
通知设置 新通知
谁说ptrade代码不安全容易泄露的?
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 6 次浏览 • 2025-07-03 11:52
实际上现在的ptrade可以对策略进行加密
可以对你的策略进行加密下载,然后把策略删除了,然后在选择上传策略。
然后策略上传之后,你是无法看到具体代码的了,只能选择启动,删除策略。
连日志里面的打印数据也不会输出。
只会显示买入 卖出 的信息。
大大的提高了策略的安全性。
需要开通ptrade的读者朋友,可以关注公众号联系:
低佣 - 低门槛,提供 技术支持
查看全部
实际上现在的ptrade可以对策略进行加密

可以对你的策略进行加密下载,然后把策略删除了,然后在选择上传策略。
然后策略上传之后,你是无法看到具体代码的了,只能选择启动,删除策略。
连日志里面的打印数据也不会输出。
只会显示买入 卖出 的信息。
大大的提高了策略的安全性。
需要开通ptrade的读者朋友,可以关注公众号联系:
低佣 - 低门槛,提供 技术支持

ptrade查看日志报错:远程服务器返回错误: (502) 错误的网关
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 32 次浏览 • 2025-06-30 18:59
访问这个API的时候就已经报错。
502异常代码,是服务器端的报错。和本地无关。
有时候能够正常查询到日志,但大部分时候查询日志的时候就出现上面的502异常。
揪心,就不能买多几台服务器么.....
查看全部
访问这个API的时候就已经报错。
502异常代码,是服务器端的报错。和本地无关。
有时候能够正常查询到日志,但大部分时候查询日志的时候就出现上面的502异常。

揪心,就不能买多几台服务器么.....
Ptrade获取的L2逐笔数据和同花顺的逐笔数据对不上的原因
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 179 次浏览 • 2025-06-12 16:40
后面有群友 发现了问题。

后面有群友 发现了问题。
国泰海通支持Ptrade,万一免5
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 271 次浏览 • 2025-06-06 13:33
实盘版下载链接:
https://dl2.app.gtja.com/dzswem/softwareVersion/202504/07/PTrade1.0-Client-V202403-07-005(PTrade).zip
需要开通和调佣的,可以关注公众号联系:
查看全部

费率做到免5起步0.01
实盘版下载链接:
https://dl2.app.gtja.com/dzswem/softwareVersion/202504/07/PTrade1.0-Client-V202403-07-005(PTrade).zip
需要开通和调佣的,可以关注公众号联系:
Ptrade获取L2逐笔数据,免费,券商提供
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 568 次浏览 • 2025-05-24 00:22
并且还发现居然可以免费使用L2逐笔数据,分时逐笔委托队列等高频毫秒级的数据
Ptrade接口文档已更新: https://ptradeapi.com
Python 3.5是2015 年发布,Python 3.11是2022 年发布。
性能上来说是有很大的提升,尤其对做回测和高频策略。
如果本身策略很简单或者日线交易的,影响可以忽略不计。
不过这个升级并不是个人可选的,只要你的Ptrade的券商升级了,就只能使用升级后的版本接口格式,旧代码需要做的修改来适配。
性能对比示例(Python 3.5 vs 3.11) By 豆包
以下是部分操作在 Python 3.5 和 3.11 中的性能对比(仅供参考):
并且相应的第三方库版本亦做了升级。
接口变动影响比较大的是pandas在 Python3.11 中,Pandas已不再支持Panel格式。
pandas里的Pannel类型是用于存储三维或以上的矩阵数据。
而升级后就不支持之前的多维行情数据格式。但笔者觉得现在更加统一和简单。
以前不同入参,有时候返回的是dataframe,有时候返回的是panel,比较混乱。
现在统一返回的dataframe. (或者返回dict,可以自己设定)
影响的API有get_history,get_price ,get_individual_transaction ,get_fundamentals等。
比如通过get_history获取的历史日线数据
count = 10
code_list = ['000695.SZ','001367.SZ']
df = get_history(count, frequency='1d', field=['open','close'], security_list=code_list, fq=None, include=False, fill='nan',is_dict=False)
print(type(df))
print(df)
返回的dataframe数据格式如下
<class 'pandas.core.frame.DataFrame'>
code open close
2025-05-15 000695.SZ NaN NaN
2025-05-16 000695.SZ NaN NaN
2025-05-19 000695.SZ 10.34 10.34
2025-05-20 000695.SZ 11.37 11.37
2025-05-21 000695.SZ 12.51 12.51
2025-05-22 000695.SZ 13.76 13.76
2025-05-09 001367.SZ 29.89 29.58
2025-05-12 001367.SZ 29.70 29.60
2025-05-13 001367.SZ 30.11 29.96
2025-05-14 001367.SZ 29.96 29.83
2025-05-15 001367.SZ 29.80 30.18
2025-05-16 001367.SZ 30.13 30.39
2025-05-19 001367.SZ 30.46 30.01
2025-05-20 001367.SZ 20.25 20.08
2025-05-21 001367.SZ 20.05 20.70
2025-05-22 001367.SZ 20.98 22.77
如果要提取 000695.SZ的数据,只需要
df[df['code']=='000695.SZ']就可以了。
code open close
2025-05-09 001367.SZ 29.89 29.58
2025-05-12 001367.SZ 29.70 29.60
2025-05-13 001367.SZ 30.11 29.96
2025-05-14 001367.SZ 29.96 29.83
2025-05-15 001367.SZ 29.80 30.18
2025-05-16 001367.SZ 30.13 30.39
2025-05-19 001367.SZ 30.46 30.01
2025-05-20 001367.SZ 20.25 20.08
2025-05-21 001367.SZ 20.05 20.70
2025-05-22 001367.SZ 20.98 22.77
然后dataframe提取收盘价或者开盘价
# 收盘价
df[df['code']=='001367.SZ']['close']
# 开盘价
df[df['code']=='001367.SZ']['open']
再拿收盘价来计算MACD:
# 计算 MACD 值
def MACD(series):
ema_short = series.ewm(span=12).mean()
ema_long = series.ewm(span=26).mean()
macd_series = ema_short - ema_long
return macd_series.iloc[-1]
close_price_series = df[df['code']=='001367.SZ']['close']
macd_val = MACD(close_price_series)
同理get_price,get_individual_transaction ,get_fundamentals与之类似。
并且在get_histroy的入参里面,多了一个is_dict的参数,默认是False,返回的是dataframe数据,如果设置为True,则返回的dict数据。
返回的有序字典(OrderDict)类型数据:(省略了部分类型)
{'001367.SZ', array([(20250509, 29.89, 29.58), (20250512, 29.7 , 29.6 ),
(20250513, 30.11, 29.96), (20250514, 29.96, 29.83),
(20250515, 29.8 , 30.18), (20250516, 30.13, 30.39),
(20250519, 30.46, 30.01), (20250520, 20.25, 20.08),
(20250521, 20.05, 20.7 ), (20250522, 20.98, 22.77)]
}
但感觉这种列表形式下,提取数据反而没有使用dataframe方便和直观,它获取数据时需要用下标提取。
但官网说,返回dict类型数据的速度比DataFrame,Panel类型数据有大幅提升,对速度有要求的,建议使用is_dict=True 读取上述数据格式。
获取L2逐笔数据
L2逐笔委托数据接口函数
get_individual_entrust(stocks=None, data_count=50, start_pos=0, search_direction=1, is_dict=False)
参数:
data_count: 数据条数,默认为50,最大为200(int);
start_pos: 起始位置,默认为0(int);
虽然一次只能获取200条,但配合start_pos游标可遍历获取全部数据。
示例代码:
获取股票001367.SZ封涨停时的最新的逐笔委托行情。
code_list = ['001367.SZ']
df = get_individual_entrust(code_list)
print(df[['business_time','hq_px','business_amount','order_no']])
输出数据如下,因数据列太多,为了美观只取了其中的4列:
时间戳,委托价格,委托数量,委托编号
因为当前已经是收盘状态,是从14:59:57.020往前取50条数据
business_time(时间戳) hq_px(委托价格) business_amount(委托数量) order_no(委托编号)
20250523145702150 24.60 100 32493957
20250523145714840 24.95 100 32505581
20250523145718430 25.05 1000 32509041
20250523145719840 25.05 1000 32510350
20250523145721750 25.05 400 32512000
20250523145727610 25.05 200 32517007
20250523145730270 25.05 400 32519085
20250523145730330 25.04 1600 32519133
20250523145732330 25.05 2900 32520779
20250523145740780 25.05 500 32527204
20250523145743550 25.05 400 32529290
20250523145743810 25.05 200 32529474
20250523145749460 25.05 4300 32533295
20250523145749910 25.05 1000 32533630
20250523145749960 25.05 300 32533666
# 省略若干.....
20250523145926790 25.05 100 32589496
20250523145927480 25.05 1200 32589844
20250523145936090 25.05 200 32594134
20250523145946600 25.05 300 32601758
20250523145946800 25.05 49100 32601865
20250523145950800 25.05 36800 32607381
20250523145953780 25.05 55200 32611265
20250523145954240 25.05 500 32611713
20250523145956830 25.05 55300 32614479
20250523145957020 25.04 8500 32614683
可以看到上面的有些1秒内有多个的委托单,每单的委托量和委托编号。
逐笔成交
同理,L2的逐笔成交数据函数的用法一样,但返回字段不同,成交的时候有成交方向,可以通过程序计算资金流入或流出。
get_individual_transaction(stocks=None, data_count=50, start_pos=0, search_direction=1, is_dict=False)
同样用上面的股票例子获取到的数据如下:
business_time hq_px business_amount business_direction
20250523145648440 0.00 2500 1
20250523145648970 0.00 3200 1
20250523145649300 0.00 100 1
20250523145649370 0.00 900 1
20250523145649880 0.00 1800 1
20250523145650150 0.00 800 1
20250523145650360 0.00 200 1
20250523145650400 0.00 500 1
20250523145650420 0.00 100 1
20250523145652050 0.00 800 1
# 省略若干.....
20250523145659220 0.00 24100 1
20250523145659550 0.00 700 1
20250523145659600 0.00 400 1
20250523150000000 25.05 100 0
20250523150000000 25.05 100 0
20250523150000000 25.05 1600 0
20250523150000000 25.05 800 0
20250523150000000 25.05 1730 0
20250523150000000 25.05 670 0
20250523150000000 25.05 2430 0
20250523150000000 25.05 1200 0
20250523150000000 25.05 9270 0
20250523150000000 25.05 148 0
20250523150000000 25.05 100 0
20250523150000000 25.05 200 0
20250523150000000 25.05 1000 0
20250523150000000 25.05 2000 0
business_direction是 成交方向,0是卖出,1是买入,从而判断该笔成交的资金是流入还是流出。
获取分时成交
get_tick_direction(symbols=None, query_date=0, start_pos=0, search_direction=1, data_count=50, is_dict=False)
这个分时成交函数可获取到当前和历史某个毫秒下,该笔总成交量下有多少笔子订单。
比如用上面的涨停股001367.SZ做示例
最后一刻3点的时候,成交了21348股,里面共有14笔成交。
time_stamp hq_px business_amount business_count
20250523143721000 25.05 100 1
20250523143724000 25.05 200 1
20250523143745000 25.05 444 1
20250523143809000 25.05 10000 2
20250523144024000 25.05 100 1
20250523144048000 25.05 1500 1
20250523144106000 25.05 300 1
20250523144112000 25.05 11692 2
20250523144124000 25.05 100 1
20250523144142000 25.05 100 1
20250523144157000 25.05 100 1
20250523144200000 25.05 2360 1
# 省略若干.....
20250523145415000 25.05 1381 1
20250523145421000 25.05 480 1
20250523145439000 25.05 100 1
20250523145451000 25.05 1753 1
20250523145521000 25.05 5384 3
20250523145539000 25.05 3600 2
20250523145557000 25.05 1000 1
20250523145609000 25.05 400 2
20250523145615000 25.05 100 1
20250523150000000 25.05 21348 14
get_gear_price 获取当前时刻的逐笔委托队列
这个函数的功能:获取委买/卖1 至 委买/卖10 10档行情的价格与委托量,但现在发现它可以获取到委托1档下逐笔委托队列。
比如当前的股票是涨停状态,你下了一笔订单有8888股去排板,那么这个函数可以获取当前委1档下的委托队列(前50名),比如下面返回的数据,可以看到你的8888手排在第9个委托队列,还有前后的单子的逐笔数量。
{'bid_grp': {1: [13.68, 15225900, 4905, {1: 33200, 2: 104800, 3: 1000, 4: 100, 5: 51800, 6: 6300, 7: 777800, 8: 184000, 9: 8888, 10: 100, 11: 600, 12: 141800, 13: 100, 14: 141800, 15: 2700,
16: 900, 17: 58600, 18: 2900, 19: 800, 20: 133800, 21: 2800, 22: 900, 23: 2900, 24: 800, 25: 400, 26: 400, 27: 48200, 28: 51800, 29: 99400, 30: 26600, 31: 81800, 32: 493000, 33: 427300, 34: 27700, 35: 2800, 36: 460500,
37: 170200, 38: 166500, 39: 24100, 40: 800, 41: 29300, 42: 500, 43: 500, 44: 500, 45: 2800, 46: 1300, 47: 61700, 48: 27000, 49: 500, 50: 78900}],
2: [13.67, 30200, 32],
3: [13.66, 11100, 16],
4: [13.65, 134400, 11],
5: [13.64, 8500, 7],
6: [13.63, 1000, 3],
7: [13.62, 200, 2],
8: [13.6, 7300, 17],
9: [13.59, 600, 2],
10: [13.58, 10700, 7]},
# 因为是涨停,所以委卖是空的,挂单就立马成交,委托队列是空的
'offer_grp': {1: [0.0, 0, 0, {}],
2: [0.0, 0, 0],
3: [0.0, 0, 0],
4: [0.0, 0, 0],
5: [0.0, 0, 0],
6: [0.0, 0, 0],
7: [0.0, 0, 0],
8: [0.0, 0, 0],
9: [0.0, 0, 0],
10: [0.0, 0, 0]}
}
所以这次ptrade的升级除了python版本的升级,还带来了更多粒度的数据,有利于高频策略的开发。
还有一些新功能的函数就等下次继续更新,记得点赞关注+收藏哦~
待续......
关注公众号: 查看全部
并且还发现居然可以免费使用L2逐笔数据,分时逐笔委托队列等高频毫秒级的数据
Ptrade接口文档已更新: https://ptradeapi.com
Python 3.5是2015 年发布,Python 3.11是2022 年发布。
性能上来说是有很大的提升,尤其对做回测和高频策略。
如果本身策略很简单或者日线交易的,影响可以忽略不计。
不过这个升级并不是个人可选的,只要你的Ptrade的券商升级了,就只能使用升级后的版本接口格式,旧代码需要做的修改来适配。
性能对比示例(Python 3.5 vs 3.11) By 豆包
以下是部分操作在 Python 3.5 和 3.11 中的性能对比(仅供参考):

并且相应的第三方库版本亦做了升级。

接口变动影响比较大的是pandas在 Python3.11 中,Pandas已不再支持Panel格式。
pandas里的Pannel类型是用于存储三维或以上的矩阵数据。
而升级后就不支持之前的多维行情数据格式。但笔者觉得现在更加统一和简单。
以前不同入参,有时候返回的是dataframe,有时候返回的是panel,比较混乱。
现在统一返回的dataframe. (或者返回dict,可以自己设定)
影响的API有get_history,get_price ,get_individual_transaction ,get_fundamentals等。
比如通过get_history获取的历史日线数据
count = 10
code_list = ['000695.SZ','001367.SZ']
df = get_history(count, frequency='1d', field=['open','close'], security_list=code_list, fq=None, include=False, fill='nan',is_dict=False)
print(type(df))
print(df)
返回的dataframe数据格式如下
<class 'pandas.core.frame.DataFrame'>
code open close
2025-05-15 000695.SZ NaN NaN
2025-05-16 000695.SZ NaN NaN
2025-05-19 000695.SZ 10.34 10.34
2025-05-20 000695.SZ 11.37 11.37
2025-05-21 000695.SZ 12.51 12.51
2025-05-22 000695.SZ 13.76 13.76
2025-05-09 001367.SZ 29.89 29.58
2025-05-12 001367.SZ 29.70 29.60
2025-05-13 001367.SZ 30.11 29.96
2025-05-14 001367.SZ 29.96 29.83
2025-05-15 001367.SZ 29.80 30.18
2025-05-16 001367.SZ 30.13 30.39
2025-05-19 001367.SZ 30.46 30.01
2025-05-20 001367.SZ 20.25 20.08
2025-05-21 001367.SZ 20.05 20.70
2025-05-22 001367.SZ 20.98 22.77
如果要提取 000695.SZ的数据,只需要
df[df['code']=='000695.SZ']就可以了。
code open close
2025-05-09 001367.SZ 29.89 29.58
2025-05-12 001367.SZ 29.70 29.60
2025-05-13 001367.SZ 30.11 29.96
2025-05-14 001367.SZ 29.96 29.83
2025-05-15 001367.SZ 29.80 30.18
2025-05-16 001367.SZ 30.13 30.39
2025-05-19 001367.SZ 30.46 30.01
2025-05-20 001367.SZ 20.25 20.08
2025-05-21 001367.SZ 20.05 20.70
2025-05-22 001367.SZ 20.98 22.77
然后dataframe提取收盘价或者开盘价
# 收盘价
df[df['code']=='001367.SZ']['close']
# 开盘价
df[df['code']=='001367.SZ']['open']
再拿收盘价来计算MACD:
# 计算 MACD 值
def MACD(series):
ema_short = series.ewm(span=12).mean()
ema_long = series.ewm(span=26).mean()
macd_series = ema_short - ema_long
return macd_series.iloc[-1]
close_price_series = df[df['code']=='001367.SZ']['close']
macd_val = MACD(close_price_series)
同理get_price,get_individual_transaction ,get_fundamentals与之类似。
并且在get_histroy的入参里面,多了一个is_dict的参数,默认是False,返回的是dataframe数据,如果设置为True,则返回的dict数据。
返回的有序字典(OrderDict)类型数据:(省略了部分类型)
{'001367.SZ', array([(20250509, 29.89, 29.58), (20250512, 29.7 , 29.6 ),
(20250513, 30.11, 29.96), (20250514, 29.96, 29.83),
(20250515, 29.8 , 30.18), (20250516, 30.13, 30.39),
(20250519, 30.46, 30.01), (20250520, 20.25, 20.08),
(20250521, 20.05, 20.7 ), (20250522, 20.98, 22.77)]
}但感觉这种列表形式下,提取数据反而没有使用dataframe方便和直观,它获取数据时需要用下标提取。
但官网说,返回dict类型数据的速度比DataFrame,Panel类型数据有大幅提升,对速度有要求的,建议使用is_dict=True 读取上述数据格式。
获取L2逐笔数据
L2逐笔委托数据接口函数
get_individual_entrust(stocks=None, data_count=50, start_pos=0, search_direction=1, is_dict=False)
参数:
data_count: 数据条数,默认为50,最大为200(int);
start_pos: 起始位置,默认为0(int);
虽然一次只能获取200条,但配合start_pos游标可遍历获取全部数据。
示例代码:
获取股票001367.SZ封涨停时的最新的逐笔委托行情。
code_list = ['001367.SZ']
df = get_individual_entrust(code_list)
print(df[['business_time','hq_px','business_amount','order_no']])
输出数据如下,因数据列太多,为了美观只取了其中的4列:
时间戳,委托价格,委托数量,委托编号
因为当前已经是收盘状态,是从14:59:57.020往前取50条数据
business_time(时间戳) hq_px(委托价格) business_amount(委托数量) order_no(委托编号)
20250523145702150 24.60 100 32493957
20250523145714840 24.95 100 32505581
20250523145718430 25.05 1000 32509041
20250523145719840 25.05 1000 32510350
20250523145721750 25.05 400 32512000
20250523145727610 25.05 200 32517007
20250523145730270 25.05 400 32519085
20250523145730330 25.04 1600 32519133
20250523145732330 25.05 2900 32520779
20250523145740780 25.05 500 32527204
20250523145743550 25.05 400 32529290
20250523145743810 25.05 200 32529474
20250523145749460 25.05 4300 32533295
20250523145749910 25.05 1000 32533630
20250523145749960 25.05 300 32533666
# 省略若干.....
20250523145926790 25.05 100 32589496
20250523145927480 25.05 1200 32589844
20250523145936090 25.05 200 32594134
20250523145946600 25.05 300 32601758
20250523145946800 25.05 49100 32601865
20250523145950800 25.05 36800 32607381
20250523145953780 25.05 55200 32611265
20250523145954240 25.05 500 32611713
20250523145956830 25.05 55300 32614479
20250523145957020 25.04 8500 32614683
可以看到上面的有些1秒内有多个的委托单,每单的委托量和委托编号。
逐笔成交
同理,L2的逐笔成交数据函数的用法一样,但返回字段不同,成交的时候有成交方向,可以通过程序计算资金流入或流出。
get_individual_transaction(stocks=None, data_count=50, start_pos=0, search_direction=1, is_dict=False)
同样用上面的股票例子获取到的数据如下:
business_time hq_px business_amount business_direction
20250523145648440 0.00 2500 1
20250523145648970 0.00 3200 1
20250523145649300 0.00 100 1
20250523145649370 0.00 900 1
20250523145649880 0.00 1800 1
20250523145650150 0.00 800 1
20250523145650360 0.00 200 1
20250523145650400 0.00 500 1
20250523145650420 0.00 100 1
20250523145652050 0.00 800 1
# 省略若干.....
20250523145659220 0.00 24100 1
20250523145659550 0.00 700 1
20250523145659600 0.00 400 1
20250523150000000 25.05 100 0
20250523150000000 25.05 100 0
20250523150000000 25.05 1600 0
20250523150000000 25.05 800 0
20250523150000000 25.05 1730 0
20250523150000000 25.05 670 0
20250523150000000 25.05 2430 0
20250523150000000 25.05 1200 0
20250523150000000 25.05 9270 0
20250523150000000 25.05 148 0
20250523150000000 25.05 100 0
20250523150000000 25.05 200 0
20250523150000000 25.05 1000 0
20250523150000000 25.05 2000 0
business_direction是 成交方向,0是卖出,1是买入,从而判断该笔成交的资金是流入还是流出。
获取分时成交
get_tick_direction(symbols=None, query_date=0, start_pos=0, search_direction=1, data_count=50, is_dict=False)
这个分时成交函数可获取到当前和历史某个毫秒下,该笔总成交量下有多少笔子订单。
比如用上面的涨停股001367.SZ做示例
最后一刻3点的时候,成交了21348股,里面共有14笔成交。
time_stamp hq_px business_amount business_count
20250523143721000 25.05 100 1
20250523143724000 25.05 200 1
20250523143745000 25.05 444 1
20250523143809000 25.05 10000 2
20250523144024000 25.05 100 1
20250523144048000 25.05 1500 1
20250523144106000 25.05 300 1
20250523144112000 25.05 11692 2
20250523144124000 25.05 100 1
20250523144142000 25.05 100 1
20250523144157000 25.05 100 1
20250523144200000 25.05 2360 1
# 省略若干.....
20250523145415000 25.05 1381 1
20250523145421000 25.05 480 1
20250523145439000 25.05 100 1
20250523145451000 25.05 1753 1
20250523145521000 25.05 5384 3
20250523145539000 25.05 3600 2
20250523145557000 25.05 1000 1
20250523145609000 25.05 400 2
20250523145615000 25.05 100 1
20250523150000000 25.05 21348 14
get_gear_price 获取当前时刻的逐笔委托队列
这个函数的功能:获取委买/卖1 至 委买/卖10 10档行情的价格与委托量,但现在发现它可以获取到委托1档下逐笔委托队列。
比如当前的股票是涨停状态,你下了一笔订单有8888股去排板,那么这个函数可以获取当前委1档下的委托队列(前50名),比如下面返回的数据,可以看到你的8888手排在第9个委托队列,还有前后的单子的逐笔数量。
{'bid_grp': {1: [13.68, 15225900, 4905, {1: 33200, 2: 104800, 3: 1000, 4: 100, 5: 51800, 6: 6300, 7: 777800, 8: 184000, 9: 8888, 10: 100, 11: 600, 12: 141800, 13: 100, 14: 141800, 15: 2700,
16: 900, 17: 58600, 18: 2900, 19: 800, 20: 133800, 21: 2800, 22: 900, 23: 2900, 24: 800, 25: 400, 26: 400, 27: 48200, 28: 51800, 29: 99400, 30: 26600, 31: 81800, 32: 493000, 33: 427300, 34: 27700, 35: 2800, 36: 460500,
37: 170200, 38: 166500, 39: 24100, 40: 800, 41: 29300, 42: 500, 43: 500, 44: 500, 45: 2800, 46: 1300, 47: 61700, 48: 27000, 49: 500, 50: 78900}],
2: [13.67, 30200, 32],
3: [13.66, 11100, 16],
4: [13.65, 134400, 11],
5: [13.64, 8500, 7],
6: [13.63, 1000, 3],
7: [13.62, 200, 2],
8: [13.6, 7300, 17],
9: [13.59, 600, 2],
10: [13.58, 10700, 7]},
# 因为是涨停,所以委卖是空的,挂单就立马成交,委托队列是空的
'offer_grp': {1: [0.0, 0, 0, {}],
2: [0.0, 0, 0],
3: [0.0, 0, 0],
4: [0.0, 0, 0],
5: [0.0, 0, 0],
6: [0.0, 0, 0],
7: [0.0, 0, 0],
8: [0.0, 0, 0],
9: [0.0, 0, 0],
10: [0.0, 0, 0]}
}所以这次ptrade的升级除了python版本的升级,还带来了更多粒度的数据,有利于高频策略的开发。
还有一些新功能的函数就等下次继续更新,记得点赞关注+收藏哦~
待续......
关注公众号:
ptrade的python版本升级到3.11, 部分数据返回格式也改变了,无语
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 415 次浏览 • 2025-05-07 14:22
返回数据可以为dataframe,也可以为dict。
为python3.5会根据数据入参不同,返回dataframe,pannel
而新的函数返回,只有dataframe,当然这很好。只是以前的代码需要改动做兼容。
而修改的地方不止这一处。
查看全部
返回数据可以为dataframe,也可以为dict。
为python3.5会根据数据入参不同,返回dataframe,pannel

而新的函数返回,只有dataframe,当然这很好。只是以前的代码需要改动做兼容。
而修改的地方不止这一处。
Ptrade LOF跌停抄底T+0 程序
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 506 次浏览 • 2025-04-29 09:02
$黄金主题LOF(SZ161116)$
$港股小盘LOF(SZ161124)$
吃早餐的突然想到,快速写了个监控跌停,封单小于X就买入,冲高后止盈卖出,T+0 ptrade 自动交易。这样抄底就不用自己盯盘啦
查看全部
$黄金主题LOF(SZ161116)$
$港股小盘LOF(SZ161124)$
吃早餐的突然想到,快速写了个监控跌停,封单小于X就买入,冲高后止盈卖出,T+0 ptrade 自动交易。这样抄底就不用自己盯盘啦

