
映射端口 methodot 云主机 外部访问
默认情况下,methodot提供的免费云主机 固定了几个端口给外部访问:

如果我们做了web,要怎么映射出来呢?
很简单,只要把web端口改为8001 - 8005 之中的一个。
然后用上面表格中对应的端口映射来访问就可以了
比如下面的flask代码:
因为8001映射出去的端口是 33442,
所以你可以在浏览器访问你的主机:
curl http://xxxxxxxxxxxxx.methodot.com:33442/
话说,之前以为这个主机随时提桶跑路的,不过用到现在还好。
每一个应用都是一个docker镜像。 所以你的linux系统是无法使用 systemctl 控制服务启动的。
会包权限不够。 收起阅读 »
如果我们做了web,要怎么映射出来呢?
很简单,只要把web端口改为8001 - 8005 之中的一个。
然后用上面表格中对应的端口映射来访问就可以了
比如下面的flask代码:
from flask import Flask, jsonify
# 最基本的测试
app =Flask(__name__)
@app.route('/about')
def about():
return 'this is about page'
@app.route('/404')
def error_handle():
return '404 error'
@app.route('/')
def error_handle():
return jsonify({'code':100})
if __name__=='__main__':
app.run(host='0.0.0.0',port=8001,debug=True)
因为8001映射出去的端口是 33442,
所以你可以在浏览器访问你的主机:
curl http://xxxxxxxxxxxxx.methodot.com:33442/
话说,之前以为这个主机随时提桶跑路的,不过用到现在还好。
每一个应用都是一个docker镜像。 所以你的linux系统是无法使用 systemctl 控制服务启动的。
会包权限不够。 收起阅读 »
vmware player Unable to install all modules. See log for details
Vmware player
Unable to install all modules. See log for details
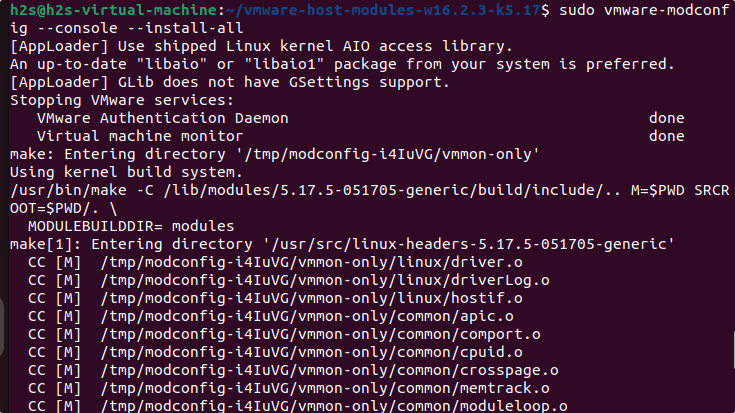
ubuntu下的vmware play经常会让更新模块。一起点击确认就可以正常编译更新。
而且一定要编译后才能打开虚拟机系统
但是奇怪的是,最近一次点击 更新,报错:
显示的英文错误信息:
Unable to install all modules. See log for details
看了日志:
报错信息在这里:
遇到问题后就google一番。
果然还是老外大神多。
翻了一个解决方案后,终于找到一个可行的。【所以必须的英语水平还是要的】
可行的方案:
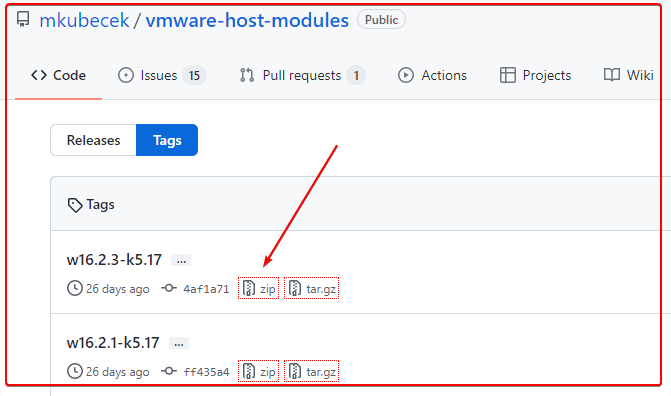
去github下载最新的host-modules
https://github.com/mkubecek/vmware-host-modules
下载一个最新的。
然后解压:
得到以下文件
然后我们打包两个文件夹
这时,文件夹下多了2个tar的文件,vmmon.tar和vmnet.tar
然后拷贝到 目录:
/usr/lib/vmware.modules.source
之后可以直接编译:
安装完成之后,再次打开vmware player就可以看到:
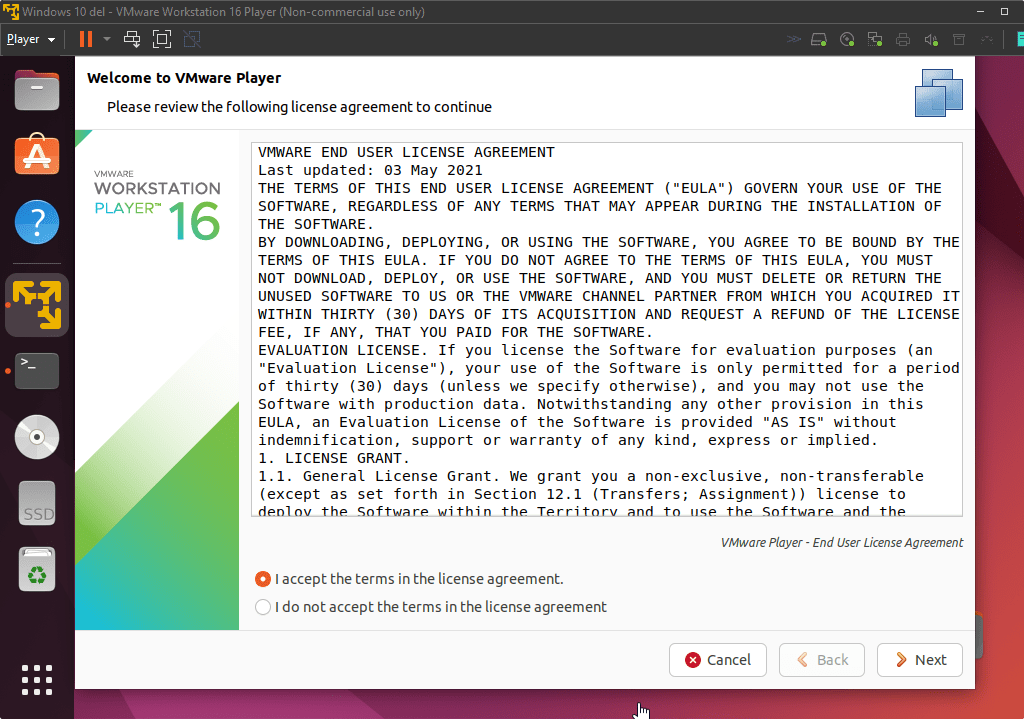
这样就是成功了。
收起阅读 »
Unable to install all modules. See log for details
ubuntu下的vmware play经常会让更新模块。一起点击确认就可以正常编译更新。
而且一定要编译后才能打开虚拟机系统
但是奇怪的是,最近一次点击 更新,报错:
显示的英文错误信息:
Unable to install all modules. See log for details
看了日志:
26 2022-07-15T02:15:09.595Z In(05) host-7426 /tmp/modconfig-PB4afO/vmmon-only/./include/vm_assert.h:372:22: note: in definition of macro ‘ASSERT_ON_COMPILE’
25 2022-07-15T02:15:09.595Z In(05) host-7426 372 | _Static_assert(e, #e); \
24 2022-07-15T02:15:09.595Z In(05) host-7426 | ^
23 2022-07-15T02:15:09.595Z In(05) host-7426 /tmp/modconfig-PB4afO/vmmon-only/./include/vm_asm_x86.h:215:7: note: in expansion of macro ‘ASSERT_ON_COMPILE_SELECTOR_SIZE’
22 2022-07-15T02:15:09.595Z In(05) host-7426 215 | ASSERT_ON_COMPILE_SELECTOR_SIZE(expr); \
21 2022-07-15T02:15:09.595Z In(05) host-7426 | ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
20 2022-07-15T02:15:09.595Z In(05) host-7426 /tmp/modconfig-PB4afO/vmmon-only/./include/vm_asm_x86.h:227:22: note: in expansion of macro ‘SET_SEGREG’
19 2022-07-15T02:15:09.595Z In(05) host-7426 227 | #define SET_GS(expr) SET_SEGREG(gs, expr)
18 2022-07-15T02:15:09.595Z In(05) host-7426 | ^~~~~~~~~~
