
火币登录时提示 谷歌验证码错误 无法登录
安全器使用的时谷歌身份验证器,反复登录几次后一直提示谷歌验证码错误,,请重新输入。
难度凉凉了吗??
和客服聊了下,只好解绑。或者用app登录
难度凉凉了吗??
和客服聊了下,只好解绑。或者用app登录
贝壳左晖一生的评价?
本人不算有钱,总共出手过三套房产,
成都市的。
成都去年年底到今年的二手房大涨,
明显是资本在推
贝壳就是其中很大的推手。
我在去年12月给贝壳打电话,
告诉他们我有房子要出手,
当时小区的成交价格大概是230万上下。
我跟中介说明情况以后,他问我着不着急卖,
我问他什么意思。
他告诉我可以挂高价,
建议我挂个255,说是有议价空间。
后面我才明白过来,搁这儿玩滚动出货呢。
诚心卖急用钱的房东,中介会压低他们的价格,
促进成交。
而我这样的,就给人当绿叶,掩护低价房源出手。
实际上就是贝壳和部分房东联手做局,
抬高价格,买家有些是刚需,只能硬着头皮上。
某朋友系列。
这是某位朋友的体会。
然后知乎,雪球上一些大佬为左晖洗白。尤其雪球的方丈,以为自己说的都是正义的。
这典型的屁股决定脑袋,说现在的年轻人戾气很重,哎。
如果这些大佬想想,现在的90后,996工作,然后蜗居在自如的甲醛房子里面,然后月底收到自如的涨价通知。
看着高企的房价,人生似乎也没什么盼头。
然后网上键盘侠一下哎,也不行呀,他们也挺难的。
收起阅读 »
成都市的。
成都去年年底到今年的二手房大涨,
明显是资本在推
贝壳就是其中很大的推手。
我在去年12月给贝壳打电话,
告诉他们我有房子要出手,
当时小区的成交价格大概是230万上下。
我跟中介说明情况以后,他问我着不着急卖,
我问他什么意思。
他告诉我可以挂高价,
建议我挂个255,说是有议价空间。
后面我才明白过来,搁这儿玩滚动出货呢。
诚心卖急用钱的房东,中介会压低他们的价格,
促进成交。
而我这样的,就给人当绿叶,掩护低价房源出手。
实际上就是贝壳和部分房东联手做局,
抬高价格,买家有些是刚需,只能硬着头皮上。
某朋友系列。
这是某位朋友的体会。
然后知乎,雪球上一些大佬为左晖洗白。尤其雪球的方丈,以为自己说的都是正义的。
这典型的屁股决定脑袋,说现在的年轻人戾气很重,哎。
如果这些大佬想想,现在的90后,996工作,然后蜗居在自如的甲醛房子里面,然后月底收到自如的涨价通知。
看着高企的房价,人生似乎也没什么盼头。
然后网上键盘侠一下哎,也不行呀,他们也挺难的。
收起阅读 »
折腾了半天,结果发现windows上无法使用redis 布隆过滤器插件
运行实例代码:
# Using Bloom Filter from redisbloom.client import Client rb = Client() rb.bfCreate('bloom', 0.01, 1000) rb.bfAdd('bloom', 'foo') # returns 1 rb.bfAdd('bloom', 'foo') # returns 0 rb.bfExists('bloom', 'foo') # returns 1 rb.bfExists('bloom', 'noexist') # returns 0
报错:
redis.exceptions.ResponseError: unknown command BF.RESERVE, with args beginning with: bloom, 0.01, 1000
连docker上得镜像也不支持。
更别说windows版本上的redis按照插件了。
只好用linux的docker了。
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
收起阅读 »
# Using Bloom Filter from redisbloom.client import Client rb = Client() rb.bfCreate('bloom', 0.01, 1000) rb.bfAdd('bloom', 'foo') # returns 1 rb.bfAdd('bloom', 'foo') # returns 0 rb.bfExists('bloom', 'foo') # returns 1 rb.bfExists('bloom', 'noexist') # returns 0
报错:
redis.exceptions.ResponseError: unknown command BF.RESERVE, with args beginning with: bloom, 0.01, 1000
连docker上得镜像也不支持。
更别说windows版本上的redis按照插件了。
只好用linux的docker了。
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
收起阅读 »
PI币邀请码:yagamizsu
输入邀请码才能继续注册哦
邀请码:yagamizsu
用邀请码注册后会获得几个PI币。
邀请码:yagamizsu
用邀请码注册后会获得几个PI币。
coinegg.fun coinegg币蛋真垃圾 入金最低要10000