部署Ptrade deepseek编程AI助手
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1259 次浏览 • 2025-03-22 19:19
(第一行:根本没有ptrade_api这个库)
一个很大的原因,是互联网的残次不齐的语料污染了Deepseek的分析结果。很多不相关的广告或者垃圾内容进入到Deepseek的分析参考对象。三人成虎,Deepseek获取的3个网站都说那个图片里的猫是只老虎,那么它就真的认为它是只老虎。
其实我们可以把API文档作为知识库,提交给Deepseek,让它学习后再替我们编写Ptrade量化程序,代码的完成度会有很大的提升。甚至基本不用修改就可以直接运行。
本文手把手带大家,部署属于自己的量化交易AI编程助手。
当然,不需要高级硬件,也不用付费。0元购。
效果图:
本次依然使用腾讯云提供的Deepseek大模型来运行。
打开链接:https://lke.cloud.tencent.com/
点击大模型知识引擎,如果没有开通就点击开通。个人有免费的token额度可用,不收费。[图片]进去之后点击“新建应用", 名称可以任意填,
在模型这里选择 Deepseek-R1 或者 Deepseek-V3
它支持从本地文档导入和网页URL导入。
我们使用的API文档URL为:https://ptradeapi.com/
但笔者发现,它这个从URL获取数据的工程能力太弱了,获取到的数据只有标题,没有内容。
所以只好手工把网站的内容全选,然后复制保存到本地的word文档。
然后点击导入文档
这里需要几分钟的时间解析,内容审核。因为这个个人定制的知识库,是可以发布出去公开使用的,所以会对问答的内容做审核。
知识库里有对字符限制,免费的可以有个300w的字符可用。本次使用的ptrade api文档用了26w的字符,所以还可以上传更多的个人编写代码库。
知识库的状态变成"待发布"之后,可以点击"发布"按钮。
然后返回到应用配置,可以在提示词里添加一些限制。
比如目前的ptrade是基于python3.5的代码编写的。如果不限制,到时写出来的语法,比如用了诸如f-string的语法,ptrade会报错的。
f'{name}' -- wrong
'{}'.format(name) -- right
如果这里不限制,最后AI写出来的代码大概率在ptrade会报错。
设置完成之后,就完成了你个人专属的ptrade代码AI助手。
现在让它写一个ptrade网格交易程序
至少里面的策略逻辑代码框架整体问题不大,至少不再出现 from ptrade_api import * 这种不存在的包导入的情况。
但细节里还是有些bug的,比如卖出的时候是查enable_amount,而不是amount,因为当日买入的数量不一定能卖出。
run_interval(execute_grid, seconds=3),还有函数的入参不符合。
并没有get_price这个函数,要用get_snapshot
复制到ptrade里面跑下回测验证一下语法。
出现语法错误,依然需要小改一下。run_interval(context,execute_grid, seconds=3) 就好了。
当然上面的代码离实盘依然有一定的距离,依然依赖提问者技术水平,但作为代码辅助工具,对编写代码效率是很大的提升。
一些没写过复杂代码的自媒体经常尬吹,AI完成替代程序员的工作,其实大部分只是满足生成最基础的demo级别的通用任务,对于高度定制的业务,依然依赖提问者的技术广度和深度,对细节的掌控。
同样使用Deepseek,一个家庭主妇和张小龙,张小龙的确可能在完全不写代码的情况下使用Deepseek写出一个微信,而家庭主妇只能用Deepseek绘出一个类似的微信的UI,却无法运行起来。
但AI作为生产力工具,无疑大大减少了很多重复基础性工作,提升效率,让强者恒强。
需要开通Ptrade,QMT,掘金,Matic,BigQuant等量化工具的读者可以在公众号菜单获取联系方式。像BigQuan已经把AI编写实盘和回测的功能集成进去了。将公众号设为星标,第一时间收到笔者的最新文章啦。
查看全部

(第一行:根本没有ptrade_api这个库)
一个很大的原因,是互联网的残次不齐的语料污染了Deepseek的分析结果。很多不相关的广告或者垃圾内容进入到Deepseek的分析参考对象。三人成虎,Deepseek获取的3个网站都说那个图片里的猫是只老虎,那么它就真的认为它是只老虎。
其实我们可以把API文档作为知识库,提交给Deepseek,让它学习后再替我们编写Ptrade量化程序,代码的完成度会有很大的提升。甚至基本不用修改就可以直接运行。
本文手把手带大家,部署属于自己的量化交易AI编程助手。
当然,不需要高级硬件,也不用付费。0元购。
效果图:

本次依然使用腾讯云提供的Deepseek大模型来运行。
打开链接:https://lke.cloud.tencent.com/
点击大模型知识引擎,如果没有开通就点击开通。个人有免费的token额度可用,不收费。[图片]进去之后点击“新建应用", 名称可以任意填,

在模型这里选择 Deepseek-R1 或者 Deepseek-V3




它支持从本地文档导入和网页URL导入。
我们使用的API文档URL为:https://ptradeapi.com/
但笔者发现,它这个从URL获取数据的工程能力太弱了,获取到的数据只有标题,没有内容。
所以只好手工把网站的内容全选,然后复制保存到本地的word文档。

然后点击导入文档


这里需要几分钟的时间解析,内容审核。因为这个个人定制的知识库,是可以发布出去公开使用的,所以会对问答的内容做审核。

知识库里有对字符限制,免费的可以有个300w的字符可用。本次使用的ptrade api文档用了26w的字符,所以还可以上传更多的个人编写代码库。
知识库的状态变成"待发布"之后,可以点击"发布"按钮。

然后返回到应用配置,可以在提示词里添加一些限制。
比如目前的ptrade是基于python3.5的代码编写的。如果不限制,到时写出来的语法,比如用了诸如f-string的语法,ptrade会报错的。
f'{name}' -- wrong
'{}'.format(name) -- right

如果这里不限制,最后AI写出来的代码大概率在ptrade会报错。
设置完成之后,就完成了你个人专属的ptrade代码AI助手。
现在让它写一个ptrade网格交易程序



至少里面的策略逻辑代码框架整体问题不大,至少不再出现 from ptrade_api import * 这种不存在的包导入的情况。
但细节里还是有些bug的,比如卖出的时候是查enable_amount,而不是amount,因为当日买入的数量不一定能卖出。
run_interval(execute_grid, seconds=3),还有函数的入参不符合。
并没有get_price这个函数,要用get_snapshot
复制到ptrade里面跑下回测验证一下语法。

