
通知设置 新通知
python3 列表推导式 vs map 差别
python • 李魔佛 发表了文章 • 0 个评论 • 4253 次浏览 • 2018-11-22 11:25
速度:
如果map里面是用的lambda,那么map速度会比列表推导式要慢,正常情况map速度稍微快那么一点点。
$ python -mtimeit -s'xs=range(10)' 'map(hex, xs)'
100000 loops, best of 3: 4.86 usec per loop
$ python -mtimeit -s'xs=range(10)' '[hex(x) for x in xs]'
100000 loops, best of 3: 5.58 usec per loop可以看到map稍微快一些
使用lambda$ python -mtimeit -s'xs=range(10)' 'map(lambda x: x+2, xs)'
100000 loops, best of 3: 4.24 usec per loop
$ python -mtimeit -s'xs=range(10)' '[x+2 for x in xs]'
100000 loops, best of 3: 2.32 usec per loop列表推导式稍微快些。
因为map返回的是生成器,所以map对于大容量的操作,不会导致内存爆掉。
而列表推导式则会爆内存,不过也有解决方案,就是使用()替代【】,这时返回的是生成器推导式
>>> [str(n) for n in range(10**100)]谨慎运行上面的,你电脑会卡到爆
如果换成map就不会有问题>>> map(str, range(10**100))
<map object at 0x2201d50>
或者>>> (str(n) for n in range(10**100))
<generator object <genexpr> at 0xacbdef>也不会有问题。
原创文章,转载请注明:
http://30daydo.com/article/378
查看全部
速度:
如果map里面是用的lambda,那么map速度会比列表推导式要慢,正常情况map速度稍微快那么一点点。
$ python -mtimeit -s'xs=range(10)' 'map(hex, xs)'可以看到map稍微快一些
100000 loops, best of 3: 4.86 usec per loop
$ python -mtimeit -s'xs=range(10)' '[hex(x) for x in xs]'
100000 loops, best of 3: 5.58 usec per loop
使用lambda
$ python -mtimeit -s'xs=range(10)' 'map(lambda x: x+2, xs)'列表推导式稍微快些。
100000 loops, best of 3: 4.24 usec per loop
$ python -mtimeit -s'xs=range(10)' '[x+2 for x in xs]'
100000 loops, best of 3: 2.32 usec per loop
因为map返回的是生成器,所以map对于大容量的操作,不会导致内存爆掉。
而列表推导式则会爆内存,不过也有解决方案,就是使用()替代【】,这时返回的是生成器推导式
>>> [str(n) for n in range(10**100)]谨慎运行上面的,你电脑会卡到爆如果换成map就不会有问题
>>> map(str, range(10**100))
<map object at 0x2201d50>
或者
>>> (str(n) for n in range(10**100))也不会有问题。
<generator object <genexpr> at 0xacbdef>
原创文章,转载请注明:
http://30daydo.com/article/378
对自己狠一点 每天要早起
闲聊 • 李魔佛 发表了文章 • 0 个评论 • 4240 次浏览 • 2018-11-20 15:21
关于早起,现在已经被越来越多的人所推崇,越来越多的人已经开始践行,还有越来越多的人也想参与进来。那当
我们决定开始早起前,首先要问自己3个问题:1、我为什么要早起?
2、怎样才能早起?
3、早起干什么?
下面我就我个人实践的经验来给大家做一些分享。
一、我为什么要早起?
在我还没有开始4点起床前,我的生活状态基本是:早上起来做早餐、早餐完送孩子上学、上班、下班、去接孩子,回家做饭、辅导孩子功课,讲故事,等一切都收拾妥当后,发现早已经9点多了。自己感觉每天都在争分夺秒,过着打仗一般的生活,我相信很多有孩子的,特别是自己带孩子的妈妈们,特别能感同身受。自己想做的、想学的太多,可属于自己的时间却是那么少。
我试过很多种方法来挤时间学习,比如利用上下班的通勤时间看书听音频,但发现只能看一些比较浅显的书,音频也听的不是很清楚,因为地铁里声音比较嘈杂,特别是早晚高峰期。再比如每晚孩子休息后再学习,但发现自己只要看有深度的书,头脑就开始混沌,学习效率也非常低。后来我通过看一些书,比如《4点起床》、《哈佛凌晨4点半》、吉田穗波的《就因为没时间,才什么都能办到》,反复实践,摸索出适合自己的频率。那就是早起学习,自己早晨学习最不受打扰,学习效率也最高,后来逐渐地把早起时间调整为4点。
二、怎样才能早起?既然决定了早起,那就去做吧,我们很多人可能平时都是7点左右才起床,如果让他突然6点、甚至更早起床,可能会不适应,也有可能会发现自己坚持不下来,断断续续,最终放弃。
我个人的经验是这样的。
第一:保证早睡,这是早起的前提
如果做不到这个前提,那早起也就变得很困难。
比如:我是4点起,那我晚上最晚10点要睡觉。
第二、设定闹钟
对于刚开始实践早起的人来说,肯定是需要设定闹钟的,等后期自己的生物钟固定下来之后,就不需要闹钟,到时候就会自然醒。
我之前公司有一位保洁大叔,他就是每天4点起床,4:30出门跑步1小时,5:30回来吃早饭,6点上班。几十年如一日,早起从不需要闹钟。
我一般会设定2个闹钟:
第一个是早睡的闹钟,因为很多时候我们会因为各种事情而忘记时间,一不小心就过了时间,拖到很晚。比如我决定10点睡,那我会设一个9:50的闹钟,闹钟一响,就会赶紧洗漱准备睡觉。
第二个是早起闹钟:
比如我是4点起床,我会设一个4点的闹钟。
第三:我们设定早起时间时要循序渐进
比如,你原先是早上7:30起床,你一下就把目标设定在4点起床,那第二天你要么是根本起不来,要么是起来了,但一整天精神不是很好。
你可以每次把早起时间向前调整半小时,适应一周后,再向前调整半小时,直到调整为你的理想起床时间。
注意:这里有一个很重要的点,就是不带手机进卧室。
因为带手机进卧室后,你可能会情不自禁地又看手机,过了休息时间,等你意识到的时候,可能已经是半小时之后,如果刷手机太投入的话,可能是1小时之后,然后你很有可能对自己说,要不我调整一下明天早起的时间或者明天我就暂时不早起吧。
特别是周末,我们一到周末,身心就会自动进入放松模式,只要有了这个想法,你便会用各种理由说服自己,比如,“难得周末,该放松了,晚点睡,熬点夜没关系”,显然这样的话,第二天就不能早起了。
我们永远都不要高估了自己的自制力。
如果必须要带的话,也请把手机放在你伸手够不到的地方,这样闹钟一响,你就必须要起床才能关掉。
我个人原先也是用手机设定闹钟,因为我起床比较早,会影响家人。所以后来我就不用手机,用手环,在app里设定好闹钟时间,戴在手上,一到时间,它就会振动,只有自己知道,也不会影响到他人。手环一振动,我便起床,绝不在床上拖延。因为你只要一拖延,可能5分钟就过去,更有可能就又睡着了。
三、早起干什么?
这是重中之重,也是你早起的动力。
我们不是为了早起而早起,如果我们早起了,却没有有效利用,那就枉费了早起。
一定要给自己设定一个清晰的早起目标。有目标,你才会更有动力。
我个人一般早起后,就会打开事先设定好的音频,可以是课程、听书、演讲,中文、英文都可以,最好是有些鼓舞人心,激昂上进的,这样比较容易把你从混沌的状态拉回清醒状态。
然后就是一边听音频,一边洗漱、喝水、做一些简单的拉伸运动,大概15分钟。
一切完毕后,关掉音频,回书房开始晨间学习。这里我建议大家在前一天晚上就列好计划清单,事先准备好,这样早上就可以直接开始,而不需要额外的花时间。
我会把重要的,有难度的事情安排在早上。比如我的晨间一般是深度阅读、学习英语、晨间反思、写文。这边我觉得早起之后要做的事最好是与你未来的某个目标是有关联的。
5:50准备出门跑步,一般跑步30-40分钟。
6:40左右到家,开始做早餐,和家人一起吃早餐,送孩子上学,开始新的一天。
四、早起带来怎样的影响?
首先是对我个人的影响。
最显著的影响就是,早起让我每天比别人多出了时间来学习和运动。
早起的学习效率特别高。每天凌晨4点,外面漆黑一片,到处都是一片安宁,你会有一种仿佛拥有了全世界的感觉。当窗外的天空一点点变亮,而你计划清单上的事项也一项项的完成的时候,那种成就感是无法比拟的。
早起让我有了更多的反思和自省。我会在晨间或者跑步的时候,进行一些反思,总结过去,展望未来,让自己不断的精进。
因为早起,我拥有了一段不被打扰的时间,可以高效地做自己想做的事情,活出升级版的自己。
其次早起对我家人所产生的影响。
因为我喜欢早起,我女儿也深受我影响,喜欢早起。当别的同龄人还需要闹钟或者父母叫才能起床的时候,她已经可以做到每天自己起床,从不需要闹钟。
我先生因为工作的关系,下班都会比较晚。经常是他回来了女儿睡了,或者女儿准备上学了他还没起床,所以缺少很多和女儿交流的机会。再加上女儿早起后喜欢听书,有时候也会打扰他休息。
所以我就和女儿沟通,建议她起床后,可以先看书然后再听书。
我和先生沟通,建议他早睡早起,把晚上的学习,调整到早上,尽量和我们保持同频,这样女儿也不会打扰到他,他和女儿之间也有了更多亲子交流的机会。
当他们践行这一约定的第二天,我跑步回来后,一打开门,就看到女儿在自己的书桌那看书,先生在书房学习,当时我脑海中就出现了一句话,“一切都是美好的样子。”随后的景象便是我在厨房边做早饭边听书,女儿在客厅听书,先生在书房学习,一家人可以在早上一起共享美好时光。现在这样的景象已是我们家的常态。
最后的几点小建议:
1、每个人的情况都是不一样的。
比如我先生,他需要8小时的睡眠时间,而我可能只需要6个多小时。因为这个世界上的确存在一些不需要睡那么久,但精力依然很旺盛的人。所以我们不一定要和别人一样,只要找到适合自己的频率就行。
2、条件允许的前提下,可以给自己每天安排15-20分钟的午睡,它可以让你下午和晚上的工作和学习精力更充沛。
3、早起的前提,一定一定是早睡
如果做不到早睡,一切都是空谈。
我非常喜欢南怀瑾大师的一句话,他说,“能够早起的人,方能控制人生。”
生命太短,没有时间留给遗憾。最后愿大家都能在早起的这段时光里,收获一个不一样的人生。
我今天的分享就到这里,感谢大家的聆听!
PS:非常喜欢今天早起打卡的一段话,“懂得跟过去的自己握手言和,把时间用在进步而不是抱怨上,学会看淡别人的评价,慢慢的变得内心强大,多读书,早些起,然后变得善良、清澈、温暖而有力量。”共勉!
查看全部
关于早起,现在已经被越来越多的人所推崇,越来越多的人已经开始践行,还有越来越多的人也想参与进来。那当
我们决定开始早起前,首先要问自己3个问题:1、我为什么要早起?
2、怎样才能早起?
3、早起干什么?
下面我就我个人实践的经验来给大家做一些分享。
一、我为什么要早起?
在我还没有开始4点起床前,我的生活状态基本是:早上起来做早餐、早餐完送孩子上学、上班、下班、去接孩子,回家做饭、辅导孩子功课,讲故事,等一切都收拾妥当后,发现早已经9点多了。自己感觉每天都在争分夺秒,过着打仗一般的生活,我相信很多有孩子的,特别是自己带孩子的妈妈们,特别能感同身受。自己想做的、想学的太多,可属于自己的时间却是那么少。
我试过很多种方法来挤时间学习,比如利用上下班的通勤时间看书听音频,但发现只能看一些比较浅显的书,音频也听的不是很清楚,因为地铁里声音比较嘈杂,特别是早晚高峰期。再比如每晚孩子休息后再学习,但发现自己只要看有深度的书,头脑就开始混沌,学习效率也非常低。后来我通过看一些书,比如《4点起床》、《哈佛凌晨4点半》、吉田穗波的《就因为没时间,才什么都能办到》,反复实践,摸索出适合自己的频率。那就是早起学习,自己早晨学习最不受打扰,学习效率也最高,后来逐渐地把早起时间调整为4点。
二、怎样才能早起?既然决定了早起,那就去做吧,我们很多人可能平时都是7点左右才起床,如果让他突然6点、甚至更早起床,可能会不适应,也有可能会发现自己坚持不下来,断断续续,最终放弃。
我个人的经验是这样的。
第一:保证早睡,这是早起的前提
如果做不到这个前提,那早起也就变得很困难。
比如:我是4点起,那我晚上最晚10点要睡觉。
第二、设定闹钟
对于刚开始实践早起的人来说,肯定是需要设定闹钟的,等后期自己的生物钟固定下来之后,就不需要闹钟,到时候就会自然醒。
我之前公司有一位保洁大叔,他就是每天4点起床,4:30出门跑步1小时,5:30回来吃早饭,6点上班。几十年如一日,早起从不需要闹钟。
我一般会设定2个闹钟:
第一个是早睡的闹钟,因为很多时候我们会因为各种事情而忘记时间,一不小心就过了时间,拖到很晚。比如我决定10点睡,那我会设一个9:50的闹钟,闹钟一响,就会赶紧洗漱准备睡觉。
第二个是早起闹钟:
比如我是4点起床,我会设一个4点的闹钟。
第三:我们设定早起时间时要循序渐进
比如,你原先是早上7:30起床,你一下就把目标设定在4点起床,那第二天你要么是根本起不来,要么是起来了,但一整天精神不是很好。
你可以每次把早起时间向前调整半小时,适应一周后,再向前调整半小时,直到调整为你的理想起床时间。
注意:这里有一个很重要的点,就是不带手机进卧室。
因为带手机进卧室后,你可能会情不自禁地又看手机,过了休息时间,等你意识到的时候,可能已经是半小时之后,如果刷手机太投入的话,可能是1小时之后,然后你很有可能对自己说,要不我调整一下明天早起的时间或者明天我就暂时不早起吧。
特别是周末,我们一到周末,身心就会自动进入放松模式,只要有了这个想法,你便会用各种理由说服自己,比如,“难得周末,该放松了,晚点睡,熬点夜没关系”,显然这样的话,第二天就不能早起了。
我们永远都不要高估了自己的自制力。
如果必须要带的话,也请把手机放在你伸手够不到的地方,这样闹钟一响,你就必须要起床才能关掉。
我个人原先也是用手机设定闹钟,因为我起床比较早,会影响家人。所以后来我就不用手机,用手环,在app里设定好闹钟时间,戴在手上,一到时间,它就会振动,只有自己知道,也不会影响到他人。手环一振动,我便起床,绝不在床上拖延。因为你只要一拖延,可能5分钟就过去,更有可能就又睡着了。
三、早起干什么?