点击查看大图
请在10000-1000000之间设置金额。。。
这样子玩,迟早没有人气的了。韭菜都去了隔壁火币平台了。
火币邀请码:9dsub
或者点击链接开户:https://www.huobi.pe/zh-cn/topic/invited/?invite_code=9dsub
最近行情火爆,可以进场捞一笔就走。
注意,所有币都是空气,进去的人都是赌徒。如果你觉得你赌术高明,那么你就可以试试。
火币邀请码:9dsub
火币邀请码有什么用?
对于新用户,没什么用的。而对于邀请别人的人,可以获取200个火苗,说实话,这个玩意我也不知道有啥用。
官方的奖励:
1、好友接受邀请后,每产生一笔真实交易手续费,会产生相应比例的奖励。
2、奖励的形式以USDT或点卡或HT的形式发放到您的交易账户,USDT奖励比例为30%,点卡奖励比例为30%,HT奖励比例为30%。
3、被邀请人使用点卡交易时,邀请人实际获得的奖励将以等额的点数进行计算后发给邀请人;被邀请人使用非点卡交易且手续费为HT时,邀请人实际获得的奖励将以HT进行计算后发给邀请人;被邀请人使用非点卡交易且手续费不为HT时,邀请人实际获得的奖励将以USDT进行折合计算后发给邀请人。
4、好友交易奖励当日统计,次日晚到账;奖励额(USDT或点卡或HT)= 实际产生交易量 * 手续费比例*奖励比例。
5、邀请人享受好友交易返佣有效时长以被邀请人实际注册的时间开始进行计算,到达有效时长(730天)后您将不享受该邀请人交易产生手续费的返佣。
6、平台将以每5分钟取一次市价进行相应币种的USDT实时换算,奖励金额以实际奖励金额为准。
7、每月1号月度榜单只可以看到上月数据。
8、每日结算时间为:0:00;打款时间为次日晚十点前。
9、充提币手续费,杠杆利息不参与手续费奖励。
10、如被邀请人违反邀请奖励的相应风控规则,其手续费将不能发放给邀请人,同时,被邀请人的邀请状态变成【已无效】并且产生的奖励记录状态变成【奖励无效】。
11、单一被邀请人奖励上限为5000USDT(点卡价值与USDT锚定1:1,HT按交易时市价折合USDT),无被邀请人数量上限。
12、如有深度渠道合作意向,请联系app@huobi.com,邮件需包含火币UID、展业国家和地区、自有资源背景、简要展业计划、自我介绍、个人微信或手机号等信息。
活动如有调整,以火币全球站平台更新为准,最终解释权归火币全球站所有。
收起阅读 »
最近行情火爆,可以进场捞一笔就走。
注意,所有币都是空气,进去的人都是赌徒。如果你觉得你赌术高明,那么你就可以试试。
火币邀请码:9dsub
火币邀请码有什么用?
对于新用户,没什么用的。而对于邀请别人的人,可以获取200个火苗,说实话,这个玩意我也不知道有啥用。
官方的奖励:
1、好友接受邀请后,每产生一笔真实交易手续费,会产生相应比例的奖励。
2、奖励的形式以USDT或点卡或HT的形式发放到您的交易账户,USDT奖励比例为30%,点卡奖励比例为30%,HT奖励比例为30%。
3、被邀请人使用点卡交易时,邀请人实际获得的奖励将以等额的点数进行计算后发给邀请人;被邀请人使用非点卡交易且手续费为HT时,邀请人实际获得的奖励将以HT进行计算后发给邀请人;被邀请人使用非点卡交易且手续费不为HT时,邀请人实际获得的奖励将以USDT进行折合计算后发给邀请人。
4、好友交易奖励当日统计,次日晚到账;奖励额(USDT或点卡或HT)= 实际产生交易量 * 手续费比例*奖励比例。
5、邀请人享受好友交易返佣有效时长以被邀请人实际注册的时间开始进行计算,到达有效时长(730天)后您将不享受该邀请人交易产生手续费的返佣。
6、平台将以每5分钟取一次市价进行相应币种的USDT实时换算,奖励金额以实际奖励金额为准。
7、每月1号月度榜单只可以看到上月数据。
8、每日结算时间为:0:00;打款时间为次日晚十点前。
9、充提币手续费,杠杆利息不参与手续费奖励。
10、如被邀请人违反邀请奖励的相应风控规则,其手续费将不能发放给邀请人,同时,被邀请人的邀请状态变成【已无效】并且产生的奖励记录状态变成【奖励无效】。
11、单一被邀请人奖励上限为5000USDT(点卡价值与USDT锚定1:1,HT按交易时市价折合USDT),无被邀请人数量上限。
12、如有深度渠道合作意向,请联系app@huobi.com,邮件需包含火币UID、展业国家和地区、自有资源背景、简要展业计划、自我介绍、个人微信或手机号等信息。
活动如有调整,以火币全球站平台更新为准,最终解释权归火币全球站所有。
收起阅读 »
pyautogui无法再远程桌面最小化或者断线后进行截图
搜索了一圈,似乎无解。
知道的朋友可以私信下我。
国外的论坛也找不到答案,只能一直开着屏幕了。。。。
知道的朋友可以私信下我。
国外的论坛也找不到答案,只能一直开着屏幕了。。。。
pyppeteer 在AppData下的dev_profile 生成大量文件
具体路径在:
C:\Users\xda\AppData\Local\pyppeteer\pyppeteer\.dev_profile
运行次数多了,这个目录下积累了几十个G的文件。

因为每次启动pyppeteer后,如果不指定userData目录,会在dev_profile生成一个新的userData目录,每次大概30MB左右的打小,所以启动的次数,越多,这个文件夹的体积就越大。
其实可以直接删除,然后启动pyppeteer是加上一个参数:userDataDir
这样每次pyppeteer都会用同一个配置文件,并且还可以把cookies,session文件存在同一个地方,如果登录过的网站,下次可以直接登录,不需要再次输入账号密码。
收起阅读 »
C:\Users\xda\AppData\Local\pyppeteer\pyppeteer\.dev_profile
运行次数多了,这个目录下积累了几十个G的文件。
因为每次启动pyppeteer后,如果不指定userData目录,会在dev_profile生成一个新的userData目录,每次大概30MB左右的打小,所以启动的次数,越多,这个文件夹的体积就越大。
其实可以直接删除,然后启动pyppeteer是加上一个参数:userDataDir
browser = await pyppeteer.launch(userDataDir='D:\Temp'
{'headless': False,
'userDataDir': UserDataDir,
'defaultViewport': {'width': 1800, 'height': 1000},
# 'enable-automation':False,
# 'ignoreDefaultArgs':['--enable-automation'],
'ignoreDefaultArgs':True,
}
这样每次pyppeteer都会用同一个配置文件,并且还可以把cookies,session文件存在同一个地方,如果登录过的网站,下次可以直接登录,不需要再次输入账号密码。
收起阅读 »

