
通知设置 新通知
程序自动获取限购-溢价LOF基金套利,并推送到微信消息
李魔佛 发表了文章 • 0 个评论 • 2581 次浏览 • 2024-03-23 23:32
如前面的印度基金LOF,嘉实原油LOF,全球芯片LOF,到现在的标普500LOF。
如果平时工作繁忙,没有时间每天翻看基金的公告,或者没时间看大V们公众号消息推送。
或者自己想要遍历所有限购状态的LOF基金,并自动筛选出溢价的可套利标的,提前埋伏。
那么可以自己动手,写个简单的监控推送程序。
微信推送电脑安装必要的python环境,和pandas,akshare库。
获取所有基金的数据
import akshare as ak
fund_purchase_em_df = ak.fund_purchase_em()
得到大概2万个基金数据。
然后剩下的就是过滤条件了,因为这里面包含了很多货基,债基等我们不需要的基金类型。
用value_counts 就知道有多少种类型:
平时我们做套利的,一般以QDII基金为主,大部分的情况是因为外汇额度用完而导致的限购。
所以监控的品种可以选择QDII类型或者海外股票等。
示例里笔者选一个 指数型-海外股票
然后过来条件按照个人喜好来设定:
比如选择限购1万以下的LOF:
def filter_func(df,type='指数型-海外股票'):
df = df[~df['基金代码'].str.startswith('0')]
condition1 = df['申购状态']=='限大额'
condition2 = df['基金类型']==type
df = df[condition1 & condition2]
df= df[~df['基金简称'].str.contains('ETF')]
df = df[(df['日累计限定金额']>0) & (df['日累计限定金额']<=10000)]
df['基金代码'] = df['基金代码'].map(lambda x: 'SH'+x if x.startswith('5') else 'SZ'+x)
return df
得到下面的结果:
因为上面的返回数据没有溢价率,所以我们就需要自己写个获取溢价率的函数去处理一下:
import requests
cookies = # 雪球上获取,不一定需要登录状态
headers = {
'authority': 'stock.xueqiu.com',
'origin': 'https://xueqiu.com',
'user-agent': 'Mozilla/5.0 (iPhone; U; CPU like Mac OS X; en) AppleWebKit/420+ (KHTML, like Gecko) Version/3.0 Mobile/1C28 Safari/419.3',
}
def fund_premium_rate(code):
params = {
'symbol': code,
'extend': 'detail',
}
response = requests.get('https://stock.xueqiu.com/v5/stock/quote.json', params=params,
cookies=cookies,
headers=headers)
try:
rate = response.json()['data']['quote']['premium_rate']
except Exception as e:
return None
else:
return rate
上面循环里会自动把没有对应场内基金的数据过滤掉。
运行2秒就得到了数据:
然后我们发现这几只限购的是处于轻微折价状态,只有易方达标普500LOF是溢价26%,只有它可以开拖拉机去套的。
微信推送
最后是发消息通知自己。早期开通的个人企业微信API,可以直接使用微信的API发送消息。如果现在申请,需要有自己的个人域名和备案。
可以设定溢价率大于某个阈值才发送消息。比如溢价率大于4以上才发送。
for code,name in code_name_mapper.items():
rate = fund_premium_rate(code)
if rate is not None:
print(f'{code} - {name}的溢价率是: {rate}')
if rate > 4:
send_message_via_wechat(f'{code} - {name}的溢价率是: {rate}, 可以关注套利。 公众号:可转债量化分析')
为了演示,去掉这个条件,把全部数据的都发送吧。
效果图
然后就可以把全部代码放在一起,用windows的定时任务或者linux的crontab自动运行了。
目前QMT,Ptrade不支持拖拉机账号,所以自动化拖拉机的功能就实现不了了哈。
PS:顺便附录一份全部限购1万以下的基金全表。
需要的关注公众号后台回复:基金限购名单
获取即可。
查看全部
如前面的印度基金LOF,嘉实原油LOF,全球芯片LOF,到现在的标普500LOF。
如果平时工作繁忙,没有时间每天翻看基金的公告,或者没时间看大V们公众号消息推送。
或者自己想要遍历所有限购状态的LOF基金,并自动筛选出溢价的可套利标的,提前埋伏。
那么可以自己动手,写个简单的监控推送程序。

微信推送电脑安装必要的python环境,和pandas,akshare库。
获取所有基金的数据
import akshare as ak
fund_purchase_em_df = ak.fund_purchase_em()

得到大概2万个基金数据。
然后剩下的就是过滤条件了,因为这里面包含了很多货基,债基等我们不需要的基金类型。
用value_counts 就知道有多少种类型:

平时我们做套利的,一般以QDII基金为主,大部分的情况是因为外汇额度用完而导致的限购。
所以监控的品种可以选择QDII类型或者海外股票等。
示例里笔者选一个 指数型-海外股票
然后过来条件按照个人喜好来设定:
比如选择限购1万以下的LOF:
def filter_func(df,type='指数型-海外股票'):
df = df[~df['基金代码'].str.startswith('0')]
condition1 = df['申购状态']=='限大额'
condition2 = df['基金类型']==type
df = df[condition1 & condition2]
df= df[~df['基金简称'].str.contains('ETF')]
df = df[(df['日累计限定金额']>0) & (df['日累计限定金额']<=10000)]
df['基金代码'] = df['基金代码'].map(lambda x: 'SH'+x if x.startswith('5') else 'SZ'+x)
return df
得到下面的结果:

因为上面的返回数据没有溢价率,所以我们就需要自己写个获取溢价率的函数去处理一下:
import requests
cookies = # 雪球上获取,不一定需要登录状态
headers = {
'authority': 'stock.xueqiu.com',
'origin': 'https://xueqiu.com',
'user-agent': 'Mozilla/5.0 (iPhone; U; CPU like Mac OS X; en) AppleWebKit/420+ (KHTML, like Gecko) Version/3.0 Mobile/1C28 Safari/419.3',
}
def fund_premium_rate(code):
params = {
'symbol': code,
'extend': 'detail',
}
response = requests.get('https://stock.xueqiu.com/v5/stock/quote.json', params=params,
cookies=cookies,
headers=headers)
try:
rate = response.json()['data']['quote']['premium_rate']
except Exception as e:
return None
else:
return rate
上面循环里会自动把没有对应场内基金的数据过滤掉。
运行2秒就得到了数据:

然后我们发现这几只限购的是处于轻微折价状态,只有易方达标普500LOF是溢价26%,只有它可以开拖拉机去套的。
微信推送
最后是发消息通知自己。早期开通的个人企业微信API,可以直接使用微信的API发送消息。如果现在申请,需要有自己的个人域名和备案。
可以设定溢价率大于某个阈值才发送消息。比如溢价率大于4以上才发送。
for code,name in code_name_mapper.items():
rate = fund_premium_rate(code)
if rate is not None:
print(f'{code} - {name}的溢价率是: {rate}')
if rate > 4:
send_message_via_wechat(f'{code} - {name}的溢价率是: {rate}, 可以关注套利。 公众号:可转债量化分析')
为了演示,去掉这个条件,把全部数据的都发送吧。
效果图
然后就可以把全部代码放在一起,用windows的定时任务或者linux的crontab自动运行了。
目前QMT,Ptrade不支持拖拉机账号,所以自动化拖拉机的功能就实现不了了哈。
PS:顺便附录一份全部限购1万以下的基金全表。
需要的关注公众号后台回复:基金限购名单
获取即可。

Ptrade无法获取lof基金的历史数据
李魔佛 回复了问题 • 2 人关注 • 1 个回复 • 3590 次浏览 • 2023-08-17 01:41
目前支持量化接口的万一免五的券商有哪些?
李魔佛 发表了文章 • 0 个评论 • 7754 次浏览 • 2023-07-04 22:52
其中能够股票免五的有国金证券,国盛证券,国信证券,安信证券。
其中,国金证券,国盛证券支持QMT、MiniQMT、Ptrade。
国信证券,安信证券支持QMT。
东莞证券支持Ptrade
可转债默认免五。
开户后可加入量化技术交流群,可获得编程技术指导。
【提问者需要把问题描述清楚即可,PS: 有些人动不动就说:“Ptrade不行呀”,“QMT垃圾呀”,结果让他贴代码上来瞅瞅,是他本身代码写的拉垮,目前贴出来的已知的问题,90%是个人代码问题。】
扫码添加微信咨询开户:
查看全部

其中能够股票免五的有国金证券,国盛证券,国信证券,安信证券。
其中,国金证券,国盛证券支持QMT、MiniQMT、Ptrade。
国信证券,安信证券支持QMT。
东莞证券支持Ptrade
可转债默认免五。

