
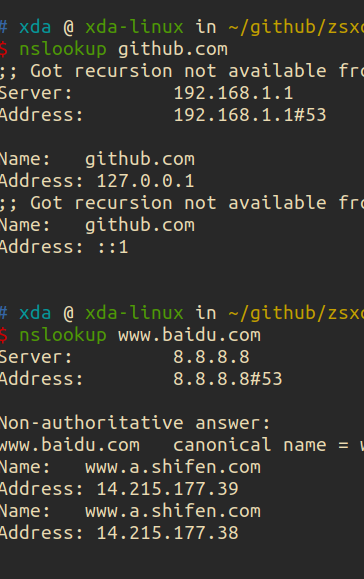
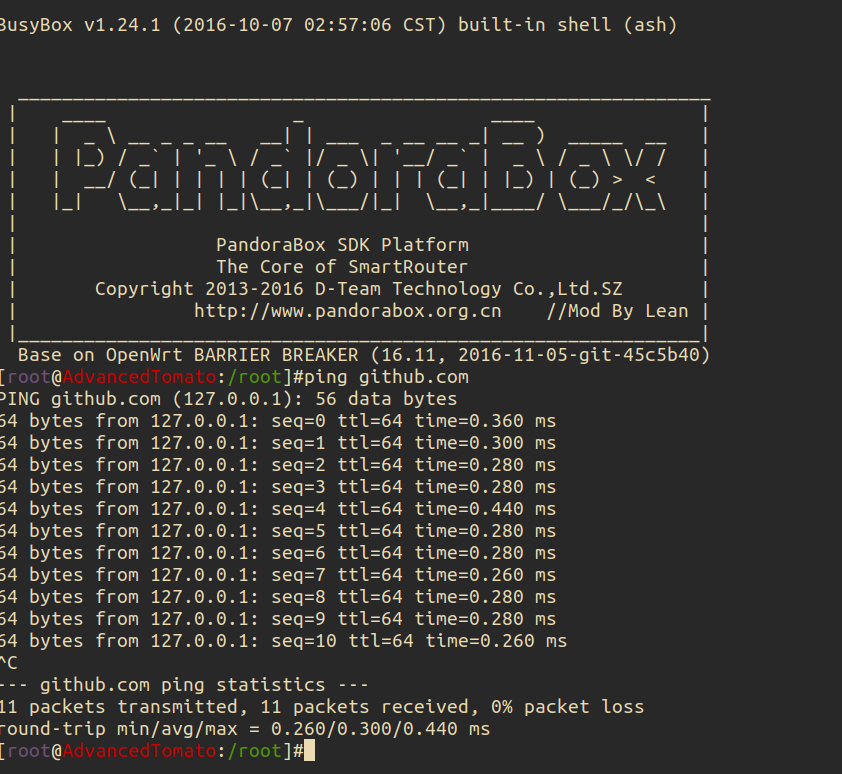
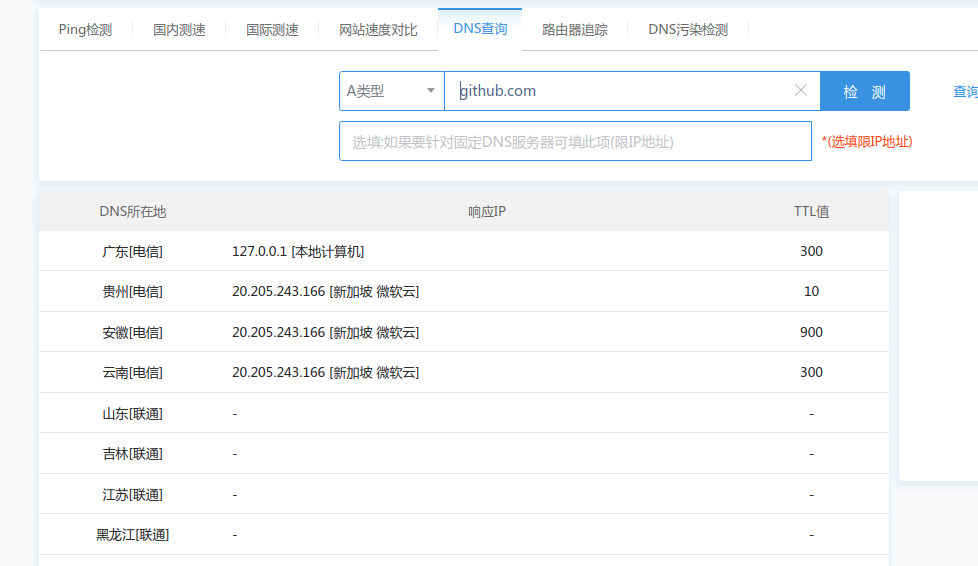
轻量服务器原来都只是一个docker出来给你的应用
一句话总结:轻量云服务器就是跑的 docker 镜像,所以当然卖的便宜。
之前的服务器好歹还给你弄个虚拟机,现在就是一个进程隔离而已,CPU 跑到 100%一段时间以后就开始失去响应了,没有强制进程调度,跑重负载肯定是不行的,所以叫:“轻量”,诚不欺我也……
之前的服务器好歹还给你弄个虚拟机,现在就是一个进程隔离而已,CPU 跑到 100%一段时间以后就开始失去响应了,没有强制进程调度,跑重负载肯定是不行的,所以叫:“轻量”,诚不欺我也……
python安装demjson报错:error in setup command: use_2to3 is invalid.
原因:在setuptools 58之后的版本已经废弃了use_2to3所以安装一个旧版本的setuptools就可以了
随便整一个
pip install setuptools==57.5.0


ubuntu用非root用户 无法启用80端口web服务
需求 conda python
默认情况下,1024以下的端口,只有root用户可以使用,例如想用python3启动一个在80端口上的web服务,只能切换到root用户再启动。如果想不用root用户启动,怎么办呢?
解决办法
记录一种测试了的办法:
Linux 内核从 2.6.24 版本开始就有了能力的概念,这使得普通用户也能够做只有超级用户才能完成的工作。
使用 setcap 命令让指定程序拥有绑定端口的能力,这样即使程序运行在普通用户下,也能够绑定到 1024 以下的特权端口上。
# 给指定程序设置 CAP_NET_BIND_SERVICE 能力
$ sudo setcap cap_net_bind_service=+eip /home/xda/miniconda3/bin/python3.9
注意赋给的程序目标不能是软链接
注意 conda的python一般都是软链接
比如:
/home/xda/miniconda3/bin/python
很可能是指向
/home/xda/miniconda3/bin/python3.9的
如果使用的python路径
/home/xda/miniconda3/bin/python
给
setcap cap_net_bind_service=+eip
会报错的。 收起阅读 »
强赎日期计数 excel文件


代码 名称 当前满足天数 强赎目标数 周期 以公告
113568 新春转债 已公告强赎
127043 川恒转债 暂不强赎
123086 海兰转债 暂不强赎
113548 石英转债 暂不强赎
128107 交科转债 已公告强赎
110071 湖盐转债 12 15 30
128111 中矿转债 暂不强赎
127013 创维转债 14 15 30
123092 天壕转债 暂不强赎
128046 利尔转债 19 20 30
127027 靖远转债 暂不强赎
113541 荣晟转债 公告要强赎
123085 万顺转2 暂不强赎
123083 朗新转债 12 15 30
128128 齐翔转2 暂不强赎
128106 华统转债 暂不强赎
113537 文灿转债 暂不强赎
128095 恩捷转债 已满足强赎条件
127007 湖广转债 暂不强赎
123012 万顺转债 暂不强赎
123057 美联转债 暂不强赎
113585 寿仙转债 暂不强赎
110061 川投转债 暂不强赎
113626 伯特转债 暂不强赎
113025 明泰转债 暂不强赎
123078 飞凯转债 暂不强赎
113567 君禾转债 暂不强赎
128017 金禾转债 暂不强赎
128040 华通转债 暂不强赎
128029 太阳转债 暂不强赎
123073 同和转债 暂不强赎
110055 伊力转债 暂不强赎
113525 台华转债 暂不强赎
123060 苏试转债 暂不强赎
127038 国微转债 暂不强赎
123046 天铁转债 暂不强赎
123098 一品转债 暂不强赎
110074 精达转债 暂不强赎
123114 三角转债 暂不强赎
113051 节能转债 暂不强赎
128140 润建转债 暂不强赎
123071 天能转债 暂不强赎
113027 华钰转债 暂不强赎
128091 新天转债 暂不强赎
128085 鸿达转债 暂不强赎
113620 傲农转债 暂不强赎
123052 飞鹿转债 暂不强赎
118000 嘉元转债 暂不强赎
128082 华锋转债 暂不强赎
128109 楚江转债 暂不强赎
113016 小康转债 暂不强赎
123027 蓝晓转债 暂不强赎
128137 洁美转债 暂不强赎
128101 联创转债 暂不强赎
123031 晶瑞转债 暂不强赎
128078 太极转债 暂不强赎
128030 天康转债 暂不强赎
123034 通光转债 暂不强赎
excel原文件:
http://xximg.30daydo.com/webupload/2022-06-04-redeem-info.xlsx
或者关注公众号:可转债量化分析
后台回复:
强赎20220604 收起阅读 »