出现语法错误,依然需要小改一下。run_interval(context,execute_grid, seconds=3) 就好了。
当然上面的代码离实盘依然有一定的距离,依然依赖提问者技术水平,但作为代码辅助工具,对编写代码效率是很大的提升。
一些没写过复杂代码的自媒体经常尬吹,AI完成替代程序员的工作,其实大部分只是满足生成最基础的demo级别的通用任务,对于高度定制的业务,依然依赖提问者的技术广度和深度,对细节的掌控。
同样使用Deepseek,一个家庭主妇和张小龙,张小龙的确可能在完全不写代码的情况下使用Deepseek写出一个微信,而家庭主妇只能用Deepseek绘出一个类似的微信的UI,却无法运行起来。
但AI作为生产力工具,无疑大大减少了很多重复基础性工作,提升效率,让强者恒强。
需要开通Ptrade,QMT,掘金,Matic,BigQuant等量化工具的读者可以在公众号菜单获取联系方式。像BigQuan已经把AI编写实盘和回测的功能集成进去了。将公众号设为星标,第一时间收到笔者的最新文章啦。
ptrade支持北交所股票交易吗?
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 645 次浏览 • 2025-03-12 20:25
可以运行下面的代码:
def initialize(context):
# 初始化策略
g.security = "600570.SS"
set_universe(g.security)
run_daily(context, func,'20:13')
def handle_data(context, data):
print('公众号:可转债量化分析')
def func(context):
info = get_Ashares(date=None)
print(info)
它会打印沪深A股的代码:
北交所有83开头的,或者找一个北交所的股票代码,在输出里面找一下:
[code]2025-03-12 20:13:00 - INFO - ['600000.SS', '600004.SS', '600006.SS', '600007.SS', '600008.SS', '600009.SS', '600010.SS', '600011.SS', '600012.SS', '600015.SS', '600016.SS', '600017.SS', '600018.SS', '600019.SS', '600020.SS', '600021.SS', '600022.SS', '600023.SS', '600025.SS', '600026.SS', '600027.SS', '600028.SS', '600029.SS', '600030.SS', '600031.SS', '600032.SS', '600033.SS', '600035.SS', '600036.SS', '600037.SS', '600038.SS', '600039.SS', '600048.SS', '600050.SS', '600051.SS', '600052.SS', '600053.SS', '600054.SS', '600055.SS', '600056.SS', '600057.SS', '600058.SS', '600059.SS', '600060.SS', '600061.SS', '600062.SS', '600063.SS', '600064.SS', '600066.SS', '600067.SS', '600070.SS', '600071.SS', '600072.SS', '600073.SS', '600075.SS', '600076.SS', '600078.SS', '600079.SS', '600080.SS', '600081.SS', '600082.SS', '600084.SS', '600085.SS', '600088.SS', '600089.SS', '600094.SS', '600095.SS', '600096.SS', '600097.SS', '600098.SS', '600099.SS', '600100.SS', '600101.SS', '600103.SS', '600104.SS', '600105.SS', '600106.SS', '600107.SS', '600108.SS', '600109.SS', '600110.SS', '600111.SS', '600113.SS', '600114.SS', '600115.SS', '600116.SS', '600117.SS', '600118.SS', '600119.SS', '600120.SS', '600121.SS', '600123.SS', '600125.SS', '600126.SS', '600127.SS', '600128.SS', '600129.SS', '600130.SS', '600131.SS', '600132.SS', '600133.SS', '600135.SS', '600136.SS', '600137.SS', '600138.SS', '600141.SS', '600143.SS', '600148.SS', '600149.SS', '600150.SS', '600151.SS', '600152.SS', '600153.SS', '600155.SS', '600156.SS', '600157.SS', '600158.SS', '600159.SS', '600160.SS', '600161.SS', '600162.SS', '600163.SS', '600165.SS', '600166.SS', '600167.SS', '600168.SS', '600169.SS', '600170.SS', '600171.SS', '600172.SS', '600173.SS', '600176.SS', '600177.SS', '600178.SS', '600179.SS', '600180.SS', '600182.SS', '600183.SS', '600184.SS', '600185.SS', '600186.SS', '600187.SS', '600188.SS', '600189.SS', '600190.SS', '600191.SS', '600192.SS', '600193.SS', '600195.SS', '600196.SS', '600197.SS', '600198.SS', '600199.SS', '600200.SS', '600201.SS', '600202.SS', '600203.SS', '600206.SS', '600207.SS', '600208.SS', '600210.SS', '600211.SS', '600212.SS', '600215.SS', '600216.SS', '600217.SS', '600218.SS', '600219.SS', '600221.SS', '600222.SS', '600223.SS', '600226.SS', '600227.SS', '600228.SS', '600229.SS', '600230.SS', '600231.SS', '600232.SS', '600233.SS', '600234.SS', '600235.SS', '600236.SS', '600237.SS', '600238.SS', '600239.SS', '600241.SS', '600243.SS', '600246.SS', '600248.SS', '600249.SS', '600250.SS', '600251.SS', '600252.SS', '600255.SS', '600256.SS', '600257.SS', '600258.SS', '600259.SS', '600261.SS', '600262.SS', '600265.SS', '600266.SS', '600267.SS', '600268.SS', '600269.SS', '600271.SS', '600272.SS', '600273.SS', '600276.SS', '600278.SS', '600279.SS', '600280.SS', '600281.SS', '600282.SS', '600283.SS', '600284.SS', '600285.SS', '600287.SS', '600288.SS', '600289.SS', '600292.SS', '600293.SS', '600295.SS', '600298.SS', '600299.SS', '600300.SS', '600301.SS', '600302.SS', '600303.SS', '600305.SS', '600307.SS', '600308.SS', '600309.SS', '600310.SS', '600312.SS', '600313.SS', '600315.SS', '600316.SS', '600318.SS', '600319.SS', '600320.SS', '600322.SS', '600323.SS', '600325.SS', '600326.SS', '600327.SS', '600328.SS', '600329.SS', '600330.SS', '600331.SS', '600332.SS', '600333.SS', '600335.SS', '600336.SS', '600337.SS', '600338.SS', '600339.SS', '600340.SS', '600343.SS', '600345.SS', '600346.SS', '600348.SS', '600350.SS', '600351.SS', '600352.SS', '600353.SS', '600354.SS', '600355.SS', '600356.SS', '600358.SS', '600359.SS', '600360.SS', '600361.SS', '600362.SS', '600363.SS', '600365.SS', '600366.SS', '600367.SS', '600368.SS', '600369.SS', '600370.SS', '600371.SS', '600372.SS', '600373.SS', '600375.SS', '600376.SS', '600377.SS', '600378.SS', '600379.SS', '600380.SS', '600381.SS', '600382.SS', '600383.SS', '600386.SS', '600387.SS', '600388.SS', '600389.SS', '600390.SS', '600391.SS', '600392.SS', '600395.SS', '600396.SS', '600397.SS', '600398.SS', '600399.SS', '600400.SS', '600403.SS', '600405.SS', '600406.SS', '600408.SS', '600409.SS', '600410.SS', '600415.SS', '600416.SS', '600418.SS', '600419.SS', '600420.SS', '600421.SS', '600422.SS', '600423.SS', '600425.SS', '600426.SS', '600428.SS', '600429.SS', '600433.SS', '600435.SS', '600436.SS', '600438.SS', '600439.SS', '600444.SS', '600446.SS', '600448.SS', '600449.SS', '600452.SS', '600455.SS', '600456.SS', '600458.SS', '600459.SS', '600460.SS', '600461.SS', '600462.SS', '600463.SS', '600467.SS', '600468.SS', '600469.SS', '600470.SS', '600475.SS', '600476.SS', '600477.SS', '600478.SS', '600479.SS', '600480.SS', '600481.SS', '600482.SS', '600483.SS', '600486.SS', '600487.SS', '600488.SS', '600489.SS', '600490.SS', '600491.SS', '600493.SS', '600495.SS', '600496.SS', '600497.SS', '600498.SS', '600499.SS', '600500.SS', '600501.SS', '600502.SS', '600503.SS', '600505.SS', '600506.SS', '600507.SS', '600508.SS', '600509.SS', '600510.SS', '600511.SS', '600512.SS', '600513.SS', '600515.SS', '600516.SS', '600517.SS', '600518.SS', '600519.SS', '600520.SS', '600521.SS', '600522.SS', '600523.SS', '600525.SS', '600526.SS', '600527.SS', '600528.SS', '600529.SS', '600530.SS', '600531.SS', '600533.SS', '600535.SS', '600536.SS', '600537.SS', '600538.SS', '600539.SS', '600540.SS', '600543.SS', '600545.SS', '600546.SS', '600547.SS', '600548.SS', '600549.SS', '600550.SS', '600551.SS', '600552.SS', '600556.SS', '600557.SS', '600558.SS', '600559.SS', '600560.SS', '600561.SS', '600562.SS', '600563.SS', '600566.SS', '600567.SS', '600568.SS', '600569.SS', '600570.SS', '600571.SS', '600572.SS', '600573.SS', '600575.SS', '600576.SS', '600577.SS', '600578.SS', '600579.SS', '600580.SS', '600581.SS', '600582.SS', '600583.SS', '600584.SS', '600585.SS', '600586.SS', '600587.SS', '600588.SS', '600589.SS', '600590.SS', '600592.SS', '600593.SS', '600594.SS', '600595.SS', '600596.SS', '600597.SS', '600598.SS', '600599.SS', '600600.SS', '600601.SS', '600602.SS', '600603.SS', '600604.SS', '600605.SS', '600606.SS', '600608.SS', '600609.SS', '600610.SS', '600611.SS', '600612.SS', '600613.SS', '600615.SS', '600616.SS', '600617.SS', '600618.SS', '600619.SS', '600620.SS', '600621.SS', '600622.SS', '600623.SS', '600624.SS', '600626.SS', '600628.SS', '600629.SS', '600630.SS', '600633.SS', '600635.SS', '600636.SS', '600637.SS', '600638.SS', '600639.SS', '600640.SS', '600641.SS', '600642.SS', '600643.SS', '600644.SS', '600645.SS', '600648.SS', '600649.SS', '600650.SS', '600651.SS', '600653.SS', '600654.SS', '600655.SS', '600657.SS', '600658.SS', '600660.SS', '600661.SS', '600662.SS', '600663.SS', '600664.SS', '600665.SS', '600666.SS', '600667.SS', '600668.SS', '600671.SS', '600673.SS', '600674.SS', '600675.SS', '600676.SS', '600678.SS', '600679.SS', '600681.SS', '600682.SS', '600683.SS', '600684.SS', '600685.SS', '600686.SS', '600688.SS', '600689.SS', '600690.SS', '600691.SS', '600692.SS', '600693.SS', '600694.SS', '600696.SS', '600697.SS', '600698.SS', '600699.SS', '600702.SS', '600703.SS', '600704.SS', '600705.SS', '600706.SS', '600707.SS', '600708.SS', '600710.SS', '600711.SS', '600712.SS', '600713.SS', '600714.SS', '600715.SS', '600716.SS', '600717.SS', '600718.SS', '600719.SS', '600720.SS', '600721.SS', '600722.SS', '600724.SS', '600725.SS', '600726.SS', '600727.SS', '600728.SS', '600729.SS', '600730.SS', '600731.SS', '600732.SS', '600733.SS', '600734.SS', '600735.SS', '600736.SS', '600737.SS', '600738.SS', '600739.SS', '600740.SS', '600741.SS', '600742.SS', '600743.SS', '600744.SS', '600745.SS', '600746.SS', '600748.SS', '600749.SS', '600750.SS', '600751.SS', '600753.SS', '600754.SS', '600755.SS', '600756.SS', '600757.SS', '600758.SS', '600759.SS', '600760.SS', '600761.SS', '600763.SS', '600764.SS', '600765.SS', '600768.SS', '600769.SS', '600770.SS', '600771.SS', '600773.SS', '600774.SS', '600775.SS', '600776.SS', '600777.SS', '600778.SS', '600779.SS', '600780.SS', '600782.SS', '600783.SS', '600784.SS', '600785.SS', '600787.SS', '600789.SS', '600790.SS', '600791.SS', '600792.SS', '600793.SS', '600794.SS', '600795.SS', '600796.SS', '600797.SS', '600798.SS', '600800.SS', '600801.SS', '600802.SS', '600803.SS', '600804.SS', '600805.SS', '600807.SS', '600808.SS', '600809.SS', '600810.SS', '600811.SS', '600812.SS', '600814.SS', '600815.SS', '600816.SS', '600817.SS', '600818.SS', '600819.SS', '600820.SS', '600821.SS', '600822.SS', '600824.SS', '600825.SS', '600826.SS', '600827.SS', '600828.SS', '600829.SS', '600830.SS', '600831.SS', '600833.SS', '600834.SS', '600835.SS', '600838.SS', '600839.SS', '600841.SS', '600843.SS', '600844.SS', '600845.SS', '600846.SS', '600847.SS', '600848.SS', '600850.SS', '600851.SS', '600853.SS', '600854.SS', '600855.SS', '600857.SS', '600858.SS', '600859.SS', '600860.SS', '600861.SS', '600862.SS', '600863.SS', '600864.SS', '600865.SS', '600866.SS', '600867.SS', '600868.SS', '600869.SS', '600871.SS', '600872.SS', '600873.SS', '600874.SS', '600875.SS', '600876.SS', '600877.SS', '600879.SS', '600880.SS', '600881.SS', '600882.SS', '600883.SS', '600884.SS', '600885.SS', '600886.SS', '600887.SS', '600888.SS', '600889.SS', '600892.SS', '600893.SS', '600894.SS', '600895.SS', '600897.SS', '600900.SS', '600901.SS', '600903.SS', '600905.SS', '600906.SS', '600908.SS', '600909.SS', '600916.SS', '600917.SS', '600918.SS', '600919.SS', '600925.SS', '600926.SS', '600927.SS', '600928.SS', '600929.SS', '600933.SS', '600935.SS', '600936.SS', '600938.SS', '600939.SS', '600941.SS', '600955.SS', '600956.SS', '600958.SS', '600959.SS', '600960.SS', '600961.SS', '600962.SS', '600963.SS', '600965.SS', '600966.SS', '600967.SS', '600968.SS', '600969.SS', '600970.SS', '600971.SS', '600973.SS', '600975.SS', '600976.SS', '600977.SS', '600979.SS', '600980.SS', '600981.SS', '600982.SS', '600983.SS', '600984.SS', '600985.SS', '600986.SS', '600987.SS', '600988.SS', '600989.SS', '600990.SS', '600992.SS', '600993.SS', '600995.SS', '600996.SS', '600997.SS', '600998.SS', '600999.SS', '601000.SS', '601001.SS', '601002.SS', '601003.SS', '601005.SS', '601006.SS', '601007.SS', '601008.SS', '601009.SS', '601010.SS', '601011.SS', '601012.SS', '601015.SS', '601016.SS', '601018.SS', '601019.SS', '601020.SS', '601021.SS', '601022.SS', '601028.SS', '601033.SS', '601038.SS', '601058.SS', '601059.SS', '601061.SS', '601065.SS', '601066.SS', '601068.SS', '601069.SS', '601077.SS', '601083.SS', '601086.SS', '601088.SS', '601089.SS', '601096.SS', '601098.SS', '601099.SS', '601100.SS', '601101.SS', '601106.SS', '601107.SS', '601108.SS', '601111.SS', '601113.SS', '601116.SS', '601117.SS', '601118.SS', '601121.SS', '601126.SS', '601127.SS', '601128.SS', '601133.SS', '601136.SS', '601137.SS', '601138.SS', '601139.SS', '601155.SS', '601156.SS', '601158.SS', '601162.SS', '601163.SS', '601166.SS', '601168.SS', '601169.SS', '601177.SS', '601179.SS', '601186.SS', '601187.SS', '601188.SS', '601198.SS', '601199.SS', '601200.SS', '601208.SS', '601211.SS', '601212.SS', '601216.SS', '601218.SS', '601222.SS', '601225.SS', '601226.SS', '601228.SS', '601229.SS', '601231.SS', '601233.SS', '601236.SS', '601238.SS', '601279.SS', '601288.SS', '601298.SS', '601311.SS', '601318.SS', '601319.SS', '601326.SS', '601328.SS', '601330.SS', '601333.SS', '601336.SS', '601339.SS', '601360.SS', '601366.SS', '601368.SS', '601369.SS', '601375.SS', '601377.SS', '601388.SS', '601390.SS', '601398.SS', '601399.SS', '601456.SS', '601500.SS', '601512.SS', '601515.SS', '601518.SS', '601519.SS', '601528.SS', '601555.SS', '601566.SS', '601567.SS', '601568.SS', '601577.SS', '601579.SS', '601588.SS', '601595.SS', '601598.SS', '601599.SS', '601600.SS', '601601.SS', '601606.SS', '601607.SS', '601608.SS', '601609.SS', '601611.SS', '601615.SS', '601616.SS', '601618.SS', '601619.SS', '601628.SS', '601633.SS', '601636.SS', '601658.SS', '601665.SS', '601666.SS', '601668.SS', '601669.SS', '601677.SS', '601678.SS', '601686.SS', '601688.SS', '601689.SS', '601696.SS', '601698.SS', '601699.SS', '601700.SS', '601702.SS', '601717.SS', '601718.SS', '601727.SS', '601728.SS', '601766.SS', '601777.SS', '601778.SS', '601788.SS', '601789.SS', '601798.SS', '601799.SS', '601800.SS', '601801.SS', '601808.SS', '601811.SS', '601816.SS', '601818.SS', '601825.SS', '601827.SS', '601828.SS', '601838.SS', '601857.SS', '601858.SS', '601860.SS', '601865.SS', '601866.SS', '601868.SS', '601869.SS', '601872.SS', '601877.SS', '601878.SS', '601880.SS', '601881.SS', '601882.SS', '601886.SS', '601888.SS', '601890.SS', '601898.SS', '601899.SS', '601900.SS', '601901.SS', '601908.SS', '601916.SS', '601918.SS', '601919.SS', '601921.SS', '601928.SS', '601929.SS', '601933.SS', '601939.SS', '601949.SS', '601952.SS', '601956.SS', '601958.SS', '601963.SS', '601965.SS', '601966.SS', '601968.SS', '601969.SS', '601975.SS', '601985.SS', '601988.SS', '601989.SS', '601990.SS', '601991.SS', '601992.SS', '601995.SS', '601996.SS', '601997.SS', '601998.SS', '601999.SS', '603000.SS', '603001.SS', '603002.SS', '603003.SS', '603004.SS', '603005.SS', '603006.SS', '603007.SS', '603008.SS', '603009.SS', '603010.SS', '603011.SS', '603012.SS', '603013.SS', '603015.SS', '603016.SS', '603017.SS', '603018.SS', '603019.SS', '603020.SS', '603021.SS', '603022.SS', '603023.SS', '603025.SS', '603026.SS', '603027.SS', '603028.SS', '603029.SS', '603030.SS', '603031.SS', '603032.SS', '603033.SS', '603035.SS', '603036.SS', '603037.SS', '603038.SS', '603039.SS', '603040.SS', '603041.SS', '603042.SS', '603043.SS', '603045.SS', '603048.SS', '603050.SS', '603051.SS', '603052.SS', '603053.SS', '603055.SS', '603056.SS', '603057.SS', '603058.SS', '603059.SS', '603060.SS', '603061.SS', '603062.SS', '603063.SS', '603065.SS', '603066.SS', '603067.SS', '603068.SS', '603069.SS', '603070.SS', '603071.SS', '603072.SS', '603073.SS', '603075.SS', '603076.SS', '603077.SS', '603078.SS', '603079.SS', '603080.SS', '603081.SS', '603082.SS', '603083.SS', '603085.SS', '603086.SS', '603087.SS', '603088.SS', '603089.SS', '603090.SS', '603091.SS', '603093.SS', '603095.SS', '603096.SS', '603097.SS', '603098.SS', '603099.SS', '603100.SS', '603101.SS', '603102.SS', '603103.SS', '603105.SS', '603106.SS', '603107.SS', '603108.SS', '603109.SS', '603110.SS', '603111.SS', '603112.SS', '603113.SS', '603115.SS', '603116.SS', '603117.SS', '603118.SS', '603119.SS', '603121.SS', '603122.SS', '603123.SS', '603125.SS', '603126.SS', '603127.SS', '603128.SS', '603129.SS', '603130.SS', '603131.SS', '603132.SS', '603135.SS', '603136.SS', '603137.SS', '603138.SS', '603139.SS', '603150.SS', '603151.SS', '603153.SS', '603155.SS', '603156.SS', '603158.SS', '603159.SS', '603160.SS', '603161.SS', '603162.SS', '603163.SS', '603165.SS', '603166.SS', '603167.SS', '603168.SS', '603169.SS', '603170.SS', '603171.SS', '603172.SS', '603173.SS', '603176.SS', '603177.SS', '603178.SS', '603179.SS', '603180.SS', '603181.SS', '603182.SS', '603183.SS', '603185.SS', '603186.SS', '603187.SS', '603188.SS', '603189.SS', '603190.SS', '603191.SS', '603192.SS', '603193.SS', '603194.SS', '603195.SS', '603196.SS', '603197.SS', '603198.SS', '603199.SS', '603200.SS', '603201.SS', '603203.SS', '603205.SS', '603206.SS', '603207.SS', '603208.SS', '603209.SS', '603211.SS', '603212.SS', '603213.SS', '603214.SS', '603215.SS', '603216.SS', '603217.SS', '603218.SS', '603219.SS', '603220.SS', '603221.SS', '603222.SS', '603223.SS', '603225.SS', '603226.SS', '603227.SS', '603228.SS', '603229.SS', '603230.SS', '603231.SS', '603232.SS', '603233.SS', '603235.SS', '603236.SS', '603237.SS', '603238.SS', '603239.SS', '603255.SS', '603256.SS', '603258.SS', '603259.SS', '603260.SS', '603261.SS', '603266.SS', '603267.SS', '603268.SS', '603269.SS', '603270.SS', '603271.SS', '603272.SS', '603273.SS', '603275.SS', '603276.SS', '603277.SS', '603278.SS', '603279.SS', '603280.SS', '603281.SS', '603282.SS', '603283.SS', '603285.SS', '603286.SS', '603288.SS', '603289.SS', '603290.SS', '603291.SS', '603296.SS', '603297.SS', '603298.SS', '603299.SS', '603300.SS', '603301.SS', '603303.SS', '603305.SS', '603306.SS', '603307.SS', '603308.SS', '603309.SS', '603310.SS', '603311.SS', '603312.SS', '603313.SS', '603315.SS', '603316.SS', '603317.SS', '603318.SS', '603319.SS', '603320.SS', '603321.SS', '603322.SS', '603323.SS', '603324.SS', '603325.SS', '603326.SS', '603327.SS', '603328.SS', '603329.SS', '603330.SS', '603331.SS', '603332.SS', '603333.SS', '603335.SS', '603336.SS', '603337.SS', '603338.SS', '603339.SS', '603341.SS', '603344.SS', '603345.SS', '603348.SS', '603350.SS', '603351.SS', '603353.SS', '603355.SS', '603356.SS', '603357.SS', '603358.SS', '603359.SS', '603360.SS', '603363.SS', '603365.SS', '603366.SS', '603367.SS', '603368.SS', '603369.SS', '603373.SS', '603375.SS', '603377.SS', '603378.SS', '603379.SS', '603380.SS', '603381.SS', '603383.SS', '603385.SS', '603386.SS', '603387.SS', '603388.SS', '603389.SS', '603390.SS', '603391.SS', '603392.SS', '603393.SS', '603395.SS', '603396.SS', '603398.SS', '603399.SS', '603408.SS', '603409.SS', '603416.SS', '603421.SS', '603429.SS', '603439.SS', '603444.SS', '603456.SS', '603458.SS', '603466.SS', '603477.SS', '603486.SS', '603488.SS', '603489.SS', '603496.SS', '603499.SS', '603500.SS', '603501.SS', '603505.SS', '603506.SS', '603507.SS', '603508.SS', '603511.SS', '603515.SS', '603516.SS', '603517.SS', '603518.SS', '603519.SS', '603520.SS', '603527.SS', '603528.SS', '603529.SS', '603530.SS', '603533.SS', '603535.SS', '603536.SS', '603538.SS', '603551.SS', '603556.SS', '603557.SS', '603558.SS', '603559.SS', '603565.SS', '603566.SS', '603567.SS', '603568.SS', '603569.SS', '603577.SS', '603578.SS', '603579.SS', '603580.SS', '603583.SS', '603585.SS', '603586.SS', '603587.SS', '603588.SS', '603589.SS', '603590.SS', '603595.SS', '603596.SS', '603598.SS', '603599.SS', '603600.SS', '603601.SS', '603602.SS', '603605.SS', '603606.SS', '603607.SS', '603608.SS', '603609.SS', '603610.SS', '603611.SS', '603612.SS', '603613.SS', '603615.SS', '603616.SS', '603617.SS', '603618.SS', '603619.SS', '603626.SS', '603628.SS', '603629.SS', '603630.SS', '603633.SS', '603636.SS', '603637.SS', '603638.SS', '603639.SS', '603648.SS', '603650.SS', '603655.SS', '603656.SS', '603657.SS', '603658.SS', '603659.SS', '603660.SS', '603661.SS', '603662.SS', '603663.SS', '603665.SS', '603666.SS', '603667.SS', '603668.SS', '603669.SS', '603676.SS', '603677.SS', '603678.SS', '603679.SS', '603680.SS', '603681.SS', '603682.SS', '603683.SS', '603685.SS', '603686.SS', '603687.SS', '603688.SS', '603689.SS', '603690.SS', '603693.SS', '603696.SS', '603697.SS', '603698.SS', '603699.SS', '603700.SS', '603701.SS', '603703.SS', '603706.SS', '603707.SS', '603708.SS', '603709.SS', '603711.SS', '603712.SS', '603713.SS', '603716.SS', '603717.SS', '603718.SS', '603719.SS', '603721.SS', '603722.SS', '603725.SS', '603726.SS', '603727.SS', '603728.SS', '603729.SS', '603730.SS', '603733.SS', '603737.SS', '603738.SS', '603739.SS', '603755.SS', '603757.SS', '603758.SS', '603759.SS', '603766.SS', '603767.SS', '603768.SS', '603773.SS', '603776.SS', '603777.SS', '603778.SS', '603779.SS', '603786.SS', '603787.SS', '603788.SS', '603789.SS', '603790.SS', '603797.SS', '603798.SS', '603799.SS', '603800.SS', '603801.SS', '603803.SS', '603806.SS', '603808.SS', '603809.SS', '603810.SS', '603811.SS', '603813.SS', '603815.SS', '603816.SS', '603817.SS', '603818.SS', '603819.SS', '603822.SS', '603823.SS', '603825.SS', '603826.SS', '603828.SS', '603829.SS', '603833.SS', '603836.SS', '603838.SS', '603839.SS', '603843.SS', '603848.SS', '603855.SS', '603856.SS', '603858.SS', '603859.SS', '603860.SS', '603861.SS', '603863.SS', '603866.SS', '603867.SS', '603868.SS', '603869.SS', '603871.SS', '603876.SS', '603877.SS', '603878.SS', '603879.SS', '603880.SS', '603881.SS', '603882.SS', '603883.SS', '603885.SS', '603886.SS', '603887.SS', '603888.SS', '603889.SS', '603890.SS', '603893.SS', '603895.SS', '603896.SS', '603897.SS', '603898.SS', '603899.SS', '603900.SS', '603901.SS', '603903.SS', '603906.SS', '603908.SS', '603909.SS', '603912.SS', '603915.SS', '603916.SS', '603917.SS', '603918.SS', '603919.SS', '603920.SS', '603922.SS', '603926.SS', '603927.SS', '603928.SS', '603929.SS', '603931.SS', '603933.SS', '603936.SS', '603937.SS', '603938.SS', '603939.SS', '603948.SS', '603949.SS', '603950.SS', '603955.SS', '603956.SS', '603958.SS', '603959.SS', '603960.SS', '603963.SS', '603966.SS', '603967.SS', '603968.SS', '603969.SS', '603970.SS', '603976.SS', '603977.SS', '603978.SS', '603979.SS', '603980.SS', '603982.SS', '603983.SS', '603985.SS', '603986.SS', '603987.SS', '603988.SS', '603989.SS', '603990.SS', '603991.SS', '603992.SS', '603993.SS', '603995.SS', '603997.SS', '603998.SS', '603999.SS', '605001.SS', '605003.SS', '605005.SS', '605006.SS', '605007.SS', '605008.SS', '605009.SS', '605011.SS', '605016.SS', '605018.SS', '605020.SS', '605028.SS', '605033.SS', '605050.SS', '605055.SS', '605056.SS', '605058.SS', '605060.SS', '605066.SS', '605068.SS', '605069.SS', '605077.SS', '605080.SS', '605081.SS', '605086.SS', '605088.SS', '605089.SS', '605090.SS', '605098.SS', '605099.SS', '605100.SS', '605108.SS', '605111.SS', '605116.SS', '605117.SS', '605118.SS', '605122.SS', '605123.SS', '605128.SS', '605133.SS', '605136.SS', '605138.SS', '605151.SS', '605155.SS', '605158.SS', '605162.SS', '605166.SS', '605167.SS', '605168.SS', '605169.SS', '605177.SS', '605178.SS', '605179.SS', '605180.SS', '605183.SS', '605186.SS', '605188.SS', '605189.SS', '605196.SS', '605198.SS', '605199.SS', '605208.SS', '605218.SS', '605222.SS', '605228.SS', '605255.SS', '605258.SS', '605259.SS', '605266.SS', '605268.SS', '605277.SS', '605286.SS', '605287.SS', '605288.SS', '605289.SS', '605296.SS', '605298.SS', '605299.SS', '605300.SS', '605303.SS', '605305.SS', '605318.SS', '605319.SS', '605333.SS', '605336.SS', '605337.SS', '605338.SS', '605339.SS', '605358.SS', '605365.SS', '605366.SS', '605368.SS', '605369.SS', '605376.SS', '605377.SS', '605378.SS', '605388.SS', '605389.SS', '605398.SS', '605399.SS', '605488.SS', '605499.SS', '605500.SS', '605507.SS', '605555.SS', '605566.SS', '605567.SS', '605577.SS', '605580.SS', '605588.SS', '605589.SS', '605598.SS', '605599.SS', '000001.SZ', '000002.SZ', '000004.SZ', '000006.SZ', '000007.SZ', '000008.SZ', '000009.SZ', '000010.SZ', '000011.SZ', '000012.SZ', '000014.SZ', '000016.SZ', '000017.SZ', '000019.SZ', '000020.SZ', '000021.SZ', '000025.SZ', '000026.SZ', '000027.SZ', '000028.SZ', '000029.SZ', '000030.SZ', '000031.SZ', '000032.SZ', '000034.SZ', '000035.SZ', '000036.SZ', '000037.SZ', '000039.SZ', '000040.SZ', '000042.SZ', '000045.SZ', '000048.SZ', '000049.SZ', '000050.SZ', '000055.SZ', '000056.SZ', '000058.SZ', '000059.SZ', '000060.SZ', '000061.SZ', '000062.SZ', '000063.SZ', '000065.SZ', '000066.SZ', '000068.SZ', '000069.SZ', '000070.SZ', '000078.SZ', '000088.SZ', '000089.SZ', '000090.SZ', '000096.SZ', '000099.SZ', '000100.SZ', '000151.SZ', '000153.SZ', '000155.SZ', '000156.SZ', '000157.SZ', '000158.SZ', '000159.SZ', '000166.SZ', '000301.SZ', '000333.SZ', '000338.SZ', '000400.SZ', '000401.SZ', '000402.SZ', '000403.SZ', '000404.SZ', '000407.SZ', '000408.SZ', '000409.SZ', '000410.SZ', '000411.SZ', '000415.SZ', '000417.SZ', '000419.SZ', '000420.SZ', '000421.SZ', '000422.SZ', '000423.SZ', '000425.SZ', '000426.SZ', '000428.SZ', '000429.SZ', '000430.SZ', '000488.SZ', '000498.SZ', '000501.SZ', '000503.SZ', '000504.SZ', '000505.SZ', '000506.SZ', '000507.SZ', '000509.SZ', '000510.SZ', '000513.SZ', '000514.SZ', '000516.SZ', '000517.SZ', '000518.SZ', '000519.SZ', '000520.SZ', '000521.SZ', '000523.SZ', '000524.SZ', '000525.SZ', '000526.SZ', '000528.SZ', '000529.SZ', '000530.SZ', '000531.SZ', '000532.SZ', '000533.SZ', '000534.SZ', '000536.SZ', '000537.SZ', '000538.SZ', '000539.SZ', '000541.SZ', '000543.SZ', '000544.SZ', '000545.SZ', '000546.SZ', '000547.SZ', '000548.SZ', '000550.SZ', '000551.SZ', '000552.SZ', '000553.SZ', '000554.SZ', '000555.SZ', '000557.SZ', '000558.SZ', '000559.SZ', '000560.SZ', '000561.SZ', '000563.SZ', '000564.SZ', '000565.SZ', '000566.SZ', '000567.SZ', '000568.SZ', '000570.SZ', '000571.SZ', '000572.SZ', '000573.SZ', '000576.SZ', '000581.SZ', '000582.SZ', '000584.SZ', '000586.SZ', '000589.SZ', '000590.SZ', '000591.SZ', '000592.SZ', '000593.SZ', '000595.SZ', '000596.SZ', '000597.SZ', '000598.SZ', '000599.SZ', '000600.SZ', '000601.SZ', '000603.SZ', '000605.SZ', '000607.SZ', '000608.SZ', '000609.SZ', '000610.SZ', '000612.SZ', '000615.SZ', '000617.SZ', '000619.SZ', '000620.SZ', '000622.SZ', '000623.SZ', '000625.SZ', '000626.SZ', '000627.SZ', '000628.SZ', '000629.SZ', '000630.SZ', '000631.SZ', '000632.SZ', '000633.SZ', '000635.SZ', '000636.SZ', '000637.SZ', '000638.SZ', '000639.SZ', '000650.SZ', '000651.SZ', '000652.SZ', '000655.SZ', '000656.SZ', '000657.SZ', '000659.SZ', '000661.SZ', '000663.SZ', '000665.SZ', '000668.SZ', '000669.SZ', '000670.SZ', '000672.SZ', '000676.SZ', '000677.SZ', '000678.SZ', '000679.SZ', '000680.SZ', '000681.SZ', '000682.SZ', '000683.SZ', '000685.SZ', '000686.SZ', '000688.SZ', '000690.SZ', '000691.SZ', '000692.SZ', '000695.SZ', '000697.SZ', '000698.SZ', '000700.SZ', '000701.SZ', '000702.SZ', '000703.SZ', '000705.SZ', '000707.SZ', '000708.SZ', '000709.SZ', '000710.SZ', '000711.SZ', '000712.SZ', '000713.SZ', '000715.SZ', '000716.SZ', '000717.SZ', '000718.SZ', '000719.SZ', '000720.SZ', '000721.SZ', '000722.SZ', '000723.SZ', '000725.SZ', '000726.SZ', '000727.SZ', '000728.SZ', '000729.SZ', '000731.SZ', '000733.SZ', '000735.SZ', '000736.SZ', '000737.SZ', '000738.SZ', '000739.SZ', '000750.SZ', '000751.SZ', '000752.SZ', '000753.SZ', '000755.SZ', '000756.SZ', '000757.SZ', '000758.SZ', '000759.SZ', '000761.SZ', '000762.SZ', '000766.SZ', '000767.SZ', '000768