pip install peewee : AttributeError: 'str' object has no attribute 'decode'
ERROR: Command errored out with exit status 1:
command: 'C:\anaconda\python.exe' -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'C:\\Users\\xda\\AppData\
\Local\\Temp\\pip-install-ftotbzih\\peewee\\setup.py'"'"'; __file__='"'"'C:\\Users\\xda\\AppData\\Local\\Temp\\pip-insta
ll-ftotbzih\\peewee\\setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"
'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --egg-base 'C:\Users\xda\AppData\Lo
cal\Temp\pip-pip-egg-info-8ou7yi3i'
cwd: C:\Users\xda\AppData\Local\Temp\pip-install-ftotbzih\peewee\
Complete output (15 lines):
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "C:\Users\xda\AppData\Local\Temp\pip-install-ftotbzih\peewee\setup.py", line 99, in <module>
elif not _have_sqlite_extension_support():
File "C:\Users\xda\AppData\Local\Temp\pip-install-ftotbzih\peewee\setup.py", line 76, in _have_sqlite_extension_su
pport
compiler.compile([src_file], output_dir=tmp_dir),
File "C:\anaconda\lib\distutils\_msvccompiler.py", line 327, in compile
self.initialize()
File "C:\anaconda\lib\distutils\_msvccompiler.py", line 224, in initialize
vc_env = _get_vc_env(plat_spec)
File "C:\anaconda\lib\site-packages\setuptools\msvc.py", line 314, in msvc14_get_vc_env
return _msvc14_get_vc_env(plat_spec)
File "C:\anaconda\lib\site-packages\setuptools\msvc.py", line 273, in _msvc14_get_vc_env
out = subprocess.check_output(
AttributeError: 'str' object has no attribute 'decode'
----------------------------------------
ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.
同样的编码问题,同样的解决方法:
找到文件msvc.py
大概在276行:
out = subprocess.check_output(把decode的部分注释掉即可
'cmd /u /c "{}" {} && set'.format(vcvarsall, plat_spec),
stderr=subprocess.STDOUT,
)
# ).decode('utf-16le', errors='replace')
收起阅读 »

特斯拉水军还挺多的 还是友商的高级黑呢
天天上头条,然后评论里第一点赞最多的
独家对话上海维权女车主:请特斯拉到事发路段实地测速


这么明显的水军,会不会是友商一起黑呢
毕竟国内的电车厂商背后的财团应该比特斯拉大得多。纯粹猜测。
反正对特斯拉没有好感,这个明显是软件设计的bug。
很早前就有了。 只是一只就没改过来。
刹车时系统回收电力,系统来减速,这个时候人再去踩一下刹车,实际控制权在电脑端,电脑在刹车回收能源,这时人就别出来控制我。只是这时电脑判断有问题了,来不及急刹车。 收起阅读 »
独家对话上海维权女车主:请特斯拉到事发路段实地测速
这么明显的水军,会不会是友商一起黑呢
毕竟国内的电车厂商背后的财团应该比特斯拉大得多。纯粹猜测。
反正对特斯拉没有好感,这个明显是软件设计的bug。
很早前就有了。 只是一只就没改过来。
刹车时系统回收电力,系统来减速,这个时候人再去踩一下刹车,实际控制权在电脑端,电脑在刹车回收能源,这时人就别出来控制我。只是这时电脑判断有问题了,来不及急刹车。 收起阅读 »
python 破解谷歌人机验证码 运用百度语音识别
谷歌人机交互页面:
https://www.recaptcha.net/recaptcha/api2/demo

如果直接从图片肝,需要收集足够的图片,然后使用yolo或者pytorch进行训练,得到模型后再进行识别。
不过这个人机交互验证码有一个语音验证的功能。
只要点击一个耳机的图标,然后就变成了语音识别。
播放一段录音,然后输入几个单词,如果单词对了,那么也可以通过。