百度seo 索引量下降后如何自查
1、会不会是网站被黑客攻击后增加了大量垃圾网页
2、会不会是Robost协议出了问题,导致大批保密页面被百度抓取
3、大幅增加的url会不会占用有限的抓取配额,导致重要优质内容未被抓取

如果是因为百度误判,可以对其进行申诉
收起阅读 »
2、会不会是Robost协议出了问题,导致大批保密页面被百度抓取
3、大幅增加的url会不会占用有限的抓取配额,导致重要优质内容未被抓取
如果是因为百度误判,可以对其进行申诉
关于申诉,除了再一次播报申诉地址(http://ziyuan.baidu.com/feedback)外,我们给各位站长提个醒,在撰写申诉内容时应该尽量将问题描述具体,引用SEO爱好者痞子瑞的经验:“网站索引量异常,可以使用百度搜索资源平台(原百度站长平台)的索引量查询工具,一级一级的遍历一下自己网站的主要子域名或目录,以确定到底是哪个子域名或目录的索引量出现了异常。”“每个频道选取一些页面,在百度网页搜索中直接搜索这样页面的URL,以定位被删除快照网页的最小范围。”“然后在投诉内容中明确给出“病体”的URL,并附上相应的数据变动截图。”这样才便于处理投诉的百度工作人员快速寻找问题症结。
收起阅读 »
数字藏品NFT 的常见术语 入门必备
随着NFT的大火,入局NFT的人群基数迅速增加。许多人有了新身份,成为了“NFT藏家“。但同时也出现了一个尴尬的问题——NFT的行话让许多小白玩家一头雾水。本来是为了找到组织寻求帮助而加入社群的小白玩家,却完全看不懂大家的聊天内容,老藏家们的聊天不是一句话带3个英文缩写,就是充满看得懂的中文字连起来却读不懂的词语。
你和NFT老藏家的距离就像是“魔法师”和“麻瓜”之间的差距,那么接下来的20个术语,
一、基础平台和应用软件
1. OS:
Opensea的简称,国际NFT交易平台,是目前全球最多用户使用,市场份额占比最高,交易量最大的NFT交易平台。
2. DC
Discord的简称,功能强大的社群通讯软件。目前绝大部分NFT项目的社群聚集地,项目方通常在DC发布重要通道,进社群推广等等。也是目前许多自发NFT社群的根据地。
3. MetaMask (狐狸钱包):
以太坊生态系统中最受欢迎,用户数量最大的NFT钱包。
二、入门级必备术语
1. White List (白名单):
简称WL,也就是NFT项目的白名单。拥有白名单可以在项目公开发售前提前购买NFT,不用和大批人比网速比手速。尤其是在目前大火项目二级市场价格都偏高,而首发作品都处于上架秒空的情况下,白名单可以是“拿到即赚到”。
2. Blue Chips (蓝筹项目):
原指赌场上的蓝色筹码(赌场桌上最基础的筹码组合是1美元的白色筹码、5美元的红色筹码和25美元的蓝色筹码),蓝色筹码为最具有价值的筹码。延伸到蓝筹项目就是指有价值、建议长期持有的优质NFT。
3. Airdrop (空投):
你的钱包会免费收到一个NFT。目前空投被项目方广泛用来激励长期持有者,在国内大多用“转赠”来代替“空投”用法。
4. Mint(铸造) :
翻译成中文,做名词有薄荷的意思,做动词则是铸造。也就是生成NFT的过程,某一个NFT项目的首次铸造。
5. Gas Fee (燃料费):
燃料费, 也可理解成手续费。从技术层面来说,区块链的每一个节点都是需要维护的,而在以太坊中的每笔交易都需要“矿工们”帮你完成,而你则要支付一定的报酬给矿工们。在海外你需要使用eth等虚拟货币进行支付,而在国内则支持RMB支付。因而Gas Fee 也称作“矿工费”。
6. DAO
Decentralized Autonomous Organization的首字母缩写,也就是“去中心化自治组织”。目前多数NFT项目方都会有自己的DAO, 当你持有该项目的NFT时你就有资质成为DAO成员,DAO群成员拥有对该项目未来发展整体方向的治理权。通过DAO,项目方可以凝聚社群,从而提升项目的发展长驱动力。
7. Roadmap(路线图):
路线图,专门指某个NFT项目计划为社群增加价值而进行的一系列活动。路线图目前已经成为许多藏家入手新项目之前必须考察的一点,一个NFT项目是否拥有路线图在一定程度上决定了该项目的规划能力以及运营能力。
8. Floor Price (地板价):
地板价,指某一NFT项目在交易市场中的最低入手价格,Floor Price的价格越高,代表该NFT项目的整体价格走向明朗。抄底也是指在该项目处于Floor Price的时候大量购入,等待其后续的爆发时机。
三、进阶级术语
1. 10k project
指由约10000个头像组成的NFT项目,10k project 以Bored Ape Yacht Club 以及 Croptofunks 为代表。但值得注意的是,这里的10k并不是固定的,该术语仅指代这一类型的头像合集,并未规定10k 的具体数量。
2. PFP
PFP在不同的行业有着不同的含义,在NFT界的PFP特指[Profile Picture],也就是“个人资料图片”。不少10 projet 都是PFP项目,比如库里购入了Cryptofunk,并将它用作自己社交媒体的头像。目前,PFP仍然广收藏家的欢迎,拥有一个价值极高的NFT,可以彰显自己的财力和投资眼光。
3. FOMO:
Fear of Missing Out的首字母缩写——错失恐惧症,意思是害怕错过的情绪。类似于担心抢不到心仪的商品或怕比别人手慢而盲目跟风下单看到什么买什么。(这里建议大家理智购买藏品,不要过分FOMO)
4. Cope:
跟 FOMO 相反的意思,意识是后悔做了某事。比如因为之前没有在地板价的时候购入,目前价格一路飙升非常的Cope。又比如之前FOMO过头,买了太多现在积仓过多,非常后悔。
5. Apeing (into something):
这里的Apein和任何Ape项目都无关。是指,出于FOMO情绪,大量投入超出自己经济承受能力的资金,也指没有对NFT项目进行一个调研和了解就盲目进行投资。
6. Rug:
Rug pull 的缩写,原意为拉地毯,在NFT行业中延伸指:在项目方或者平台卷款潜逃事件。具体指:NFT项目的创建者争取到投资,然后突然放弃项目,骗取项目投资者的资金。比如Frosties项目创始人因Rug pull就被美国司法部指控欺诈和洗钱。
7.1:1 Art:
意思是指每件作品都是独一无二的(1 of 1),10k project中多数都是1:1 ART,这也是PFP项目容易受到市场追捧的一个原因。
8.McDonald's:
字面意思: 麦当劳。当有人在Discord中说 McDonald's则意味着没钱了,吃土,去搬砖的意思。国内社群更多用美团来代替。 收起阅读 »
你和NFT老藏家的距离就像是“魔法师”和“麻瓜”之间的差距,那么接下来的20个术语,
一、基础平台和应用软件
1. OS:
Opensea的简称,国际NFT交易平台,是目前全球最多用户使用,市场份额占比最高,交易量最大的NFT交易平台。
2. DC
Discord的简称,功能强大的社群通讯软件。目前绝大部分NFT项目的社群聚集地,项目方通常在DC发布重要通道,进社群推广等等。也是目前许多自发NFT社群的根据地。
3. MetaMask (狐狸钱包):
以太坊生态系统中最受欢迎,用户数量最大的NFT钱包。
二、入门级必备术语
1. White List (白名单):
简称WL,也就是NFT项目的白名单。拥有白名单可以在项目公开发售前提前购买NFT,不用和大批人比网速比手速。尤其是在目前大火项目二级市场价格都偏高,而首发作品都处于上架秒空的情况下,白名单可以是“拿到即赚到”。
2. Blue Chips (蓝筹项目):
原指赌场上的蓝色筹码(赌场桌上最基础的筹码组合是1美元的白色筹码、5美元的红色筹码和25美元的蓝色筹码),蓝色筹码为最具有价值的筹码。延伸到蓝筹项目就是指有价值、建议长期持有的优质NFT。
3. Airdrop (空投):
你的钱包会免费收到一个NFT。目前空投被项目方广泛用来激励长期持有者,在国内大多用“转赠”来代替“空投”用法。
4. Mint(铸造) :
翻译成中文,做名词有薄荷的意思,做动词则是铸造。也就是生成NFT的过程,某一个NFT项目的首次铸造。
5. Gas Fee (燃料费):
燃料费, 也可理解成手续费。从技术层面来说,区块链的每一个节点都是需要维护的,而在以太坊中的每笔交易都需要“矿工们”帮你完成,而你则要支付一定的报酬给矿工们。在海外你需要使用eth等虚拟货币进行支付,而在国内则支持RMB支付。因而Gas Fee 也称作“矿工费”。
6. DAO
Decentralized Autonomous Organization的首字母缩写,也就是“去中心化自治组织”。目前多数NFT项目方都会有自己的DAO, 当你持有该项目的NFT时你就有资质成为DAO成员,DAO群成员拥有对该项目未来发展整体方向的治理权。通过DAO,项目方可以凝聚社群,从而提升项目的发展长驱动力。
7. Roadmap(路线图):
路线图,专门指某个NFT项目计划为社群增加价值而进行的一系列活动。路线图目前已经成为许多藏家入手新项目之前必须考察的一点,一个NFT项目是否拥有路线图在一定程度上决定了该项目的规划能力以及运营能力。
8. Floor Price (地板价):
地板价,指某一NFT项目在交易市场中的最低入手价格,Floor Price的价格越高,代表该NFT项目的整体价格走向明朗。抄底也是指在该项目处于Floor Price的时候大量购入,等待其后续的爆发时机。
三、进阶级术语
1. 10k project
指由约10000个头像组成的NFT项目,10k project 以Bored Ape Yacht Club 以及 Croptofunks 为代表。但值得注意的是,这里的10k并不是固定的,该术语仅指代这一类型的头像合集,并未规定10k 的具体数量。
2. PFP
PFP在不同的行业有着不同的含义,在NFT界的PFP特指[Profile Picture],也就是“个人资料图片”。不少10 projet 都是PFP项目,比如库里购入了Cryptofunk,并将它用作自己社交媒体的头像。目前,PFP仍然广收藏家的欢迎,拥有一个价值极高的NFT,可以彰显自己的财力和投资眼光。
3. FOMO:
Fear of Missing Out的首字母缩写——错失恐惧症,意思是害怕错过的情绪。类似于担心抢不到心仪的商品或怕比别人手慢而盲目跟风下单看到什么买什么。(这里建议大家理智购买藏品,不要过分FOMO)
4. Cope:
跟 FOMO 相反的意思,意识是后悔做了某事。比如因为之前没有在地板价的时候购入,目前价格一路飙升非常的Cope。又比如之前FOMO过头,买了太多现在积仓过多,非常后悔。
5. Apeing (into something):
这里的Apein和任何Ape项目都无关。是指,出于FOMO情绪,大量投入超出自己经济承受能力的资金,也指没有对NFT项目进行一个调研和了解就盲目进行投资。
6. Rug:
Rug pull 的缩写,原意为拉地毯,在NFT行业中延伸指:在项目方或者平台卷款潜逃事件。具体指:NFT项目的创建者争取到投资,然后突然放弃项目,骗取项目投资者的资金。比如Frosties项目创始人因Rug pull就被美国司法部指控欺诈和洗钱。
7.1:1 Art:
意思是指每件作品都是独一无二的(1 of 1),10k project中多数都是1:1 ART,这也是PFP项目容易受到市场追捧的一个原因。
8.McDonald's:
字面意思: 麦当劳。当有人在Discord中说 McDonald's则意味着没钱了,吃土,去搬砖的意思。国内社群更多用美团来代替。 收起阅读 »
ubuntu下最好的图形git管理工具kranken (免费版本)
kranken 是笔者在ubuntu下用过最好的git图形界面工具。