17 2022-07-15T02:15:09.595Z In(05) host-7426 /tmp/modconfig-PB4afO/vmmon-only/common/task.c:2726:10: note: in expansion of macro ‘SET_GS’
16 2022-07-15T02:15:09.595Z In(05) host-7426 2726 | SET_GS(gs);
15 2022-07-15T02:15:09.595Z In(05) host-7426 | ^~~~~~
14 2022-07-15T02:15:09.595Z In(05) host-7426 make[2]: *** [scripts/Makefile.build:285: /tmp/modconfig-PB4afO/vmmon-only/common/task.o] Error 1
13 2022-07-15T02:15:09.595Z In(05) host-7426 make[2]: *** Waiting for unfinished jobs....
12 2022-07-15T02:15:09.595Z In(05) host-7426 make[1]: *** [Makefile:1875: /tmp/modconfig-PB4afO/vmmon-only] Error 2
11 2022-07-15T02:15:09.595Z In(05) host-7426 make: *** [Makefile:117: vmmon.ko] Error 2
10 2022-07-15T02:15:09.595Z In(05) host-7426 Using kernel build system.
9 2022-07-15T02:15:09.595Z In(05) host-7426 /tmp/modconfig-PB4afO/vmnet-only/driver.c: In function ‘VNetFileOpUnlockedIoctl’:
8 2022-07-15T02:15:09.595Z In(05) host-7426 /tmp/modconfig-PB4afO/vmnet-only/driver.c:966:7: warning: this statement may fall through [-Wimplicit-fallthrough=]
7 2022-07-15T02:15:09.595Z In(05) host-7426 966 | {
6 2022-07-15T02:15:09.595Z In(05) host-7426 | ^
5 2022-07-15T02:15:09.595Z In(05) host-7426 /tmp/modconfig-PB4afO/vmnet-only/driver.c:976:4: note: here
4 2022-07-15T02:15:09.595Z In(05) host-7426 976 | case SIOCGETAPIVERSION:
3 2022-07-15T02:15:09.595Z In(05) host-7426 | ^~~~
2 2022-07-15T02:15:09.595Z In(05) host-7426 Skipping BTF generation for /tmp/modconfig-PB4afO/vmnet-only/vmnet.ko due to unavailability of vmlinux
1 2022-07-15T02:15:09.595Z In(05) host-7426 Unable to install all modules. See log for details.
报错信息在这里:
host-7426 Skipping BTF generation for /tmp/modconfig-PB4afO/vmnet-only/vmnet.ko due to unavailability of vmlinux
host-7426 Unable to install all modules. See log for details
遇到问题后就google一番。
果然还是老外大神多。
翻了一个解决方案后,终于找到一个可行的。【所以必须的英语水平还是要的】
可行的方案:
去github下载最新的host-modules
https://github.com/mkubecek/vmware-host-modules
下载一个最新的。
然后解压:
unzip w16.2.3-k5.17.zip
得到以下文件
INSTALL
LICENSE
Makefile
README
vmmon-only
vmnet-only
然后我们打包两个文件夹
vmmon-only
vmnet-only
tar -cf vmmon.tar vmmon-only
tar -cf vmnet.tar vmnet-only
这时,文件夹下多了2个tar的文件,vmmon.tar和vmnet.tar
然后拷贝到 目录:
/usr/lib/vmware.modules.source
sudo cp -v vmmon.tar vmnet.tar /usr/lib/vmware/modules/source/
之后可以直接编译:
sudo vmware-modconfig --console --install-all
安装完成之后,再次打开vmware player就可以看到:
这样就是成功了。
收起阅读 »
linux监控shell进程是否运行,不运行的时候自动启动
脚本很简单。
保存为monitor.sh
给个执行权限
chmod +x monitor.sh
然后设置定时任务,
比如隔5分钟运行一次上面的脚本
*/5 * * * * monitor.sh
收起阅读 »
保存为monitor.sh
#!/bin/bash
line=$(ps -aux | grep -c /usr/sbin/ssh | grep -v "grep")
# 匹配的行数
if [ $line -eq 1 ];
then
sudo /etc/init.d/ssh restart
# 重启ssh服务
else
echo ssh is running....
# 向日志发送邮件,显示ssh运行中。。。
fi
给个执行权限
chmod +x monitor.sh
然后设置定时任务,
比如隔5分钟运行一次上面的脚本
*/5 * * * * monitor.sh
收起阅读 »