开户后可加入量化技术交流群,可获得编程技术指导。
【提问者需要把问题描述清楚即可,PS: 有些人动不动就说:“Ptrade不行呀”,“QMT垃圾呀”,结果让他贴代码上来瞅瞅,是他本身代码写的拉垮,目前贴出来的已知的问题,90%是个人代码问题。】
扫码添加微信咨询开户:

akshare 官网地址
李魔佛 发表了文章 • 0 个评论 • 7911 次浏览 • 2023-05-25 21:50
不明白为啥百度前面几页都显示不到akshare的官网。对这个搜索结果实在有点无语。

ptrade 微信通知
李魔佛 发表了文章 • 0 个评论 • 3317 次浏览 • 2022-09-20 10:29
所以情况多了,经常会忘记,手动登录进去重启。导致策略没有运行。
所以办法1,在盘前函数加入 微信通知,在交易日,如果盘前(8:30分左右),没有收到微信提醒,那么就需要即使登录到ptrade进行手动重启。
代码如下:def notify(content=''):
send_qywx(
'微信id', '微信key', 'agent', info=content,
touser= '你的微信名字',
)
def before_trading_start(context, data):
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
notify('Ptrade 盘前运行{}'.format(now))
差不多这样就可以了。
不过笔者一般会使用另外一个种方式,因为如果哪一天没有收到,意味这ptrade没有起来,但你没有收到,你也就忘了这么一回事。 所以笔者的做法是,正常情况下不推送,而在ptrade不启动的时候才推送到微信。
下回更新。待续
# 继续更新
每天盘前,ptrade会到mysql插入一条数据,比如当天的日期
然后有个程序每天定时去读取mysql,如果读不到数据,就发送数据给微信即可。
class DBSelector():
'''
数据库选择类
'''
def get_engine(self):
from sqlalchemy import create_engine
try:
engine = create_engine(
'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(USER, PASSWORD, MYSQL_HOST, MYSQL_PORT, MYSQL_DB))
except Exception as e:
log.error(e)
return None
return engine
def get_mysql_conn(self, db):
import pymysql
try:
conn = pymysql.connect(host=MYSQL_HOST, port=MYSQL_PORT, user=USER, password=PASSWORD, db=db,
charset='utf8')
except Exception as e:
log.error(e)
return None
else:
return conn
def main():
now = datetime.datetime.now()
if not now.weekday():
print('not week day')
return
db = DBSelector()
conn = db.get_mysql_conn('ptrade')
cursor = conn.cursor()
sql_str = 'select count(*) from `ptrade_runing_status` where `date`=%s limit 1'
date = now.strftime('%Y-%m-%d')
cursor.execute(sql_str, (date,))
result = cursor.fetchone()
if result[0] == 0:
send_message_via_wechat('{} ptrade没有启动!'.format(now))
if __name__=='__main__':
main()
查看全部
所以情况多了,经常会忘记,手动登录进去重启。导致策略没有运行。
所以办法1,在盘前函数加入 微信通知,在交易日,如果盘前(8:30分左右),没有收到微信提醒,那么就需要即使登录到ptrade进行手动重启。
代码如下:
def notify(content=''):
send_qywx(
'微信id', '微信key', 'agent', info=content,
touser= '你的微信名字',
)
def before_trading_start(context, data):
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
notify('Ptrade 盘前运行{}'.format(now))
差不多这样就可以了。
不过笔者一般会使用另外一个种方式,因为如果哪一天没有收到,意味这ptrade没有起来,但你没有收到,你也就忘了这么一回事。 所以笔者的做法是,正常情况下不推送,而在ptrade不启动的时候才推送到微信。
下回更新。待续
# 继续更新
每天盘前,ptrade会到mysql插入一条数据,比如当天的日期
然后有个程序每天定时去读取mysql,如果读不到数据,就发送数据给微信即可。
class DBSelector():
'''
数据库选择类
'''
def get_engine(self):
from sqlalchemy import create_engine
try:
engine = create_engine(
'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(USER, PASSWORD, MYSQL_HOST, MYSQL_PORT, MYSQL_DB))
except Exception as e:
log.error(e)
return None
return engine
def get_mysql_conn(self, db):
import pymysql
try:
conn = pymysql.connect(host=MYSQL_HOST, port=MYSQL_PORT, user=USER, password=PASSWORD, db=db,
charset='utf8')
except Exception as e:
log.error(e)
return None
else:
return conn
def main():
now = datetime.datetime.now()
if not now.weekday():
print('not week day')
return
db = DBSelector()
conn = db.get_mysql_conn('ptrade')
cursor = conn.cursor()
sql_str = 'select count(*) from `ptrade_runing_status` where `date`=%s limit 1'
date = now.strftime('%Y-%m-%d')
cursor.execute(sql_str, (date,))
result = cursor.fetchone()
if result[0] == 0:
send_message_via_wechat('{} ptrade没有启动!'.format(now))
if __name__=='__main__':
main()

Ptrade的回测程序是在本地运行还是远程服务器? 关闭ptrade后原来运行的回测还可以继续运行吗?
回复李魔佛 回复了问题 • 1 人关注 • 1 个回复 • 5636 次浏览 • 2022-09-11 21:07
Ptrade与QMT 获取可转债基础数据,溢价率,剩余规模,评级,双低,是否强赎
李魔佛 发表了文章 • 0 个评论 • 4131 次浏览 • 2022-09-08 22:25
搜索接口文档,关键字 可转债 , 只有可怜的一个接口。并且这个接口还是最近才提供的。
基本没有可转债的其他基础数据。
比如 溢价率,剩余规模,评级,双低,到期,强赎。
笔者也为了方便,跨平台,把数据调用抽离出来,写成可以调用 接口的方式。
用的post请求方式。
这样无论是ptrade还是qmt,还是平时写的选股web页面, 都可以直接调用同一个数据源。 而你只需要维护一个数据数据源。
需要接口的,可以加入星球 或者 开通ptrade/QMT 的同时 获取。
查看全部

搜索接口文档,关键字 可转债 , 只有可怜的一个接口。并且这个接口还是最近才提供的。
基本没有可转债的其他基础数据。
比如 溢价率,剩余规模,评级,双低,到期,强赎。