那接下来的问题就简单了,拿到录音->识别录音,转化为文本,然后在输入框输入,就基本大功告成了。
英文转文本,网上有不少的AI平台可以白嫖,不过论效果,个人觉得百度的AI效果还不错,起码可以免费调用5W次。
完整代码如下:
这个是百度识别语音部分:
然后下面的是获取语音部分,并且点击输入结果。
最终试了,效果还是达到98%的准确率。 收起阅读 »
https://www.recaptcha.net/recaptcha/api2/demo
如果直接从图片肝,需要收集足够的图片,然后使用yolo或者pytorch进行训练,得到模型后再进行识别。
不过这个人机交互验证码有一个语音验证的功能。
只要点击一个耳机的图标,然后就变成了语音识别。
播放一段录音,然后输入几个单词,如果单词对了,那么也可以通过。
那接下来的问题就简单了,拿到录音->识别录音,转化为文本,然后在输入框输入,就基本大功告成了。
英文转文本,网上有不少的AI平台可以白嫖,不过论效果,个人觉得百度的AI效果还不错,起码可以免费调用5W次。
完整代码如下:
这个是百度识别语音部分:
# -*- coding: utf-8 -*-
# @Time : 2021/4/24 20:50
# @File : baidu_voice_service.py
# @Author : Rocky C@www.30daydo.com
import os
import time
import requests
import sys
import pickle
sys.path.append('..')
from config import API_KEY,SECRET_KEY
from base64 import b64encode
from pathlib import PurePath
import subprocess
BASE = PurePath(__file__).parent
# 需要识别的文件
# 文件格式
# 文件后缀只支持 pcm/wav/amr 格式,极速版额外支持m4a 格式
CUID = '24057753' # 随意
# 采样率
RATE = 16000 # 固定值
ASR_URL = 'http://vop.baidu.com/server_api'
#测试自训练平台需要打开以下信息, 自训练平台模型上线后,您会看见 第二步:“”获取专属模型参数pid:8001,modelid:1234”,按照这个信息获取 dev_pid=8001,lm_id=1234
'''
http://vop.baidu.com/server_api
1537 普通话(纯中文识别) 输入法模型 有标点 支持自定义词库
1737 英语 英语模型 无标点 不支持自定义词库
1637 粤语 粤语模型 有标点 不支持自定义词库
1837 四川话 四川话模型 有标点 不支持自定义词库
1936 普通话远场
'''
DEV_PID = 1737
SCOPE = 'brain_enhanced_asr' # 有此scope表示有asr能力,没有请在网页里开通极速版
class DemoError(Exception):
pass
TOKEN_URL = 'http://openapi.baidu.com/oauth/2.0/token'
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
r = requests.post(
url=TOKEN_URL,
data=params
)
result = r.json()
if ('access_token' in result.keys() and 'scope' in result.keys()):
if SCOPE and (not SCOPE in result['scope'].split(' ')): # SCOPE = False 忽略检查
raise DemoError('scope is not correct')
return result['access_token']
else:
raise DemoError('MAYBE API_KEY or SECRET_KEY not correct: access_token or scope not found in token response')
""" TOKEN end """
def dump_token(token):
with open(os.path.join(BASE,'token.pkl'),'wb') as fp:
pickle.dump({'token':token},fp)
def load_token(filename):
if not os.path.exists(filename):
token=fetch_token()
dump_token(token)
return token
else:
with open(filename,'rb') as fp:
token = pickle.load(fp)
return token['token']
def recognize_service(token,filename):
FORMAT = filename[-3:]
with open(filename, 'rb') as speech_file:
speech_data = speech_file.read()
length = len(speech_data)
if length == 0:
raise DemoError('file %s length read 0 bytes' % filename)
b64_data = b64encode(speech_data)
params = {'cuid': CUID, 'token': token, 'dev_pid': DEV_PID,'speech':b64_data,'len':length,'format':FORMAT,'rate':RATE,'channel':1}
headers = {
'Content-Type':'application/json',
}
r = requests.post(url=ASR_URL,json=params,headers=headers)
return r.json()
def rate_convertor(filename):
filename = filename.split('.')[0]
CMD=f'ffmpeg.exe -y -i {filename}.mp3 -ac 1 -ar 16000 {filename}.wav'
try:
p=subprocess.Popen(CMD, stdin=subprocess.PIPE)
p.communicate()
time.sleep(1)
except Exception as e:
print(e)
return False,None
else:
return True,f'{filename}.wav'
def clear(file):
try:
os.remove(file)
except Exception as e:
print(e)
def get_voice_text(audio_file):
filename = 'token.pkl'
token = load_token(filename)
convert_status,file = rate_convertor(audio_file)
clear(file)
if not convert_status:
return None
result = recognize_service(token,file)
return result['result'][0]
if __name__ == '__main__':
get_voice_text('1.mp3')
然后下面的是获取语音部分,并且点击输入结果。
# -*- coding: utf-8 -*-代码里需要你申请一个百度AI的key以便生成token。
# @Time : 2021/4/25 15:16
# @File : download_mp3.py
# @Author : Rocky C@www.30daydo.com
#!/usr/bin/env python3
import os
import subprocess
import time
import re
import requests
import urllib.request
import zipfile
import io
from google.cloud import speech_v1
from random import randint, uniform
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from google_recaptcha.baidu_voice_service import get_voice_text,clear
class Gcaptcha:
def __init__(self, url):
self.response = None
self.attempts = 0
self.successful = 0
self.failed = 0
self.solved = 0
self.mp3 = 'audio.mp3'
# self.wav='audio.wav'
# Set Chrome to run in headless mode and mute the audio
opts = webdriver.ChromeOptions()
# opts.headless = True
opts.add_argument("--mute-audio")
# opts.add_argument("--headless",)
CHROME_PATH = r'C:\git\EZProject\bin\chromedriver.exe'
self.driver = webdriver.Chrome(executable_path=CHROME_PATH,options=opts)
self.driver.maximize_window()
self.driver.get(url)
self.__bypass_webdriver_check()
# Initialize gcaptcha solver
self.__initialize()
while True:
# Download MP3 file
mp3_file = self.__download_mp3()
# Transcribe MP3 file
result = get_voice_text(self.mp3)
# audio_transcription = transcribe(mp3_file)
# self.transcription.attempts += 1
# If the MP3 file is properly transcribed
if result is not None:
# self.transcription.successful += 1
# Verify transcription
verify = self.__submit_transcription(result)
# Transcription successful with confidence >60%
if verify:
gcaptcha_response = self.__get_response()
self.response = gcaptcha_response
# self.recaptcha.solved += 1
# Delete MP3 file
self.driver.close()
self.driver.quit()
break
# Multiple correct solutions required. Solving again.
else:
self.solved += 1
clear(self.mp3)
# If the MP3 file could not be transcribed
else:
self.failed += 1
clear(self.mp3)
# Click on the "Get a new challenge" button to use a new MP3 file
self.__refresh_mp3()
# time.sleep(uniform(2, 4))
def __initialize(self):
# Access initial gcaptcha iframe
self.driver.switch_to.frame(self.driver.find_element(By.CSS_SELECTOR, 'iframe[name^=a]'))
self.__bypass_webdriver_check()
# Click the gcaptcha checkbox
checkbox = self.driver.find_element(By.CSS_SELECTOR, '#recaptcha-anchor')
self.__mouse_click(checkbox)
# Go back to original content to access second gcaptcha iframe
self.driver.switch_to.default_content()
# Wait roughly 3 seconds for second gcaptcha iframe to load
time.sleep(uniform(2.5, 3))
# Find second gcaptcha iframe
gcaptcha = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'iframe[name^=c]'))
)
# Access second gcaptcha iframe
self.driver.switch_to.frame(gcaptcha)
self.__bypass_webdriver_check()
# Click the audio button
audio_button = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.rc-button-audio'))
)
self.__mouse_click(audio_button)