.SZ', '000776.SZ', '000777.SZ', '000778.SZ', '000779.SZ', '000782.SZ', '000783.SZ', '000785.SZ', '000786.SZ', '000788.SZ', '000789.SZ', '000790.SZ', '000791.SZ', '000792.SZ', '000793.SZ', '000795.SZ', '000796.SZ', '000797.SZ', '000798.SZ', '000799.SZ', '000800.SZ', '000801.SZ', '000802.SZ', '000803.SZ', '000807.SZ', '000809.SZ', '000810.SZ', '000811.SZ', '000812.SZ', '000813.SZ', '000815.SZ', '000816.SZ', '000818.SZ', '000819.SZ', '000820.SZ', '000821.SZ', '000822.SZ', '000823.SZ', '000825.SZ', '000826.SZ', '000828.SZ', '000829.SZ', '000830.SZ', '000831.SZ', '000833.SZ', '000837.SZ', '000838.SZ', '000839.SZ', '000848.SZ', '000850.SZ', '000851.SZ', '000852.SZ', '000856.SZ', '000858.SZ', '000859.SZ', '000860.SZ', '000862.SZ', '000863.SZ', '000868.SZ', '000869.SZ', '000875.SZ', '000876.SZ', '000877.SZ', '000878.SZ', '000880.SZ', '000881.SZ', '000882.SZ', '000883.SZ', '000885.SZ', '000886.SZ', '000887.SZ', '000888.SZ', '000889.SZ', '000890.SZ', '000892.SZ', '000893.SZ', '000895.SZ', '000897.SZ', '000898.SZ', '000899.SZ', '000900.SZ', '000901.SZ', '000902.SZ', '000903.SZ', '000905.SZ', '000906.SZ', '000908.SZ', '000909.SZ', '000910.SZ', '000911.SZ', '000912.SZ', '000913.SZ', '000915.SZ', '000917.SZ', '000919.SZ', '000920.SZ', '000921.SZ', '000922.SZ', '000923.SZ', '000925.SZ', '000926.SZ', '000927.SZ', '000928.SZ', '000929.SZ', '000930.SZ', '000931.SZ', '000932.SZ', '000933.SZ', '000935.SZ', '000936.SZ', '000937.SZ', '000938.SZ', '000948.SZ', '000949.SZ', '000950.SZ', '000951.SZ', '000952.SZ', '000953.SZ', '000955.SZ', '000957.SZ', '000958.SZ', '000959.SZ', '000960.SZ', '000962.SZ', '000963.SZ', '000965.SZ', '000966.SZ', '000967.SZ', '000968.SZ', '000969.SZ', '000970.SZ', '000972.SZ', '000973.SZ', '000975.SZ', '000977.SZ', '000978.SZ', '000980.SZ', '000981.SZ', '000983.SZ', '000985.SZ', '000987.SZ', '000988.SZ', '000989.SZ', '000990.SZ', '000993.SZ', '000995.SZ', '000997.SZ', '000998.SZ', '000999.SZ', '001201.SZ', '001202.SZ', '001203.SZ', '001205.SZ', '001206.SZ', '001207.SZ', '001208.SZ', '001209.SZ', '001210.SZ', '001211.SZ', '001212.SZ', '001213.SZ', '001215.SZ', '001216.SZ', '001217.SZ', '001218.SZ', '001219.SZ', '001222.SZ', '001223.SZ', '001225.SZ', '001226.SZ', '001227.SZ', '001228.SZ', '001229.SZ', '001230.SZ', '001231.SZ', '001234.SZ', '001236.SZ', '001238.SZ', '001239.SZ', '001255.SZ', '001256.SZ', '001258.SZ', '001259.SZ', '001260.SZ', '001266.SZ', '001267.SZ', '001268.SZ', '001269.SZ', '001270.SZ', '001277.SZ', '001278.SZ', '001279.SZ', '001282.SZ', '001283.SZ', '001286.SZ', '001287.SZ', '001288.SZ', '001289.SZ', '001296.SZ', '001298.SZ', '001299.SZ', '001300.SZ', '001301.SZ', '001306.SZ', '001308.SZ', '001309.SZ', '001311.SZ', '001313.SZ', '001314.SZ', '001316.SZ', '001317.SZ', '001318.SZ', '001319.SZ', '001322.SZ', '001323.SZ', '001324.SZ', '001326.SZ', '001328.SZ', '001330.SZ', '001331.SZ', '001332.SZ', '001333.SZ', '001336.SZ', '001337.SZ', '001338.SZ', '001339.SZ', '001356.SZ', '001358.SZ', '001359.SZ', '001360.SZ', '001366.SZ', '001367.SZ', '001368.SZ', '001373.SZ', '001376.SZ', '001378.SZ', '001379.SZ', '001380.SZ', '001387.SZ', '001389.SZ', '001391.SZ', '001395.SZ', '001696.SZ', '001872.SZ', '001896.SZ', '001914.SZ', '001965.SZ', '001979.SZ', '002001.SZ', '002003.SZ', '002004.SZ', '002005.SZ', '002006.SZ', '002007.SZ', '002008.SZ', '002009.SZ', '002010.SZ', '002011.SZ', '002012.SZ', '002014.SZ', '002015.SZ', '002016.SZ', '002017.SZ', '002019.SZ', '002020.SZ', '002021.SZ', '002022.SZ', '002023.SZ', '002024.SZ', '002025.SZ', '002026.SZ', '002027.SZ', '002028.SZ', '002029.SZ', '002030.SZ', '002031.SZ', '002032.SZ', '002033.SZ', '002034.SZ', '002035.SZ', '002036.SZ', '002037.SZ', '002038.SZ', '002039.SZ', '002040.SZ', '002041.SZ', '002042.SZ', '002043.SZ', '002044.SZ', '002045.SZ', '002046.SZ', '002047.SZ', '002048.SZ', '002049.SZ', '002050.SZ', '002051.SZ', '002052.SZ', '002053.SZ', '002054.SZ', '002055.SZ', '002056.SZ', '002057.SZ', '002058.SZ', '002059.SZ', '002060.SZ', '002061.SZ', '002062.SZ', '002063.SZ', '002064.SZ', '002065.SZ', '002066.SZ', '002067.SZ', '002068.SZ', '002069.SZ', '002072.SZ', '002073.SZ', '002074.SZ', '002075.SZ', '002076.SZ', '002077.SZ', '002078.SZ', '002079.SZ', '002080.SZ', '002081.SZ', '002082.SZ', '002083.SZ', '002084.SZ', '002085.SZ', '002086.SZ', '002088.SZ', '002090.SZ', '002091.SZ', '002092.SZ', '002093.SZ', '002094.SZ', '002095.SZ', '002096.SZ', '002097.SZ', '002098.SZ', '002099.SZ', '002100.SZ', '002101.SZ', '002102.SZ', '002103.SZ', '002104.SZ', '002105.SZ', '002106.SZ', '002107.SZ', '002108.SZ', '002109.SZ', '002110.SZ', '002111.SZ', '002112.SZ', '002114.SZ', '002115.SZ', '002116.SZ', '002117.SZ', '002119.SZ', '002120.SZ', '002121.SZ', '002122.SZ', '002123.SZ', '002124.SZ', '002125.SZ', '002126.SZ', '002127.SZ', '002128.SZ', '002129.SZ', '002130.SZ', '002131.SZ', '002132.SZ', '002133.SZ', '002134.SZ', '002135.SZ', '002136.SZ', '002137.SZ', '002138.SZ', '002139.SZ', '002140.SZ', '002141.SZ', '002142.SZ', '002144.SZ', '002145.SZ', '002146.SZ', '002148.SZ', '002149.SZ', '002150.SZ', '002151.SZ', '002152.SZ', '002153.SZ', '002154.SZ', '002155.SZ', '002156.SZ', '002157.SZ', '002158.SZ', '002159.SZ', '002160.SZ', '002161.SZ', '002162.SZ', '002163.SZ', '002164.SZ', '002165.SZ', '002166.SZ', '002167.SZ', '002168.SZ', '002169.SZ', '002170.SZ', '002171.SZ', '002172.SZ', '002173.SZ', '002174.SZ', '002175.SZ', '002176.SZ', '002177.SZ', '002178.SZ', '002179.SZ', '002180.SZ', '002181.SZ', '002182.SZ', '002183.SZ', '002184.SZ', '002185.SZ', '002186.SZ', '002187.SZ', '002188.SZ', '002189.SZ', '002190.SZ', '002191.SZ', '002192.SZ', '002193.SZ', '002194.SZ', '002195.SZ', '002196.SZ', '002197.SZ', '002198.SZ', '002199.SZ', '002200.SZ', '002201.SZ', '002202.SZ', '002203.SZ', '002204.SZ', '002205.SZ', '002206.SZ', '002207.SZ', '002208.SZ', '002209.SZ', '002210.SZ', '002211.SZ', '002212.SZ', '002213.SZ', '002214.SZ', '002215.SZ', '002216.SZ', '002217.SZ', '002218.SZ', '002219.SZ', '002221.SZ', '002222.SZ', '002223.SZ', '002224.SZ', '002225.SZ', '002226.SZ', '002227.SZ', '002228.SZ', '002229.SZ', '002230.SZ', '002231.SZ', '002232.SZ', '002233.SZ', '002234.SZ', '002235.SZ', '002236.SZ', '002237.SZ', '002238.SZ', '002239.SZ', '002240.SZ', '002241.SZ', '002242.SZ', '002243.SZ', '002244.SZ', '002245.SZ', '002246.SZ', '002247.SZ', '002248.SZ', '002249.SZ', '002250.SZ', '002251.SZ', '002252.SZ', '002253.SZ', '002254.SZ', '002255.SZ', '002256.SZ', '002258.SZ', '002259.SZ', '002261.SZ', '002262.SZ', '002263.SZ', '002264.SZ', '002265.SZ', '002266.SZ', '002267.SZ', '002268.SZ', '002269.SZ', '002270.SZ', '002271.SZ', '002272.SZ', '002273.SZ', '002274.SZ', '002275.SZ', '002276.SZ', '002277.SZ', '002278.SZ', '002279.SZ', '002281.SZ', '002282.SZ', '002283.SZ', '002284.SZ', '002285.SZ', '002286.SZ', '002287.SZ', '002289.SZ', '002290.SZ', '002291.SZ', '002292.SZ', '002293.SZ', '002294.SZ', '002295.SZ', '002296.SZ', '002297.SZ', '002298.SZ', '002299.SZ', '002300.SZ', '002301.SZ', '002302.SZ', '002303.SZ', '002304.SZ', '002305.SZ', '002306.SZ', '002307.SZ', '002309.SZ', '002310.SZ', '002311.SZ', '002312.SZ', '002313.SZ', '002314.SZ', '002315.SZ', '002316.SZ', '002317.SZ', '002318.SZ', '002319.SZ', '002320.SZ', '002321.SZ', '002322.SZ', '002323.SZ', '002324.SZ', '002326.SZ', '002327.SZ', '002328.SZ', '002329.SZ', '002330.SZ', '002331.SZ', '002332.SZ', '002333.SZ', '002334.SZ', '002335.SZ', '002336.SZ', '002337.SZ', '002338.SZ', '002339.SZ', '002340.SZ', '002342.SZ', '002343.SZ', '002344.SZ', '002345.SZ', '002346.SZ', '002347.SZ', '002348.SZ', '002349.SZ', '002350.SZ', '002351.SZ', '002352.SZ', '002353.SZ', '002354.SZ', '002355.SZ', '002356.SZ', '002357.SZ', '002358.SZ', '002360.SZ', '002361.SZ', '002362.SZ', '002363.SZ', '002364.SZ', '002365.SZ', '002366.SZ', '002367.SZ', '002368.SZ', '002369.SZ', '002370.SZ', '002371.SZ', '002372.SZ', '002373.SZ', '002374.SZ', '002375.SZ', '002376.SZ', '002377.SZ', '002378.SZ', '002379.SZ', '002380.SZ', '002381.SZ', '002382.SZ', '002383.SZ', '002384.SZ', '002385.SZ', '002386.SZ', '002387.SZ', '002388.SZ', '002389.SZ', '002390.SZ', '002391.SZ', '002392.SZ', '002393.SZ', '002394.SZ', '002395.SZ', '002396.SZ', '002397.SZ', '002398.SZ', '002399.SZ', '002400.SZ', '002401.SZ', '002402.SZ', '002403.SZ', '002404.SZ', '002405.SZ', '002406.SZ', '002407.SZ', '002408.SZ', '002409.SZ', '002410.SZ', '002412.SZ', '002413.SZ', '002414.SZ', '002415.SZ', '002416.SZ', '002418.SZ', '002419.SZ', '002420.SZ', '002421.SZ', '002422.SZ', '002423.SZ', '002424.SZ', '002425.SZ', '002426.SZ', '002427.SZ', '002428.SZ', '002429.SZ', '002430.SZ', '002431.SZ', '002432.SZ', '002434.SZ', '002436.SZ', '002437.SZ', '002438.SZ', '002439.SZ', '002440.SZ', '002441.SZ', '002442.SZ', '002443.SZ', '002444.SZ', '002445.SZ', '002446.SZ', '002448.SZ', '002449.SZ', '002451.SZ', '002452.SZ', '002453.SZ', '002454.SZ', '002455.SZ', '002456.SZ', '002457.SZ', '002458.SZ', '002459.SZ', '002460.SZ', '002461.SZ', '002462.SZ', '002463.SZ', '002465.SZ', '002466.SZ', '002467.SZ', '002468.SZ', '002469.SZ', '002470.SZ', '002471.SZ', '002472.SZ', '002474.SZ', '002475.SZ', '002476.SZ', '002478.SZ', '002479.SZ', '002480.SZ', '002481.SZ', '002482.SZ', '002483.SZ', '002484.SZ', '002485.SZ', '002486.SZ', '002487.SZ', '002488.SZ', '002489.SZ', '002490.SZ', '002491.SZ', '002492.SZ', '002493.SZ', '002494.SZ', '002495.SZ', '002496.SZ', '002497.SZ', '002498.SZ', '002500.SZ', '002501.SZ', '002506.SZ', '002507.SZ', '002508.SZ', '002510.SZ', '002511.SZ', '002512.SZ', '002513.SZ', '002514.SZ', '002515.SZ', '002516.SZ', '002517.SZ', '002518.SZ', '002519.SZ', '002520.SZ', '002521.SZ', '002522.SZ', '002523.SZ', '002524.SZ', '002526.SZ', '002527.SZ', '002528.SZ', '002529.SZ', '002530.SZ', '002531.SZ', '002532.SZ', '002533.SZ', '002534.SZ', '002535.SZ', '002536.SZ', '002537.SZ', '002538.SZ', '002539.SZ', '002540.SZ', '002541.SZ', '002542.SZ', '002543.SZ', '002544.SZ', '002545.SZ', '002546.SZ', '002547.SZ', '002548.SZ', '002549.SZ', '002550.SZ', '002551.SZ', '002552.SZ', '002553.SZ', '002554.SZ', '002555.SZ', '002556.SZ', '002557.SZ', '002558.SZ', '002559.SZ', '002560.SZ', '002561.SZ', '002562.SZ', '002563.SZ', '002564.SZ', '002565.SZ', '002566.SZ', '002567.SZ', '002568.SZ', '002569.SZ', '002570.SZ', '002571.SZ', '002572.SZ', '002573.SZ', '002574.SZ', '002575.SZ', '002576.SZ', '002577.SZ', '002578.SZ', '002579.SZ', '002580.SZ', '002581.SZ', '002582.SZ', '002583.SZ', '002584.SZ', '002585.SZ', '002586.SZ', '002587.SZ', '002588.SZ', '002589.SZ', '002590.SZ', '002591.SZ', '002592.SZ', '002593.SZ', '002594.SZ', '002595.SZ', '002596.SZ', '002597.SZ', '002598.SZ', '002599.SZ', '002600.SZ', '002601.SZ', '002602.SZ', '002603.SZ', '002605.SZ', '002606.SZ', '002607.SZ', '002608.SZ', '002609.SZ', '002611.SZ', '002612.SZ', '002613.SZ', '002614.SZ', '002615.SZ', '002616.SZ', '002617.SZ', '002620.SZ', '002622.SZ', '002623.SZ', '002624.SZ', '002625.SZ', '002626.SZ', '002627.SZ', '002628.SZ', '002629.SZ', '002630.SZ', '002631.SZ', '002632.SZ', '002633.SZ', '002634.SZ', '002635.SZ', '002636.SZ', '002637.SZ', '002638.SZ', '002639.SZ', '002640.SZ', '002641.SZ', '002642.SZ', '002643.SZ', '002644.SZ', '002645.SZ', '002646.SZ', '002647.SZ', '002648.SZ', '002649.SZ', '002650.SZ', '002651.SZ', '002652.SZ', '002653.SZ', '002654.SZ', '002655.SZ', '002656.SZ', '002657.SZ', '002658.SZ', '002659.SZ', '002660.SZ', '002661.SZ', '002662.SZ', '002663.SZ', '002664.SZ', '002666.SZ', '002667.SZ', '002668.SZ', '002669.SZ', '002670.SZ', '002671.SZ', '002672.SZ', '002673.SZ', '002674.SZ', '002675.SZ', '002676.SZ', '002677.SZ', '002678.SZ', '002679.SZ', '002681.SZ', '002682.SZ', '002683.SZ', '002685.SZ', '002686.SZ', '002687.SZ', '002688.SZ', '002689.SZ', '002690.SZ', '002691.SZ', '002692.SZ', '002693.SZ', '002694.SZ', '002695.SZ', '002696.SZ', '002697.SZ', '002698.SZ', '002700.SZ', '002701.SZ', '002702.SZ', '002703.SZ', '002705.SZ', '002706.SZ', '002707.SZ', '002708.SZ', '002709.SZ', '002712.SZ', '002713.SZ', '002714.SZ', '002715.SZ', '002716.SZ', '002717.SZ', '002718.SZ', '002719.SZ', '002721.SZ', '002722.SZ', '002723.SZ', '002724.SZ', '002725.SZ', '002726.SZ', '002727.SZ', '002728.SZ', '002729.SZ', '002730.SZ', '002731.SZ', '002732.SZ', '002733.SZ', '002734.SZ', '002735.SZ', '002736.SZ', '002737.SZ', '002738.SZ', '002739.SZ', '002741.SZ', '002742.SZ', '002743.SZ', '002745.SZ', '002746.SZ', '002747.SZ', '002748.SZ', '002749.SZ', '002750.SZ', '002752.SZ', '002753.SZ', '002755.SZ', '002756.SZ', '002757.SZ', '002758.SZ', '002759.SZ', '002760.SZ', '002761.SZ', '002762.SZ', '002763.SZ', '002765.SZ', '002766.SZ', '002767.SZ', '002768.SZ', '002769.SZ', '002771.SZ', '002772.SZ', '002773.SZ', '002774.SZ', '002775.SZ', '002777.SZ', '002778.SZ', '002779.SZ', '002780.SZ', '002782.SZ', '002783.SZ', '002785.SZ', '002786.SZ', '002787.SZ', '002788.SZ', '002789.SZ', '002790.SZ', '002791.SZ', '002792.SZ', '002793.SZ', '002795.SZ', '002796.SZ', '002797.SZ', '002798.SZ', '002799.SZ', '002800.SZ', '002801.SZ', '002802.SZ', '002803.SZ', '002805.SZ', '002806.SZ', '002807.SZ', '002808.SZ', '002809.SZ', '002810.SZ', '002811.SZ', '002812.SZ', '002813.SZ', '002815.SZ', '002816.SZ', '002817.SZ', '002818.SZ', '002819.SZ', '002820.SZ', '002821.SZ', '002822.SZ', '002823.SZ', '002824.SZ', '002825.SZ', '002826.SZ', '002827.SZ', '002828.SZ', '002829.SZ', '002830.SZ', '002831.SZ', '002832.SZ', '002833.SZ', '002835.SZ', '002836.SZ', '002837.SZ', '002838.SZ', '002839.SZ', '002840.SZ', '002841.SZ', '002842.SZ', '002843.SZ', '002845.SZ', '002846.SZ', '002847.SZ', '002848.SZ', '002849.SZ', '002850.SZ', '002851.SZ', '002852.SZ', '002853.SZ', '002855.SZ', '002856.SZ', '002857.SZ', '002858.SZ', '002859.SZ', '002860.SZ', '002861.SZ', '002862.SZ', '002863.SZ', '002864.SZ', '002865.SZ', '002866.SZ', '002867.SZ', '002868.SZ', '002869.SZ', '002870.SZ', '002871.SZ', '002872.SZ', '002873.SZ', '002875.SZ', '002876.SZ', '002877.SZ', '002878.SZ', '002879.SZ', '002880.SZ', '002881.SZ', '002882.SZ', '002883.SZ', '002884.SZ', '002885.SZ', '002886.SZ', '002887.SZ', '002888.SZ', '002889.SZ', '002890.SZ', '002891.SZ', '002892.SZ', '002893.SZ', '002895.SZ', '002896.SZ', '002897.SZ', '002898.SZ', '002899.SZ', '002900.SZ', '002901.SZ', '002902.SZ', '002903.SZ', '002905.SZ', '002906.SZ', '002907.SZ', '002908.SZ', '002909.SZ', '002910.SZ', '002911.SZ', '002912.SZ', '002913.SZ', '002915.SZ', '002916.SZ', '002917.SZ', '002918.SZ', '002919.SZ', '002920.SZ', '002921.SZ', '002922.SZ', '002923.SZ', '002925.SZ', '002926.SZ', '002927.SZ', '002928.SZ', '002929.SZ', '002930.SZ', '002931.SZ', '002932.SZ', '002933.SZ', '002935.SZ', '002936.SZ', '002937.SZ', '002938.SZ', '002939.SZ', '002940.SZ', '002941.SZ', '002942.SZ', '002943.SZ', '002945.SZ', '002946.SZ', '002947.SZ', '002948.SZ', '002949.SZ', '002950.SZ', '002951.SZ', '002952.SZ', '002953.SZ', '002955.SZ', '002956.SZ', '002957.SZ', '002958.SZ', '002959.SZ', '002960.SZ', '002961.SZ', '002962.SZ', '002963.SZ', '002965.SZ', '002966.SZ', '002967.SZ', '002968.SZ', '002969.SZ', '002970.SZ', '002971.SZ', '002972.SZ', '002973.SZ', '002975.SZ', '002976.SZ', '002977.SZ', '002978.SZ', '002979.SZ', '002980.SZ', '002981.SZ', '002982.SZ', '002983.SZ', '002984.SZ', '002985.SZ', '002986.SZ', '002987.SZ', '002988.SZ', '002989.SZ', '002990.SZ', '002991.SZ', '002992.SZ', '002993.SZ', '002995.SZ', '002996.SZ', '002997.SZ', '002998.SZ', '002999.SZ', '003000.SZ', '003001.SZ', '003002.SZ', '003003.SZ', '003004.SZ', '003005.SZ', '003006.SZ', '003007.SZ', '003008.SZ', '003009.SZ', '003010.SZ', '003011.SZ', '003012.SZ', '003013.SZ', '003015.SZ', '003016.SZ', '003017.SZ', '003018.SZ', '003019.SZ', '003020.SZ', '003021.SZ', '003022.SZ', '003023.SZ', '003025.SZ', '003026.SZ', '003027.SZ', '003028.SZ', '003029.SZ', '003030.SZ', '003031.SZ', '003032.SZ', '003033.SZ', '003035.SZ', '003036.SZ', '003037.SZ', '003038.SZ', '003039.SZ', '003040.SZ', '003041.SZ', '003042.SZ', '003043.SZ', '003816.SZ', '688001.SS', '688002.SS', '688003.SS', '688004.SS', '688005.SS', '688006.SS', '688007.SS', '688008.SS', '688009.SS', '688010.SS', '688011.SS', '688012.SS', '688013.SS', '688015.SS', '688016.SS', '688017.SS', '688018.SS', '688019.SS', '688020.SS', '688021.SS', '688022.SS', '688023.SS', '688025.SS', '688026.SS', '688027.SS', '688028.SS', '688029.SS', '688030.SS', '688031.SS', '688032.SS', '688033.SS', '688035.SS', '688036.SS', '688037.SS', '688038.SS', '688039.SS', '688041.SS', '688045.SS', '688046.SS', '688047.SS', '688048.SS', '688049.SS', '688050.SS', '688051.SS', '688052.SS', '688053.SS', '688055.SS', '688056.SS', '688057.SS', '688058.SS', '688059.SS', '688060.SS', '688061.SS', '688062.SS', '688063.SS', '688065.SS', '688066.SS', '688067.SS', '688068.SS', '688069.SS', '688070.SS', '688071.SS', '688072.SS', '688073.SS', '688075.SS', '688076.SS', '688077.SS', '688078.SS', '688079.SS', '688080.SS', '688081.SS', '688082.SS', '688083.SS', '688084.SS', '688085.SS', '688087.SS', '688088.SS', '688089.SS', '688090.SS', '688091.SS', '688092.SS', '688093.SS', '688095.SS', '688096.SS', '688097.SS', '688098.SS', '688099.SS', '688100.SS', '688101.SS', '688102.SS', '688103.SS', '688105.SS', '688106.SS', '688107.SS', '688108.SS', '688109.SS', '688110.SS', '688111.SS', '688112.SS', '688113.SS', '688114.SS', '688115.SS', '688116.SS', '688117.SS', '688118.SS', '688119.SS', '688120.SS', '688121.SS', '688122.SS', '688123.SS', '688125.SS', '688126.SS', '688127.SS', '688128.SS', '688129.SS', '688130.SS', '688131.SS', '688132.SS', '688133.SS', '688135.SS', '688136.SS', '688137.SS', '688138.SS', '688139.SS', '688141.SS', '688143.SS', '688146.SS', '688147.SS', '688148.SS', '688150.SS', '688151.SS', '688152.SS', '688153.SS', '688155.SS', '688156.SS', '688157.SS', '688158.SS', '688159.SS', '688160.SS', '688161.SS', '688162.SS', '688163.SS', '688165.SS', '688166.SS', '688167.SS', '688168.SS', '688169.SS', '688170.SS', '688171.SS', '688172.SS', '688173.SS', '688175.SS', '688176.SS', '688177.SS', '688178.SS', '688179.SS', '688180.SS', '688181.SS', '688182.SS', '688183.SS', '688184.SS', '688185.SS', '688186.SS', '688187.SS', '688188.SS', '688189.SS', '688190.SS', '688191.SS', '688192.SS', '688193.SS', '688195.SS', '688196.SS', '688197.SS', '688198.SS', '688199.SS', '688200.SS', '688201.SS', '688202.SS', '688203.SS', '688205.SS', '688206.SS', '688207.SS', '688208.SS', '688209.SS', '688210.SS', '688211.SS', '688212.SS', '688213.SS', '688215.SS', '688216.SS', '688217.SS', '688218.SS', '688219.SS', '688220.SS', '688221.SS', '688222.SS', '688223.SS', '688225.SS', '688226.SS', '688227.SS', '688228.SS', '688229.SS', '688230.SS', '688231.SS', '688232.SS', '688233.SS', '688234.SS', '688235.SS', '688236.SS', '688237.SS', '688238.SS', '688239.SS', '688244.SS', '688246.SS', '688247.SS', '688248.SS', '688249.SS', '688251.SS', '688252.SS', '688253.SS', '688255.SS', '688256.SS', '688257.SS', '688258.SS', '688259.SS', '688260.SS', '688261.SS', '688262.SS', '688265.SS', '688266.SS', '688267.SS', '688268.SS', '688269.SS', '688270.SS', '688271.SS', '688272.SS', '688273.SS', '688275.SS', '688276.SS', '688277.SS', '688278.SS', '688279.SS', '688280.SS', '688281.SS', '688282.SS', '688283.SS', '688285.SS', '688286.SS', '688287.SS', '688288.SS', '688289.SS', '688290.SS', '688291.SS', '688292.SS', '688293.SS', '688295.SS', '688296.SS', '688297.SS', '688298.SS', '688299.SS', '688300.SS', '688301.SS', '688302.SS', '688303.SS', '688305.SS', '688306.SS', '688307.SS', '688308.SS', '688309.SS', '688310.SS', '688311.SS', '688312.SS', '688313.SS', '688314.SS', '688315.SS', '688316.SS', '688317.SS', '688318.SS', '688319.SS', '688320.SS', '688321.SS', '688322.SS', '688323.SS', '688325.SS', '688326.SS', '688327.SS', '688328.SS', '688329.SS', '688330.SS', '688331.SS', '688332.SS', '688333.SS', '688334.SS', '688335.SS', '688336.SS', '688337.SS', '688338.SS', '688339.SS', '688343.SS', '688345.SS', '688347.SS', '688348.SS', '688349.SS', '688350.SS', '688351.SS', '688352.SS', '688353.SS', '688355.SS', '688356.SS', '688357.SS', '688358.SS', '688359.SS', '688360.SS', '688361.SS', '688362.SS', '688363.SS', '688365.SS', '688366.SS', '688367.SS', '688368.SS', '688369.SS', '688370.SS', '688371.SS', '688372.SS', '688373.SS', '688375.SS', '688376.SS', '688377.SS', '688378.SS', '688379.SS', '688380.SS', '688381.SS', '688382.SS', '688383.SS', '688385.SS', '688386.SS', '688387.SS', '688388.SS', '688389.SS', '688390.SS', '688391.SS', '688392.SS', '688393.SS', '688395.SS', '688396.SS', '688398.SS', '688399.SS', '688400.SS', '688401.SS', '688403.SS', '688408.SS', '688409.SS', '688410.SS', '688411.SS', '688416.SS', '688418.SS', '688419.SS', '688420.SS', '688425.SS', '688426.SS', '688428.SS', '688429.SS', '688432.SS', '688433.SS', '688435.SS', '688439.SS', '688443.SS', '688448.SS', '688449.SS', '688450.SS', '688455.SS', '688456.SS', '688458.SS', '688459.SS', '688466.SS', '688468.SS', '688469.SS', '688472.SS', '688475.SS', '688478.SS', '688479.SS', '688480.SS', '688484.SS', '688485.SS', '688486.SS', '688488.SS', '688489.SS', '688496.SS', '688498.SS', '688499.SS', '688500.SS', '688501.SS', '688502.SS', '688503.SS', '688505.SS', '688506.SS', '688507.SS', '688508.SS', '688509.SS', '688510.SS', '688511.SS', '688512.SS', '688513.SS', '688515.SS', '688516.SS', '688517.SS', '688518.SS', '688519.SS', '688520.SS', '688521.SS', '688522.SS', '688523.SS', '688525.SS', '688526.SS', '688528.SS', '688529.SS', '688530.SS', '688531.SS', '688533.SS', '688535.SS', '688536.SS', '688538.SS', '688539.SS', '688543.SS', '688545.SS', '688548.SS', '688549.SS', '688550.SS', '688551.SS', '688552.SS', '688553.SS', '688556.SS', '688557.SS', '688558.SS', '688559.SS', '688560.SS', '688561.SS', '688562.SS', '688563.SS', '688565.SS', '688566.SS', '688567.SS', '688568.SS', '688569.SS', '688570.SS', '688571.SS', '688573.SS', '688575.SS', '688576.SS', '688577.SS', '688578.SS', '688579.SS', '688580.SS', '688581.SS', '688582.SS', '688583.SS', '688584.SS', '688585.SS', '688586.SS', '688588.SS', '688589.SS', '688590.SS', '688591.SS', '688592.SS', '688593.SS', '688595.SS', '688596.SS', '688597.SS', '688598.SS', '688599.SS', '688600.SS', '688601.SS', '688602.SS', '688603.SS', '688605.SS', '688606.SS', '688607.SS', '688608.SS', '688609.SS', '688610.SS', '688611.SS', '688612.SS', '688613.SS', '688615.SS', '688616.SS', '688617.SS', '688618.SS', '688619.SS', '688620.SS', '688621.SS', '688622.SS', '688623.SS', '688625.SS', '688626.SS', '688627.SS', '688628.SS', '688629.SS', '688630.SS', '688631.SS', '688633.SS', '688636.SS', '688638.SS', '688639.SS', '688646.SS', '688648.SS', '688651.SS', '688652.SS', '688653.SS', '688655.SS', '688656.SS', '688657.SS', '688658.SS', '688659.SS', '688660.SS', '688661.SS', '688662.SS', '688663.SS', '688665.SS', '688667.SS', '688668.SS', '688669.SS', '688670.SS', '688671.SS', '688676.SS', '688677.SS', '688678.SS', '688679.SS', '688680.SS', '688681.SS', '688682.SS', '688683.SS', '688685.SS', '688686.SS', '688687.SS', '688689.SS', '688690.SS', '688691.SS', '688692.SS', '688693.SS', '688695.SS', '688696.SS', '688697.SS', '688698.SS', '688699.SS', '688700.SS', '688701.SS', '688702.SS', '688707.SS', '688708.SS', '688709.SS', '688710.SS', '688711.SS', '688716.SS', '688717.SS', '688718.SS', '688719.SS', '688720.SS', '688721.SS', '688722.SS', '688726.SS', '688728.SS', '688733.SS', '688737.SS', '688739.SS', '688750.SS', '688758.SS', '688766.SS', '688767.SS', '688768.SS', '688772.SS', '688776.SS', '688777.SS', '688778.SS', '688779.SS', '688786.SS', '688787.SS', '688788.SS', '688789.SS', '688793.SS', '688798.SS', '688799.SS', '688800.SS', '688819.SS', '688981.SS', '689009.SS', '300001.SZ', '300002.SZ', '300003.SZ', '300004.SZ', '300005.SZ', '300006.SZ', '300007.SZ', '300008.SZ', '300009.SZ', '300010.SZ', '300011.SZ', '300012.SZ', '300013.SZ', '300014.SZ', '300015.SZ', '300016.SZ', '300017.SZ', '300018.SZ', '300019.SZ', '300020.SZ', '300021.SZ', '300022.SZ', '300024.SZ', '300025.SZ', '300026.SZ', '300027.SZ', '300029.SZ', '300030.SZ', '300031.SZ', '300032.SZ', '300033.SZ', '300034.SZ', '300035.SZ', '300036.SZ', '300037.SZ', '300039.SZ', '300040.SZ', '300041.SZ', '300042.SZ', '300043.SZ', '300044.SZ', '300045.SZ', '300046.SZ', '300047.SZ', '300048.SZ', '300049.SZ', '300050.SZ', '300051.SZ', '300052.SZ', '300053.SZ', '300054.SZ', '300055.SZ', '300056.SZ', '300057.SZ', '300058.SZ', '300059.SZ', '300061.SZ', '300062.SZ', '300063.SZ', '300065.SZ', '300066.SZ', '300067.SZ', '300068.SZ', '300069.SZ', '300070.SZ', '300071.SZ', '300072.SZ', '300073.SZ', '300074.SZ', '300075.SZ', '300076.SZ', '300077.SZ', '300078.SZ', '300079.SZ', '300080.SZ', '300081.SZ', '300082.SZ', '300083.SZ', '300084.SZ', '300085.SZ', '300086.SZ', '300087.SZ', '300088.SZ', '300091.SZ', '300092.SZ', '300093.SZ', '300094.SZ', '300095.SZ', '300096.SZ', '300097.SZ', '300098.SZ', '300099.SZ', '300100.SZ', '300101.SZ', '300102.SZ', '300103.SZ', '300105.SZ', '300106.SZ', '300107.SZ', '300108.SZ', '300109.SZ', '300110.SZ', '300111.SZ', '300112.SZ', '300113.SZ', '300115.SZ', '300117.SZ', '300118.SZ', '300119.SZ', '300120.SZ', '300121.SZ', '300122.SZ', '300123.SZ', '300124.SZ', '300125.SZ', '300126.SZ', '300127.SZ', '300128.SZ', '300129.SZ', '300130.SZ', '300131.SZ', '300132.SZ', '300133.SZ', '300134.SZ', '300135.SZ', '300136.SZ', '300137.SZ', '300138.SZ', '300139.SZ', '300140.SZ', '300141.SZ', '300142.SZ', '300143.SZ', '300144.SZ', '300145.SZ', '300146.SZ', '300147.SZ', '300148.SZ', '300149.SZ', '300150.SZ', '300151.SZ', '300152.SZ', '300153.SZ', '300154.SZ', '300155.SZ', '300157.SZ', '300158.SZ', '300159.SZ', '300160.SZ', '300161.SZ', '300162.SZ', '300163.SZ', '300164.SZ', '300165.SZ', '300166.SZ', '300167.SZ', '300168.SZ', '300169.SZ', '300170.SZ', '300171.SZ', '300172.SZ', '300173.SZ', '300174.SZ', '300175.SZ', '300176.SZ', '300177.SZ', '300179.SZ', '300180.SZ', '300181.SZ', '300182.SZ', '300183.SZ', '300184.SZ', '300185.SZ', '300187.SZ', '300188.SZ', '300189.SZ', '300190.SZ', '300191.SZ', '300192.SZ', '300193.SZ', '300194.SZ', '300195.SZ', '300196.SZ', '300197.SZ', '300198.SZ', '300199.SZ', '300200.SZ', '300201.SZ', '300203.SZ', '300204.SZ', '300205.SZ', '300206.SZ', '300207.SZ', '300208.SZ', '300209.SZ', '300210.SZ', '300211.SZ', '300212.SZ', '300213.SZ', '300214.SZ', '300215.SZ', '300217.SZ', '300218.SZ', '300219.SZ', '300220.SZ', '300221.SZ', '300222.SZ', '300223.SZ', '300224.SZ', '300225.SZ', '300226.SZ', '300227.SZ', '300228.SZ', '300229.SZ', '300230.SZ', '300231.SZ', '300232.SZ', '300233.SZ', '300234.SZ', '300235.SZ', '300236.SZ', '300237.SZ', '300238.SZ', '300239.SZ', '300240.SZ', '300241.SZ', '300242.SZ', '300243.SZ', '300244.SZ', '300245.SZ', '300246.SZ', '300247.SZ', '