批量修改wordpress文章中的所有的链接
有时候你的文章中,某个地方的引用的链接失效了。需要你去替换一个新的链接。
假如只有2,3篇文章需要修改,那么就很简单,进入wordpress的后台进行修改。
但如果动辄几十篇,甚至上百上千篇文章,手动修改就工作量太大了,且容易出错。
那么可以选择后台数据库直接修改。
1. 先备份一下数据库,以防操作失误导致数据丢失。
2. 打开数据库软件,比如navicat
找到wp_post 这个表
运行下面的命令:
上面的sql命令就是把crop.png 的图片改为 resize.png 的图片的mysql命令。
修改万后,刷新一下缓存就可以了。 收起阅读 »
假如只有2,3篇文章需要修改,那么就很简单,进入wordpress的后台进行修改。
但如果动辄几十篇,甚至上百上千篇文章,手动修改就工作量太大了,且容易出错。
那么可以选择后台数据库直接修改。
1. 先备份一下数据库,以防操作失误导致数据丢失。
2. 打开数据库软件,比如navicat
找到wp_post 这个表
运行下面的命令:
UPDATE wp_posts set post_content = REPLACE(post_content,"crop.png","hxxy-resize.png") where post_content like '%crop.png%';
上面的sql命令就是把crop.png 的图片改为 resize.png 的图片的mysql命令。
修改万后,刷新一下缓存就可以了。 收起阅读 »
一创聚宽的实盘只支持每日开盘价和分钟交易
在一创的官网里面浏览到了一创上跑聚宽实盘的一些信息:
不支持虚拟机和xp系统,费率万2.5(这个实在要吐槽一下,太太太贵)
只支持股票和场内基金,不支持可转债。
只能跑一个策略。(额。。。无力吐槽)
执行周期最低的是分钟级别,没有秒级别。

其他量化平台实盘案例,可以参考本站其他文章。
收起阅读 »
1.交易佣金是多少?
A股万分之二点五,最低五元手续费;
货币类ETF买卖和申赎均无费用;
场内基金只能买卖不能申赎,交易费用根据客户交易佣金来定,有最低5元限制;
具体情况请联系一创咨询;
2.平台支持的交易频率是多少?
支持「每分」和「每天」两个交易频率
3.平台支持的交易品种有哪些?
目前支持A股、场内基金。
4.可以同时跑几个实盘策略?
目前每个用户可以运行1个实盘策略,需要更多权限请联系自己的客户经理申请。
5.其他问题如何咨询?
查看常见问题及实盘说明文档
点击聚宽官网的在线客服免费咨询
6.请问实盘支持哪些系统
请您使用win7、8、9、10系统和mac系统进行实盘账户的绑定操作。目前暂时不支持win xp等系统和虚拟机。
不支持虚拟机和xp系统,费率万2.5(这个实在要吐槽一下,太太太贵)
只支持股票和场内基金,不支持可转债。
只能跑一个策略。(额。。。无力吐槽)
执行周期最低的是分钟级别,没有秒级别。
其他量化平台实盘案例,可以参考本站其他文章。
收起阅读 »
ptrade的run_interval定时执行或者handle_data周期运行
在这几个函数里面打上标识,输出线程名字。