time.sleep(0.5)
def __mouse_click(self, element):
cursor = ActionChains(self.driver)
cursor.move_to_element(element)
cursor.pause(uniform(0.3, 0.5))
cursor.click()
cursor.perform()
def __bypass_webdriver_check(self):
self.driver.execute_script(
'const newProto = navigator.__proto__; delete newProto.webdriver; navigator.__proto__ = newProto;')
def __download_mp3(self):
self.driver.switch_to.default_content()
self.driver.switch_to.frame(self.driver.find_element(By.CSS_SELECTOR, 'iframe[name^=c]'))
self.__bypass_webdriver_check()
# Check if the Google servers are blocking us
if len(self.driver.find_elements(By.CSS_SELECTOR, '.rc-doscaptcha-body-text')) == 0:
audio_file = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.rc-audiochallenge-tdownload-link'))
)
# Click the play button
play_button = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.rc-audiochallenge-play-button > button'))
)
self.__mouse_click(play_button)
# Get URL of MP3 file
audio_url = audio_file.get_attribute('href')
# Predefine the MP3 file name
# Download the MP3 file
try:
urllib.request.urlretrieve(audio_url, self.mp3)
except Exception as e:
print(e)
return None
else:
return self.mp3
else:
Error('Too many requests have been sent to Google. You are currently being blocked by their servers.')
exit(-1)
def __refresh_mp3(self):
self.driver.switch_to.default_content()
self.driver.switch_to.frame(self.driver.find_element(By.CSS_SELECTOR, 'iframe[name^=c]'))
self.__bypass_webdriver_check()
# Click on the refresh button to retrieve a new mp3 file
refresh_button = self.driver.find_element(By.CSS_SELECTOR, '#recaptcha-reload-button')
self.__mouse_click(refresh_button)
def __submit_transcription(self, text):
self.driver.switch_to.default_content()
self.driver.switch_to.frame(self.driver.find_element(By.CSS_SELECTOR, 'iframe[name^=c]'))
self.__bypass_webdriver_check()
# Input field for response
input_field = self.driver.find_element(By.CSS_SELECTOR, '#audio-response')
# Instantly type the full text without delays because Google isn't checking delays between keystrokes
input_field.send_keys(text)
# Click "Verify" button
verify_button = self.driver.find_element(By.CSS_SELECTOR, '#recaptcha-verify-button')
self.__mouse_click(verify_button)
# Wait roughly 3 seconds for verification to complete
time.sleep(uniform(2, 3))
self.driver.switch_to.default_content()
self.driver.switch_to.frame(self.driver.find_element(By.CSS_SELECTOR, 'iframe[name^=a]'))
self.__bypass_webdriver_check()
# Check to see if verified by recaptcha
try:
self.driver.find_element(By.CSS_SELECTOR, '.recaptcha-checkbox-checked')
except NoSuchElementException:
return False
else:
return True
def __get_response(self):
# Switch back to main parent window and get gcaptcha response
self.driver.switch_to.default_content()
response = self.driver.find_element(By.CSS_SELECTOR, '#g-recaptcha-response').get_attribute('value')
return response
class Error(Exception):
def __init__(self, message):
get_files = os.listdir()
match_regex = re.compile(r'^audio\d+.mp3|chromedriver_\w+\d+.zip$')
filtered_files = [f for f in get_files if match_regex.match(f)]
for file in filtered_files:
clear(file)
raise Exception(f'ERROR: {message}')
if __name__=='__main__':
gcaptcha = Gcaptcha('https://www.google.com/recaptcha/api2/demo')
最终试了,效果还是达到98%的准确率。 收起阅读 »
百度AI的语音识别无法识别到英文原因
大概率是因为你的音频码率和要求的不一致造成的。
可以尝试使用ffmepg转下码:
可以尝试使用ffmepg转下码:
ffmpeg.exe -i 3.mp3 -ac 1 -ar 16000 16k.wav试过后就能够正常识别到语音内容了。
百度英语中文语音识别为文字服务 python demo【使用requests重写官方demo】
官方使用的稍微底层的urllib写的,用过了requests库的人看着不习惯。故重写之,并做了封装。
官方demo:
https://github.com/Baidu-AIP/speech-demo
# -*- coding: utf-8 -*-
# @Time : 2021/4/24 20:50
# @File : baidu_voice_service.py
# @Author : Rocky C@www.30daydo.com
import os
import requests
import sys
import pickle
sys.path.append('..')
from config import API_KEY,SECRET_KEY
from base64 import b64encode
from pathlib import PurePath
BASE = PurePath(__file__).parent
# 需要识别的文件
AUDIO_FILE = r'C:\OtherGit\speech-demo\rest-api-asr\python\audio\2.m4a' # 只支持 pcm/wav/amr 格式,极速版额外支持m4a 格式
# 文件格式
FORMAT = AUDIO_FILE[-3:] # 文件后缀只支持 pcm/wav/amr 格式,极速版额外支持m4a 格式
CUID = '24057753'
# 采样率
RATE = 16000 # 固定值
ASR_URL = 'http://vop.baidu.com/server_api'
#测试自训练平台需要打开以下信息, 自训练平台模型上线后,您会看见 第二步:“”获取专属模型参数pid:8001,modelid:1234”,按照这个信息获取 dev_pid=8001,lm_id=1234
'''
http://vop.baidu.com/server_api
1537 普通话(纯中文识别) 输入法模型 有标点 支持自定义词库
1737 英语 英语模型 无标点 不支持自定义词库
1637 粤语 粤语模型 有标点 不支持自定义词库
1837 四川话 四川话模型 有标点 不支持自定义词库
1936 普通话远场
'''
DEV_PID = 1737
SCOPE = 'brain_enhanced_asr' # 有此scope表示有asr能力,没有请在网页里开通极速版
class DemoError(Exception):
pass
TOKEN_URL = 'http://openapi.baidu.com/oauth/2.0/token'
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
r = requests.post(
url=TOKEN_URL,
data=params
)
result = r.json()
if ('access_token' in result.keys() and 'scope' in result.keys()):
if SCOPE and (not SCOPE in result['scope'].split(' ')): # SCOPE = False 忽略检查
raise DemoError('scope is not correct')
return result['access_token']
else:
raise DemoError('MAYBE API_KEY or SECRET_KEY not correct: access_token or scope not found in token response')
""" TOKEN end """
def dump_token(token):
with open(os.path.join(BASE,'token.pkl'),'wb') as fp:
pickle.dump({'token':token},fp)
def load_token(filename):
if not os.path.exists(filename):
token=fetch_token()
dump_token(token)
return token
else:
with open(filename,'rb') as fp:
token = pickle.load(fp)
return token['token']
def recognize_service(token,filename):
with open(filename, 'rb') as speech_file:
speech_data = speech_file.read()
length = len(speech_data)
if length == 0:
raise DemoError('file %s length read 0 bytes' % AUDIO_FILE)
b64_data = b64encode(speech_data)
params = {'cuid': CUID, 'token': token, 'dev_pid': DEV_PID,'speech':b64_data,'len':length,'format':FORMAT,'rate':RATE,'channel':1}
headers = {
'Content-Type':'application/json',
}
r = requests.post(url=ASR_URL,json=params,headers=headers)
return r.json()
def main():
filename = 'token.pkl'
token = load_token(filename)
result = recognize_service(token,AUDIO_FILE)
print(result['result'])
if __name__ == '__main__':
main()
只需要替换自己的key就可以使用。
自己录了几段英文测试了下,还是蛮准的。 收起阅读 »
银河证券拖拉机如何开通 一拖六 一拖七
首先你得先开通一个银河证券的账户,笔者这里目前开通的费率是股票万一免5,转债沪市百万分之五,深市十万分之五,基金申购打一折,基金买卖费率万0.5,没有最低5元限制。需要可以文末扫描开通。

