
用户问的比较多的关于ptrade基础问题
一些星友(星球好友)问的比较多的问题:
1. 国金的Ptrade 实盘交易客户端是无法进行回测的,在任何时间段;
而模拟客户端可以,可以找自己的经理申请一个Ptrade模拟客户端账户;
2. 国盛的Ptrade实盘交易客户端仅在交易时间无法回测,但非交易时间可以回测;
主要是因为实盘回测和交易在同一个服务器,回测占用过多资源会影响实盘交易;模拟客户端没有这个问题;
任何时间段均可以回测; (之前某个券商的ptrade实盘服务器,因为某个用户开了40多个回测策略,一直在后台运行,而且是关于运算密集型的,导致实盘交易的程序也崩溃了)
3. 国金Ptrade无法回测星球上面的可转债实盘代码,实盘代码是基于当前的实时数据,用来进行回测没有意义,因为获取不到可转债的历史数据(溢价率,规模等),只有历史的价格数据;
4. 国金Ptrade无法使用星球上的可转债代码进行实盘,因为无法访问外网,无法访问我部署的接口数据; 而国盛的Ptrade可以;如果国金Ptrade需要实盘交易可转债,需要手工上传一些基础数据,Ptrade提供上传功能,具体操作可查找星球相关文章;
5. 在共享的Ptrade模拟试用账户上,不要保留个人代码记录,跑完后记得删除,否则其他共有同一个账户的人可以进去修改复制你的策略和代码;如果是单独的个人模拟账户,则没有这个问题。
 收起阅读 »
收起阅读 »
1. 国金的Ptrade 实盘交易客户端是无法进行回测的,在任何时间段;
而模拟客户端可以,可以找自己的经理申请一个Ptrade模拟客户端账户;
2. 国盛的Ptrade实盘交易客户端仅在交易时间无法回测,但非交易时间可以回测;
主要是因为实盘回测和交易在同一个服务器,回测占用过多资源会影响实盘交易;模拟客户端没有这个问题;
任何时间段均可以回测; (之前某个券商的ptrade实盘服务器,因为某个用户开了40多个回测策略,一直在后台运行,而且是关于运算密集型的,导致实盘交易的程序也崩溃了)
3. 国金Ptrade无法回测星球上面的可转债实盘代码,实盘代码是基于当前的实时数据,用来进行回测没有意义,因为获取不到可转债的历史数据(溢价率,规模等),只有历史的价格数据;
4. 国金Ptrade无法使用星球上的可转债代码进行实盘,因为无法访问外网,无法访问我部署的接口数据; 而国盛的Ptrade可以;如果国金Ptrade需要实盘交易可转债,需要手工上传一些基础数据,Ptrade提供上传功能,具体操作可查找星球相关文章;
5. 在共享的Ptrade模拟试用账户上,不要保留个人代码记录,跑完后记得删除,否则其他共有同一个账户的人可以进去修改复制你的策略和代码;如果是单独的个人模拟账户,则没有这个问题。
收起阅读 »
如何下载Ptrade上的数据?
很多菜鸟会觉得不能下载或者上传数据到Ptrade的。
部分券商的Ptrade可以连通外网,只需要部署一个mysql服务器,或者rabbitMQ,就可以快捷的接受数据了。为啥是这两个,而不是mongodb?
因为ptrade内置的pip装好的库就有pymysql和pyzmq,可以配置下就可以直接开箱使用。如果需要开通有外网功能的Ptrade券商,可以关注公众号:可转债量化分析,后台留言:ptrade外网,即可咨询开通。
1. 首先,我们把数据保存到ptrade的服务端,保存方法多样,比如csv,excel,sql文件等,比如df.to_csv, df.to_excel等等。这里要注意一下,保存的路径。需要指定,/home/fly/notebook
2. 文件保存了之后,接着就可以下载了。
数据在研究的页面那里。

然后点击某个文件,
如果是非纯文本文件,比如excel文件,会显示:
不用理会,直接点击左上角的文件,下载,选择本地的路径,然后文件就可以下载下来了。
 收起阅读 »
收起阅读 »
部分券商的Ptrade可以连通外网,只需要部署一个mysql服务器,或者rabbitMQ,就可以快捷的接受数据了。为啥是这两个,而不是mongodb?
因为ptrade内置的pip装好的库就有pymysql和pyzmq,可以配置下就可以直接开箱使用。如果需要开通有外网功能的Ptrade券商,可以关注公众号:可转债量化分析,后台留言:ptrade外网,即可咨询开通。
1. 首先,我们把数据保存到ptrade的服务端,保存方法多样,比如csv,excel,sql文件等,比如df.to_csv, df.to_excel等等。这里要注意一下,保存的路径。需要指定,/home/fly/notebook
import pickle
from collections import defaultdict
NOTEBOOK_PATH = '/home/fly/notebook/'
'''
持仓N日后卖出,仓龄变量每日pickle进行保存,重启策略后可以保证逻辑连贯
'''
def initialize(context):
#尝试启动pickle文件
try:
with open(NOTEBOOK_PATH+'hold_days.pkl','rb') as f:
g.hold_days = pickle.load(f)
2. 文件保存了之后,接着就可以下载了。
数据在研究的页面那里。
然后点击某个文件,
如果是非纯文本文件,比如excel文件,会显示:
Error! not UTF-8 encoded
Saving disable
See console for more details
不用理会,直接点击左上角的文件,下载,选择本地的路径,然后文件就可以下载下来了。
迅投QMT修改编辑器字体大小,4个空格缩进(默认是TAB),背景颜色
QMT的默认编辑器是非常难用的。字体,大小,颜色,编码,缩进,一言难尽。
而且在菜单里面也找不到设置的地方。
其实用户是可以修改这个编辑器的配置的。
找到QMT的安装目录,找到config文件夹,里面有个editor.xml 的文件,用记事本或者notepad++等文本编辑器打开。

如果要修改字体大小,可以修改:
<font FamilyName="Courier New" IsBold="false" size="16"/>
把size设置大一点,字体即可变大。
如果要把tab缩进改为空格缩进(主流IDE,pycharm vscode都是4个空格缩进的),可以改成下面的
<font FamilyName="Courier New" IsBold="false" size="20"/>
<align TabStop="4" AutoIndent="true" IndentationsUseTabs="false" WrapWord="false"/>