这是重中之重,也是你早起的动力。
我们不是为了早起而早起,如果我们早起了,却没有有效利用,那就枉费了早起。
一定要给自己设定一个清晰的早起目标。有目标,你才会更有动力。
我个人一般早起后,就会打开事先设定好的音频,可以是课程、听书、演讲,中文、英文都可以,最好是有些鼓舞人心,激昂上进的,这样比较容易把你从混沌的状态拉回清醒状态。
然后就是一边听音频,一边洗漱、喝水、做一些简单的拉伸运动,大概15分钟。
一切完毕后,关掉音频,回书房开始晨间学习。这里我建议大家在前一天晚上就列好计划清单,事先准备好,这样早上就可以直接开始,而不需要额外的花时间。
我会把重要的,有难度的事情安排在早上。比如我的晨间一般是深度阅读、学习英语、晨间反思、写文。这边我觉得早起之后要做的事最好是与你未来的某个目标是有关联的。
5:50准备出门跑步,一般跑步30-40分钟。
6:40左右到家,开始做早餐,和家人一起吃早餐,送孩子上学,开始新的一天。
四、早起带来怎样的影响?
首先是对我个人的影响。
最显著的影响就是,早起让我每天比别人多出了时间来学习和运动。
早起的学习效率特别高。每天凌晨4点,外面漆黑一片,到处都是一片安宁,你会有一种仿佛拥有了全世界的感觉。当窗外的天空一点点变亮,而你计划清单上的事项也一项项的完成的时候,那种成就感是无法比拟的。
早起让我有了更多的反思和自省。我会在晨间或者跑步的时候,进行一些反思,总结过去,展望未来,让自己不断的精进。
因为早起,我拥有了一段不被打扰的时间,可以高效地做自己想做的事情,活出升级版的自己。
其次早起对我家人所产生的影响。
因为我喜欢早起,我女儿也深受我影响,喜欢早起。当别的同龄人还需要闹钟或者父母叫才能起床的时候,她已经可以做到每天自己起床,从不需要闹钟。
我先生因为工作的关系,下班都会比较晚。经常是他回来了女儿睡了,或者女儿准备上学了他还没起床,所以缺少很多和女儿交流的机会。再加上女儿早起后喜欢听书,有时候也会打扰他休息。
所以我就和女儿沟通,建议她起床后,可以先看书然后再听书。
我和先生沟通,建议他早睡早起,把晚上的学习,调整到早上,尽量和我们保持同频,这样女儿也不会打扰到他,他和女儿之间也有了更多亲子交流的机会。
当他们践行这一约定的第二天,我跑步回来后,一打开门,就看到女儿在自己的书桌那看书,先生在书房学习,当时我脑海中就出现了一句话,“一切都是美好的样子。”随后的景象便是我在厨房边做早饭边听书,女儿在客厅听书,先生在书房学习,一家人可以在早上一起共享美好时光。现在这样的景象已是我们家的常态。
最后的几点小建议:
1、每个人的情况都是不一样的。
比如我先生,他需要8小时的睡眠时间,而我可能只需要6个多小时。因为这个世界上的确存在一些不需要睡那么久,但精力依然很旺盛的人。所以我们不一定要和别人一样,只要找到适合自己的频率就行。
2、条件允许的前提下,可以给自己每天安排15-20分钟的午睡,它可以让你下午和晚上的工作和学习精力更充沛。
3、早起的前提,一定一定是早睡
如果做不到早睡,一切都是空谈。
我非常喜欢南怀瑾大师的一句话,他说,“能够早起的人,方能控制人生。”
生命太短,没有时间留给遗憾。最后愿大家都能在早起的这段时光里,收获一个不一样的人生。
我今天的分享就到这里,感谢大家的聆听!
PS:非常喜欢今天早起打卡的一段话,“懂得跟过去的自己握手言和,把时间用在进步而不是抱怨上,学会看淡别人的评价,慢慢的变得内心强大,多读书,早些起,然后变得善良、清澈、温暖而有力量。”共勉!
np.empty() 函数的用法 (有坑)
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 44750 次浏览 • 2018-11-20 11:36
但是实际结果返回:array([[4.67296746e-307, 1.69121096e-306, 9.34601642e-307,
1.33511562e-306],
[8.34447260e-308, 6.23043768e-307, 2.22522597e-306,
1.33511969e-306],
[1.37962320e-306, 9.34604358e-307, 9.79101082e-307,
1.78020576e-306],
[1.69119873e-306, 2.22522868e-306, 1.24611809e-306,
8.06632139e-308]])
what ?
感觉里面的元素是随机生成的。
查了下官方文档,的确是。np.empty()返回一个随机元素的矩阵,大小按照参数定义。
所以使用的时候要小心。需要手工把每一个值重新定义,否则该值是一个随机数,调试起来会比较麻烦。
原创文章
转载请注明出处:
http://www.30daydo.com/article/376
查看全部
但是实际结果返回:
array([[4.67296746e-307, 1.69121096e-306, 9.34601642e-307,
1.33511562e-306],
[8.34447260e-308, 6.23043768e-307, 2.22522597e-306,
1.33511969e-306],
[1.37962320e-306, 9.34604358e-307, 9.79101082e-307,
1.78020576e-306],
[1.69119873e-306, 2.22522868e-306, 1.24611809e-306,
8.06632139e-308]])
what ?
感觉里面的元素是随机生成的。
查了下官方文档,的确是。np.empty()返回一个随机元素的矩阵,大小按照参数定义。
所以使用的时候要小心。需要手工把每一个值重新定义,否则该值是一个随机数,调试起来会比较麻烦。
原创文章
转载请注明出处:
http://www.30daydo.com/article/376
Hbase thrift python3不兼容
数据库 • 李魔佛 发表了文章 • 0 个评论 • 3026 次浏览 • 2018-11-19 18:26
无奈只好切换到py2的虚拟环境。
无奈只好切换到py2的虚拟环境。
Hbase添加一个列族
数据库 • 李魔佛 发表了文章 • 0 个评论 • 12635 次浏览 • 2018-11-19 16:52
alter 'tablename', 'columnfamily2'
然后就可以插入新的数据了。
alter 'tablename', 'columnfamily2'
然后就可以插入新的数据了。
centos 7 自带的jdk路径
Linux • 李魔佛 发表了文章 • 0 个评论 • 4247 次浏览 • 2018-11-19 14:46
需要自己去输入
jdk路径如下:
/etc/alternatives/java_sdk_1.8.0_openjdk
然后创建环境变量:
export JAVA_HOME=/etc/alternatives/java_sdk_1.8.0_openjdk
这样省去了到官网下载JDK和配置的时间了。
查看全部
需要自己去输入
jdk路径如下:
/etc/alternatives/java_sdk_1.8.0_openjdk
然后创建环境变量:
export JAVA_HOME=/etc/alternatives/java_sdk_1.8.0_openjdk
这样省去了到官网下载JDK和配置的时间了。
海通证券 可转债转股 失败的原因
股票 • 李魔佛 发表了文章 • 0 个评论 • 7133 次浏览 • 2018-11-14 15:13
后面问了客服才知道,可转债转股会冻结千分之三的资金。转股后资金就会解冻。实际上转债不需要手续费。

后面问了客服才知道,可转债转股会冻结千分之三的资金。转股后资金就会解冻。实际上转债不需要手续费。
NLTK基础教程 用nltk和python库构建机器学习应用 笔记与勘误
书籍 • 李魔佛 发表了文章 • 0 个评论 • 2929 次浏览 • 2018-11-13 13:55
1. 第6页:
lst[0:2]
这个应该是list的前2位,不是前3位。(不应该啊,这么基础的都会错)
输出是1,2
2. 第25页
wlem.lemmatize('ate') 改为
wlem.lemmatize('ate','v’)
需要手工添加一个动词v,才能够识别到词性的原型。
查看全部

勘误:
1. 第6页:
lst[0:2]
这个应该是list的前2位,不是前3位。(不应该啊,这么基础的都会错)
输出是1,2
2. 第25页
wlem.lemmatize('ate') 改为
wlem.lemmatize('ate','v’)
需要手工添加一个动词v,才能够识别到词性的原型。
docker下载的ElasticSearch镜像 web/postman访问时需要密码,如何去除
数据库 • 李魔佛 发表了文章 • 0 个评论 • 3943 次浏览 • 2018-11-13 11:40
可是在postman中请求接口:
GET : 10.18.6.102:9200/_cat/indices?v
爆出下面的错误:
missing authentication token for REST request
然后使用浏览器查询:发现需要输入账户和密码。
账户名:elastic
密码:changeme
如何才能删除这个用户名和密码呢? 每次请求不需要密码。
进入docker容器
修改这个文件
/usr/share/elasticsearch/config/elasticssearch.yml
添加最后一行:
xpack.security.enabled: false
然后记得commit一下你的修改。
查看全部
可是在postman中请求接口:
GET : 10.18.6.102:9200/_cat/indices?v
爆出下面的错误:
missing authentication token for REST request
然后使用浏览器查询:发现需要输入账户和密码。
账户名:elastic
密码:changeme
如何才能删除这个用户名和密码呢? 每次请求不需要密码。
进入docker容器
修改这个文件
/usr/share/elasticsearch/config/elasticssearch.yml
添加最后一行:
xpack.security.enabled: false
然后记得commit一下你的修改。
Docker ElasticSearch挂载本地数据 报错
数据库 • 李魔佛 发表了文章 • 0 个评论 • 11212 次浏览 • 2018-11-13 10:37
挂载命令:docker run -p 9200:9200 -e "http.host=0.0.0.0" -e "transport.host=127.0.0.1" -v /home/myuser/elastic_data/:/usr/share/elasticsearch/data docker.elastic.co/elasticsearch/elasticsearch:5.5.1
其中-v是指定的挂载路径
/home/myuser/elastic_data/
这个是本地路径
运行后报错:[2018-11-13T02:23:33,994][INFO ][o.e.n.Node ] initializing ...
[2018-11-13T02:23:34,010][WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.IllegalStateException: Failed to create node environment
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:127) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:114) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:67) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:122) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.cli.Command.main(Command.java:88) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:91) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:84) ~[elasticsearch-5.5.1.jar:5.5.1]
Caused by: java.lang.IllegalStateException: Failed to create node environment
at org.elasticsearch.node.Node.<init>(Node.java:267) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.node.Node.<init>(Node.java:244) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:232) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:232) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:351) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:123) ~[elasticsearch-5.5.1.jar:5.5.1]
... 6 more
Caused by: java.nio.file.AccessDeniedException: /usr/share/elasticsearch/data/nodes
at sun.nio.fs.UnixException.translateToIOException(UnixException.java:84) ~[?:?]
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:102) ~[?:?]
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:107) ~[?:?]
at sun.nio.fs.UnixFileSystemProvider.createDirectory(UnixFileSystemProvider.java:384) ~[?:?]
at java.nio.file.Files.createDirectory(Files.java:674) ~[?:1.8.0_141]
at java.nio.file.Files.createAndCheckIsDirectory(Files.java:781) ~[?:1.8.0_141]
at java.nio.file.Files.createDirectories(Files.java:767) ~[?:1.8.0_141]
at org.elasticsearch.env.NodeEnvironment.<init>(NodeEnvironment.java:221) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.node.Node.<init>(Node.java:264) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.node.Node.<init>(Node.java:244) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:232) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:232) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:351) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:123) ~[elasticsearch-5.5.1.jar:5.5.1]
... 6 more
原因是权限问题,需要把目录
/home/myuser/elastic_data/ 改为777, 然后问题就解决了chmod 777 /home/myuser/elastic_data/
原创文章
转载请注明出处:
http://30daydo.com/article/369
查看全部
挂载命令:
docker run -p 9200:9200 -e "http.host=0.0.0.0" -e "transport.host=127.0.0.1" -v /home/myuser/elastic_data/:/usr/share/elasticsearch/data docker.elastic.co/elasticsearch/elasticsearch:5.5.1
其中-v是指定的挂载路径
/home/myuser/elastic_data/
这个是本地路径
运行后报错:
[2018-11-13T02:23:33,994][INFO ][o.e.n.Node ] initializing ...