300248.SZ', '300249.SZ', '300250.SZ', '300251.SZ', '300252.SZ', '300253.SZ', '300254.SZ', '300255.SZ', '300256.SZ', '300257.SZ', '300258.SZ', '300259.SZ', '300260.SZ', '300261.SZ', '300263.SZ', '300264.SZ', '300265.SZ', '300266.SZ', '300267.SZ', '300268.SZ', '300269.SZ', '300270.SZ', '300271.SZ', '300272.SZ', '300274.SZ', '300275.SZ', '300276.SZ', '300277.SZ', '300278.SZ', '300279.SZ', '300280.SZ', '300281.SZ', '300283.SZ', '300284.SZ', '300285.SZ', '300286.SZ', '300287.SZ', '300288.SZ', '300289.SZ', '300290.SZ', '300291.SZ', '300292.SZ', '300293.SZ', '300294.SZ', '300295.SZ', '300296.SZ', '300298.SZ', '300299.SZ', '300300.SZ', '300301.SZ', '300302.SZ', '300303.SZ', '300304.SZ', '300305.SZ', '300306.SZ', '300307.SZ', '300308.SZ', '300310.SZ', '300311.SZ', '300313.SZ', '300314.SZ', '300315.SZ', '300316.SZ', '300317.SZ', '300318.SZ', '300319.SZ', '300320.SZ', '300321.SZ', '300322.SZ', '300323.SZ', '300324.SZ', '300326.SZ', '300327.SZ', '300328.SZ', '300329.SZ', '300331.SZ', '300332.SZ', '300333.SZ', '300334.SZ', '300335.SZ', '300337.SZ', '300338.SZ', '300339.SZ', '300340.SZ', '300341.SZ', '300342.SZ', '300343.SZ', '300344.SZ', '300345.SZ', '300346.SZ', '300347.SZ', '300348.SZ', '300349.SZ', '300350.SZ', '300351.SZ', '300352.SZ', '300353.SZ', '300354.SZ', '300355.SZ', '300357.SZ', '300358.SZ', '300359.SZ', '300360.SZ', '300363.SZ', '300364.SZ', '300365.SZ', '300366.SZ', '300368.SZ', '300369.SZ', '300370.SZ', '300371.SZ', '300373.SZ', '300374.SZ', '300375.SZ', '300376.SZ', '300377.SZ', '300378.SZ', '300379.SZ', '300380.SZ', '300381.SZ', '300382.SZ', '300383.SZ', '300384.SZ', '300385.SZ', '300386.SZ', '300387.SZ', '300388.SZ', '300389.SZ', '300390.SZ', '300391.SZ', '300393.SZ', '300394.SZ', '300395.SZ', '300396.SZ', '300397.SZ', '300398.SZ', '300399.SZ', '300400.SZ', '300401.SZ', '300402.SZ', '300403.SZ', '300404.SZ', '300405.SZ', '300406.SZ', '300407.SZ', '300408.SZ', '300409.SZ', '300410.SZ', '300411.SZ', '300412.SZ', '300413.SZ', '300414.SZ', '300415.SZ', '300416.SZ', '300417.SZ', '300418.SZ', '300419.SZ', '300420.SZ', '300421.SZ', '300422.SZ', '300423.SZ', '300424.SZ', '300425.SZ', '300426.SZ', '300427.SZ', '300428.SZ', '300429.SZ', '300430.SZ', '300432.SZ', '300433.SZ', '300434.SZ', '300435.SZ', '300436.SZ', '300437.SZ', '300438.SZ', '300439.SZ', '300440.SZ', '300441.SZ', '300442.SZ', '300443.SZ', '300444.SZ', '300445.SZ', '300446.SZ', '300447.SZ', '300448.SZ', '300449.SZ', '300450.SZ', '300451.SZ', '300452.SZ', '300453.SZ', '300454.SZ', '300455.SZ', '300456.SZ', '300457.SZ', '300458.SZ', '300459.SZ', '300460.SZ', '300461.SZ', '300462.SZ', '300463.SZ', '300464.SZ', '300465.SZ', '300466.SZ', '300467.SZ', '300468.SZ', '300469.SZ', '300470.SZ', '300471.SZ', '300472.SZ', '300473.SZ', '300474.SZ', '300475.SZ', '300476.SZ', '300477.SZ', '300478.SZ', '300479.SZ', '300480.SZ', '300481.SZ', '300482.SZ', '300483.SZ', '300484.SZ', '300485.SZ', '300486.SZ', '300487.SZ', '300488.SZ', '300489.SZ', '300490.SZ', '300491.SZ', '300492.SZ', '300493.SZ', '300494.SZ', '300496.SZ', '300497.SZ', '300498.SZ', '300499.SZ', '300500.SZ', '300501.SZ', '300502.SZ', '300503.SZ', '300504.SZ', '300505.SZ', '300506.SZ', '300507.SZ', '300508.SZ', '300509.SZ', '300510.SZ', '300511.SZ', '300512.SZ', '300513.SZ', '300514.SZ', '300515.SZ', '300516.SZ', '300517.SZ', '300518.SZ', '300519.SZ', '300520.SZ', '300521.SZ', '300522.SZ', '300523.SZ', '300525.SZ', '300527.SZ', '300528.SZ', '300529.SZ', '300530.SZ', '300531.SZ', '300532.SZ', '300533.SZ', '300534.SZ', '300535.SZ', '300536.SZ', '300537.SZ', '300538.SZ', '300539.SZ', '300540.SZ', '300541.SZ', '300542.SZ', '300543.SZ', '300545.SZ', '300546.SZ', '300547.SZ', '300548.SZ', '300549.SZ', '300550.SZ', '300551.SZ', '300552.SZ', '300553.SZ', '300554.SZ', '300555.SZ', '300556.SZ', '300557.SZ', '300558.SZ', '300559.SZ', '300560.SZ', '300561.SZ', '300562.SZ', '300563.SZ', '300564.SZ', '300565.SZ', '300566.SZ', '300567.SZ', '300568.SZ', '300569.SZ', '300570.SZ', '300571.SZ', '300572.SZ', '300573.SZ', '300575.SZ', '300576.SZ', '300577.SZ', '300578.SZ', '300579.SZ', '300580.SZ', '300581.SZ', '300582.SZ', '300583.SZ', '300584.SZ', '300585.SZ', '300586.SZ', '300587.SZ', '300588.SZ', '300589.SZ', '300590.SZ', '300591.SZ', '300592.SZ', '300593.SZ', '300594.SZ', '300595.SZ', '300596.SZ', '300597.SZ', '300598.SZ', '300599.SZ', '300600.SZ', '300601.SZ', '300602.SZ', '300603.SZ', '300604.SZ', '300605.SZ', '300606.SZ', '300607.SZ', '300608.SZ', '300609.SZ', '300610.SZ', '300611.SZ', '300612.SZ', '300613.SZ', '300614.SZ', '300615.SZ', '300616.SZ', '300617.SZ', '300618.SZ', '300619.SZ', '300620.SZ', '300621.SZ', '300622.SZ', '300623.SZ', '300624.SZ', '300625.SZ', '300626.SZ', '300627.SZ', '300628.SZ', '300629.SZ', '300630.SZ', '300631.SZ', '300632.SZ', '300633.SZ', '300634.SZ', '300635.SZ', '300636.SZ', '300637.SZ', '300638.SZ', '300639.SZ', '300640.SZ', '300641.SZ', '300642.SZ', '300643.SZ', '300644.SZ', '300645.SZ', '300647.SZ', '300648.SZ', '300649.SZ', '300650.SZ', '300651.SZ', '300652.SZ', '300653.SZ', '300654.SZ', '300655.SZ', '300656.SZ', '300657.SZ', '300658.SZ', '300659.SZ', '300660.SZ', '300661.SZ', '300662.SZ', '300663.SZ', '300664.SZ', '300665.SZ', '300666.SZ', '300667.SZ', '300668.SZ', '300669.SZ', '300670.SZ', '300671.SZ', '300672.SZ', '300673.SZ', '300674.SZ', '300675.SZ', '300676.SZ', '300677.SZ', '300678.SZ', '300679.SZ', '300680.SZ', '300681.SZ', '300682.SZ', '300683.SZ', '300684.SZ', '300685.SZ', '300686.SZ', '300687.SZ', '300688.SZ', '300689.SZ', '300690.SZ', '300691.SZ', '300692.SZ', '300693.SZ', '300694.SZ', '300695.SZ', '300696.SZ', '300697.SZ', '300698.SZ', '300699.SZ', '300700.SZ', '300701.SZ', '300702.SZ', '300703.SZ', '300705.SZ', '300706.SZ', '300707.SZ', '300708.SZ', '300709.SZ', '300710.SZ', '300711.SZ', '300712.SZ', '300713.SZ', '300715.SZ', '300716.SZ', '300717.SZ', '300718.SZ', '300719.SZ', '300720.SZ', '300721.SZ', '300722.SZ', '300723.SZ', '300724.SZ', '300725.SZ', '300726.SZ', '300727.SZ', '300729.SZ', '300730.SZ', '300731.SZ', '300732.SZ', '300733.SZ', '300735.SZ', '300736.SZ', '300737.SZ', '300738.SZ', '300739.SZ', '300740.SZ', '300741.SZ', '300743.SZ', '300745.SZ', '300746.SZ', '300747.SZ', '300748.SZ', '300749.SZ', '300750.SZ', '300751.SZ', '300752.SZ', '300753.SZ', '300755.SZ', '300756.SZ', '300757.SZ', '300758.SZ', '300759.SZ', '300760.SZ', '300761.SZ', '300762.SZ', '300763.SZ', '300765.SZ', '300766.SZ', '300767.SZ', '300768.SZ', '300769.SZ', '300770.SZ', '300771.SZ', '300772.SZ', '300773.SZ', '300774.SZ', '300775.SZ', '300776.SZ', '300777.SZ', '300778.SZ', '300779.SZ', '300780.SZ', '300781.SZ', '300782.SZ', '300783.SZ', '300784.SZ', '300785.SZ', '300786.SZ', '300787.SZ', '300788.SZ', '300789.SZ', '300790.SZ', '300791.SZ', '300792.SZ', '300793.SZ', '300795.SZ', '300796.SZ', '300797.SZ', '300798.SZ', '300800.SZ', '300801.SZ', '300802.SZ', '300803.SZ', '300804.SZ', '300805.SZ', '300806.SZ', '300807.SZ', '300808.SZ', '300809.SZ', '300810.SZ', '300811.SZ', '300812.SZ', '300813.SZ', '300814.SZ', '300815.SZ', '300816.SZ', '300817.SZ', '300818.SZ', '300819.SZ', '300820.SZ', '300821.SZ', '300822.SZ', '300823.SZ', '300824.SZ', '300825.SZ', '300826.SZ', '300827.SZ', '300828.SZ', '300829.SZ', '300830.SZ', '300831.SZ', '300832.SZ', '300833.SZ', '300834.SZ', '300835.SZ', '300836.SZ', '300837.SZ', '300838.SZ', '300839.SZ', '300840.SZ', '300841.SZ', '300842.SZ', '300843.SZ', '300844.SZ', '300845.SZ', '300846.SZ', '300847.SZ', '300848.SZ', '300849.SZ', '300850.SZ', '300851.SZ', '300852.SZ', '300853.SZ', '300854.SZ', '300855.SZ', '300856.SZ', '300857.SZ', '300858.SZ', '300859.SZ', '300860.SZ', '300861.SZ', '300862.SZ', '300863.SZ', '300864.SZ', '300865.SZ', '300866.SZ', '300867.SZ', '300868.SZ', '300869.SZ', '300870.SZ', '300871.SZ', '300872.SZ', '300873.SZ', '300875.SZ', '300876.SZ', '300877.SZ', '300878.SZ', '300879.SZ', '300880.SZ', '300881.SZ', '300882.SZ', '300883.SZ', '300884.SZ', '300885.SZ', '300886.SZ', '300887.SZ', '300888.SZ', '300889.SZ', '300890.SZ', '300891.SZ', '300892.SZ', '300893.SZ', '300894.SZ', '300895.SZ', '300896.SZ', '300897.SZ', '300898.SZ', '300899.SZ', '300900.SZ', '300901.SZ', '300902.SZ', '300903.SZ', '300904.SZ', '300905.SZ', '300906.SZ', '300907.SZ', '300908.SZ', '300909.SZ', '300910.SZ', '300911.SZ', '300912.SZ', '300913.SZ', '300915.SZ', '300916.SZ', '300917.SZ', '300918.SZ', '300919.SZ', '300920.SZ', '300921.SZ', '300922.SZ', '300923.SZ', '300925.SZ', '300926.SZ', '300927.SZ', '300928.SZ', '300929.SZ', '300930.SZ', '300931.SZ', '300932.SZ', '300933.SZ', '300935.SZ', '300936.SZ', '300937.SZ', '300938.SZ', '300939.SZ', '300940.SZ', '300941.SZ', '300942.SZ', '300943.SZ', '300945.SZ', '300946.SZ', '300947.SZ', '300948.SZ', '300949.SZ', '300950.SZ', '300951.SZ', '300952.SZ', '300953.SZ', '300955.SZ', '300956.SZ', '300957.SZ', '300958.SZ', '300959.SZ', '300960.SZ', '300961.SZ', '300962.SZ', '300963.SZ', '300964.SZ', '300965.SZ', '300966.SZ', '300967.SZ', '300968.SZ', '300969.SZ', '300970.SZ', '300971.SZ', '300972.SZ', '300973.SZ', '300975.SZ', '300976.SZ', '300977.SZ', '300978.SZ', '300979.SZ', '300980.SZ', '300981.SZ', '300982.SZ', '300983.SZ', '300984.SZ', '300985.SZ', '300986.SZ', '300987.SZ', '300988.SZ', '300989.SZ', '300990.SZ', '300991.SZ', '300992.SZ', '300993.SZ', '300994.SZ', '300995.SZ', '300996.SZ', '300997.SZ', '300998.SZ', '300999.SZ', '301000.SZ', '301001.SZ', '301002.SZ', '301003.SZ', '301004.SZ', '301005.SZ', '301006.SZ', '301007.SZ', '301008.SZ', '301009.SZ', '301010.SZ', '301011.SZ', '301012.SZ', '301013.SZ', '301015.SZ', '301016.SZ', '301017.SZ', '301018.SZ', '301019.SZ', '301020.SZ', '301021.SZ', '301022.SZ', '301023.SZ', '301024.SZ', '301025.SZ', '301026.SZ', '301027.SZ', '301028.SZ', '301029.SZ', '301030.SZ', '301031.SZ', '301032.SZ', '301033.SZ', '301035.SZ', '301036.SZ', '301037.SZ', '301038.SZ', '301039.SZ', '301040.SZ', '301041.SZ', '301042.SZ', '301043.SZ', '301045.SZ', '301046.SZ', '301047.SZ', '301048.SZ', '301049.SZ', '301050.SZ', '301051.SZ', '301052.SZ', '301053.SZ', '301055.SZ', '301056.SZ', '301057.SZ', '301058.SZ', '301059.SZ', '301060.SZ', '301061.SZ', '301062.SZ', '301063.SZ', '301065.SZ', '301066.SZ', '301067.SZ', '301068.SZ', '301069.SZ', '301070.SZ', '301071.SZ', '301072.SZ', '301073.SZ', '301075.SZ', '301076.SZ', '301077.SZ', '301078.SZ', '301079.SZ', '301080.SZ', '301081.SZ', '301082.SZ', '301083.SZ', '301085.SZ', '301086.SZ', '301087.SZ', '301088.SZ', '301089.SZ', '301090.SZ', '301091.SZ', '301092.SZ', '301093.SZ', '301095.SZ', '301096.SZ', '301097.SZ', '301098.SZ', '301099.SZ', '301100.SZ', '301101.SZ', '301102.SZ', '301103.SZ', '301105.SZ', '301106.SZ', '301107.SZ', '301108.SZ', '301109.SZ', '301110.SZ', '301111.SZ', '301112.SZ', '301113.SZ', '301115.SZ', '301116.SZ', '301117.SZ', '301118.SZ', '301119.SZ', '301120.SZ', '301121.SZ', '301122.SZ', '301123.SZ', '301125.SZ', '301126.SZ', '301127.SZ', '301128.SZ', '301129.SZ', '301130.SZ', '301131.SZ', '301132.SZ', '301133.SZ', '301135.SZ', '301136.SZ', '301137.SZ', '301138.SZ', '301139.SZ', '301141.SZ', '301148.SZ', '301149.SZ', '301150.SZ', '301151.SZ', '301152.SZ', '301153.SZ', '301155.SZ', '301156.SZ', '301157.SZ', '301158.SZ', '301159.SZ', '301160.SZ', '301161.SZ', '301162.SZ', '301163.SZ', '301165.SZ', '301166.SZ', '301167.SZ', '301168.SZ', '301169.SZ', '301170.SZ', '301171.SZ', '301172.SZ', '301173.SZ', '301175.SZ', '301176.SZ', '301177.SZ', '301178.SZ', '301179.SZ', '301180.SZ', '301181.SZ', '301182.SZ', '301183.SZ', '301185.SZ', '301186.SZ', '301187.SZ', '301188.SZ', '301189.SZ', '301190.SZ', '301191.SZ', '301192.SZ', '301193.SZ', '301195.SZ', '301196.SZ', '301197.SZ', '301198.SZ', '301199.SZ', '301200.SZ', '301201.SZ', '301202.SZ', '301203.SZ', '301205.SZ', '301206.SZ', '301207.SZ', '301208.SZ', '301209.SZ', '301210.SZ', '301211.SZ', '301212.SZ', '301213.SZ', '301215.SZ', '301216.SZ', '301217.SZ', '301218.SZ', '301219.SZ', '301220.SZ', '301221.SZ', '301222.SZ', '301223.SZ', '301225.SZ', '301226.SZ', '301227.SZ', '301228.SZ', '301229.SZ', '301230.SZ', '301231.SZ', '301232.SZ', '301233.SZ', '301234.SZ', '301235.SZ', '301236.SZ', '301237.SZ', '301238.SZ', '301239.SZ', '301246.SZ', '301248.SZ', '301251.SZ', '301252.SZ', '301255.SZ', '301256.SZ', '301257.SZ', '301258.SZ', '301259.SZ', '301260.SZ', '301261.SZ', '301262.SZ', '301263.SZ', '301265.SZ', '301266.SZ', '301267.SZ', '301268.SZ', '301269.SZ', '301270.SZ', '301272.SZ', '301273.SZ', '301275.SZ', '301276.SZ', '301277.SZ', '301278.SZ', '301279.SZ', '301280.SZ', '301281.SZ', '301282.SZ', '301283.SZ', '301285.SZ', '301286.SZ', '301287.SZ', '301288.SZ', '301289.SZ', '301290.SZ', '301291.SZ', '301292.SZ', '301293.SZ', '301295.SZ', '301296.SZ', '301297.SZ', '301298.SZ', '301299.SZ', '301300.SZ', '301301.SZ', '301302.SZ', '301303.SZ', '301305.SZ', '301306.SZ', '301307.SZ', '301308.SZ', '301309.SZ', '301310.SZ', '301311.SZ', '301312.SZ', '301313.SZ', '301314.SZ', '301315.SZ', '301316.SZ', '301317.SZ', '301318.SZ', '301319.SZ', '301320.SZ', '301321.SZ', '301322.SZ', '301323.SZ', '301325.SZ', '301326.SZ', '301327.SZ', '301328.SZ', '301329.SZ', '301330.SZ', '301331.SZ', '301332.SZ', '301333.SZ', '301335.SZ', '301336.SZ', '3013 查看全部
可以运行下面的代码:
def initialize(context):
# 初始化策略
g.security = "600570.SS"
set_universe(g.security)
run_daily(context, func,'20:13')
def handle_data(context, data):
print('公众号:可转债量化分析')
def func(context):
info = get_Ashares(date=None)
print(info)
它会打印沪深A股的代码:
北交所有83开头的,或者找一个北交所的股票代码,在输出里面找一下:
[code]2025-03-12 20:13:00 - INFO - ['600000.SS', '600004.SS', '600006.SS', '600007.SS', '600008.SS', '600009.SS', '600010.SS', '600011.SS', '600012.SS', '600015.SS', '600016.SS', '600017.SS', '600018.SS', '600019.SS', '600020.SS', '600021.SS', '600022.SS', '600023.SS', '600025.SS', '600026.SS', '600027.SS', '600028.SS', '600029.SS', '600030.SS', '600031.SS', '600032.SS', '600033.SS', '600035.SS', '600036.SS', '600037.SS', '600038.SS', '600039.SS', '600048.SS', '600050.SS', '600051.SS', '600052.SS', '600053.SS', '600054.SS', '600055.SS', '600056.SS', '600057.SS', '600058.SS', '600059.SS', '600060.SS', '600061.SS', '600062.SS', '600063.SS', '600064.SS', '600066.SS', '600067.SS', '600070.SS', '600071.SS', '600072.SS', '600073.SS', '600075.SS', '600076.SS', '600078.SS', '600079.SS', '600080.SS', '600081.SS', '600082.SS', '600084.SS', '600085.SS', '600088.SS', '600089.SS', '600094.SS', '600095.SS', '600096.SS', '600097.SS', '600098.SS', '600099.SS', '600100.SS', '600101.SS', '600103.SS', '600104.SS', '600105.SS', '600106.SS', '600107.SS', '600108.SS', '600109.SS', '600110.SS', '600111.SS', '600113.SS', '600114.SS', '600115.SS', '600116.SS', '600117.SS', '600118.SS', '600119.SS', '600120.SS', '600121.SS', '600123.SS', '600125.SS', '600126.SS', '600127.SS', '600128.SS', '600129.SS', '600130.SS', '600131.SS', '600132.SS', '600133.SS', '600135.SS', '600136.SS', '600137.SS', '600138.SS', '600141.SS', '600143.SS', '600148.SS', '600149.SS', '600150.SS', '600151.SS', '600152.SS', '600153.SS', '600155.SS', '600156.SS', '600157.SS', '600158.SS', '600159.SS', '600160.SS', '600161.SS', '600162.SS', '600163.SS', '600165.SS', '600166.SS', '600167.SS', '600168.SS', '600169.SS', '600170.SS', '600171.SS', '600172.SS', '600173.SS', '600176.SS', '600177.SS', '600178.SS', '600179.SS', '600180.SS', '600182.SS', '600183.SS', '600184.SS', '600185.SS', '600186.SS', '600187.SS', '600188.SS', '600189.SS', '600190.SS', '600191.SS', '600192.SS', '600193.SS', '600195.SS', '600196.SS', '600197.SS', '600198.SS', '600199.SS', '600200.SS', '600201.SS', '600202.SS', '600203.SS', '600206.SS', '600207.SS', '600208.SS', '600210.SS', '600211.SS', '600212.SS', '600215.SS', '600216.SS', '600217.SS', '600218.SS', '600219.SS', '600221.SS', '600222.SS', '600223.SS', '600226.SS', '600227.SS', '600228.SS', '600229.SS', '600230.SS', '600231.SS', '600232.SS', '600233.SS', '600234.SS', '600235.SS', '600236.SS', '600237.SS', '600238.SS', '600239.SS', '600241.SS', '600243.SS', '600246.SS', '600248.SS', '600249.SS', '600250.SS', '600251.SS', '600252.SS', '600255.SS', '600256.SS', '600257.SS', '600258.SS', '600259.SS', '600261.SS', '600262.SS', '600265.SS', '600266.SS', '600267.SS', '600268.SS', '600269.SS', '600271.SS', '600272.SS', '600273.SS', '600276.SS', '600278.SS', '600279.SS', '600280.SS', '600281.SS', '600282.SS', '600283.SS', '600284.SS', '600285.SS', '600287.SS', '600288.SS', '600289.SS', '600292.SS', '600293.SS', '600295.SS', '600298.SS', '600299.SS', '600300.SS', '600301.SS', '600302.SS', '600303.SS', '600305.SS', '600307.SS', '600308.SS', '600309.SS', '600310.SS', '600312.SS', '600313.SS', '600315.SS', '600316.SS', '600318.SS', '600319.SS', '600320.SS', '600322.SS', '600323.SS', '600325.SS', '600326.SS', '600327.SS', '600328.SS', '600329.SS', '600330.SS', '600331.SS', '600332.SS', '600333.SS', '600335.SS', '600336.SS', '600337.SS', '600338.SS', '600339.SS', '600340.SS', '600343.SS', '600345.SS', '600346.SS', '600348.SS', '600350.SS', '600351.SS', '600352.SS', '600353.SS', '600354.SS', '600355.SS', '600356.SS', '600358.SS', '600359.SS', '600360.SS', '600361.SS', '600362.SS', '600363.SS', '600365.SS', '600366.SS', '600367.SS', '600368.SS', '600369.SS', '600370.SS', '600371.SS', '600372.SS', '600373.SS', '600375.SS', '600376.SS', '600377.SS', '600378.SS', '600379.SS', '600380.SS', '600381.SS', '600382.SS', '600383.SS', '600386.SS', '600387.SS', '600388.SS', '600389.SS', '600390.SS', '600391.SS', '600392.SS', '600395.SS', '600396.SS', '600397.SS', '600398.SS', '600399.SS', '600400.SS', '600403.SS', '600405.SS', '600406.SS', '600408.SS', '600409.SS', '600410.SS', '600415.SS', '600416.SS', '600418.SS', '600419.SS', '600420.SS', '600421.SS', '600422.SS', '600423.SS', '600425.SS', '600426.SS', '600428.SS', '600429.SS', '600433.SS', '600435.SS', '600436.SS', '600438.SS', '600439.SS', '600444.SS', '600446.SS', '600448.SS', '600449.SS', '600452.SS', '600455.SS', '600456.SS', '600458.SS', '600459.SS', '600460.SS', '600461.SS', '600462.SS', '600463.SS', '600467.SS', '600468.SS', '600469.SS', '600470.SS', '600475.SS', '600476.SS', '600477.SS', '600478.SS', '600479.SS', '600480.SS', '600481.SS', '600482.SS', '600483.SS', '600486.SS', '600487.SS', '600488.SS', '600489.SS', '600490.SS', '600491.SS', '600493.SS', '600495.SS', '600496.SS', '600497.SS', '600498.SS', '600499.SS', '600500.SS', '600501.SS', '600502.SS', '600503.SS', '600505.SS', '600506.SS', '600507.SS', '600508.SS', '600509.SS', '600510.SS', '600511.SS', '600512.SS', '600513.SS', '600515.SS', '600516.SS', '600517.SS', '600518.SS', '600519.SS', '600520.SS', '600521.SS', '600522.SS', '600523.SS', '600525.SS', '600526.SS', '600527.SS', '600528.SS', '600529.SS', '600530.SS', '600531.SS', '600533.SS', '600535.SS', '600536.SS', '600537.SS', '600538.SS', '600539.SS', '600540.SS', '600543.SS', '600545.SS', '600546.SS', '600547.SS', '600548.SS', '600549.SS', '600550.SS', '600551.SS', '600552.SS', '600556.SS', '600557.SS', '600558.SS', '600559.SS', '600560.SS', '600561.SS', '600562.SS', '600563.SS', '600566.SS', '600567.SS', '600568.SS', '600569.SS', '600570.SS', '600571.SS', '600572.SS', '600573.SS', '600575.SS', '600576.SS', '600577.SS', '600578.SS', '600579.SS', '600580.SS', '600581.SS', '600582.SS', '600583.SS', '600584.SS', '600585.SS', '600586.SS', '600587.SS', '600588.SS', '600589.SS', '600590.SS', '600592.SS', '600593.SS', '600594.SS', '600595.SS', '600596.SS', '600597.SS', '600598.SS', '600599.SS', '600600.SS', '600601.SS', '600602.SS', '600603.SS', '600604.SS', '600605.SS', '600606.SS', '600608.SS', '600609.SS', '600610.SS', '600611.SS', '600612.SS', '600613.SS', '600615.SS', '600616.SS', '600617.SS', '600618.SS', '600619.SS', '600620.SS', '600621.SS', '600622.SS', '600623.SS', '600624.SS', '600626.SS', '600628.SS', '600629.SS', '600630.SS', '600633.SS', '600635.SS', '600636.SS', '600637.SS', '600638.SS', '600639.SS', '600640.SS', '600641.SS', '600642.SS', '600643.SS', '600644.SS', '600645.SS', '600648.SS', '600649.SS', '600650.SS', '600651.SS', '600653.SS', '600654.SS', '600655.SS', '600657.SS', '600658.SS', '600660.SS', '600661.SS', '600662.SS', '600663.SS', '600664.SS', '600665.SS', '600666.SS', '600667.SS', '600668.SS', '600671.SS', '600673.SS', '600674.SS', '600675.SS', '600676.SS', '600678.SS', '600679.SS', '600681.SS', '600682.SS', '600683.SS', '600684.SS', '600685.SS', '600686.SS', '600688.SS', '600689.SS', '600690.SS', '600691.SS', '600692.SS', '600693.SS', '600694.SS', '600696.SS', '600697.SS', '600698.SS', '600699.SS', '600702.SS', '600703.SS', '600704.SS', '600705.SS', '600706.SS', '600707.SS', '600708.SS', '600710.SS', '600711.SS', '600712.SS', '600713.SS', '600714.SS', '600715.SS', '600716.SS', '600717.SS', '600718.SS', '600719.SS', '600720.SS', '600721.SS', '600722.SS', '600724.SS', '600725.SS', '600726.SS', '600727.SS', '600728.SS', '600729.SS', '600730.SS', '600731.SS', '600732.SS', '600733.SS', '600734.SS', '600735.SS', '600736.SS', '600737.SS', '600738.SS', '600739.SS', '600740.SS', '600741.SS', '600742.SS', '600743.SS', '600744.SS', '600745.SS', '600746.SS', '600748.SS', '600749.SS', '600750.SS', '600751.SS', '600753.SS', '600754.SS', '600755.SS', '600756.SS', '600757.SS', '600758.SS', '600759.SS', '600760.SS', '600761.SS', '600763.SS', '600764.SS', '600765.SS', '600768.SS', '600769.SS', '600770.SS', '600771.SS', '600773.SS', '600774.SS', '600775.SS', '600776.SS', '600777.SS', '600778.SS', '600779.SS', '600780.SS', '600782.SS', '600783.SS', '600784.SS', '600785.SS', '600787.SS', '600789.SS', '600790.SS', '600791.SS', '600792.SS', '600793.SS', '600794.SS', '600795.SS', '600796.SS', '600797.SS', '600798.SS', '600800.SS', '600801.SS', '600802.SS', '600803.SS', '600804.SS', '600805.SS', '600807.SS', '600808.SS', '600809.SS', '600810.SS', '600811.SS', '600812.SS', '600814.SS', '600815.SS', '600816.SS', '600817.SS', '600818.SS', '600819.SS', '600820.SS', '600821.SS', '600822.SS', '600824.SS', '600825.SS', '600826.SS', '600827.SS', '600828.SS', '600829.SS', '600830.SS', '600831.SS', '600833.SS', '600834.SS', '600835.SS', '600838.SS', '600839.SS', '600841.SS', '600843.SS', '600844.SS', '600845.SS', '600846.SS', '600847.SS', '600848.SS', '600850.SS', '600851.SS', '600853.SS', '600854.SS', '600855.SS', '600857.SS', '600858.SS', '600859.SS', '600860.SS', '600861.SS', '600862.SS', '600863.SS', '600864.SS', '600865.SS', '600866.SS', '600867.SS', '600868.SS', '600869.SS', '600871.SS', '600872.SS', '600873.SS', '600874.SS', '600875.SS', '600876.SS', '600877.SS', '600879.SS', '600880.SS', '600881.SS', '600882.SS', '600883.SS', '600884.SS', '600885.SS', '600886.SS', '600887.SS', '600888.SS', '600889.SS', '600892.SS', '600893.SS', '600894.SS', '600895.SS', '600897.SS', '600900.SS', '600901.SS', '600903.SS', '600905.SS', '600906.SS', '600908.SS', '600909.SS', '600916.SS', '600917.SS', '600918.SS', '600919.SS', '600925.SS', '600926.SS', '600927.SS', '600928.SS', '600929.SS', '600933.SS', '600935.SS', '600936.SS', '600938.SS', '600939.SS', '600941.SS', '600955.SS', '600956.SS', '600958.SS', '600959.SS', '600960.SS', '600961.SS', '600962.SS', '600963.SS', '600965.SS', '600966.SS', '600967.SS', '600968.SS', '600969.SS', '600970.SS', '600971.SS', '600973.SS', '600975.SS', '600976.SS', '600977.SS', '600979.SS', '600980.SS', '600981.SS', '600982.SS', '600983.SS', '600984.SS', '600985.SS', '600986.SS', '600987.SS', '600988.SS', '600989.SS', '600990.SS', '600992.SS', '600993.SS', '600995.SS', '600996.SS', '600997.SS', '600998.SS', '600999.SS', '601000.SS', '601001.SS', '601002.SS', '601003.SS', '601005.SS', '601006.SS', '601007.SS', '601008.SS', '601009.SS', '601010.SS', '601011.SS', '601012.SS', '601015.SS', '601016.SS', '601018.SS', '601019.SS', '601020.SS', '601021.SS', '601022.SS', '601028.SS', '601033.SS', '601038.SS', '601058.SS', '601059.SS', '601061.SS', '601065.SS', '601066.SS', '601068.SS', '601069.SS', '601077.SS', '601083.SS', '601086.SS', '601088.SS', '601089.SS', '601096.SS', '601098.SS', '601099.SS', '601100.SS', '601101.SS', '601106.SS', '601107.SS', '601108.SS', '601111.SS', '601113.SS', '601116.SS', '601117.SS', '601118.SS', '601121.SS', '601126.SS', '601127.SS', '601128.SS', '601133.SS', '601136.SS', '601137.SS', '601138.SS', '601139.SS', '601155.SS', '601156.SS', '601158.SS', '601162.SS', '601163.SS', '601166.SS', '601168.SS', '601169.SS', '601177.SS', '601179.SS', '601186.SS', '601187.SS', '601188.SS', '601198.SS', '601199.SS', '601200.SS', '601208.SS', '601211.SS', '601212.SS', '601216.SS', '601218.SS', '601222.SS', '601225.SS', '601226.SS', '601228.SS', '601229.SS', '601231.SS', '601233.SS', '601236.SS', '601238.SS', '601279.SS', '601288.SS', '601298.SS', '601311.SS', '601318.SS', '601319.SS', '601326.SS', '601328.SS', '601330.SS', '601333.SS', '601336.SS', '601339.SS', '601360.SS', '601366.SS', '601368.SS', '601369.SS', '601375.SS', '601377.SS', '601388.SS', '601390.SS', '601398.SS', '601399.SS', '601456.SS', '601500.SS', '601512.SS', '601515.SS', '601518.SS', '601519.SS', '601528.SS', '601555.SS', '601566.SS', '601567.SS', '601568.SS', '601577.SS', '601579.SS', '601588.SS', '601595.SS', '601598.SS', '601599.SS', '601600.SS', '601601.SS', '601606.SS', '601607.SS', '601608.SS', '601609.SS', '601611.SS', '601615.SS', '601616.SS', '601618.SS', '601619.SS', '601628.SS', '601633.SS', '601636.SS', '601658.SS', '601665.SS', '601666.SS', '601668.SS', '601669.SS', '601677.SS', '601678.SS', '601686.SS', '601688.SS', '601689.SS', '601696.SS', '601698.SS', '601699.SS', '601700.SS', '601702.SS', '601717.SS', '601718.SS', '601727.SS', '601728.SS', '601766.SS', '601777.SS', '601778.SS', '601788.SS', '601789.SS', '601798.SS', '601799.SS', '601800.SS', '601801.SS', '601808.SS', '601811.SS', '601816.SS', '601818.SS', '601825.SS', '601827.SS', '601828.SS', '601838.SS', '601857.SS', '601858.SS', '601860.SS', '601865.SS', '601866.SS', '601868.SS', '601869.SS', '601872.SS', '601877.SS', '601878.SS', '601880.SS', '601881.SS', '601882.SS', '601886.SS', '601888.SS', '601890.SS', '601898.SS', '601899.SS', '601900.SS', '601901.SS', '601908.SS', '601916.SS', '601918.SS', '601919.SS', '601921.SS', '601928.SS', '601929.SS', '601933.SS', '601939.SS', '601949.SS', '601952.SS', '601956.SS', '601958.SS', '601963.SS', '601965.SS', '601966.SS', '601968.SS', '601969.SS', '601975.SS', '601985.SS', '601988.SS', '601989.SS', '601990.SS', '601991.SS', '601992.SS', '601995.SS', '601996.SS', '601997.SS', '601998.SS', '601999.SS', '603000.SS', '603001.SS', '603002.SS', '603003.SS', '603004.SS', '603005.SS', '603006.SS', '603007.SS', '603008.SS', '603009.SS', '603010.SS', '603011.SS', '603012.SS', '603013.SS', '603015.SS', '603016.SS', '603017.SS', '603018.SS', '603019.SS', '603020.SS', '603021.SS', '603022.SS', '603023.SS', '603025.SS', '603026.SS', '603027.SS', '603028.SS', '603029.SS', '603030.SS', '603031.SS', '603032.SS', '603033.SS', '603035.SS', '603036.SS', '603037.SS', '603038.SS', '603039.SS', '603040.SS', '603041.SS', '603042.SS', '603043.SS', '603045.SS', '603048.SS', '603050.SS', '603051.SS', '603052.SS', '603053.SS', '603055.SS', '603056.SS', '603057.SS', '603058.SS', '603059.SS', '603060.SS', '603061.SS', '603062.SS', '603063.SS', '603065.SS', '603066.SS', '603067.SS', '603068.SS', '603069.SS', '603070.SS', '603071.SS', '603072.SS', '603073.SS', '603075.SS', '603076.SS', '603077.SS', '603078.SS', '603079.SS', '603080.SS', '603081.SS', '603082.SS', '603083.SS', '603085.SS', '603086.SS', '603087.SS', '603088.SS', '603089.SS', '603090.SS', '603091.SS', '603093.SS', '603095.SS', '603096.SS', '603097.SS', '603098.SS', '603099.SS', '603100.SS', '603101.SS', '603102.SS', '603103.SS', '603105.SS', '603106.SS', '603107.SS', '603108.SS', '603109.SS', '603110.SS', '603111.SS', '603112.SS', '603113.SS', '603115.SS', '603116.SS', '603117.SS', '603118.SS', '603119.SS', '603121.SS', '603122.SS', '603123.SS', '603125.SS', '603126.SS', '603127.SS', '603128.SS', '603129.SS', '603130.SS', '603131.SS', '603132.SS', '603135.SS', '603136.SS', '603137.SS', '603138.SS', '603139.SS', '603150.SS', '603151.SS', '603153.SS', '603155.SS', '603156.SS', '603158.SS', '603159.SS', '603160.SS', '603161.SS', '603162.SS', '603163.SS', '603165.SS', '603166.SS', '603167.SS', '603168.SS', '603169.SS', '603170.SS', '603171.SS', '603172.SS', '603173.SS', '603176.SS', '603177.SS', '603178.SS', '603179.SS', '603180.SS', '603181.SS', '603182.SS', '603183.SS', '603185.SS', '603186.SS', '603187.SS', '603188.SS', '603189.SS', '603190.SS', '603191.SS', '603192.SS', '603193.SS', '603194.SS', '603195.SS', '603196.SS', '603197.SS', '603198.SS', '603199.SS', '603200.SS', '603201.SS', '603203.SS', '603205.SS', '603206.SS', '603207.SS', '603208.SS', '603209.SS', '603211.SS', '603212.SS', '603213.SS', '603214.SS', '603215.SS', '603216.SS', '603217.SS', '603218.SS', '603219.SS', '603220.SS', '603221.SS', '603222.SS', '603223.SS', '603225.SS', '603226.SS', '603227.SS', '603228.SS', '603229.SS', '603230.SS', '603231.SS', '603232.SS', '603233.SS', '603235.SS', '603236.SS', '603237.SS', '603238.SS', '603239.SS', '603255.SS', '603256.SS', '603258.SS', '603259.SS', '603260.SS', '603261.SS', '603266.SS', '603267.SS', '603268.SS', '603269.SS', '603270.SS', '603271.SS', '603272.SS', '603273.SS', '603275.SS', '603276.SS', '603277.SS', '603278.SS', '603279.SS', '603280.SS', '603281.SS', '603282.SS', '603283.SS', '603285.SS', '603286.SS', '603288.SS', '603289.SS', '603290.SS', '603291.SS', '603296.SS', '603297.SS', '603298.SS', '603299.SS', '603300.SS', '603301.SS', '603303.SS', '603305.SS', '603306.SS', '603307.SS', '603308.SS', '603309.SS', '603310.SS', '603311.SS', '603312.SS', '603313.SS', '603315.SS', '603316.SS', '603317.SS', '603318.SS', '603319.SS', '603320.SS', '603321.SS', '603322.SS', '603323.SS', '603324.SS', '603325.SS', '603326.SS', '603327.SS', '603328.SS', '603329.SS', '603330.SS', '603331.SS', '603332.SS', '603333.SS', '603335.SS', '603336.SS', '603337.SS', '603338.SS', '603339.SS', '603341.SS', '603344.SS', '603345.SS', '603348.SS', '603350.SS', '603351.SS', '603353.SS', '603355.SS', '603356.SS', '603357.SS', '603358.SS', '603359.SS', '603360.SS', '603363.SS', '603365.SS', '603366.SS', '603367.SS', '603368.SS', '603369.SS', '603373.SS', '603375.SS', '603377.SS', '603378.SS', '603379.SS', '603380.SS', '603381.SS', '603383.SS', '603385.SS', '603386.SS', '603387.SS', '603388.SS', '603389.SS', '603390.SS', '603391.SS', '603392.SS', '603393.SS', '603395.SS', '603396.SS', '603398.SS', '603399.SS', '603408.SS', '603409.SS', '603416.SS', '603421.SS', '603429.SS', '603439.SS', '603444.SS', '603456.SS', '603458.SS', '603466.SS', '603477.SS', '603486.SS', '603488.SS', '603489.SS', '603496.SS', '603499.SS', '603500.SS', '603501.SS', '603505.SS', '603506.SS', '603507.SS', '603508.SS', '603511.SS', '603515.SS', '603516.SS', '603517.SS', '603518.SS', '603519.SS', '603520.SS', '603527.SS', '603528.SS', '603529.SS', '603530.SS', '603533.SS', '603535.SS', '603536.SS', '603538.SS', '603551.SS', '603556.SS', '603557.SS', '603558.SS', '603559.SS', '603565.SS', '603566.SS', '603567.SS', '603568.SS', '603569.SS', '603577.SS', '603578.SS', '603579.SS', '603580.SS', '603583.SS', '603585.SS', '603586.SS', '603587.SS', '603588.SS', '603589.SS', '603590.SS', '603595.SS', '603596.SS', '603598.SS', '603599.SS', '603600.SS', '603601.SS', '603602.SS', '603605.SS', '603606.SS', '603607.SS', '603608.SS', '603609.SS', '603610.SS', '603611.SS', '603612.SS', '603613.SS', '603615.SS', '603616.SS', '603617.SS', '603618.SS', '603619.SS', '603626.SS', '603628.SS', '603629.SS', '603630.SS', '603633.SS', '603636.SS', '603637.SS', '603638.SS', '603639.SS', '603648.SS', '603650.SS', '603655.SS', '603656.SS', '603657.SS', '603658.SS', '603659.SS', '603660.SS', '603661.SS', '603662.SS', '603663.SS', '603665.SS', '603666.SS', '603667.SS', '603668.SS', '603669.SS', '603676.SS', '603677.SS', '603678.SS', '603679.SS', '603680.SS', '603681.SS', '603682.SS', '603683.SS', '603685.SS', '603686.SS', '603687.SS', '603688.SS', '603689.SS', '603690.SS', '603693.SS', '603696.SS', '603697.SS', '603698.SS', '603699.SS', '603700.SS', '603701.SS', '603703.SS', '603706.SS', '603707.SS', '603708.SS', '603709.SS', '603711.SS', '603712.SS', '603713.SS', '603716.SS', '603717.SS', '603718.SS', '603719.SS', '603721.SS', '603722.SS', '603725.SS', '603726.SS', '603727.SS', '603728.SS', '603729.SS', '603730.SS', '603733.SS', '603737.SS', '603738.SS', '603739.SS', '603755.SS', '603757.SS', '603758.SS', '603759.SS', '603766.SS', '603767.SS', '603768.SS', '603773.SS', '603776.SS', '603777.SS', '603778.SS', '603779.SS', '603786.SS', '603787.SS', '603788.SS', '603789.SS', '603790.SS', '603797.SS', '603798.SS', '603799.SS', '603800.SS', '603801.SS', '603803.SS', '603806.SS', '603808.SS', '603809.SS', '603810.SS', '603811.SS', '603813.SS', '603815.SS', '603816.SS', '603817.SS', '603818.SS', '603819.SS', '603822.SS', '603823.SS', '603825.SS', '603826.SS', '603828.SS', '603829.SS', '603833.SS', '603836.SS', '603838.SS', '603839.SS', '603843.SS', '603848.SS', '603855.SS', '603856.SS', '603858.SS', '603859.SS', '603860.SS', '603861.SS', '603863.SS', '603866.SS', '603867.SS', '603868.SS', '603869.SS', '603871.SS', '603876.SS', '603877.SS', '603878.SS', '603879.SS', '603880.SS', '603881.SS', '603882.SS', '603883.SS', '603885.SS', '603886.SS', '603887.SS', '603888.SS', '603889.SS', '603890.SS', '603893.SS', '603895.SS', '603896.SS', '603897.SS', '603898.SS', '603899.SS', '603900.SS', '603901.SS', '603903.SS', '603906.SS', '603908.SS', '603909.SS', '603912.SS', '603915.SS', '603916.SS', '603917.SS', '603918.SS', '603919.SS', '603920.SS', '603922.SS', '603926.SS', '603927.SS', '603928.SS', '603929.SS', '603931.SS', '603933.SS', '603936.SS', '603937.SS', '603938.SS', '603939.SS', '603948.SS', '603949.SS', '603950.SS', '603955.SS', '603956.SS', '603958.SS', '603959.SS', '603960.SS', '603963.SS', '603966.SS', '603967.SS', '603968.SS', '603969.SS', '603970.SS', '603976.SS', '603977.SS', '603978.SS', '603979.SS', '603980.SS', '603982.SS', '603983.SS', '603985.SS', '603986.SS', '603987.SS', '603988.SS', '603989.SS', '603990.SS', '603991.SS', '603992.SS', '603993.SS', '603995.SS', '603997.SS', '603998.SS', '603999.SS', '605001.SS', '605003.SS', '605005.SS', '605006.SS', '605007.SS', '605008.SS', '605009.SS', '605011.SS', '605016.SS', '605018.SS', '605020.SS', '605028.SS', '605033.SS', '605050.SS', '605055.SS', '605056.SS', '605058.SS', '605060.SS', '605066.SS', '605068.SS', '605069.SS', '605077.SS', '605080.SS', '605081.SS', '605086.SS', '605088.SS', '605089.SS', '605090.SS', '605098.SS', '605099.SS', '605100.SS', '605108.SS', '605111.SS', '605116.SS', '605117.SS', '605118.SS', '605122.SS', '605123.SS', '605128.SS', '605133.SS', '605136.SS', '605138.SS', '605151.SS', '605155.SS', '605158.SS', '605162.SS', '605166.SS', '605167.SS', '605168.SS', '605169.SS', '605177.SS', '605178.SS', '605179.SS', '605180.SS', '605183.SS', '605186.SS', '605188.SS', '605189.SS', '605196.SS', '605198.SS', '605199.SS', '605208.SS', '605218.SS', '605222.SS', '605228.SS', '605255.SS', '605258.SS', '605259.SS', '605266.SS', '605268.SS', '605277.SS', '605286.SS', '605287.SS', '605288.SS', '605289.SS', '605296.SS', '605298.SS', '605299.SS', '605300.SS', '605303.SS', '605305.SS', '605318.SS', '605319.SS', '605333.SS', '605336.SS', '605337.SS', '605338.SS', '605339.SS', '605358.SS', '605365.SS', '605366.SS', '605368.SS', '605369.SS', '605376.SS', '605377.SS', '605378.SS', '605388.SS', '605389.SS', '605398.SS', '605399.SS', '605488.SS', '605499.SS', '605500.SS', '605507.SS', '605555.SS', '605566.SS', '605567.SS', '605577.SS', '605580.SS', '605588.SS', '605589.SS', '605598.SS', '605599.SS', '000001.SZ', '000002.SZ', '000004.SZ', '000006.SZ', '000007.SZ', '000008.SZ', '000009.SZ', '000010.SZ', '000011.SZ', '000012.SZ', '000014.SZ', '000016.SZ', '000017.SZ', '000019.SZ', '000020.SZ', '000021.SZ', '000025.SZ', '000026.SZ', '000027.SZ', '000028.SZ', '000029.SZ', '000030.SZ', '000031.SZ', '000032.SZ', '000034.SZ', '000035.SZ', '000036.SZ', '000037.SZ', '000039.SZ', '000040.SZ', '000042.SZ', '000045.SZ', '000048.SZ', '000049.SZ', '000050.SZ', '000055.SZ', '000056.SZ', '000058.SZ', '000059.SZ', '000060.SZ', '000061.SZ', '000062.SZ', '000063.SZ', '000065.SZ', '000066.SZ', '000068.SZ', '000069.SZ', '000070.SZ', '000078.SZ', '000088.SZ', '000089.SZ', '000090.SZ', '000096.SZ', '000099.SZ', '000100.SZ', '000151.SZ', '000153.SZ', '000155.SZ', '000156.SZ', '000157.SZ', '000158.SZ', '000159.SZ', '000166.SZ', '000301.SZ', '000333.SZ', '000338.SZ', '000400.SZ', '000401.SZ', '000402.SZ', '000403.SZ', '000404.SZ', '000407.SZ', '000408.SZ', '000409.SZ', '000410.SZ', '000411.SZ', '000415.SZ', '000417.SZ', '000419.SZ', '000420.SZ', '000421.SZ', '000422.SZ', '000423.SZ', '000425.SZ', '000426.SZ', '000428.SZ', '000429.SZ', '000430.SZ', '000488.SZ', '000498.SZ', '000501.SZ', '000503.SZ', '000504.SZ', '000505.SZ', '000506.SZ', '000507.SZ', '000509.SZ', '000510.SZ', '000513.SZ', '000514.SZ', '000516.SZ', '000517.SZ', '000518.SZ', '000519.SZ', '000520.SZ', '000521.SZ', '000523.SZ', '000524.SZ', '000525.SZ', '000526.SZ', '000528.SZ', '000529.SZ', '000530.SZ', '000531.SZ', '000532.SZ', '000533.SZ', '000534.SZ', '000536.SZ', '000537.SZ', '000538.SZ', '000539.SZ', '000541.SZ', '000543.SZ', '000544.SZ', '000545.SZ', '000546.SZ', '000547.SZ', '000548.SZ', '000550.SZ', '000551.SZ', '000552.SZ', '000553.SZ', '000554.SZ', '000555.SZ', '000557.SZ', '000558.SZ', '000559.SZ', '000560.SZ', '000561.SZ', '000563.SZ', '000564.SZ', '000565.SZ', '000566.SZ', '000567.SZ', '000568.SZ', '000570.SZ', '000571.SZ', '000572.SZ', '000573.SZ', '000576.SZ', '000581.SZ', '000582.SZ', '000584.SZ', '000586.SZ', '000589.SZ', '000590.SZ', '000591.SZ', '000592.SZ', '000593.SZ', '000595.SZ', '000596.SZ', '000597.SZ', '000598.SZ', '000599.SZ', '000600.SZ', '000601.SZ', '000603.SZ', '000605.SZ', '000607.SZ', '000608.SZ', '000609.SZ', '000610.SZ', '000612.SZ', '000615.SZ', '000617.SZ', '000619.SZ', '000620.SZ', '000622.SZ', '000623.SZ', '000625.SZ', '000626.SZ', '000627.SZ', '000628.SZ', '000629.SZ', '000630.SZ', '000631.SZ', '000632.SZ', '000633.SZ', '000635.SZ', '000636.SZ', '000637.SZ', '000638.SZ', '000639.SZ', '000650.SZ', '000651.SZ', '000652.SZ', '000655.SZ', '000656.SZ', '000657.SZ', '000659.SZ', '000661.SZ', '000663.SZ', '000665.SZ', '000668.SZ', '000669.SZ', '000670.SZ', '000672.SZ', '000676.SZ', '000677.SZ', '000678.SZ', '000679.SZ', '000680.SZ', '000681.SZ', '000682.SZ', '000683.SZ', '000685.SZ', '000686.SZ', '000688.SZ', '000690.SZ', '000691.SZ', '000692.SZ', '000695.SZ', '000697.SZ', '000698.SZ', '000700.SZ', '000701.SZ', '000702.SZ', '000703.SZ', '000705.SZ', '000707.SZ', '000708.SZ', '000709.SZ', '000710.SZ', '000711.SZ', '000712.SZ', '000713.SZ', '000715.SZ', '000716.SZ', '000717.SZ', '000718.SZ', '000719.SZ', '000720.SZ', '000721.SZ', '000722.SZ', '000723.SZ', '000725.SZ', '000726.SZ', '000727.SZ', '000728.SZ', '000729.SZ', '000731.SZ', '000733.SZ', '000735.SZ', '000736.SZ', '000737.SZ', '000738.SZ', '000739.SZ', '000750.SZ', '000751.SZ', '000752.SZ', '000753.SZ', '000755.SZ', '000756.SZ', '000757.SZ', '000758.SZ', '000759.SZ', '000761.SZ', '000762.SZ', '000766.SZ', '000767.SZ', '000768.SZ', '000776.SZ', '000777.SZ', '000778.SZ', '000779.SZ', '000782.SZ', '000783.SZ', '000785.SZ', '000786.SZ', '000788.SZ', '000789.SZ', '000790.SZ', '000791.SZ', '000792.SZ', '000793.SZ', '000795.SZ', '000796.SZ', '000797.SZ', '000798.SZ', '000799.SZ', '000800.SZ', '000801.SZ', '000802.SZ', '000803.SZ', '000807.SZ', '000809.SZ', '000810.SZ', '000811.SZ', '000812.SZ', '000813.SZ', '000815.SZ', '000816.SZ', '000818.SZ', '000819.SZ', '000820.SZ', '000821.SZ', '000822.SZ', '000823.SZ', '000825.SZ', '000826.SZ', '000828.SZ', '000829.SZ', '000830.SZ', '000831.SZ', '000833.SZ', '000837.SZ', '000838.SZ', '000839.SZ', '000848.SZ', '000850.SZ', '000851.SZ', '000852.SZ', '000856.SZ', '000858.SZ', '000859.SZ', '000860.SZ', '000862.SZ', '000863.SZ', '000868.SZ', '000869.SZ', '000875.SZ', '000876.SZ', '000877.SZ', '000878.SZ', '000880.SZ', '000881.SZ', '000882.SZ', '000883.SZ', '000885.SZ', '000886.SZ', '000887.SZ', '000888.SZ', '000889.SZ', '000890.SZ', '000892.SZ', '000893.SZ', '000895.SZ', '000897.SZ', '000898.SZ', '000899.SZ', '000900.SZ', '000901.SZ', '000902.SZ', '000903.SZ', '000905.SZ', '000906.SZ', '000908.SZ', '000909.SZ', '000910.SZ', '000911.SZ', '000912.SZ', '000913.SZ', '000915.SZ', '000917.SZ', '000919.SZ', '000920.SZ', '000921.SZ', '000922.SZ', '000923.SZ', '000925.SZ', '000926.SZ', '000927.SZ', '000928.SZ', '000929.SZ', '000930.SZ', '000931.SZ', '000932.SZ', '000933.SZ', '000935.SZ', '000936.SZ', '000937.SZ', '000938.SZ', '000948.SZ', '000949.SZ', '000950.SZ', '000951.SZ', '000952.SZ', '000953.SZ', '000955.SZ', '000957.SZ', '000958.SZ', '000959.SZ', '000960.SZ', '000962.SZ', '000963.SZ', '000965.SZ', '000966.SZ', '000967.SZ', '000968.SZ', '000969.SZ', '000970.SZ', '000972.SZ', '000973.SZ', '000975.SZ', '000977.SZ', '000978.SZ', '000980.SZ', '000981.SZ', '000983.SZ', '000985.SZ', '000987.SZ', '000988.SZ', '000989.SZ', '000990.SZ', '000993.SZ', '000995.SZ', '000997.SZ', '000998.SZ', '000999.SZ', '001201.SZ', '001202.SZ', '001203.SZ', '001205.SZ', '001206.SZ', '001207.SZ', '001208.SZ', '001209.SZ', '001210.SZ', '001211.SZ', '001212.SZ', '001213.SZ', '001215.SZ', '001216.SZ', '001217.SZ', '001218.SZ', '001219.SZ', '001222.SZ', '001223.SZ', '001225.SZ', '001226.SZ', '001227.SZ', '001228.SZ', '001229.SZ', '001230.SZ', '001231.SZ', '001234.SZ', '001236.SZ', '001238.SZ', '001239.SZ', '001255.SZ', '001256.SZ', '001258.SZ', '001259.SZ', '001260.SZ', '001266.SZ', '001267.SZ', '001268.SZ', '001269.SZ', '001270.SZ', '001277.SZ', '001278.SZ', '001279.SZ', '001282.SZ', '001283.SZ', '001286.SZ', '001287.SZ', '001288.SZ', '001289.SZ', '001296.SZ', '001298.SZ', '001299.SZ', '001300.SZ', '001301.SZ', '001306.SZ', '001308.SZ', '001309.SZ', '001311.SZ', '001313.SZ', '001314.SZ', '001316.SZ', '001317.SZ', '001318.SZ', '001319.SZ', '001322.SZ', '001323.SZ', '001324.SZ', '001326.SZ', '001328.SZ', '001330.SZ', '001331.SZ', '001332.SZ', '001333.SZ', '001336.SZ', '001337.SZ', '001338.SZ', '001339.SZ', '001356.SZ', '001358.SZ', '001359.SZ', '001360.SZ', '001366.SZ', '001367.SZ', '001368.SZ', '001373.SZ', '001376.SZ', '001378.SZ', '001379.SZ', '001380.SZ', '001387.SZ', '001389.SZ', '001391.SZ', '001395.SZ', '001696.SZ', '001872.SZ', '001896.SZ', '001914.SZ', '001965.SZ', '001979.SZ', '002001.SZ', '002003.SZ', '002004.SZ', '002005.SZ', '002006.SZ', '002007.SZ', '002008.SZ', '002009.SZ', '002010.SZ', '002011.SZ', '002012.SZ', '002014.SZ', '002015.SZ', '002016.SZ', '002017.SZ', '002019.SZ', '002020.SZ', '002021.SZ', '002022.SZ', '002023.SZ', '002024.SZ', '002025.SZ', '002026.SZ', '002027.SZ', '002028.SZ', '002029.SZ', '002030.SZ', '002031.SZ', '002032.SZ', '002033.SZ', '002034.SZ', '002035.SZ', '002036.SZ', '002037.SZ', '002038.SZ', '002039.SZ', '002040.SZ', '002041.SZ', '002042.SZ', '002043.SZ', '002044.SZ', '002045.SZ', '002046.SZ', '002047.SZ', '002048.SZ', '002049.SZ', '002050.SZ', '002051.SZ', '002052.SZ', '002053.SZ', '002054.SZ', '002055.SZ', '002056.SZ', '002057.SZ', '002058.SZ', '002059.SZ', '002060.SZ', '002061.SZ', '002062.SZ', '002063.SZ', '002064.SZ', '002065.SZ', '002066.SZ', '002067.SZ', '002068.SZ', '002069.SZ', '002072.SZ', '002073.SZ', '002074.SZ', '002075.SZ', '002076.SZ', '002077.SZ', '002078.SZ', '002079.SZ', '002080.SZ', '002081.SZ', '002082.SZ', '002083.SZ', '002084.SZ', '002085.SZ', '002086.SZ', '002088.SZ', '002090.SZ', '002091.SZ', '002092.SZ', '002093.SZ', '002094.SZ', '002095.SZ', '002096.SZ', '002097.SZ', '002098.SZ', '002099.SZ', '002100.SZ', '002101.SZ', '002102.SZ', '002103.SZ', '002104.SZ', '002105.SZ', '002106.SZ', '002107.SZ', '002108.SZ', '002109.SZ', '002110.SZ', '002111.SZ', '002112.SZ', '002114.SZ', '002115.SZ', '002116.SZ', '002117.SZ', '002119.SZ', '002120.SZ', '002121.SZ', '002122.SZ', '002123.SZ', '002124.SZ', '002125.SZ', '002126.SZ', '002127.SZ', '002128.SZ', '002129.SZ', '002130.SZ', '002131.SZ', '002132.SZ', '002133.SZ', '002134.SZ', '002135.SZ', '002136.SZ', '002137.SZ', '002138.SZ', '002139.SZ', '002140.SZ', '002141.SZ', '002142.SZ', '002144.SZ', '002145.SZ', '002146.SZ', '002148.SZ', '002149.SZ', '002150.SZ', '002151.SZ', '002152.SZ', '002153.SZ', '002154.SZ', '002155.SZ', '002156.SZ', '002157.SZ', '002158.SZ', '002159.SZ', '002160.SZ', '002161.SZ', '002162.SZ', '002163.SZ', '002164.SZ', '002165.SZ', '002166.SZ', '002167.SZ', '002168.SZ', '002169.SZ', '002170.SZ', '002171.SZ', '002172.SZ', '002173.SZ', '002174.SZ', '002175.SZ', '002176.SZ', '002177.SZ', '002178.SZ', '002179.SZ', '002180.SZ', '002181.SZ', '002182.SZ', '002183.SZ', '002184.SZ', '002185.SZ', '002186.SZ', '002187.SZ', '002188.SZ', '002189.SZ', '002190.SZ', '002191.SZ', '002192.SZ', '002193.SZ', '002194.SZ', '002195.SZ', '002196.SZ', '002197.SZ', '002198.SZ', '002199.SZ', '002200.SZ', '002201.SZ', '002202.SZ', '002203.SZ', '002204.SZ', '002205.SZ', '002206.SZ', '002207.SZ', '002208.SZ', '002209.SZ', '002210.SZ', '002211.SZ', '002212.SZ', '002213.SZ', '002214.SZ', '002215.SZ', '002216.SZ', '002217.SZ', '002218.SZ', '002219.SZ', '002221.SZ', '002222.SZ', '002223.SZ', '002224.SZ', '002225.SZ', '002226.SZ', '002227.SZ', '002228.SZ', '002229.SZ', '002230.SZ', '002231.SZ', '002232.SZ', '002233.SZ', '002234.SZ', '002235.SZ', '002236.SZ', '002237.SZ', '002238.SZ', '002239.SZ', '002240.SZ', '002241.SZ', '002242.SZ', '002243.SZ', '002244.SZ', '002245.SZ', '002246.SZ', '002247.SZ', '002248.SZ', '002249.SZ', '002250.SZ', '002251.SZ', '002252.SZ', '002253.SZ', '002254.SZ', '002255.SZ', '002256.SZ', '002258.SZ', '002259.SZ', '002261.SZ', '002262.SZ', '002263.SZ', '002264.SZ', '002265.SZ', '002266.SZ', '002267.SZ', '002268.SZ', '002269.SZ', '002270.SZ', '002271.SZ', '002272.SZ', '002273.SZ', '002274.SZ', '002275.SZ', '002276.SZ', '002277.SZ', '002278.SZ', '002279.SZ', '002281.SZ', '002282.SZ', '002283.SZ', '002284.SZ', '002285.SZ', '002286.SZ', '002287.SZ', '002289.SZ', '002290.SZ', '002291.SZ', '002292.SZ', '002293.SZ', '002294.SZ', '002295.SZ', '002296.SZ', '002297.SZ', '002298.SZ', '002299.SZ', '002300.SZ', '002301.SZ', '002302.SZ', '002303.SZ', '002304.SZ', '002305.SZ', '002306.SZ', '002307.SZ', '002309.SZ', '002310.SZ', '002311.SZ', '002312.SZ', '002313.SZ', '002314.SZ', '002315.SZ', '002316.SZ', '002317.SZ', '002318.SZ', '002319.SZ', '002320.SZ', '002321.SZ', '002322.SZ', '002323.SZ', '002324.SZ', '002326.SZ', '002327.SZ', '002328.SZ', '002329.SZ', '002330.SZ', '002331.SZ', '002332.SZ', '002333.SZ', '002334.SZ', '002335.SZ', '002336.SZ', '002337.SZ', '002338.SZ', '002339.SZ', '002340.SZ', '002342.SZ', '002343.SZ', '002344.SZ', '002345.SZ', '002346.SZ', '002347.SZ', '002348.SZ', '002349.SZ', '002350.SZ', '002351.SZ', '002352.SZ', '002353.SZ', '002354.SZ', '002355.SZ', '002356.SZ', '002357.SZ', '002358.SZ', '002360.SZ', '002361.SZ', '002362.SZ', '002363.SZ', '002364.SZ', '002365.SZ', '002366.SZ', '002367.SZ', '002368.SZ', '002369.SZ', '002370.SZ', '002371.SZ', '002372.SZ', '002373.SZ', '002374.SZ', '002375.SZ', '002376.SZ', '002377.SZ', '002378.SZ', '002379.SZ', '002380.SZ', '002381.SZ', '002382.SZ', '002383.SZ', '002384.SZ', '002385.SZ', '002386.SZ', '002387.SZ', '002388.SZ', '002389.SZ', '002390.SZ', '002391.SZ', '002392.SZ', '002393.SZ', '002394.SZ', '002395.SZ', '002396.SZ', '002397.SZ', '002398.SZ', '002399.SZ', '002400.SZ', '002401.SZ', '002402.SZ', '002403.SZ', '002404.SZ', '002405.SZ', '002406.SZ', '002407.SZ', '002408.SZ', '002409.SZ', '002410.SZ', '002412.SZ', '002413.SZ', '002414.SZ', '002415.SZ', '002416.SZ', '002418.SZ', '002419.SZ', '002420.SZ', '002421.SZ', '002422.SZ', '002423.SZ', '002424.SZ', '002425.SZ', '002426.SZ', '002427.SZ', '002428.SZ', '002429.SZ', '002430.SZ', '002431.SZ', '002432.SZ', '002434.SZ', '002436.SZ', '002437.SZ', '002438.SZ', '002439.SZ', '002440.SZ', '002441.SZ', '002442.SZ', '002443.SZ', '002444.SZ', '002445.SZ', '002446.SZ', '002448.SZ', '002449.SZ', '002451.SZ', '002452.SZ', '002453.SZ', '002454.SZ', '002455.SZ', '002456.SZ', '002457.SZ', '002458.SZ', '002459.SZ', '002460.SZ', '002461.SZ', '002462.SZ', '002463.SZ', '002465.SZ', '002466.SZ', '002467.SZ', '002468.SZ', '002469.SZ', '002470.SZ', '002471.SZ', '002472.SZ', '002474.SZ', '002475.SZ', '002476.SZ', '002478.SZ', '002479.SZ', '002480.SZ', '002481.SZ', '002482.SZ', '002483.SZ', '002484.SZ', '002485.SZ', '002486.SZ', '002487.SZ', '002488.SZ', '002489.SZ', '002490.SZ', '002491.SZ', '002492.SZ', '002493.SZ', '002494.SZ', '002495.SZ', '002496.SZ', '002497.SZ', '002498.SZ', '002500.SZ', '002501.SZ', '002506.SZ', '002507.SZ', '002508.SZ', '002510.SZ', '002511.SZ', '002512.SZ', '002513.SZ', '002514.SZ', '002515.SZ', '002516.SZ', '002517.SZ', '002518.SZ', '002519.SZ', '002520.SZ', '002521.SZ', '002522.SZ', '002523.SZ', '002524.SZ', '002526.SZ', '002527.SZ', '002528.SZ', '002529.SZ', '002530.SZ', '002531.SZ', '002532.SZ', '002533.SZ', '002534.SZ', '002535.SZ', '002536.SZ', '002537.SZ', '002538.SZ', '002539.SZ', '002540.SZ', '002541.SZ', '002542.SZ', '002543.SZ', '002544.SZ', '002545.SZ', '002546.SZ', '002547.SZ', '002548.SZ', '002549.SZ', '002550.SZ', '002551.SZ', '002552.SZ', '002553.SZ', '002554.SZ', '002555.SZ', '002556.SZ', '002557.SZ', '002558.SZ', '002559.SZ', '002560.SZ', '002561.SZ', '002562.SZ', '002563.SZ', '002564.SZ', '002565.SZ', '002566.SZ', '002567.SZ', '002568.SZ', '002569.SZ', '002570.SZ', '002571.SZ', '002572.SZ', '002573.SZ', '002574.SZ', '002575.SZ', '002576.SZ', '002577.SZ', '002578.SZ', '002579.SZ', '002580.SZ', '002581.SZ', '002582.SZ', '002583.SZ', '002584.SZ', '002585.SZ', '002586.SZ', '002587.SZ', '002588.SZ', '002589.SZ', '002590.SZ', '002591.SZ', '002592.SZ', '002593.SZ', '002594.SZ', '002595.SZ', '002596.SZ', '002597.SZ', '002598.SZ', '002599.SZ', '002600.SZ', '002601.SZ', '002602.SZ', '002603.SZ', '002605.SZ', '002606.SZ', '002607.SZ', '002608.SZ', '002609.SZ', '002611.SZ', '002612.SZ', '002613.SZ', '002614.SZ', '002615.SZ', '002616.SZ', '002617.SZ', '002620.SZ', '002622.SZ', '002623.SZ', '002624.SZ', '002625.SZ', '002626.SZ', '002627.SZ', '002628.SZ', '002629.SZ', '002630.SZ', '002631.SZ', '002632.SZ', '002633.SZ', '002634.SZ', '002635.SZ', '002636.SZ', '002637.SZ', '002638.SZ', '002639.SZ', '002640.SZ', '002641.SZ', '002642.SZ', '002643.SZ', '002644.SZ', '002645.SZ', '002646.SZ', '002647.SZ', '002648.SZ', '002649.SZ', '002650.SZ', '002651.SZ', '002652.SZ', '002653.SZ', '002654.SZ', '002655.SZ', '002656.SZ', '002657.SZ', '002658.SZ', '002659.SZ', '002660.SZ', '002661.SZ', '002662.SZ', '002663.SZ', '002664.SZ', '002666.SZ', '002667.SZ', '002668.SZ', '002669.SZ', '002670.SZ', '002671.SZ', '002672.SZ', '002673.SZ', '002674.SZ', '002675.SZ', '002676.SZ', '002677.SZ', '002678.SZ', '002679.SZ', '002681.SZ', '002682.SZ', '002683.SZ', '002685.SZ', '002686.SZ', '002687.SZ', '002688.SZ', '002689.SZ', '002690.SZ', '002691.SZ', '002692.SZ', '002693.SZ', '002694.SZ', '002695.SZ', '002696.SZ', '002697.SZ', '002698.SZ', '002700.SZ', '002701.SZ', '002702.SZ', '002703.SZ', '002705.SZ', '002706.SZ', '002707.SZ', '002708.SZ', '002709.SZ', '002712.SZ', '002713.SZ', '002714.SZ', '002715.SZ', '002716.SZ', '002717.SZ', '002718.SZ', '002719.SZ', '002721.SZ', '002722.SZ', '002723.SZ', '002724.SZ', '002725.SZ', '002726.SZ', '002727.SZ', '002728.SZ', '002729.SZ', '002730.SZ', '002731.SZ', '002732.SZ', '002733.SZ', '002734.SZ', '002735.SZ', '002736.SZ', '002737.SZ', '002738.SZ', '002739.SZ', '002741.SZ', '002742.SZ', '002743.SZ', '002745.SZ', '002746.SZ', '002747.SZ', '002748.SZ', '002749.SZ', '002750.SZ', '002752.SZ', '002753.SZ', '002755.SZ', '002756.SZ', '002757.SZ', '002758.SZ', '002759.SZ', '002760.SZ', '002761.SZ', '002762.SZ', '002763.SZ', '002765.SZ', '002766.SZ', '002767.SZ', '002768.SZ', '002769.SZ', '002771.SZ', '002772.SZ', '002773.SZ', '002774.SZ', '002775.SZ', '002777.SZ', '002778.SZ', '002779.SZ', '002780.SZ', '002782.SZ', '002783.SZ', '002785.SZ', '002786.SZ', '002787.SZ', '002788.SZ', '002789.SZ', '002790.SZ', '002791.SZ', '002792.SZ', '002793.SZ', '002795.SZ', '002796.SZ', '002797.SZ', '002798.SZ', '002799.SZ', '002800.SZ', '002801.SZ', '002802.SZ', '002803.SZ', '002805.SZ', '002806.SZ', '002807.SZ', '002808.SZ', '002809.SZ', '002810.SZ', '002811.SZ', '002812.SZ', '002813.SZ', '002815.SZ', '002816.SZ', '002817.SZ', '002818.SZ', '002819.SZ', '002820.SZ', '002821.SZ', '002822.SZ', '002823.SZ', '002824.SZ', '002825.SZ', '002826.SZ', '002827.SZ', '002828.SZ', '002829.SZ', '002830.SZ', '002831.SZ', '002832.SZ', '002833.SZ', '002835.SZ', '002836.SZ', '002837.SZ', '002838.SZ', '002839.SZ', '002840.SZ', '002841.SZ', '002842.SZ', '002843.SZ', '002845.SZ', '002846.SZ', '002847.SZ', '002848.SZ', '002849.SZ', '002850.SZ', '002851.SZ', '002852.SZ', '002853.SZ', '002855.SZ', '002856.SZ', '002857.SZ', '002858.SZ', '002859.SZ', '002860.SZ', '002861.SZ', '002862.SZ', '002863.SZ', '002864.SZ', '002865.SZ', '002866.SZ', '002867.SZ', '002868.SZ', '002869.SZ', '002870.SZ', '002871.SZ', '002872.SZ', '002873.SZ', '002875.SZ', '002876.SZ', '002877.SZ', '002878.SZ', '002879.SZ', '002880.SZ', '002881.SZ', '002882.SZ', '002883.SZ', '002884.SZ', '002885.SZ', '002886.SZ', '002887