如果需要修改背景色:
同理:
<color bgcolor="255,255,255"/>
修改这一行,
比如变成黑色背景
<color bgcolor="0,0,0"/>
PS: 上述配置部分券商可以在QMT的IDE上设置,比如字体大小等,而在这个xml里面修改却生效不了
改为后记得重启QMT生效
公众号后台回复:
qmt配置文件
可以获取修改为tab缩进的配置文件
 收起阅读 »
收起阅读 »
而且在菜单里面也找不到设置的地方。
其实用户是可以修改这个编辑器的配置的。
找到QMT的安装目录,找到config文件夹,里面有个editor.xml 的文件,用记事本或者notepad++等文本编辑器打开。
如果要修改字体大小,可以修改:
<font FamilyName="Courier New" IsBold="false" size="16"/>
把size设置大一点,字体即可变大。
如果要把tab缩进改为空格缩进(主流IDE,pycharm vscode都是4个空格缩进的),可以改成下面的
<font FamilyName="Courier New" IsBold="false" size="20"/>
<align TabStop="4" AutoIndent="true" IndentationsUseTabs="false" WrapWord="false"/>
如果需要修改背景色:
同理:
<color bgcolor="255,255,255"/>
修改这一行,
比如变成黑色背景
<color bgcolor="0,0,0"/>
PS: 上述配置部分券商可以在QMT的IDE上设置,比如字体大小等,而在这个xml里面修改却生效不了
改为后记得重启QMT生效
公众号后台回复:
qmt配置文件
可以获取修改为tab缩进的配置文件
收起阅读 »
QMT vs Ptrade 速度对比 (二)实时行情速度对比
上一篇文章(QMT vs Ptrade 速度对比 (一) 历史行情获取速度)对了了QMT和Ptrade的获取历史行情速度,本篇文章继续对它俩的实时行情速度。
本文以获取市场所有可转债的实时行情为例子,比较二者的速度。
Ptrade获取所有可转债实时行情
目前市场上有480多只可转债,由于Ptrade内置的数据源不足以支撑可转债的大部分策略,所以需要调用外部数据源,因此使用国盛证券的Ptrade进行交易,因为目前只有它可以链接外网,你可以把可转债的数据写入到数据库或者写成自己的接口,传递给Ptrade就可以了。
比如下面的基础数据接口。
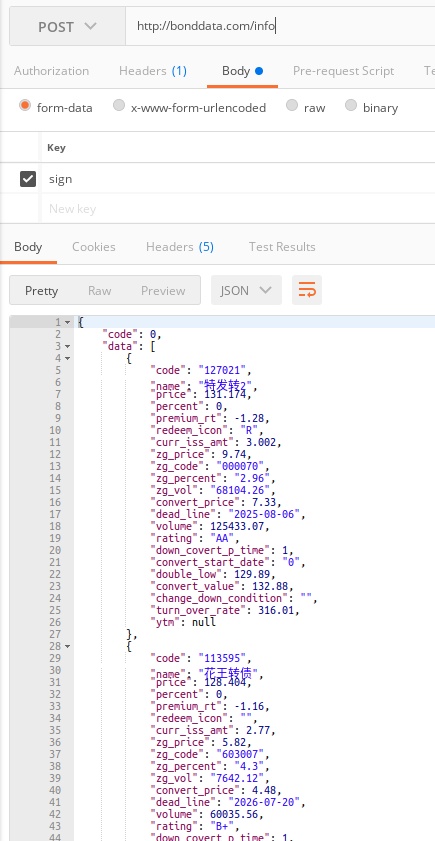
【目前星球用户可以提供数据接口免费调用功能,提供实时数据功能,强赎倒数多个API接口】
然后调用端使用python的requests库请求下就有了。下面代码可以在Ptrade里面部署运行,用于获取可转债溢价率,剩余规模等数据。
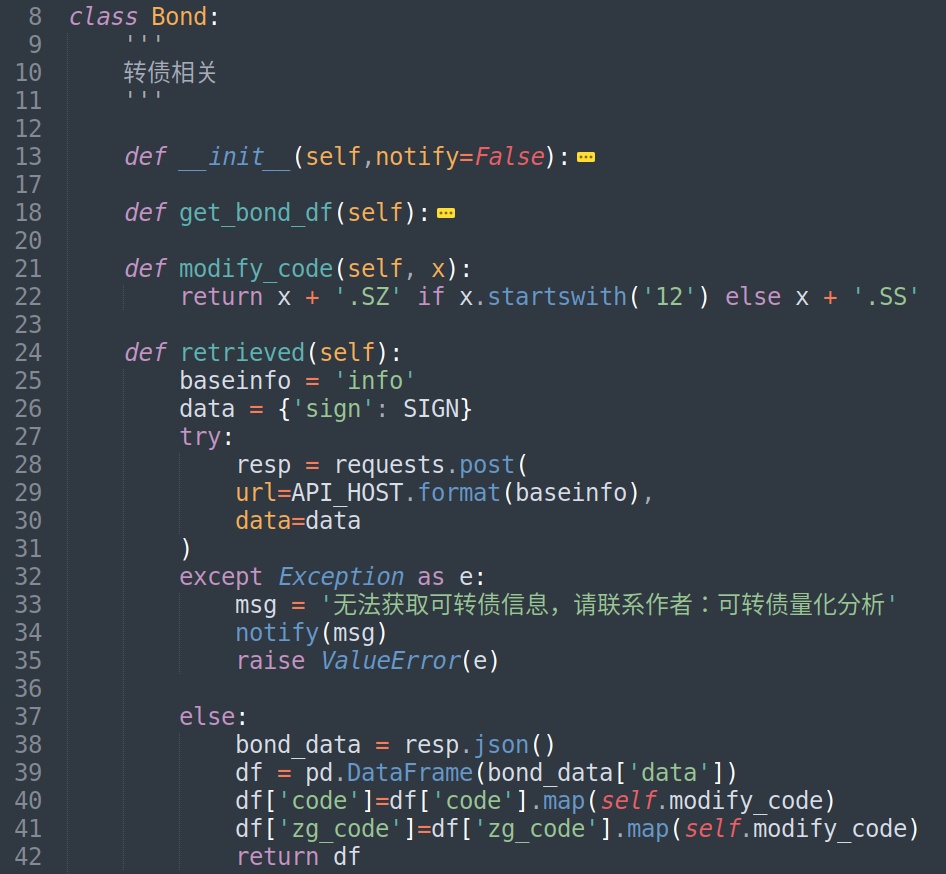
然后在Ptrade的定时执行函数里面获取实时tick数据,使用get_snapshot,把所有的转债代码传入get_snapshot就可以拿到可转债的行情数据了,行情数据3秒更新一次。
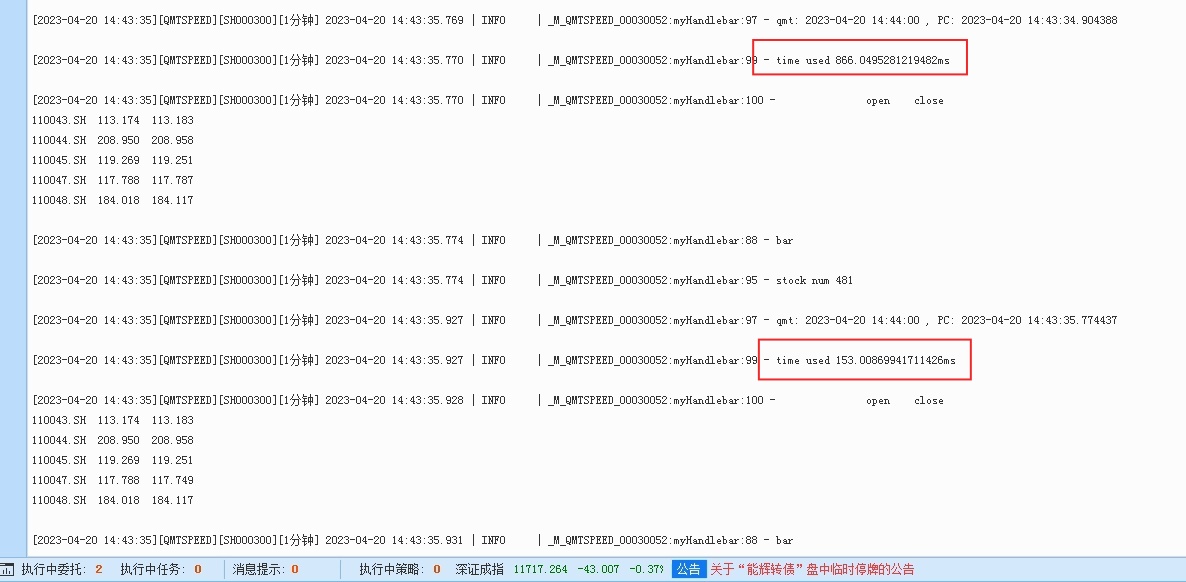
在Ptrade里面的运行情况
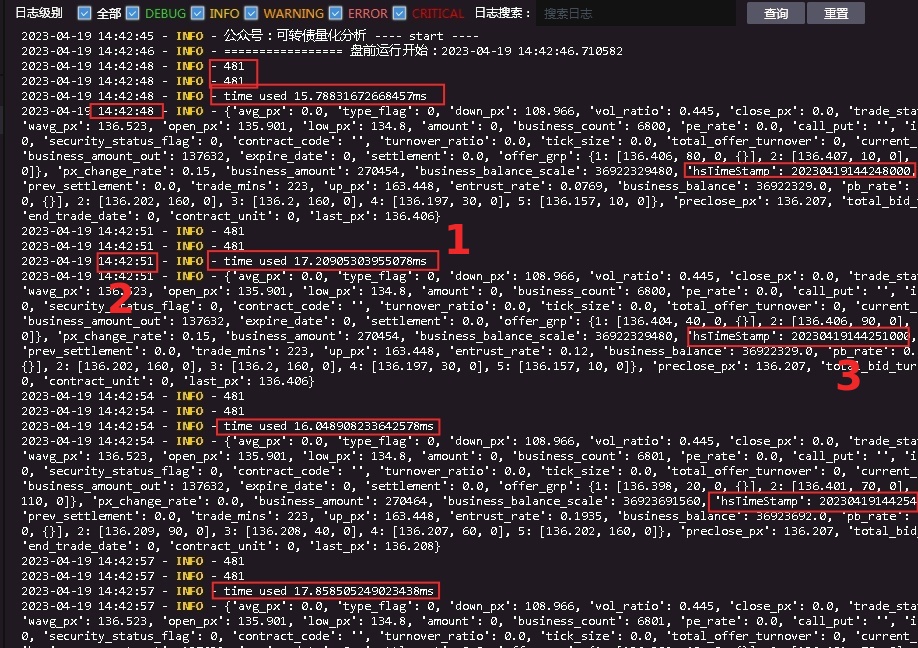
红框的地方是几个时间点要关注的。
481:获取的转债个数有481
红色数字1的位置: time used
获取行情数据所用的时间,大概在17毫秒(ms)左右,数据一直比较稳定。返回的数据里面字段除了价格,还有昨收价,委买卖1队列,涨停价,成交量等多个数据,参考上图里面的那个字典格式的数据。 具体可以参考接口文档(http://ptradeapi.com)
红色数字2的位置:日志输出时候的时间,也就是程序当前所在时刻,在目前程序在14:42:51,红色数字3的时间,是当前价格的里面的时间,也就tick对应的时间,当前的tick时间是hsTimeStamp: 20230419144251000, 也就是 2023-04-19 14:42:51:000, 所以当前时间程序获取的tick时间是一致的。为什么这里要强调这个呢? 假如当前程序时刻是14:42:51, 而获取的tick timestamp数据是14:42:48,那么说明当前程序拿到的最新tick数据却是在48秒时的数据,也就是数据延时了3秒。所以Ptrade里面的tick数据并没有出现延时滞后。
QMT 实时行情
同样QMT提供的可转债基础也是少的可怜,几乎为零。所以同样调用个人部署的可转债接口数据,如法炮制。PS:通过数据解耦的方式,不同数据可以在不同的量化软件里面使用,省去很多重复编写的代码,即使后面接入掘金,聚宽等平台,你只需要编写下单接口逻辑即可。
QMT取实时行情代码如下:

Bond是一个类,和ptrade里面的一样的,用来获取转债基础数据。
同样在QMT的实盘模式下执行:
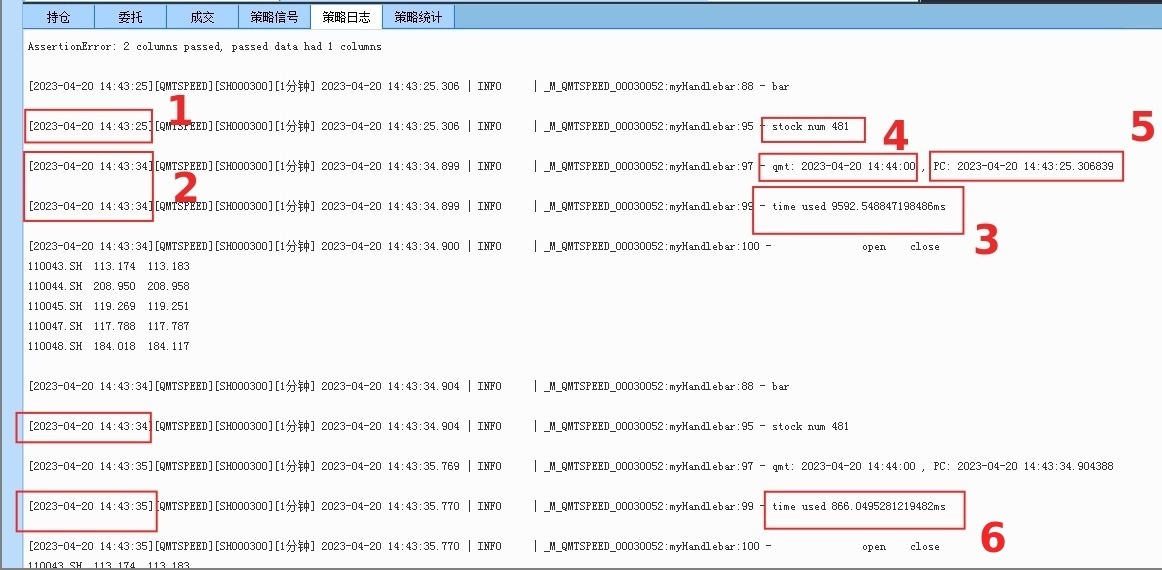
网络环境:500M宽带网络,PC:CPU I7 - 内存24GB
stock num : 481 同样获取的是481个转债实时行情数据
红色数字1时间:日志输出的当前时间,获取行情数据前的时间14:43:25
红色数字2时间:日志输出的当前时间,此时为已经获取行情数据后的时间:14:43:34
红色数字3:第一次获取行情数据时间差,达到了9.5秒! 这个数字简直惊呆了。 反复测试几次后,依然如此,使用get_market_data获取实时行情数据,第一次数据到达的时候都要挺久的。
新人刚使用这个函数获取实时行情的时候,往往会以为自己代码出bug,等待很久没数据出来,尤其是获取超过1000个股票代码的行情的时候,等待时候更久,等待时间随着输入的个数增加而增加; 同时QMT占用内存也会稳步增加,如果机子的内存太小,可能还会卡死了。(qmt里面的坑还挺多的)


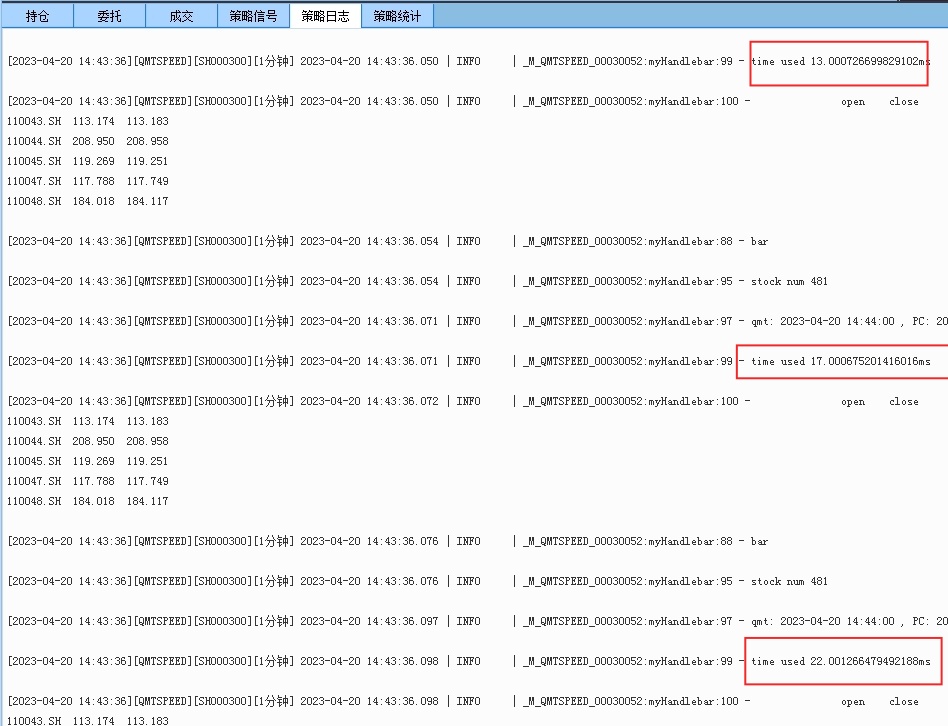
红色数字6,第二次获取实时行情所用的时间,这一次就快很多了,只用了800毫秒。
随着后续运行,获取实时行情的时间就趋于稳定,从800毫秒慢慢降到150毫秒,最后到13-20毫秒,基本和ptrade差不多级别了。
实时行情延时方面,对比通达信