可以知道,他们是通过多线程触发的。 每一次运行的线程名字都不一样。
所以在里面操作一些共享变量的时候,最好加锁操作。
比如:
可以知道,他们是通过多线程触发的。 每一次运行的线程名字都不一样。
所以在里面操作一些共享变量的时候,最好加锁操作。
比如:
def query_offset(self,start,count):收起阅读 »
sqlite_str = 'select code,open,current from {} limit {},{}'.format(self.table_name,start,count)
cursor = self.db.cursor()
with lock:
try:
cursor.execute(sqlite_str)
except Exception as e:
log.info(e)
self.db.rollback()
else:
return cursor.fetchall()
aria2c 不能下载https的文件
下载命令:
aria2c https:// openresty.org/download/openresty-1.21.4.1-win64.zip
只要把https改为http就可以了。(前提是完整没有把http跳转到https)
aria2 http: //openresty.org/download/openresty-1.21.4.1-win64.zip
不过这个办法不是长久之计,要解决这个问题,需要你重新编译ariac2, 编译的时候添加 ssl参数就可以啦
进入ariac2的源码目录:
收起阅读 »
aria2c https:// openresty.org/download/openresty-1.21.4.1-win64.zip
$ aria2c
https: //openresty.org/download/openresty-1.21.4.1-win64.zip
07/10 10:58:58 [NOTICE] Downloading 1 item(s)
07/10 10:58:58 [ERROR] CUID#7 - Download aborted. URI=https: //openresty.org/download/openresty-1.21.4.1-win64.zip
Exception: [AbstractCommand.cc:351] errorCode=1 URI=https: //openresty.org/download/openresty-1.21.4.1-win64.zip
-> [InitiateConnectionCommandFactory.cc:87] errorCode=1 https is not supported yet.
07/10 10:58:58 [NOTICE] Download GID#b9bc95619990e7e4 not complete:
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
b9bc95|ERR | n/a|
https: //openresty.org/download/openresty-1.21.4.1-win64.zip
http: //openresty.org/download/openresty-1.21.4.1-win64.zip
Status Legend:
(ERR):error occurred.
aria2 will resume download if the transfer is restarted.
If there are any errors, then see the log file. See '-l' option in help/man page for details.
只要把https改为http就可以了。(前提是完整没有把http跳转到https)
aria2 http: //openresty.org/download/openresty-1.21.4.1-win64.zip
不过这个办法不是长久之计,要解决这个问题,需要你重新编译ariac2, 编译的时候添加 ssl参数就可以啦
进入ariac2的源码目录:
./configure --with-openssl接着:
make && sudo make install然后就可以啦
收起阅读 »
python sqlite3 多线程 批量写入 【代码】
1. 随机生成一个数组数据
2. 在多线程里面批量插入数据
几个关注点:
sqlite3.connect(_type, check_same_thread=False) 要设置为False
批量写的时候,记得要加锁
假如不加锁会出错:
收起阅读 »
2. 在多线程里面批量插入数据
几个关注点:
sqlite3.connect(_type, check_same_thread=False) 要设置为False
批量写的时候,记得要加锁
import datetime
import random
import sqlite3
import threading
import logging as log
import time
lock = threading.Lock()
class SQLiteDBCls:
def __init__(self, cache=True):
_type = ":memory:"
self.db = sqlite3.connect(_type, check_same_thread=False)
self.table_name = 'tick_data'
def create_index(self):
cmd = 'CREATE INDEX code_ix ON {} (current)'.format(self.table_name)
with lock:
try:
cursor = self.db.cursor()
cursor.execute(cmd)
except Exception as e:
log.info(e)
self.db.rollback()
else:
self.db.commit()
def create_table(self):
# cursor = self.db.cursor()
cmd = 'create table if not exists {} (id INTEGER PRIMARY KEY AUTOINCREMENT,code text,open double,current time)'.format(
self.table_name)
with lock:
try:
cursor = self.db.cursor()
cursor.execute(cmd)
except Exception as e:
log.info(e)
self.db.rollback()
else:
self.db.commit()
def add(self, code, price, t):
cmd = 'insert into {} (code,open,current) values (?,?,?);'.format(self.table_name)
with lock:
try:
cursor = self.db.cursor()
cursor.execute(cmd, (code, price, t))
except Exception as e:
log.info(e)
self.db.rollback()
else:
self.db.commit()
def batch_add(self, data):
# 批量加入
print('===========',threading.current_thread().getName())
# log.info(threading.current_thread().getName())
cmd = 'insert into {} (code,open,current) values (?,?,?)'.format(self.table_name)
with lock:
try:
cursor = self.db.cursor()
cursor.executemany(cmd, data)
except Exception as e:
log.info(e)
self.db.rollback()
else:
self.db.commit()
def result(self):
cmd = 'select count(*) from `{}`'.format(self.table_name)
with lock:
try:
cursor = self.db.cursor()
cursor.execute(cmd)
except Exception as e:
log.info(e)
self.db.rollback()
else:
return cursor.fetchone()
def data_gen():
minute = 6000
code = ['123011.SS','110010.SS','112111.SS']
for i in range(minute):
current = (datetime.datetime.now()+datetime.timedelta(minutes=i)).strftime('%H:%M:%D')
data_list =
for c in code:
price = 5+random.random()+120
data = (c,price,current)
data_list.append(data)
yield data_list
# time.sleep(0.5)
app = SQLiteDBCls(cache=True)
app.create_table()
app.create_index()
def data_validation():
print(app.result())
app.sync_up()
def multithread_mode():
total_count = 0
thread_list =
for d in data_gen():
print(d)
total_count+=len(d)
# app.batch_add(d)
t=threading.Thread(target=app.batch_add,args=(d,))
thread_list.append(t)
for t in thread_list:
t.start()
for t in thread_list:
t.join()
print(total_count)
if __name__=='__main__':
multithread_mode()
data_validation()
假如不加锁会出错:
File "/home/xda/miniconda3/envs/cpy/lib/python3.9/threading.py", line 910, in run
self._target(*self._args, **self._kwargs)
File "/home/xda/github/stock_strategy/sqlite_issue_debug.py", line 77, in batch_add
self.db.commit()
Exception in thread Thread-3824:
Exception in thread Thread-3826:
Traceback (most recent call last):
File "/home/xda/miniconda3/envs/cpy/lib/python3.9/threading.py", line 973, in _bootstrap_inner
sqlite3.OperationalError: cannot commit - no transaction is activeTraceback (most recent call last):
File "/home/xda/github/stock_strategy/sqlite_issue_debug.py", line 72, in batch_add
cursor.executemany(cmd, data)
sqlite3.InterfaceError: Error binding parameter 0 - probably unsupported type.
收起阅读 »
低门槛开通量化交易接口Ptrade QMT (入金1万即可,AA级大券商)
(如果按证监会对证券公司的分类结果,(98家券商中,AA级只有15家,没有AAA级),算是头部券商,具备一定的实力)
该券商为AA级券商,GJ证券,腾讯入股的A股券商
该券商营业部最近对量化交易软件推广期,对开通门槛做了大幅降低, 目前只需要入金1W,既可以开通量化交易接口与软件,有Ptrade和QMT两个。 二者支持python语言编写策略,支持tick,分钟线,日线,等级别的实盘交易。
点击查看大图
Ptrade为云端部署,QMT为本地部署(你的策略只会放着本地,使用本地python运行)