有了银河证券账户就就可以开通拖拉机了。
效果图如下:

选择场内基金

选择基金申购! 不要选认购,不要选认购,不要选认购!
选择你要申购的标的代码,比如华宝油气,原油基金 折价品种。

笔者公众号内有银河证券的autojs 拖拉机+多账户 自动申购脚本,自动卖出脚本
拖拉机开通很简单。
在首页点击开户:

底下有个加挂户的,点击之

然后填入相关的信息。
如果没有开过深基金户的,添加新加,如果已经开过的,那么只要把旧的深基金账户贴上去就可以。
新开的话,一天只能开一个,如果开多次,会提示已经有一个在办理中,继续加挂会有提示错误信息。
收益率,绝对值不高,但是单个标的的收益率绝对高的爆棚

所以只是套一户的话,就没多大意思了。 不过银河就是可以一个账户开6个股东号,也就是以你一个人在限购的情况。所以如果限购500,那么如果一次循环套利收益率50%,250元,6个股东号,收益1500元。 然后把家人的身份证拿过来开了户,一个家庭6户,1500*6=9000元,所以理论套利下来,一个家庭收益率就有9000元,如果成员数更多,收益更多。
所以这个套利的核心是一个支持 多开股东户的券商,且券商支持申购打折,(不打折的话一次套利会损失1%)多张身份证账户,笔者这里适合的银河券商,股票费率可以做到万一免五,申购一折。
扫描联系开户,备注:开户
非诚勿扰,墨迹勿扰。
 收起阅读 »
收起阅读 »
有了银河证券账户就就可以开通拖拉机了。
效果图如下:
选择场内基金
选择基金申购! 不要选认购,不要选认购,不要选认购!
选择你要申购的标的代码,比如华宝油气,原油基金 折价品种。
笔者公众号内有银河证券的autojs 拖拉机+多账户 自动申购脚本,自动卖出脚本
拖拉机开通很简单。
在首页点击开户:
底下有个加挂户的,点击之
然后填入相关的信息。
如果没有开过深基金户的,添加新加,如果已经开过的,那么只要把旧的深基金账户贴上去就可以。
新开的话,一天只能开一个,如果开多次,会提示已经有一个在办理中,继续加挂会有提示错误信息。
收益率,绝对值不高,但是单个标的的收益率绝对高的爆棚
所以只是套一户的话,就没多大意思了。 不过银河就是可以一个账户开6个股东号,也就是以你一个人在限购的情况。所以如果限购500,那么如果一次循环套利收益率50%,250元,6个股东号,收益1500元。 然后把家人的身份证拿过来开了户,一个家庭6户,1500*6=9000元,所以理论套利下来,一个家庭收益率就有9000元,如果成员数更多,收益更多。
所以这个套利的核心是一个支持 多开股东户的券商,且券商支持申购打折,(不打折的话一次套利会损失1%)多张身份证账户,笔者这里适合的银河券商,股票费率可以做到万一免五,申购一折。
扫描联系开户,备注:开户
非诚勿扰,墨迹勿扰。
收起阅读 »


基金常见误区
1. C类规模一定比A大吗:
错,只能说明大部分情况下是这样,不过实际上查了下相关的基金数据,C类也会比A类的规模大。
比如这两只:


错,只能说明大部分情况下是这样,不过实际上查了下相关的基金数据,C类也会比A类的规模大。
比如这两只:
直接买入 红利增强与易基综债 【2021-04-22】
试验一下策略的灵敏度。
收盘再来更新一波。
### 盘后更新 #####
当天两个都埋伏失败。。。看看明天的情况。如果没拉升,平盘卖出,如果暴跌,则7天后选择赎回。
收盘再来更新一波。
### 盘后更新 #####
当天两个都埋伏失败。。。看看明天的情况。如果没拉升,平盘卖出,如果暴跌,则7天后选择赎回。
南方聚利160131 开放申购 2021年5月14日
当前的溢价率其高,当前溢价率是150%。
大概率是基金公司在做局,让你们进去套利的啦。
不过目前该基金的规模在5千万,看起来规模不算特别大,并且是一只债基。
跟520弘盈差不多的套路。
大概率是基金公司在做局,让你们进去套利的啦。
不过目前该基金的规模在5千万,看起来规模不算特别大,并且是一只债基。
跟520弘盈差不多的套路。
本地代码 搜索脚本 python实现
本来用find+grep可以搞定的,不过如果搜索多个路径和多个规则,写正则可能写过不来
上面语句是在py文件中查找redis的字符。
不过如果要在指定多个位置查找,可能要拼接几个管道,并且如果我要几个字符的关系是并集,就是多个关键字要在文本中同时出现,而且不一定在同一行,所以也不好写。
所以写了个python脚本,也方便在centos下运行
运行: python main.py --kw=asyncio,gather

收起阅读 »
find . -type f -name "*.py" | xargs grep "redis"
上面语句是在py文件中查找redis的字符。
不过如果要在指定多个位置查找,可能要拼接几个管道,并且如果我要几个字符的关系是并集,就是多个关键字要在文本中同时出现,而且不一定在同一行,所以也不好写。
所以写了个python脚本,也方便在centos下运行
# -*- coding: utf-8 -*-
# @Time : 2021/4/14 1:46
# @File : search_string_in_folder.py
# @Author : Rocky C@www.30daydo.com
'''
搜索代码脚本
'''
import fire
import glob
import re
# TODO 用PYQT重写一个
PATH_LIST = [r'C:\git\\',r'C:\OtherGit\\',r'C:\OneDrive\viewed_code\\']
POST_FIX = 'py' # 后缀文件
# 关键词
WORDS=[]
EXCLUDE_PATH=[r'C:\OtherGit\cpython']
DEBUG = True
class FileSearcher:
def __init__(self,kw):
self.root_path_list = PATH_LIST
self.default_coding ='utf-8'
self.exception_handle_coding='gbk'
self.kw=[]
if not isinstance(kw,tuple):
kw=(kw,)
for k in kw:
k=k.strip()
self.kw.append(k)
def search(self,file,encoding):
match_dict = dict()
for w in self.kw:
match_dict.setdefault(w, False)
line_number = 0
line_list=list()
with open(file, 'r', encoding=encoding) as fp:
while 1:
try:
line = fp.readline()
except UnicodeDecodeError as e:
if DEBUG:
print(f'Error coding in file {file}')
print(e)
return None,None,None
except Exception as e:
if DEBUG:
print(f'Error in file {file}')
print(e)
break
if not line:
break
line = line.strip()
if not line:
continue
for w in self.kw:
m=re.search(w,line,re.IGNORECASE)
if m:
match_dict.update({w:True})
line_list.append(line_number)
line_number+=1
return True,match_dict.copy(),line_list.copy()
def print_match_result(self,file,line_list,encoding):
with open(file, 'r', encoding=encoding) as fp:
line_number = 0
while 1:
try:
line = fp.readline()
except Exception as e:
if DEBUG:
print(f'Error in file {file}')
print(e)
break
if not line:
break
line=line.strip()
if not line:
continue
if line_number in line_list:
print(f'{file} :: {line_number} ====>\n {line[:50]}\n')
line_number += 1
def run(self):
for path in self.root_path_list:
search_path=path+'**/*.'+POST_FIX
for file in glob.iglob(search_path,recursive=True):
for ex_path in EXCLUDE_PATH:
ex_path=ex_path.replace('\\','')
temp_file=file.replace('\\','')
if ex_path in temp_file:
continue
use_encoding=self.default_coding
encode_proper,match_dict,line_list=self.search(file,use_encoding)
if not encode_proper:
use_encoding = self.exception_handle_coding
encode_proper,match_dict,line_list=self.search(file, use_encoding)
if match_dict is not None and len(match_dict)>0 and all(match_dict.values()):
# print(match_dict.values())
self.print_match_result(file,line_list,use_encoding)
# print(line_list)
def test_error_file():
path=r'C:\git\CodePool\example-code\19-dyn-attr-prop\oscon\schedule2.py'
with open(path,'r',encoding='utf8') as fp:
while 1:
x=fp.readline()
if not x:
break
print(x)
def main(kw):
app = FileSearcher(kw)
app.run()
if __name__ == '__main__':
fire.Fire(main)
运行: python main.py --kw=asyncio,gather
收起阅读 »

万一免五 银河证券 非网红营业部 转债免五低佣金 百万分之五
最新更新(2022年3月19日):
【银河万一免五又开了! 难得的机会,需要开的赶紧,过了这个时间窗口就没有啦】
======================= 以前的内容 ======================================
目前市面上的银河默认不是免五的,需要找到特定的营业部才能开通。
本营业部非网红营业部,可以一加六拖拉机。以防为了套利时出不去哈。
股票费率万一免五,
可转债(新规后)也是免五,沪市费率十万分之五,深市十万分之五。