不过最新的版本已经要收费了。
但是如果你用回以前的旧版本,还是可以依然免费的。
反正多试几次就可以。
不要点击安装,不然出错了,也不知道是什么问题。
使用命令行安装:
如果报错,依赖出错,那么可以这样操作:
搞定 收起阅读 »
不过最新的版本已经要收费了。
但是如果你用回以前的旧版本,还是可以依然免费的。
[url]https://release.axocdn.com/lin ... 1.deb[/url]
[url]https://release.axocdn.com/lin ... 1.rpm[/url]
[url]https://release.axocdn.com/lin ... ar.gz[/url]
[url]https://release.axocdn.com/win ... 1.exe[/url]
如果上面链接下载不了,可以换一个源。我在本地ip下似乎下不了,跑到腾讯云上的云服务器 就可以正常下载。
反正多试几次就可以。
不要点击安装,不然出错了,也不知道是什么问题。
使用命令行安装:
sudo dpkg -i gitkraken-amd64.deb
如果报错,依赖出错,那么可以这样操作:
sudo apt --fix-broken install
搞定 收起阅读 »
忠告:千万不要在集思录开银河证券(中关村营业部) 有图为证
个人的亲身经历,在集思录上的广告贴帮家人开了几个银河证券的户。

就是这样的帖子,真TM害人。 直接扫描开户后,后面连经理都找不到,打电话,一直忙音,我的天。

上面是家人的中关村营业部的账户(并非随意喷这个垃圾营业部的,是确实开到这个营业部的)。
这个账户是很久前开的(大概3年前吧,疫情刚开始的时候),当时银河证券在集思录的页面是上宣传的是万一免五开户。所以当时也没有留意就开了。
开了之后由于一直做的基金套利和可转债交易。 股票没有交易过。
然后今天居然银行板块非常低估,所以打算入点银行股,定投计划。
结果上周买了一点苏州银行。
今天开交割单。

股票的费率是万3
现在都什么年代了,居然股票还能开出万3的费率。这个不确定他们是不是在背地里暗自把我这个账户的费率提高上去了。
然后打电话过去他们的营业部:

全程就一个字,拽。(当然手机也有自动录音)
我们营业部都是服务百万级别的大户,你爱用不用,现在北京疫情办事不方便,现在也没有免五,调不了免五了。
销户的话随意啦。
巴拉巴拉。
听完后,第二天就把账户清理了,预约了销户。
然后找了另外一个朋友,轻松开了费率万一免五的银河。
狗日的中关村银河。886
收起阅读 »
就是这样的帖子,真TM害人。 直接扫描开户后,后面连经理都找不到,打电话,一直忙音,我的天。
上面是家人的中关村营业部的账户(并非随意喷这个垃圾营业部的,是确实开到这个营业部的)。
这个账户是很久前开的(大概3年前吧,疫情刚开始的时候),当时银河证券在集思录的页面是上宣传的是万一免五开户。所以当时也没有留意就开了。
开了之后由于一直做的基金套利和可转债交易。 股票没有交易过。
然后今天居然银行板块非常低估,所以打算入点银行股,定投计划。
结果上周买了一点苏州银行。
今天开交割单。
股票的费率是万3
现在都什么年代了,居然股票还能开出万3的费率。这个不确定他们是不是在背地里暗自把我这个账户的费率提高上去了。
然后打电话过去他们的营业部:
全程就一个字,拽。(当然手机也有自动录音)
我们营业部都是服务百万级别的大户,你爱用不用,现在北京疫情办事不方便,现在也没有免五,调不了免五了。
销户的话随意啦。
巴拉巴拉。
听完后,第二天就把账户清理了,预约了销户。
然后找了另外一个朋友,轻松开了费率万一免五的银河。
狗日的中关村银河。886
收起阅读 »
python seo 小工具 查询百度权重,备案信息
平时主要比较频繁查询 站长之家这个网站:

还有百度的收录情况:

对于经常操作的朋友,需要使用程序查询,还可以批量查询,并保存到excel或者数据库。

上图为入库到mongodb的数据
源码实现:
main.py 入口函数:
其他具体实现的文件:
baidu_collection.py
seo_info.py
运行效果:

需要完整代码,可关注公众号联系:
 收起阅读 »
收起阅读 »
还有百度的收录情况:
对于经常操作的朋友,需要使用程序查询,还可以批量查询,并保存到excel或者数据库。
上图为入库到mongodb的数据
源码实现:
main.py 入口函数:
from baidu_collection import baidu_site_collect
from seo_info import crawl_info
from configure.settings import DBSelector
import datetime
import argparse
client = DBSelector().mongo('qq')
doc = client['db_parker']['seo']
def main():
parser = argparse.ArgumentParser()
'''
Command line options
'''
parser.add_argument(
'-n',
'--name', type=str,
help='input web domain'
)
parser.add_argument(
'-f',
'--file', type=str,
help='input web site domain file name'
)
FLAGS = parser.parse_args()
site_list=
if FLAGS.name:
print(FLAGS.name)
if '.' in FLAGS.name:
site_list.append(FLAGS.name)
elif FLAGS.file:
print(FLAGS.file)
with open(FLAGS.file,'r') as fp:
webs=fp.readlines()
site_list.extend(list(map(lambda x:x.strip(),webs)))
if site_list:
run(site_list=site_list)
else:
print("please input correct web domain")
def run(site_list):
# TODO: 改为命令行形式
for site in site_list:
count = baidu_site_collect(site)
info = crawl_info(site)
print(info)
print(count)
info['site'] = site
info['baidu_count'] = count
info['update_time'] = datetime.datetime.now()
doc.insert_one(info)
if __name__ == '__main__':
main()
其他具体实现的文件:
baidu_collection.py
from parsel import Selector
import requests
def baidu_site_collect(site):
# 百度收录
headers = {'User-Agent': 'Chrome Google FireFox IE'}
url = 'https://www.baidu.com/s?wd=site:{}&rsv_spt=1&rsv_iqid=0xf8b7b7e50006c034&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=0&rsv_dl=ib&rsv_sug3=14&rsv_sug1=7&rsv_sug7=100&rsv_n=2&rsv_btype=i&inputT=8238&rsv_sug4=8238'.format(site)
resp = requests.get(
url=url,
headers=headers
)
resp.encoding='utf8'
html = resp.text
selector = Selector(text=html)
count = selector.xpath('//div[@class="op_site_domain c-row"]/div/p/span/b/text()').extract_first()
if count:
count=int(count.replace(',',''))
return count
if __name__=='__main__':
site='30daydo.com'
print(baidu_site_collect(site))
seo_info.py
import argparse
from atexit import register
import sys
import requests
import re
from parsel import Selector
#参数自定义
# parser = argparse.ArgumentParser()
# parser.add_argument('-r', dest='read', help='path file')
# parser.add_argument('-u',dest='read',help='targetdomain')
# parser_args = parser.parse_args()
#爬虫模块查询
VERBOSE = True
def askurl(target_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
#baidu权重
baidu_url=f"https://rank.chinaz.com/{target_url}"
baidu_txt=requests.get(url=baidu_url,headers=headers)
baidu_html=baidu_txt.content.decode('utf-8')
baidu_PC=re.findall('PC端</i><img src="//csstools.chinaz.com/tools/images/rankicons/baidu(.*?).png"></a></li>',baidu_html,re.S)
baidu_moblie=re.findall('移动端</i><img src="//csstools.chinaz.com/tools/images/rankicons/bd(.*?).png"></a></li>',baidu_html,re.S)
#分割线
print("*"*60)
#如果查询html中有正则出来到权重关键字就输出,否则将不输出
result={}
baidu_pc_weight = None
baidu_mobile_weight = None
if len(baidu_PC) > 0:
print('百度_PC:', baidu_PC[0])
baidu_pc_weight=baidu_PC[0]
if len(baidu_moblie) > 0:
print('百度_moblie:', baidu_moblie[0])
baidu_mobile_weight = baidu_moblie[0]
else:
print("百度无权重")
result['baidu_pc_weight']=baidu_pc_weight
result['baidu_mobile_weight']=baidu_mobile_weight
#360权重
url=f"https://rank.chinaz.com/sorank/{target_url}/"
text = requests.get(url=url,headers=headers)
html=text.content.decode('utf-8')
sorank360_PC=re.findall('PC端</i><img src="//csstools.chinaz.com/tools/images/rankicons/360(.*?).png"></a><',html,re.S)
sorank360_Mobile=re.findall('移动端</i><img src="//csstools.chinaz.com/tools/images/rankicons/360(.*?).png"',html,re.S)
_360_pc_weight=None
_360_mobile_weight=None
# 如果查询html中有正则出来到权重关键字就输出,否则将不输出
if len(sorank360_PC) > 0:
_360_pc_weight=sorank360_PC[0]
print("360_PC:", sorank360_PC[0])
if len(sorank360_Mobile) > 0:
_360_mobile_weight=sorank360_Mobile[0]
print("360_moblie:", sorank360_Mobile[0])
else:
print("360无权重")
result['360_pc_weight']=_360_pc_weight
result['360_mobile_weight']=_360_mobile_weight
#搜狗权重
sogou_pc_weight=None
sogou_mobile_weight=None
sogou_url = f"https://rank.chinaz.com/sogoupc/{target_url}"
sougou_txt = requests.get(url=sogou_url, headers=headers)
sougou_html = sougou_txt.content.decode('utf-8')
sougou_PC = re.findall('PC端</i><img src="//csstools.chinaz.com/tools/images/rankicons/sogou(.*?).png"></a></li>',sougou_html, re.S)
sougou_mobile = re.findall('移动端</i><img src="//csstools.chinaz.com/tools/images/rankicons/sogou(.*?).png"></a></li>',sougou_html, re.S)
# 如果查询html中有正则出来到权重关键字就输出,否则将不输出
if len(sougou_PC) > 0:
print('搜狗_PC:', sougou_PC[1])
sogou_pc_weight=sougou_PC[1]
if len(sougou_mobile) > 0 :
print('搜狗_moblie:', sougou_mobile[1])
sogou_mobile_weight=sougou_mobile[1]
else:
print('搜狗无权重')
result['sogou_pc_weight']=sogou_pc_weight
result['sogou_mobile_weight']=sogou_mobile_weight
#神马权重
shenma_pc_weight =None
shenma_url=f'https://rank.chinaz.com/smrank/{target_url}'
shenma_txt=requests.get(url=shenma_url,headers=headers)
shenma_html=shenma_txt.content.decode('utf-8')
shenma_PC=re.findall('class="tc mt5"><img src="//csstools.chinaz.com/tools/images/rankicons/shenma(.*?).png"></a></li>',shenma_html,re.S)
# 如果查询html中有正则出来到权重关键字就输出,否则将不输出
if len(shenma_PC) > 0:
print('神马权重为:', shenma_PC[1])
shenma_pc_weight=shenma_PC[1]
else:
print("神马无权重")
result['shenma_pc_weight']=shenma_pc_weight
# result['shenma_mobile_weight']=None
#头条权重
toutiao_pc_weight=None
toutiao_url=f'https://rank.chinaz.com/toutiao/{target_url}'
toutiao_txt=requests.get(url=toutiao_url,headers=headers)
toutiao_html=toutiao_txt.content.decode('utf-8')
toutiao_PC=re.findall('class="tc mt5"><img src="//csstools.chinaz.com/tools/images/rankicons/toutiao(.*?).png"></a></li>',toutiao_html,re.S)
# 如果查询html中有正则出来到权重关键字就输出,否则将不输出
if len(toutiao_PC) > 0:
print('头条权重为:', toutiao_PC[1])
toutiao_pc_weight=toutiao_PC[1]
else:
print("头条无权重")
result['toutiao_pc_weight']=toutiao_pc_weight
# result['toutiao_mobile_weight']=None
#备案信息、title、企业性质
beian_url=f"https://seo.chinaz.com/{target_url}"
beian_txt=requests.get(url=beian_url,headers=headers)
beian_html=beian_txt.content.decode('utf-8')
with open('beian_html.html','w') as fp:
fp.write(beian_html)
title,beian_no,name,ip,nature,register,years=parse_info(beian_html)
result['name']=name
result['title']=title
result['beian_no']=beian_no
result['ip']=ip
result['nature']=nature
result['register']=register
result['years']=years
try:
print("备案信息:",beian_no,"名称:",name,"网站首页Title:",title,"企业性质:",nature,"IP地址为:",ip)
print("*"*60)
except:
print("没有查询到有效信息!")
return result
strip_fun = lambda x:x.strip() if x is not None else ""
def parse_info(html):
resp = Selector(text=html)
title = strip_fun(resp.xpath('//div[@class="_chinaz-seo-t2l ellipsis"]/text()').extract_first())
table = resp.xpath('//table[@class="_chinaz-seo-newt"]/tbody')
if table[0].xpath('.//tr[4]/td[2]/span[1]/i'):
beian_num=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[1]/i/a/text()').extract_first())
else:
beian_num=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[1]/a/text()').extract_first())
name=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[2]/i/text()').extract_first())
if not name:
print('---->',name)
name=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[2]/i/a/text()').extract_first())
nature=strip_fun(table[0].xpath('.//tr[4]/td[2]/span[3]/i/text()').extract_first())
ip=strip_fun(table[0].xpath('.//tr[5]/td[2]/div/span[1]/i/a/text()').extract_first())
register=strip_fun(table[0].xpath('.//tr[3]/td[2]/div[1]/span[1]/i/text()').extract_first())
years=strip_fun(table[0].xpath('.//tr[3]/td[2]/div[2]/span[1]/i/text()').extract_first())
return title,beian_num,name,ip,nature,register,years
def crawl_info(site):
return askurl(site)
if __name__ == '__main__':
main()
运行效果:
需要完整代码,可关注公众号联系:
收起阅读 »