点击查看大图
该QMT支持虚拟机内运行,也就是可以在云主机(腾讯云,阿里云这些服务器上)运行。
QMT

点击查看大图
目前开通门槛低,时间有限,需要的朋友抓紧时间开通,过了这个时间就没有下次机会了。
交易费率: 量化没有流量费。(针对该营业部开户用户)
股票万一
可转债(新规) 沪:十万分之四点四,深:十万分之四
基金:万0.5
没有流量费
需要的朋友可以加微信咨询开通:备注 一万量化开户 (否则不通过或者没有低门槛介绍)
 收起阅读 »
收起阅读 »
该券商为AA级券商,GJ证券,腾讯入股的A股券商
该券商营业部最近对量化交易软件推广期,对开通门槛做了大幅降低, 目前只需要入金1W,既可以开通量化交易接口与软件,有Ptrade和QMT两个。 二者支持python语言编写策略,支持tick,分钟线,日线,等级别的实盘交易。
点击查看大图
Ptrade为云端部署,QMT为本地部署(你的策略只会放着本地,使用本地python运行)
点击查看大图
该QMT支持虚拟机内运行,也就是可以在云主机(腾讯云,阿里云这些服务器上)运行。
QMT
点击查看大图
目前开通门槛低,时间有限,需要的朋友抓紧时间开通,过了这个时间就没有下次机会了。
交易费率: 量化没有流量费。(针对该营业部开户用户)
股票万一
可转债(新规) 沪:十万分之四点四,深:十万分之四
基金:万0.5
没有流量费
需要的朋友可以加微信咨询开通:备注 一万量化开户 (否则不通过或者没有低门槛介绍)
收起阅读 »
重启ptrade策略会重新载入修改的代码吗?
会的。

这个是方便你修改了代码,不用重新新建策略,重启一下,原来旧代码就会被覆盖的。
这个是方便你修改了代码,不用重新新建策略,重启一下,原来旧代码就会被覆盖的。
qmt如何获取高频数据(大于3秒间隔的行情)
对于可转债日内交易的朋友,喜欢追涨杀跌。
可转债天生T+0, 适合使用量化工具进行操作,速度快,下单稳,快。
对于qmt而言,可以设置定时器,run_time.

你可以设置1毫秒执行一次,笔者也试过,贼快。 然后你就打算在间隔1毫秒里面获取行情,你就可以获取近乎实时的行情数据了吗? 注意,拿实时行情数据使用
想多了。
即使你设置1毫秒,而行情数据更新是3s更新一次,你在3s的间隔内,无论你用多高的频率获取,拿到的数据还是一个快照,3秒的快照。
也就是一般的操作,是无法突破快于3秒的行情。
那么如何突破呢。
使用订阅行情配合L2数据即可。
不过不一定所有的券商都支持L2数据。而且需要费用开通。
实际外面很多tushare,akshare数据源,他们的时间更新间隔也是大于3s的。 而集思录的数据源更新速度更慢,之前测试过,大约6s。
那么使用订阅行情如何获取快于3s的数据呢?
待续,持续更新ing。。。。

收起阅读 »
可转债天生T+0, 适合使用量化工具进行操作,速度快,下单稳,快。
对于qmt而言,可以设置定时器,run_time.
你可以设置1毫秒执行一次,笔者也试过,贼快。 然后你就打算在间隔1毫秒里面获取行情,你就可以获取近乎实时的行情数据了吗? 注意,拿实时行情数据使用
获取分笔数据 ContextInfo.get_full_tick()这个函数。
想多了。
即使你设置1毫秒,而行情数据更新是3s更新一次,你在3s的间隔内,无论你用多高的频率获取,拿到的数据还是一个快照,3秒的快照。
也就是一般的操作,是无法突破快于3秒的行情。
那么如何突破呢。
使用订阅行情配合L2数据即可。
不过不一定所有的券商都支持L2数据。而且需要费用开通。
实际外面很多tushare,akshare数据源,他们的时间更新间隔也是大于3s的。 而集思录的数据源更新速度更慢,之前测试过,大约6s。
那么使用订阅行情如何获取快于3s的数据呢?
待续,持续更新ing。。。。
收起阅读 »






获取可转债历史分时tick数据 【python】
可转债的历史分时tick数据,基本在很多大平台,优矿,聚宽,米宽等平台都没有提供。
对于想做日内回测的朋友,是一件很痛苦的事情。
那么,接下来,本文结束一种通过第三方平台的数据,来把可转债的分时tick数据获取下来,并保存到本地数据库。
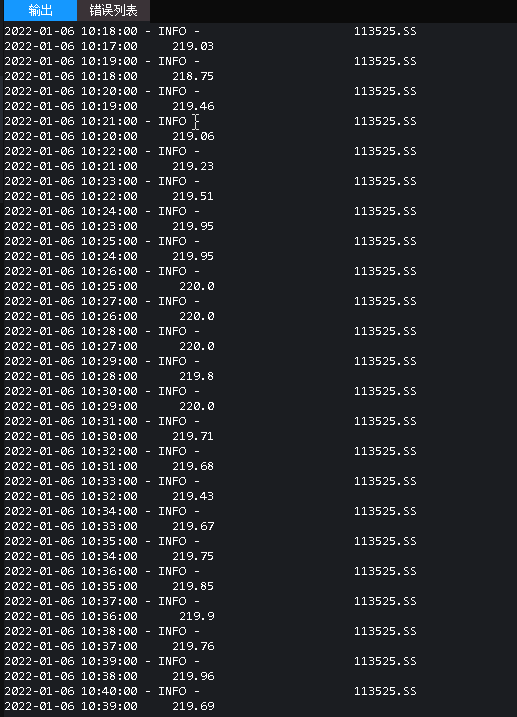
2022-07-05 更新:
如果直接拿历史数据,可以拿到1分钟级别的数据,如上图所示。
如果要拿秒级别的,需要实时采集。
笔者使用sqlite做为内存缓存,盘后统一入到mysql中。