[2018-11-13T02:23:34,010][WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.IllegalStateException: Failed to create node environment
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:127) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:114) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:67) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:122) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.cli.Command.main(Command.java:88) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:91) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:84) ~[elasticsearch-5.5.1.jar:5.5.1]
Caused by: java.lang.IllegalStateException: Failed to create node environment
at org.elasticsearch.node.Node.<init>(Node.java:267) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.node.Node.<init>(Node.java:244) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:232) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:232) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:351) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:123) ~[elasticsearch-5.5.1.jar:5.5.1]
... 6 more
Caused by: java.nio.file.AccessDeniedException: /usr/share/elasticsearch/data/nodes
at sun.nio.fs.UnixException.translateToIOException(UnixException.java:84) ~[?:?]
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:102) ~[?:?]
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:107) ~[?:?]
at sun.nio.fs.UnixFileSystemProvider.createDirectory(UnixFileSystemProvider.java:384) ~[?:?]
at java.nio.file.Files.createDirectory(Files.java:674) ~[?:1.8.0_141]
at java.nio.file.Files.createAndCheckIsDirectory(Files.java:781) ~[?:1.8.0_141]
at java.nio.file.Files.createDirectories(Files.java:767) ~[?:1.8.0_141]
at org.elasticsearch.env.NodeEnvironment.<init>(NodeEnvironment.java:221) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.node.Node.<init>(Node.java:264) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.node.Node.<init>(Node.java:244) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:232) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:232) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:351) ~[elasticsearch-5.5.1.jar:5.5.1]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:123) ~[elasticsearch-5.5.1.jar:5.5.1]
... 6 more
原因是权限问题,需要把目录
/home/myuser/elastic_data/ 改为777, 然后问题就解决了
chmod 777 /home/myuser/elastic_data/
原创文章
转载请注明出处:
http://30daydo.com/article/369
elasticsearch-head连接不上elasticsearch服务器
数据库 • 李魔佛 发表了文章 • 0 个评论 • 3809 次浏览 • 2018-11-13 09:21
查看全部

MongoDB数据导入到ElasticSearch python代码实现
数据库 • 李魔佛 发表了文章 • 0 个评论 • 4194 次浏览 • 2018-11-12 14:13
ret = collection.find({})
# 删除mongo的_id字段,否则无法把Object类型插入到Elastic
map(lambda x:(del x['_id']),ret)
actions=
for idx,item in enumerate(ret):
i={
"_index":"jsl",
"_type":"text",
"_id":idx,
"_source":{
# 需要提取的字段
"title":item.get('title'),
"url":item.get('url')
}
}
actions.append(i)
start=time.time()
helpers.bulk(es,actions)
end=time.time()-start
print(end)
运行下来,20W条数据,大概用了15秒左右全部导入ElasticSearch 数据库中。 查看全部
es = Elasticsearch(['10.18.6.26:9200'])
ret = collection.find({})
# 删除mongo的_id字段,否则无法把Object类型插入到Elastic
map(lambda x:(del x['_id']),ret)
actions=
for idx,item in enumerate(ret):
i={
"_index":"jsl",
"_type":"text",
"_id":idx,
"_source":{
# 需要提取的字段
"title":item.get('title'),
"url":item.get('url')
}
}
actions.append(i)
start=time.time()
helpers.bulk(es,actions)
end=time.time()-start
print(end)
运行下来,20W条数据,大概用了15秒左右全部导入ElasticSearch 数据库中。
numpy logspace的用法
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 7217 次浏览 • 2018-10-28 17:54
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)[source]
Return numbers spaced evenly on a log scale.
In linear space, the sequence starts at base ** start (base to the power of start) and ends with base ** stop (see endpoint below).
Parameters:
start : float
base ** start is the starting value of the sequence.
stop : float
base ** stop is the final value of the sequence, unless endpoint is False. In that case, num + 1 values are spaced over the interval in log-space, of which all but the last (a sequence of length num) are returned.
num : integer, optional
Number of samples to generate. Default is 50.
endpoint : boolean, optional
If true, stop is the last sample. Otherwise, it is not included. Default is True.
base : float, optional
The base of the log space. The step size between the elements in ln(samples) / ln(base) (or log_base(samples)) is uniform. Default is 10.0.
dtype : dtype
The type of the output array. If dtype is not given, infer the data type from the other input arguments.
Returns:
samples : ndarray
num samples, equally spaced on a log scale
上面是官方的文档,英文说的很明白,但网上尤其是csdn的解释,(其实都是你抄我,我抄你),实在让人看的一头雾水
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
比如 np.logspace(0,10,9)
那么会有结果是:
array([1.00000000e+00, 1.77827941e+01, 3.16227766e+02, 5.62341325e+03,
1.00000000e+05, 1.77827941e+06, 3.16227766e+07, 5.62341325e+08,
1.00000000e+10])
第一位是开始值0,第二位是结束值10,然后在这0-10之间产生9个值,这9个值是均匀分布的,默认包括最后一个结束点,就是0到10的9个等产数列,那么根据等差数列的公式,a1+(n-1)*d=an,算出,d=1.25,那么a1=0,接着a2=1.25,a3=2.5,。。。。。a9=10,然后再对这9个值做已10为底的指数运算,也就是10^0, 10^1.25 , 10^2.5 这样的结果 查看全部
numpy.logspace
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)[source]
Return numbers spaced evenly on a log scale.
In linear space, the sequence starts at base ** start (base to the power of start) and ends with base ** stop (see endpoint below).
Parameters:
start : float
base ** start is the starting value of the sequence.
stop : float
base ** stop is the final value of the sequence, unless endpoint is False. In that case, num + 1 values are spaced over the interval in log-space, of which all but the last (a sequence of length num) are returned.
num : integer, optional
Number of samples to generate. Default is 50.
endpoint : boolean, optional
If true, stop is the last sample. Otherwise, it is not included. Default is True.
base : float, optional
The base of the log space. The step size between the elements in ln(samples) / ln(base) (or log_base(samples)) is uniform. Default is 10.0.
dtype : dtype
The type of the output array. If dtype is not given, infer the data type from the other input arguments.
Returns:
samples : ndarray
num samples, equally spaced on a log scale
上面是官方的文档,英文说的很明白,但网上尤其是csdn的解释,(其实都是你抄我,我抄你),实在让人看的一头雾水
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
比如 np.logspace(0,10,9)
那么会有结果是:
array([1.00000000e+00, 1.77827941e+01, 3.16227766e+02, 5.62341325e+03,
1.00000000e+05, 1.77827941e+06, 3.16227766e+07, 5.62341325e+08,
1.00000000e+10])
第一位是开始值0,第二位是结束值10,然后在这0-10之间产生9个值,这9个值是均匀分布的,默认包括最后一个结束点,就是0到10的9个等产数列,那么根据等差数列的公式,a1+(n-1)*d=an,算出,d=1.25,那么a1=0,接着a2=1.25,a3=2.5,。。。。。a9=10,然后再对这9个值做已10为底的指数运算,也就是10^0, 10^1.25 , 10^2.5 这样的结果
统一社会信用代码真伪校验
python • 李魔佛 发表了文章 • 0 个评论 • 7458 次浏览 • 2018-10-26 11:28
二是在组织机构代码前增加行政区划代码,这个组合不难发现就是税务登记证号码。这样就提高了统一社会代码的兼容性,在过渡期内税务机关可以利用这种嵌套规则更加便利地升级到新的信用代码系统。
三是预留前两位给登记机关和机构类别,这样统一社会信用代码在应用中更加清晰高效,第一位便于登记机关管理,可以作为检索条目,第二位可以准确给组织机构归类,方便细化分管。
四是统一社会信用代码的主体标识码天生具有的大容量。通过数字字母组合,加上指数级增长,可以确保在很长一段时间内无需升位就可容纳大量组织机构。
五是统一社会信用代码位数为18位,和身份证的位数相同,这一巧妙设计在未来“两码管两人”的应用中可以实现登记、检索、填表等统一。
六是统一社会信用代码中内嵌的主体标识码具有校验位,同时自身第十八位也是校验位,与身份证号相比是双校验,确保了号码准确性
第17,18位是校验位,具体的校验规则如下: # -*-coding=utf-8-*-
# @Time : 2018/10/30 15:23
# @File : social_code_gen2.py
# -*- coding: utf-8 -*-
'''
Created on 2017年4月5日
18位统一社会信用代码从2015年10月1日正式实行
@author: rocky
'''
# 统一社会信用代码中不使用I,O,Z,S,V
SOCIAL_CREDIT_CHECK_CODE_DICT = {
'0':0,'1':1,'2':2,'3':3,'4':4,'5':5,'6':6,'7':7,'8':8,'9':9,
'A':10,'B':11,'C':12, 'D':13, 'E':14, 'F':15, 'G':16, 'H':17, 'J':18, 'K':19, 'L':20, 'M':21, 'N':22, 'P':23, 'Q':24,
'R':25, 'T':26, 'U':27, 'W':28, 'X':29, 'Y':30}
# GB11714-1997全国组织机构代码编制规则中代码字符集
ORGANIZATION_CHECK_CODE_DICT = {
'0':0,'1':1,'2':2,'3':3,'4':4,'5':5,'6':6,'7':7,'8':8,'9':9,
'A':10,'B':11,'C':12, 'D':13, 'E':14, 'F':15, 'G':16, 'H':17,'I':18, 'J':19, 'K':20, 'L':21, 'M':22, 'N':23, 'O':24,'P':25, 'Q':26,
'R':27,'S':28, 'T':29, 'U':30,'V':31, 'W':32, 'X':33, 'Y':34,'Z':35}
class UnifiedSocialCreditIdentifier(object):
'''
统一社会信用代码
'''
def __init__(self):
'''
Constructor
'''
def check_social_credit_code(self,code):
'''
校验统一社会信用代码的校验码
计算校验码公式:
C9 = 31-mod(sum(Ci*Wi),31),其中Ci为组织机构代码的第i位字符,Wi为第i位置的加权因子,C9为校验码
'''
# 第i位置上的加权因子
weighting_factor = [1,3,9,27,19,26,16,17,20,29,25,13,8,24,10,30,28]
# 本体代码
ontology_code = code[0:17]
# 校验码
check_code = code[17]
# 计算校验码
tmp_check_code = self.gen_check_code(weighting_factor, ontology_code, 31, SOCIAL_CREDIT_CHECK_CODE_DICT)
if tmp_check_code==check_code:
return True
else:
return False
def check_organization_code(self,code):
'''
校验组织机构代码是否正确,该规则按照GB 11714编制
统一社会信用代码的第9~17位为主体标识码(组织机构代码),共九位字符
计算校验码公式:
C9 = 11-mod(sum(Ci*Wi),11),其中Ci为组织机构代码的第i位字符,Wi为第i位置的加权因子,C9为校验码
@param code: 统一社会信用代码
'''
# 第i位置上的加权因子
weighting_factor = [3,7,9,10,5,8,4,2]
# 第9~17位为主体标识码(组织机构代码)
organization_code = code[8:17]
# 本体代码
ontology_code=organization_code[0:8]
# 校验码
check_code = organization_code[8]
#
print(organization_code,ontology_code,check_code)
# 计算校验码
tmp_check_code = self.gen_check_code(weighting_factor, ontology_code, 11, ORGANIZATION_CHECK_CODE_DICT)
if tmp_check_code==check_code:
return True
else:
return False
def gen_check_code(self,weighting_factor,ontology_code, modulus,check_code_dict):
'''
@param weighting_factor: 加权因子
@param ontology_code:本体代码
@param modulus: 模数
@param check_code_dict: 字符字典
'''
total = 0
for i in range(len(ontology_code)):
if ontology_code[i].isdigit():
print(ontology_code[i] ,weighting_factor[i])
total += int(ontology_code[i]) * weighting_factor[i]
else:
total += check_code_dict[ontology_code[i]]*weighting_factor[i]
diff = modulus - total % modulus
print(diff)
return list(check_code_dict.keys())[list(check_code_dict.values())[diff]]
if __name__ == '__main__':
u = UnifiedSocialCreditIdentifier()
print(u.check_organization_code(code='91421126331832178C'))
print(u.check_social_credit_code(code='91420100052045470K'))
更新:
引用具体的生成规则
如下是《法人和其他组织统一社会信用代码编码规则》的说明。
1 范围
本标准规定了法人和其他组织统一社会信用代码(以下简称统一代码)的术语和定义、构成。本标准适用于对统一代码的编码、信息处理和信息共享交换。
2 规范性引用文件
下列文件对于本文件的应用是必不可少的。凡是注日期的引用文件,仅注日期的版本适用于本文件。凡是不注日期的引用文件,其最新版本(包括所有的修改单)适用于本文件。
GB/T 2260 中华人民共和国行政区划代码GB 11714 全国组织机构代码编制规则GB/T 17710 信息技术 安全技术 校验字符系统
3 术语和定义
下列术语和定义适用于本文件。
3.1 组织机构 organization
企业、事业单位、机关、社会团体及其他依法成立的单位的通称。[GB/T 20091-2006, 定义2.2]
3.2 法人 legal entities
具有民事权利能力和民事行为能力,依法独立享有民事权利和承担民事义务的组织。
3.3 其他组织 other organizations
合法成立、有一定的组织机构和财产,不具备法人资格的组织。
3.4 组织机构代码 organization code
主体标识码 subject identification code按照GB 11714编制,赋予每一个组织机构在全国范围内唯一的,始终不变的识别标识码。
3.5 统一社会信用代码 unified social credit identifier
每一个法人和其他组织在全国范围内唯一的,终身不变的法定身份识别码。
4 统一代码的构成
4.1 结构
统一代码由十八位的阿拉伯数字或大写英文字母(不使用I、O、Z、S、V)组成。
第1位:登记管理部门代码(共一位字符)第2位:机构类别代码(共一位字符)第3位~第8位:登记管理机关行政区划码(共六位阿拉伯数字)第9位~第17位:主体标识码(组织机构代码)(共九位字符)第18位:校验码(共一位字符)
4.2 代码及说明
登记管理部门代码:使用阿拉伯数字或大写英文字母表示。
机构编制:1民政:5工商:9其他:Y
机构类别代码:使用阿拉伯数字或大写英文字母表示。
机构编制机关:11打头机构编制事业单位:12打头机构编制中央编办直接管理机构编制的群众团体:13打头机构编制其他:19打头民政社会团体:51打头民政民办非企业单位:52打头民政基金会:53打头民政其他:59打头工商企业:91打头工商个体工商户:92打头工商农民专业合作社:93打头其他:Y1打头
登记管理机关行政区划码:只能使用阿拉伯数字表示。按照GB/T 2260编码。
主体标识码(组织机构代码):使用阿拉伯数字或英文大写字母表示。按照GB 11714编码。
在实行统一社会信用代码之前,以前的组织机构代码证上的组织机构代码由九位字符组成。格式为XXXXXXXX-Y。前面八位被称为“本体代码”;最后一位被称为“校验码”。校验码和本体代码由一个连字号(-)连接起来。以便让人很容易的看出校验码。但是三证合一后,组织机构的九位字符全部被纳入统一社会信用代码的第9位至第17位,其原有组织机构代码上的连字号不带入统一社会信用代码。
原有组织机构代码上的“校验码”的计算规则是:
例如:某公司的组织机构代码是:59467239-9。那其最后一位的组织机构代码校验码9是如何计算出来的呢?