原来ubuntu发行的版本数字是按照年份来定的22.04 是22年4月发行的
怪不得以前好奇,怎么ubuntu为啥都是双数版本。
最早用的10.04 这么看就是12年前的操作系统了。
而18.04也差不多也是4年前的操作系统了。
而当前最新的应该就是22.04 LTS 长期支持版本了。
最早用的10.04 这么看就是12年前的操作系统了。
而18.04也差不多也是4年前的操作系统了。
而当前最新的应该就是22.04 LTS 长期支持版本了。



vs code远程开发 ssh端口不是默认22时如何配置
有时候服务器的ssh端口不是22,比如时2222的时候,需要如何配置呢?
其实这个和ssh远程连接一样。
ssh root@192.168.1.1:2222
然后按下enter键 就可以了。
其实这个和ssh远程连接一样。
ssh root@192.168.1.1:2222
然后按下enter键 就可以了。
python识别股票K线形态,准确率回测(一)
python识别股票K线形态,准确率回测(一)
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)

做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
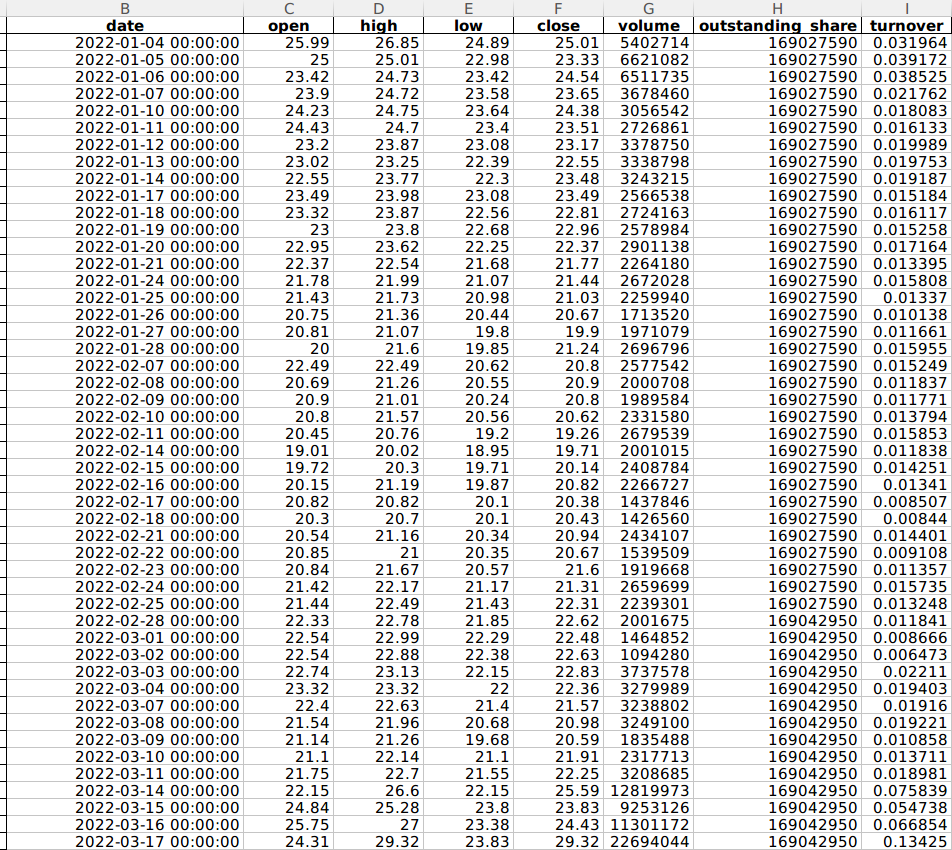
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