如果盘中每隔3秒使用mysql储存,显然会造成不必要的io阻塞(开个线程存数据也是一个方案)。
使用sqlite的时候,设置为memeory模式,速度比存文件要快很多倍。
待续 收起阅读 »
对于想做日内回测的朋友,是一件很痛苦的事情。
那么,接下来,本文结束一种通过第三方平台的数据,来把可转债的分时tick数据获取下来,并保存到本地数据库。
2022-07-05 更新:
如果直接拿历史数据,可以拿到1分钟级别的数据,如上图所示。
如果要拿秒级别的,需要实时采集。
笔者使用sqlite做为内存缓存,盘后统一入到mysql中。
如果盘中每隔3秒使用mysql储存,显然会造成不必要的io阻塞(开个线程存数据也是一个方案)。
使用sqlite的时候,设置为memeory模式,速度比存文件要快很多倍。
待续 收起阅读 »
最近几天的有道云笔记保存的笔记全部丢失了
狗日了。网易越来越拉跨了。
最近几天记录了几篇笔记,基本全部都不见了,最新日期的还是6月17日的。中间这几天保存的笔记被狗吃了。
搜索功能也越做越垃圾,建议用一个 云文件同步+typora 做笔记就可以。
最近几天记录了几篇笔记,基本全部都不见了,最新日期的还是6月17日的。中间这几天保存的笔记被狗吃了。
搜索功能也越做越垃圾,建议用一个 云文件同步+typora 做笔记就可以。
golang 插入redis 集合,并判断元素是否存在
代码如下:
1. "server/service" 是当前的报名
2. 用的go-redis这个库
判断元素是否在集合中:
conn.SIsMember("User", sign).Result()
完整代码:
github地址:
https://github.com/Rockyzsu/BondInfoServer.git
收起阅读 »
1. "server/service" 是当前的报名
2. 用的go-redis这个库
判断元素是否在集合中:
conn.SIsMember("User", sign).Result()
完整代码:
package cache
import (
"server/service"
"fmt"
"github.com/go-redis/redis"
)
type Cache struct {
conn *redis.Client
}
func (this *Cache) CacheInit() {
this.connect()
}
func (this *Cache) connect() {
conf := service.ReadRedisConfig()
this.conn = redis.NewClient(&redis.Options{
Addr: conf.Addr,
Password: conf.Password,
DB: conf.DB,
})
}
func (this *Cache) Get(id string) (string, bool) {
result, err := this.conn.Get(id).Result()
if err != nil {
fmt.Println(err)
return "", false
}
return result, true
}
func (this *Cache) Set(id string, content string) bool {
_, err := this.conn.Set(id, content, 0).Result()
if err != nil {
fmt.Println(err)
return false
} else {
return true
}
}
func (this *Cache) CheckUserExist(sign string) bool {
result, err := this.conn.SIsMember("User", sign).Result()
if err != nil {
fmt.Println(err)
return false
}
return result
}
func (this *Cache) AddUser(name string) bool {
_, err := this.conn.SAdd("User", name).Result()
if err != nil {
fmt.Println(err)
return false
} else {
return true
}
}
github地址:
https://github.com/Rockyzsu/BondInfoServer.git
收起阅读 »
可转债交易新规什么时候实施,利好股市
上交所发布关于可转换公司债券适当性管理相关事项的通知,个人投资者参与向不特定对象发行的可转债申购、交易,应当同时符合下列条件:申请权限开通前20个交易日证券账户及资金账户内的资产日均不低于人民币10万元(不包括该投资者通过融资融券融入的资金和证券);参与证券交易24个月以上。
昨天才看到可转债投资新规 今日和券商确认就已落地实施了(6.18日前开户的不受影响)来势汹汹,没有任何时间缓冲

但如果已满2年交易年限的老铁们,现在还有如下最低可转债费率(新规),需要的赶紧,
即使可转债降温,那又将利好股票,需要股票万一免五的也赶紧,不然又不知道哪天新规突然杀到,再想要也没有了
广发可转债:沪十万分之4.1,深十万分之4.1
银河股票:万一免五 ;可转债:沪十万分之5,深十万分之5
需要开户请扫码联系,备注:开户

收起阅读 »