第一步:取组织机构代码的前八位本体代码为基数。5 9 4 6 7 2 3 9提示:如果本体代码中含有英文大写字母。则A的基数是10,B的基数是11,C的基数是12,依此类推,直到Z的基数是35。
第二步:取加权因子数值。因为组织机构代码的本体代码一共是八位字符。则这八位的加权因子数值从左到右分别是:3、7、9、10、5、8、4、2。
第三步:本体代码基数与对应位数的因子数值相乘。5×3=15,9×7=63,4×9=36,6×10=60,7×5=35,2×8=16,3×4=12,9×2=18第四步:将乘积求和相加。15+63+36+60+35+16+12+18=255第五步:将和数除以11,求余数。255÷11=33,余数是2。第六步:用阿拉伯数字11减去余数,得求校验码的数值。当校验码的数值为10时,校验码用英文大写字母X来表示;当校验码的数值为11时,校验码用0来表示;其余求出的校验码数值就用其本身的阿拉伯数字来表示。11-2=9,因此此公司完整的组织机构代码为 59467239-9。
校验码:使用阿拉伯数字或大写英文字母来表示。校验码的计算方法参照 GB/T 17710。
例如:某公司的统一社会信用代码为91512081MA62K0260E,那其最后一位的校验码E是如何计算出来的呢?
第一步:取统一社会信用代码的前十七位为基数。9 1 5 1 2 0 8 1 21 10 6 2 19 0 2 6 0提示:如果前十七位统一社会信用代码含有英文大写字母(不使用I、O、Z、S、V这五个英文字母)。则英文字母对应的基数分别为:A=10、B=11、C=12、D=13、E=14、F=15、G=16、H=17、J=18、K=19、L=20、M=21、N=22、P=23、Q=24、R=25、T=26、U=27、W=28、X=29、Y=30
第二步:取加权因子数值。因为统一社会信用代码前面前面有十七位字符。则这十七位的加权因子数值从左到右分别是:1、3、9、27、19、26、16、17、20、29、25、13、8、24、10、30、28
第三步:基数与对应位数的因子数值相乘。9×1=9,1×3=3,5×9=45,1×27=27,2×19=38,0×26=0,8×16=1281×17=17,21×20=420,10×29=290,6×25=150,2×13=26,19×8=1520×23=0,2×10=20,6×30=180,0×28=0
第四步:将乘积求和相加。9+3+45+27+38+0+128+17+420+290+150+26+152+0+20+180+0=1495
第五步:将和数除以31,求余数。1495÷31=48,余数是17。
第六步:用阿拉伯数字31减去余数,得求校验码的数值。当校验码的数值为0~9时,就直接用该校验码的数值作为最终的统一社会信用代码的校验码;如果校验码的数值是10~30,则校验码转换为对应的大写英文字母。对应关系为:A=10、B=11、C=12、D=13、E=14、F=15、G=16、H=17、J=18、K=19、L=20、M=21、N=22、P=23、Q=24、R=25、T=26、U=27、W=28、X=29、Y=30
因为,31-17=14,所以该公司完整的统一社会信用代码为 91512081MA62K0260E。
————————————————
统一社会信用代码与原来营业执照注册号、税务登记号、组织机构代码的转换关系
由于18位统一社会信用代码从2015年10月1日才正式实行。当前还有很多系统并没有完全转换到统一社会信用代码上。当您遇到需要让您填写组织机构代码或者税务登记号的时候,您应该如何从统一社会信用代码获取信息呢?
实质上:统一社会信用代码的第九位到第十七位就是原来的组织机构代码。统一社会信用代码的第三位到第十七位绝大多数的情况都是原来的税务登记证号。(不过由于少数发证机构对地方行政区划代码做了规范。所以,有少部分企业的新的统一社会信用代码并不一定的第3位到第8位的阿拉伯数字并一定能完全对应以前的税务登记证号的前六位。)统一社会信用代码无法对应原来营业执照的注册号。当遇到非要您填写营业执照的注册号,又暂时无法识别统一社会信用代码的场合。你则只有拿出以前旧的营业执照查看上面的注册号。
例如:91370200163562681G这个统一社会信用代码。
其组织机构代码是:16356268-1其税务登记号是:370200163562681 如果与之前的税务登记号稍微有所出入,则一般是370200不一致。尤其是00这两位
原创文章,转载请注明出处
http://30daydo.com/article/364
查看全部
一是嵌入了组织机构代码作为主体标识码。通过组织机构代码的唯一性确保社会信用代码不会重码。换言之,组织机构代码的唯一性完美“遗传”给统一社会信用代码。
二是在组织机构代码前增加行政区划代码,这个组合不难发现就是税务登记证号码。这样就提高了统一社会代码的兼容性,在过渡期内税务机关可以利用这种嵌套规则更加便利地升级到新的信用代码系统。
三是预留前两位给登记机关和机构类别,这样统一社会信用代码在应用中更加清晰高效,第一位便于登记机关管理,可以作为检索条目,第二位可以准确给组织机构归类,方便细化分管。
四是统一社会信用代码的主体标识码天生具有的大容量。通过数字字母组合,加上指数级增长,可以确保在很长一段时间内无需升位就可容纳大量组织机构。
五是统一社会信用代码位数为18位,和身份证的位数相同,这一巧妙设计在未来“两码管两人”的应用中可以实现登记、检索、填表等统一。
六是统一社会信用代码中内嵌的主体标识码具有校验位,同时自身第十八位也是校验位,与身份证号相比是双校验,确保了号码准确性
第17,18位是校验位,具体的校验规则如下:
# -*-coding=utf-8-*-
# @Time : 2018/10/30 15:23
# @File : social_code_gen2.py
# -*- coding: utf-8 -*-
'''
Created on 2017年4月5日
18位统一社会信用代码从2015年10月1日正式实行
@author: rocky
'''
# 统一社会信用代码中不使用I,O,Z,S,V
SOCIAL_CREDIT_CHECK_CODE_DICT = {
'0':0,'1':1,'2':2,'3':3,'4':4,'5':5,'6':6,'7':7,'8':8,'9':9,
'A':10,'B':11,'C':12, 'D':13, 'E':14, 'F':15, 'G':16, 'H':17, 'J':18, 'K':19, 'L':20, 'M':21, 'N':22, 'P':23, 'Q':24,
'R':25, 'T':26, 'U':27, 'W':28, 'X':29, 'Y':30}
# GB11714-1997全国组织机构代码编制规则中代码字符集
ORGANIZATION_CHECK_CODE_DICT = {
'0':0,'1':1,'2':2,'3':3,'4':4,'5':5,'6':6,'7':7,'8':8,'9':9,
'A':10,'B':11,'C':12, 'D':13, 'E':14, 'F':15, 'G':16, 'H':17,'I':18, 'J':19, 'K':20, 'L':21, 'M':22, 'N':23, 'O':24,'P':25, 'Q':26,
'R':27,'S':28, 'T':29, 'U':30,'V':31, 'W':32, 'X':33, 'Y':34,'Z':35}
class UnifiedSocialCreditIdentifier(object):
'''
统一社会信用代码
'''
def __init__(self):
'''
Constructor
'''
def check_social_credit_code(self,code):
'''
校验统一社会信用代码的校验码
计算校验码公式:
C9 = 31-mod(sum(Ci*Wi),31),其中Ci为组织机构代码的第i位字符,Wi为第i位置的加权因子,C9为校验码
'''
# 第i位置上的加权因子
weighting_factor = [1,3,9,27,19,26,16,17,20,29,25,13,8,24,10,30,28]
# 本体代码
ontology_code = code[0:17]
# 校验码
check_code = code[17]
# 计算校验码
tmp_check_code = self.gen_check_code(weighting_factor, ontology_code, 31, SOCIAL_CREDIT_CHECK_CODE_DICT)
if tmp_check_code==check_code:
return True
else:
return False
def check_organization_code(self,code):
'''
校验组织机构代码是否正确,该规则按照GB 11714编制
统一社会信用代码的第9~17位为主体标识码(组织机构代码),共九位字符
计算校验码公式:
C9 = 11-mod(sum(Ci*Wi),11),其中Ci为组织机构代码的第i位字符,Wi为第i位置的加权因子,C9为校验码
@param code: 统一社会信用代码
'''
# 第i位置上的加权因子
weighting_factor = [3,7,9,10,5,8,4,2]
# 第9~17位为主体标识码(组织机构代码)
organization_code = code[8:17]
# 本体代码
ontology_code=organization_code[0:8]
# 校验码
check_code = organization_code[8]
#
print(organization_code,ontology_code,check_code)
# 计算校验码
tmp_check_code = self.gen_check_code(weighting_factor, ontology_code, 11, ORGANIZATION_CHECK_CODE_DICT)
if tmp_check_code==check_code:
return True
else:
return False
def gen_check_code(self,weighting_factor,ontology_code, modulus,check_code_dict):
'''
@param weighting_factor: 加权因子
@param ontology_code:本体代码
@param modulus: 模数
@param check_code_dict: 字符字典
'''
total = 0
for i in range(len(ontology_code)):
if ontology_code[i].isdigit():
print(ontology_code[i] ,weighting_factor[i])
total += int(ontology_code[i]) * weighting_factor[i]
else:
total += check_code_dict[ontology_code[i]]*weighting_factor[i]
diff = modulus - total % modulus
print(diff)
return list(check_code_dict.keys())[list(check_code_dict.values())[diff]]
if __name__ == '__main__':
u = UnifiedSocialCreditIdentifier()
print(u.check_organization_code(code='91421126331832178C'))
print(u.check_social_credit_code(code='91420100052045470K'))
更新:
引用具体的生成规则

如下是《法人和其他组织统一社会信用代码编码规则》的说明。
1 范围
本标准规定了法人和其他组织统一社会信用代码(以下简称统一代码)的术语和定义、构成。本标准适用于对统一代码的编码、信息处理和信息共享交换。
2 规范性引用文件
下列文件对于本文件的应用是必不可少的。凡是注日期的引用文件,仅注日期的版本适用于本文件。凡是不注日期的引用文件,其最新版本(包括所有的修改单)适用于本文件。
GB/T 2260 中华人民共和国行政区划代码GB 11714 全国组织机构代码编制规则GB/T 17710 信息技术 安全技术 校验字符系统
3 术语和定义
下列术语和定义适用于本文件。
3.1 组织机构 organization
企业、事业单位、机关、社会团体及其他依法成立的单位的通称。[GB/T 20091-2006, 定义2.2]
3.2 法人 legal entities
具有民事权利能力和民事行为能力,依法独立享有民事权利和承担民事义务的组织。
3.3 其他组织 other organizations
合法成立、有一定的组织机构和财产,不具备法人资格的组织。
3.4 组织机构代码 organization code
主体标识码 subject identification code按照GB 11714编制,赋予每一个组织机构在全国范围内唯一的,始终不变的识别标识码。
3.5 统一社会信用代码 unified social credit identifier
每一个法人和其他组织在全国范围内唯一的,终身不变的法定身份识别码。
4 统一代码的构成
4.1 结构
统一代码由十八位的阿拉伯数字或大写英文字母(不使用I、O、Z、S、V)组成。
第1位:登记管理部门代码(共一位字符)第2位:机构类别代码(共一位字符)第3位~第8位:登记管理机关行政区划码(共六位阿拉伯数字)第9位~第17位:主体标识码(组织机构代码)(共九位字符)第18位:校验码(共一位字符)
4.2 代码及说明
登记管理部门代码:使用阿拉伯数字或大写英文字母表示。
机构编制:1民政:5工商:9其他:Y
机构类别代码:使用阿拉伯数字或大写英文字母表示。
机构编制机关:11打头机构编制事业单位:12打头机构编制中央编办直接管理机构编制的群众团体:13打头机构编制其他:19打头民政社会团体:51打头民政民办非企业单位:52打头民政基金会:53打头民政其他:59打头工商企业:91打头工商个体工商户:92打头工商农民专业合作社:93打头其他:Y1打头
登记管理机关行政区划码:只能使用阿拉伯数字表示。按照GB/T 2260编码。
主体标识码(组织机构代码):使用阿拉伯数字或英文大写字母表示。按照GB 11714编码。
在实行统一社会信用代码之前,以前的组织机构代码证上的组织机构代码由九位字符组成。格式为XXXXXXXX-Y。前面八位被称为“本体代码”;最后一位被称为“校验码”。校验码和本体代码由一个连字号(-)连接起来。以便让人很容易的看出校验码。但是三证合一后,组织机构的九位字符全部被纳入统一社会信用代码的第9位至第17位,其原有组织机构代码上的连字号不带入统一社会信用代码。
原有组织机构代码上的“校验码”的计算规则是:
例如:某公司的组织机构代码是:59467239-9。那其最后一位的组织机构代码校验码9是如何计算出来的呢?
