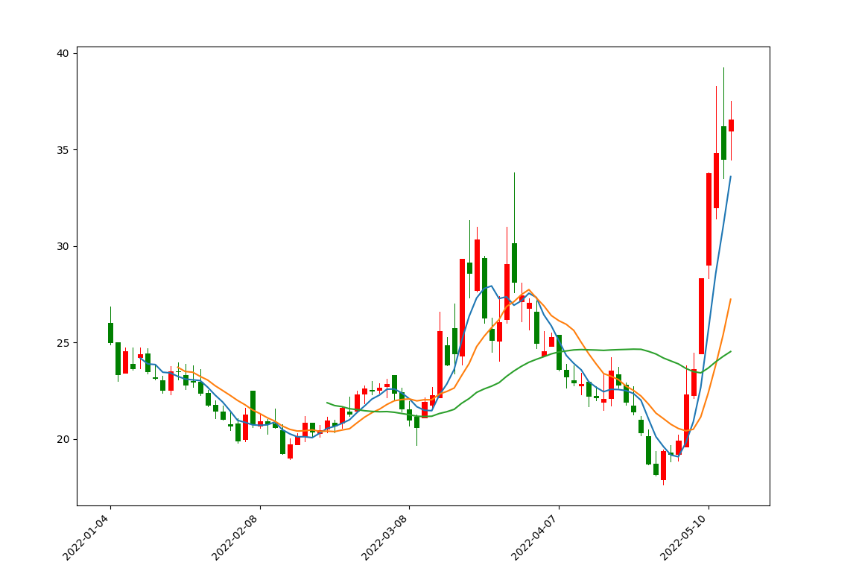
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
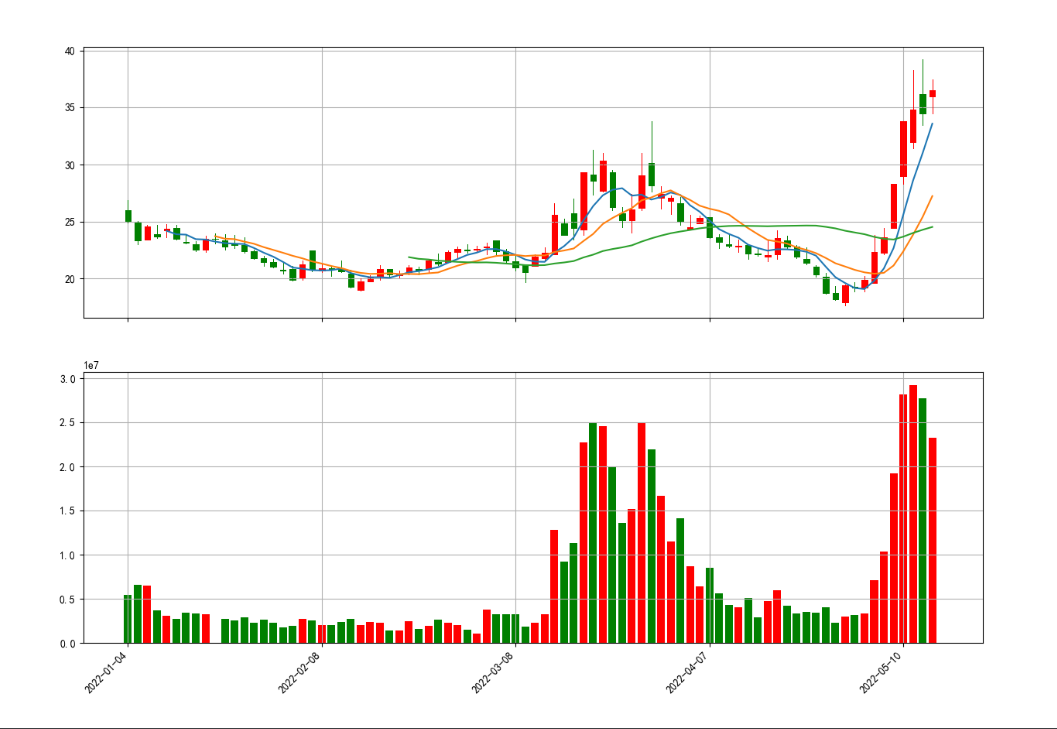
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线

根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。

那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
def long_up_shadow(o,c,h,l):
return True if (h-c)/c >=0.07 and (h-o)/o>=0.07 else False
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
df = pd.read_excel("同和药业k.xlsx")
count_num = []
for row,item in df.iterrows():
if long_up_shadow(item['open'],item['close'],item['high'],item['low']):
count_num.append(row)
plot_image(df,count_num)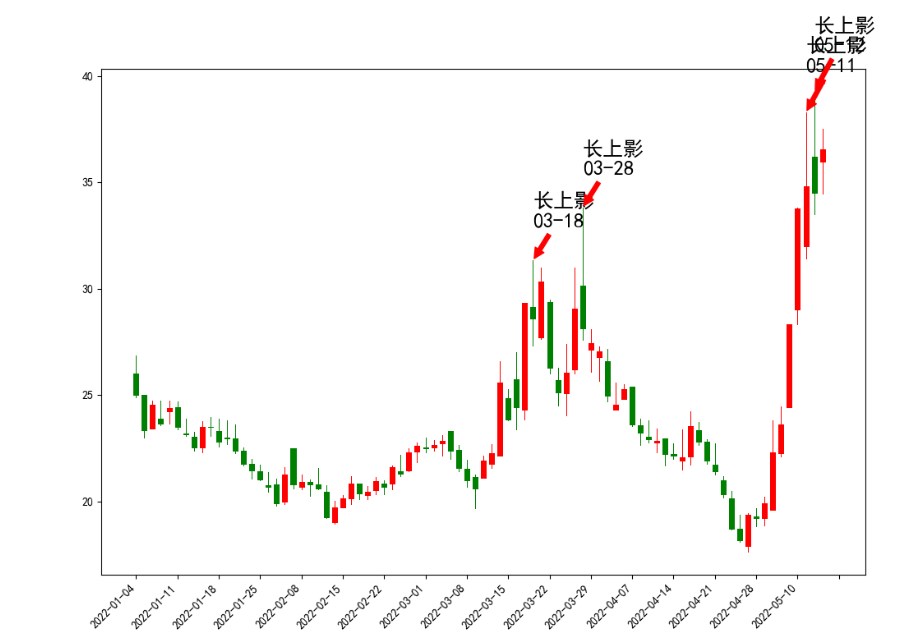
图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。

截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
df['tow_crows'] = talib.CDL2CROWS(df['open'].values, df['high'].values, df['low'].values, df['close'].values)
pattern = df[(df['tow_crows'] == 100) | (df['tow_crows'] == -100)]
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续)
在2015年山顶5178点 开始定投所有大A股票 结果会是怎样?
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 3718 次浏览 • 2021-03-29 00:41
而事实真的是这样吗?
笔者使用2015年6月12日上一轮全面牛市的高点5178点,作为定投的起始点。而定投标的股票为大A所有股票。
股票池为2015年6月12日没有停牌的股票,共 2415 只。使用的量化平台是优矿。
(没错,以前股票数就才两千多只,这几年股票数接近翻倍了)def get_all_code(date):
'''
获取某天的股市运行的股票,排除停牌
'''
df=DataAPI.MktEqudAdjGet(secID=u"",ticker=u"",
tradeDate=date,
beginDate=u"",
endDate=u"",
isOpen="",
field=u"",
pandas="1")
df=df[df['turnoverValue']>0] # 停牌
return df['ticker'].tolist()
部分股票样本数据
接着从2015年6月12日开始定投,这里笔者按照一个月定投一次,也就是22个交易日定投一次。
每次定投金额10000元。定投到2021年3月28日。
如果定投当天遇到股票停牌,则顺势延续到复牌后继续定投。
这里定投采用净值法定投,为的是让数据更加准确。因为如果按照实际定投股票,10000元的金额可能连1手的茅台也买不进去,这里计算买入的份额为=10000元/股票股价, 比如茅台的股价是2000元,那么这里买入的份额就是5股,并没按照实际股票的1手来算。这样计算得到结果更加精准。
python计算代码如下: 1import time
2import datetime
3
4stock_profit_list=
5start=time.time()
6
7today=datetime.datetime.now().strftime('%Y-%m-%d')
8
9def get_trade_date():
10 df=DataAPI.TradeCalGet(exchangeCD=u"XSHG,XSHE",
11 beginDate=high_date,
12 endDate=today,isOpen=u"1",
13 field=u"",pandas="1")
14 return df['calendarDate'].tolist()
15
16def fixed_investment(code):
17 stock_profit_dict={}
18 stock_profit_dict['code']=code
19 df=DataAPI.MktEqudAdjGet(secID=u"",ticker=code,tradeDate=u'',beginDate=high_date,endDate=today,isOpen="1",field=u"",pandas="1")
20 total_amount=0
21 invest_count=0
22 every_invest_cash=10000
23 total_money_list=list()
24 last_date=None
25 for trade_date in trade_date_list_interval:
26 trade_df = df[df['tradeDate']==trade_date]
27 if len(trade_df)>0:
28 invest_count+=1
29 price=trade_df['closePrice'].iloc[0]
30 amount=every_invest_cash/price
31 cost=invest_count*every_invest_cash
32 profit=total_amount*price/cost
33 total_money_list.append(profit)
34 total_amount=total_amount+amount
35 total_money=price*total_amount
36 last_date=trade_date
37
38
39 stock_profit_dict['profit_rate']=profit
40 stock_profit_dict['last_date']=last_date
41 stock_profit_dict['invest_count']=invest_count
42 stock_profit_dict['total_amount']=total_amount
43 stock_profit_dict['total_money']=total_money
44 stock_profit_dict['profit_list']=total_money_list
45 stock_profit_dict['cost']=cost
46 return stock_profit_dict
47
48for code in target_codes:
49 profit_dict = fixed_investment(code)
50 stock_profit_list.append(profit_dict)
51
52print(time.time()-start)
最终得到的数据保存在stock_profit_list变量里面。在计算过程也记录里每一个股票当前一期定投阶段的阶段收益率,组合成一个列表。
为的是倒后镜看看,曾经的历史定投收益率,也可以看看曾经的历史定投收益率的最大值。便于和现在最后一期收益率的对比。
得到数据按照profit_rate收益率排个序:profi_df_sorted = profit_df.sort_values(by='profit_rate',ascending=False)
得到下面的数据:
上面的股票熟悉不?基本都是年初那一批基金ikun们的抱团股。
定投收益率最高的是山西汾酒,收益率达到8.56,即856%,从股灾高点定投下来,到现在2021年3月28日,收益率是8倍!
其月K线如下:
牛气冲天的5年十倍股,股灾时山西汾酒的股价徘徊在21-26之间左右。如果股灾的时候采用一把梭,收益率是336/26=12.9 倍。
而采用定投方式的收益率也不差,8.56倍。
再继续看看定投收益排在倒数的
真是好家伙,亏得底裤都不见了。清一色的退市股,定投收益率基本在0.1以下,意味着投资了100元,最后就剩10元以下。
在前面计算的时候,特意加了一个数据列,定投期数和定投停止日期,也就是股票退市或者停牌导致无法交易的日子。
invest_count为定投期数,定投一次此值加1. last_date 为最后一个交易日期。倒数第一个国恒退,只交易1期,7月10日退市,等不来第2期的定投,不过也好,这样子只也不至于越陷越深。
国恒退日K
total_money 列是投资得到总金额,cost是投入的成本。投资期数越多,随着股价上涨,该金额会越高,而股价不断下跌,则该金额会越来越少。所以遇到国恒退这种股票,当期只投了10000元就无法继续投下去,还是运气比较好的。类似于止损操作了。
toal_money减去cost得到的是绝对收益。之前因为没有加这一列,可以通过以下公式计算得到:profit_df['absolute_profit']=profit_df['total_money']-profit_df['cost']
按绝对收益计算,最多的还是前面那20位个股,赚最多的山西汾酒,129W的定投金额,盈利金额达到900W。
同样倒序排一下,绝对亏损最多的,肯定也是定投期数较多的。
[图片]
亏损最多的天夏退,目前还没有完全退市,定投了114期,总亏损金额达到100W,定投总金额是110W。额,只剩10W。
它的月K线是这样的。其跌到4元多的时候还放量了,可能一堆人冲进去抄底了,然后按亏损幅度,4元跌到0.22元,亏损幅度也是94.5%,这个亏损幅度其实和在山顶29元站岗的亏损率其实没什么区别了。高手死于抄底,呵呵。
接着看看上面所有股票的定投的平均收益率:profi_df_sorted['profit_rate'].mean()
得到的收益率的平均值为:1.043,减去本金1,收益为1.043-1=0.043,也就是4.3%个点。
换句话说,如果在股票高点5178点定投全市场股票,5年多来的最后收益率为4.3%.
中位数是0.87-1=-0.13,= -13%,中位数是亏损13%,定投金额约126W,亏损金额为14W。
看到这里,笔者想要表述的是,即使是定投也需要挑选一个好标的股票或者基金,也就是择股择时能力。
如果在一个垃圾股或者基金上定投,只会让你越陷越深,亏损越来越多。假如你在定投康得新或者乐视,定投了100期,投入了不少的金额和时间,突然暴雷,然后ST,那么你会继续定投下去吗?
另外,定投也需要一定的择时能力,比如在前春节前,基金抱团股热度不减,对于大部分没有择股能力的人来说,当时是应该止盈离场的。当然,如果倒后镜看,如果有能力抓取上面的大牛股,也不一定能够把上面的8倍收益落袋而安。
上面数据有一列max_profit,total_money/cost, 也就是定投期间,获得的最大收益率。按此列排序:
在定投期间,最大收益率的是ST中安,最大收益率是14.6-1=13.6倍。最后到这个月最终定投收益率是0.67,亏损状态,0.67-1=-0.37,亏损为-37%,绝对收益absolute_profit为-29W.
排在第4是是乐视退,定投期间最大收益max_profit达到10倍,最后如果坚持定投,是亏损93%的。
如果把定投时间放在2018年1月12日,那么得到的定投收益率排名前20名是这样的:
得到不一样的前20排名,定投收益率最高的是英科医疗,疫情手套涨了10倍的大牛股。而山西汾酒跌到第10,并且收益率也只有4倍左右。而茅台也没出现在前20的榜单上。
不同的定投时间,得到的是不一样的结果。当然择股能力强的大神,就不屑定投而采用一把梭了,大神向往的是英科医疗的一年十倍,而不是十年十倍(大V组合抱团,抱团基金的组合)。
其改变定投时间的定投收益率的平均值以及中位数数据如下:
平均收益率达到了1.14-1=0.14=14%,也就是如果你在18年开始定投全市场股票,当前平均收益率是14%,不过中位数的收益率是1-1=0%,因为这两年股票大小票分化得太严重(24%的个股跌破2440的低点,指数涨41%),四分一分位的定投收益率为27%,到了中位数就为0%了。其定投收益率较2015年山顶定投也有了很大的区别。
今天就到这里吧,感觉文章太长了,本来还想把全市场的基金加进来比较的(不同时间点定投全市场所有基金),碍于篇幅原因,留在下一篇再写吧,敬请留意!
微信公众号:
可转债量化分析
查看全部
而事实真的是这样吗?
笔者使用2015年6月12日上一轮全面牛市的高点5178点,作为定投的起始点。而定投标的股票为大A所有股票。