Ptrade内置的第三方库查看
通过import pip查看到的Ptrade第三方库列表:
由于内置了pymysql,所以可以直接读取你的数据库内容。这个需要你的ptrade具有连接外网功能才可以。
注:据个人经验,券商的开发能力约等于0,所以这一行为是恒生电子开放的,并非券商所为,券商并没有这么强的魔改能力,或者不敢做一些大的改动。
需要开通Ptrade的投资者可以联系微信:
股票费率万一免五
收起阅读 »
APScheduler (3.3.1)
arch (3.2)
bcolz (1.2.1)
beautifulsoup4 (4.6.0)
bleach (1.5.0)
boto (2.43.0)
Bottleneck (1.0.0)
bz2file (0.98)
cachetools (3.1.0)
click (4.0)
contextlib2 (0.4.0)
crypto (1.4.1)
cvxopt (1.1.8)
cx-Oracle (8.0.1)
cycler (0.10.0)
cyordereddict (0.2.2)
Cython (0.22.1)
decorator (4.0.10)
entrypoints (0.2.2)
fastcache (1.0.2)
gensim (0.13.3)
h5py (2.6.0)
hmmlearn (0.2.0)
hs-udata (0.3.6)
html5lib (0.9999999)
ipykernel (4.5.0)
ipython (5.1.0)
ipython-genutils (0.1.0)
ipywidgets (5.2.2)
jieba (0.38)
Jinja2 (2.8)
jsonpickle (1.0)
jsonschema (2.5.1)
jupyter (1.0.0)
jupyter-client (4.4.0)
jupyter-console (5.0.0)
jupyter-core (4.2.0)
jupyter-kernel-gateway (1.1.1)
Keras (2.3.1)
Keras-Applications (1.0.8)
Keras-Preprocessing (1.1.0)
line-profiler (2.1.2)
Logbook (1.4.3)
lxml (4.5.0)
Markdown (2.2.0)
MarkupSafe (0.23)
matplotlib (1.5.3)
mistune (0.7.3)
Naked (0.1.31)
nbconvert (4.2.0)
nbformat (4.1.0)
networkx (1.9.1)
nose (1.3.6)
notebook (4.2.3)
numexpr (2.6.1)
numpy (1.11.2)
pandas (0.23.4)
patsy (0.4.0)
pexpect (4.2.1)
pickleshare (0.7.4)
pip (9.0.1)
pkgconfig (1.0.0)
prompt-toolkit (1.0.8)
protobuf (3.3.0)
ptvsd (2.2.0)
ptyprocess (0.5.1)
PyBrain (0.3)
pycrypto (2.6.1)
Pygments (2.1.3)
PyMySQL (0.9.3)
pyparsing (2.1.10)
python-dateutil (2.7.5)
pytz (2015.4)
PyWavelets (0.4.0)
PyYAML (5.3.1)
pyzmq (16.1.0.dev0)
qtconsole (4.2.1)
requests (2.7.0)
retrying (1.3.3)
scikit-learn (0.18)
scipy (0.18.0)
seaborn (0.7.1)
setuptools (28.7.1)
setuptools-scm (3.1.0)
shellescape (3.4.1)
simplegeneric (0.8.1)
simplejson (3.17.0)
six (1.10.0)
sklearn (0.0)
smart-open (1.3.5)
SQLAlchemy (1.0.8)
statsmodels (0.10.2)
TA-Lib (0.4.10)
tables (3.3.0)
tabulate (0.7.5)
tensorflow (1.3.0rc1)
tensorflow-tensorboard (0.1.2)
terminado (0.6)
Theano (0.8.2)
toolz (0.7.4)
tornado (4.4.2)
traitlets (4.3.1)
tushare (1.2.48)
tzlocal (1.3)
wcwidth (0.1.7)
Werkzeug (0.12.2)
wheel (0.29.0)
widgetsnbextension (1.2.6)
xcsc-tushare (1.0.0)
xgboost (0.6a2)
xlrd (1.1.0)
xlwt (1.3.0)
zipline (0.8.3)
You are using pip version 9.0.1, however version 22.1.2 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
由于内置了pymysql,所以可以直接读取你的数据库内容。这个需要你的ptrade具有连接外网功能才可以。
注:据个人经验,券商的开发能力约等于0,所以这一行为是恒生电子开放的,并非券商所为,券商并没有这么强的魔改能力,或者不敢做一些大的改动。
需要开通Ptrade的投资者可以联系微信:
股票费率万一免五
收起阅读 »
在中国网络环境下获取Golang.org上的Golang Packages
在中国网络环境下获取Golang.org上的Golang Packages
背景
目前在中国网络环境下无法访问Golang.org。
问题
不能运行go get golang.org/x/XX来获取Golang packages。
解决方案收起阅读 »
方案 A: 使用github 上的镜像
获取Golang Package在github镜像上的路径: golang.org/x/PATH_TO_PACKAGE --> github.com/golang/PATH_TO_PACKAGE.
// Ex:
golang.org/x/net/context --> github.com/golang/net/context
运行go get来安装github镜像的Golang packages。
// Ex:
go get github.com/golang/net/context
你会碰到如下错误提示:
package github.com/golang/net/context:
code in directory /go/src/github.com/golang/net/context
expects import "golang.org/x/net/context"
忽略错误。 Golang的Package的源代码已经成功下载于:
$GOPATH/src/github.com/golang/PATH_TO_PACKAGE.
复制 $GOPATH/src/github.com/golang/PATH_TO_PACKAGE 到 $GOPATH/src/golang.org/x/PATH_TO_PACKAGE.
// Ex:
mkdir $GOPATH/src/golang.org/x -p
cp $GOPATH/src/github.com/golang/net $GOPATH/src/golang.org/x/ -rf
运行 go build 来编译。
方案 B: 使用第三方网站 - https://gopm.io/download
输入包路径即可下载zip文件。



linux下好用的git gui工具 推荐!
之前写过一篇免费版的kranken
ubuntu下最好的图形git管理工具kranken (免费版本)
用了一个月之后,发现免费版不支持私有仓库,这。。。。。
那自己的私有仓库还得专门找软件管理。
突然看到ubuntu下平时用的不多的vs code,发现里面git的插件可真多。
把最多星的git相关插件装上后,它的功能基本大部分都可以覆盖了95%kraken的可视化功能了!