第一步:取组织机构代码的前八位本体代码为基数。5 9 4 6 7 2 3 9提示:如果本体代码中含有英文大写字母。则A的基数是10,B的基数是11,C的基数是12,依此类推,直到Z的基数是35。
第二步:取加权因子数值。因为组织机构代码的本体代码一共是八位字符。则这八位的加权因子数值从左到右分别是:3、7、9、10、5、8、4、2。
第三步:本体代码基数与对应位数的因子数值相乘。5×3=15,9×7=63,4×9=36,6×10=60,7×5=35,2×8=16,3×4=12,9×2=18第四步:将乘积求和相加。15+63+36+60+35+16+12+18=255第五步:将和数除以11,求余数。255÷11=33,余数是2。第六步:用阿拉伯数字11减去余数,得求校验码的数值。当校验码的数值为10时,校验码用英文大写字母X来表示;当校验码的数值为11时,校验码用0来表示;其余求出的校验码数值就用其本身的阿拉伯数字来表示。11-2=9,因此此公司完整的组织机构代码为 59467239-9。
校验码:使用阿拉伯数字或大写英文字母来表示。校验码的计算方法参照 GB/T 17710。
例如:某公司的统一社会信用代码为91512081MA62K0260E,那其最后一位的校验码E是如何计算出来的呢?
第一步:取统一社会信用代码的前十七位为基数。9 1 5 1 2 0 8 1 21 10 6 2 19 0 2 6 0提示:如果前十七位统一社会信用代码含有英文大写字母(不使用I、O、Z、S、V这五个英文字母)。则英文字母对应的基数分别为:A=10、B=11、C=12、D=13、E=14、F=15、G=16、H=17、J=18、K=19、L=20、M=21、N=22、P=23、Q=24、R=25、T=26、U=27、W=28、X=29、Y=30
第二步:取加权因子数值。因为统一社会信用代码前面前面有十七位字符。则这十七位的加权因子数值从左到右分别是:1、3、9、27、19、26、16、17、20、29、25、13、8、24、10、30、28
第三步:基数与对应位数的因子数值相乘。9×1=9,1×3=3,5×9=45,1×27=27,2×19=38,0×26=0,8×16=1281×17=17,21×20=420,10×29=290,6×25=150,2×13=26,19×8=1520×23=0,2×10=20,6×30=180,0×28=0
第四步:将乘积求和相加。9+3+45+27+38+0+128+17+420+290+150+26+152+0+20+180+0=1495
第五步:将和数除以31,求余数。1495÷31=48,余数是17。
第六步:用阿拉伯数字31减去余数,得求校验码的数值。当校验码的数值为0~9时,就直接用该校验码的数值作为最终的统一社会信用代码的校验码;如果校验码的数值是10~30,则校验码转换为对应的大写英文字母。对应关系为:A=10、B=11、C=12、D=13、E=14、F=15、G=16、H=17、J=18、K=19、L=20、M=21、N=22、P=23、Q=24、R=25、T=26、U=27、W=28、X=29、Y=30
因为,31-17=14,所以该公司完整的统一社会信用代码为 91512081MA62K0260E。
————————————————
统一社会信用代码与原来营业执照注册号、税务登记号、组织机构代码的转换关系
由于18位统一社会信用代码从2015年10月1日才正式实行。当前还有很多系统并没有完全转换到统一社会信用代码上。当您遇到需要让您填写组织机构代码或者税务登记号的时候,您应该如何从统一社会信用代码获取信息呢?
实质上:统一社会信用代码的第九位到第十七位就是原来的组织机构代码。统一社会信用代码的第三位到第十七位绝大多数的情况都是原来的税务登记证号。(不过由于少数发证机构对地方行政区划代码做了规范。所以,有少部分企业的新的统一社会信用代码并不一定的第3位到第8位的阿拉伯数字并一定能完全对应以前的税务登记证号的前六位。)统一社会信用代码无法对应原来营业执照的注册号。当遇到非要您填写营业执照的注册号,又暂时无法识别统一社会信用代码的场合。你则只有拿出以前旧的营业执照查看上面的注册号。
例如:91370200163562681G这个统一社会信用代码。
其组织机构代码是:16356268-1其税务登记号是:370200163562681 如果与之前的税务登记号稍微有所出入,则一般是370200不一致。尤其是00这两位
原创文章,转载请注明出处
http://30daydo.com/article/364
报错 ImportError cannot import name patterns Django版本兼容问题
python • 李魔佛 发表了文章 • 0 个评论 • 4899 次浏览 • 2018-10-25 11:20
百度出来的csdn上的结果:https://blog.csdn.net/xudailong_blog/article/details/78313568
就是不对的,我把django降级到1.10,也是报错,明显不对嘛。
官方上说的1.8之后不建议使用,所以应该降级到1.8才可以。
降级命令:
pip install django==1.8
即可。
查看全部
百度出来的csdn上的结果:https://blog.csdn.net/xudailong_blog/article/details/78313568
就是不对的,我把django降级到1.10,也是报错,明显不对嘛。
官方上说的1.8之后不建议使用,所以应该降级到1.8才可以。
降级命令:
pip install django==1.8
即可。
中年 鲁先圣 (摘录至智慧与思维)
闲聊 • 李魔佛 发表了文章 • 0 个评论 • 2470 次浏览 • 2018-10-21 22:02
现在我明白,很多事情不可为,纵使你多么努力也于事无补,所以就不去做。我也明白,世界的规则是如此神奇,你的努力成长,时间最终赋予你的,必将是一种气定神闲的超凡气质。
著名的心理学家津巴多和博弈德有一个关于“时间商”的理论:对待时间的态度,以及运用时间创造价值的能力。
这是真知灼见,看看世界上所有那些卓有建树的人,有哪一个不是时间的主人?俄国作家托尔斯泰,日本作家村上春树,都是每日凌晨四点起床,每天早晨写作五、六个小时,日积月累,成为著作等身的文学巨匠。
相反的是,那些一事无成的人,又有哪一个不是放纵时间、蹉跎岁月的人?
我很庆幸自己,在这么多的人生选择当中,我选择了勤奋与真诚,选择了梦想和远方。而这种选择,到了今天,全部沉淀成一种坚不可摧的超越青春的力量。我从故乡起步,经由无数的山山水水,经由一个个悲欢离合,也经由无数的人和事,把思索与梦想最终塑造成今天的我。
昂首阔步,需要底气;敢于说不,不仅要有底气,还需要资格。
只有每天都走陌生的路,每天都向未知的世界进发,你的领地才会不断扩大;如果每天都在重复自己,你的人生,就永远只能在原点踱步。
其实观察一个人是否强大,只看两点就足够:看他是否总是唉声叹气,看他走路是否昂首挺胸。
如果你总是在意别人是否关注你,那是你把自己看轻了。如果你足够强大,你的光芒,自会照亮整个世界。
北宋朱熹说:“不奋发,则心日颓废;不检束,则心日恣势。”如果一个人不努力,不严格要求自己的行为,则必将放纵而日渐迷惘,也就渐渐迷失了人生的方向。
一直喜欢刘禹锡的《乌衣巷》:“朱雀桥边野草花,乌衣巷口夕阳斜。旧时王谢堂前燕,飞入寻常百姓家。
”当年晋朝的王导、谢安两位宰相府就在乌衣巷里,到了唐朝,相府早已经不知所踪,而那曾经在相府筑巢的紫燕的后代,又在这里的百姓家筑巢了。沧海桑田,白驹过隙,所谓的荣华富贵,不过都是过眼烟云啊。
奥地利作家茨威格说:“所有命运赠送的礼物,都早已在暗中标好了价格。”这话我坚信不疑,我从来不相信天上会掉馅饼,更不相信有什么救世主。我也知道,任何所谓的幸运,背后一定潜藏着代价。
生活总是让我们与各种各样的人相遇,几乎每一天都不断有别样的人生出现在我们的视野里。每一次,当面对一个人的时候,我都在想,这个人怎么把自己的人生打造得这样华丽?或者,这个人怎么把自己弄得这样灰头灰脸、狼败不堪?而我,为什么是目前的我,而没有成为他们中的一个?
一切都不是偶然的,这就是人生的况味吧?
孩子渐渐长大了,我对孩子说,爸爸并没有什么人生的秘诀要告诉你,但是有两句话要你切记:你一定要远离那些每天苦大仇深的人,因为这些人会慢慢侵蚀掉你的正气和阳光;你要与朝气蓬勃、锐气凛凛的人在一起,他们不仅仅会不断激发你的才华,更会给你的人生注入不竭的正能量。 查看全部
现在我明白,很多事情不可为,纵使你多么努力也于事无补,所以就不去做。我也明白,世界的规则是如此神奇,你的努力成长,时间最终赋予你的,必将是一种气定神闲的超凡气质。
著名的心理学家津巴多和博弈德有一个关于“时间商”的理论:对待时间的态度,以及运用时间创造价值的能力。
这是真知灼见,看看世界上所有那些卓有建树的人,有哪一个不是时间的主人?俄国作家托尔斯泰,日本作家村上春树,都是每日凌晨四点起床,每天早晨写作五、六个小时,日积月累,成为著作等身的文学巨匠。
相反的是,那些一事无成的人,又有哪一个不是放纵时间、蹉跎岁月的人?
我很庆幸自己,在这么多的人生选择当中,我选择了勤奋与真诚,选择了梦想和远方。而这种选择,到了今天,全部沉淀成一种坚不可摧的超越青春的力量。我从故乡起步,经由无数的山山水水,经由一个个悲欢离合,也经由无数的人和事,把思索与梦想最终塑造成今天的我。
昂首阔步,需要底气;敢于说不,不仅要有底气,还需要资格。
只有每天都走陌生的路,每天都向未知的世界进发,你的领地才会不断扩大;如果每天都在重复自己,你的人生,就永远只能在原点踱步。
其实观察一个人是否强大,只看两点就足够:看他是否总是唉声叹气,看他走路是否昂首挺胸。
如果你总是在意别人是否关注你,那是你把自己看轻了。如果你足够强大,你的光芒,自会照亮整个世界。
北宋朱熹说:“不奋发,则心日颓废;不检束,则心日恣势。”如果一个人不努力,不严格要求自己的行为,则必将放纵而日渐迷惘,也就渐渐迷失了人生的方向。
一直喜欢刘禹锡的《乌衣巷》:“朱雀桥边野草花,乌衣巷口夕阳斜。旧时王谢堂前燕,飞入寻常百姓家。
”当年晋朝的王导、谢安两位宰相府就在乌衣巷里,到了唐朝,相府早已经不知所踪,而那曾经在相府筑巢的紫燕的后代,又在这里的百姓家筑巢了。沧海桑田,白驹过隙,所谓的荣华富贵,不过都是过眼烟云啊。
奥地利作家茨威格说:“所有命运赠送的礼物,都早已在暗中标好了价格。”这话我坚信不疑,我从来不相信天上会掉馅饼,更不相信有什么救世主。我也知道,任何所谓的幸运,背后一定潜藏着代价。
生活总是让我们与各种各样的人相遇,几乎每一天都不断有别样的人生出现在我们的视野里。每一次,当面对一个人的时候,我都在想,这个人怎么把自己的人生打造得这样华丽?或者,这个人怎么把自己弄得这样灰头灰脸、狼败不堪?而我,为什么是目前的我,而没有成为他们中的一个?