股票池为2015年6月12日没有停牌的股票,共 2415 只。使用的量化平台是优矿。
(没错,以前股票数就才两千多只,这几年股票数接近翻倍了)
def get_all_code(date):
'''
获取某天的股市运行的股票,排除停牌
'''
df=DataAPI.MktEqudAdjGet(secID=u"",ticker=u"",
tradeDate=date,
beginDate=u"",
endDate=u"",
isOpen="",
field=u"",
pandas="1")
df=df[df['turnoverValue']>0] # 停牌
return df['ticker'].tolist()


部分股票样本数据
接着从2015年6月12日开始定投,这里笔者按照一个月定投一次,也就是22个交易日定投一次。
每次定投金额10000元。定投到2021年3月28日。
如果定投当天遇到股票停牌,则顺势延续到复牌后继续定投。
这里定投采用净值法定投,为的是让数据更加准确。因为如果按照实际定投股票,10000元的金额可能连1手的茅台也买不进去,这里计算买入的份额为=10000元/股票股价, 比如茅台的股价是2000元,那么这里买入的份额就是5股,并没按照实际股票的1手来算。这样计算得到结果更加精准。
python计算代码如下:
1import time
2import datetime
3
4stock_profit_list=
5start=time.time()
6
7today=datetime.datetime.now().strftime('%Y-%m-%d')
8
9def get_trade_date():
10 df=DataAPI.TradeCalGet(exchangeCD=u"XSHG,XSHE",
11 beginDate=high_date,
12 endDate=today,isOpen=u"1",
13 field=u"",pandas="1")
14 return df['calendarDate'].tolist()
15
16def fixed_investment(code):
17 stock_profit_dict={}
18 stock_profit_dict['code']=code
19 df=DataAPI.MktEqudAdjGet(secID=u"",ticker=code,tradeDate=u'',beginDate=high_date,endDate=today,isOpen="1",field=u"",pandas="1")
20 total_amount=0
21 invest_count=0
22 every_invest_cash=10000
23 total_money_list=list()
24 last_date=None
25 for trade_date in trade_date_list_interval:
26 trade_df = df[df['tradeDate']==trade_date]
27 if len(trade_df)>0:
28 invest_count+=1
29 price=trade_df['closePrice'].iloc[0]
30 amount=every_invest_cash/price
31 cost=invest_count*every_invest_cash
32 profit=total_amount*price/cost
33 total_money_list.append(profit)
34 total_amount=total_amount+amount
35 total_money=price*total_amount
36 last_date=trade_date
37
38
39 stock_profit_dict['profit_rate']=profit
40 stock_profit_dict['last_date']=last_date
41 stock_profit_dict['invest_count']=invest_count
42 stock_profit_dict['total_amount']=total_amount
43 stock_profit_dict['total_money']=total_money
44 stock_profit_dict['profit_list']=total_money_list
45 stock_profit_dict['cost']=cost
46 return stock_profit_dict
47
48for code in target_codes:
49 profit_dict = fixed_investment(code)
50 stock_profit_list.append(profit_dict)
51
52print(time.time()-start)
最终得到的数据保存在stock_profit_list变量里面。在计算过程也记录里每一个股票当前一期定投阶段的阶段收益率,组合成一个列表。
为的是倒后镜看看,曾经的历史定投收益率,也可以看看曾经的历史定投收益率的最大值。便于和现在最后一期收益率的对比。
得到数据按照profit_rate收益率排个序:
profi_df_sorted = profit_df.sort_values(by='profit_rate',ascending=False)
得到下面的数据:

上面的股票熟悉不?基本都是年初那一批基金ikun们的抱团股。
定投收益率最高的是山西汾酒,收益率达到8.56,即856%,从股灾高点定投下来,到现在2021年3月28日,收益率是8倍!
其月K线如下:

牛气冲天的5年十倍股,股灾时山西汾酒的股价徘徊在21-26之间左右。如果股灾的时候采用一把梭,收益率是336/26=12.9 倍。
而采用定投方式的收益率也不差,8.56倍。
再继续看看定投收益排在倒数的

真是好家伙,亏得底裤都不见了。清一色的退市股,定投收益率基本在0.1以下,意味着投资了100元,最后就剩10元以下。
在前面计算的时候,特意加了一个数据列,定投期数和定投停止日期,也就是股票退市或者停牌导致无法交易的日子。
invest_count为定投期数,定投一次此值加1. last_date 为最后一个交易日期。倒数第一个国恒退,只交易1期,7月10日退市,等不来第2期的定投,不过也好,这样子只也不至于越陷越深。

国恒退日K
total_money 列是投资得到总金额,cost是投入的成本。投资期数越多,随着股价上涨,该金额会越高,而股价不断下跌,则该金额会越来越少。所以遇到国恒退这种股票,当期只投了10000元就无法继续投下去,还是运气比较好的。类似于止损操作了。
toal_money减去cost得到的是绝对收益。之前因为没有加这一列,可以通过以下公式计算得到:
profit_df['absolute_profit']=profit_df['total_money']-profit_df['cost']
按绝对收益计算,最多的还是前面那20位个股,赚最多的山西汾酒,129W的定投金额,盈利金额达到900W。

同样倒序排一下,绝对亏损最多的,肯定也是定投期数较多的。
[图片]
亏损最多的天夏退,目前还没有完全退市,定投了114期,总亏损金额达到100W,定投总金额是110W。额,只剩10W。

它的月K线是这样的。其跌到4元多的时候还放量了,可能一堆人冲进去抄底了,然后按亏损幅度,4元跌到0.22元,亏损幅度也是94.5%,这个亏损幅度其实和在山顶29元站岗的亏损率其实没什么区别了。高手死于抄底,呵呵。
接着看看上面所有股票的定投的平均收益率:
profi_df_sorted['profit_rate'].mean()得到的收益率的平均值为:1.043,减去本金1,收益为1.043-1=0.043,也就是4.3%个点。
换句话说,如果在股票高点5178点定投全市场股票,5年多来的最后收益率为4.3%.

中位数是0.87-1=-0.13,= -13%,中位数是亏损13%,定投金额约126W,亏损金额为14W。
看到这里,笔者想要表述的是,即使是定投也需要挑选一个好标的股票或者基金,也就是择股择时能力。
如果在一个垃圾股或者基金上定投,只会让你越陷越深,亏损越来越多。假如你在定投康得新或者乐视,定投了100期,投入了不少的金额和时间,突然暴雷,然后ST,那么你会继续定投下去吗?
另外,定投也需要一定的择时能力,比如在前春节前,基金抱团股热度不减,对于大部分没有择股能力的人来说,当时是应该止盈离场的。当然,如果倒后镜看,如果有能力抓取上面的大牛股,也不一定能够把上面的8倍收益落袋而安。
上面数据有一列max_profit,total_money/cost, 也就是定投期间,获得的最大收益率。按此列排序:

在定投期间,最大收益率的是ST中安,最大收益率是14.6-1=13.6倍。最后到这个月最终定投收益率是0.67,亏损状态,0.67-1=-0.37,亏损为-37%,绝对收益absolute_profit为-29W.
排在第4是是乐视退,定投期间最大收益max_profit达到10倍,最后如果坚持定投,是亏损93%的。
如果把定投时间放在2018年1月12日,那么得到的定投收益率排名前20名是这样的:

得到不一样的前20排名,定投收益率最高的是英科医疗,疫情手套涨了10倍的大牛股。而山西汾酒跌到第10,并且收益率也只有4倍左右。而茅台也没出现在前20的榜单上。
不同的定投时间,得到的是不一样的结果。当然择股能力强的大神,就不屑定投而采用一把梭了,大神向往的是英科医疗的一年十倍,而不是十年十倍(大V组合抱团,抱团基金的组合)。
其改变定投时间的定投收益率的平均值以及中位数数据如下:

平均收益率达到了1.14-1=0.14=14%,也就是如果你在18年开始定投全市场股票,当前平均收益率是14%,不过中位数的收益率是1-1=0%,因为这两年股票大小票分化得太严重(24%的个股跌破2440的低点,指数涨41%),四分一分位的定投收益率为27%,到了中位数就为0%了。其定投收益率较2015年山顶定投也有了很大的区别。
今天就到这里吧,感觉文章太长了,本来还想把全市场的基金加进来比较的(不同时间点定投全市场所有基金),碍于篇幅原因,留在下一篇再写吧,敬请留意!
微信公众号:
可转债量化分析

bandcamp移动开发更简单
数据库 • linxiaojue 发表了文章 • 0 个评论 • 4779 次浏览 • 2019-12-14 05:12
http://TalkingData.bandcamp.com/
http://Bugly.bandcamp.com/
http://Box2D.bandcamp.com/
http://aineice.bandcamp.com/
http://wyyp.bandcamp.com/
http://Prepo.bandcamp.com/
http://Chipmunk.bandcamp.com/
http://openinstall.bandcamp.com/
http://MobileInsight.bandcamp.com/
http://zhugelo.bandcamp.com/
http://CobubRazor.bandcamp.com/
http://Testin.bandcamp.com/
http://crashlytics.bandcamp.com/
http://APKProtect.bandcamp.com/
http://Ucloud.bandcamp.com/
http://ydkfpgj.bandcamp.com/releases
http://TalkingData.bandcamp.com/releases
http://Bugly.bandcamp.com/releases
http://Box2D.bandcamp.com/releases
http://aineice.bandcamp.com/releases
http://wyyp.bandcamp.com/releases
http://Prepo.bandcamp.com/releases
http://Chipmunk.bandcamp.com/releases
http://openinstall.bandcamp.com/releases
http://MobileInsight.bandcamp.com/releases
http://zhugelo.bandcamp.com/releases
http://CobubRazor.bandcamp.com/releases
http://Testin.bandcamp.com/releases
http://crashlytics.bandcamp.com/releases
http://APKProtect.bandcamp.com/releases
http://Ucloud.bandcamp.com/releases 查看全部
http://TalkingData.bandcamp.com/
http://Bugly.bandcamp.com/
http://Box2D.bandcamp.com/
http://aineice.bandcamp.com/
http://wyyp.bandcamp.com/
http://Prepo.bandcamp.com/
http://Chipmunk.bandcamp.com/
http://openinstall.bandcamp.com/
http://MobileInsight.bandcamp.com/
http://zhugelo.bandcamp.com/
http://CobubRazor.bandcamp.com/
http://Testin.bandcamp.com/
http://crashlytics.bandcamp.com/
http://APKProtect.bandcamp.com/
http://Ucloud.bandcamp.com/
http://ydkfpgj.bandcamp.com/releases
http://TalkingData.bandcamp.com/releases
http://Bugly.bandcamp.com/releases
http://Box2D.bandcamp.com/releases
http://aineice.bandcamp.com/releases
http://wyyp.bandcamp.com/releases
http://Prepo.bandcamp.com/releases
http://Chipmunk.bandcamp.com/releases
http://openinstall.bandcamp.com/releases
http://MobileInsight.bandcamp.com/releases
http://zhugelo.bandcamp.com/releases
http://CobubRazor.bandcamp.com/releases
http://Testin.bandcamp.com/releases
http://crashlytics.bandcamp.com/releases
http://APKProtect.bandcamp.com/releases
http://Ucloud.bandcamp.com/releases
numpy indices的用法
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 10431 次浏览 • 2019-07-08 17:58
M_ij = 2*i + 3*j
One way to define this matrix would be
i, j = np.indices((2,3))
M = 2*i + 3*j
which yields
array([[0, 3, 6],
[2, 5, 8]])
In other words, np.indices returns arrays which can be used as indices. The elements in i indicate the row index:
In [12]: i
Out[12]:
array([[0, 0, 0],
[1, 1, 1]])
The elements in j indicate the column index:
In [13]: j
Out[13]:
array([[0, 1, 2],
[0, 1, 2]])
上面是Stack Overflow的解释。 翻译一下:
np.indices((2,3))
返回的是一个行列的索引,然后可以用这个索引快速的创建二维数据。
比如我要画一个圆:
img = np.zeros((400,400))
ir,ic = np.indices(img.shape)
circle = (ir-135)**2+(ic-150)**2 < 30**2 # 半径30,圆心在135,150
img[circle]=1
img现在就是一个圆啦
查看全部
Suppose you have a matrix M whose (i,j)-th element equals
M_ij = 2*i + 3*j
One way to define this matrix would be
i, j = np.indices((2,3))
M = 2*i + 3*j
which yields
array([[0, 3, 6],
[2, 5, 8]])
In other words, np.indices returns arrays which can be used as indices. The elements in i indicate the row index:
In [12]: i
Out[12]:
array([[0, 0, 0],
[1, 1, 1]])
The elements in j indicate the column index:
In [13]: j
Out[13]:
array([[0, 1, 2],
[0, 1, 2]])
上面是Stack Overflow的解释。 翻译一下:
np.indices((2,3))
返回的是一个行列的索引,然后可以用这个索引快速的创建二维数据。
比如我要画一个圆:
img = np.zeros((400,400))
ir,ic = np.indices(img.shape)
circle = (ir-135)**2+(ic-150)**2 < 30**2 # 半径30,圆心在135,150
img[circle]=1
img现在就是一个圆啦
修改easytrader国金证券的默认启动路径
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 6045 次浏览 • 2019-06-17 10:23
pywinauto.application.AppStartError: Could not create the process "C:\全能行证券交易终端\xiadan.exe"
Error returned by CreateProcess: (2, 'CreateProcess', '系统找不到指定的文件。')
看了配置文件,也是没有具体的参数可以修改,只好修改源代码。
别听到改源代码就害怕,只是需要改一行就可以了。
找到文件:
site-package\easytrader\config\client.py
找过这一行:
class GJ(CommonConfig):
DEFAULT_EXE_PATH = "C:\\Tool\\xiadan.exe"只要修改上面的路径就可以了。注意用双斜杠。
查看全部
pywinauto.application.AppStartError: Could not create the process "C:\全能行证券交易终端\xiadan.exe"
Error returned by CreateProcess: (2, 'CreateProcess', '系统找不到指定的文件。')
看了配置文件,也是没有具体的参数可以修改,只好修改源代码。
别听到改源代码就害怕,只是需要改一行就可以了。
找到文件:
site-package\easytrader\config\client.py
找过这一行:
class GJ(CommonConfig):只要修改上面的路径就可以了。注意用双斜杠。
DEFAULT_EXE_PATH = "C:\\Tool\\xiadan.exe"
jupyter notebook格式的文件损坏如何修复
python • 李魔佛 发表了文章 • 0 个评论 • 6204 次浏览 • 2019-06-08 13:44
使用下面的代码:
# 拯救损坏的jupyter 文件
import re
import codecs
pattern = re.compile('"source": \[(.*?)\]\s+\},',re.S)
filename = 'tushare_usage.ipynb'
with codecs.open(filename,encoding='utf8') as f:
content = f.read()
source = pattern.findall(content)
for s in source:
t=s.replace('\\n','')
t=re.sub('"','',t)
t=re.sub('(,$)','',t)
print(t)只要把你要修复的文件替换一下就可以了。 查看全部
使用下面的代码:
# 拯救损坏的jupyter 文件只要把你要修复的文件替换一下就可以了。
import re
import codecs
pattern = re.compile('"source": \[(.*?)\]\s+\},',re.S)
filename = 'tushare_usage.ipynb'
with codecs.open(filename,encoding='utf8') as f:
content = f.read()
source = pattern.findall(content)
for s in source:
t=s.replace('\\n','')
t=re.sub('"','',t)
t=re.sub('(,$)','',t)
print(t)
python数据分析之 A股上市公司按地区分布与可视化 地图显示
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 10700 次浏览 • 2018-12-19 14:07
地区 数目
浙江 431
江苏 401
北京 316
广东 303
上海 285
深圳 283
山东 196
福建 132
四川 120
湖南 104
安徽 103
湖北 101
河南 79
辽宁 72
河北 56
新疆 54
天津 50
陕西 49
重庆 48
吉林 41
江西 41
山西 38
黑龙江 37
广西 37
云南 33
甘肃 33
海南 31
贵州 29
内蒙 25
西藏 18
宁夏 13
青海 12
看看我们的641主席的功劳,江浙一带的上市公司数量已经超过广东了。
接下来我们使用pandas进行数据可视化:
首先读入数据:# A股上市公司分布:
df = pd.read_sql('tb_basic_info',con=engine)engine为from sqlalchemy import create_engine 中的连接引擎。
然后直接统计:result = df['area'].value_counts()得到的result就是统计结果:
看是不是比mysql语句简单多了?
得到一样的数据。
接下来使用图像来显示我们的数据:
什么? 一条命令就可以啦~ 实在太强大了!
从这个柱状图上,可以更加直观地看到A股上市公司的分布情况,东部长三角和珠三角的公司数目最多。而西部只有东部的零头。
接着把数据转化为百分比数据:total = result.sum()
ration = result/total*100
可以看到江浙地区占了22%的数量,体量还是很大的。
接下来,为了数据更加直观,把数据在地图上显示出来:
点击查看大图
颜色越红,表明上市公司越多。现在数据够直观了吧。
实现代码:# 热力图
def create_heatmap(attr,value,name,maptype):
style = Style(title_color="#fff", title_pos="center",
width=1200, height=600, background_color="#696969")
# 可视化
geo = Geo(name,**style.init_style)
geo.add("", attr, value, visual_range=[min(value), max(value)], symbol_size=8,
visual_text_color="#000",
is_visualmap=True, type='effectScatter',effect_scale=7,is_random=True,is_roam=False,is_piecewise = True,visual_split_number= 10,
)
geo.render('{}.html'.format(name)) create_heatmap(attr,value,'公司分布','china')
更多的数据分析,请关注本网站。
不定期更新哦
原创文章
转载请注明出处:
http://30daydo.com/article/388
查看全部
SELECT area `地区`,count(*) as `数目` FROM `tb_basic_info` GROUP BY area order by 数目 desc;得到下面的结果: 接着我们使用pandas进行数据可视化。
地区 数目
浙江 431
江苏 401
北京 316
广东 303
上海 285
深圳 283
山东 196
福建 132
四川 120
湖南 104
安徽 103
湖北 101
河南 79
辽宁 72
河北 56
新疆 54
天津 50
陕西 49
重庆 48
吉林 41
江西 41
山西 38
黑龙江 37
广西 37
云南 33
甘肃 33
海南 31
贵州 29
内蒙 25
西藏 18
宁夏 13
青海 12
看看我们的641主席的功劳,江浙一带的上市公司数量已经超过广东了。
接下来我们使用pandas进行数据可视化:
首先读入数据:
# A股上市公司分布:engine为from sqlalchemy import create_engine 中的连接引擎。
df = pd.read_sql('tb_basic_info',con=engine)
然后直接统计:
result = df['area'].value_counts()得到的result就是统计结果:
看是不是比mysql语句简单多了?
得到一样的数据。
接下来使用图像来显示我们的数据:

什么? 一条命令就可以啦~ 实在太强大了!
从这个柱状图上,可以更加直观地看到A股上市公司的分布情况,东部长三角和珠三角的公司数目最多。而西部只有东部的零头。
接着把数据转化为百分比数据:
total = result.sum()
ration = result/total*100

可以看到江浙地区占了22%的数量,体量还是很大的。
接下来,为了数据更加直观,把数据在地图上显示出来:

点击查看大图
颜色越红,表明上市公司越多。现在数据够直观了吧。
实现代码:
# 热力图
def create_heatmap(attr,value,name,maptype):
style = Style(title_color="#fff", title_pos="center",
width=1200, height=600, background_color="#696969")
# 可视化
geo = Geo(name,**style.init_style)
geo.add("", attr, value, visual_range=[min(value), max(value)], symbol_size=8,
visual_text_color="#000",
is_visualmap=True, type='effectScatter',effect_scale=7,is_random=True,is_roam=False,is_piecewise = True,visual_split_number= 10,
)
geo.render('{}.html'.format(name))
create_heatmap(attr,value,'公司分布','china')
更多的数据分析,请关注本网站。
不定期更新哦
原创文章
转载请注明出处:
http://30daydo.com/article/388
python识别股票K线形态,准确率回测(一)
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 1 个评论 • 13531 次浏览 • 2022-05-22 01:13
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)
做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
# pip install akshare
import akshare as ak
def get_k_line(code="sz002241"): #
df = ak.stock_zh_a_daily(symbol=code, start_date="20220101", end_date="20220515",
adjust="qfq")
# 这个函数只适合取股票数据,转债会报错,转债的日线数据可以使用其他函数,这里选择股价前复权
df.to_excel("同和药业k.xlsx")
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
date:交易日期
open:代表开盘价
high:当天最高价
low:当天最低价
close:当天收盘价
volume:当天成交量(元)
outstanding_share:流动股本(股)
turnover:换手率
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
#显示出来
plt.show()
运行此段代码后,会显示如下效果图:
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
import matplotlib.ticker as ticker
#将股票时间转换为标准时间,不带时分秒的数据
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.strptime(date, '%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
ax.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线
根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。
那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
def long_up_shadow(o,c,h,l):
return True if (h-c)/c >=0.07 and (h-o)/o>=0.07 else False
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
df = pd.read_excel("同和药业k.xlsx")
count_num = []
for row,item in df.iterrows():
if long_up_shadow(item['open'],item['close'],item['high'],item['low']):
count_num.append(row)
plot_image(df,count_num)
图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。
截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
df['tow_crows'] = talib.CDL2CROWS(df['open'].values, df['high'].values, df['low'].values, df['close'].values)
pattern = df[(df['tow_crows'] == 100) | (df['tow_crows'] == -100)]
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续) 查看全部
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)
做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
# pip install akshare
import akshare as ak
def get_k_line(code="sz002241"): #
df = ak.stock_zh_a_daily(symbol=code, start_date="20220101", end_date="20220515",
adjust="qfq")
# 这个函数只适合取股票数据,转债会报错,转债的日线数据可以使用其他函数,这里选择股价前复权
df.to_excel("同和药业k.xlsx")
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
date:交易日期
open:代表开盘价
high:当天最高价
low:当天最低价
close:当天收盘价
volume:当天成交量(元)
outstanding_share:流动股本(股)
turnover:换手率
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
#显示出来
plt.show()
运行此段代码后,会显示如下效果图:
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
import matplotlib.ticker as ticker
#将股票时间转换为标准时间,不带时分秒的数据
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.strptime(date, '%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
ax.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线
根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。
那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
def long_up_shadow(o,c,h,l):
return True if (h-c)/c >=0.07 and (h-o)/o>=0.07 else False
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
df = pd.read_excel("同和药业k.xlsx")
count_num = []
for row,item in df.iterrows():
if long_up_shadow(item['open'],item['close'],item['high'],item['low']):
count_num.append(row)
plot_image(df,count_num)图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。
截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
df['tow_crows'] = talib.CDL2CROWS(df['open'].values, df['high'].values, df['low'].values, df['close'].values)
pattern = df[(df['tow_crows'] == 100) | (df['tow_crows'] == -100)]
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续)
Ptrade获取历史涨停的股票|python代码
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 2523 次浏览 • 2024-11-01 18:41
下面的程序用于监控可转债的正股,在过去10天里是否出现涨停。
下面的ptrade的代码片段。需要完整代码,可关注公众号私信获取。
def hit_limit_recent():
# 选出最近N天正股有涨停的可转债
N =10
scale = 5
latest_price = 160
bond_name_dict, bond_zg_dict = get_all_bond_info(scale=scale,latest_price=latest_price)
zg_list = list(bond_zg_dict.values())
panel_info = get_history(N, frequency='1d', field=['close','high_limit'], security_list=zg_list, fq='pre', include=False, fill='nan')
df = panel_info.swapaxes("minor_axis", "items")
target_list = []
for code in zg_list:
stock_df = df[code]
hit_high = stock_df[stock_df['close']==stock_df['high_limit']]
if len(hit_high) > 0:
# print(hit_high.index)
target_list.append(code)
zz_target_list = []
for code,zg_code in bond_zg_dict.items():
if zg_code in target_list:
print(code, bond_name_dict[code])
zz_target_list.append(code)
return zz_target_list当然,会有一个情形,就是实际最后是开板状态,但是收盘价格和涨停价格一样。
这种属于涨停开板状态,需要利用tick的委卖买来判断。
查看全部
下面的程序用于监控可转债的正股,在过去10天里是否出现涨停。
下面的ptrade的代码片段。需要完整代码,可关注公众号私信获取。
def hit_limit_recent():当然,会有一个情形,就是实际最后是开板状态,但是收盘价格和涨停价格一样。
# 选出最近N天正股有涨停的可转债
N =10
scale = 5
latest_price = 160
bond_name_dict, bond_zg_dict = get_all_bond_info(scale=scale,latest_price=latest_price)
zg_list = list(bond_zg_dict.values())
panel_info = get_history(N, frequency='1d', field=['close','high_limit'], security_list=zg_list, fq='pre', include=False, fill='nan')
df = panel_info.swapaxes("minor_axis", "items")
target_list = []
for code in zg_list:
stock_df = df[code]
hit_high = stock_df[stock_df['close']==stock_df['high_limit']]
if len(hit_high) > 0:
# print(hit_high.index)
target_list.append(code)
zz_target_list = []
for code,zg_code in bond_zg_dict.items():
if zg_code in target_list:
print(code, bond_name_dict[code])
zz_target_list.append(code)
return zz_target_list
这种属于涨停开板状态,需要利用tick的委卖买来判断。
哪些股票突破了10月8日的最高点?
股票 • 李魔佛 发表了文章 • 0 个评论 • 2868 次浏览 • 2024-10-25 10:28
本文继续贴一下股票从10月8日的最高,到目前的涨跌分布。
数据包含北交所数据。
当前价格相对10月8日高点,涨幅前面的基本是北交所,创业板的股票。天马新材涨幅高达284%,一路涨停板30%,45度角冲上来。
创业板的光智科技8连板,20%一个板,最终今天开板后又封住,录得相对8号高点到目前的涨幅为258%
这些不知名的股票,要么处于亏损状态,要么四五百的市盈率,日后大概率会遵循怎么上去就怎么下来的规律。
比如像下面跌幅榜排名前面的,从高点跌去80%的股票。
长联科技节前最后一天上市,上市当天就吸引了足够的关注,涨了足足17倍。打新中签者,一签浮盈17万。而节后第一天该股冲高回落,依然大涨收盘。
而该股后面就开启了暴跌模式。
跌到今天之后,相对高点跌幅达到81%。
10月8日高点下来的A股个股数据统计
平均跌幅为-8.73%,中位数跌幅为-11%。当天开盘前,散户幻觉认为牛市来了,股票高开后,肯定不能轻易被买到,纷纷挂高价,甚至涨停价。(当时氛围太火爆,当时我也有这种牛市冲冲冲的幻觉)
而截至昨日收盘价,依然有652只股票,突破了10月8日的最高点,相对10日8日的最高点获得了正涨幅,比例为12%,比例比转债的稍微大一些。
A股的股票看起来暴富机会比转债要大的多,但同样会伴随更大的概率,让你一贫如洗,盈亏同源。
查看全部
本文继续贴一下股票从10月8日的最高,到目前的涨跌分布。
数据包含北交所数据。
当前价格相对10月8日高点,涨幅前面的基本是北交所,创业板的股票。天马新材涨幅高达284%,一路涨停板30%,45度角冲上来。
创业板的光智科技8连板,20%一个板,最终今天开板后又封住,录得相对8号高点到目前的涨幅为258%
这些不知名的股票,要么处于亏损状态,要么四五百的市盈率,日后大概率会遵循怎么上去就怎么下来的规律。
比如像下面跌幅榜排名前面的,从高点跌去80%的股票。
长联科技节前最后一天上市,上市当天就吸引了足够的关注,涨了足足17倍。打新中签者,一签浮盈17万。而节后第一天该股冲高回落,依然大涨收盘。
而该股后面就开启了暴跌模式。
跌到今天之后,相对高点跌幅达到81%。
10月8日高点下来的A股个股数据统计
平均跌幅为-8.73%,中位数跌幅为-11%。当天开盘前,散户幻觉认为牛市来了,股票高开后,肯定不能轻易被买到,纷纷挂高价,甚至涨停价。(当时氛围太火爆,当时我也有这种牛市冲冲冲的幻觉)
而截至昨日收盘价,依然有652只股票,突破了10月8日的最高点,相对10日8日的最高点获得了正涨幅,比例为12%,比例比转债的稍微大一些。
A股的股票看起来暴富机会比转债要大的多,但同样会伴随更大的概率,让你一贫如洗,盈亏同源。
可转债现金替代策略 | QMT | Ptrade
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 2426 次浏览 • 2024-10-15 11:05
适合大资金,求稳。
挑选低价格的AAA可转债,比如 正股是 银行,高分红的国企股,比如 大秦铁路的转债,大秦转债等,且到期收益为正。作为标的池。
然后 先 在标的池里挑选出一个价格最低的转债,1/3 仓位 买入,其余仓位买入银华日利。
程序每分钟监控。或者不用那么频繁,可以设置每小时,每天都可以。
如果转债价格下跌了X,就卖出银华日利(1/10仓位),买入转债; (这里仓位随意举例)
如果转债价格上涨了Y,就卖出转债(1/5仓位),买入银华日利;(这里仓位随意举例)
一般AAA的大规模转债,其波动比较小,很少会遇到趋势上涨。 所以大部分的时间是做有波动的高抛低吸。
但,一旦遇到趋势上涨,或者突破,那么按照策略 会不断卖出转债;
一旦转债仓位为0,就可以在标的池买入另外一只标的(1/3仓位),从而继续下一轮的高抛低吸。
如果转债价格一直跌,但由于AAA的转债有保底,且有回售,转股,下修等各种手段,来兜底,
所以一般遇到跌幅行情,下跌不会超过10%,所以策略可以一直在卖出银华日利,买入转债;
如果中途,出现了其他好的标的,你需要手动交易,那么可以手动卖出银华日利或者可转债,腾出仓位,来操作。