笔者也为了方便,跨平台,把数据调用抽离出来,写成可以调用 接口的方式。

用的post请求方式。
这样无论是ptrade还是qmt,还是平时写的选股web页面, 都可以直接调用同一个数据源。 而你只需要维护一个数据数据源。

需要接口的,可以加入星球 或者 开通ptrade/QMT 的同时 获取。
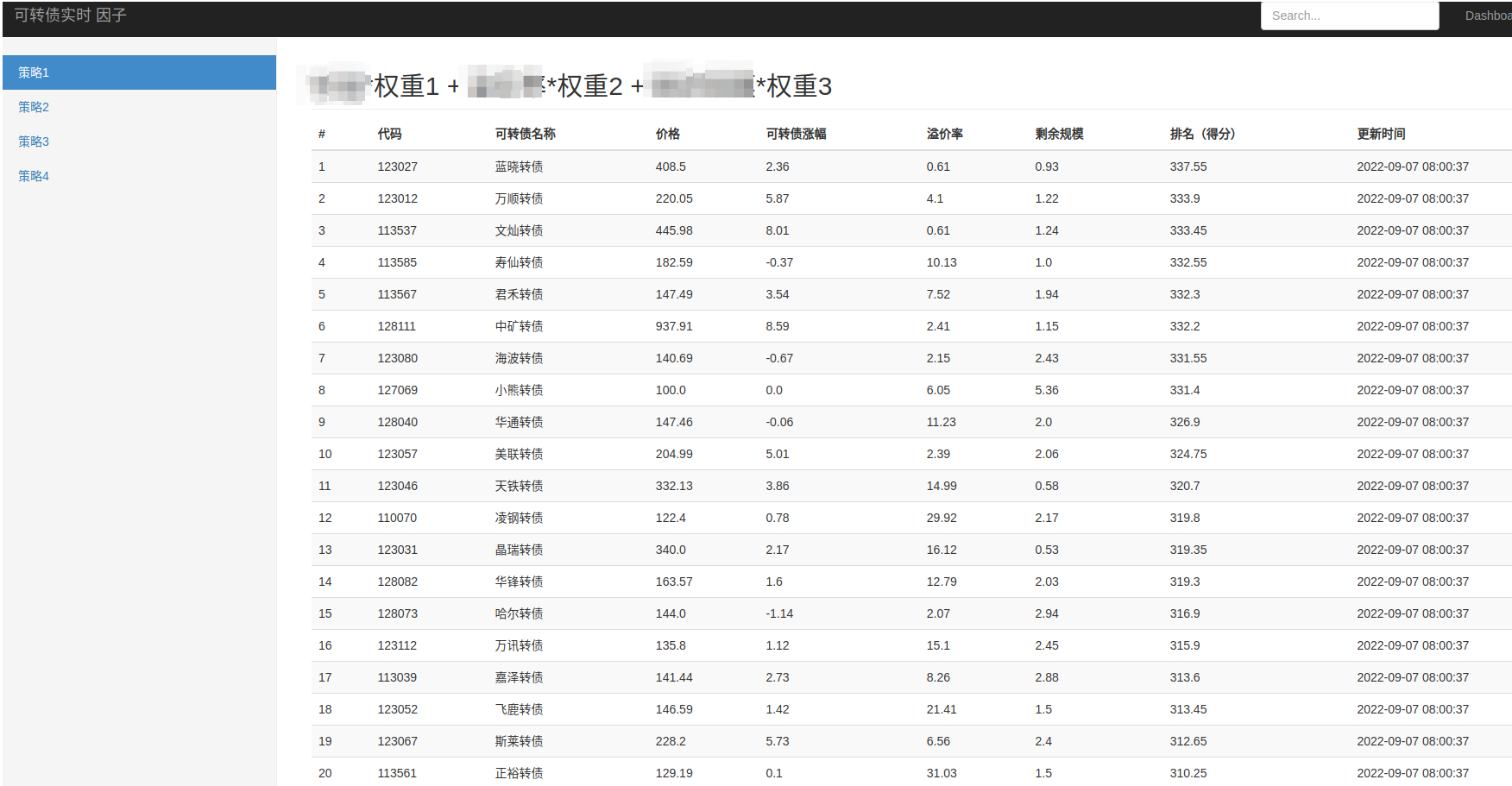
花了1小时用django快速写了个可转债实时系统
李魔佛 发表了文章 • 0 个评论 • 2563 次浏览 • 2022-09-07 08:08
用django快速搭了个页面给他
点击查看大图
数据是实时选出来的。当时帮他做的回测收益率也是很高,主要回撤控制得很好。
本来想用gin写,发现后台的dataframe还有这要找go下对应的库,避免计算出错,还是用会python吧(-。-)
公众号: 查看全部
用django快速搭了个页面给他
数据是实时选出来的。当时帮他做的回测收益率也是很高,主要回撤控制得很好。
本来想用gin写,发现后台的dataframe还有这要找go下对应的库,避免计算出错,还是用会python吧(-。-)
公众号:
ptrade和qmt的内置代码编辑器,哪个比较好用?
李魔佛 发表了文章 • 0 个评论 • 3379 次浏览 • 2022-09-05 11:24
答:都十分渣,半斤八两。更裸手在记事本写代码差不多的感觉。 尤其对于新人,经常可能会因为一些拼写错误,换行等问题,折腾一天,才能找到原因,至少pycharm对没有引用的变量是变灰的,语法错误是红的,快速帮助定位错误。(我自己就亲身经历过这种调试惨案,太惨痛。)
查看全部
答:都十分渣,半斤八两。更裸手在记事本写代码差不多的感觉。 尤其对于新人,经常可能会因为一些拼写错误,换行等问题,折腾一天,才能找到原因,至少pycharm对没有引用的变量是变灰的,语法错误是红的,快速帮助定位错误。(我自己就亲身经历过这种调试惨案,太惨痛。)
从零开始 手撸一个回测框架 (以可转债双低,低溢价为例)
李魔佛 发表了文章 • 0 个评论 • 3726 次浏览 • 2022-09-01 18:39
Mysql 数据
下面是代码主框架,目前通过之前优矿的导出的csv数据 ,计算 各个因子。 通过不同权重评分,进行轮动。class DataFeed:
def __init__(self):
self.csv_path = CSV_PATH
self.position = {}
self.HighValue = 0
self.Start_Cash = 1000000 # 初始资金
self.MyCash = self.Start_Cash
self.Withdraw = 0
self.daily_netvalue =
self.current_day = 0
self.PosValue = 0
self.threshold = 0 # 阈值
self.HighValue = self.Start_Cash
self.date_list, self.source = self.feed()
self.day_count = 0
def unpossibile(self, df, date):
# 剔除当日涨停的转债,买不入
raise_limited_dict = {
'2022-04-08': ['127057', ],
'2022-07-27': ['127065', ],
'2022-07-28': ['127065', ],
}
target_list = raise_limited_dict.get(date, None)
if target_list is None:
return df
return df.drop(index=target_list, axis=1)
def feed(self):
df = pd.read_csv(self.csv_path,
encoding='utf8',
dtype={'tickerEqu': str, 'tickerBond': str, 'secID_x': str},
)
del df['Unnamed: 0']
df['tradeDate'] = pd.to_datetime(df['tradeDate'], format='%Y-%m-%d')
df = df.set_index('tradeDate')
date_set = set(df.index.tolist())
date_list = list(map(lambda x: x.strftime('%Y-%m-%d'), date_set))
date_list.sort()
return date_list, df
def filters(self, df, today):
# 过滤条件,可添加多个条件
df = self.unpossibile(df, today)
return df
def logprint(self, current):
log.info('当前日期{}'.format(current))
def run(self):
for current in self.date_list:
if current < START_DATE or current > END_DATE:
continue
if self.day_count % FREQ != 0:
self.get_daily_netvalue(current)
else:
self.handle_data(current)
self.day_count += 1
self.after_trade()
双低和低溢价选债轮动:
上面是主要框架代码, 根据数据来驱动交易。 可以根据不同的时间日期进行回测交易。不同持有个数,不同轮动功能天数。【完整代码可以常见 知识星球】
运行: python main.py
运行后会自动保存一个excel文件:
并且可以生成收益率曲线图:
完整代码与数据可以参考星球代码:
查看全部

下面是代码主框架,目前通过之前优矿的导出的csv数据 ,计算 各个因子。 通过不同权重评分,进行轮动。
class DataFeed:
def __init__(self):
self.csv_path = CSV_PATH
self.position = {}
self.HighValue = 0
self.Start_Cash = 1000000 # 初始资金
self.MyCash = self.Start_Cash
self.Withdraw = 0
self.daily_netvalue =
self.current_day = 0
self.PosValue = 0
self.threshold = 0 # 阈值
self.HighValue = self.Start_Cash
self.date_list, self.source = self.feed()
self.day_count = 0
def unpossibile(self, df, date):
# 剔除当日涨停的转债,买不入
raise_limited_dict = {
'2022-04-08': ['127057', ],
'2022-07-27': ['127065', ],
'2022-07-28': ['127065', ],
}
target_list = raise_limited_dict.get(date, None)
if target_list is None:
return df
return df.drop(index=target_list, axis=1)
def feed(self):
df = pd.read_csv(self.csv_path,
encoding='utf8',
dtype={'tickerEqu': str, 'tickerBond': str, 'secID_x': str},
)
del df['Unnamed: 0']
df['tradeDate'] = pd.to_datetime(df['tradeDate'], format='%Y-%m-%d')
df = df.set_index('tradeDate')
date_set = set(df.index.tolist())
date_list = list(map(lambda x: x.strftime('%Y-%m-%d'), date_set))
date_list.sort()
return date_list, df
def filters(self, df, today):
# 过滤条件,可添加多个条件
df = self.unpossibile(df, today)
return df
def logprint(self, current):
log.info('当前日期{}'.format(current))
def run(self):
for current in self.date_list:
if current < START_DATE or current > END_DATE:
continue
if self.day_count % FREQ != 0:
self.get_daily_netvalue(current)
else:
self.handle_data(current)
self.day_count += 1
self.after_trade()
双低和低溢价选债轮动:

上面是主要框架代码, 根据数据来驱动交易。 可以根据不同的时间日期进行回测交易。不同持有个数,不同轮动功能天数。【完整代码可以常见 知识星球】
运行: python main.py

运行后会自动保存一个excel文件:
并且可以生成收益率曲线图:

完整代码与数据可以参考星球代码:
python获取通达信可转债日线和分时数据
李魔佛 发表了文章 • 0 个评论 • 9401 次浏览 • 2022-08-28 10:41
除了优矿,还有哪些可以获取可转债日线,甚至分时tick数据呢?当然笔者压箱底里面还有很多可用数据源的。本文就简单介绍其中一个,下通达信数据源。
安装
使用pip安装第三方库pytdxpip install pytdx
分时数据
下面6行python代码, 就可以获取通达信的可转债分时数据。from pytdx.hq import TdxHq_API
api = TdxHq_API()
with api.connect('119.147.212.81', 7709):
data = api.get_security_bars(7, 0, '123045', 0, 240) # 123045 为转债代码 ,240 为获取 240个转债数据
df = api.to_df(data)
df=df.sort_values('datetime')
如果需要遍历当前最新可转债代码,需要结合前面的文章。【注意这代码会定期更新,因网站架构或者字段是不定时变动】
不过前面的接口只能读取800条数据,以一天240条数据计算,只能读取2天多的数据量,对于需要更多数据的朋友来说,肯定不够的。或者有一个办法,把上面代码写成定时任务,就可以每天收盘后自动存储对应的数据。
如果需要更多的历史数据,那么可以使用pytdx的另外一个功能,那就是使用python读取通达信本地数据文件。
先用通达信同步1分钟(或5分钟)数据到本地.
选择沪深京分钟线,当然,其他数据你也可以选择。勾选一分钟线数据或者5分钟线数据,还有日期。不过这里日期会有限制,只能下载100天的1分钟线,或者500天的5分钟线。所以如果长期需要这个数据,你可以每隔一段时间下载一次。
数据保存路径:通达信安装目录的 vipdoc 子目录比如我的通达信客户端安装在 c:\new_tdx 下,
即
c:\new_tdx\vipdoc\sz\lday\ 下是深圳的日k线数据
c:\new_tdx\vipdoc\sh\lday\ 下是上海的日k线数据
c:\new_tdx\vipdoc\sh\minline\ 下是上海的分钟线数据
c:\new_tdx\vipdoc\sz\minline\ 下是深圳的分钟线数据
如果你需要更久的历史数据,可以到网上找找,下载下来后按照下面代码读取即可。 from pytdx.reader import TdxMinBarReader
path='/home/xda/Downloads/sz128014.lc1'
reader = TdxMinBarReader()
df = reader.get_df(path)
#df.to_excel('tick.xlsx') # 导出为excel
得到dataframe对象后,接着可以保存为excel,数据库都很简单了。一条语句的事情。
可转债日线数据
当然,能够获取到分钟数据,对于日线数据更加不在话下了。日线数据并没有日期限制,想下多少有多少。api = TdxHq_API()
api = api.connect('119.147.212.81', 7709)
data=api.get_k_data('123045', '2020-05-01', '2022-08-26') # 123045 为可转债代码,可以替换任意代码
data.to_excel('k-line.xlsx')
如果想获取正股或者其他股票数据,只需要把代码替换成正股股票代码即可。
如果分钟数据还不满足,还可以使用更小粒度的tick数据。下回有空再继续介绍,敬请关注。
欢迎关注公众号 查看全部

除了优矿,还有哪些可以获取可转债日线,甚至分时tick数据呢?当然笔者压箱底里面还有很多可用数据源的。本文就简单介绍其中一个,下通达信数据源。
安装
使用pip安装第三方库pytdx
pip install pytdx
分时数据
下面6行python代码, 就可以获取通达信的可转债分时数据。
from pytdx.hq import TdxHq_API
api = TdxHq_API()
with api.connect('119.147.212.81', 7709):
data = api.get_security_bars(7, 0, '123045', 0, 240) # 123045 为转债代码 ,240 为获取 240个转债数据
df = api.to_df(data)
df=df.sort_values('datetime')

如果需要遍历当前最新可转债代码,需要结合前面的文章。【注意这代码会定期更新,因网站架构或者字段是不定时变动】
不过前面的接口只能读取800条数据,以一天240条数据计算,只能读取2天多的数据量,对于需要更多数据的朋友来说,肯定不够的。或者有一个办法,把上面代码写成定时任务,就可以每天收盘后自动存储对应的数据。
如果需要更多的历史数据,那么可以使用pytdx的另外一个功能,那就是使用python读取通达信本地数据文件。
先用通达信同步1分钟(或5分钟)数据到本地.

选择沪深京分钟线,当然,其他数据你也可以选择。勾选一分钟线数据或者5分钟线数据,还有日期。不过这里日期会有限制,只能下载100天的1分钟线,或者500天的5分钟线。所以如果长期需要这个数据,你可以每隔一段时间下载一次。
数据保存路径:通达信安装目录的 vipdoc 子目录
比如我的通达信客户端安装在 c:\new_tdx 下,
即
c:\new_tdx\vipdoc\sz\lday\ 下是深圳的日k线数据
c:\new_tdx\vipdoc\sh\lday\ 下是上海的日k线数据
c:\new_tdx\vipdoc\sh\minline\ 下是上海的分钟线数据
c:\new_tdx\vipdoc\sz\minline\ 下是深圳的分钟线数据

如果你需要更久的历史数据,可以到网上找找,下载下来后按照下面代码读取即可。
from pytdx.reader import TdxMinBarReader
path='/home/xda/Downloads/sz128014.lc1'
reader = TdxMinBarReader()
df = reader.get_df(path)
#df.to_excel('tick.xlsx') # 导出为excel

得到dataframe对象后,接着可以保存为excel,数据库都很简单了。一条语句的事情。
可转债日线数据
当然,能够获取到分钟数据,对于日线数据更加不在话下了。日线数据并没有日期限制,想下多少有多少。
api = TdxHq_API()
api = api.connect('119.147.212.81', 7709)
data=api.get_k_data('123045', '2020-05-01', '2022-08-26') # 123045 为可转债代码,可以替换任意代码
data.to_excel('k-line.xlsx')

如果想获取正股或者其他股票数据,只需要把代码替换成正股股票代码即可。
如果分钟数据还不满足,还可以使用更小粒度的tick数据。下回有空再继续介绍,敬请关注。

欢迎关注公众号
6行python代码 获取通达信的可转债分时数据
李魔佛 发表了文章 • 0 个评论 • 4184 次浏览 • 2022-08-27 14:33
api = TdxHq_API()
with api.connect('119.147.212.81', 7709):
data = api.get_security_bars(7, 0, '123045', 0, 240) # 123045 为转债代码 ,240 为获取 240个转债数据
df = api.to_df(data)
df=df.sort_values('datetime')
点击查看大图
如果需要遍历当前最新可转债代码(集思录),需要结合前面的文章。
公众号:
查看全部
from pytdx.hq import TdxHq_API
api = TdxHq_API()
with api.connect('119.147.212.81', 7709):
data = api.get_security_bars(7, 0, '123045', 0, 240) # 123045 为转债代码 ,240 为获取 240个转债数据
df = api.to_df(data)
df=df.sort_values('datetime')