一切都不是偶然的,这就是人生的况味吧?
孩子渐渐长大了,我对孩子说,爸爸并没有什么人生的秘诀要告诉你,但是有两句话要你切记:你一定要远离那些每天苦大仇深的人,因为这些人会慢慢侵蚀掉你的正气和阳光;你要与朝气蓬勃、锐气凛凛的人在一起,他们不仅仅会不断激发你的才华,更会给你的人生注入不竭的正能量。
零起点python机器学习快速入门 读后感
书籍 • 李魔佛 发表了文章 • 0 个评论 • 2949 次浏览 • 2018-10-15 09:24
没想到出书还能够出成这个样子的。书的内容如果压缩一下,估计也就30-40页的内容,因为大部分都是不断的重复垃圾代码。
像import库,代码作者等信息,居然可以占了一页,关键是,这些无用的信息居然还在每个项目中都重复出现。
核心代码就没几句,大部分是输出信息,看起来书本大部分内容都是一样的,只是输出的具体内容不一样。
通篇都是输出 print (df.tail()) 这种格式的。
说实在,大部分内容都是在网上抄袭sklearn官网的,图也是截取官网的。很无趣的一本书,还好是在图书馆借的,花了2小时左右就把书看完了。
想看的真心建议不要买了。上几页样本让大家体验一下。
上面是不同的页,但是内容却无比的相似。
还有代码第一次见这么奇葩的,一行里面写几句python语句;
对训练结果集不做任何的归一化处理。
查看全部

这是第二次读零起点系列的书,这个系列的书没有最烂,只有更烂。
没想到出书还能够出成这个样子的。书的内容如果压缩一下,估计也就30-40页的内容,因为大部分都是不断的重复垃圾代码。
像import库,代码作者等信息,居然可以占了一页,关键是,这些无用的信息居然还在每个项目中都重复出现。
核心代码就没几句,大部分是输出信息,看起来书本大部分内容都是一样的,只是输出的具体内容不一样。
通篇都是输出 print (df.tail()) 这种格式的。
说实在,大部分内容都是在网上抄袭sklearn官网的,图也是截取官网的。很无趣的一本书,还好是在图书馆借的,花了2小时左右就把书看完了。
想看的真心建议不要买了。上几页样本让大家体验一下。



上面是不同的页,但是内容却无比的相似。
还有代码第一次见这么奇葩的,一行里面写几句python语句;
对训练结果集不做任何的归一化处理。
np.asfarray的用法
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 9413 次浏览 • 2018-09-24 10:52
numpy.asfarray(a, dtype=<class 'numpy.float64'>)
Return an array converted to a float type.
Parameters:
a : array_like
The input array.
dtype : str or dtype object, optional
Float type code to coerce input array a. If dtype is one of the ‘int’ dtypes, it is replaced with float64.
Returns:
out : ndarray
The input a as a float ndarray.
用法就是把一个普通的数组转为一个浮点类型的数组:
Examples
>>>
>>> np.asfarray([2, 3])
array([ 2., 3.])
>>> np.asfarray([2, 3], dtype='float')
array([ 2., 3.])
>>> np.asfarray([2, 3], dtype='int8')
array([ 2., 3.]) 查看全部
numpy.asfarray(a, dtype=<class 'numpy.float64'>)
Return an array converted to a float type.
Parameters:
a : array_like
The input array.
dtype : str or dtype object, optional
Float type code to coerce input array a. If dtype is one of the ‘int’ dtypes, it is replaced with float64.
Returns:
out : ndarray
The input a as a float ndarray.
用法就是把一个普通的数组转为一个浮点类型的数组:
Examples
>>>
>>> np.asfarray([2, 3])
array([ 2., 3.])
>>> np.asfarray([2, 3], dtype='float')
array([ 2., 3.])
>>> np.asfarray([2, 3], dtype='int8')
array([ 2., 3.])
jupyter notebook 显示 opencv的图片
python • 李魔佛 发表了文章 • 0 个评论 • 8356 次浏览 • 2018-09-22 22:55
import cv2
from matplotlib import pyplot as plt
import matplotlib
%matplotlib inlineimg = cv2.imread('forest.jpg')
plt.imshow(img)效果如图:
查看全部
import sys
import cv2
from matplotlib import pyplot as plt
import matplotlib
%matplotlib inline
img = cv2.imread('forest.jpg')
plt.imshow(img)效果如图:
python爬虫集思录所有用户的帖子 scrapy写入mongodb数据库
python爬虫 • 李魔佛 发表了文章 • 0 个评论 • 6260 次浏览 • 2018-09-02 21:52
项目采用scrapy的框架,数据写入到mongodb的数据库。 整个站点爬下来大概用了半小时,数据有12w条。
项目中的主要代码如下:
主spider# -*- coding: utf-8 -*-
import re
import scrapy
from scrapy import Request, FormRequest
from jsl.items import JslItem
from jsl import config
import logging
class AllcontentSpider(scrapy.Spider):
name = 'allcontent'
headers = {
'Host': 'www.jisilu.cn', 'Connection': 'keep-alive', 'Pragma': 'no-cache',
'Cache-Control': 'no-cache', 'Accept': 'application/json,text/javascript,*/*;q=0.01',
'Origin': 'https://www.jisilu.cn', 'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/67.0.3396.99Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8',
'Referer': 'https://www.jisilu.cn/login/',
'Accept-Encoding': 'gzip,deflate,br',
'Accept-Language': 'zh,en;q=0.9,en-US;q=0.8'
}
def start_requests(self):
login_url = 'https://www.jisilu.cn/login/'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip,deflate,br', 'Accept-Language': 'zh,en;q=0.9,en-US;q=0.8',
'Cache-Control': 'no-cache', 'Connection': 'keep-alive',
'Host': 'www.jisilu.cn', 'Pragma': 'no-cache', 'Referer': 'https://www.jisilu.cn/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/67.0.3396.99Safari/537.36'}
yield Request(url=login_url, headers=headers, callback=self.login,dont_filter=True)
def login(self, response):
url = 'https://www.jisilu.cn/account/ajax/login_process/'
data = {
'return_url': 'https://www.jisilu.cn/',
'user_name': config.username,
'password': config.password,
'net_auto_login': '1',
'_post_type': 'ajax',
}
yield FormRequest(
url=url,
headers=self.headers,
formdata=data,
callback=self.parse,
dont_filter=True
)
def parse(self, response):
for i in range(1,3726):
focus_url = 'https://www.jisilu.cn/home/explore/sort_type-new__day-0__page-{}'.format(i)
yield Request(url=focus_url, headers=self.headers, callback=self.parse_page,dont_filter=True)
def parse_page(self, response):
nodes = response.xpath('//div[@class="aw-question-list"]/div')
for node in nodes:
each_url=node.xpath('.//h4/a/@href').extract_first()
yield Request(url=each_url,headers=self.headers,callback=self.parse_item,dont_filter=True)
def parse_item(self,response):
item = JslItem()
title = response.xpath('//div[@class="aw-mod-head"]/h1/text()').extract_first()
s = response.xpath('//div[@class="aw-question-detail-txt markitup-box"]').xpath('string(.)').extract_first()
ret = re.findall('(.*?)\.donate_user_avatar', s, re.S)
try:
content = ret[0].strip()
except:
content = None
createTime = response.xpath('//div[@class="aw-question-detail-meta"]/span/text()').extract_first()
resp_no = response.xpath('//div[@class="aw-mod aw-question-detail-box"]//ul/h2/text()').re_first('\d+')
url = response.url
item['title'] = title.strip()
item['content'] = content
try:
item['resp_no']=int(resp_no)
except Exception as e:
logging.warning('e')
item['resp_no']=None
item['createTime'] = createTime
item['url'] = url.strip()
resp =
for index,reply in enumerate(response.xpath('//div[@class="aw-mod-body aw-dynamic-topic"]/div[@class="aw-item"]')):
replay_user = reply.xpath('.//div[@class="pull-left aw-dynamic-topic-content"]//p/a/text()').extract_first()
rep_content = reply.xpath(
'.//div[@class="pull-left aw-dynamic-topic-content"]//div[@class="markitup-box"]/text()').extract_first()
# print rep_content
agree=reply.xpath('.//em[@class="aw-border-radius-5 aw-vote-count pull-left"]/text()').extract_first()
resp.append({replay_user.strip()+'_{}'.format(index): [int(agree),rep_content.strip()]})
item['resp'] = resp
yield item
login函数是模拟登录集思录,通过抓包就可以知道一些上传的data。
然后就是分页去抓取。逻辑很简单。
然后pipeline里面写入mongodb。import pymongo
from collections import OrderedDict
class JslPipeline(object):
def __init__(self):
self.db = pymongo.MongoClient(host='10.18.6.1',port=27017)
# self.user = u'neo牛3' # 修改为指定的用户名 如 毛之川 ,然后找到用户的id,在用户也的源码哪里可以找到 比如持有封基是8132
self.collection = self.db['db_parker']['jsl']
def process_item(self, item, spider):
self.collection.insert(OrderedDict(item))
return item
抓取到的数据入库mongodb:
点击查看大图
原创文章
转载请注明出处:http://30daydo.com/publish/article/351
查看全部
项目采用scrapy的框架,数据写入到mongodb的数据库。 整个站点爬下来大概用了半小时,数据有12w条。
项目中的主要代码如下:
主spider
# -*- coding: utf-8 -*-
import re
import scrapy
from scrapy import Request, FormRequest
from jsl.items import JslItem
from jsl import config
import logging
class AllcontentSpider(scrapy.Spider):
name = 'allcontent'
headers = {
'Host': 'www.jisilu.cn', 'Connection': 'keep-alive', 'Pragma': 'no-cache',
'Cache-Control': 'no-cache', 'Accept': 'application/json,text/javascript,*/*;q=0.01',
'Origin': 'https://www.jisilu.cn', 'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/67.0.3396.99Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8',
'Referer': 'https://www.jisilu.cn/login/',
'Accept-Encoding': 'gzip,deflate,br',
'Accept-Language': 'zh,en;q=0.9,en-US;q=0.8'
}
def start_requests(self):
login_url = 'https://www.jisilu.cn/login/'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip,deflate,br', 'Accept-Language': 'zh,en;q=0.9,en-US;q=0.8',
'Cache-Control': 'no-cache', 'Connection': 'keep-alive',
'Host': 'www.jisilu.cn', 'Pragma': 'no-cache', 'Referer': 'https://www.jisilu.cn/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/67.0.3396.99Safari/537.36'}
yield Request(url=login_url, headers=headers, callback=self.login,dont_filter=True)
def login(self, response):
url = 'https://www.jisilu.cn/account/ajax/login_process/'
data = {
'return_url': 'https://www.jisilu.cn/',
'user_name': config.username,
'password': config.password,
'net_auto_login': '1',
'_post_type': 'ajax',
}
yield FormRequest(
url=url,
headers=self.headers,
formdata=data,
callback=self.parse,
dont_filter=True
)
def parse(self, response):
for i in range(1,3726):
focus_url = 'https://www.jisilu.cn/home/explore/sort_type-new__day-0__page-{}'.format(i)
yield Request(url=focus_url, headers=self.headers, callback=self.parse_page,dont_filter=True)
def parse_page(self, response):
nodes = response.xpath('//div[@class="aw-question-list"]/div')
for node in nodes:
each_url=node.xpath('.//h4/a/@href').extract_first()
yield Request(url=each_url,headers=self.headers,callback=self.parse_item,dont_filter=True)
def parse_item(self,response):
item = JslItem()
title = response.xpath('//div[@class="aw-mod-head"]/h1/text()').extract_first()
s = response.xpath('//div[@class="aw-question-detail-txt markitup-box"]').xpath('string(.)').extract_first()
ret = re.findall('(.*?)\.donate_user_avatar', s, re.S)
try:
content = ret[0].strip()
except:
content = None
createTime = response.xpath('//div[@class="aw-question-detail-meta"]/span/text()').extract_first()
resp_no = response.xpath('//div[@class="aw-mod aw-question-detail-box"]//ul/h2/text()').re_first('\d+')
url = response.url
item['title'] = title.strip()
item['content'] = content
try:
item['resp_no']=int(resp_no)
except Exception as e:
logging.warning('e')
item['resp_no']=None
item['createTime'] = createTime
item['url'] = url.strip()
resp =
for index,reply in enumerate(response.xpath('//div[@class="aw-mod-body aw-dynamic-topic"]/div[@class="aw-item"]')):
replay_user = reply.xpath('.//div[@class="pull-left aw-dynamic-topic-content"]//p/a/text()').extract_first()
rep_content = reply.xpath(
'.//div[@class="pull-left aw-dynamic-topic-content"]//div[@class="markitup-box"]/text()').extract_first()
# print rep_content
agree=reply.xpath('.//em[@class="aw-border-radius-5 aw-vote-count pull-left"]/text()').extract_first()
resp.append({replay_user.strip()+'_{}'.format(index): [int(agree),rep_content.strip()]})
item['resp'] = resp
yield item
login函数是模拟登录集思录,通过抓包就可以知道一些上传的data。
然后就是分页去抓取。逻辑很简单。
然后pipeline里面写入mongodb。
import pymongo
from collections import OrderedDict
class JslPipeline(object):
def __init__(self):
self.db = pymongo.MongoClient(host='10.18.6.1',port=27017)
# self.user = u'neo牛3' # 修改为指定的用户名 如 毛之川 ,然后找到用户的id,在用户也的源码哪里可以找到 比如持有封基是8132
self.collection = self.db['db_parker']['jsl']
def process_item(self, item, spider):
self.collection.insert(OrderedDict(item))
return item
抓取到的数据入库mongodb:

点击查看大图
原创文章
转载请注明出处:http://30daydo.com/publish/article/351
docker里运行mongodb,保存的数据在外部使用mongoexport不能导出:提示错误Unrecognized field 'snapshot'
python • 李魔佛 发表了文章 • 0 个评论 • 10451 次浏览 • 2018-08-31 14:21
很无语。 目前还找不到原因。
docker里面运行的mongodb, mongodb的数据挂载到宿主机。 开放了27017端口。
在windows下使用mongoexport工具导出数据:
错误信息:C:\Program Files\MongoDB\Server\3.4\bin>mongoexport.exe /h 10.18.6.102 /d stock
/c company /o company.json /type json
2018-08-31T14:13:47.841+0800 connected to: 10.18.6.102
2018-08-31T14:13:47.854+0800 Failed: Failed to parse: { find: "company", filt
er: {}, sort: {}, skip: 0, snapshot: true, $readPreference: { mode: "secondaryPr
eferred" }, $db: "stock" }. Unrecognized field 'snapshot'.