取110048.SH 这个转债的行情数据作为参考,因为QMT返回字段里面没有带tick的时间戳,所以拿通达信作的分时数据作为的对比,没有用L2,所以框住的位置时间约在14:47:03 ~ 14:47:06
图片上半部分通达信的分时数据,左下角的数据时间是14:47:06,所以数据并没有出现很大的延时。
总结
QMT稳定运行的时候,实时行情基本和Ptrade同一级别水平。但QMT的行情波动性大一些。而在初始启动获取数据时,QMT会非常耗费资源,且等待时间较长,而Ptrade则不存在这种问题。
QMT可以随意获取外部数据,所以对券商没有很高要求;而Ptrade目前只有一家券商(国盛证券)可以自由访问外部数据,如果缺少需要的数据或者指标,将无法实现相应的策略。
参考API接口文档:
Ptrade: http://ptradeapi.com/
QMT: http://qmt.ptradeapi.com/
公众号:
收起阅读 »
【100行python代码实现可转债日内网格-成交驱动】 自定义买卖步长
基于ptrade的可转债日内网格实盘,基于成交驱动,成交后马上挂入下一轮的网格委托。
## 2023-04-19 更新: 部分成交的需要等待全部成交才触发下一轮挂单
简单的可转债日内网格策略,自定义买卖步长,基准价格,买入与卖出数量,保留底仓张数
开始同时挂买入和卖出委托,如果买入成交后,撤掉委卖(如果是卖出先成交,则撤掉委买),继续挂入下一个步长的委买与委卖,不断循环。
把注释和空格去了100行不到。
代码仅供参考学习具体用法:
用于实盘亏损盈亏自负
后续如果有需要再贴个升级版:多标的网格
或者,额,qmt版本。。。
部分代码截图:

实盘交易日志:点击查看大图


完整代码请参见知识星球.
知识无价,请尊重知识。
收起阅读 »
## 2023-04-19 更新: 部分成交的需要等待全部成交才触发下一轮挂单
简单的可转债日内网格策略,自定义买卖步长,基准价格,买入与卖出数量,保留底仓张数
开始同时挂买入和卖出委托,如果买入成交后,撤掉委卖(如果是卖出先成交,则撤掉委买),继续挂入下一个步长的委买与委卖,不断循环。
把注释和空格去了100行不到。
代码仅供参考学习具体用法:
用于实盘亏损盈亏自负
后续如果有需要再贴个升级版:多标的网格
或者,额,qmt版本。。。
部分代码截图:
实盘交易日志:点击查看大图
完整代码请参见知识星球.
知识无价,请尊重知识。
收起阅读 »
本地CPU部署的stable diffusion webui 环境,本地不受限,还可以生成色图黄图
正常输出,生成图的纹理贴图光线很逼真。

.jpeg")
需要不断调节词汇(英语),打造你想要的人物设定

由于本地使用的词汇不限制,还能够生成细节丰富的黄图。(宅男福音)
提供一个语法给你们用用:

整体来说,现在的AI技术和效果就像跃迁了一个台阶。
 收起阅读 »
收起阅读 »
需要不断调节词汇(英语),打造你想要的人物设定
由于本地使用的词汇不限制,还能够生成细节丰富的黄图。(宅男福音)
提供一个语法给你们用用:
prompt: beautiful, masterpiece, best quality, extremely detailed face, perfect lighting, (1girl, solo, 1boy, 1girl, NemoNelly, Slight penetration, lying, on back, spread legs:1.5), street, crowd, ((skinny)), ((puffy eyes)), brown hair, medium hair, cowboy shot, medium breasts, swept bangs, walking, outdoors, sunshine, light_rays, fantasy, rococo, hair_flower,low tied hair, smile, half-closed eyes, dating, (nude), nsfw, (heavy breathing:1.5), tears, crying, blush, wet, sweat, <lora:koreanDollLikeness_v15:0.4>, <lora:povImminentPenetration_ipv1:0>, <lora:breastinclassBetter_v14:0.1>
整体来说,现在的AI技术和效果就像跃迁了一个台阶。
收起阅读 »
Stable Diffusion WebUI 模型下载速度很慢,但挂上梯子后速度狂飙
安装命令:
不过安装实在太慢了。而且安装好了之后,如果下载模型,还要单独下载,也是奇慢。
试了下把梯子代理挂上,模型下载就飞快了


除了模型,还有一些checkpoint文件
Stable diffusion v1.4
stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt
Stable diffusion v1.5
stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt
lora模型
koreanDollLikeness_v15.safetensors
等等。
收起阅读 »
$ git clone https ://github.com/AUTOMATIC1111/stable-diffusion-webui.git
$ cd stable-diffusion-webui
$ git checkout 22bcc7be428c94e9408f589966c2040187245d81
# 我们需要 CPU 版本的 torch
$ export TORCH_COMMAND="pip install torch==1.13.1 torchvision==0.14.1 --index-url https: //download.pytorch.org/whl/cpu"
$ export USE_NNPACK=0
# 前 4 个参数是为了让其运行在 CPU 上, 最后一个参数是让 WebUI 可以远程访问
$ bash webui.sh --skip-torch-cuda-test --no-half --precision full --use-cpu all --listen
不过安装实在太慢了。而且安装好了之后,如果下载模型,还要单独下载,也是奇慢。
试了下把梯子代理挂上,模型下载就飞快了
除了模型,还有一些checkpoint文件
Stable diffusion v1.4
stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt
Stable diffusion v1.5
stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt
lora模型
koreanDollLikeness_v15.safetensors
等等。
收起阅读 »
没有显卡GPU,想用CPU玩Stable Diffusion 本地部署AI绘图吗? 手把手保姆教程






在网上看到那些美cry的AI生成的美女图片 ,你是不是也蠢蠢欲动想要按照自己的想法生成一副属于自己的女神照呢?
什么?你的电脑显卡没有显卡? 没关系,今天笔者带大家手把手在本地电脑上使用CPU部署Stable Diffusion+Lora AI绘画 模型。
什么是Stable Diffusion ?
Stable Diffusion 是一种通过文字描述创造出图像的 AI 模型. 它是一个开源软件, 有许多人愿意在网络上免费分享他们的计算资源, 使得新手可以在线尝试.
安装
本地部署的 Stable Diffusion 有更高的可玩性, 例如允许您替换模型文件, 细致的调整参数, 以及突破线上服务的道德伦理检查等. 鉴于我目前没有可供霍霍的 GPU, 因此我将在一台本地ubuntu上部署,因为Stable Diffusion 在运行过程中大概需要吃掉 12G 内存。如果你的电脑或者服务器没有16GB以上的内存,需要配置一个虚拟内存来扩展你的内存容量,当然,性能也打个折扣,毕竟是在硬盘上扩展的内存空间。
如果你的电脑内存大小大于16GB,可以忽略以下的操作:
$ dd if=/dev/zero of=/mnt/swap bs=64M count=256笔者的电脑配置:
$ chmod 0600 /mnt/swap
$ mkswap /mnt/swap
$ swapon /mnt/swap

然后直接安装下载并安装 Stable Diffusion WebUI:
稍等片刻(依赖你的网速)

由于需要连接到github下载源码,所以如果网络不稳定掉线,需要重新运行安装命令就可以了。

重新运行:
bash webui.sh --skip-torch-cuda-test --no-half --precision full --use-cpu all --listen
这个脚本会自动创建python的虚拟环境,并安装对应的pip依赖,一键到位,可谓贴心。果断要到github上给原作者加星

等待一段时间, 在浏览器中打开 127.0.0.1:7860 即可见到 UI 界面.
下载更多模型
模型, 有时称为检查点文件(checkpoint), 是预先训练的 Stable Diffusion 权重, 用于生成一般或特定的图像类型. 模型可以生成的图像取决于用于训练它们的数据. 如果训练数据中没有猫, 模型将无法产生猫的形象. 同样, 如果您仅使用猫图像训练模型, 则只会产生猫.
Stable Diffusion WebUI 运行时会自动下载 Stable Diffusion v1.5 模型. 下面提供了一些快速下载其它模型的命令.
$ cd models/Stable-diffusion
# Stable diffusion v1.4
# 下面的URL超链接过长有省略号,需要右键复制url
$ wget https://huggingface.co/CompVis ... .ckpt
# Stable diffusion v1.5
$ wget https://huggingface.co/runwaym ... .ckpt
# F222
$ wget https://huggingface.co/acheong ... .ckpt
# Anything V3
$ wget
https://huggingface.co/Linaqru ... nsors
# Open Journey
$ wget https://huggingface.co/prompth ... .ckpt
# DreamShaper
$ wget https://civitai.com/api/download/models/5636 -O dreamshaper_331BakedVae.safetensors
# ChilloutMix
$ wget https://civitai.com/api/download/models/11745 -O chilloutmix_NiPrunedFp32Fix.safetensors
# Robo Diffusion
$ wget
https://huggingface.co/nousr/r ... .ckpt
# Mo-di-diffusion
$ wget
https://huggingface.co/nitroso ... .ckpt
# Inkpunk Diffusion
$ wget修改配置文件
https://huggingface.co/Envvi/I ... .ckpt
ui-config.json 内包含众多的设置项, 可按照个人的习惯修改部分默认值. 例如我的配置部分如下:
{
"txt2img/Batch size/value": 4,
"txt2img/Width/value": 480,
"txt2img/Height/value": 270
}提示语示例model: chilloutmix_NiPrunedFp32Fix.safetensors
prompt: beautiful, masterpiece, best quality, extremely detailed face, perfect lighting, (1girl, solo, 1boy, 1girl, NemoNelly, Slight penetration, lying, on back, spread legs:1.5), street, crowd, ((skinny)), ((puffy eyes)), brown hair, medium hair, cowboy shot, medium breasts, swept bangs, walking, outdoors, sunshine, light_rays, fantasy, rococo, hair_flower,low tied hair, smile, half-closed eyes, dating, (nude), nsfw, (heavy breathing:1.5), tears, crying, blush, wet, sweat, <lora:koreanDollLikeness_v15:0.4>, <lora:povImminentPenetration_ipv1:0>, <lora:breastinclassBetter_v14:0.1>
prompt: paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.331), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), bad hands, missing fingers, extra digit, bad body, pubic
上述提示词结尾引用了 3 个 Lora 模型, 需提前下载至 models/Lora 目录.
$ cd models/Lora
$ wget
https://huggingface.co/amornln ... nsors
$ wget
https://huggingface.co/samle/s ... nsors
$ wget https://huggingface.co/jomcs/N ... nsors生成的效果图:

收起阅读 »
QMT vs Ptrade 速度对比 (一) 历史行情获取速度
众所周知(狗头),QMT是在你本地电脑运行的,包括行情获取,计算指标,选股选债,下单都在你的本地电脑执行。行情数据通过网络去券商服务器或者迅投(QMT)服务器获取,拿到数据在你的本地电脑处理,比如计算涨速,量比,然后再使用下单接口把下单指令通过网络提交到券商柜台,券商柜台接到QMT的委托指令后,再提交给交易所。
Ptrade(恒生电子)则是在券商部署的服务器上执行,你下载的Ptrade在你的本地电脑,只是负责写代码,把代码部署到券商服务器,然后在券商服务其执行你的策略,当然你的代码在券商服务器运行时是被加密的。行情获取,计算指标,下单委托都在券商机房内部执行,属于云策略的类型,策略部署好了,就不需要开着本地电脑观察它的状态。
对比环境均为同一个券商下的QMT和Ptrade,均为生产环境的实盘版本。(PS:温馨提示,平时少用模拟版本,bug多,交易不准,还浪费时间。我平时调试都直接在实盘上调试的,要对自己的策略有信心哈,至少回测过了的嘛O(∩_∩)O~~)
历史行情数据获取
目标:获取2022年到昨天的沪深300所有股票的日线收盘价数据。
QMT
获取行情数据 使用这个函数:ContextInfo.get_market_data()
在fields里面指定只获取close价格即可。
QMT测试代码如下:(需要的也可以后台留言回复获取)
[vscode里面的代码,需要复制到qmt里面执行]
把代码复制到QMT里面,然后切换到模型交易,在中间切换到实盘模式,就会运行上面代码。
注意,这里需要第一次运行上面的代码来计算时间,因为QMT会有个cache缓存机制,它会把曾经跑过的历史数据自动下载下来,保存到你的电脑硬盘里,从而加快QMT后续的读取速度,同样的数据没有必要每次再去网络上拉。
大部分情况下网络IO都会是任何一个量化交易系通最大的性能瓶颈。
运行得到下面的结果:

上面运行时间是22秒。不要惊讶哦,首次获取历史行情数据都是挺慢的。如果你的电脑网速够快,或者但在阿里云,腾讯云之类的云服务上跑,获取历史行情速度会有所提高。
在你运行了上面的代码之后,QMT会在某个时刻,在后台把数据下载到本地QMT安装目录下。

文件按照股票代码作为文件名存储。当然里面不是txt格式,而是QMT做了相应的封装的。上面按照修改日期排序,4月11日多了很多新的DAT数据文件,显然是刚刚生成的。
QMT在获取历史行情数据后,会有个触发器,在后台一次性保存大量的文件,所以QMT会在某一个瞬间,界面会出现卡顿,甚至无响应,而看任务管理器会看到内存飙升甚至爆满100%,有些新人菜鸟就认为QMT太占内存,太垃圾的结论,这也是片面的。实际上在数据完备的情况下,QMT需要的内存4GB就够的了。如果你经常会有扫描全市场股票代码历史数据的话,内存还是尽量选大一点的。如果无法避免内存突然飙升,可以每次把获取行情的股票代码列表减少,细分多几批获取,用时间换空间。
当然 QMT也提供了一个下载历史数据的一个菜单入口,用于在图形界面下手动下载历史行情,从而加速历史行情读取速度。

等数据下载完成后,
第二次跑上面的同一个代码,运行时间明显快了。

但用时还是要7.9秒,反复测试几次,获取时间依然是在6-8秒之间波动。 因为程序读取历史行情数据的一个个独立的文件,所以这里硬盘的性能因素对获取行情影响还是很大的。
笔者感觉7.9秒这个速度还是很慢的,换了台性能好一点的的windows机子,下载了历史数据后再跑了一次:

但用时依然在6秒左右。
所以个人是不推荐大家在tick策略里面,在盘中去获取历史数据的,这个动作应该在盘前就应该完成,把数据保存到内存列表或者dataframe变量中,盘中用的时候去取就可以了。 当然低频策略就无所谓啦。
Ptrade
操作上ptrade相对而言更加简洁,容易上手。
它的API设计和它对应的API文档更加规范,可读性更好。
直接把代码复制到量化->策略,新建策略,然后在交易里面添加策略,直接启动策略。代码设置定时运行,在启动策略后的一分钟后运行。

同样获取沪深300的日线数据,2022年1月到2023年4月10日。
get_price - 获取历史数据 get_price(security, start_date=None, end_date=None, frequency='1d', fields=None, fq=None, count=None)
运行

上面的结果显示,Ptrade获取同样的历史数据耗时只有700毫秒,0.7秒左右。测试多几次,获取时间基本每次都比较平稳,在0.6-0.8秒之间。(下面打印的306不是沪深300的个数,而是获取到的日期的天数,它返回的结构虽然都是panel,但和QMT的轴有点不同)。
结论
总的来说,获取历史行情数据的速度,Ptrade是秒杀了QMT的,不在一个量级上的。
本来想继续对比实时行情,下单延时对比等等,但开盘时间有限,写了一下时间就不够用了。所以把教程拆分为多个系列,下一篇再对比QMT和PTrade的实时行情数据,下单回调等等啦。
如果想要自己测试文中的数据,可以获取代码,公众号 后台回复: 历史行情数据代码
参考API接口文档:
Ptrade: http://ptradeapi.com/
QMT: http://qmt.ptradeapi.com/
公众号:
收起阅读 »
Ptrade(恒生电子)则是在券商部署的服务器上执行,你下载的Ptrade在你的本地电脑,只是负责写代码,把代码部署到券商服务器,然后在券商服务其执行你的策略,当然你的代码在券商服务器运行时是被加密的。行情获取,计算指标,下单委托都在券商机房内部执行,属于云策略的类型,策略部署好了,就不需要开着本地电脑观察它的状态。
对比环境均为同一个券商下的QMT和Ptrade,均为生产环境的实盘版本。(PS:温馨提示,平时少用模拟版本,bug多,交易不准,还浪费时间。我平时调试都直接在实盘上调试的,要对自己的策略有信心哈,至少回测过了的嘛O(∩_∩)O~~)
历史行情数据获取
目标:获取2022年到昨天的沪深300所有股票的日线收盘价数据。
QMT
获取行情数据 使用这个函数:ContextInfo.get_market_data()
用法: ContextInfo.get_market_data(fields, stock_code = , start_time = '',
end_time = '', skip_paused = True, period = 'follow',
dividend_type = 'follow', count = -1)
open -- 开盘价(str:numpy.float64);
high -- 最高价(str:numpy.float64);
low --最低价(str:numpy.float64);
close -- 收盘价(str:numpy.float64);
volume -- 交易量(str:numpy.float64);
money -- 交易金额(str:numpy.float64);
price -- 最新价(str:numpy.float64);
preclose -- 昨收盘价(str:numpy.float64)(仅日线返回);
high_limit -- 涨停价(str:numpy.float64)(仅日线返回);
low_limit -- 跌停价(str:numpy.float64)(仅日线返回);
unlimited -- 判断查询日是否无涨跌停限制(1:该日无涨跌停限制;0:该日有涨跌停限制)(str:numpy.float64)(仅日线返回);
在fields里面指定只获取close价格即可。
QMT测试代码如下:(需要的也可以后台留言回复获取)
[vscode里面的代码,需要复制到qmt里面执行]
把代码复制到QMT里面,然后切换到模型交易,在中间切换到实盘模式,就会运行上面代码。
注意,这里需要第一次运行上面的代码来计算时间,因为QMT会有个cache缓存机制,它会把曾经跑过的历史数据自动下载下来,保存到你的电脑硬盘里,从而加快QMT后续的读取速度,同样的数据没有必要每次再去网络上拉。
大部分情况下网络IO都会是任何一个量化交易系通最大的性能瓶颈。
运行得到下面的结果:
上面运行时间是22秒。不要惊讶哦,首次获取历史行情数据都是挺慢的。如果你的电脑网速够快,或者但在阿里云,腾讯云之类的云服务上跑,获取历史行情速度会有所提高。
在你运行了上面的代码之后,QMT会在某个时刻,在后台把数据下载到本地QMT安装目录下。
文件按照股票代码作为文件名存储。当然里面不是txt格式,而是QMT做了相应的封装的。上面按照修改日期排序,4月11日多了很多新的DAT数据文件,显然是刚刚生成的。
QMT在获取历史行情数据后,会有个触发器,在后台一次性保存大量的文件,所以QMT会在某一个瞬间,界面会出现卡顿,甚至无响应,而看任务管理器会看到内存飙升甚至爆满100%,有些新人菜鸟就认为QMT太占内存,太垃圾的结论,这也是片面的。实际上在数据完备的情况下,QMT需要的内存4GB就够的了。如果你经常会有扫描全市场股票代码历史数据的话,内存还是尽量选大一点的。如果无法避免内存突然飙升,可以每次把获取行情的股票代码列表减少,细分多几批获取,用时间换空间。
当然 QMT也提供了一个下载历史数据的一个菜单入口,用于在图形界面下手动下载历史行情,从而加速历史行情读取速度。
等数据下载完成后,
第二次跑上面的同一个代码,运行时间明显快了。
但用时还是要7.9秒,反复测试几次,获取时间依然是在6-8秒之间波动。 因为程序读取历史行情数据的一个个独立的文件,所以这里硬盘的性能因素对获取行情影响还是很大的。
笔者感觉7.9秒这个速度还是很慢的,换了台性能好一点的的windows机子,下载了历史数据后再跑了一次:
但用时依然在6秒左右。
所以个人是不推荐大家在tick策略里面,在盘中去获取历史数据的,这个动作应该在盘前就应该完成,把数据保存到内存列表或者dataframe变量中,盘中用的时候去取就可以了。 当然低频策略就无所谓啦。
Ptrade
操作上ptrade相对而言更加简洁,容易上手。
它的API设计和它对应的API文档更加规范,可读性更好。
直接把代码复制到量化->策略,新建策略,然后在交易里面添加策略,直接启动策略。代码设置定时运行,在启动策略后的一分钟后运行。
同样获取沪深300的日线数据,2022年1月到2023年4月10日。
get_price - 获取历史数据 get_price(security, start_date=None, end_date=None, frequency='1d', fields=None, fq=None, count=None)
运行
上面的结果显示,Ptrade获取同样的历史数据耗时只有700毫秒,0.7秒左右。测试多几次,获取时间基本每次都比较平稳,在0.6-0.8秒之间。(下面打印的306不是沪深300的个数,而是获取到的日期的天数,它返回的结构虽然都是panel,但和QMT的轴有点不同)。
结论
总的来说,获取历史行情数据的速度,Ptrade是秒杀了QMT的,不在一个量级上的。
本来想继续对比实时行情,下单延时对比等等,但开盘时间有限,写了一下时间就不够用了。所以把教程拆分为多个系列,下一篇再对比QMT和PTrade的实时行情数据,下单回调等等啦。
如果想要自己测试文中的数据,可以获取代码,公众号 后台回复: 历史行情数据代码
参考API接口文档:
Ptrade: http://ptradeapi.com/
QMT: http://qmt.ptradeapi.com/
公众号:
收起阅读 »