运行此段代码后,会显示如下效果图:
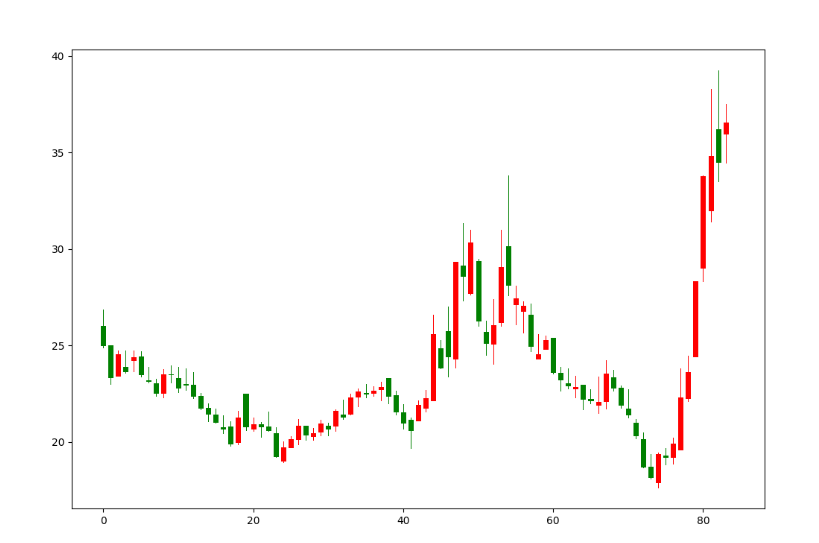
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
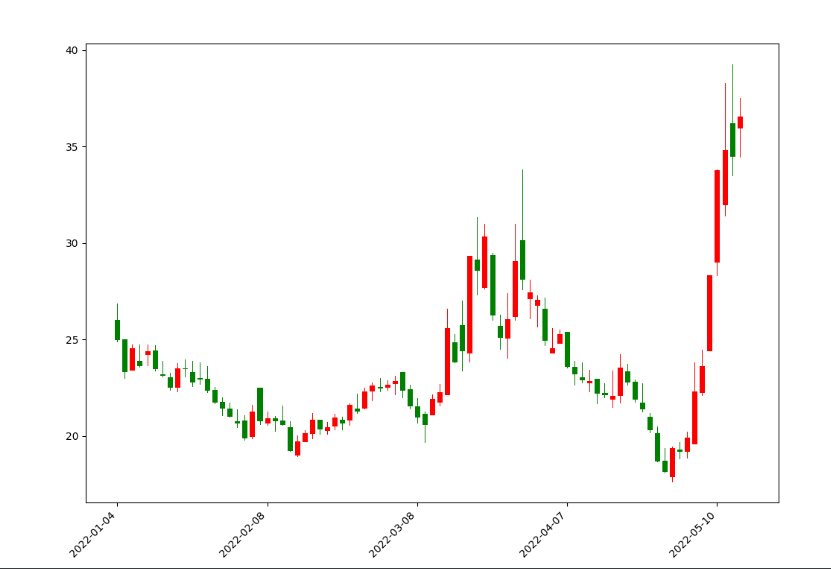
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
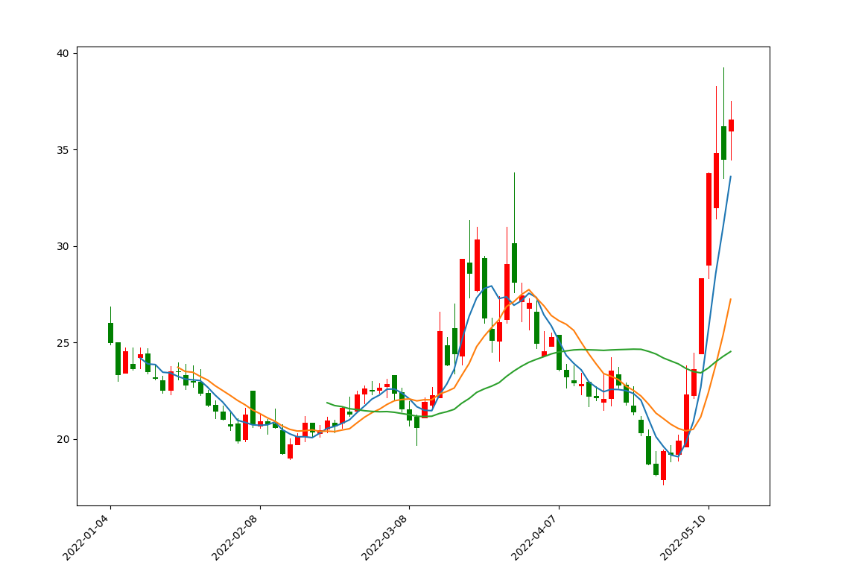
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
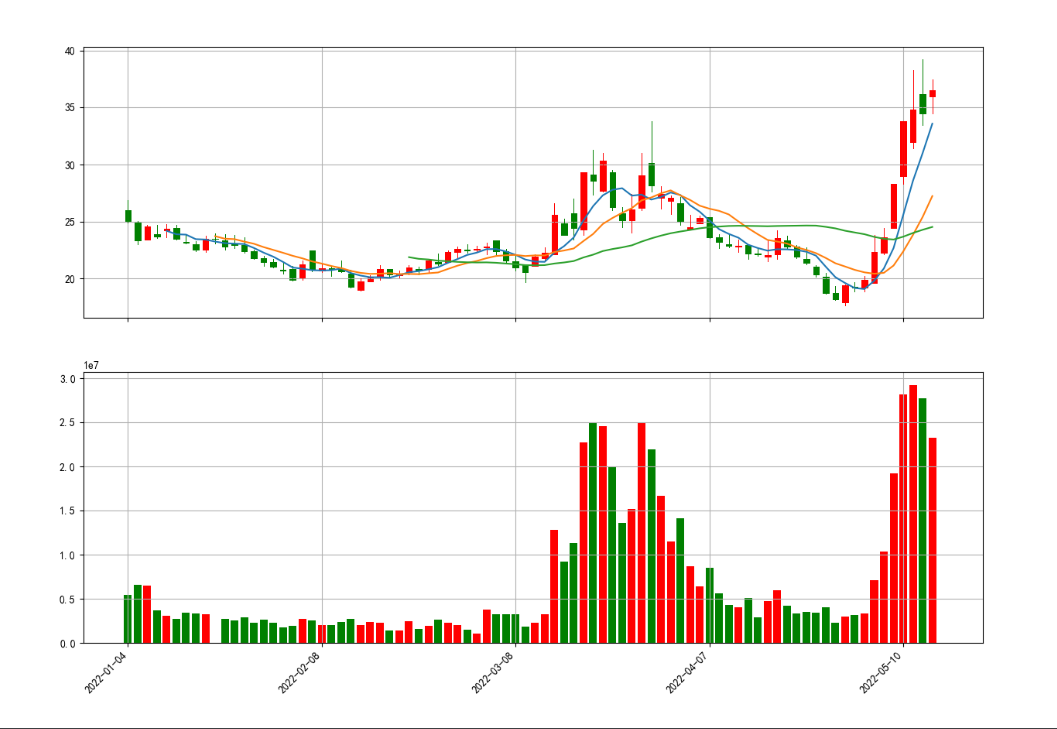
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线

根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。

那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
然后把这个长上影函数应用到上面的同和药业。
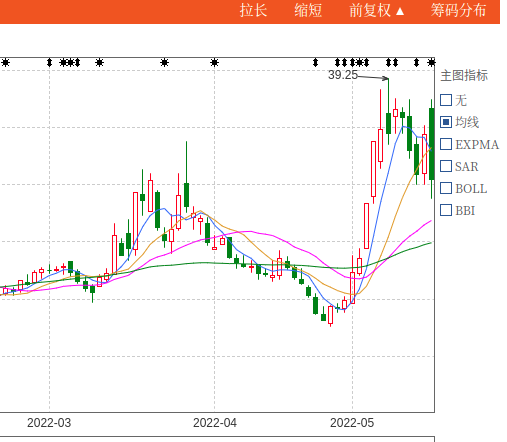
得到的效果:
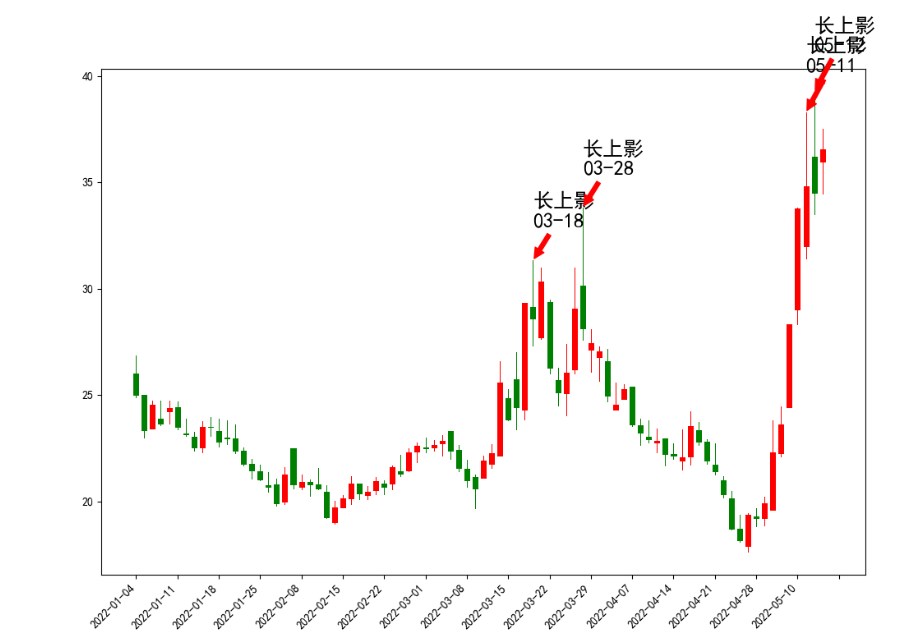
图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。