C:\Program Files\MongoDB\Server\3.4\bin>
目前这个问题已经解决:
需要进去docker容器里面,然后在容器里面操作,把数据导出来到挂载的目录下,然后可以直接获取到数据了。 查看全部
很无语。 目前还找不到原因。
docker里面运行的mongodb, mongodb的数据挂载到宿主机。 开放了27017端口。
在windows下使用mongoexport工具导出数据:
错误信息:
C:\Program Files\MongoDB\Server\3.4\bin>mongoexport.exe /h 10.18.6.102 /d stock
/c company /o company.json /type json
2018-08-31T14:13:47.841+0800 connected to: 10.18.6.102
2018-08-31T14:13:47.854+0800 Failed: Failed to parse: { find: "company", filt
er: {}, sort: {}, skip: 0, snapshot: true, $readPreference: { mode: "secondaryPr
eferred" }, $db: "stock" }. Unrecognized field 'snapshot'.
C:\Program Files\MongoDB\Server\3.4\bin>
目前这个问题已经解决:
需要进去docker容器里面,然后在容器里面操作,把数据导出来到挂载的目录下,然后可以直接获取到数据了。
django不同版本的兼容性太麻烦了
python • 李魔佛 发表了文章 • 0 个评论 • 3369 次浏览 • 2018-08-26 18:20
哪些淘宝店铺被你列入了黑名单? 让我们一起来曝光
闲聊 • 李魔佛 发表了文章 • 0 个评论 • 4895 次浏览 • 2018-08-25 20:59
1. 以尚牛仔
转至知乎的:
让我来一个。
买了一条牛仔裤,收到货没及时拆开,过了一个多星期再拆发现拉链是坏的,于是就去找卖家。
上来就说我买的时间太久了,一句道歉的话都没说。后面再回她干脆不鸟我了...然后我就给了差评“坏了就是坏了,态度还那么差!连句道歉都没有,现在鸟都不鸟了”。接着又过十天,也就是今天下午,打电话给我让我删了差评,然后再给我退20块赔偿,当时刚睡醒,听她态度还行就同意了。然后挂完电话想说晚点再删,没想到她就开始在淘宝上连环call!我就给她删了。
当时也想过会不会删了就被拉黑名单,但想说刚刚态度不错就没继续怀疑!但是!果然!删完以后态度依旧很十多天前一个样!依旧是保持高冷的态度鸟都不鸟,打电话也不接了!呵呵!然后百度了一下,说这是许多卖家惯用的手段,让你先删了评论给你赔偿,然后等你删了就不理你。
告诫各位下次在淘宝上买的东西不好就是不好,该差评就差评,别被卖家骗了!
告诫各位下次在淘宝上买的东西不好就是不好,该差评就差评,别被卖家骗了!
告诫各位下次在淘宝上买的东西不好就是不好,该差评就差评,别被卖家骗了! 查看全部
1. 以尚牛仔

转至知乎的:
让我来一个。
买了一条牛仔裤,收到货没及时拆开,过了一个多星期再拆发现拉链是坏的,于是就去找卖家。
上来就说我买的时间太久了,一句道歉的话都没说。后面再回她干脆不鸟我了...然后我就给了差评“坏了就是坏了,态度还那么差!连句道歉都没有,现在鸟都不鸟了”。接着又过十天,也就是今天下午,打电话给我让我删了差评,然后再给我退20块赔偿,当时刚睡醒,听她态度还行就同意了。然后挂完电话想说晚点再删,没想到她就开始在淘宝上连环call!我就给她删了。
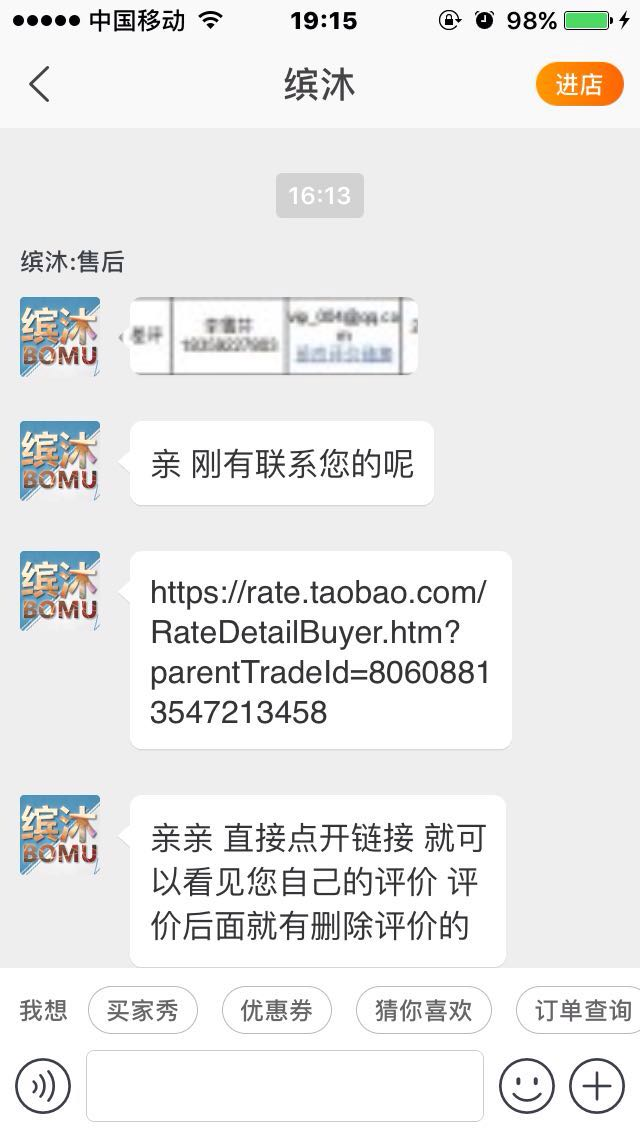
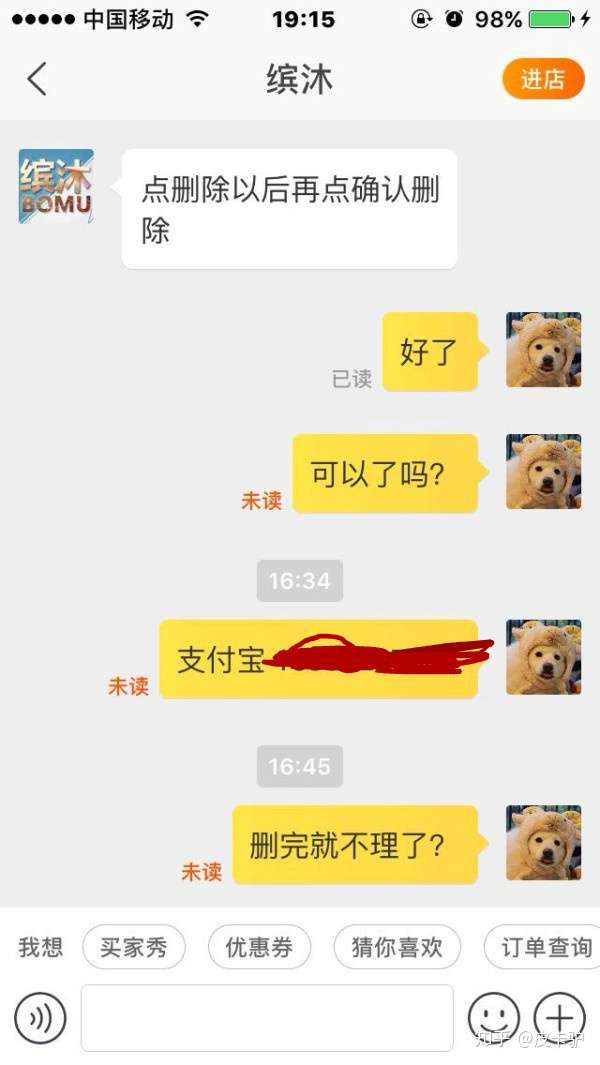
当时也想过会不会删了就被拉黑名单,但想说刚刚态度不错就没继续怀疑!但是!果然!删完以后态度依旧很十多天前一个样!依旧是保持高冷的态度鸟都不鸟,打电话也不接了!呵呵!然后百度了一下,说这是许多卖家惯用的手段,让你先删了评论给你赔偿,然后等你删了就不理你。
告诫各位下次在淘宝上买的东西不好就是不好,该差评就差评,别被卖家骗了!
告诫各位下次在淘宝上买的东西不好就是不好,该差评就差评,别被卖家骗了!
告诫各位下次在淘宝上买的东西不好就是不好,该差评就差评,别被卖家骗了!
python mongodb大数据(>3GB)转移Mysql数据库
python • 李魔佛 发表了文章 • 0 个评论 • 5018 次浏览 • 2018-08-20 15:44
于是使用了分段遍历的方法.# -*-coding=utf-8-*-
import pandas as pd
import json
import pymongo
from sqlalchemy import create_engine
# 将mongo数据转移到mysql
client = pymongo.MongoClient('xxx')
doc = client['spider']['meituan']
engine = create_engine('mysql+pymysql://xxx:xxx@xxx:/xxx?charset=utf8')
def classic_method():
temp =
start = 0
# 数据太大还是会爆内存,或者游标丢失
for i in doc.find().batch_size(500):
start += 1
del i['_id']
temp.append(i)
print(start)
print('start to save to mysql')
df = pd.read_json(json.dumps(temp))
df = df.set_index('poiid', drop=True)
df.to_sql('meituan', con=engine, if_exists='replace')
print('done')
def chunksize_move():
block = 10000
total = doc.find({}).count()
iter_number = total // block
for i in range(iter_number + 1):
small_part = doc.find({}).limit(block).skip(i * block)
list_data =
for item in small_part:
del item['_id']
del item['crawl_time']
item['poiid'] = int(item['poiid'])
for k, v in item.items():
if isinstance(v, dict) or isinstance(v, list):
item[k] = json.dumps(v, ensure_ascii=False)
list_data.append(item)
df = pd.DataFrame(list_data)
df = df.set_index('poiid', drop=True)
try:
df.to_sql('meituan', con=engine, if_exists='append')
print('to sql {}'.format(i))
except Exception as e:
print(e)
chunksize_move()
速度比一次批量的要快不少. 查看全部
for i in doc.find({})进行逐行遍历的话,游标就会超时,而且越到后面速度越慢.于是使用了分段遍历的方法.