ptrade担保品买卖,融资买入,融券卖出,卖券还款,买券还券 下单后回调函数里面的结构
【ptrade的稳定性,获取行情速度,实盘交易,回测速度无意不秒杀QMT的。
而对于不能安装第三方库的原因,不少菜鸟转而选择了QMT。有点可惜了ptrade。ptrade其实也可以联通外部数据。
ptrade软件设计层面和体验是企业级的,而QMT就呵呵哒,0售后技术支持,软件bug层出不穷。里面的某个别的工程师(袁姓)素质也是底下,我星球上的代码他也抄过去,抄过去后呢 放到他自己付费星球,而且还不止一篇。】
而ptrade相对而言,恒生电子的工程师服务就很到位,发送日志给他们,会在一天内分析结果告知你哪些出现问题了。
题外话说多了。
ptrade支持两融账户的量化操作。
如:担保品买卖,融资买入,融券卖出,卖券还款,买券还券
margin_trade - 担保品买卖它们之间的参数都比较相近:
margincash_open - 融资买入
margincash_close - 卖券还款
margincash_direct_refund - 直接还款
marginsec_open - 融券卖出
marginsec_close - 买券还券
margin_xxxx(security, amount, limit_price=None)
security:股票代码(str);
amount:交易数量,输入正数(int);
limit_price:买卖限价(float);
而用它们进行买卖操作后,在on_trade_response回调函数里面的机构提如下:
担保品买入:
2023-03-31 14:41:02 - INFO - 生成订单,订单号:cd25d27f39854721aac99db13c9e9b73股票代码:601328.SS 数量:信用买入1000
2023-03-31 14:41:02 - INFO - {'error_info': '', 'stock_code': '601328.SS', 'order_id': 'cd25d27f39854721aac99db13c9e9b73', 'status': '2', 'price': 5.1, 'entrust_type': '9', 'amount': 1000, 'business_amount': 0.0, 'entrust_prop': '0', 'entrust_no': '1', 'order_time': '2023-03-31 14:35:53.776'}
2023-03-31 14:41:02 - INFO - {'business_amount': 1000, 'order_id': 'cd25d27f39854721aac99db13c9e9b73', 'stock_code': '601328.SS', 'entrust_bs': '1', 'entrust_no': '1', 'status': '8', 'business_balance': 5100.0, 'business_price': 5.1, 'business_id': '2', 'business_time': '2023-03-31 14:39:17'}
融资买入:
2023-03-31 14:52:00 - INFO - 生成订单,订单号:01b7851d37014709bde3ec6ebe9e89c3股票代码:601328.SS 数量:融资买入100
2023-03-31 14:52:00 - INFO - {'price': 5.1, 'entrust_prop': '0', 'status': '2', 'entrust_type': '6', 'stock_code': '601328.SS', 'business_amount': 0.0, 'entrust_no': '3', 'order_time': '2023-03-31 14:46:51.620', 'error_info': '', 'amount': 100, 'order_id': '01b7851d37014709bde3ec6ebe9e89c3'}
2023-03-31 14:52:00 - INFO - {'business_id': '4', 'business_balance': 509.99999999999994, 'business_price': 5.1, 'order_id': '01b7851d37014709bde3ec6ebe9e89c3', 'business_time': '2023-03-31 14:50:14', 'status': '8', 'entrust_bs': '1', 'business_amount': 100, 'entrust_no': '3', 'stock_code': '601328.SS'}
卖券还款
2023-03-31 14:58:20 - INFO - start
2023-03-31 14:59:00 - INFO - 生成订单,订单号:20cef28ec52c4d41b09c80fc49167497股票代码:600269.SS 数量:卖券还款-200
2023-03-31 14:59:00 - INFO - {'business_amount': 0.0, 'amount': -200, 'stock_code': '600269.SS', 'error_info': '', 'order_time': '2023-03-31 14:53:51.375', 'price': 3.38, 'entrust_type': '6', 'status': '2', 'order_id': '20cef28ec52c4d41b09c80fc49167497', 'entrust_prop': '0', 'entrust_no': '5'}
2023-03-31 14:59:00 - INFO - {'status': '8', 'business_time': '2023-03-31 14:57:14', 'stock_code': '600269.SS', 'entrust_bs': '2', 'business_id': '6', 'business_balance': -676.0, 'business_amount': -200, 'order_id': '20cef28ec52c4d41b09c80fc49167497', 'business_price': 3.38, 'entrust_no': '5'}
返回的结构体和那个普通账户交易的回调函数基本一致的。
收起阅读 »
Ptrade融资融券双均线 代码 讲解
因为一些融资融券的函数只能在交易模块使用,所以如果需要模拟的话,可以使用模拟端进行交易。
收起阅读 »
def initialize(context):
# 初始化策略
# 设置我们要操作的股票池, 这里我们只操作一支股票
g.security = "600300.SS"
set_universe(g.security)
def before_trading_start(context, data):
# 买入标识
g.order_buy_flag = False
# 卖出标识
g.order_sell_flag = False
#当五日均线高于十日均线时买入,当五日均线低于十日均线时卖出
def handle_data(context, data):
# 得到十日历史价格
df = get_history(10, "1d", "close", g.security, fq=None, include=False)
# 得到五日均线价格
ma5 = round(df["close"][-5:].mean(), 3)
# 得到十日均线价格
ma10 = round(df["close"][-10:].mean(), 3)
# 取得昨天收盘价
price = data[g.security]["close"]
# 如果五日均线大于十日均线
if ma5 > ma10:
if not g.order_buy_flag:
# 获取最大可融资数量
amount = get_margincash_open_amount(g.security).get(g.security)
# 进行融资买入操作
margincash_open(g.security, amount)
# 记录这次操作
log.info("Buying %s Amount %s" % (g.security, amount))
# 当日已融资买入
g.order_buy_flag = True
# 如果五日均线小于十日均线,并且目前有头寸
elif ma5 < ma10 and get_position(g.security).amount > 0:
if not g.order_sell_flag:
# 获取标的卖券还款最大可卖数量
amount = get_margincash_close_amount(g.security).get(g.security)
# 进行卖券还款操作
margincash_close(g.security, -amount)
# 记录这次操作
log.info("Selling %s Amount %s" % (g.security, amount))
# 当日已卖券还款
g.order_sell_flag = True
收起阅读 »
Ptrade担保品买入卖出
担保品卖出指的是融资融券交易当中,用自有资金进行买卖的行为
实际上是买卖股票,但在信用账户上,用只有资金买卖股票。
ptrade支持两融操作。
比如下面的示例代告诉我们,担保品买入股票的3个不同参数的效果:
def initialize(context):
g.security = '600570.SS'
set_universe(g.security)
def handle_data(context, data):
# 以系统最新价委托
margin_trade(g.security, 100)
# 以72块价格下一个限价单
margin_trade(g.security, 100, limit_price=72)
# 以最优五档即时成交剩余撤销委托
margin_trade(g.security, 200, market_type=4)
security:股票代码(str);
amount:交易数量,正数表示买入,负数表示卖出(int);
limit_price:买卖限价(float);
market_type:市价委托类型,上证非科创板股票支持参数1、4,上证科创板股票支持参数0、1、2、4,深证股票支持参数0、2、3、4、5(int);
0:对手方最优价格;
1:最优五档即时成交剩余转限价;
2:本方最优价格;
3:即时成交剩余撤销;
4:最优五档即时成交剩余撤销;
5:全额成交或撤单;
收起阅读 »
anaconda安装python报错 缺少:api-ms-win-core-path-l1-1-0.dll
在win7的系统里面,使用anaconda安装python10,安装上了之后,激活虚拟环境: 然后运行python结果报错:

少了dll文件。
于是学网上(csdn)的方法进行修复,把缺的dll下载下来复制到system32的目录。
但是后面还是报错。
后面才发现,win7的机子只能安装python3.8以下的版本,高版本会报错。
收起阅读 »
少了dll文件。
于是学网上(csdn)的方法进行修复,把缺的dll下载下来复制到system32的目录。
但是后面还是报错。
Python path configuration:
PYTHONHOME = (not set)
PYTHONPATH = (not set)
program name = 'python'
isolated = 0
environment = 1
user site = 1
import site = 1
sys._base_executable = '\u0158\x06'
sys.base_prefix = '.'
sys.base_exec_prefix = '.'
sys.executable = '\u0158\x06'
sys.prefix = '.'
sys.exec_prefix = '.'
sys.path = [
'C:\\anaconda\\python38.zip',
'.\\DLLs',
'.\\lib',
'',
]
Fatal Python error: init_fs_encoding: failed to get the Python codec of the filesystem encodin
Python runtime state: core initialized
ModuleNotFoundError: No module named 'encodings'
Current thread 0x000013a8 (most recent call first):
后面才发现,win7的机子只能安装python3.8以下的版本,高版本会报错。
收起阅读 »
国信如何运行miniQMT
国信的QMT名字叫iQuant, 它也有属于自己的miniQMT。
不过它需要额外申请。就看你的经理愿不愿意帮你去申请了。
毕竟申请这个没有资金要求,纯粹看经理的心情了。申请需要打印纸质电子版文件并签字,拍照发给营业部审核。
而且开通了miniQMT后,只能拉取数据,无法进行交易,因为个人是没有交易权限的,只有机构才可以申请miniQMT的交易权限。
这也是经理不愿意帮你开通的原因,他们有可能会说国信目前不支持miniQMT这样的胡话来推搪打发你。如果需要申请开通,可以联系文末二维码开通国信iquant和miniQMT,这位经理比较热心肠,只要申请,就可以帮你开通miniQMT权限。
如何打开国信的miniQMT?
国信的miniQMT并不是和iQuant绑定的,笔者怀疑是因为iQuant定制化过多,甚至把miniQMT给阉割了。以至于为了补回miniQMT,他们还得特意要下载一个QMT的客户端(其实这个就是其他券商的QMT客户端),然后使用这个客户端和xtquant通讯。
输入个人的账户和密码后,登录极速版,对,国信的极速版即使miniQMT了。勾选极简模式。 国信的miniQMT支持自动登录,这个比国金的要好。国金的由于没有自动登录,每天还得自己手动的登录一次。(笔者之前也提供了几个版本的自动登录脚本,需要的可以到星球获取)


行情源这里要注意,如果你选择的获取最新价,那么在获取行情数据的返回值里面,只有最新价格,没有5档委托价格。( 国信iquant并没有这个选择菜单,估计是深度定制了,删除了)。
由于没有交易权限,账户里面没有显示个人的持仓信息,直接是空白一片

然后把xtquant的文件夹复制到本地的python site-package目录下。用以下下载数据的代码测试一下:
运行python app.py
稍等片刻,数据导出到当前路径,名字为:
128022.sz
打开看一下,数据在csv里面的了。
可关注下面关注号; 如需要开通国信,可以后台回复:开通国信证券
收起阅读 »
不过它需要额外申请。就看你的经理愿不愿意帮你去申请了。
毕竟申请这个没有资金要求,纯粹看经理的心情了。申请需要打印纸质电子版文件并签字,拍照发给营业部审核。
而且开通了miniQMT后,只能拉取数据,无法进行交易,因为个人是没有交易权限的,只有机构才可以申请miniQMT的交易权限。
这也是经理不愿意帮你开通的原因,他们有可能会说国信目前不支持miniQMT这样的胡话来推搪打发你。如果需要申请开通,可以联系文末二维码开通国信iquant和miniQMT,这位经理比较热心肠,只要申请,就可以帮你开通miniQMT权限。
如何打开国信的miniQMT?
国信的miniQMT并不是和iQuant绑定的,笔者怀疑是因为iQuant定制化过多,甚至把miniQMT给阉割了。以至于为了补回miniQMT,他们还得特意要下载一个QMT的客户端(其实这个就是其他券商的QMT客户端),然后使用这个客户端和xtquant通讯。
输入个人的账户和密码后,登录极速版,对,国信的极速版即使miniQMT了。勾选极简模式。 国信的miniQMT支持自动登录,这个比国金的要好。国金的由于没有自动登录,每天还得自己手动的登录一次。(笔者之前也提供了几个版本的自动登录脚本,需要的可以到星球获取)
行情源这里要注意,如果你选择的获取最新价,那么在获取行情数据的返回值里面,只有最新价格,没有5档委托价格。( 国信iquant并没有这个选择菜单,估计是深度定制了,删除了)。
由于没有交易权限,账户里面没有显示个人的持仓信息,直接是空白一片
然后把xtquant的文件夹复制到本地的python site-package目录下。用以下下载数据的代码测试一下:
import pandas as pd
import datetime
def get_tick(code, start_time, end_time, period='tick'):
from xtquant import xtdata
xtdata.download_history_data(code, period=period, start_time=start_time, end_time=end_time)
data = xtdata.get_local_data(field_list=, stock_code=
, period=period, count=10)
result_list = data
df = pd.DataFrame(result_list)保存上述代码为app.py
df['time_str'] = df['time'].apply(lambda x: datetime.datetime.fromtimestamp(x / 1000.0))
return df
def process_timestamp(df, filename):
df = df.set_index('time_str')
result = df.resample('3S').first().ffill()
# result = result[(result.index >= '2022-07-20 09:30') & (result.index <= '2022-07-20 15:00')]
result = result.reset_index()
result.to_csv(filename + '.csv')
def dump_single_code_tick():
# 导出单个转债的tick数据
code='128022'
start_date = '20210113'
end_date = '20210130'
post_fix = 'SZ' if code.startswith('12') else 'SH'
code = '{}.{}'.format(code,post_fix)
filename = '{}'.format(code)
df = get_tick(code, start_date, end_date)
process_timestamp(df, filename)
dump_single_code_tick()
运行python app.py
稍等片刻,数据导出到当前路径,名字为:
128022.sz
打开看一下,数据在csv里面的了。
可关注下面关注号; 如需要开通国信,可以后台回复:开通国信证券
收起阅读 »
golang执行系统shell命令,并获取返回内容
可以使用 os/exec 包中的 Command 函数执行 shell 命令,并使用 CombinedOutput 方法获取命令的输出结果和退出码。示例代码如下:
调用 runCommand 函数即可执行 shell 命令,并获取命令的输出结果。如果命令执行成功,则返回输出结果和 nil,否则返回空字符串和错误信息。需要注意的是,由于 CombinedOutput 方法会等待命令执行完毕才返回,因此在执行耗时较长的命令时可能会阻塞程序的执行。可以使用 Start 和 Wait 方法实现异步执行命令的效果。 收起阅读 »
import (
"fmt"
"os/exec"
)
func runCommand(command string) (string, error) {
cmd := exec.Command("sh", "-c", command)
output, err := cmd.CombinedOutput()
if err != nil {
return "", err
}
return string(output), nil
}
调用 runCommand 函数即可执行 shell 命令,并获取命令的输出结果。如果命令执行成功,则返回输出结果和 nil,否则返回空字符串和错误信息。需要注意的是,由于 CombinedOutput 方法会等待命令执行完毕才返回,因此在执行耗时较长的命令时可能会阻塞程序的执行。可以使用 Start 和 Wait 方法实现异步执行命令的效果。 收起阅读 »
修改正在运行的docker容器,禁用重启自动启动
启动拖慢了速度,尤其是一些只用一两次的镜像,每次还在电脑重启时容器跟随启动,太占用资源。
可以使用 docker update 命令修改容器的配置,示例命令如下:
这条命令会将容器的重启策略设置为不重启,即禁用重启自动启动。如果需要启用自动启动,只需要将 --restart 参数的值改为 always 或 on-failure 等相应的选项即可。
需要注意的是,修改容器的配置并不会立即生效,需要重启容器才能使修改生效。可以使用 docker restart 命令重启容器,示例命令如下:
执行这条命令后,容器会被重启并应用新的配置。 收起阅读 »
可以使用 docker update 命令修改容器的配置,示例命令如下:
docker update --restart=no <容器ID或名称>
这条命令会将容器的重启策略设置为不重启,即禁用重启自动启动。如果需要启用自动启动,只需要将 --restart 参数的值改为 always 或 on-failure 等相应的选项即可。
需要注意的是,修改容器的配置并不会立即生效,需要重启容器才能使修改生效。可以使用 docker restart 命令重启容器,示例命令如下:
docker restart <容器ID或名称>
执行这条命令后,容器会被重启并应用新的配置。 收起阅读 »
国内免登录免注册的chatGPT套壳网站大全【 超全整理】
本地CPU部署的stable diffusion webui 环境,本地不受限,还可以生成色图黄图
还没有体验的朋友可以试试chatGPT的强大
PS: 目前部分可能需要科学上网才能访问了。