.SZ', '002888.SZ', '002889.SZ', '002890.SZ', '002891.SZ', '002892.SZ', '002893.SZ', '002895.SZ', '002896.SZ', '002897.SZ', '002898.SZ', '002899.SZ', '002900.SZ', '002901.SZ', '002902.SZ', '002903.SZ', '002905.SZ', '002906.SZ', '002907.SZ', '002908.SZ', '002909.SZ', '002910.SZ', '002911.SZ', '002912.SZ', '002913.SZ', '002915.SZ', '002916.SZ', '002917.SZ', '002918.SZ', '002919.SZ', '002920.SZ', '002921.SZ', '002922.SZ', '002923.SZ', '002925.SZ', '002926.SZ', '002927.SZ', '002928.SZ', '002929.SZ', '002930.SZ', '002931.SZ', '002932.SZ', '002933.SZ', '002935.SZ', '002936.SZ', '002937.SZ', '002938.SZ', '002939.SZ', '002940.SZ', '002941.SZ', '002942.SZ', '002943.SZ', '002945.SZ', '002946.SZ', '002947.SZ', '002948.SZ', '002949.SZ', '002950.SZ', '002951.SZ', '002952.SZ', '002953.SZ', '002955.SZ', '002956.SZ', '002957.SZ', '002958.SZ', '002959.SZ', '002960.SZ', '002961.SZ', '002962.SZ', '002963.SZ', '002965.SZ', '002966.SZ', '002967.SZ', '002968.SZ', '002969.SZ', '002970.SZ', '002971.SZ', '002972.SZ', '002973.SZ', '002975.SZ', '002976.SZ', '002977.SZ', '002978.SZ', '002979.SZ', '002980.SZ', '002981.SZ', '002982.SZ', '002983.SZ', '002984.SZ', '002985.SZ', '002986.SZ', '002987.SZ', '002988.SZ', '002989.SZ', '002990.SZ', '002991.SZ', '002992.SZ', '002993.SZ', '002995.SZ', '002996.SZ', '002997.SZ', '002998.SZ', '002999.SZ', '003000.SZ', '003001.SZ', '003002.SZ', '003003.SZ', '003004.SZ', '003005.SZ', '003006.SZ', '003007.SZ', '003008.SZ', '003009.SZ', '003010.SZ', '003011.SZ', '003012.SZ', '003013.SZ', '003015.SZ', '003016.SZ', '003017.SZ', '003018.SZ', '003019.SZ', '003020.SZ', '003021.SZ', '003022.SZ', '003023.SZ', '003025.SZ', '003026.SZ', '003027.SZ', '003028.SZ', '003029.SZ', '003030.SZ', '003031.SZ', '003032.SZ', '003033.SZ', '003035.SZ', '003036.SZ', '003037.SZ', '003038.SZ', '003039.SZ', '003040.SZ', '003041.SZ', '003042.SZ', '003043.SZ', '003816.SZ', '688001.SS', '688002.SS', '688003.SS', '688004.SS', '688005.SS', '688006.SS', '688007.SS', '688008.SS', '688009.SS', '688010.SS', '688011.SS', '688012.SS', '688013.SS', '688015.SS', '688016.SS', '688017.SS', '688018.SS', '688019.SS', '688020.SS', '688021.SS', '688022.SS', '688023.SS', '688025.SS', '688026.SS', '688027.SS', '688028.SS', '688029.SS', '688030.SS', '688031.SS', '688032.SS', '688033.SS', '688035.SS', '688036.SS', '688037.SS', '688038.SS', '688039.SS', '688041.SS', '688045.SS', '688046.SS', '688047.SS', '688048.SS', '688049.SS', '688050.SS', '688051.SS', '688052.SS', '688053.SS', '688055.SS', '688056.SS', '688057.SS', '688058.SS', '688059.SS', '688060.SS', '688061.SS', '688062.SS', '688063.SS', '688065.SS', '688066.SS', '688067.SS', '688068.SS', '688069.SS', '688070.SS', '688071.SS', '688072.SS', '688073.SS', '688075.SS', '688076.SS', '688077.SS', '688078.SS', '688079.SS', '688080.SS', '688081.SS', '688082.SS', '688083.SS', '688084.SS', '688085.SS', '688087.SS', '688088.SS', '688089.SS', '688090.SS', '688091.SS', '688092.SS', '688093.SS', '688095.SS', '688096.SS', '688097.SS', '688098.SS', '688099.SS', '688100.SS', '688101.SS', '688102.SS', '688103.SS', '688105.SS', '688106.SS', '688107.SS', '688108.SS', '688109.SS', '688110.SS', '688111.SS', '688112.SS', '688113.SS', '688114.SS', '688115.SS', '688116.SS', '688117.SS', '688118.SS', '688119.SS', '688120.SS', '688121.SS', '688122.SS', '688123.SS', '688125.SS', '688126.SS', '688127.SS', '688128.SS', '688129.SS', '688130.SS', '688131.SS', '688132.SS', '688133.SS', '688135.SS', '688136.SS', '688137.SS', '688138.SS', '688139.SS', '688141.SS', '688143.SS', '688146.SS', '688147.SS', '688148.SS', '688150.SS', '688151.SS', '688152.SS', '688153.SS', '688155.SS', '688156.SS', '688157.SS', '688158.SS', '688159.SS', '688160.SS', '688161.SS', '688162.SS', '688163.SS', '688165.SS', '688166.SS', '688167.SS', '688168.SS', '688169.SS', '688170.SS', '688171.SS', '688172.SS', '688173.SS', '688175.SS', '688176.SS', '688177.SS', '688178.SS', '688179.SS', '688180.SS', '688181.SS', '688182.SS', '688183.SS', '688184.SS', '688185.SS', '688186.SS', '688187.SS', '688188.SS', '688189.SS', '688190.SS', '688191.SS', '688192.SS', '688193.SS', '688195.SS', '688196.SS', '688197.SS', '688198.SS', '688199.SS', '688200.SS', '688201.SS', '688202.SS', '688203.SS', '688205.SS', '688206.SS', '688207.SS', '688208.SS', '688209.SS', '688210.SS', '688211.SS', '688212.SS', '688213.SS', '688215.SS', '688216.SS', '688217.SS', '688218.SS', '688219.SS', '688220.SS', '688221.SS', '688222.SS', '688223.SS', '688225.SS', '688226.SS', '688227.SS', '688228.SS', '688229.SS', '688230.SS', '688231.SS', '688232.SS', '688233.SS', '688234.SS', '688235.SS', '688236.SS', '688237.SS', '688238.SS', '688239.SS', '688244.SS', '688246.SS', '688247.SS', '688248.SS', '688249.SS', '688251.SS', '688252.SS', '688253.SS', '688255.SS', '688256.SS', '688257.SS', '688258.SS', '688259.SS', '688260.SS', '688261.SS', '688262.SS', '688265.SS', '688266.SS', '688267.SS', '688268.SS', '688269.SS', '688270.SS', '688271.SS', '688272.SS', '688273.SS', '688275.SS', '688276.SS', '688277.SS', '688278.SS', '688279.SS', '688280.SS', '688281.SS', '688282.SS', '688283.SS', '688285.SS', '688286.SS', '688287.SS', '688288.SS', '688289.SS', '688290.SS', '688291.SS', '688292.SS', '688293.SS', '688295.SS', '688296.SS', '688297.SS', '688298.SS', '688299.SS', '688300.SS', '688301.SS', '688302.SS', '688303.SS', '688305.SS', '688306.SS', '688307.SS', '688308.SS', '688309.SS', '688310.SS', '688311.SS', '688312.SS', '688313.SS', '688314.SS', '688315.SS', '688316.SS', '688317.SS', '688318.SS', '688319.SS', '688320.SS', '688321.SS', '688322.SS', '688323.SS', '688325.SS', '688326.SS', '688327.SS', '688328.SS', '688329.SS', '688330.SS', '688331.SS', '688332.SS', '688333.SS', '688334.SS', '688335.SS', '688336.SS', '688337.SS', '688338.SS', '688339.SS', '688343.SS', '688345.SS', '688347.SS', '688348.SS', '688349.SS', '688350.SS', '688351.SS', '688352.SS', '688353.SS', '688355.SS', '688356.SS', '688357.SS', '688358.SS', '688359.SS', '688360.SS', '688361.SS', '688362.SS', '688363.SS', '688365.SS', '688366.SS', '688367.SS', '688368.SS', '688369.SS', '688370.SS', '688371.SS', '688372.SS', '688373.SS', '688375.SS', '688376.SS', '688377.SS', '688378.SS', '688379.SS', '688380.SS', '688381.SS', '688382.SS', '688383.SS', '688385.SS', '688386.SS', '688387.SS', '688388.SS', '688389.SS', '688390.SS', '688391.SS', '688392.SS', '688393.SS', '688395.SS', '688396.SS', '688398.SS', '688399.SS', '688400.SS', '688401.SS', '688403.SS', '688408.SS', '688409.SS', '688410.SS', '688411.SS', '688416.SS', '688418.SS', '688419.SS', '688420.SS', '688425.SS', '688426.SS', '688428.SS', '688429.SS', '688432.SS', '688433.SS', '688435.SS', '688439.SS', '688443.SS', '688448.SS', '688449.SS', '688450.SS', '688455.SS', '688456.SS', '688458.SS', '688459.SS', '688466.SS', '688468.SS', '688469.SS', '688472.SS', '688475.SS', '688478.SS', '688479.SS', '688480.SS', '688484.SS', '688485.SS', '688486.SS', '688488.SS', '688489.SS', '688496.SS', '688498.SS', '688499.SS', '688500.SS', '688501.SS', '688502.SS', '688503.SS', '688505.SS', '688506.SS', '688507.SS', '688508.SS', '688509.SS', '688510.SS', '688511.SS', '688512.SS', '688513.SS', '688515.SS', '688516.SS', '688517.SS', '688518.SS', '688519.SS', '688520.SS', '688521.SS', '688522.SS', '688523.SS', '688525.SS', '688526.SS', '688528.SS', '688529.SS', '688530.SS', '688531.SS', '688533.SS', '688535.SS', '688536.SS', '688538.SS', '688539.SS', '688543.SS', '688545.SS', '688548.SS', '688549.SS', '688550.SS', '688551.SS', '688552.SS', '688553.SS', '688556.SS', '688557.SS', '688558.SS', '688559.SS', '688560.SS', '688561.SS', '688562.SS', '688563.SS', '688565.SS', '688566.SS', '688567.SS', '688568.SS', '688569.SS', '688570.SS', '688571.SS', '688573.SS', '688575.SS', '688576.SS', '688577.SS', '688578.SS', '688579.SS', '688580.SS', '688581.SS', '688582.SS', '688583.SS', '688584.SS', '688585.SS', '688586.SS', '688588.SS', '688589.SS', '688590.SS', '688591.SS', '688592.SS', '688593.SS', '688595.SS', '688596.SS', '688597.SS', '688598.SS', '688599.SS', '688600.SS', '688601.SS', '688602.SS', '688603.SS', '688605.SS', '688606.SS', '688607.SS', '688608.SS', '688609.SS', '688610.SS', '688611.SS', '688612.SS', '688613.SS', '688615.SS', '688616.SS', '688617.SS', '688618.SS', '688619.SS', '688620.SS', '688621.SS', '688622.SS', '688623.SS', '688625.SS', '688626.SS', '688627.SS', '688628.SS', '688629.SS', '688630.SS', '688631.SS', '688633.SS', '688636.SS', '688638.SS', '688639.SS', '688646.SS', '688648.SS', '688651.SS', '688652.SS', '688653.SS', '688655.SS', '688656.SS', '688657.SS', '688658.SS', '688659.SS', '688660.SS', '688661.SS', '688662.SS', '688663.SS', '688665.SS', '688667.SS', '688668.SS', '688669.SS', '688670.SS', '688671.SS', '688676.SS', '688677.SS', '688678.SS', '688679.SS', '688680.SS', '688681.SS', '688682.SS', '688683.SS', '688685.SS', '688686.SS', '688687.SS', '688689.SS', '688690.SS', '688691.SS', '688692.SS', '688693.SS', '688695.SS', '688696.SS', '688697.SS', '688698.SS', '688699.SS', '688700.SS', '688701.SS', '688702.SS', '688707.SS', '688708.SS', '688709.SS', '688710.SS', '688711.SS', '688716.SS', '688717.SS', '688718.SS', '688719.SS', '688720.SS', '688721.SS', '688722.SS', '688726.SS', '688728.SS', '688733.SS', '688737.SS', '688739.SS', '688750.SS', '688758.SS', '688766.SS', '688767.SS', '688768.SS', '688772.SS', '688776.SS', '688777.SS', '688778.SS', '688779.SS', '688786.SS', '688787.SS', '688788.SS', '688789.SS', '688793.SS', '688798.SS', '688799.SS', '688800.SS', '688819.SS', '688981.SS', '689009.SS', '300001.SZ', '300002.SZ', '300003.SZ', '300004.SZ', '300005.SZ', '300006.SZ', '300007.SZ', '300008.SZ', '300009.SZ', '300010.SZ', '300011.SZ', '300012.SZ', '300013.SZ', '300014.SZ', '300015.SZ', '300016.SZ', '300017.SZ', '300018.SZ', '300019.SZ', '300020.SZ', '300021.SZ', '300022.SZ', '300024.SZ', '300025.SZ', '300026.SZ', '300027.SZ', '300029.SZ', '300030.SZ', '300031.SZ', '300032.SZ', '300033.SZ', '300034.SZ', '300035.SZ', '300036.SZ', '300037.SZ', '300039.SZ', '300040.SZ', '300041.SZ', '300042.SZ', '300043.SZ', '300044.SZ', '300045.SZ', '300046.SZ', '300047.SZ', '300048.SZ', '300049.SZ', '300050.SZ', '300051.SZ', '300052.SZ', '300053.SZ', '300054.SZ', '300055.SZ', '300056.SZ', '300057.SZ', '300058.SZ', '300059.SZ', '300061.SZ', '300062.SZ', '300063.SZ', '300065.SZ', '300066.SZ', '300067.SZ', '300068.SZ', '300069.SZ', '300070.SZ', '300071.SZ', '300072.SZ', '300073.SZ', '300074.SZ', '300075.SZ', '300076.SZ', '300077.SZ', '300078.SZ', '300079.SZ', '300080.SZ', '300081.SZ', '300082.SZ', '300083.SZ', '300084.SZ', '300085.SZ', '300086.SZ', '300087.SZ', '300088.SZ', '300091.SZ', '300092.SZ', '300093.SZ', '300094.SZ', '300095.SZ', '300096.SZ', '300097.SZ', '300098.SZ', '300099.SZ', '300100.SZ', '300101.SZ', '300102.SZ', '300103.SZ', '300105.SZ', '300106.SZ', '300107.SZ', '300108.SZ', '300109.SZ', '300110.SZ', '300111.SZ', '300112.SZ', '300113.SZ', '300115.SZ', '300117.SZ', '300118.SZ', '300119.SZ', '300120.SZ', '300121.SZ', '300122.SZ', '300123.SZ', '300124.SZ', '300125.SZ', '300126.SZ', '300127.SZ', '300128.SZ', '300129.SZ', '300130.SZ', '300131.SZ', '300132.SZ', '300133.SZ', '300134.SZ', '300135.SZ', '300136.SZ', '300137.SZ', '300138.SZ', '300139.SZ', '300140.SZ', '300141.SZ', '300142.SZ', '300143.SZ', '300144.SZ', '300145.SZ', '300146.SZ', '300147.SZ', '300148.SZ', '300149.SZ', '300150.SZ', '300151.SZ', '300152.SZ', '300153.SZ', '300154.SZ', '300155.SZ', '300157.SZ', '300158.SZ', '300159.SZ', '300160.SZ', '300161.SZ', '300162.SZ', '300163.SZ', '300164.SZ', '300165.SZ', '300166.SZ', '300167.SZ', '300168.SZ', '300169.SZ', '300170.SZ', '300171.SZ', '300172.SZ', '300173.SZ', '300174.SZ', '300175.SZ', '300176.SZ', '300177.SZ', '300179.SZ', '300180.SZ', '300181.SZ', '300182.SZ', '300183.SZ', '300184.SZ', '300185.SZ', '300187.SZ', '300188.SZ', '300189.SZ', '300190.SZ', '300191.SZ', '300192.SZ', '300193.SZ', '300194.SZ', '300195.SZ', '300196.SZ', '300197.SZ', '300198.SZ', '300199.SZ', '300200.SZ', '300201.SZ', '300203.SZ', '300204.SZ', '300205.SZ', '300206.SZ', '300207.SZ', '300208.SZ', '300209.SZ', '300210.SZ', '300211.SZ', '300212.SZ', '300213.SZ', '300214.SZ', '300215.SZ', '300217.SZ', '300218.SZ', '300219.SZ', '300220.SZ', '300221.SZ', '300222.SZ', '300223.SZ', '300224.SZ', '300225.SZ', '300226.SZ', '300227.SZ', '300228.SZ', '300229.SZ', '300230.SZ', '300231.SZ', '300232.SZ', '300233.SZ', '300234.SZ', '300235.SZ', '300236.SZ', '300237.SZ', '300238.SZ', '300239.SZ', '300240.SZ', '300241.SZ', '300242.SZ', '300243.SZ', '300244.SZ', '300245.SZ', '300246.SZ', '300247.SZ', '300248.SZ', '300249.SZ', '300250.SZ', '300251.SZ', '300252.SZ', '300253.SZ', '300254.SZ', '300255.SZ', '300256.SZ', '300257.SZ', '300258.SZ', '300259.SZ', '300260.SZ', '300261.SZ', '300263.SZ', '300264.SZ', '300265.SZ', '300266.SZ', '300267.SZ', '300268.SZ', '300269.SZ', '300270.SZ', '300271.SZ', '300272.SZ', '300274.SZ', '300275.SZ', '300276.SZ', '300277.SZ', '300278.SZ', '300279.SZ', '300280.SZ', '300281.SZ', '300283.SZ', '300284.SZ', '300285.SZ', '300286.SZ', '300287.SZ', '300288.SZ', '300289.SZ', '300290.SZ', '300291.SZ', '300292.SZ', '300293.SZ', '300294.SZ', '300295.SZ', '300296.SZ', '300298.SZ', '300299.SZ', '300300.SZ', '300301.SZ', '300302.SZ', '300303.SZ', '300304.SZ', '300305.SZ', '300306.SZ', '300307.SZ', '300308.SZ', '300310.SZ', '300311.SZ', '300313.SZ', '300314.SZ', '300315.SZ', '300316.SZ', '300317.SZ', '300318.SZ', '300319.SZ', '300320.SZ', '300321.SZ', '300322.SZ', '300323.SZ', '300324.SZ', '300326.SZ', '300327.SZ', '300328.SZ', '300329.SZ', '300331.SZ', '300332.SZ', '300333.SZ', '300334.SZ', '300335.SZ', '300337.SZ', '300338.SZ', '300339.SZ', '300340.SZ', '300341.SZ', '300342.SZ', '300343.SZ', '300344.SZ', '300345.SZ', '300346.SZ', '300347.SZ', '300348.SZ', '300349.SZ', '300350.SZ', '300351.SZ', '300352.SZ', '300353.SZ', '300354.SZ', '300355.SZ', '300357.SZ', '300358.SZ', '300359.SZ', '300360.SZ', '300363.SZ', '300364.SZ', '300365.SZ', '300366.SZ', '300368.SZ', '300369.SZ', '300370.SZ', '300371.SZ', '300373.SZ', '300374.SZ', '300375.SZ', '300376.SZ', '300377.SZ', '300378.SZ', '300379.SZ', '300380.SZ', '300381.SZ', '300382.SZ', '300383.SZ', '300384.SZ', '300385.SZ', '300386.SZ', '300387.SZ', '300388.SZ', '300389.SZ', '300390.SZ', '300391.SZ', '300393.SZ', '300394.SZ', '300395.SZ', '300396.SZ', '300397.SZ', '300398.SZ', '300399.SZ', '300400.SZ', '300401.SZ', '300402.SZ', '300403.SZ', '300404.SZ', '300405.SZ', '300406.SZ', '300407.SZ', '300408.SZ', '300409.SZ', '300410.SZ', '300411.SZ', '300412.SZ', '300413.SZ', '300414.SZ', '300415.SZ', '300416.SZ', '300417.SZ', '300418.SZ', '300419.SZ', '300420.SZ', '300421.SZ', '300422.SZ', '300423.SZ', '300424.SZ', '300425.SZ', '300426.SZ', '300427.SZ', '300428.SZ', '300429.SZ', '300430.SZ', '300432.SZ', '300433.SZ', '300434.SZ', '300435.SZ', '300436.SZ', '300437.SZ', '300438.SZ', '300439.SZ', '300440.SZ', '300441.SZ', '300442.SZ', '300443.SZ', '300444.SZ', '300445.SZ', '300446.SZ', '300447.SZ', '300448.SZ', '300449.SZ', '300450.SZ', '300451.SZ', '300452.SZ', '300453.SZ', '300454.SZ', '300455.SZ', '300456.SZ', '300457.SZ', '300458.SZ', '300459.SZ', '300460.SZ', '300461.SZ', '300462.SZ', '300463.SZ', '300464.SZ', '300465.SZ', '300466.SZ', '300467.SZ', '300468.SZ', '300469.SZ', '300470.SZ', '300471.SZ', '300472.SZ', '300473.SZ', '300474.SZ', '300475.SZ', '300476.SZ', '300477.SZ', '300478.SZ', '300479.SZ', '300480.SZ', '300481.SZ', '300482.SZ', '300483.SZ', '300484.SZ', '300485.SZ', '300486.SZ', '300487.SZ', '300488.SZ', '300489.SZ', '300490.SZ', '300491.SZ', '300492.SZ', '300493.SZ', '300494.SZ', '300496.SZ', '300497.SZ', '300498.SZ', '300499.SZ', '300500.SZ', '300501.SZ', '300502.SZ', '300503.SZ', '300504.SZ', '300505.SZ', '300506.SZ', '300507.SZ', '300508.SZ', '300509.SZ', '300510.SZ', '300511.SZ', '300512.SZ', '300513.SZ', '300514.SZ', '300515.SZ', '300516.SZ', '300517.SZ', '300518.SZ', '300519.SZ', '300520.SZ', '300521.SZ', '300522.SZ', '300523.SZ', '300525.SZ', '300527.SZ', '300528.SZ', '300529.SZ', '300530.SZ', '300531.SZ', '300532.SZ', '300533.SZ', '300534.SZ', '300535.SZ', '300536.SZ', '300537.SZ', '300538.SZ', '300539.SZ', '300540.SZ', '300541.SZ', '300542.SZ', '300543.SZ', '300545.SZ', '300546.SZ', '300547.SZ', '300548.SZ', '300549.SZ', '300550.SZ', '300551.SZ', '300552.SZ', '300553.SZ', '300554.SZ', '300555.SZ', '300556.SZ', '300557.SZ', '300558.SZ', '300559.SZ', '300560.SZ', '300561.SZ', '300562.SZ', '300563.SZ', '300564.SZ', '300565.SZ', '300566.SZ', '300567.SZ', '300568.SZ', '300569.SZ', '300570.SZ', '300571.SZ', '300572.SZ', '300573.SZ', '300575.SZ', '300576.SZ', '300577.SZ', '300578.SZ', '300579.SZ', '300580.SZ', '300581.SZ', '300582.SZ', '300583.SZ', '300584.SZ', '300585.SZ', '300586.SZ', '300587.SZ', '300588.SZ', '300589.SZ', '300590.SZ', '300591.SZ', '300592.SZ', '300593.SZ', '300594.SZ', '300595.SZ', '300596.SZ', '300597.SZ', '300598.SZ', '300599.SZ', '300600.SZ', '300601.SZ', '300602.SZ', '300603.SZ', '300604.SZ', '300605.SZ', '300606.SZ', '300607.SZ', '300608.SZ', '300609.SZ', '300610.SZ', '300611.SZ', '300612.SZ', '300613.SZ', '300614.SZ', '300615.SZ', '300616.SZ', '300617.SZ', '300618.SZ', '300619.SZ', '300620.SZ', '300621.SZ', '300622.SZ', '300623.SZ', '300624.SZ', '300625.SZ', '300626.SZ', '300627.SZ', '300628.SZ', '300629.SZ', '300630.SZ', '300631.SZ', '300632.SZ', '300633.SZ', '300634.SZ', '300635.SZ', '300636.SZ', '300637.SZ', '300638.SZ', '300639.SZ', '300640.SZ', '300641.SZ', '300642.SZ', '300643.SZ', '300644.SZ', '300645.SZ', '300647.SZ', '300648.SZ', '300649.SZ', '300650.SZ', '300651.SZ', '300652.SZ', '300653.SZ', '300654.SZ', '300655.SZ', '300656.SZ', '300657.SZ', '300658.SZ', '300659.SZ', '300660.SZ', '300661.SZ', '300662.SZ', '300663.SZ', '300664.SZ', '300665.SZ', '300666.SZ', '300667.SZ', '300668.SZ', '300669.SZ', '300670.SZ', '300671.SZ', '300672.SZ', '300673.SZ', '300674.SZ', '300675.SZ', '300676.SZ', '300677.SZ', '300678.SZ', '300679.SZ', '300680.SZ', '300681.SZ', '300682.SZ', '300683.SZ', '300684.SZ', '300685.SZ', '300686.SZ', '300687.SZ', '300688.SZ', '300689.SZ', '300690.SZ', '300691.SZ', '300692.SZ', '300693.SZ', '300694.SZ', '300695.SZ', '300696.SZ', '300697.SZ', '300698.SZ', '300699.SZ', '300700.SZ', '300701.SZ', '300702.SZ', '300703.SZ', '300705.SZ', '300706.SZ', '300707.SZ', '300708.SZ', '300709.SZ', '300710.SZ', '300711.SZ', '300712.SZ', '300713.SZ', '300715.SZ', '300716.SZ', '300717.SZ', '300718.SZ', '300719.SZ', '300720.SZ', '300721.SZ', '300722.SZ', '300723.SZ', '300724.SZ', '300725.SZ', '300726.SZ', '300727.SZ', '300729.SZ', '300730.SZ', '300731.SZ', '300732.SZ', '300733.SZ', '300735.SZ', '300736.SZ', '300737.SZ', '300738.SZ', '300739.SZ', '300740.SZ', '300741.SZ', '300743.SZ', '300745.SZ', '300746.SZ', '300747.SZ', '300748.SZ', '300749.SZ', '300750.SZ', '300751.SZ', '300752.SZ', '300753.SZ', '300755.SZ', '300756.SZ', '300757.SZ', '300758.SZ', '300759.SZ', '300760.SZ', '300761.SZ', '300762.SZ', '300763.SZ', '300765.SZ', '300766.SZ', '300767.SZ', '300768.SZ', '300769.SZ', '300770.SZ', '300771.SZ', '300772.SZ', '300773.SZ', '300774.SZ', '300775.SZ', '300776.SZ', '300777.SZ', '300778.SZ', '300779.SZ', '300780.SZ', '300781.SZ', '300782.SZ', '300783.SZ', '300784.SZ', '300785.SZ', '300786.SZ', '300787.SZ', '300788.SZ', '300789.SZ', '300790.SZ', '300791.SZ', '300792.SZ', '300793.SZ', '300795.SZ', '300796.SZ', '300797.SZ', '300798.SZ', '300800.SZ', '300801.SZ', '300802.SZ', '300803.SZ', '300804.SZ', '300805.SZ', '300806.SZ', '300807.SZ', '300808.SZ', '300809.SZ', '300810.SZ', '300811.SZ', '300812.SZ', '300813.SZ', '300814.SZ', '300815.SZ', '300816.SZ', '300817.SZ', '300818.SZ', '300819.SZ', '300820.SZ', '300821.SZ', '300822.SZ', '300823.SZ', '300824.SZ', '300825.SZ', '300826.SZ', '300827.SZ', '300828.SZ', '300829.SZ', '300830.SZ', '300831.SZ', '300832.SZ', '300833.SZ', '300834.SZ', '300835.SZ', '300836.SZ', '300837.SZ', '300838.SZ', '300839.SZ', '300840.SZ', '300841.SZ', '300842.SZ', '300843.SZ', '300844.SZ', '300845.SZ', '300846.SZ', '300847.SZ', '300848.SZ', '300849.SZ', '300850.SZ', '300851.SZ', '300852.SZ', '300853.SZ', '300854.SZ', '300855.SZ', '300856.SZ', '300857.SZ', '300858.SZ', '300859.SZ', '300860.SZ', '300861.SZ', '300862.SZ', '300863.SZ', '300864.SZ', '300865.SZ', '300866.SZ', '300867.SZ', '300868.SZ', '300869.SZ', '300870.SZ', '300871.SZ', '300872.SZ', '300873.SZ', '300875.SZ', '300876.SZ', '300877.SZ', '300878.SZ', '300879.SZ', '300880.SZ', '300881.SZ', '300882.SZ', '300883.SZ', '300884.SZ', '300885.SZ', '300886.SZ', '300887.SZ', '300888.SZ', '300889.SZ', '300890.SZ', '300891.SZ', '300892.SZ', '300893.SZ', '300894.SZ', '300895.SZ', '300896.SZ', '300897.SZ', '300898.SZ', '300899.SZ', '300900.SZ', '300901.SZ', '300902.SZ', '300903.SZ', '300904.SZ', '300905.SZ', '300906.SZ', '300907.SZ', '300908.SZ', '300909.SZ', '300910.SZ', '300911.SZ', '300912.SZ', '300913.SZ', '300915.SZ', '300916.SZ', '300917.SZ', '300918.SZ', '300919.SZ', '300920.SZ', '300921.SZ', '300922.SZ', '300923.SZ', '300925.SZ', '300926.SZ', '300927.SZ', '300928.SZ', '300929.SZ', '300930.SZ', '300931.SZ', '300932.SZ', '300933.SZ', '300935.SZ', '300936.SZ', '300937.SZ', '300938.SZ', '300939.SZ', '300940.SZ', '300941.SZ', '300942.SZ', '300943.SZ', '300945.SZ', '300946.SZ', '300947.SZ', '300948.SZ', '300949.SZ', '300950.SZ', '300951.SZ', '300952.SZ', '300953.SZ', '300955.SZ', '300956.SZ', '300957.SZ', '300958.SZ', '300959.SZ', '300960.SZ', '300961.SZ', '300962.SZ', '300963.SZ', '300964.SZ', '300965.SZ', '300966.SZ', '300967.SZ', '300968.SZ', '300969.SZ', '300970.SZ', '300971.SZ', '300972.SZ', '300973.SZ', '300975.SZ', '300976.SZ', '300977.SZ', '300978.SZ', '300979.SZ', '300980.SZ', '300981.SZ', '300982.SZ', '300983.SZ', '300984.SZ', '300985.SZ', '300986.SZ', '300987.SZ', '300988.SZ', '300989.SZ', '300990.SZ', '300991.SZ', '300992.SZ', '300993.SZ', '300994.SZ', '300995.SZ', '300996.SZ', '300997.SZ', '300998.SZ', '300999.SZ', '301000.SZ', '301001.SZ', '301002.SZ', '301003.SZ', '301004.SZ', '301005.SZ', '301006.SZ', '301007.SZ', '301008.SZ', '301009.SZ', '301010.SZ', '301011.SZ', '301012.SZ', '301013.SZ', '301015.SZ', '301016.SZ', '301017.SZ', '301018.SZ', '301019.SZ', '301020.SZ', '301021.SZ', '301022.SZ', '301023.SZ', '301024.SZ', '301025.SZ', '301026.SZ', '301027.SZ', '301028.SZ', '301029.SZ', '301030.SZ', '301031.SZ', '301032.SZ', '301033.SZ', '301035.SZ', '301036.SZ', '301037.SZ', '301038.SZ', '301039.SZ', '301040.SZ', '301041.SZ', '301042.SZ', '301043.SZ', '301045.SZ', '301046.SZ', '301047.SZ', '301048.SZ', '301049.SZ', '301050.SZ', '301051.SZ', '301052.SZ', '301053.SZ', '301055.SZ', '301056.SZ', '301057.SZ', '301058.SZ', '301059.SZ', '301060.SZ', '301061.SZ', '301062.SZ', '301063.SZ', '301065.SZ', '301066.SZ', '301067.SZ', '301068.SZ', '301069.SZ', '301070.SZ', '301071.SZ', '301072.SZ', '301073.SZ', '301075.SZ', '301076.SZ', '301077.SZ', '301078.SZ', '301079.SZ', '301080.SZ', '301081.SZ', '301082.SZ', '301083.SZ', '301085.SZ', '301086.SZ', '301087.SZ', '301088.SZ', '301089.SZ', '301090.SZ', '301091.SZ', '301092.SZ', '301093.SZ', '301095.SZ', '301096.SZ', '301097.SZ', '301098.SZ', '301099.SZ', '301100.SZ', '301101.SZ', '301102.SZ', '301103.SZ', '301105.SZ', '301106.SZ', '301107.SZ', '301108.SZ', '301109.SZ', '301110.SZ', '301111.SZ', '301112.SZ', '301113.SZ', '301115.SZ', '301116.SZ', '301117.SZ', '301118.SZ', '301119.SZ', '301120.SZ', '301121.SZ', '301122.SZ', '301123.SZ', '301125.SZ', '301126.SZ', '301127.SZ', '301128.SZ', '301129.SZ', '301130.SZ', '301131.SZ', '301132.SZ', '301133.SZ', '301135.SZ', '301136.SZ', '301137.SZ', '301138.SZ', '301139.SZ', '301141.SZ', '301148.SZ', '301149.SZ', '301150.SZ', '301151.SZ', '301152.SZ', '301153.SZ', '301155.SZ', '301156.SZ', '301157.SZ', '301158.SZ', '301159.SZ', '301160.SZ', '301161.SZ', '301162.SZ', '301163.SZ', '301165.SZ', '301166.SZ', '301167.SZ', '301168.SZ', '301169.SZ', '301170.SZ', '301171.SZ', '301172.SZ', '301173.SZ', '301175.SZ', '301176.SZ', '301177.SZ', '301178.SZ', '301179.SZ', '301180.SZ', '301181.SZ', '301182.SZ', '301183.SZ', '301185.SZ', '301186.SZ', '301187.SZ', '301188.SZ', '301189.SZ', '301190.SZ', '301191.SZ', '301192.SZ', '301193.SZ', '301195.SZ', '301196.SZ', '301197.SZ', '301198.SZ', '301199.SZ', '301200.SZ', '301201.SZ', '301202.SZ', '301203.SZ', '301205.SZ', '301206.SZ', '301207.SZ', '301208.SZ', '301209.SZ', '301210.SZ', '301211.SZ', '301212.SZ', '301213.SZ', '301215.SZ', '301216.SZ', '301217.SZ', '301218.SZ', '301219.SZ', '301220.SZ', '301221.SZ', '301222.SZ', '301223.SZ', '301225.SZ', '301226.SZ', '301227.SZ', '301228.SZ', '301229.SZ', '301230.SZ', '301231.SZ', '301232.SZ', '301233.SZ', '301234.SZ', '301235.SZ', '301236.SZ', '301237.SZ', '301238.SZ', '301239.SZ', '301246.SZ', '301248.SZ', '301251.SZ', '301252.SZ', '301255.SZ', '301256.SZ', '301257.SZ', '301258.SZ', '301259.SZ', '301260.SZ', '301261.SZ', '301262.SZ', '301263.SZ', '301265.SZ', '301266.SZ', '301267.SZ', '301268.SZ', '301269.SZ', '301270.SZ', '301272.SZ', '301273.SZ', '301275.SZ', '301276.SZ', '301277.SZ', '301278.SZ', '301279.SZ', '301280.SZ', '301281.SZ', '301282.SZ', '301283.SZ', '301285.SZ', '301286.SZ', '301287.SZ', '301288.SZ', '301289.SZ', '301290.SZ', '301291.SZ', '301292.SZ', '301293.SZ', '301295.SZ', '301296.SZ', '301297.SZ', '301298.SZ', '301299.SZ', '301300.SZ', '301301.SZ', '301302.SZ', '301303.SZ', '301305.SZ', '301306.SZ', '301307.SZ', '301308.SZ', '301309.SZ', '301310.SZ', '301311.SZ', '301312.SZ', '301313.SZ', '301314.SZ', '301315.SZ', '301316.SZ', '301317.SZ', '301318.SZ', '301319.SZ', '301320.SZ', '301321.SZ', '301322.SZ', '301323.SZ', '301325.SZ', '301326.SZ', '301327.SZ', '301328.SZ', '301329.SZ', '301330.SZ', '301331.SZ', '301332.SZ', '301333.SZ', '301335.SZ', '301336.SZ', '3013
ptrade python最新版本支持3.11
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 980 次浏览 • 2025-02-27 17:42
国金证券 PTRADE智能策略交易终端预期3月底4月中做实盘版本升级。
操作手册和开发手册请登录测试客户端后点击右上角帮助和量化菜单下帮助获取。
量化接口升级说明下载链接:https:/pan.baidu.com/s/1S5xXHpOLFVDYdJrOgYDBqA 提取码:gjz9。
本次主干版本升级涉及的问题修复、功能优化和需求实现较多,策略量化AP变动较大,python版本升级311。
如您有在运行的策略程序、工具功能等,请务必进行测试环境验证调整,确认策略程序在python311环境、工具功能等可正常运行。
实盘确认升级完成后,您需要将测试环境验证后策略迁移实盘后重新启用。
如您需新开通测试环境账户,可与我司服务老师联系获取。感谢各位长期以来对我公司的信任和支持,由此给各位带来的不便敬请谅解。谢谢!
需要开通的可以联系: 查看全部
国金证券 PTRADE智能策略交易终端预期3月底4月中做实盘版本升级。
操作手册和开发手册请登录测试客户端后点击右上角帮助和量化菜单下帮助获取。
量化接口升级说明下载链接:https:/pan.baidu.com/s/1S5xXHpOLFVDYdJrOgYDBqA 提取码:gjz9。
本次主干版本升级涉及的问题修复、功能优化和需求实现较多,策略量化AP变动较大,python版本升级311。
如您有在运行的策略程序、工具功能等,请务必进行测试环境验证调整,确认策略程序在python311环境、工具功能等可正常运行。
实盘确认升级完成后,您需要将测试环境验证后策略迁移实盘后重新启用。
如您需新开通测试环境账户,可与我司服务老师联系获取。感谢各位长期以来对我公司的信任和支持,由此给各位带来的不便敬请谅解。谢谢!