收起阅读 »
ubuntu下最好的图形git管理工具kranken (免费版本)
用了一个月之后,发现免费版不支持私有仓库,这。。。。。
那自己的私有仓库还得专门找软件管理。
突然看到ubuntu下平时用的不多的vs code,发现里面git的插件可真多。
把最多星的git相关插件装上后,它的功能基本大部分都可以覆盖了95%kraken的可视化功能了!
收起阅读 »
Ptrade可以连接外网了!
现在用的券商的Ptrade居然可以连接外网了,早期券商为了安全保密,把访问外网的权限给封了,但是后面吐槽的人太多了。 现在这个功能不再加以限制。

测试代码:
代码复制到回测那里,然后点击回测就可以看到结果了。
这下可以把之前的qmt的接口 搬到ptrade。 比如集思录接口,tushare接口,宁稳的接口,太多了。
笔者用的ptrade是国盛证券的,亲测可用~
PS:Ptrade是运行在券商机房,下单速度还是行情获取,都要比本地的qmt要快。且稳定,至少你家里断电断网的概率比人家机房断电断网的概率要大得多。
需要开通的投资者可以联系微信:
股票费率万一免五
备注:Ptrade 收起阅读 »
测试代码:
import requests
def initialize(context):
# 初始化策略
g.security = "600570.SS"
set_universe(g.security)
def handle_data(context, data):
url='http://www.baidu.com'
headers={'User-Agent':'Google'}
try:
r=requests.get(url,headers=headers)
r.encoding='utf8'
print(r.text)
except Exception as e:
print('error')
print(e)
代码复制到回测那里,然后点击回测就可以看到结果了。
这下可以把之前的qmt的接口 搬到ptrade。 比如集思录接口,tushare接口,宁稳的接口,太多了。
笔者用的ptrade是国盛证券的,亲测可用~
PS:Ptrade是运行在券商机房,下单速度还是行情获取,都要比本地的qmt要快。且稳定,至少你家里断电断网的概率比人家机房断电断网的概率要大得多。
需要开通的投资者可以联系微信:
股票费率万一免五
备注:Ptrade 收起阅读 »
腾讯云上的rshim进程是什么作用
这个应用一直开者,而且还杀不死。
kill -9 pid
之后又会重新启动一个新的进程。 看着就像病毒或者木马的特征。
而且百度出来的结果都是csdn式的抄袭:

问了腾讯云的技术人员,居然他们也不知道是什么。
因为笔者的3台腾讯云的轻量服务器都有这个进程:


因为占用的CPU不高,所以笔者认为这个不是病毒。
然后google了一下:

这才发现,这个只是linux底层的一个驱动。
kill -9 pid
之后又会重新启动一个新的进程。 看着就像病毒或者木马的特征。
而且百度出来的结果都是csdn式的抄袭:
问了腾讯云的技术人员,居然他们也不知道是什么。
因为笔者的3台腾讯云的轻量服务器都有这个进程:
因为占用的CPU不高,所以笔者认为这个不是病毒。
然后google了一下:
这才发现,这个只是linux底层的一个驱动。
The rshim driver provides a way to access the rshim resources on the BlueField target from external host machine收起阅读 »
golang gin ajax post 前端与后端的正确写法
比较常用的场景,记录一下:
前端是一个页面html页面
效果大体上这样的:

有几个按钮,然后每个按钮绑定一个点击事件
submitBTN.onclick = function (event) {
.....
同上面代码
然后在代码里面执行post操作,使用的是ajax封装的方法:
注意,contentType用下面的:
还有不要把
写完前端之后,就去后端
路由方法:
绑定上面的url update-site1
然后就是实现
controllers.BaiduSite1 这个方法:
获取ajax里面的字段,
使用:context 中的PostForm方法
剩下的就是一些常规的操作方法
最后需要设置json的返回数据
完整代码可以到公众号里面获取:

收起阅读 »
前端是一个页面html页面
<script type="text/javascript">
var submitBTN = document.getElementById("url_update");
submitBTN.onclick = function (event) {
// 注意这里是 onclick 函数
console.log("click");
$.ajax({
url: "/update-site1",
type: "POST",
data: {value:1},
cache: false,
contentType: "application/x-www-form-urlencoded",
success: function (data) {
console.log(data);
if (data.code !== 0) {
alert('更新失败')
} else {
new_str = data.res + " " + data.count
$("#txt_content").val(new_str);
alert('更新资源成功!')
}
},
fail: function (data) {
alert("更新失败!");
}
});
$.ajax({
url: "/update-site1",
type: "POST",
data: {value:2},
cache: false,
contentType: "application/x-www-form-urlencoded",
success: function (data) {
console.log(data);
if (data.code !== 0) {
alert('更新失败')
} else {
new_str = data.res + " " + data.count
$("#txt_content").val(new_str);
alert('更新资源成功!')
}
},
fail: function (data) {
alert("更新失败!");
}
})
}
</script>
效果大体上这样的:
有几个按钮,然后每个按钮绑定一个点击事件
submitBTN.onclick = function (event) {
.....
同上面代码
然后在代码里面执行post操作,使用的是ajax封装的方法:
注意,contentType用下面的:
contentType: "application/x-www-form-urlencoded",
还有不要把
processData: false,这个设置为false,否则gin的后端解析不到数据
写完前端之后,就去后端
路由方法:
绑定上面的url update-site1
router.POST("/update-site1", controllers.BaiduSite1)然后就是实现
controllers.BaiduSite1 这个方法:
func BaiduSite1(ctx *gin.Context) {
if ctx.Request.Method == "POST" {
value := ctx.PostForm("value")
fmt.Println(value)
int_value, err := strconv.Atoi(value)
if err != nil {
ctx.JSON(http.StatusOK, gin.H{
"code": 1,
"res": "",
"count": 0,
})
return
}
res, count := webmaster.PushProcess(1, int_value)
ctx.JSON(http.StatusOK, gin.H{
"code": 0,
"res": res,
"count": count,
})
}
}获取ajax里面的字段,
使用:context 中的PostForm方法
value := ctx.PostForm("value")剩下的就是一些常规的操作方法
最后需要设置json的返回数据
ctx.JSON(http.StatusOK, gin.H{
"code": 0,
"res": res,
"count": count,
完整代码可以到公众号里面获取:
收起阅读 »