收起阅读 »
还没有体验的朋友可以试试chatGPT的强大
PS: 目前部分可能需要科学上网才能访问了。
ChatGPT 镜像网站汇总另外还有chatGPT共享整理一批 注册好的免费chatGPT账户,从分享群里获取的,亲测有效
BAI Chat GPT3.5 免登录 https://chat.theb.ai
ChatGPT GPT3.5 免登录 https://www.aitoolgpt.com/
Chat For AI GPT3.5 免登录,限制5次提问 https://chatforai.com/
ChatGPT Web GPT3.5 免登录 https://freechatgpt.chat/
ChatGPT GPT3.5 免登录 https://fastgpt.app/
光速Ai GPT3.5 免登录,限制 https://ai.ls
ChatGPT演示 GPT3.5 免登录 https://chatgpt.ddiu.me/
免费GPT GPT3.5 免登录 https://freegpt.one/
FreeGPT GPT3.5 免登录 https://freegpt.cc
ChatGPT Hub GPT3.5 免费100次,Plus接口 https://www.mulaen.com/
TGGPT GPT3.5 登录很卡 https://chat.tgbot.co/chat
New Chat GPT3.5 需API https://fastgpt.app/
开发交流 GPT3.5 免登录 https://chat.yqcloud.top
Ai117 GPT3.5 免登录 https://ai117.com/
周报通 GPT3.5 写周报专用 https://zhoubaotong.com/zh
Fake ChatGPT 未知 免登录 https://gpt.sheepig.top/chat
AI EDU GPT3.5 需API https://chat.forchange.cn/
中文公益版 免登录 https://gpt.tool00.com/
免费ChatGPT(论坛支持) GPT3 免登录 https://openaizh.com/chatgpt.html
AI Chat Bot GPT3 免登录,不稳定 https://chat.gptocean.com/
Hi icu GPT3 部分付费 https://hi.icu/
Aicodehelper GPT3 免登录 https://aicodehelper.com/
ChatGPT Robot 其他 其他 https://ai.zecoba.cn/
Ai帮个忙 其他 工具箱 https://ai-toolbox.codefuture.top/
GPTZero 内容检测 内容检测 https://gptzero.me/
ChatGPT中文版 GPT3.5 免登录 https://chat35.com/chat
收起阅读 »
ptrade QMT 动态止盈卖出 python代码实现
帮你轻松实现自动止盈。
比如设置20%,那么会每天盘中扫描,可以精确到3S 一格,如果你的持仓股的收益率大于20%,它将会帮你自动卖出。
占坑 待续 》》》
比如设置20%,那么会每天盘中扫描,可以精确到3S 一格,如果你的持仓股的收益率大于20%,它将会帮你自动卖出。
占坑 待续 》》》
linux下自制护眼,久坐提醒 python小程序
很简单,在任意linux版本均可运行,python3环境;
保存为app.py
运行; python app.py
然后写到系统的crontab计划任务里面,每个40分钟执行几次,
屏幕会黑屏60s , 60可以自行设置。
挺好用的。
PS: AI生成的image还真心不错呢。 就是太吃显存了

收起阅读 »
保存为app.py
运行; python app.py
然后写到系统的crontab计划任务里面,每个40分钟执行几次,
屏幕会黑屏60s , 60可以自行设置。
挺好用的。
import datetime as dt
import tkinter as tk
# Linux 护眼程序
sec = 60 # 休息时间 秒
root = tk.Tk()
root.config(bg='black')
root.wm_attributes('-topmost',1)
root.wm_attributes('-fullscreen',1)
L = tk.Label(root,font=('Consolas', 50), bg='black')
L.place(relx=0.5,rely=0.5,anchor=tk.CENTER)
# 改变的内容
msg = "{}\n 站起来 {} \n 动一动 {}\n{}"
now = dt.datetime.now()
aa = {0:'↑',1:'→',2:'↓',3:'←'}
bb = {0:'~~_↑_~~',1:'~_↑ ↑_~'}
for i in range(sec):
t = msg.format(sec-i,aa[i%4],bb[i%2],(now+dt.timedelta(seconds=i)).ctime())
c = 'Black' # 颜色可以搞随机换
root.after(i*1000,L.config,{'text':t,'fg':c})
root.after(sec*1000,root.destroy)
root.mainloop()
PS: AI生成的image还真心不错呢。 就是太吃显存了
收起阅读 »
ptrade qmt的模拟账户能不用尽量不用,无尽的bug让你浪费时间 怀疑人生
个人平时基本很少用模拟账户。但有时候又没有办法。实盘账户在跑,仓位无法挪腾出来测试(最近折腾的打板策略)
所以临时登录了模拟账户。 里面也挺悲剧的,初始化的500w资金,之前测试的时候随意买入的转债,很多都强赎了。而ptrade里面依然还在,导致大部分是亏损99%以上, 账上只剩可怜的88w,虚拟基金。
今天用ptrade获取A股市场所有的股票代码,居然调试了半小时,代码如下
输出的stock是[],没有任何数据。

上面的xxxxx is expired , close all positions by system. 是因为模拟账户上退市转债还依然挂在上面,清仓也清不掉。每次跑就循环一分钟输出。。
换了个券商的模拟账户,问题依然在,只好倒腾实盘账户。然后问题就解决了。
这个问题,在qmt上就更加严重了。 下次在星球上或者群里慢慢吐槽吧
收起阅读 »
所以临时登录了模拟账户。 里面也挺悲剧的,初始化的500w资金,之前测试的时候随意买入的转债,很多都强赎了。而ptrade里面依然还在,导致大部分是亏损99%以上, 账上只剩可怜的88w,虚拟基金。
今天用ptrade获取A股市场所有的股票代码,居然调试了半小时,代码如下
def initialize(context):
# 初始化策略
g.security = "600570.SS"
set_universe(g.security)
def handle_data(context, data):
stock=get_Ashares()
log.info(stock)
输出的stock是[],没有任何数据。
上面的xxxxx is expired , close all positions by system. 是因为模拟账户上退市转债还依然挂在上面,清仓也清不掉。每次跑就循环一分钟输出。。
换了个券商的模拟账户,问题依然在,只好倒腾实盘账户。然后问题就解决了。
这个问题,在qmt上就更加严重了。 下次在星球上或者群里慢慢吐槽吧
收起阅读 »
qmt position对象里面有哪些属性?
查看属性的代码:
得到的position的内置属性有下面的:
虽然有上面的属性,但是实际上很可能是空的,并没有值。

收起阅读 »
obj_list = get_trade_detail_data(ACCOUNT,'stock','position')
for obj in obj_list:
print(obj.m_strInstrumentID,obj.m_strInstrumentName,'----')
# 查看有哪些属性字段
print('='*10)
for item in dir(obj):
if not item.startswith('__'):
print(item)
print('='*10)
得到的position的内置属性有下面的:
m_bIsToday
m_dAvgOpenPrice
m_dCloseAmount
m_dCloseProfit
m_dFloatProfit
m_dInstrumentValue
m_dLastPrice
m_dLastSettlementPrice
m_dMargin
m_dMarketValue
m_dOpenCost
m_dOpenPrice
m_dPositionCost
m_dPositionProfit
m_dProfitRate
m_dRealUsedMargin
m_dRedemptionVolume
m_dReferenceRate
m_dRoyalty
m_dSettlementPrice
m_dSingleCost
m_dStaticHoldMargin
m_dStockLastPrice
m_dStructFundVol
m_dTotalCost
m_eFutureTradeType
m_eSideFlag
m_nCanUseVolume
m_nCidIncrease
m_nCidIsDelist
m_nCidRateOfCurrentLine
m_nCidRateOfTotalValue
m_nCloseVolume
m_nCoveredVolume
m_nDirection
m_nEnableExerciseVolume
m_nFrozenVolume
m_nHedgeFlag
m_nLegId
m_nOnRoadVolume
m_nOptCombUsedVolume
m_nPREnableVolume
m_nVolume
m_nYesterdayVolume
m_strAccountID
m_strAccountKey
m_strComTradeID
m_strExchangeID
m_strExchangeName
m_strExpireDate
m_strInstrumentID
m_strInstrumentName
m_strOpenDate
m_strProductID
m_strProductName
m_strStockHolder
m_strTradeID
m_strTradingDay
m_xtTag
虽然有上面的属性,但是实际上很可能是空的,并没有值。
收起阅读 »
qmt 可转债 双低(阈值)轮动 实盘代码
之前在星球埋的坑,答应群友写个qmt的双低可转债的轮动实盘代码。
用已有的ptrade的代码,然后部分获取行情和交易接口按照qmt的接口文档(http://qmt.ptradeapi.com )重写,就给了一版。(对,很早以前就有一版ptrade的转债双低的了)
无论是qmt还是ptrade,都只是一个工具,用熟悉了,都无所哪个好哪个不好。