也就是这个策略的可转债,纯粹当做现金来替代来使用。
接着就是使用QMT和Ptrade实现。
待续............
查看全部
适合大资金,求稳。
挑选低价格的AAA可转债,比如 正股是 银行,高分红的国企股,比如 大秦铁路的转债,大秦转债等,且到期收益为正。作为标的池。
然后 先 在标的池里挑选出一个价格最低的转债,1/3 仓位 买入,其余仓位买入银华日利。
程序每分钟监控。或者不用那么频繁,可以设置每小时,每天都可以。
如果转债价格下跌了X,就卖出银华日利(1/10仓位),买入转债; (这里仓位随意举例)
如果转债价格上涨了Y,就卖出转债(1/5仓位),买入银华日利;(这里仓位随意举例)
一般AAA的大规模转债,其波动比较小,很少会遇到趋势上涨。 所以大部分的时间是做有波动的高抛低吸。
但,一旦遇到趋势上涨,或者突破,那么按照策略 会不断卖出转债;
一旦转债仓位为0,就可以在标的池买入另外一只标的(1/3仓位),从而继续下一轮的高抛低吸。
如果转债价格一直跌,但由于AAA的转债有保底,且有回售,转股,下修等各种手段,来兜底,
所以一般遇到跌幅行情,下跌不会超过10%,所以策略可以一直在卖出银华日利,买入转债;
如果中途,出现了其他好的标的,你需要手动交易,那么可以手动卖出银华日利或者可转债,腾出仓位,来操作。
也就是这个策略的可转债,纯粹当做现金来替代来使用。
接着就是使用QMT和Ptrade实现。
待续............
python Ptrade获取热门板块,连板股票 python代码
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 6093 次浏览 • 2024-08-23 16:57
Ptrade API文档:https://ptradeapi.com/#get_sort_msg
get_sort_msg – 获取板块、行业的涨幅排名
get_sort_msg(sort_type_grp=None, sort_field_name=None, sort_type=1, data_count=100)
接口说明
该接口用于获取板块、行业的涨幅排名。
参数 sort_type_grp: 板块或行业的代码(list[str]/str);
(暂时只支持XBHS.DY地域、XBHS.GN概念、XBHS.ZJHHY证监会行业、XBHS.ZS指数、XBHS.HY行业等)
示例代码:按概念板块涨幅倒序排名
import datetime
START_TIME = (datetime.datetime.now() + datetime.timedelta(minutes=1)).strftime('%H:%M')
def execution(context):
#获取XBHS.GN的概念排名信息
sort_data = get_sort_msg(sort_type_grp='XBHS.GN', sort_field_name='px_change_rate', sort_type=1, data_count=100)
for data in sort_data:
log.info('板块: {} '.format(data['prod_name']))
for sub_stock in data['rise_first_grp']:
log.info('{} 涨幅 :{}'.format(sub_stock['prod_name'],sub_stock['px_change_rate']))
log.info('\n')
def initialize(context):
# 初始化策略
run_daily(context, execution, time=START_TIME) # 扫描
log.info("公众号:可转债量化分析\n")
def handle_data(context, data):
pass
上面代码在ptrade启动后一分钟拿到结果。不限制要求开盘时间的。其实Ptrade可以在24小时任意时刻启动。
get_sort_msg 返回的数据结构体如下:
具体字段的含义:
prod_code: 行业代码(str:str);
prod_name: 行业名称(str:str);
hq_type_code: 行业板块代码(str:str);
time_stamp: 时间戳毫秒级(str:int);
trade_mins: 交易分钟数(str:int);
trade_status: 交易状态(str:str);
preclose_px: 昨日收盘价(str:float);
open_px: 今日开盘价(str:float);
last_px: 最新价(str:float);
high_px: 最高价(str:float);
low_px: 最低价(str:float);
wavg_px: 加权平均价(str:float);
business_amount: 总成交量(str:int);
business_balance: 总成交额(str:int);
px_change: 涨跌额(str:float);
amplitude: 振幅(str:int);
px_change_rate: 涨跌幅(str:float);
circulation_amount: 流通股本(str:int);
total_shares: 总股本(str:int);
market_value: 市值(str:int);
circulation_value: 流通市值(str:int);
vol_ratio: 量比(str:float);
shares_per_hand: 每手股数(str:int);
rise_count: 上涨家数(str:int);
fall_count: 下跌家数(str:int);
member_count: 成员个数(str:int);
rise_first_grp: 领涨股票(其包含以下五个字段)(str:list[dict{str:int,str:str,str:str,str:float,str:float},...]);
prod_code: 股票代码(str:str);
prod_name: 证券名称(str:str);
hq_type_code: 类型代码(str:str);
last_px: 最新价(str:float);
px_change_rate: 涨跌幅(str:float);
fall_first_grp: 领跌股票(其包含以下五个字段)(str:list[dict{str:int,str:str,str:str,str:float,str:float},...]);
prod_code: 股票代码(str:str);
prod_name: 证券名称(str:str);
hq_type_code: 类型代码(str:str);
last_px: 最新价(str:float);
px_change_rate: 涨跌幅(str:float);
这个返回数据是实时的,可以用来选股,选择热门股,热门板块,涨停板块,昨日涨停,昨日连板板块。
比如上面运行结果里就有 昨日连板的板块个股,有9个,在rise_first_grp 字段里面:
需要开通Ptrade的读者朋友可以后天联系哦,提供不同券商ptrade,低门槛,低费率,还有技术支持群!
查看全部
Ptrade API文档:https://ptradeapi.com/#get_sort_msg
get_sort_msg – 获取板块、行业的涨幅排名
get_sort_msg(sort_type_grp=None, sort_field_name=None, sort_type=1, data_count=100)
接口说明
该接口用于获取板块、行业的涨幅排名。
参数 sort_type_grp: 板块或行业的代码(list[str]/str);
(暂时只支持XBHS.DY地域、XBHS.GN概念、XBHS.ZJHHY证监会行业、XBHS.ZS指数、XBHS.HY行业等)
示例代码:按概念板块涨幅倒序排名
import datetime
START_TIME = (datetime.datetime.now() + datetime.timedelta(minutes=1)).strftime('%H:%M')
def execution(context):
#获取XBHS.GN的概念排名信息
sort_data = get_sort_msg(sort_type_grp='XBHS.GN', sort_field_name='px_change_rate', sort_type=1, data_count=100)
for data in sort_data:
log.info('板块: {} '.format(data['prod_name']))
for sub_stock in data['rise_first_grp']:
log.info('{} 涨幅 :{}'.format(sub_stock['prod_name'],sub_stock['px_change_rate']))
log.info('\n')
def initialize(context):
# 初始化策略
run_daily(context, execution, time=START_TIME) # 扫描
log.info("公众号:可转债量化分析\n")
def handle_data(context, data):
pass
上面代码在ptrade启动后一分钟拿到结果。不限制要求开盘时间的。其实Ptrade可以在24小时任意时刻启动。
get_sort_msg 返回的数据结构体如下:
具体字段的含义:
prod_code: 行业代码(str:str);
prod_name: 行业名称(str:str);
hq_type_code: 行业板块代码(str:str);
time_stamp: 时间戳毫秒级(str:int);
trade_mins: 交易分钟数(str:int);
trade_status: 交易状态(str:str);
preclose_px: 昨日收盘价(str:float);
open_px: 今日开盘价(str:float);
last_px: 最新价(str:float);
high_px: 最高价(str:float);
low_px: 最低价(str:float);
wavg_px: 加权平均价(str:float);
business_amount: 总成交量(str:int);
business_balance: 总成交额(str:int);
px_change: 涨跌额(str:float);
amplitude: 振幅(str:int);
px_change_rate: 涨跌幅(str:float);
circulation_amount: 流通股本(str:int);
total_shares: 总股本(str:int);
market_value: 市值(str:int);
circulation_value: 流通市值(str:int);
vol_ratio: 量比(str:float);
shares_per_hand: 每手股数(str:int);
rise_count: 上涨家数(str:int);
fall_count: 下跌家数(str:int);
member_count: 成员个数(str:int);
rise_first_grp: 领涨股票(其包含以下五个字段)(str:list[dict{str:int,str:str,str:str,str:float,str:float},...]);
prod_code: 股票代码(str:str);
prod_name: 证券名称(str:str);
hq_type_code: 类型代码(str:str);
last_px: 最新价(str:float);
px_change_rate: 涨跌幅(str:float);
fall_first_grp: 领跌股票(其包含以下五个字段)(str:list[dict{str:int,str:str,str:str,str:float,str:float},...]);
prod_code: 股票代码(str:str);
prod_name: 证券名称(str:str);
hq_type_code: 类型代码(str:str);
last_px: 最新价(str:float);
px_change_rate: 涨跌幅(str:float);
这个返回数据是实时的,可以用来选股,选择热门股,热门板块,涨停板块,昨日涨停,昨日连板板块。
比如上面运行结果里就有 昨日连板的板块个股,有9个,在rise_first_grp 字段里面:
需要开通Ptrade的读者朋友可以后天联系哦,提供不同券商ptrade,低门槛,低费率,还有技术支持群!
python量化分析教程 | 最近几年A股养老基金整体盈亏情况分析
股票 • 李魔佛 发表了文章 • 0 个评论 • 2641 次浏览 • 2024-07-25 17:30
不仅是散户被深套,很多基金也都大幅亏损。甚至前阵子看到证券时报报道,养老目标基金都出现不是清盘的现象。
于是笔者好奇心驱使,想看看这些养老基金最近几年的盈利情况,会不会把长辈老人们的下半辈子养老金都亏空了。
作为一名授人以渔的公众号博主,不仅仅贴个收益率图出来这么简单的啦。如果只是想看数据,直接跳过前面的操作即可。
笔者手把手教大家做数据分析,学会后不仅仅只对养老基金这一类别的基金做分析,还可以对不同类型的基金做分析。
前提:电脑按照了python已经相关库(jupyter notebook,pandas,akshare)
数据源:天天基金网
打开东财的天天基金网(https://fund.eastmoney.com/),在基金搜索页面输入:养老
总共有515个与养老相关的公募基金。如果没显示全,点击下图里面的“点击展开更多”按钮
抓包就找到对应的URL地址了,如下:https://fundsuggest.eastmoney.com/FundSearch/api/FundSearchPageAPI.ashx?callback=jQuery18306906210160165065_1721823304653&m=1&key=养老&pageindex=0&pagesize=515&_=1721823360126
如果你想分析其他类型的主题基金,只需要把上面的url里面的key=养老,换成其他的就可以了,比如 key=芯片
浏览器输入上面的URL就可以拿到数据了。
简单起见,我就不写爬取数据的代码,直接复制粘贴浏览器返回的内容就好了。
然后把前面起始的jQuery18306906210160165065_1721823304653( 和最后的括号去掉,就得到一个json数据了。
js_data = {
"ErrCode": 0,
"ErrMsg": "0",
"Datas": [
{
"_id": "001171",
"CODE": "001171",
"NAME": "工银养老产业股票A",
"STOCKMARKET": "",
"NEWTEXCH": ""
},
......... # 省略若干
]
}
(文末提供这个数据文件的获取方式)
接着写一个函数获取某个基金的当前收益率:目前就获取最近3年的收益率。
import akshare as ak
def get_fund_info(code,name):
fund_open_fund_info_em_df = ak.fund_open_fund_info_em(symbol=code, indicator="累计收益率走势",period="3年")
latest_perf = fund_open_fund_info_em_df.iloc[-1]['累计收益率']
return {'code':code,'profit':latest_perf,'name':name}
可以改动period='5年', ’10年‘,’成立以来',从而获取不同区间的收益率
接着把500多个基金遍历一遍就OK了。
fund_perf_list = []
for item in js_data['Datas']:
print('processing code {}'.format(item['CODE']))
try:
fund_perf_list.append(get_fund_info(item['CODE'],item['NAME']))
time.sleep(0.5)
except Exception as e:
print('error in processing code {}'.format(item['CODE']))
print(e)
然后去倒杯茶,慢慢等它跑完。
数据分析
把数据转为dataframe,按照收益率排名
import pandas as pd
df = pd.DataFrame(fund_perf_list)
rank_df = df.sort_values(by='profit')
也可以导出到excel
rank_df.to_excel('亏麻的养老基金.xlsx')
亏损最多的鹏华养老产业股票,最近3年亏损了-53%,不过它应该也不属于养老基金范畴,只是买的养老产业的股票。
而华夏养老2055五年持有混合(FOF)A 011745,这种才是标准的养老基金,这些养老基金大部分是FOF(它们持有标的是基金,而不是股票)
2021年成立,买入后还要锁定5年,期间不可卖出,老人们被套牢了也无法割肉了。成立以来亏损了-34%,近3年亏损了-41%。
于是笔者继续过滤一下,找出里面的全部FOF基金
fof_fund_df = rank_df[rank_df['name'].str.contains('FOF')]
得到下面的养老基金FOF全部数据
然后使用describe函数看看大体的涨跌幅情况:
总共有484个数据,平均涨幅为-8.38%
中位数是-6.13%。
涨幅最大的是4.85%,中欧预见平衡养老三年持有混合发起(FOF)Y
打开详情一看,原来是得益于成立得晚的缘故,而该基金是今年2月成立的。
最近3年沪深300指数跌了32%,而这个跌幅可以在485只养老基金里面排到了477名。聊以慰藉的是,绝大部分的养老基金在下跌行情下是跑赢了沪深300的。