如果需要遍历当前最新可转债代码(集思录),需要结合前面的文章。
公众号:
Ptrade 逆回购+自动申购新股可转债
李魔佛 发表了文章 • 0 个评论 • 3743 次浏览 • 2022-08-24 20:03
本站所有代码均经过实盘验证。# ptrade软件-量化-回测 里,新建策略,复制全文粘贴进去,周期选分钟,再到交易里新增交易
import time
def reverse_repurchase(context):
cash = context.portfolio.cash
amount = int(cash/1000)*10
log.info(amount)
order('131810.SZ', -1*amount) # 深圳逆回购,
def ipo(context):
ipo_stocks_order()
def initialize(context):
g.flag = False
log.info("initialize g.flag=" + str(g.flag) )
run_daily(context, reverse_repurchase, '14:57')
run_daily(context, ipo, '13:30')
def before_trading_start(context, data):
pass
def handle_data(context, data):
pass
def on_order_response(context, order_list):
# 该函数会在委托回报返回时响应
log.info(order_list)
上面代码设定在13:30分申购新股,新债;
在14:57分申购深圳逆回购R-001
喜欢的朋友拿去,欢迎转载。
欢迎关注公众号
查看全部
本站所有代码均经过实盘验证。
# ptrade软件-量化-回测 里,新建策略,复制全文粘贴进去,周期选分钟,再到交易里新增交易
import time
def reverse_repurchase(context):
cash = context.portfolio.cash
amount = int(cash/1000)*10
log.info(amount)
order('131810.SZ', -1*amount) # 深圳逆回购,
def ipo(context):
ipo_stocks_order()
def initialize(context):
g.flag = False
log.info("initialize g.flag=" + str(g.flag) )
run_daily(context, reverse_repurchase, '14:57')
run_daily(context, ipo, '13:30')
def before_trading_start(context, data):
pass
def handle_data(context, data):
pass
def on_order_response(context, order_list):
# 该函数会在委托回报返回时响应
log.info(order_list)
上面代码设定在13:30分申购新股,新债;
在14:57分申购深圳逆回购R-001
喜欢的朋友拿去,欢迎转载。
欢迎关注公众号
Ptrade 获取当天可转债代码列表
李魔佛 发表了文章 • 0 个评论 • 2984 次浏览 • 2022-08-22 18:46
可以在开盘的时候获取所有可转债列表。
def initialize(context):
run_daily(context, get_trade_cb_list, "9:25")
def before_trading_start(context, data):
# 每日清空,避免取到昨日市场代码表
g.trade_cb_list =
def handle_data(context, data):
pass
# 获取当天可交易的可转债代码列表
def get_trade_cb_list(context):
cb_list = get_cb_list()
cb_snapshot = get_snapshot(cb_list)
# 代码有行情快照并且交易状态不在暂停交易、停盘、长期停盘、退市状态的判定为可交易代码
g.trade_cb_list = [cb_code for cb_code in cb_list if
cb_snapshot.get(cb_code, {}).get("trade_status") not in
[None, "HALT", "SUSP", "STOPT", "DELISTED"]]
log.info("当天可交易的可转债代码列表为:%s" % g.trade_cb_list)
如果需要获取可转债溢价率,评级,剩余规模,强赎等数据,可以调用我之前提供的接口。
需要的可以关注个人星球和公众号。
欢迎关注公众号
查看全部
可以在开盘的时候获取所有可转债列表。
def initialize(context):
run_daily(context, get_trade_cb_list, "9:25")
def before_trading_start(context, data):
# 每日清空,避免取到昨日市场代码表
g.trade_cb_list =
def handle_data(context, data):
pass
# 获取当天可交易的可转债代码列表
def get_trade_cb_list(context):
cb_list = get_cb_list()
cb_snapshot = get_snapshot(cb_list)
# 代码有行情快照并且交易状态不在暂停交易、停盘、长期停盘、退市状态的判定为可交易代码
g.trade_cb_list = [cb_code for cb_code in cb_list if
cb_snapshot.get(cb_code, {}).get("trade_status") not in
[None, "HALT", "SUSP", "STOPT", "DELISTED"]]
log.info("当天可交易的可转债代码列表为:%s" % g.trade_cb_list)
如果需要获取可转债溢价率,评级,剩余规模,强赎等数据,可以调用我之前提供的接口。
需要的可以关注个人星球和公众号。
欢迎关注公众号
Ptrade里面的 持久化 (pickle)要求 报错:
李魔佛 发表了文章 • 0 个评论 • 3542 次浏览 • 2022-08-22 17:42
为什么要做持久化处理
服务器异常、策略优化等诸多场景,都会使得正在进行的模拟盘和实盘策略存在中断后再重启的需求,但是一旦交易中止后,策略中存储在内存中的全局变量就清空了,因此通过持久化处理为量化交易保驾护航必不可少。
量化框架持久化处理
使用pickle模块保存股票池、账户信息、订单信息、全局变量g定义的变量等内容。
注意事项:
框架会在before_trading_start(隔日开始)、handle_data、after_trading_end事件后触发持久化信息更新及保存操作;
券商升级/环境重启后恢复交易时,框架会先执行策略initialize函数再执行持久化信息恢复操作。
如果持久化信息保存有策略定义的全局对象g中的变量,将会以持久化信息中的变量覆盖掉initialize函数中初始化的该变量。
1 全局变量g中不能被序列化的变量将不会被保存。
您可在initialize中初始化该变量时名字以'__'开头;
2 涉及到IO(打开的文件,实例化的类对象等)的对象是不能被序列化的;
3 全局变量g中以'__'开头的变量为私有变量,持久化时将不会被保存;
示例代码:class Test(object):
count = 5
def print_info(self):
self.count += 1
log.info("a" * self.count)
def initialize(context):
g.security = "600570.SS"
set_universe(g.security)
# 初始化无法被序列化类对象,并赋值为私有变量,落地持久化信息时跳过保存该变量
g.__test_class = Test()
def handle_data(context, data):
# 调用私有变量中定义的方法
g.__test_class.print_info()
其实官方文档说了这么多,实际意思就是 类和涉及IO的 变量 不能序列化,导致不能在g中作为全局变量,如果要作为全局变量,需要 用2个前下划线__ 命名,比如 g.__db = Bond()
class Bond:
pass
不然就会报错:
_pickle.PickingError: Can't pick <class 'IOEngine.user_module : attribute loopup
欢迎关注公众号 查看全部
为什么要做持久化处理
服务器异常、策略优化等诸多场景,都会使得正在进行的模拟盘和实盘策略存在中断后再重启的需求,但是一旦交易中止后,策略中存储在内存中的全局变量就清空了,因此通过持久化处理为量化交易保驾护航必不可少。
量化框架持久化处理
使用pickle模块保存股票池、账户信息、订单信息、全局变量g定义的变量等内容。
注意事项:
框架会在before_trading_start(隔日开始)、handle_data、after_trading_end事件后触发持久化信息更新及保存操作;
券商升级/环境重启后恢复交易时,框架会先执行策略initialize函数再执行持久化信息恢复操作。
如果持久化信息保存有策略定义的全局对象g中的变量,将会以持久化信息中的变量覆盖掉initialize函数中初始化的该变量。
1 全局变量g中不能被序列化的变量将不会被保存。
您可在initialize中初始化该变量时名字以'__'开头;
2 涉及到IO(打开的文件,实例化的类对象等)的对象是不能被序列化的;
3 全局变量g中以'__'开头的变量为私有变量,持久化时将不会被保存;
示例代码:
class Test(object):
count = 5
def print_info(self):
self.count += 1
log.info("a" * self.count)
def initialize(context):
g.security = "600570.SS"
set_universe(g.security)
# 初始化无法被序列化类对象,并赋值为私有变量,落地持久化信息时跳过保存该变量
g.__test_class = Test()
def handle_data(context, data):
# 调用私有变量中定义的方法
g.__test_class.print_info()
其实官方文档说了这么多,实际意思就是 类和涉及IO的 变量 不能序列化,导致不能在g中作为全局变量,如果要作为全局变量,需要 用2个前下划线__ 命名,比如 g.__db = Bond()
class Bond:
pass
不然就会报错:
_pickle.PickingError: Can't pick <class 'IOEngine.user_module : attribute loopup

欢迎关注公众号
虚拟机 云服务器 运行qmt 方案
李魔佛 发表了文章 • 0 个评论 • 5640 次浏览 • 2022-08-20 17:17
众所周知,部分券商(国盛证券)限制了虚拟机登录QMT。
比如在vmare中安装了QMT,可以在QMT的信息里面看到:
点击查看大图
比如上面的截图, 如果和实体机的设备信息做一个对比,可以看到,虚拟机下的QMT的硬盘序列号(红框的位置) 是空的,而实体物理机下,红框的硬盘序列号 是有内容的。 所以一个办法是尝试修改这个硬盘序列号。
或者换一个支持虚拟机的券商。其实这个限制是券商端定制的功能,部分券商并没有限制虚拟机禁止登陆QMT的。
比如国金证券的QMT,可以在虚拟机或者云服务器上登录。费率也可以万一免五,参考文章:
http://www.30daydo.com/article/44479 查看全部

点击查看大图
众所周知,部分券商(国盛证券)限制了虚拟机登录QMT。
比如在vmare中安装了QMT,可以在QMT的信息里面看到:

点击查看大图
比如上面的截图, 如果和实体机的设备信息做一个对比,可以看到,虚拟机下的QMT的硬盘序列号(红框的位置) 是空的,而实体物理机下,红框的硬盘序列号 是有内容的。 所以一个办法是尝试修改这个硬盘序列号。
或者换一个支持虚拟机的券商。其实这个限制是券商端定制的功能,部分券商并没有限制虚拟机禁止登陆QMT的。
比如国金证券的QMT,可以在虚拟机或者云服务器上登录。费率也可以万一免五,参考文章:
http://www.30daydo.com/article/44479
通过mini qmt xtdata获取tick数据 python代码
李魔佛 发表了文章 • 0 个评论 • 5786 次浏览 • 2022-08-17 18:03
from xtquant import xtdata
xtdata.download_history_data(code, period=period, start_time=start_time, end_time=end_time)
data = xtdata.get_local_data(field_list=, stock_code=, period=period, count=10)
result_list = data df = pd.DataFrame(result_list)
df['time_str'] = df['time'].apply(lambda x: datetime.datetime.fromtimestamp(x / 1000.0))
return df
上面python代码传入一个代码,和初试时间,需要的周期数据(分钟,秒,日等),就可以返回一个dataframe格式的数据了。
欢迎关注公众号 查看全部
def get_tick(code, start_time, end_time, period='tick'):
from xtquant import xtdata
xtdata.download_history_data(code, period=period, start_time=start_time, end_time=end_time)
data = xtdata.get_local_data(field_list=, stock_code=
, period=period, count=10)
result_list = data
df = pd.DataFrame(result_list)
df['time_str'] = df['time'].apply(lambda x: datetime.datetime.fromtimestamp(x / 1000.0))
return df
上面python代码传入一个代码,和初试时间,需要的周期数据(分钟,秒,日等),就可以返回一个dataframe格式的数据了。
欢迎关注公众号
Ptrade下单接口 order,order_target, order_value,order_target_value的区别
李魔佛 发表了文章 • 0 个评论 • 3273 次浏览 • 2022-08-11 23:57
接口
order_value 接口通过 金额/限价 或者 金额/默认最新价 两种方式转换成需要交易的数量,
传入 order 接口
order_target_value 接口通过持仓金额比较得到需要交易的金额, 金额/限价 或者 金额/默
认最新价 两种方式转换成需要交易的数量,传入 order 接口
所以其他几个接口都是对order的封装。
order接口的逻辑:order 接口:
一、
先判断 limit_price 是否传入,传入则用传入价格限价,不传入则最新价代替,都是
限价方式报单。二、
判断隔夜单和交易时间,交易时间(9:10(系统可配)~15:00)范围的订单会马上
加入未处理订单队列,其他订单先放到一个队列,等时间到交易时间就放到未处理订单
队列三、
未处理订单队列的订单会进行限价判断,如果没有传入限价就按当前最新价处理,
然后报柜台
欢迎关注公众号 查看全部
order_target 接口通过持仓数量比较将入参的目标数量转换成需要交易的成交,传入 order
接口
order_value 接口通过 金额/限价 或者 金额/默认最新价 两种方式转换成需要交易的数量,
传入 order 接口
order_target_value 接口通过持仓金额比较得到需要交易的金额, 金额/限价 或者 金额/默
认最新价 两种方式转换成需要交易的数量,传入 order 接口
所以其他几个接口都是对order的封装。
order接口的逻辑:
order 接口:
一、
先判断 limit_price 是否传入,传入则用传入价格限价,不传入则最新价代替,都是
限价方式报单。
二、
判断隔夜单和交易时间,交易时间(9:10(系统可配)~15:00)范围的订单会马上
加入未处理订单队列,其他订单先放到一个队列,等时间到交易时间就放到未处理订单
队列
三、
未处理订单队列的订单会进行限价判断,如果没有传入限价就按当前最新价处理,
然后报柜台
欢迎关注公众号
Ptrade抢新上市的可转债
李魔佛 发表了文章 • 0 个评论 • 2445 次浏览 • 2022-08-11 10:20