因为经常会被同行举报,所以优惠会不定期关闭,需要的朋友要抓紧时间开,开了以后即使后面银河关闭了免五的通道,后面的费率还是以你现在开的费率来计算,也是免五的。
需要的朋友可以扫描关注: 备注 : 开户,非诚勿扰。
收起阅读 »
【银河万一免五又开了! 难得的机会,需要开的赶紧,过了这个时间窗口就没有啦】
======================= 以前的内容 ======================================
目前市面上的银河默认不是免五的,需要找到特定的营业部才能开通。
本营业部非网红营业部,可以一加六拖拉机。以防为了套利时出不去哈。
股票费率万一免五,
可转债(新规后)也是免五,沪市费率十万分之五,深市十万分之五。
因为经常会被同行举报,所以优惠会不定期关闭,需要的朋友要抓紧时间开,开了以后即使后面银河关闭了免五的通道,后面的费率还是以你现在开的费率来计算,也是免五的。
需要的朋友可以扫描关注: 备注 : 开户,非诚勿扰。
收起阅读 »
绿盟下载官网被黑了?
以前一个不错的绿色软件下载网站。
现在这样子了。

不知道是网站换人了还是被黑了?
现在这样子了。
不知道是网站换人了还是被黑了?
判读一个函数是不是协程
传入的是函数名,不需要加入括号:
调用:
收起阅读 »
def check_coroutine(fun):
if iscoroutinefunction(fun):
print('是协程')
else:
print('不是协程')
async def visit_web():
browser = await pyppeteer.launch(
{'headless': False,
'userDataDir': UserDataDir,
'defaultViewport': {'width': 1800, 'height': 1000},
'ignoreDefaultArgs':True,
}
)
page = await browser.newPage()
# 可以在launch下配置
# await page.setViewport({
# "width": 1900,
# "height": 1020
# })
# 先执行下面的JS 再去goto
await page.evaluate(
'''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''')
# await page.screenshot({'path': 'test.png', 'fullPage': True})
# await page.pdf({'path': 'test.pdf'})
# await asyncio.sleep(5)
await page.goto(url=URL)
# 这里的js是异步的写法
dimensions = await page.evaluate(
'''
()=>{
return {
width:document.documentElement.clientWidth,
height:document.documentElement.clientHeight,
deviceScaleFactor_:window.devicePixelRatio,
}
}
'''
)
result = await page.evaluate(
'''
()=>{
var title = document.title;
return {title:title};
}
'''
)
await browser.close()
调用:
check_coroutine(visit_web)注意,上面不能用visit_web()
收起阅读 »
可转债T+0 零手续费 零费率 免佣金
一般而言,可转债的手续费都会比股票低
可转债新规后,佣金沪深市十万分之五
那么如果你是很抠的人,这里并不是贬义词,在菜市场,你会比较价格,而在证券市场上,为什么不挑选便宜的佣金的券商呢?
看交割单
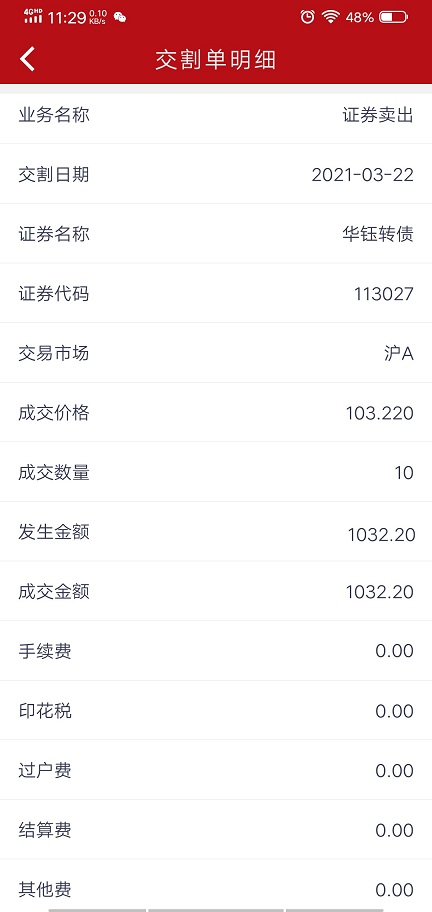
以前看到一个案例,发现低佣是多么难得:
券商交割单只是统计到分,也就是一分钱以下是不会收取的,那么买入转债的时候,如果你的交易金额较大,那么可以使用拆单功能,就是把一个大单拆分为多个小单,如果你每个小单小于5千元,那么券商的交割费用系统就会舍弃分钱后面的金额,也就是交易费用原来是 0.003元,但只能取到分钱位置,也就是0.00,后面的3就被舍弃了,这样手续费就是为0了。
所以你要做的就是找一个可转债低佣的券商,越低越好
需要可以扫描开户:
备注:开户
非诚勿扰。
收起阅读 »
可转债新规后,佣金沪深市十万分之五
那么如果你是很抠的人,这里并不是贬义词,在菜市场,你会比较价格,而在证券市场上,为什么不挑选便宜的佣金的券商呢?
看交割单
以前看到一个案例,发现低佣是多么难得:
券商交割单只是统计到分,也就是一分钱以下是不会收取的,那么买入转债的时候,如果你的交易金额较大,那么可以使用拆单功能,就是把一个大单拆分为多个小单,如果你每个小单小于5千元,那么券商的交割费用系统就会舍弃分钱后面的金额,也就是交易费用原来是 0.003元,但只能取到分钱位置,也就是0.00,后面的3就被舍弃了,这样手续费就是为0了。
所以你要做的就是找一个可转债低佣的券商,越低越好
需要可以扫描开户:
备注:开户
非诚勿扰。
收起阅读 »