绘制直方图
直方图可以一览数据得养老基金涨跌幅分布情况:
fof_fund_df.plot(kind='hist',bins=20,y='profit',width=2,grid=True)
从图可以看到,大部分养老基金的涨跌幅落在-20到0之间。
亏损达到-30%以上的其实也不是很多。
整体来说,养老基金FOF比买入主流宽基波动要小一些,但并非保本的理财工具,对于风险接受能力低的老一辈朋友,需要慎重考虑的。
原文数据可在公众号:
可转债量化分析
获取
查看全部
不仅是散户被深套,很多基金也都大幅亏损。甚至前阵子看到证券时报报道,养老目标基金都出现不是清盘的现象。
于是笔者好奇心驱使,想看看这些养老基金最近几年的盈利情况,会不会把长辈老人们的下半辈子养老金都亏空了。
作为一名授人以渔的公众号博主,不仅仅贴个收益率图出来这么简单的啦。如果只是想看数据,直接跳过前面的操作即可。
笔者手把手教大家做数据分析,学会后不仅仅只对养老基金这一类别的基金做分析,还可以对不同类型的基金做分析。
前提:电脑按照了python已经相关库(jupyter notebook,pandas,akshare)
数据源:天天基金网
打开东财的天天基金网(https://fund.eastmoney.com/),在基金搜索页面输入:养老
总共有515个与养老相关的公募基金。如果没显示全,点击下图里面的“点击展开更多”按钮
抓包就找到对应的URL地址了,如下:https://fundsuggest.eastmoney.com/FundSearch/api/FundSearchPageAPI.ashx?callback=jQuery18306906210160165065_1721823304653&m=1&key=养老&pageindex=0&pagesize=515&_=1721823360126
如果你想分析其他类型的主题基金,只需要把上面的url里面的key=养老,换成其他的就可以了,比如 key=芯片
浏览器输入上面的URL就可以拿到数据了。
简单起见,我就不写爬取数据的代码,直接复制粘贴浏览器返回的内容就好了。
然后把前面起始的jQuery18306906210160165065_1721823304653( 和最后的括号去掉,就得到一个json数据了。
js_data = {
"ErrCode": 0,
"ErrMsg": "0",
"Datas": [
{
"_id": "001171",
"CODE": "001171",
"NAME": "工银养老产业股票A",
"STOCKMARKET": "",
"NEWTEXCH": ""
},
......... # 省略若干
]
}(文末提供这个数据文件的获取方式)
接着写一个函数获取某个基金的当前收益率:目前就获取最近3年的收益率。
import akshare as ak
def get_fund_info(code,name):
fund_open_fund_info_em_df = ak.fund_open_fund_info_em(symbol=code, indicator="累计收益率走势",period="3年")
latest_perf = fund_open_fund_info_em_df.iloc[-1]['累计收益率']
return {'code':code,'profit':latest_perf,'name':name}
可以改动period='5年', ’10年‘,’成立以来',从而获取不同区间的收益率
接着把500多个基金遍历一遍就OK了。
fund_perf_list = []
for item in js_data['Datas']:
print('processing code {}'.format(item['CODE']))
try:
fund_perf_list.append(get_fund_info(item['CODE'],item['NAME']))
time.sleep(0.5)
except Exception as e:
print('error in processing code {}'.format(item['CODE']))
print(e)
然后去倒杯茶,慢慢等它跑完。
数据分析
把数据转为dataframe,按照收益率排名
import pandas as pd
df = pd.DataFrame(fund_perf_list)
rank_df = df.sort_values(by='profit')
也可以导出到excel
rank_df.to_excel('亏麻的养老基金.xlsx')
亏损最多的鹏华养老产业股票,最近3年亏损了-53%,不过它应该也不属于养老基金范畴,只是买的养老产业的股票。
而华夏养老2055五年持有混合(FOF)A 011745,这种才是标准的养老基金,这些养老基金大部分是FOF(它们持有标的是基金,而不是股票)
2021年成立,买入后还要锁定5年,期间不可卖出,老人们被套牢了也无法割肉了。成立以来亏损了-34%,近3年亏损了-41%。
于是笔者继续过滤一下,找出里面的全部FOF基金
fof_fund_df = rank_df[rank_df['name'].str.contains('FOF')]
得到下面的养老基金FOF全部数据
然后使用describe函数看看大体的涨跌幅情况:
总共有484个数据,平均涨幅为-8.38%
中位数是-6.13%。
涨幅最大的是4.85%,中欧预见平衡养老三年持有混合发起(FOF)Y
打开详情一看,原来是得益于成立得晚的缘故,而该基金是今年2月成立的。
最近3年沪深300指数跌了32%,而这个跌幅可以在485只养老基金里面排到了477名。聊以慰藉的是,绝大部分的养老基金在下跌行情下是跑赢了沪深300的。
绘制直方图
直方图可以一览数据得养老基金涨跌幅分布情况:
fof_fund_df.plot(kind='hist',bins=20,y='profit',width=2,grid=True)
从图可以看到,大部分养老基金的涨跌幅落在-20到0之间。
亏损达到-30%以上的其实也不是很多。
整体来说,养老基金FOF比买入主流宽基波动要小一些,但并非保本的理财工具,对于风险接受能力低的老一辈朋友,需要慎重考虑的。
原文数据可在公众号:
可转债量化分析
获取
python识别股票K线形态,准确率回测(一)
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 1 个评论 • 13531 次浏览 • 2022-05-22 01:13
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)
做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
# pip install akshare
import akshare as ak
def get_k_line(code="sz002241"): #
df = ak.stock_zh_a_daily(symbol=code, start_date="20220101", end_date="20220515",
adjust="qfq")
# 这个函数只适合取股票数据,转债会报错,转债的日线数据可以使用其他函数,这里选择股价前复权
df.to_excel("同和药业k.xlsx")
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
date:交易日期
open:代表开盘价
high:当天最高价
low:当天最低价
close:当天收盘价
volume:当天成交量(元)
outstanding_share:流动股本(股)
turnover:换手率
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
#显示出来
plt.show()
运行此段代码后,会显示如下效果图:
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
import matplotlib.ticker as ticker
#将股票时间转换为标准时间,不带时分秒的数据
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.strptime(date, '%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
ax.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线
根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。
那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
def long_up_shadow(o,c,h,l):
return True if (h-c)/c >=0.07 and (h-o)/o>=0.07 else False
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
df = pd.read_excel("同和药业k.xlsx")
count_num = []
for row,item in df.iterrows():
if long_up_shadow(item['open'],item['close'],item['high'],item['low']):
count_num.append(row)
plot_image(df,count_num)
图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。
截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
df['tow_crows'] = talib.CDL2CROWS(df['open'].values, df['high'].values, df['low'].values, df['close'].values)
pattern = df[(df['tow_crows'] == 100) | (df['tow_crows'] == -100)]
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续) 查看全部
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)
做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
# pip install akshare
import akshare as ak
def get_k_line(code="sz002241"): #
df = ak.stock_zh_a_daily(symbol=code, start_date="20220101", end_date="20220515",
adjust="qfq")
# 这个函数只适合取股票数据,转债会报错,转债的日线数据可以使用其他函数,这里选择股价前复权
df.to_excel("同和药业k.xlsx")
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
date:交易日期
open:代表开盘价
high:当天最高价
low:当天最低价
close:当天收盘价
volume:当天成交量(元)
outstanding_share:流动股本(股)
turnover:换手率
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
#显示出来
plt.show()
运行此段代码后,会显示如下效果图:
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
import matplotlib.ticker as ticker
#将股票时间转换为标准时间,不带时分秒的数据
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.strptime(date, '%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
ax.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线
根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。
那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
def long_up_shadow(o,c,h,l):
return True if (h-c)/c >=0.07 and (h-o)/o>=0.07 else False
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
df = pd.read_excel("同和药业k.xlsx")
count_num = []
for row,item in df.iterrows():
if long_up_shadow(item['open'],item['close'],item['high'],item['low']):
count_num.append(row)
plot_image(df,count_num)图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。
截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
df['tow_crows'] = talib.CDL2CROWS(df['open'].values, df['high'].values, df['low'].values, df['close'].values)
pattern = df[(df['tow_crows'] == 100) | (df['tow_crows'] == -100)]
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续)
在2015年山顶5178点 开始定投所有大A股票 结果会是怎样?
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 3718 次浏览 • 2021-03-29 00:41
而事实真的是这样吗?
笔者使用2015年6月12日上一轮全面牛市的高点5178点,作为定投的起始点。而定投标的股票为大A所有股票。
股票池为2015年6月12日没有停牌的股票,共 2415 只。使用的量化平台是优矿。
(没错,以前股票数就才两千多只,这几年股票数接近翻倍了)def get_all_code(date):
'''
获取某天的股市运行的股票,排除停牌
'''
df=DataAPI.MktEqudAdjGet(secID=u"",ticker=u"",
tradeDate=date,
beginDate=u"",
endDate=u"",
isOpen="",
field=u"",
pandas="1")
df=df[df['turnoverValue']>0] # 停牌
return df['ticker'].tolist()
部分股票样本数据
接着从2015年6月12日开始定投,这里笔者按照一个月定投一次,也就是22个交易日定投一次。
每次定投金额10000元。定投到2021年3月28日。
如果定投当天遇到股票停牌,则顺势延续到复牌后继续定投。
这里定投采用净值法定投,为的是让数据更加准确。因为如果按照实际定投股票,10000元的金额可能连1手的茅台也买不进去,这里计算买入的份额为=10000元/股票股价, 比如茅台的股价是2000元,那么这里买入的份额就是5股,并没按照实际股票的1手来算。这样计算得到结果更加精准。
python计算代码如下: 1import time
2import datetime
3
4stock_profit_list=
5start=time.time()
6
7today=datetime.datetime.now().strftime('%Y-%m-%d')
8
9def get_trade_date():
10 df=DataAPI.TradeCalGet(exchangeCD=u"XSHG,XSHE",
11 beginDate=high_date,
12 endDate=today,isOpen=u"1",
13 field=u"",pandas="1")
14 return df['calendarDate'].tolist()
15
16def fixed_investment(code):
17 stock_profit_dict={}
18 stock_profit_dict['code']=code
19 df=DataAPI.MktEqudAdjGet(secID=u"",ticker=code,tradeDate=u'',beginDate=high_date,endDate=today,isOpen="1",field=u"",pandas="1")
20 total_amount=0
21 invest_count=0
22 every_invest_cash=10000
23 total_money_list=list()
24 last_date=None
25 for trade_date in trade_date_list_interval:
26 trade_df = df[df['tradeDate']==trade_date]
27 if len(trade_df)>0:
28 invest_count+=1