PS: 也不是每一只都是去抢,还是需要提前判断下。规模小的优先。
欢迎关注公众号
自己写的包在 PTrade 里如何使用的方法有吗?
李魔佛 发表了文章 • 0 个评论 • 2933 次浏览 • 2022-08-08 03:28
A:和常规 Python 函数调用时一样的,只是需要和你的其它函数放在同一个脚本
中,暂时不支持跨越脚本文件的调用。
所以你写的包,都要放着ptrade的策略里面,不能另外保存到一个地方,然后通过 from xxxx import xxxx 这种方式导入。
所以有时候你的ptrade文件会臃肿无比。经常复制粘贴。也是无奈之举。
欢迎关注公众号 查看全部
A:和常规 Python 函数调用时一样的,只是需要和你的其它函数放在同一个脚本
中,暂时不支持跨越脚本文件的调用。
所以你写的包,都要放着ptrade的策略里面,不能另外保存到一个地方,然后通过 from xxxx import xxxx 这种方式导入。
所以有时候你的ptrade文件会臃肿无比。经常复制粘贴。也是无奈之举。
欢迎关注公众号
ptrade支持文件的读写吗,Excel 文件可以读写吗
李魔佛 发表了文章 • 0 个评论 • 3268 次浏览 • 2022-08-08 00:01
当前支持 csv,xlsx,txt,pkl 等文件的读取,需要手动将对应文件上传到研究环境中,
然后在回测中使用 get_research_path()+”文件名”获取文件路径后进行读取(见下图),
回写文件类似,可使用 pd.to_csv()等函数存储在研究环境指定目录下。
值得注意的是,当前支持单个文件最大为 50M
模型每天都会更新的,权重文件,能上传吗?
可以,注意文件大小的限制。
欢迎关注公众号 查看全部
当前支持 csv,xlsx,txt,pkl 等文件的读取,需要手动将对应文件上传到研究环境中,
然后在回测中使用 get_research_path()+”文件名”获取文件路径后进行读取(见下图),
回写文件类似,可使用 pd.to_csv()等函数存储在研究环境指定目录下。
值得注意的是,当前支持单个文件最大为 50M

模型每天都会更新的,权重文件,能上传吗?
可以,注意文件大小的限制。
欢迎关注公众号
优矿使用的python版本
李魔佛 发表了文章 • 0 个评论 • 2746 次浏览 • 2022-08-07 08:22
从底层来看它的报错信息:
它是使用python2.7
可是异常操作,却可以使用python3的语法
try:
....
except Exception as e:
.....
所以有些地方还是得要注意一下 py2和py3的区别
比如py2的字典默认顺序是无序的。(这个有一次调试一个bug耗费了一两个小时,结果发现用了字典,取key,结果发现key的顺序全部是乱的,py3从3.6开始字典的key是有序的)
查看全部
从底层来看它的报错信息:

它是使用python2.7
可是异常操作,却可以使用python3的语法
try:
....
except Exception as e:
.....
所以有些地方还是得要注意一下 py2和py3的区别
比如py2的字典默认顺序是无序的。(这个有一次调试一个bug耗费了一两个小时,结果发现用了字典,取key,结果发现key的顺序全部是乱的,py3从3.6开始字典的key是有序的)
可转债多因子回测 优矿代码
李魔佛 发表了文章 • 0 个评论 • 4001 次浏览 • 2022-08-06 18:00
实际运用里面,可以加入很多很多因子,比如正股涨跌幅,正股波动率,转债到期时间,正股ROE等等多大几十个因子。
之前写了一个多因子回测的优矿python代码,用户可以自己修改参数,
比如下面的正股波动率因子,Bond_Volatility_ENABLE = True
Bond_Volatility_DAYS = 30
TOP_RIPPLE = 50
Bond_Volatility_LOG_ENABLE = True # 波动率日志开关
Bond_Volatility_ENABLE = True 设为True,就是回测过程加入这个因子,设为False就忽略这个因子。
下面的
Bond_Volatility_DAYS 为N天内的正股波动率,一般设置30天,20天内就够了,因为一年之前的即使波动很大,那对当前转债的影响也很小。
TOP_RIPPLE 选择波动率最大的前面N只转债
举个例子,下面转债是根据其对应正股的30天里的波动率选出来的。(当前是8月5日,也就是7月5日到8月5日之间的数据)。
计算波动率具体代码如下;
每个因子写成一个类。
这样可以不用修改主代码,就可以无限地添加,修改因子。# 基类
class ConditionFilter:
def filters(self, *args, **kwargs):
if self.enable:
return self.fun(*args, **kwargs)
else:
return True
def fun(self, *args, **kwargs):
# 继承的实现这个函数
raise NotImplemented
上面是部分过滤因子,也就是不满足的都会被移除。 比如规模大于10亿的会移除。
然后得到的结果,进行因子评分。 # 权重 溢价率、转债价格、正股N天涨幅,正股ROE
weights = {'溢价率': 0, '转债价格': 1, '正股N天涨幅': 0, '正股ROE': 0, '规模': 0}
每个权重赋予一个权重分最高是1,最低是0,如果你想回测 低溢价率 策略,只需要把其他因子的权重全部设置为0,溢价率设置为1即可。双底的话就是 溢价率和价格各为0.5 就可以了。
设置好参数后,设置你要回测的时间,持仓周期,持有个数等可调参数。
稍等片刻就会有结果了。因子越多,运行时间会增加。一般几分钟就可以得到几年来的回测结果。
中途可以查看日志
完整代码以及运行流程可到知识星球咨询了解。
欢迎关注公众号 查看全部
实际运用里面,可以加入很多很多因子,比如正股涨跌幅,正股波动率,转债到期时间,正股ROE等等多大几十个因子。

之前写了一个多因子回测的优矿python代码,用户可以自己修改参数,
比如下面的正股波动率因子,
Bond_Volatility_ENABLE = True
Bond_Volatility_DAYS = 30
TOP_RIPPLE = 50
Bond_Volatility_LOG_ENABLE = True # 波动率日志开关
Bond_Volatility_ENABLE = True 设为True,就是回测过程加入这个因子,设为False就忽略这个因子。
下面的
Bond_Volatility_DAYS 为N天内的正股波动率,一般设置30天,20天内就够了,因为一年之前的即使波动很大,那对当前转债的影响也很小。
TOP_RIPPLE 选择波动率最大的前面N只转债
举个例子,下面转债是根据其对应正股的30天里的波动率选出来的。(当前是8月5日,也就是7月5日到8月5日之间的数据)。

计算波动率具体代码如下;

每个因子写成一个类。
这样可以不用修改主代码,就可以无限地添加,修改因子。
# 基类
class ConditionFilter:
def filters(self, *args, **kwargs):
if self.enable:
return self.fun(*args, **kwargs)
else:
return True
def fun(self, *args, **kwargs):
# 继承的实现这个函数
raise NotImplemented