# -*-coding=utf-8-*-
import pandas as pd
import json
import pymongo
from sqlalchemy import create_engine
# 将mongo数据转移到mysql
client = pymongo.MongoClient('xxx')
doc = client['spider']['meituan']
engine = create_engine('mysql+pymysql://xxx:xxx@xxx:/xxx?charset=utf8')
def classic_method():
temp =
start = 0
# 数据太大还是会爆内存,或者游标丢失
for i in doc.find().batch_size(500):
start += 1
del i['_id']
temp.append(i)
print(start)
print('start to save to mysql')
df = pd.read_json(json.dumps(temp))
df = df.set_index('poiid', drop=True)
df.to_sql('meituan', con=engine, if_exists='replace')
print('done')
def chunksize_move():
block = 10000
total = doc.find({}).count()
iter_number = total // block
for i in range(iter_number + 1):
small_part = doc.find({}).limit(block).skip(i * block)
list_data =
for item in small_part:
del item['_id']
del item['crawl_time']
item['poiid'] = int(item['poiid'])
for k, v in item.items():
if isinstance(v, dict) or isinstance(v, list):
item[k] = json.dumps(v, ensure_ascii=False)
list_data.append(item)
df = pd.DataFrame(list_data)
df = df.set_index('poiid', drop=True)
try:
df.to_sql('meituan', con=engine, if_exists='append')
print('to sql {}'.format(i))
except Exception as e:
print(e)
chunksize_move()

速度比一次批量的要快不少.
python 把mongodb的数据迁移到mysql
python • 李魔佛 发表了文章 • 0 个评论 • 4523 次浏览 • 2018-08-20 11:02
import pymongo
from setting import get_engine
# 将mongo数据转移到mysql
client = pymongo.MongoClient('10.18.6.101')
doc = client['spider']['meituan']
engine = create_engine('mysql+pymysql://localhost:1234@10.18.4.211/spider?charset=utf8')
temp=[]
for i in doc.find({}):
del i['_id']
temp.append(i)
print('start to save to mysql')
df = pd.read_json(json.dumps(temp))
df = df.set_index('poiid',drop=True)
df.to_sql('meituan',con=engine,if_exists='replace')
print('done')
居然CPU飙到了90%
查看全部
import pymongo
from setting import get_engine
# 将mongo数据转移到mysql
client = pymongo.MongoClient('10.18.6.101')
doc = client['spider']['meituan']
engine = create_engine('mysql+pymysql://localhost:1234@10.18.4.211/spider?charset=utf8')
temp=[]
for i in doc.find({}):
del i['_id']
temp.append(i)
print('start to save to mysql')
df = pd.read_json(json.dumps(temp))
df = df.set_index('poiid',drop=True)
df.to_sql('meituan',con=engine,if_exists='replace')
print('done')

居然CPU飙到了90%
python json.loads 文件中的字典不能用单引号
python • 李魔佛 发表了文章 • 0 个评论 • 5280 次浏览 • 2018-08-20 09:28
只能改成双引号,或者使用
with open('cookies', 'r') as f:
# js = json.load(f)
js=eval(f.read())
# cookie=js.get('Cookie','')
headers = js.get('headers', '')
#content为文件的内容 查看全部
python json.loads 文件中的字典不能用单引号
只能改成双引号,或者使用
with open('cookies', 'r') as f:
# js = json.load(f)
js=eval(f.read())
# cookie=js.get('Cookie','')
headers = js.get('headers', '')
#content为文件的内容
有道云笔记经常会保存丢失
闲聊 • 李魔佛 发表了文章 • 0 个评论 • 3178 次浏览 • 2018-08-19 16:58
## 更新 2019-01-19
今天再次发生,保存的一个网页链接在笔记里,结果3天后居然找不到了,果然神奇。(公司电脑和家里笔记本同步过)
## 更新 2019-01-19
今天再次发生,保存的一个网页链接在笔记里,结果3天后居然找不到了,果然神奇。(公司电脑和家里笔记本同步过)
scrapy记录日志的最新方法
python爬虫 • 李魔佛 发表了文章 • 0 个评论 • 4167 次浏览 • 2018-08-15 15:01
log.msg("This is a warning", level=log.WARING)
在Spider中添加log
在spider中添加log的推荐方式是使用Spider的 log() 方法。该方法会自动在调用 scrapy.log.start() 时赋值 spider 参数。
其它的参数则直接传递给 msg() 方法
scrapy.log模块scrapy.log.start(logfile=None, loglevel=None, logstdout=None)启动log功能。该方法必须在记录任何信息之前被调用。否则调用前的信息将会丢失。
但是运行的时候出现警告:
[py.warnings] WARNING: E:\git\CrawlMan\bilibili\bilibili\spiders\bili.py:14: ScrapyDeprecationWarning: log.msg has been deprecated, create a python logger and log through it instead
log.msg
原来官方以及不推荐使用log.msg了
最新的用法:# -*- coding: utf-8 -*-
import scrapy
from scrapy_splash import SplashRequest
import logging
# from scrapy import log
class BiliSpider(scrapy.Spider):
name = 'ordinary' # 这个名字就是上面连接中那个启动应用的名字
allowed_domain = ["bilibili.com"]
start_urls = [
"https://www.bilibili.com/"
]
def parse(self, response):
logging.info('====================================================')
content = response.xpath("//div[@class='num-wrap']").extract_first()
logging.info(content)
logging.info('====================================================') 查看全部
from scrapy import log
log.msg("This is a warning", level=log.WARING)
在Spider中添加log
在spider中添加log的推荐方式是使用Spider的 log() 方法。该方法会自动在调用 scrapy.log.start() 时赋值 spider 参数。
其它的参数则直接传递给 msg() 方法
scrapy.log模块scrapy.log.start(logfile=None, loglevel=None, logstdout=None)启动log功能。该方法必须在记录任何信息之前被调用。否则调用前的信息将会丢失。
但是运行的时候出现警告:
[py.warnings] WARNING: E:\git\CrawlMan\bilibili\bilibili\spiders\bili.py:14: ScrapyDeprecationWarning: log.msg has been deprecated, create a python logger and log through it instead
log.msg
原来官方以及不推荐使用log.msg了
最新的用法:
# -*- coding: utf-8 -*-
import scrapy
from scrapy_splash import SplashRequest
import logging
# from scrapy import log
class BiliSpider(scrapy.Spider):
name = 'ordinary' # 这个名字就是上面连接中那个启动应用的名字
allowed_domain = ["bilibili.com"]
start_urls = [
"https://www.bilibili.com/"
]
def parse(self, response):
logging.info('====================================================')
content = response.xpath("//div[@class='num-wrap']").extract_first()
logging.info(content)
logging.info('====================================================')
adbapi查询语句 -- python3
python • 李魔佛 发表了文章 • 0 个评论 • 4008 次浏览 • 2018-08-12 19:40
Abstract
Twisted is an asynchronous networking framework, but most database API implementations unfortunately have blocking interfaces -- for this reason, twisted.enterprise.adbapi was created. It is a non-blocking interface to the standardized DB-API 2.0 API, which allows you to access a number of different RDBMSes.
What you should already know
Python :-)
How to write a simple Twisted Server (see this tutorial to learn how)
Familiarity with using database interfaces (see the documentation for DBAPI 2.0 or this article by Andrew Kuchling)
Quick Overview
Twisted is an asynchronous framework. This means standard database modules cannot be used directly, as they typically work something like:# Create connection... db = dbmodule.connect('mydb', 'andrew', 'password') # ...which blocks for an unknown amount of time # Create a cursor cursor = db.cursor() # Do a query... resultset = cursor.query('SELECT * FROM table WHERE ...') # ...which could take a long time, perhaps even minutes.Those delays are unacceptable when using an asynchronous framework such as Twisted. For this reason, twisted provides twisted.enterprise.adbapi, an asynchronous wrapper for any DB-API 2.0-compliant module. It is currently best tested with the pyPgSQL module for PostgreSQL.
enterprise.adbapi will do blocking database operations in seperate threads, which trigger callbacks in the originating thread when they complete. In the meantime, the original thread can continue doing normal work, like servicing other requests.
How do I use adbapi?
Rather than creating a database connection directly, use the adbapi.ConnectionPool class to manage a connections for you. This allows enterprise.adbapi to use multiple connections, one per thread. This is easy:# Using the "dbmodule" from the previous example, create a ConnectionPool from twisted.enterprise import adbapi dbpool = adbapi.ConnectionPool("dbmodule", 'mydb', 'andrew', 'password')Things to note about doing this:
There is no need to import dbmodule directly. You just pass the name to adbapi.ConnectionPool's constructor.
The parameters you would pass to dbmodule.connect are passed as extra arguments to adbapi.ConnectionPool's constructor. Keyword parameters work as well.
You may also control the size of the connection pool with the keyword parameters cp_min and cp_max. The default minimum and maximum values are 3 and 5.
So, now you need to be able to dispatch queries to your ConnectionPool. We do this by subclassing adbapi.Augmentation. Here's an example:class AgeDatabase(adbapi.Augmentation): """A simple example that can retrieve an age from the database""" def getAge(self, name): # Define the query sql = """SELECT Age FROM People WHERE name = ?""" # Run the query, and return a Deferred to the caller to add # callbacks to. return self.runQuery(sql, name) def gotAge(resultlist, name): """Callback for handling the result of the query""" age = resultlist[0][0] # First field of first record print "%s is %d years old" % (name, age) db = AgeDatabase(dbpool) # These will *not* block. Hooray! db.getAge("Andrew").addCallbacks(gotAge, db.operationError, callbackArgs=("Andrew",)) db.getAge("Glyph").addCallbacks(gotAge, db.operationError, callbackArgs=("Glyph",)) # Of course, nothing will happen until the reactor is started from twisted.internet import reactor reactor.run()This is straightforward, except perhaps for the return value of getAge. It returns a twisted.internet.defer.Deferred, which allows arbitrary callbacks to be called upon completion (or upon failure). More documentation on Deferred is available here.
Also worth noting is that this example assumes that dbmodule uses the qmarks paramstyle (see the DB-API specification). If your dbmodule uses a different paramstyle (e.g. pyformat) then use that. Twisted doesn't attempt to offer any sort of magic paramater munging -- runQuery(query, params, ...) maps directly onto cursor.execute(query, params, ...).
And that's it!
That's all you need to know to use a database from within Twisted. You probably should read the adbapi module's documentation to get an idea of the other functions it has, but hopefully this document presents the core ideas. 查看全部
Abstract
Twisted is an asynchronous networking framework, but most database API implementations unfortunately have blocking interfaces -- for this reason, twisted.enterprise.adbapi was created. It is a non-blocking interface to the standardized DB-API 2.0 API, which allows you to access a number of different RDBMSes.
What you should already know
Python :-)
How to write a simple Twisted Server (see this tutorial to learn how)
Familiarity with using database interfaces (see the documentation for DBAPI 2.0 or this article by Andrew Kuchling)
Quick Overview
Twisted is an asynchronous framework. This means standard database modules cannot be used directly, as they typically work something like:# Create connection... db = dbmodule.connect('mydb', 'andrew', 'password') # ...which blocks for an unknown amount of time # Create a cursor cursor = db.cursor() # Do a query... resultset = cursor.query('SELECT * FROM table WHERE ...') # ...which could take a long time, perhaps even minutes.Those delays are unacceptable when using an asynchronous framework such as Twisted. For this reason, twisted provides twisted.enterprise.adbapi, an asynchronous wrapper for any DB-API 2.0-compliant module. It is currently best tested with the pyPgSQL module for PostgreSQL.
enterprise.adbapi will do blocking database operations in seperate threads, which trigger callbacks in the originating thread when they complete. In the meantime, the original thread can continue doing normal work, like servicing other requests.
How do I use adbapi?
Rather than creating a database connection directly, use the adbapi.ConnectionPool class to manage a connections for you. This allows enterprise.adbapi to use multiple connections, one per thread. This is easy:# Using the "dbmodule" from the previous example, create a ConnectionPool from twisted.enterprise import adbapi dbpool = adbapi.ConnectionPool("dbmodule", 'mydb', 'andrew', 'password')Things to note about doing this:
There is no need to import dbmodule directly. You just pass the name to adbapi.ConnectionPool's constructor.
The parameters you would pass to dbmodule.connect are passed as extra arguments to adbapi.ConnectionPool's constructor. Keyword parameters work as well.
You may also control the size of the connection pool with the keyword parameters cp_min and cp_max. The default minimum and maximum values are 3 and 5.
So, now you need to be able to dispatch queries to your ConnectionPool. We do this by subclassing adbapi.Augmentation. Here's an example:class AgeDatabase(adbapi.Augmentation): """A simple example that can retrieve an age from the database""" def getAge(self, name): # Define the query sql = """SELECT Age FROM People WHERE name = ?""" # Run the query, and return a Deferred to the caller to add # callbacks to. return self.runQuery(sql, name) def gotAge(resultlist, name): """Callback for handling the result of the query""" age = resultlist[0][0] # First field of first record print "%s is %d years old" % (name, age) db = AgeDatabase(dbpool) # These will *not* block. Hooray! db.getAge("Andrew").addCallbacks(gotAge, db.operationError, callbackArgs=("Andrew",)) db.getAge("Glyph").addCallbacks(gotAge, db.operationError, callbackArgs=("Glyph",)) # Of course, nothing will happen until the reactor is started from twisted.internet import reactor reactor.run()This is straightforward, except perhaps for the return value of getAge. It returns a twisted.internet.defer.Deferred, which allows arbitrary callbacks to be called upon completion (or upon failure). More documentation on Deferred is available here.
Also worth noting is that this example assumes that dbmodule uses the qmarks paramstyle (see the DB-API specification). If your dbmodule uses a different paramstyle (e.g. pyformat) then use that. Twisted doesn't attempt to offer any sort of magic paramater munging -- runQuery(query, params, ...) maps directly onto cursor.execute(query, params, ...).
And that's it!
That's all you need to know to use a database from within Twisted. You probably should read the adbapi module's documentation to get an idea of the other functions it has, but hopefully this document presents the core ideas.