29 price=trade_df['closePrice'].iloc[0]
30 amount=every_invest_cash/price
31 cost=invest_count*every_invest_cash
32 profit=total_amount*price/cost
33 total_money_list.append(profit)
34 total_amount=total_amount+amount
35 total_money=price*total_amount
36 last_date=trade_date
37
38
39 stock_profit_dict['profit_rate']=profit
40 stock_profit_dict['last_date']=last_date
41 stock_profit_dict['invest_count']=invest_count
42 stock_profit_dict['total_amount']=total_amount
43 stock_profit_dict['total_money']=total_money
44 stock_profit_dict['profit_list']=total_money_list
45 stock_profit_dict['cost']=cost
46 return stock_profit_dict
47
48for code in target_codes:
49 profit_dict = fixed_investment(code)
50 stock_profit_list.append(profit_dict)
51
52print(time.time()-start)
最终得到的数据保存在stock_profit_list变量里面。在计算过程也记录里每一个股票当前一期定投阶段的阶段收益率,组合成一个列表。
为的是倒后镜看看,曾经的历史定投收益率,也可以看看曾经的历史定投收益率的最大值。便于和现在最后一期收益率的对比。
得到数据按照profit_rate收益率排个序:profi_df_sorted = profit_df.sort_values(by='profit_rate',ascending=False)
得到下面的数据:
上面的股票熟悉不?基本都是年初那一批基金ikun们的抱团股。
定投收益率最高的是山西汾酒,收益率达到8.56,即856%,从股灾高点定投下来,到现在2021年3月28日,收益率是8倍!
其月K线如下:
牛气冲天的5年十倍股,股灾时山西汾酒的股价徘徊在21-26之间左右。如果股灾的时候采用一把梭,收益率是336/26=12.9 倍。
而采用定投方式的收益率也不差,8.56倍。
再继续看看定投收益排在倒数的
真是好家伙,亏得底裤都不见了。清一色的退市股,定投收益率基本在0.1以下,意味着投资了100元,最后就剩10元以下。
在前面计算的时候,特意加了一个数据列,定投期数和定投停止日期,也就是股票退市或者停牌导致无法交易的日子。
invest_count为定投期数,定投一次此值加1. last_date 为最后一个交易日期。倒数第一个国恒退,只交易1期,7月10日退市,等不来第2期的定投,不过也好,这样子只也不至于越陷越深。
国恒退日K
total_money 列是投资得到总金额,cost是投入的成本。投资期数越多,随着股价上涨,该金额会越高,而股价不断下跌,则该金额会越来越少。所以遇到国恒退这种股票,当期只投了10000元就无法继续投下去,还是运气比较好的。类似于止损操作了。
toal_money减去cost得到的是绝对收益。之前因为没有加这一列,可以通过以下公式计算得到:profit_df['absolute_profit']=profit_df['total_money']-profit_df['cost']
按绝对收益计算,最多的还是前面那20位个股,赚最多的山西汾酒,129W的定投金额,盈利金额达到900W。
同样倒序排一下,绝对亏损最多的,肯定也是定投期数较多的。
[图片]
亏损最多的天夏退,目前还没有完全退市,定投了114期,总亏损金额达到100W,定投总金额是110W。额,只剩10W。
它的月K线是这样的。其跌到4元多的时候还放量了,可能一堆人冲进去抄底了,然后按亏损幅度,4元跌到0.22元,亏损幅度也是94.5%,这个亏损幅度其实和在山顶29元站岗的亏损率其实没什么区别了。高手死于抄底,呵呵。
接着看看上面所有股票的定投的平均收益率:profi_df_sorted['profit_rate'].mean()
得到的收益率的平均值为:1.043,减去本金1,收益为1.043-1=0.043,也就是4.3%个点。
换句话说,如果在股票高点5178点定投全市场股票,5年多来的最后收益率为4.3%.
中位数是0.87-1=-0.13,= -13%,中位数是亏损13%,定投金额约126W,亏损金额为14W。
看到这里,笔者想要表述的是,即使是定投也需要挑选一个好标的股票或者基金,也就是择股择时能力。
如果在一个垃圾股或者基金上定投,只会让你越陷越深,亏损越来越多。假如你在定投康得新或者乐视,定投了100期,投入了不少的金额和时间,突然暴雷,然后ST,那么你会继续定投下去吗?
另外,定投也需要一定的择时能力,比如在前春节前,基金抱团股热度不减,对于大部分没有择股能力的人来说,当时是应该止盈离场的。当然,如果倒后镜看,如果有能力抓取上面的大牛股,也不一定能够把上面的8倍收益落袋而安。
上面数据有一列max_profit,total_money/cost, 也就是定投期间,获得的最大收益率。按此列排序:
在定投期间,最大收益率的是ST中安,最大收益率是14.6-1=13.6倍。最后到这个月最终定投收益率是0.67,亏损状态,0.67-1=-0.37,亏损为-37%,绝对收益absolute_profit为-29W.
排在第4是是乐视退,定投期间最大收益max_profit达到10倍,最后如果坚持定投,是亏损93%的。
如果把定投时间放在2018年1月12日,那么得到的定投收益率排名前20名是这样的:
得到不一样的前20排名,定投收益率最高的是英科医疗,疫情手套涨了10倍的大牛股。而山西汾酒跌到第10,并且收益率也只有4倍左右。而茅台也没出现在前20的榜单上。
不同的定投时间,得到的是不一样的结果。当然择股能力强的大神,就不屑定投而采用一把梭了,大神向往的是英科医疗的一年十倍,而不是十年十倍(大V组合抱团,抱团基金的组合)。
其改变定投时间的定投收益率的平均值以及中位数数据如下:
平均收益率达到了1.14-1=0.14=14%,也就是如果你在18年开始定投全市场股票,当前平均收益率是14%,不过中位数的收益率是1-1=0%,因为这两年股票大小票分化得太严重(24%的个股跌破2440的低点,指数涨41%),四分一分位的定投收益率为27%,到了中位数就为0%了。其定投收益率较2015年山顶定投也有了很大的区别。
今天就到这里吧,感觉文章太长了,本来还想把全市场的基金加进来比较的(不同时间点定投全市场所有基金),碍于篇幅原因,留在下一篇再写吧,敬请留意!
微信公众号:
可转债量化分析
查看全部
而事实真的是这样吗?
笔者使用2015年6月12日上一轮全面牛市的高点5178点,作为定投的起始点。而定投标的股票为大A所有股票。
股票池为2015年6月12日没有停牌的股票,共 2415 只。使用的量化平台是优矿。
(没错,以前股票数就才两千多只,这几年股票数接近翻倍了)
def get_all_code(date):
'''
获取某天的股市运行的股票,排除停牌
'''
df=DataAPI.MktEqudAdjGet(secID=u"",ticker=u"",
tradeDate=date,
beginDate=u"",
endDate=u"",
isOpen="",
field=u"",
pandas="1")
df=df[df['turnoverValue']>0] # 停牌
return df['ticker'].tolist()
部分股票样本数据
接着从2015年6月12日开始定投,这里笔者按照一个月定投一次,也就是22个交易日定投一次。
每次定投金额10000元。定投到2021年3月28日。
如果定投当天遇到股票停牌,则顺势延续到复牌后继续定投。
这里定投采用净值法定投,为的是让数据更加准确。因为如果按照实际定投股票,10000元的金额可能连1手的茅台也买不进去,这里计算买入的份额为=10000元/股票股价, 比如茅台的股价是2000元,那么这里买入的份额就是5股,并没按照实际股票的1手来算。这样计算得到结果更加精准。
python计算代码如下:
1import time
2import datetime
3
4stock_profit_list=
5start=time.time()
6
7today=datetime.datetime.now().strftime('%Y-%m-%d')
8
9def get_trade_date():
10 df=DataAPI.TradeCalGet(exchangeCD=u"XSHG,XSHE",
11 beginDate=high_date,
12 endDate=today,isOpen=u"1",
13 field=u"",pandas="1")
14 return df['calendarDate'].tolist()
15
16def fixed_investment(code):
17 stock_profit_dict={}
18 stock_profit_dict['code']=code
19 df=DataAPI.MktEqudAdjGet(secID=u"",ticker=code,tradeDate=u'',beginDate=high_date,endDate=today,isOpen="1",field=u"",pandas="1")
20 total_amount=0
21 invest_count=0
22 every_invest_cash=10000
23 total_money_list=list()
24 last_date=None
25 for trade_date in trade_date_list_interval:
26 trade_df = df[df['tradeDate']==trade_date]
27 if len(trade_df)>0:
28 invest_count+=1
29 price=trade_df['closePrice'].iloc[0]
30 amount=every_invest_cash/price
31 cost=invest_count*every_invest_cash
32 profit=total_amount*price/cost
33 total_money_list.append(profit)
34 total_amount=total_amount+amount
35 total_money=price*total_amount
36 last_date=trade_date
37
38
39 stock_profit_dict['profit_rate']=profit
40 stock_profit_dict['last_date']=last_date
41 stock_profit_dict['invest_count']=invest_count
42 stock_profit_dict['total_amount']=total_amount
43 stock_profit_dict['total_money']=total_money
44 stock_profit_dict['profit_list']=total_money_list
45 stock_profit_dict['cost']=cost
46 return stock_profit_dict
47
48for code in target_codes:
49 profit_dict = fixed_investment(code)
50 stock_profit_list.append(profit_dict)
51
52print(time.time()-start)
最终得到的数据保存在stock_profit_list变量里面。在计算过程也记录里每一个股票当前一期定投阶段的阶段收益率,组合成一个列表。
为的是倒后镜看看,曾经的历史定投收益率,也可以看看曾经的历史定投收益率的最大值。便于和现在最后一期收益率的对比。
得到数据按照profit_rate收益率排个序:
profi_df_sorted = profit_df.sort_values(by='profit_rate',ascending=False)
得到下面的数据:
上面的股票熟悉不?基本都是年初那一批基金ikun们的抱团股。
定投收益率最高的是山西汾酒,收益率达到8.56,即856%,从股灾高点定投下来,到现在2021年3月28日,收益率是8倍!
其月K线如下:
牛气冲天的5年十倍股,股灾时山西汾酒的股价徘徊在21-26之间左右。如果股灾的时候采用一把梭,收益率是336/26=12.9 倍。
而采用定投方式的收益率也不差,8.56倍。
再继续看看定投收益排在倒数的
真是好家伙,亏得底裤都不见了。清一色的退市股,定投收益率基本在0.1以下,意味着投资了100元,最后就剩10元以下。
在前面计算的时候,特意加了一个数据列,定投期数和定投停止日期,也就是股票退市或者停牌导致无法交易的日子。
invest_count为定投期数,定投一次此值加1. last_date 为最后一个交易日期。倒数第一个国恒退,只交易1期,7月10日退市,等不来第2期的定投,不过也好,这样子只也不至于越陷越深。
国恒退日K
total_money 列是投资得到总金额,cost是投入的成本。投资期数越多,随着股价上涨,该金额会越高,而股价不断下跌,则该金额会越来越少。所以遇到国恒退这种股票,当期只投了10000元就无法继续投下去,还是运气比较好的。类似于止损操作了。
toal_money减去cost得到的是绝对收益。之前因为没有加这一列,可以通过以下公式计算得到:
profit_df['absolute_profit']=profit_df['total_money']-profit_df['cost']
按绝对收益计算,最多的还是前面那20位个股,赚最多的山西汾酒,129W的定投金额,盈利金额达到900W。
同样倒序排一下,绝对亏损最多的,肯定也是定投期数较多的。
[图片]
亏损最多的天夏退,目前还没有完全退市,定投了114期,总亏损金额达到100W,定投总金额是110W。额,只剩10W。
它的月K线是这样的。其跌到4元多的时候还放量了,可能一堆人冲进去抄底了,然后按亏损幅度,4元跌到0.22元,亏损幅度也是94.5%,这个亏损幅度其实和在山顶29元站岗的亏损率其实没什么区别了。高手死于抄底,呵呵。
接着看看上面所有股票的定投的平均收益率:
profi_df_sorted['profit_rate'].mean()得到的收益率的平均值为:1.043,减去本金1,收益为1.043-1=0.043,也就是4.3%个点。
换句话说,如果在股票高点5178点定投全市场股票,5年多来的最后收益率为4.3%.
中位数是0.87-1=-0.13,= -13%,中位数是亏损13%,定投金额约126W,亏损金额为14W。
看到这里,笔者想要表述的是,即使是定投也需要挑选一个好标的股票或者基金,也就是择股择时能力。
如果在一个垃圾股或者基金上定投,只会让你越陷越深,亏损越来越多。假如你在定投康得新或者乐视,定投了100期,投入了不少的金额和时间,突然暴雷,然后ST,那么你会继续定投下去吗?
另外,定投也需要一定的择时能力,比如在前春节前,基金抱团股热度不减,对于大部分没有择股能力的人来说,当时是应该止盈离场的。当然,如果倒后镜看,如果有能力抓取上面的大牛股,也不一定能够把上面的8倍收益落袋而安。
上面数据有一列max_profit,total_money/cost, 也就是定投期间,获得的最大收益率。按此列排序:
在定投期间,最大收益率的是ST中安,最大收益率是14.6-1=13.6倍。最后到这个月最终定投收益率是0.67,亏损状态,0.67-1=-0.37,亏损为-37%,绝对收益absolute_profit为-29W.
排在第4是是乐视退,定投期间最大收益max_profit达到10倍,最后如果坚持定投,是亏损93%的。
如果把定投时间放在2018年1月12日,那么得到的定投收益率排名前20名是这样的:
得到不一样的前20排名,定投收益率最高的是英科医疗,疫情手套涨了10倍的大牛股。而山西汾酒跌到第10,并且收益率也只有4倍左右。而茅台也没出现在前20的榜单上。
不同的定投时间,得到的是不一样的结果。当然择股能力强的大神,就不屑定投而采用一把梭了,大神向往的是英科医疗的一年十倍,而不是十年十倍(大V组合抱团,抱团基金的组合)。
其改变定投时间的定投收益率的平均值以及中位数数据如下:
平均收益率达到了1.14-1=0.14=14%,也就是如果你在18年开始定投全市场股票,当前平均收益率是14%,不过中位数的收益率是1-1=0%,因为这两年股票大小票分化得太严重(24%的个股跌破2440的低点,指数涨41%),四分一分位的定投收益率为27%,到了中位数就为0%了。其定投收益率较2015年山顶定投也有了很大的区别。
今天就到这里吧,感觉文章太长了,本来还想把全市场的基金加进来比较的(不同时间点定投全市场所有基金),碍于篇幅原因,留在下一篇再写吧,敬请留意!
微信公众号:
可转债量化分析
bandcamp移动开发更简单
数据库 • linxiaojue 发表了文章 • 0 个评论 • 4779 次浏览 • 2019-12-14 05:12
http://TalkingData.bandcamp.com/
http://Bugly.bandcamp.com/
http://Box2D.bandcamp.com/
http://aineice.bandcamp.com/
http://wyyp.bandcamp.com/
http://Prepo.bandcamp.com/