上面是部分过滤因子,也就是不满足的都会被移除。 比如规模大于10亿的会移除。
然后得到的结果,进行因子评分。
# 权重 溢价率、转债价格、正股N天涨幅,正股ROE
weights = {'溢价率': 0, '转债价格': 1, '正股N天涨幅': 0, '正股ROE': 0, '规模': 0}
每个权重赋予一个权重分最高是1,最低是0,如果你想回测 低溢价率 策略,只需要把其他因子的权重全部设置为0,溢价率设置为1即可。双底的话就是 溢价率和价格各为0.5 就可以了。
设置好参数后,设置你要回测的时间,持仓周期,持有个数等可调参数。
稍等片刻就会有结果了。因子越多,运行时间会增加。一般几分钟就可以得到几年来的回测结果。

中途可以查看日志
完整代码以及运行流程可到知识星球咨询了解。

欢迎关注公众号
ptrade策略代码:集合竞价追涨停策略
李魔佛 发表了文章 • 0 个评论 • 6692 次浏览 • 2022-08-04 15:24
# 初始化此策略
# 设置我们要操作的股票池, 这里我们只操作一支股票
g.security = '600570.SS'
set_universe(g.security)
#每天9:23分运行集合竞价处理函数
run_daily(context, aggregate_auction_func, time='9:23')
def aggregate_auction_func(context):
stock = g.security
#最新价
snapshot = get_snapshot(stock)
price = snapshot[stock]['last_px']
#涨停价
up_limit = snapshot[stock]['up_px']
#如果最新价不小于涨停价,买入
if float(price) >= float(up_limit):
order(g.security, 100, limit_price=up_limit)
def handle_data(context, data):
pass
分解讲解:def initialize(context):
# 初始化此策略
# 设置我们要操作的股票池, 这里我们只操作一支股票
g.security = '600570.SS'
set_universe(g.security)
#每天9:23分运行集合竞价处理函数
run_daily(context, aggregate_auction_func, time='9:23')
initialize是初始化函数,一定要有的函数。在策略运行时首先运行的,而且只会运行一次。
set_universe(g.security) 在把标的代码放进去。这里是 '600570.SS' 记得要有后缀,上证股票用 .SS ,深圳股票用.SZ。
run_daily(context, aggregate_auction_func, time='9:23')
这一行是设定每天运行一次。这个策略是日线级别的,所以每天只要运行一次就可以了。 分别传入3个参数。
第一个参数固定是context,第二个要执行的函数名,记住只能传函数名,不能把括号也加进去,第三个参数,是运行的时间,现在设定在 9:23
那么接下来就是要实现上面那个函数名了: aggregate_auction_func,这个名字可以随意定义def aggregate_auction_func(context):
stock = g.security
#最新价
snapshot = get_snapshot(stock)
price = snapshot[stock]['last_px']
#涨停价
up_limit = snapshot[stock]['up_px']
#如果最新价不小于涨停价,买入
if float(price) >= float(up_limit):
order(g.security, 100, limit_price=up_limit)
stock = g.security , g是全局变量,用来在上下文中传递数据。这里就是上面的'600570.SS'
snapshot = get_snapshot(stock)
这个就是获取行情数据,当前的价格
up_limit = snapshot[stock]['up_px']
拿到这个标的的涨停价
if float(price) >= float(up_limit):
这个是当前价格大于涨停板价格(主要考虑了四舍五入,用于大号比较安全)
order(g.security, 100, limit_price=up_limit)
这个就是下单函数。
买入100股,不限价,市价成交。
然后就可以点击运行交易。
程序每天都会自动交易。
欢迎关注公众号
查看全部
def initialize(context):
# 初始化此策略
# 设置我们要操作的股票池, 这里我们只操作一支股票
g.security = '600570.SS'
set_universe(g.security)
#每天9:23分运行集合竞价处理函数
run_daily(context, aggregate_auction_func, time='9:23')
def aggregate_auction_func(context):
stock = g.security
#最新价
snapshot = get_snapshot(stock)
price = snapshot[stock]['last_px']
#涨停价
up_limit = snapshot[stock]['up_px']
#如果最新价不小于涨停价,买入
if float(price) >= float(up_limit):
order(g.security, 100, limit_price=up_limit)
def handle_data(context, data):
pass
分解讲解:
def initialize(context):
# 初始化此策略
# 设置我们要操作的股票池, 这里我们只操作一支股票
g.security = '600570.SS'
set_universe(g.security)
#每天9:23分运行集合竞价处理函数
run_daily(context, aggregate_auction_func, time='9:23')
initialize是初始化函数,一定要有的函数。在策略运行时首先运行的,而且只会运行一次。
set_universe(g.security) 在把标的代码放进去。这里是 '600570.SS' 记得要有后缀,上证股票用 .SS ,深圳股票用.SZ。
run_daily(context, aggregate_auction_func, time='9:23')
这一行是设定每天运行一次。这个策略是日线级别的,所以每天只要运行一次就可以了。 分别传入3个参数。
第一个参数固定是context,第二个要执行的函数名,记住只能传函数名,不能把括号也加进去,第三个参数,是运行的时间,现在设定在 9:23
那么接下来就是要实现上面那个函数名了: aggregate_auction_func,这个名字可以随意定义
def aggregate_auction_func(context):
stock = g.security
#最新价
snapshot = get_snapshot(stock)
price = snapshot[stock]['last_px']
#涨停价
up_limit = snapshot[stock]['up_px']
#如果最新价不小于涨停价,买入
if float(price) >= float(up_limit):
order(g.security, 100, limit_price=up_limit)
stock = g.security , g是全局变量,用来在上下文中传递数据。这里就是上面的'600570.SS'
snapshot = get_snapshot(stock)
这个就是获取行情数据,当前的价格
up_limit = snapshot[stock]['up_px']
拿到这个标的的涨停价
if float(price) >= float(up_limit):
这个是当前价格大于涨停板价格(主要考虑了四舍五入,用于大号比较安全)
order(g.security, 100, limit_price=up_limit)
这个就是下单函数。
买入100股,不限价,市价成交。
然后就可以点击运行交易。
程序每天都会自动交易。
欢迎关注公众号
ptrade可以同时执行多少个实盘策略?
李魔佛 发表了文章 • 0 个评论 • 3330 次浏览 • 2022-08-02 20:41
而在代码里面,如果多个策略同时运行,需要在代码层面区分不同策略下的单子,不然会造成冲突。比如你第一个策略下的单子,被第二个策略清仓了。
那么要如何区分不同策略下单呢?
1. 如果是日内策略,只需要用一个字典dict,记录每次买入记录,每次的卖出标的都要在dict里面。
2. 持久化。虽然大部分券商的ptrade都不支持联网,但是,可以使用本地持久化,pickle或者sqlite。保存在云本地。 查看全部