完整代码在个人星球。
觉得之前星球太便宜了,不仅给了代码,还部署了接口免费使用,通过接口获取可转债的实时数据,强赎天数,规模,溢价率,评级等等一系列数据。 而且随着时间的推移,里面积累的数据,代码也越来越多,感觉这样对前面进去并不断续费的星友有点公平,尽管以后他们续费都直接打折扣。所以还是按照一些大v运营的意见,逐年涨价策略。
越往后的朋友,因为前面积累的内容越多,因此价格也随之增长。
当然有能力可以自己写接口,部署,实盘,获取三方数据的大v,就没必要加了。
 收起阅读 »
收起阅读 »
用已有的ptrade的代码,然后部分获取行情和交易接口按照qmt的接口文档(http://qmt.ptradeapi.com )重写,就给了一版。(对,很早以前就有一版ptrade的转债双低的了)
无论是qmt还是ptrade,都只是一个工具,用熟悉了,都无所哪个好哪个不好。
完整代码在个人星球。
觉得之前星球太便宜了,不仅给了代码,还部署了接口免费使用,通过接口获取可转债的实时数据,强赎天数,规模,溢价率,评级等等一系列数据。 而且随着时间的推移,里面积累的数据,代码也越来越多,感觉这样对前面进去并不断续费的星友有点公平,尽管以后他们续费都直接打折扣。所以还是按照一些大v运营的意见,逐年涨价策略。
越往后的朋友,因为前面积累的内容越多,因此价格也随之增长。
当然有能力可以自己写接口,部署,实盘,获取三方数据的大v,就没必要加了。
收起阅读 »
qmt软件里面的快速计算是在什么模式下使用的?
QMT 平台模型是根据行情驱动,逐 K 线运行的。
即点击运行模型时,模型是从第 0 根 K 线开始运行到最后一根 K 线(如想加快模型运行速度,可以策略编辑器 - 基本信息中设置快速计算,限制计算范围,只计算最新的指定数量的 K 线范围),每根 K 线调用一次 Python 模型中的 handlebar(ContextInfo) 函数。
也就是你点击“运行”按钮的时候,如果你的快速计算默认设置的是0,
handlebar里面的k线是从2005年1月1日运行的,即使你在代码里面设置了运行时间:

都是不管用的。
需要在代码里添加一句:
或者 把快速计算的值设置为1, 就只会以最新的k线计算。也就是只会执行1次handlebar。

不得不说,qmt的说明文档很让人困惑的。笔者也多次吐槽了。
如果没有编程的朋友,不建议自己折腾了。不少编程大咖都惊呼这软件和文档入门太难,文档太扯淡。
如果需要qmt策略代码 和实盘代码 代写,可以在公众号后台留言:qmt代写
收起阅读 »
即点击运行模型时,模型是从第 0 根 K 线开始运行到最后一根 K 线(如想加快模型运行速度,可以策略编辑器 - 基本信息中设置快速计算,限制计算范围,只计算最新的指定数量的 K 线范围),每根 K 线调用一次 Python 模型中的 handlebar(ContextInfo) 函数。
也就是你点击“运行”按钮的时候,如果你的快速计算默认设置的是0,
handlebar里面的k线是从2005年1月1日运行的,即使你在代码里面设置了运行时间:
def init(ContextInfo):或者在回测参数里面设置的时间:
print("==============start==========")
ContextInfo.start = '2023-02-20 10:00:00'
ContextInfo.end = '2023-02-23 10:00:00'
都是不管用的。
需要在代码里添加一句:
if not ContextInfo.is_last_bar():
return
或者 把快速计算的值设置为1, 就只会以最新的k线计算。也就是只会执行1次handlebar。
不得不说,qmt的说明文档很让人困惑的。笔者也多次吐槽了。
如果没有编程的朋友,不建议自己折腾了。不少编程大咖都惊呼这软件和文档入门太难,文档太扯淡。
如果需要qmt策略代码 和实盘代码 代写,可以在公众号后台留言:qmt代写
收起阅读 »
qmt隔夜文件单(python代码实现)实盘代码

代码基于iquant平台编写。可以拿去参考参考。
# encoding:gbk
import logging
import pandas as pd
from datetime import datetime, timedelta, time
from decimal import InvalidOperation
from decimal import Decimal as D
from READFILE import read_file
logging.basicConfig(level=logging.INFO)
# 挂单失败后的等待时长,以秒计
TIMEOUT_ON_FAIL_SEC = 30
# 规避 account_callback 的 Racing Condition
RUN_TIME_DELAY = 10
# global FILEPATH, DIR, PRICE, VOL, START_TIME, account
SH_pattern = r'^[1-9]\d{5}\.(sh|SH)$'
SZ_pattern = r'^(?!39)\d{6}\.(sz|SZ)$'
SH_prefix = ['5', '6', '9', '11']
SZ_prefix = ['0', '2', '30', '12', '159']
COLNAMES = ['direction', 'vol', 'price', 'start_time']
def init(ContextInfo):
ContextInfo.accID = account
ContextInfo.set_account(ContextInfo.accID)
ContextInfo.can_order = False
ContextInfo.all_order_done = False
if not load_file_order(ContextInfo):
load_sys_order(ContextInfo)
# load_file_order(ContextInfo)
ContextInfo.run_time("place_order", "{0}nSecond".format(TIMEOUT_ON_FAIL_SEC),
(datetime.now() + timedelta(seconds=RUN_TIME_DELAY)).strftime('%Y-%m-%d %H:%M:%S'), 'SH')
def account_callback(ContextInfo, accountInfo):
if not ContextInfo.can_order:
ContextInfo.can_order = True
def handlebar(ContextInfo):
return
def load_file_order(ContextInfo):
def _price_vol_filtering(row):
if not isinstance(row.start_time, time):
logging.warning('读取{0}指令时间失败: {1}'.format(row.name, row.start_time))
return None
if row.direction not in ['买', '卖']:
logging.warning('读取{0}买卖方向失败: {1}'.format(row.name, row.direction))
return None
try:
# parse start_time
curr_start_time = datetime.now().strftime('%Y-%m-%d ') + row.start_time.strftime('%H:%M:%S')
curr_start_time = datetime.strptime(curr_start_time, '%Y-%m-%d %H:%M:%S')
# parse direction
curr_direction = 23 if row.direction == '买' else 24
# parse price and vol
price = D(row.price)
vol = int(row.vol)
return pd.Series([curr_direction, vol, price, curr_start_time])
except InvalidOperation:
logging.warning("读取 {0} 指令价格失败: {1}".format(row.name, row.price))
return None
except ValueError:
logging.warning('读取 {0} 下单总量失败: {1}'.format(row.name, row.vol))
return None
def _name_parser(asset_name):
# 目前默认用户输入.SH 或.SZ时标的名称正确
if '.SH' in asset_name or '.SZ' in asset_name:
# todo: SH/SZ_pattern regex check here?
return asset_name
else:
raise ValueError('{0} 标的代码不合法'.format(asset_name))
try:
tmp_df = read_file(FILEPATH, names=COLNAMES, index_col=0)
except:
logging.warning('读取挂单配置文件失败或挂单配置文件为空,尝试交易读取配置面板参数')
return None
if tmp_df.empty:
logging.warning('读取挂单配置文件失败或挂单配置文件为空,尝试交易读取配置面板参数')
return None
tmp_df.index = tmp_df.index.to_series().astype(str)
tmp_df.index = tmp_df.index.str.strip()
tmp_df.index = tmp_df.index.str.upper()
tmp_df.index = tmp_df.index.to_series().apply(_name_parser).dropna()
tmp_df = tmp_df.apply(_price_vol_filtering, axis=1, broadcast=True).dropna()
if tmp_df.empty:
logging.warning('读取挂单配置文件失败或挂单配置文件为空,尝试交易读取配置面板参数')
return False
tmp_df.set_axis(COLNAMES, axis='columns', inplace=True)
# 挂单成功Flag
tmp_df['finished'] = [False] * tmp_df.shape[0]
ContextInfo.order_df = tmp_df
ContextInfo.set_universe(ContextInfo.order_df.index.tolist())
return True
def load_sys_order(ContextInfo):
try:
asset_name = ContextInfo.stockcode + '.' + ContextInfo.market
ContextInfo.set_universe([asset_name])
direction = 23 if DIR == '买入' else 24
start_time = datetime.strptime(datetime.now().strftime('%Y%m%d') + str(START_TIME), '%Y%m%d%H%M%S')
price = D(PRICE)
vol = int(VOL)
except BaseException:
raise ValueError("读取策略面板交易配置失败。请尝试修正挂单配置文件或者策略面板参数。")
price = float(price)
ContextInfo.order_df = pd.DataFrame(data=[direction, vol, price, start_time], index=COLNAMES,
columns=[asset_name]).T
ContextInfo.order_df['finished'] = False
return
def place_order(ContextInfo):
if not ContextInfo.can_order or ContextInfo.all_order_done:
return
for curr_asset in ContextInfo.get_universe():
if not ContextInfo.order_df.loc[curr_asset].finished \
and datetime.now() > ContextInfo.order_df.loc[curr_asset].start_time:
curr_order = ContextInfo.order_df.loc[curr_asset]
direction = int(curr_order.direction)
txt_direction = '买入' if direction == 23 else '卖出'
price = float(D(curr_order.price))
vol = int(curr_order.vol)
order_remark = '隔日文件挂单: 以 {0} {1} {2}'.format(price, txt_direction, curr_asset)
passorder(direction, 1101, ContextInfo.accID, curr_asset, 11, price, vol, order_remark, 1, order_remark,
ContextInfo)
ContextInfo.order_df.loc[curr_asset, 'finished'] = True
ContextInfo.all_order_done = all(ContextInfo.order_df['finished'].tolist())
def order_callback(ContextInfo, orderInfo):
curr_asset = orderInfo.m_strInstrumentID + '.' + orderInfo.m_strExchangeID
curr_remark = orderInfo.m_strRemark
curr_status = orderInfo.m_nOrderStatus
if '隔日文件挂单' in curr_remark and curr_status == 57:
ContextInfo.order_df.loc[curr_asset, 'finished'] = False
ContextInfo.all_order_done = False
logging.error('{0} 隔日文件挂单:报单废单 (柜台返回失败),原因:{1} 尝试重报'.format(curr_asset, orderInfo.m_strCancelInfo))
elif '隔日文件挂单' in curr_remark and curr_status == 50:
logging.info('{0} 隔日文件挂单:报单成功'.format(curr_asset))
return
def orderError_callback(ContextInfo, orderArgs, errMsg):
curr_asset = orderArgs.orderCode
if '隔日文件挂单' in orderArgs.strategyName:
ContextInfo.order_df.loc[curr_asset, 'finished'] = False
ContextInfo.all_order_done = False
logging.error('{0} 隔日文件挂单:账号下单异常 (COS/iQuant校验失败), 错误消息:{1} 尝试重报'.format(curr_asset, errMsg))
return
把上述代码复制到iquant里面,然后部署到策略运行,运行策略,切换为实盘
收起阅读 »
qmt的文档写的有点稀烂
在部署QMT 在线文档的时候,还是忍不住吐槽下它的文档。
这也是当时不用QMT的一个重要原因。
不仅仅是文档,而且还有它的函数接口的涉及。
比如最常用的交易函数,passorder
里面有11个参数,可选参数有2个。 对于一个常用函数来说,这个参数有点多了。
而更为令人费解的,是它参数里面额设定值
比如第一个opType,操作类型。
里面有59个数字:
它把期货,股票,期权所有品种压缩到一起,通过参数数字来辨认交易类别。
那么我们来看一看一个例子,就拿一个官网的一个例子来说:
最简单的例子:
一般人看了上面的代码,里面全部是数字,简直就像灾难一样。 但是我要明白它的交易品种和交易逻辑,
就得对着文档去查,编号23是啥,1101是啥,11,14又是啥。
如果我是代码reviewer,底下的员工这种文档,或者写代码的人,提交上这样的代码,绝对100%是要reject这个提交的。
然后orderType 更加让人吐血。。
然后下单 类型,继续来各种枚举:
会不会用常量定义个值给客户调用呢?
没有标注类型:
虽然python是若类型的语言,可是qmt底层是c++,有些参数不对,就会导致异常:
比如交易软件:
比如下单函数passorder的参数列表:
看完不想吐槽了,一群文科生设计的软件。。。