http://Chipmunk.bandcamp.com/
http://openinstall.bandcamp.com/
http://MobileInsight.bandcamp.com/
http://zhugelo.bandcamp.com/
http://CobubRazor.bandcamp.com/
http://Testin.bandcamp.com/
http://crashlytics.bandcamp.com/
http://APKProtect.bandcamp.com/
http://Ucloud.bandcamp.com/
http://ydkfpgj.bandcamp.com/releases
http://TalkingData.bandcamp.com/releases
http://Bugly.bandcamp.com/releases
http://Box2D.bandcamp.com/releases
http://aineice.bandcamp.com/releases
http://wyyp.bandcamp.com/releases
http://Prepo.bandcamp.com/releases
http://Chipmunk.bandcamp.com/releases
http://openinstall.bandcamp.com/releases
http://MobileInsight.bandcamp.com/releases
http://zhugelo.bandcamp.com/releases
http://CobubRazor.bandcamp.com/releases
http://Testin.bandcamp.com/releases
http://crashlytics.bandcamp.com/releases
http://APKProtect.bandcamp.com/releases
http://Ucloud.bandcamp.com/releases 查看全部
http://TalkingData.bandcamp.com/
http://Bugly.bandcamp.com/
http://Box2D.bandcamp.com/
http://aineice.bandcamp.com/
http://wyyp.bandcamp.com/
http://Prepo.bandcamp.com/
http://Chipmunk.bandcamp.com/
http://openinstall.bandcamp.com/
http://MobileInsight.bandcamp.com/
http://zhugelo.bandcamp.com/
http://CobubRazor.bandcamp.com/
http://Testin.bandcamp.com/
http://crashlytics.bandcamp.com/
http://APKProtect.bandcamp.com/
http://Ucloud.bandcamp.com/
http://ydkfpgj.bandcamp.com/releases
http://TalkingData.bandcamp.com/releases
http://Bugly.bandcamp.com/releases
http://Box2D.bandcamp.com/releases
http://aineice.bandcamp.com/releases
http://wyyp.bandcamp.com/releases
http://Prepo.bandcamp.com/releases
http://Chipmunk.bandcamp.com/releases
http://openinstall.bandcamp.com/releases
http://MobileInsight.bandcamp.com/releases
http://zhugelo.bandcamp.com/releases
http://CobubRazor.bandcamp.com/releases
http://Testin.bandcamp.com/releases
http://crashlytics.bandcamp.com/releases
http://APKProtect.bandcamp.com/releases
http://Ucloud.bandcamp.com/releases
numpy indices的用法
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 10431 次浏览 • 2019-07-08 17:58
M_ij = 2*i + 3*j
One way to define this matrix would be
i, j = np.indices((2,3))
M = 2*i + 3*j
which yields
array([[0, 3, 6],
[2, 5, 8]])
In other words, np.indices returns arrays which can be used as indices. The elements in i indicate the row index:
In [12]: i
Out[12]:
array([[0, 0, 0],
[1, 1, 1]])
The elements in j indicate the column index:
In [13]: j
Out[13]:
array([[0, 1, 2],
[0, 1, 2]])
上面是Stack Overflow的解释。 翻译一下:
np.indices((2,3))
返回的是一个行列的索引,然后可以用这个索引快速的创建二维数据。
比如我要画一个圆:
img = np.zeros((400,400))
ir,ic = np.indices(img.shape)
circle = (ir-135)**2+(ic-150)**2 < 30**2 # 半径30,圆心在135,150
img[circle]=1
img现在就是一个圆啦
查看全部
Suppose you have a matrix M whose (i,j)-th element equals
M_ij = 2*i + 3*j
One way to define this matrix would be
i, j = np.indices((2,3))
M = 2*i + 3*j
which yields
array([[0, 3, 6],
[2, 5, 8]])
In other words, np.indices returns arrays which can be used as indices. The elements in i indicate the row index:
In [12]: i
Out[12]:
array([[0, 0, 0],
[1, 1, 1]])
The elements in j indicate the column index:
In [13]: j
Out[13]:
array([[0, 1, 2],
[0, 1, 2]])
上面是Stack Overflow的解释。 翻译一下:
np.indices((2,3))
返回的是一个行列的索引,然后可以用这个索引快速的创建二维数据。
比如我要画一个圆:
img = np.zeros((400,400))
ir,ic = np.indices(img.shape)
circle = (ir-135)**2+(ic-150)**2 < 30**2 # 半径30,圆心在135,150
img[circle]=1
img现在就是一个圆啦
修改easytrader国金证券的默认启动路径
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 6045 次浏览 • 2019-06-17 10:23
pywinauto.application.AppStartError: Could not create the process "C:\全能行证券交易终端\xiadan.exe"
Error returned by CreateProcess: (2, 'CreateProcess', '系统找不到指定的文件。')
看了配置文件,也是没有具体的参数可以修改,只好修改源代码。
别听到改源代码就害怕,只是需要改一行就可以了。
找到文件:
site-package\easytrader\config\client.py
找过这一行:
class GJ(CommonConfig):
DEFAULT_EXE_PATH = "C:\\Tool\\xiadan.exe"只要修改上面的路径就可以了。注意用双斜杠。
查看全部
pywinauto.application.AppStartError: Could not create the process "C:\全能行证券交易终端\xiadan.exe"
Error returned by CreateProcess: (2, 'CreateProcess', '系统找不到指定的文件。')
看了配置文件,也是没有具体的参数可以修改,只好修改源代码。
别听到改源代码就害怕,只是需要改一行就可以了。
找到文件:
site-package\easytrader\config\client.py
找过这一行:
class GJ(CommonConfig):只要修改上面的路径就可以了。注意用双斜杠。
DEFAULT_EXE_PATH = "C:\\Tool\\xiadan.exe"
jupyter notebook格式的文件损坏如何修复
python • 李魔佛 发表了文章 • 0 个评论 • 6204 次浏览 • 2019-06-08 13:44
使用下面的代码:
# 拯救损坏的jupyter 文件
import re
import codecs
pattern = re.compile('"source": \[(.*?)\]\s+\},',re.S)
filename = 'tushare_usage.ipynb'
with codecs.open(filename,encoding='utf8') as f:
content = f.read()
source = pattern.findall(content)
for s in source:
t=s.replace('\\n','')
t=re.sub('"','',t)
t=re.sub('(,$)','',t)
print(t)只要把你要修复的文件替换一下就可以了。 查看全部
使用下面的代码:
# 拯救损坏的jupyter 文件只要把你要修复的文件替换一下就可以了。
import re
import codecs
pattern = re.compile('"source": \[(.*?)\]\s+\},',re.S)
filename = 'tushare_usage.ipynb'
with codecs.open(filename,encoding='utf8') as f:
content = f.read()
source = pattern.findall(content)
for s in source:
t=s.replace('\\n','')
t=re.sub('"','',t)
t=re.sub('(,$)','',t)
print(t)
python数据分析之 A股上市公司按地区分布与可视化 地图显示
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 10700 次浏览 • 2018-12-19 14:07
地区 数目
浙江 431
江苏 401
北京 316
广东 303
上海 285
深圳 283
山东 196
福建 132
四川 120
湖南 104
安徽 103
湖北 101
河南 79
辽宁 72
河北 56
新疆 54
天津 50
陕西 49
重庆 48
吉林 41
江西 41
山西 38
黑龙江 37
广西 37
云南 33
甘肃 33
海南 31
贵州 29
内蒙 25
西藏 18
宁夏 13
青海 12
看看我们的641主席的功劳,江浙一带的上市公司数量已经超过广东了。
接下来我们使用pandas进行数据可视化:
首先读入数据:# A股上市公司分布:
df = pd.read_sql('tb_basic_info',con=engine)engine为from sqlalchemy import create_engine 中的连接引擎。
然后直接统计:result = df['area'].value_counts()得到的result就是统计结果:
看是不是比mysql语句简单多了?
得到一样的数据。
接下来使用图像来显示我们的数据:
什么? 一条命令就可以啦~ 实在太强大了!
从这个柱状图上,可以更加直观地看到A股上市公司的分布情况,东部长三角和珠三角的公司数目最多。而西部只有东部的零头。
接着把数据转化为百分比数据:total = result.sum()
ration = result/total*100
可以看到江浙地区占了22%的数量,体量还是很大的。
接下来,为了数据更加直观,把数据在地图上显示出来:
点击查看大图
颜色越红,表明上市公司越多。现在数据够直观了吧。
实现代码:# 热力图
def create_heatmap(attr,value,name,maptype):
style = Style(title_color="#fff", title_pos="center",
width=1200, height=600, background_color="#696969")
# 可视化
geo = Geo(name,**style.init_style)
geo.add("", attr, value, visual_range=[min(value), max(value)], symbol_size=8,
visual_text_color="#000",
is_visualmap=True, type='effectScatter',effect_scale=7,is_random=True,is_roam=False,is_piecewise = True,visual_split_number= 10,
)
geo.render('{}.html'.format(name)) create_heatmap(attr,value,'公司分布','china')
更多的数据分析,请关注本网站。
不定期更新哦
原创文章
转载请注明出处:
http://30daydo.com/article/388
查看全部
SELECT area `地区`,count(*) as `数目` FROM `tb_basic_info` GROUP BY area order by 数目 desc;得到下面的结果: 接着我们使用pandas进行数据可视化。
地区 数目
浙江 431
江苏 401
北京 316
广东 303
上海 285
深圳 283
山东 196
福建 132
四川 120
湖南 104
安徽 103
湖北 101
河南 79
辽宁 72
河北 56
新疆 54
天津 50
陕西 49
重庆 48
吉林 41
江西 41
山西 38
黑龙江 37
广西 37
云南 33
甘肃 33
海南 31
贵州 29
内蒙 25
西藏 18
宁夏 13
青海 12
看看我们的641主席的功劳,江浙一带的上市公司数量已经超过广东了。
接下来我们使用pandas进行数据可视化:
首先读入数据:
# A股上市公司分布:engine为from sqlalchemy import create_engine 中的连接引擎。
df = pd.read_sql('tb_basic_info',con=engine)
然后直接统计:
result = df['area'].value_counts()得到的result就是统计结果:
看是不是比mysql语句简单多了?
得到一样的数据。
接下来使用图像来显示我们的数据:
什么? 一条命令就可以啦~ 实在太强大了!
从这个柱状图上,可以更加直观地看到A股上市公司的分布情况,东部长三角和珠三角的公司数目最多。而西部只有东部的零头。
接着把数据转化为百分比数据:
total = result.sum()
ration = result/total*100
可以看到江浙地区占了22%的数量,体量还是很大的。
接下来,为了数据更加直观,把数据在地图上显示出来:
点击查看大图
颜色越红,表明上市公司越多。现在数据够直观了吧。
实现代码:
# 热力图
def create_heatmap(attr,value,name,maptype):
style = Style(title_color="#fff", title_pos="center",
width=1200, height=600, background_color="#696969")
# 可视化
geo = Geo(name,**style.init_style)
geo.add("", attr, value, visual_range=[min(value), max(value)], symbol_size=8,
visual_text_color="#000",
is_visualmap=True, type='effectScatter',effect_scale=7,is_random=True,is_roam=False,is_piecewise = True,visual_split_number= 10,
)
geo.render('{}.html'.format(name))
create_heatmap(attr,value,'公司分布','china')
更多的数据分析,请关注本网站。
不定期更新哦
原创文章
转载请注明出处:
http://30daydo.com/article/388