而在代码里面,如果多个策略同时运行,需要在代码层面区分不同策略下的单子,不然会造成冲突。比如你第一个策略下的单子,被第二个策略清仓了。
那么要如何区分不同策略下单呢?
1. 如果是日内策略,只需要用一个字典dict,记录每次买入记录,每次的卖出标的都要在dict里面。
2. 持久化。虽然大部分券商的ptrade都不支持联网,但是,可以使用本地持久化,pickle或者sqlite。保存在云本地。
ptrade如何以指定价格下单?
李魔佛 发表了文章 • 0 个评论 • 4259 次浏览 • 2022-07-30 19:27
order函数:order-按数量买卖
order(security, amount, limit_price=None)
买卖标的。
注意:
由于下述原因,回测中实际买入或者卖出的股票数量有时候可能与委托设置的不一样,针对上述内容调整,系统会在日志中增加警告信息:
根据委托买入数量与价格经计算后的资金数量,大于当前可用资金;
委托卖出数量大于当前可用持仓数量;
每次交易数量只能是100的整数倍,但是卖出所有股票时不受此限制;
股票停牌、股票未上市或者退市、股票不存在;
回测中每天结束时会取消所有未完成交易;
order_target - 函数order_target(security, amount, limit_price=None)
买卖股票,直到股票最终数量达到指定的amount。
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
参数
security: 股票代码(str);
amount: 期望的最终数量(int);
limit_price:买卖限价(float);
返回
Order对象中的id或者None。如果创建订单成功,则返回Order对象的id,失败则返回None(str)。
order_value 函数order_value - 指定目标价值买卖
order_value(security, value, limit_price=None)
买卖指定价值为value的股票。
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
order_target_value - 函数order_target_value - 指定持仓市值买卖
order_target_value(security, value, limit_price=None)
调整股票仓位到value价值
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
order_market 函数order_market - 按市价进行委托
order_market(security, amount, market_type=None, limit_price=None)
可以使用多种市价类型进行委托。
注意:该函数仅在股票交易模块可用。
上面几个在handle_data中使用的下单函数,都是无法指定价格的,limit_price 只是用于限价,比如你要卖1000股,limit_price的作用是不要把价格卖出你的目标,至于多少卖,是无法控制的。
但是有一个tick_data函数,专门用于行情交易的,里面可调用的函数也很少。tick_data(可选)
tick_data(context, data)
该函数会每隔3秒执行一次。
注意 :
该函数仅在交易模块可用。
该函数在9:30之后才能执行。
该函数中只能使用order_tick进行对应的下单操作。里面下单,用的下单函数是
order_tick - tick行情触发买卖
order_tick(sid, amount, priceGear='1', limit_price=None)
买卖股票下单,可设定价格档位进行委托
注意:该函数仅在交易模块可用。
参数
sid:股票代码(str);
amount:交易数量,正数表示买入,负数表示卖出(int)
priceGear:盘口档位,level1:1~5买档/-1~-5卖档,level2:1~10买档/-1~-10卖档(str)
limit_price:买卖限价,当输入参数中也包含priceGear时,下单价格以limit_price为主(float);
注意到里面:
limit_price:买卖限价,当输入参数中也包含priceGear时,下单价格以limit_price为主
发现这里面居然可以定义价格下单,所以如果一定要指定价格,就需要使用tick_data 触发。
使用代码:
def initialize(context):
g.security = "600570.SS"
set_universe(g.security)
def tick_data(context,data):
security = g.security
current_price = eval(data[security]['tick']['bid_grp'][0])[1][0]
if current_price > 56 and current_price < 57:
# 以买一档下单
order_tick(g.security, -100, "1")
# 以卖二档下单
order_tick(g.security, 100, "-2")
# 以指定价格下单
order_tick(g.security, 100, limit_price=56.5)
def handle_data(context, data):
pass 查看全部
order函数:
order-按数量买卖
order(security, amount, limit_price=None)
买卖标的。
注意:
由于下述原因,回测中实际买入或者卖出的股票数量有时候可能与委托设置的不一样,针对上述内容调整,系统会在日志中增加警告信息:
根据委托买入数量与价格经计算后的资金数量,大于当前可用资金;
委托卖出数量大于当前可用持仓数量;
每次交易数量只能是100的整数倍,但是卖出所有股票时不受此限制;
股票停牌、股票未上市或者退市、股票不存在;
回测中每天结束时会取消所有未完成交易;
order_target - 函数
order_target(security, amount, limit_price=None)
买卖股票,直到股票最终数量达到指定的amount。
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
参数
security: 股票代码(str);
amount: 期望的最终数量(int);
limit_price:买卖限价(float);
返回
Order对象中的id或者None。如果创建订单成功,则返回Order对象的id,失败则返回None(str)。
order_value 函数
order_value - 指定目标价值买卖
order_value(security, value, limit_price=None)
买卖指定价值为value的股票。
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
order_target_value - 函数
order_target_value - 指定持仓市值买卖
order_target_value(security, value, limit_price=None)
调整股票仓位到value价值
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
order_market 函数
order_market - 按市价进行委托
order_market(security, amount, market_type=None, limit_price=None)
可以使用多种市价类型进行委托。
注意:该函数仅在股票交易模块可用。
上面几个在handle_data中使用的下单函数,都是无法指定价格的,limit_price 只是用于限价,比如你要卖1000股,limit_price的作用是不要把价格卖出你的目标,至于多少卖,是无法控制的。
但是有一个tick_data函数,专门用于行情交易的,里面可调用的函数也很少。
tick_data(可选)里面下单,用的下单函数是
tick_data(context, data)
该函数会每隔3秒执行一次。
注意 :
该函数仅在交易模块可用。
该函数在9:30之后才能执行。
该函数中只能使用order_tick进行对应的下单操作。
order_tick - tick行情触发买卖
order_tick(sid, amount, priceGear='1', limit_price=None)
买卖股票下单,可设定价格档位进行委托
注意:该函数仅在交易模块可用。
参数
sid:股票代码(str);
amount:交易数量,正数表示买入,负数表示卖出(int)
priceGear:盘口档位,level1:1~5买档/-1~-5卖档,level2:1~10买档/-1~-10卖档(str)
limit_price:买卖限价,当输入参数中也包含priceGear时,下单价格以limit_price为主(float);
注意到里面:
limit_price:买卖限价,当输入参数中也包含priceGear时,下单价格以limit_price为主
发现这里面居然可以定义价格下单,所以如果一定要指定价格,就需要使用tick_data 触发。
使用代码:
def initialize(context):
g.security = "600570.SS"
set_universe(g.security)
def tick_data(context,data):
security = g.security
current_price = eval(data[security]['tick']['bid_grp'][0])[1][0]
if current_price > 56 and current_price < 57:
# 以买一档下单
order_tick(g.security, -100, "1")
# 以卖二档下单
order_tick(g.security, 100, "-2")
# 以指定价格下单
order_tick(g.security, 100, limit_price=56.5)
def handle_data(context, data):
pass
ptrade每天自动打新 (新股和可转债)附python代码
李魔佛 发表了文章 • 0 个评论 • 5728 次浏览 • 2022-07-28 11:10
def initialize(context):
g.flag = False
log.info("initialize g.flag=" + str(g.flag) )
def before_trading_start(context, data):
g.flag = False
log.info("before_trading_start g.flag=" + str(g.flag) )
def handle_data(context, data):
if not g.flag and time.strftime("%H:%M:%S", time.localtime()) > '09:35:00':
# 自动打新
log.info("自动打新")
ipo_stocks_order()
g.flag = True
def on_order_response(context, order_list):
# 该函数会在委托回报返回时响应
log.info(order_list)
交易页面
程序运行返回代码:
点击查看大图
【如果没有打新额度或者没有开通对应的权限,会显示可收购为0】
底下的成功的是可转债申购成功。
然后可以到券商app上看看是否已经有自动申购成功的记录。 查看全部
import time
def initialize(context):
g.flag = False
log.info("initialize g.flag=" + str(g.flag) )
def before_trading_start(context, data):
g.flag = False
log.info("before_trading_start g.flag=" + str(g.flag) )
def handle_data(context, data):
if not g.flag and time.strftime("%H:%M:%S", time.localtime()) > '09:35:00':
# 自动打新
log.info("自动打新")
ipo_stocks_order()
g.flag = True
def on_order_response(context, order_list):
# 该函数会在委托回报返回时响应
log.info(order_list)
交易页面

程序运行返回代码:

【如果没有打新额度或者没有开通对应的权限,会显示可收购为0】
底下的成功的是可转债申购成功。
然后可以到券商app上看看是否已经有自动申购成功的记录。
QMT模拟盘和实盘切换
李魔佛 发表了文章 • 0 个评论 • 3999 次浏览 • 2022-07-20 19:30
也不会发送至柜台,即python产生的委托会在客户端节点被截断。python发出的所有交易信号(下单、
撤单等)由此规则约束。
点击图片放大
使用QMT的客户端登录,在模型交易页面:
这个切换也比较简单,只要点击一下实盘,就可以马上切换。
欢迎关注公众号 查看全部
也不会发送至柜台,即python产生的委托会在客户端节点被截断。python发出的所有交易信号(下单、
撤单等)由此规则约束。

点击图片放大
使用QMT的客户端登录,在模型交易页面:
这个切换也比较简单,只要点击一下实盘,就可以马上切换。
欢迎关注公众号
qmt获取可转债历史tick行情数据
李魔佛 发表了文章 • 0 个评论 • 5133 次浏览 • 2022-07-20 19:18
当然拿到数据后,它的tick数据是参差不齐的,虽然是L1的数据,当时有些时间间隔大于3s,而有些却可以小于3s。
所以可以对这些数据进行时间的重采样处理。 比如全部变为1s,或者变为3s,变为1分钟就没必要了。 因为获取行情本身就自带1m的数据参数。
result = df.resample('3S',).first().ffill()
dataframe重采样采用3秒的代码入行,而且要向前补全,因为某些时刻没有交易的话,它的价格还是上一档的价格。
最后处理的数据如上图所示。
查看全部

需要在mini qmt中获取历史tick,如果在qmt里面,只能获取到订阅行情的数据。
当然拿到数据后,它的tick数据是参差不齐的,虽然是L1的数据,当时有些时间间隔大于3s,而有些却可以小于3s。
所以可以对这些数据进行时间的重采样处理。 比如全部变为1s,或者变为3s,变为1分钟就没必要了。 因为获取行情本身就自带1m的数据参数。
result = df.resample('3S',).first().ffill()dataframe重采样采用3秒的代码入行,而且要向前补全,因为某些时刻没有交易的话,它的价格还是上一档的价格。

最后处理的数据如上图所示。