收起阅读 »
这也是当时不用QMT的一个重要原因。
不仅仅是文档,而且还有它的函数接口的涉及。
比如最常用的交易函数,passorder
综合交易下单 passorder()
用法: passorder(opType, orderType, accountid, orderCode, prType, modelprice, volume[, strategyName, quickTrade, userOrderId], ContextInfo)
里面有11个参数,可选参数有2个。 对于一个常用函数来说,这个参数有点多了。
而更为令人费解的,是它参数里面额设定值
比如第一个opType,操作类型。
里面有59个数字:
期货六键:
0:开多
1:平昨多
2:平今多
3:开空
4:平昨空
5:平今空
期货四键:
6:平多,优先平今
7:平多,优先平昨
8:平空,优先平今
9:平空,优先平昨
期货两键:
10:卖出,如有多仓,优先平仓,优先平今,如有余量,再开空
11:卖出,如有多仓,优先平仓,优先平昨,如有余量,再开空
12:买入,如有空仓,优先平仓,优先平今,如有余量,再开多
13:买入,如有空仓,优先平仓,优先平昨,如有余量,再开多
14:买入,不优先平仓
15:卖出,不优先平仓
股票买卖:
23:股票买入,或沪港通、深港通股票买入
24:股票卖出,或沪港通、深港通股票卖出
融资融券:
27:融资买入
28:融券卖出
29:买券还券
30:直接还券
31:卖券还款
32:直接还款
33:信用账号股票买入
34:信用账号股票卖出
组合交易:
25:组合买入,或沪港通、深港通的组合买入
26:组合卖出,或沪港通、深港通的组合卖出
27:融资买入
28:融券卖出
29:买券还券
31:卖券还款
33:信用账号股票买入
34:信用账号股票卖出
40:期货组合开多
43:期货组合开空
46:期货组合平多,优先平今
47:期货组合平多,优先平昨
48:期货组合平空,优先平今
49:期货组合平空,优先平昨
期权交易:
50:买入开仓
51:卖出平仓
52:卖出开仓
53:买入平仓
54:备兑开仓
55:备兑平仓
56:认购行权
57:认沽行权
58:证券锁定
59:证券解锁
它把期货,股票,期权所有品种压缩到一起,通过参数数字来辨认交易类别。
那么我们来看一看一个例子,就拿一个官网的一个例子来说:
最简单的例子:
passorder(23,1101,account,s,11,14.00,100,2,ContextInfo)
一般人看了上面的代码,里面全部是数字,简直就像灾难一样。 但是我要明白它的交易品种和交易逻辑,
就得对着文档去查,编号23是啥,1101是啥,11,14又是啥。
如果我是代码reviewer,底下的员工这种文档,或者写代码的人,提交上这样的代码,绝对100%是要reject这个提交的。
然后orderType 更加让人吐血。。
1101:单股、单账号、普通、股/手方式下单这排列组合,谁能记得住,逼着你去查文档,或者每次复制粘贴旧代码。
1102:单股、单账号、普通、金额(元)方式下单(只支持股票)
1113:单股、单账号、总资产、比例 [0 ~ 1] 方式下单
1123:单股、单账号、可用、比例[0 ~ 1]方式下单
1201:单股、账号组(无权重)、普通、股/手方式下单
1202:单股、账号组(无权重)、普通、金额(元)方式下单(只支持股票)
1213:单股、账号组(无权重)、总资产、比例 [0 ~ 1] 方式下单
1223:单股、账号组(无权重)、可用、比例 [0 ~ 1] 方式下单
2101:组合、单账号、普通、按组合股票数量(篮子中股票设定的数量)方式下单 > 对应 volume 的单位为篮子的份
2102:组合、单账号、普通、按组合股票权重(篮子中股票设定的权重)方式下单 > 对应 volume 的单位为元
2103:组合、单账号、普通、按账号可用方式下单 > (底层篮子股票怎么分配?答:按可用资金比例后按篮子中股票权重分配,如用户没填权重则按相等权重分配)只对股票篮子支持
2201:组合、账号组(无权重)、普通、按组合股票数量方式下单
2202:组合、账号组(无权重)、普通、按组合股票权重方式下单
然后下单 类型,继续来各种枚举:
-1:无效(实际下单时,需要用交易面板交易函数那设定的选价类型)
0:卖5价
1:卖4价
2:卖3价
3:卖2价
4:卖1价
5:最新价
6:买1价
7:买2价(组合不支持)
8:买3价(组合不支持)
9:买4价(组合不支持)
10:买5价(组合不支持)
11:(指定价)模型价(只对单股情况支持,对组合交易不支持)
12:涨跌停价
13:挂单价
14:对手价
27:市价即成剩撤(仅对股票期权申报有效)
28:市价即全成否则撤(仅对股票期权申报有效)
29:市价剩转限价(仅对股票期权申报有效)
42:最优五档即时成交剩余撤销申报(仅对上交所申报有效)
43:最优五档即时成交剩转限价申报(仅对上交所申报有效)
44:对手方最优价格委托(仅对深交所申报有效)
45:本方最优价格委托(仅对深交所申报有效)
46:即时成交剩余撤销委托(仅对深交所申报有效)
47:最优五档即时成交剩余撤销委托(仅对深交所申报有效)
48:全额成交或撤销委托(仅对深交所申报有效)
49:科创板盘后定价
会不会用常量定义个值给客户调用呢?
passorder(
ContextInfo.TYPE_STOCK,
ContextInfo.TYPE_BUY,
100,
ContextInfo.LIMIT_PRICE,
ContextInfo)
没有标注类型:
虽然python是若类型的语言,可是qmt底层是c++,有些参数不对,就会导致异常:
比如交易软件:
比如下单函数passorder的参数列表:
volume,下单数量(股 / 手 / 元 / %)这个类型如果用了浮点,前面类型用了以股为但是,是会报错的,因为不存在100.11 股这样的非100单位的下单数据。
passorder(opType, orderType, accountID, orderCode, prType, price, volume, ContextInfo)
根据 orderType 值最后一位确定 volume 的单位:
单股下单时:
1:股 / 手
2:金额(元)
3:比例(%)
看完不想吐槽了,一群文科生设计的软件。。。
收起阅读 »




qmt iquant最新接口文档
申请了个二级域名,作为QMT iQuant的接口文档。懒得再去搞新的域名了,凑合这用,和ptrade的接口文档拼在一个根域名下面
http://qmt.ptradeapi.com



除了官方的接口文档,还加入了一些个人平时编写的写法与回测,实盘代码。 不定期更新。
欢迎关注收藏。 收起阅读 »
http://qmt.ptradeapi.com
除了官方的接口文档,还加入了一些个人平时编写的写法与回测,实盘代码。 不定期更新。
欢迎关注收藏。 收起阅读 »
整理一批 注册好的免费chatGPT账户,从分享群里获取的,亲测有效

请勿随意修改密码:
ChatGPT共享账号https://chat.openai.com/auth/login
账号1:vickye89@hotmail.com
密码:LeZ25X5dwL
账号2:eugeniev552@hotmail.com
密码2:4w95MnvIvc
账号3:ayakonewuyo@hotmail.com
密码3:q8UCd2lST4
账号4:ludmillasteb9@hotmail.com
密码4:7sb54Oii8I
账号5:chr89kuchto@hotmail.com
密码5:Cea7IQj5ud
账号6:emil03mk@hotmail.com
密码6:ENC82hip2A
账号7:lydiavn9ktutoky@hotmail.com
密码7:6351VsZz25
账号8:tulagj3@hotmail.com
密码8:Wx99eCqer7
账号9:prue56zjehle@hotmail.com
密码9:8398k84X85
账号10:vernitagq2@hotmail.com
密码10:geFfr4H0x9
账号11:kirstiealtqw@hotmail.com
密码11:1FBbV8OJg9
账号12:ralphnamer32d@hotmail.com
密码12:F85T86YtbL
账号13:celinabullievmu@hotmail.com
密码13:OqTz0lj525
账号14:chanafdidelaet@hotmail.com
密码14:6x3CM4pPYY
账号15:alita07pbogdon@hotmail.com
密码15:Umppl1ylc0
账号16:averilltxgt@hotmail.com
密码16:94cymN2p42
账号17:mobyfotohy7@hotmail.com
密码17:c8iJi0Fd
账号18:muficylequ9@hotmail.com
密码18:5p0KWJf1D
账号19:naehahogujo0@hotmail.com
密码19:xgH5o3jKV
账号20:naejexelibu@hotmail.com
密码20:fZg44fVeh
账号21:naezhaeshequsito@outlook.com
密码21:PtRbh31IF
账号22:neladeroka@hotmail.com
密码22:McTk3Qrz
账号23:pyvohywaeli@outlook.com
密码23:Ehk9d5QFz4
账号24:qadakidone@hotmail.com
密码24:I836s6941q
账号25:qaraesisheby9@hotmail.com
密码25:UQkJim80c
账号26:qaxiberasipy@outlook.com
密码26:XVYluIYy2P
账号27:qeluzhaelagy4@hotmail.com
密码27:8qZEl20fR
账号28:qobiluno7@hotmail.com
密码28:4KiM2C0q9
账号29:qupipaeshe1@outlook.com
密码29:4j9NSpGHEZ
账号30:qyshymisifi0@hotmail.com
密码30:Sfp9D0UNK4
账号31:raehotushawo@hotmail.com
密码31:2d0H8o9L
ChatGPT登录地址 ChatGPT
需要配合梯子使用,效果更佳。
如果显示:

就是要搭梯子了
更多数据,请关注公众号,后台回复:chatgpt账户
收起阅读 »
【白嫖服务器】render.com上部署flask程序
要在Render.com上部署Flask应用程序,可以按照以下步骤进行操作:
1. 注册Render.com帐户并创建一个新的Web服务。
2. 在“添加服务”页面上选择“Web服务”并选择“自定义”作为服务类型。
3. 选择一个适合您的Flask应用程序的服务器和端口。
4. 在“高级”选项卡中添加一个名为“WEB_COMMAND”的环境变量,其值为“gunicorn your_app_name:app”(替换your_app_name为您的应用程序名称)。
5. 在“高级”选项卡中添加一个名为“WEB_CONCURRENCY”的环境变量,其值为应用程序的工作进程数(例如2)。
6. 将您的Flask应用程序代码推送到GitHub或其他源代码管理库中,并将其链接到Render.com服务。
7. 等待几分钟,Render.com将自动构建和部署您的Flask应用程序。
完成以上步骤后,您的Flask应用程序将已经成功部署在Render.com上。
示例代码:

同步到github上后,绑定域名,运行得到:

是不是很简单呢?
网站可以免费解析25个域名,超过的需要收费。不过一般人应该不会超过那么多的域名的了吧。
收起阅读 »
1. 注册Render.com帐户并创建一个新的Web服务。
2. 在“添加服务”页面上选择“Web服务”并选择“自定义”作为服务类型。
3. 选择一个适合您的Flask应用程序的服务器和端口。
4. 在“高级”选项卡中添加一个名为“WEB_COMMAND”的环境变量,其值为“gunicorn your_app_name:app”(替换your_app_name为您的应用程序名称)。
5. 在“高级”选项卡中添加一个名为“WEB_CONCURRENCY”的环境变量,其值为应用程序的工作进程数(例如2)。
6. 将您的Flask应用程序代码推送到GitHub或其他源代码管理库中,并将其链接到Render.com服务。
7. 等待几分钟,Render.com将自动构建和部署您的Flask应用程序。
完成以上步骤后,您的Flask应用程序将已经成功部署在Render.com上。
示例代码:
from flask import Flask上面是app.py 的内容
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
同步到github上后,绑定域名,运行得到:
是不是很简单呢?
网站可以免费解析25个域名,超过的需要收费。不过一般人应该不会超过那么多的域名的了吧。
Starting February 1, 2022, we will begin charging $0.60 per custom domain per month beyond the first 25 custom domains for a web service or static site. The first 25 custom domains for web services and static sites will continue to be free.
收起阅读 »