截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续) 收起阅读 »
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)
做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
# pip install akshare
import akshare as ak
def get_k_line(code="sz002241"): #
df = ak.stock_zh_a_daily(symbol=code, start_date="20220101", end_date="20220515",
adjust="qfq")
# 这个函数只适合取股票数据,转债会报错,转债的日线数据可以使用其他函数,这里选择股价前复权
df.to_excel("同和药业k.xlsx")
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
date:交易日期
open:代表开盘价
high:当天最高价
low:当天最低价
close:当天收盘价
volume:当天成交量(元)
outstanding_share:流动股本(股)
turnover:换手率
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
#显示出来
plt.show()
运行此段代码后,会显示如下效果图:
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
import matplotlib.ticker as ticker
#将股票时间转换为标准时间,不带时分秒的数据
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.strptime(date, '%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
ax.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线
根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。
那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
def long_up_shadow(o,c,h,l):
return True if (h-c)/c >=0.07 and (h-o)/o>=0.07 else False
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
df = pd.read_excel("同和药业k.xlsx")
count_num = []
for row,item in df.iterrows():
if long_up_shadow(item['open'],item['close'],item['high'],item['low']):
count_num.append(row)
plot_image(df,count_num)图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。
截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
df['tow_crows'] = talib.CDL2CROWS(df['open'].values, df['high'].values, df['low'].values, df['close'].values)
pattern = df[(df['tow_crows'] == 100) | (df['tow_crows'] == -100)]
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续) 收起阅读 »
B站批量下载某个UP主的所有视频
B站上不少优秀的学习资源,下载到本地观看,便于快进,多倍速。 也可以放到平板,手机,在没有网络,或者网络条件不佳的环境下观看。

使用python实现
https://github.com/Rockyzsu/bilibili
主要代码:
收起阅读 »
使用python实现
https://github.com/Rockyzsu/bilibili
B站视频下载
自动批量下载B站一个系列的视频
下载某个UP主的所有视频
使用:
下载you-get库,git clone https://github.com/soimort/you-get.git 复制其本地路径,比如/root/you-get/you-get
初次运行,删除history.db 文件, 修改配置文件config.py
START=1 # 下载系列视频的 第一个
END=1 # 下载系列视频的最后一个 , 比如一个系列教程有30个视频, start=5 ,end = 20 下载从第5个到第20个
ID='BV1oK411L7au' # 视频的ID
YOU_GET_PATH='/home/xda/othergit/you-get/you-get' # 你的you-get路径
MINS=1 # 每次循环等待1分钟
user_id = '518973111' # UP主的ID
total_page = 3 # up主的视频的页数
执行 python downloader.py ,进行下载循环
python people.py ,把某个up主的视频链接加入到待下载队列
python add_data.py --id=BV1oK411L7au --start=4 --end=8 下载视频id为BV1oK411L7au的系列教程,从第4开始,到第8个结束,如果只有一个的话,start和end设为1即可。
可以不断地往队列里面添加下载链接。
主要代码:
# @Time : 2019/1/28 14:19
# @File : youtube_downloader.py
import logging
import os
import subprocess
import datetime
import sqlite3
import time
from config import YOU_GET_PATH,MINS
CMD = 'python {} {}'
filename = 'url.txt'
class SQLite():
def __init__(self):
self.conn = sqlite3.connect('history.db')
self.cursor = self.conn.cursor()
self.create_table()
def create_table(self):
create_sql = 'create table if not exists tb_download (url varchar(100),status tinyint,crawltime datetime)'
create_record_tb = 'create table if not exists tb_record (idx varchar(100) PRIMARY KEY,start tinyint,end tinyint,status tinyint)'
self.cursor.execute(create_record_tb)
self.conn.commit()
self.cursor.execute(create_sql)
self.conn.commit()
def exists(self,url):
querySet = 'select * from tb_download where url = ? and status = 1'
self.cursor.execute(querySet,(url,))
ret = self.cursor.fetchone()
return True if ret else False
def insert_history(self,url,status):
query = 'select * from tb_download where url=?'
self.cursor.execute(query,(url,))
ret = self.cursor.fetchone()
current = datetime.datetime.now()
if ret:
insert_sql='update tb_download set status=?,crawltime=? where url = ?'
args=(status,status,current,url)
else:
insert_sql = 'insert into tb_download values(?,?,?)'
args=(url,status,current)
try:
self.cursor.execute(insert_sql,args)
except:
self.conn.rollback()
return False
else:
self.conn.commit()
return True
def get(self):
sql = 'select idx,start,end from tb_record where status=0'
self.cursor.execute(sql)
ret= self.cursor.fetchone()
return ret
def set(self,idx):
print('set status =1')
sql='update tb_record set status=1 where idx=?'
self.cursor.execute(sql,(idx,))
self.conn.commit()
def llogger(filename):
logger = logging.getLogger(filename) # 不加名称设置root logger
logger.setLevel(logging.DEBUG) # 设置输出级别
formatter = logging.Formatter(
'[%(asctime)s][%(filename)s][line: %(lineno)d]\[%(levelname)s] ## %(message)s)',
datefmt='%Y-%m-%d %H:%M:%S')
# 使用FileHandler输出到文件
prefix = os.path.splitext(filename)[0]
fh = logging.FileHandler(prefix + '.log')
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
# 使用StreamHandler输出到屏幕
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
ch.setFormatter(formatter)
# 添加两个Handler
logger.addHandler(ch)
logger.addHandler(fh)
return logger
logger = llogger('download.log')
sql_obj = SQLite()
def run():
while 1:
result = sql_obj.get()
print(result)
if result:
idx=result[0]
start=result[1]
end=result[2]
try:
download_bilibili(idx,start,end)
except:
pass
else:
sql_obj.set(idx)
else:
time.sleep(MINS*60)
def download_bilibili(id,start_page,total_page):
global doc
bilibili_url = 'https://www.bilibili.com/video/{}?p={}'
for i in range(start_page, total_page+1):
next_url = bilibili_url.format(id, i)
if sql_obj.exists(next_url):
print('have download')
continue
try:
command = CMD.format(YOU_GET_PATH, next_url)
p = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE,
shell=True)
output, error = p.communicate()
except Exception as e:
print('has execption')
sql_obj.insert_history(next_url,status=0)
logger.error(e)
continue
else:
output_str = output.decode()
if len(output_str) == 0:
sql_obj.insert_history(next_url,status=0)
logger.info('下载失败')
continue
logger.info('{} has been downloaded !'.format(next_url))
sql_obj.insert_history(next_url,status=1)
run()
收起阅读 »
python3的map是迭代器,不用for循环或者next触发是不会执行的
最近刚好有位群友咨询,他写的代码如下:
作用很简单,就是拿到列表后用map放入到sqlite里面。
但是上面的代码并不起作用。
因为map只是定义了一个迭代器,并没有被触发。
可以加一个list(map(lambda x:update_data(x,1,1),bv_list))
这样就可以执行了。 收起阅读 »
def update_data(id,start,end):
status=0
conn = sqlite3.connect('history.db')
cursor = conn.cursor()
insert_sql ='insert into tb_record values(?,?,?,?)'
try:
cursor.execute(insert_sql,(id,start,end,status))
except Exception as e:
print(e)
print('Error')
else:
conn.commit()
print("successfully insert")
bv_list = []
for i in range(1, total_page + 1):
bv_list.extend(visit(i))
print(bv_list)
map(lambda x:update_data(x,1,1),bv_list)
作用很简单,就是拿到列表后用map放入到sqlite里面。
但是上面的代码并不起作用。
因为map只是定义了一个迭代器,并没有被触发。
可以加一个list(map(lambda x:update_data(x,1,1),bv_list))
这样就可以执行了。 收起阅读 »
dataframe如何 遍历所有的列?
如果遍历行,我们经常会使用df.iterrows(), 而列呢?
可以使用df.items()
可以使用df.items()
Python pandas.DataFrame.items用法及代码示例收起阅读 »
用法:
DataFrame.items()
迭代(列名,系列)对。
遍历 DataFrame 列,返回一个包含列名和内容的元组作为一个系列。
生成(Yield):
label:对象
被迭代的 DataFrame 的列名。
content:Series
属于每个标签的列条目,作为一个系列。
例子:
>>> df = pd.DataFrame({'species':['bear', 'bear', 'marsupial'],
... 'population':[1864, 22000, 80000]},
... index=['panda', 'polar', 'koala'])
>>> df
species population
panda bear 1864
polar bear 22000
koala marsupial 80000
>>> for label, content in df.items():
... print(f'label:{label}')
... print(f'content:{content}', sep='\n')
...
label:species
content:
panda bear
polar bear
koala marsupial
Name:species, dtype:object
label:population
content:
panda 1864
polar 22000
koala 80000
Name:population, dtype:int64
ubuntu20 conda安装python ta-lib 股票分析库
. 使用 Anaconda 里面的conda 工具
$ conda install -c quantopian ta-lib=0.4.9
一般而说,上面的会失败,可以按照下面的方法:
2. 自己手工编译安装,适合需要自己修改内部的一些函数
a) 下载ta-lib的源码
$ wget [url=http://prdownloads.sourceforge ... ar.gz(]http://prdownloads.sourceforge ... ar.gz[/url]
如果无法下载的话,可以直接复制到浏览器下载,我的wget就是无法下载,估计有反盗链设计了
prdownloads.sourceforge.net/ta-lib/ta-lib-0.4.0-src.tar.gz
或者文末也可以获取。
$ untar and cd
$ ./configure --prefix=/usr
$ make
$ sudo make install
假如之前用anaconda安装过,需要将生成的库替换到anaconda安装的目录
$ cp /usr/lib/libta_lib* /home/user/anaconda2/lib/
b) 下载ta-lib的Python wrapper
pip install ta-lib
或者
$ git clone https://github.com/mrjbq7/ta-lib.git
$ cd ta-lib
$ python setup.py install
最后在Python里面 import talib没有报错就安装成功了
在公众号后台留言: talib 就可以获取文件。
收起阅读 »
Ubuntu20安装搜狗输入法 (自带的智能拼音太烂了)
效果图:

Ubuntu20.04安装搜狗输入法步骤
1、更新源
在终端执行 sudo apt update
2、安装fcitx输入法框架
\1. 在终端输入 sudo apt install fcitx
\2. 设置fcitx为系统输入法
点击左下角菜单选择语言支持,将语言选择为fcitx(如下图二)
\3. 设置fcitx开机自启动
在终端执行sudo cp /usr/share/applications/fcitx.desktop /etc/xdg/autostart/
\4. 卸载系统ibus输入法框架
在终端执行 sudo apt purge ibus
3、安装搜狗输入法
\1. 在官网下载搜狗输入法安装包,并安装,安装命令 sudo dpkg -i 安装包名
\2. 安装输入法依赖
在终端执行
sudo apt install libqt5qml5 libqt5quick5 libqt5quickwidgets5 qml-module-qtquick2
sudo apt install libgsettings-qt1
4、重启电脑、调出输入法
1.重启电脑
2.查看右上角,可以看到“搜狗”字样,在输入窗口即可且出搜狗输入法。
\3. 没有“搜狗”字样,选择配置,将搜狗加入输入法列表即可
至此,搜狗输入法安装完毕 收起阅读 »
Ubuntu20.04安装搜狗输入法步骤
1、更新源
在终端执行 sudo apt update
2、安装fcitx输入法框架
\1. 在终端输入 sudo apt install fcitx
\2. 设置fcitx为系统输入法
点击左下角菜单选择语言支持,将语言选择为fcitx(如下图二)
\3. 设置fcitx开机自启动
在终端执行sudo cp /usr/share/applications/fcitx.desktop /etc/xdg/autostart/
\4. 卸载系统ibus输入法框架
在终端执行 sudo apt purge ibus
3、安装搜狗输入法
\1. 在官网下载搜狗输入法安装包,并安装,安装命令 sudo dpkg -i 安装包名
\2. 安装输入法依赖
在终端执行
sudo apt install libqt5qml5 libqt5quick5 libqt5quickwidgets5 qml-module-qtquick2
sudo apt install libgsettings-qt1
4、重启电脑、调出输入法
1.重启电脑
2.查看右上角,可以看到“搜狗”字样,在输入窗口即可且出搜狗输入法。
\3. 没有“搜狗”字样,选择配置,将搜狗加入输入法列表即可
至此,搜狗输入法安装完毕 收起阅读 »

shell批量导入mysql数据库 附代码
把目录下的sql脚本名字复制到
restore_db=(db_bond_daily.sql db_bond_history.sql)
里面,比如这里的 db_bond_daily.sql db_bond_history.sql
收起阅读 »
restore_db=(db_bond_daily.sql db_bond_history.sql)
里面,比如这里的 db_bond_daily.sql db_bond_history.sql
#!/bin/bash
# 批量备份数据库
MYSQL_USER=root
MYSQL_PASSWORD=123456 # 改为你的mysql密码
HOST=127.0.0.1
restore_db=(db_bond_daily.sql db_bond_history.sql) # sql 文件列表
for i in ${restore_db[*]}
do
name=(${i//./ }) # 切割名字
mysql -h$HOST -u$MYSQL_USER -p$MYSQL_PASSWORD ${name[0]}<${i}
done
收起阅读 »
腾讯云轻量服务器使用mysqldump导出数据 导致进程被杀
只能说任何数据库都不能随意放在轻量服务器,io读写太差了。
稍微密集一点,直接被杀掉。
在方面放mysql服务,简直就是煞笔行为。
稍微密集一点,直接被杀掉。
在方面放mysql服务,简直就是煞笔行为。
centos yum安装mysql client 客户端
centos7 下使用yum下找不到mysql客户端的rpm包了,
这时需要从官网下载
1.安装rpm源
rpm -ivh https://repo.mysql.com//mysql57-community-release-el7-11.noarch.rpm
2.安装客户端
#可以通过yum搜索
#若是64位的话直接安装
结果报错
报以下密钥错误:
则先执行以下命令再安装:
操作:
连到数据库:mysql -h 数据库地址 -u数据库用户名 -p数据库密码 -D 数据库名称
mysql -h 88.88.19.252 -utravelplat -pHdkj1234 -D etravel
数据库导出(表结构):mysqldump -h 数据库地址 -u数据库用户名 -p数据库密码 -d 数据库名称 > 文件名.sql
mysqldump -h 88.88.19.252 -utravelplat -pHdkj1234 -d etravel > db20190713.sql
数据库导出(表结构 + 表数据):mysqldump -h 数据库地址 -u数据库用户名 -p数据库密码 数据库名称 > 文件名.sql
mysqldump -h 88.88.19.252 -utravelplat -pHdkj1234 etravel > db20190713.sql
数据库表导出(表结构 + 表数据):
mysqldump -h 88.88.19.252 -utravelplat -pHdkj1234 etravel doc > doc.sql
导入到数据库:source 文件名.sql
source db20190713.sql
收起阅读 »
这时需要从官网下载
1.安装rpm源
rpm -ivh https://repo.mysql.com//mysql57-community-release-el7-11.noarch.rpm
2.安装客户端
#可以通过yum搜索
yum search mysql
#若是64位的话直接安装
yum install mysql-community-client.x86_64
结果报错
报以下密钥错误:
The GPG keys listed for the "MySQL 5.7 Community Server" repository are already installed but they are not correct for this package.
Check that the correct key URLs are configured for this repository.
则先执行以下命令再安装:
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022然后重新安装 yum install mysql-community-client.x86_64
wget -q -O - https://repo.mysql.com/RPM-GPG-KEY-mysql-2022|yum install
操作:
连到数据库:mysql -h 数据库地址 -u数据库用户名 -p数据库密码 -D 数据库名称
mysql -h 88.88.19.252 -utravelplat -pHdkj1234 -D etravel
数据库导出(表结构):mysqldump -h 数据库地址 -u数据库用户名 -p数据库密码 -d 数据库名称 > 文件名.sql
mysqldump -h 88.88.19.252 -utravelplat -pHdkj1234 -d etravel > db20190713.sql
数据库导出(表结构 + 表数据):mysqldump -h 数据库地址 -u数据库用户名 -p数据库密码 数据库名称 > 文件名.sql
mysqldump -h 88.88.19.252 -utravelplat -pHdkj1234 etravel > db20190713.sql
数据库表导出(表结构 + 表数据):
mysqldump -h 88.88.19.252 -utravelplat -pHdkj1234 etravel doc > doc.sql
导入到数据库:source 文件名.sql
source db20190713.sql
收起阅读 »