需要开通的可以联系:
Grok3对比国内的AI应用,效果差得很远,举例豆包
AI应用 • 李魔佛 发表了文章 • 0 个评论 • 721 次浏览 • 2025-02-21 12:56
有A的期权是啥意思。
就是这种带A后缀的期权。
然后我们看看Grok3的回答
这个就不是正确答案。胡扯,担心死因为联网搜索,搜索到垃圾信息,于是我也把它的联网搜索功能去掉,依然是得出的垃圾结果。
再看看豆包的回复:
正确答案。
不知道为啥那么多人在说grok3好,实在费解。
查看全部
有A的期权是啥意思。

就是这种带A后缀的期权。
然后我们看看Grok3的回答

这个就不是正确答案。胡扯,担心死因为联网搜索,搜索到垃圾信息,于是我也把它的联网搜索功能去掉,依然是得出的垃圾结果。
再看看豆包的回复:

正确答案。
不知道为啥那么多人在说grok3好,实在费解。
QMT获取北交所市场代码
QMT • 李魔佛 发表了文章 • 0 个评论 • 657 次浏览 • 2025-02-21 11:30
现在的券商只要你开了科创板,可以直接开通北交所,不再需要20交易日,50w的要求。
QMT获取北交所代码:
运行输出结果:
需要开通量化api权限的券商,可以扫码关注并咨询 查看全部
现在的券商只要你开了科创板,可以直接开通北交所,不再需要20交易日,50w的要求。
QMT获取北交所代码:

运行输出结果:

需要开通量化api权限的券商,可以扫码关注并咨询
ptrade支持外网,mysql 远程数据库的券商
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 811 次浏览 • 2025-02-17 14:16
比如如果你要获取可转债的一些强赎数据,内置数据是不支持的。
那么如果你想要获取集思录的数据,那么就会无能为力。
不过有一个券商可以支持访问外部数据的。因为ptrade内置了pymysq,redis,zeromq,wsocket等第三方库,
所以你可以在ptrade内部,直接范围mysql的数据,zeromq的数据,甚至直接和外部的api进行双向通信。
实例中直接用requests访问的百度
实盘,模拟盘中均可操作。
需要开通的朋友可以公众号联系:
费率也支持万0.854 免5哦~ 查看全部
比如如果你要获取可转债的一些强赎数据,内置数据是不支持的。
那么如果你想要获取集思录的数据,那么就会无能为力。
不过有一个券商可以支持访问外部数据的。因为ptrade内置了pymysq,redis,zeromq,wsocket等第三方库,
所以你可以在ptrade内部,直接范围mysql的数据,zeromq的数据,甚至直接和外部的api进行双向通信。
实例中直接用requests访问的百度
实盘,模拟盘中均可操作。
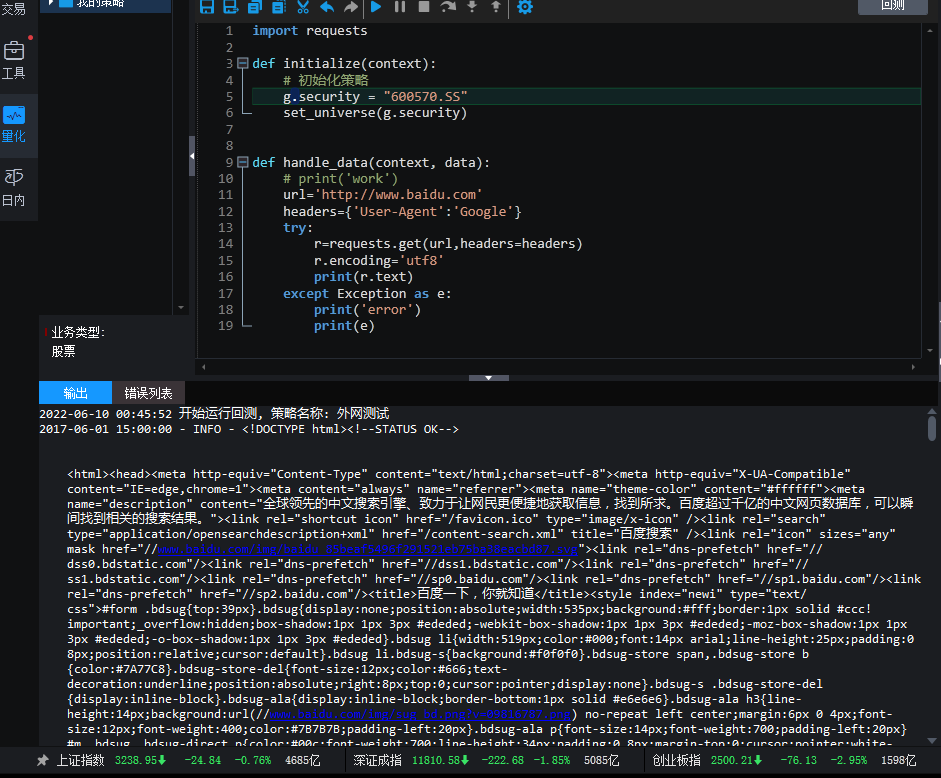
需要开通的朋友可以公众号联系:
费率也支持万0.854 免5哦~
用fofa+python搜索别人部署的deepseek服务器,白嫖!
AI应用 • 李魔佛 发表了文章 • 0 个评论 • 667 次浏览 • 2025-02-13 12:59
然后用vs code插件,添加自动cline 自动化写代码。
能用,而且速度也挺快!

然后用vs code插件,添加自动cline 自动化写代码。
能用,而且速度也挺快!

本地部署deepseek的api,用于vs code cline,但无法项目自动创建文件
AI应用 • 李魔佛 发表了文章 • 0 个评论 • 1744 次浏览 • 2025-02-13 12:19
但无法生成文件,
其实是无法理解命令输出
具体错误提示如下:
Cline is having trouble...
Cline uses complex prompts and iterative task execution that may be challenging for less capable models. For best results, it's recommended to use Claude 3.5 Sonnet for its advanced agentic coding capabilities.
其实是模型不支持,需要用tool use类的模型。
比如:deepseek-r1-coder-tools:32b
地址:https://ollama.com/ishumilin/deepseek-r1-coder-tools:32b
然后就正常了。
查看全部

但无法生成文件,
其实是无法理解命令输出
具体错误提示如下:
Cline is having trouble...
Cline uses complex prompts and iterative task execution that may be challenging for less capable models. For best results, it's recommended to use Claude 3.5 Sonnet for its advanced agentic coding capabilities.
其实是模型不支持,需要用tool use类的模型。
比如:deepseek-r1-coder-tools:32b
地址:https://ollama.com/ishumilin/deepseek-r1-coder-tools:32b
然后就正常了。
江海证券支持QMT,miniQMT,且低门槛开通
QMT • 李魔佛 发表了文章 • 0 个评论 • 1302 次浏览 • 2025-02-12 00:46
江海证券有限公司于2003年12月15日在哈尔滨市市场监督管理局登记成立。法定代表人孙名扬,公司经营范围包括证券经纪,证券承销与保荐,证券投资咨询,证券自营等。
这logo看起来有点像银河呢。
江海证券现有分支机构75家,其中17家分公司,58家营业部,遍布北京、上海、广州、深圳、厦门、青岛、大连、成都、武汉、长沙、合肥及黑龙江省内等主要城市,形成了“覆盖龙江、辐射沿海、布局全国”的业务发展格局。
不过上面的是2018年的数据,最新的可能会少一些。因为现在很多营业部都更加注重线上业务。也就是通过线上就可以开通账号。
目前江海证券能够开通量化QMT,和miniQMT的自动化交易权限。
下载地址:
江海证券QMT实盘_实盘_1.0.0.36190.exe
或者直接到官网:
https://www.jhzq.com.cn/main/home/software/index.shtml
选择QMT下载即可
江海证券也支持无限易量化平台。
需要的可以咨询公众号: 查看全部
江海证券有限公司于2003年12月15日在哈尔滨市市场监督管理局登记成立。法定代表人孙名扬,公司经营范围包括证券经纪,证券承销与保荐,证券投资咨询,证券自营等。

这logo看起来有点像银河呢。
江海证券现有分支机构75家,其中17家分公司,58家营业部,遍布北京、上海、广州、深圳、厦门、青岛、大连、成都、武汉、长沙、合肥及黑龙江省内等主要城市,形成了“覆盖龙江、辐射沿海、布局全国”的业务发展格局。
不过上面的是2018年的数据,最新的可能会少一些。因为现在很多营业部都更加注重线上业务。也就是通过线上就可以开通账号。
目前江海证券能够开通量化QMT,和miniQMT的自动化交易权限。

下载地址:
江海证券QMT实盘_实盘_1.0.0.36190.exe
或者直接到官网:
https://www.jhzq.com.cn/main/home/software/index.shtml
选择QMT下载即可
江海证券也支持无限易量化平台。
需要的可以咨询公众号:
deepseek等一众AI预测港股古茗翻车
AI应用 • 李魔佛 发表了文章 • 0 个评论 • 594 次浏览 • 2025-02-12 00:41
今天暗盘交易,结果就打脸了,古茗在几个平台都是10%涨幅收盘的。
投资里面涉及到各种的因子,包括情绪,有的因子是我们事后才感知的,
而AI事前并不能完全感知所以因素,如当前打新行情火热,AI并没有考虑此因子,只是考虑了基石投资者,保荐机构,横向对比同行业的奈雪,茶百道等同行,推断出此次不值得申购。
投资是一群人的博弈游戏,如果根据AI平台得出的意见想法都趋同一致,
对于同一标的都看好,或者都不看好,大家都去追捧,可能会被顶到涨停;大家都抛弃,可能没有买量躺在跌停板。
显然,AI时代,需要投资者更异于常人的逆向思维能力。 查看全部
今天暗盘交易,结果就打脸了,古茗在几个平台都是10%涨幅收盘的。

投资里面涉及到各种的因子,包括情绪,有的因子是我们事后才感知的,
而AI事前并不能完全感知所以因素,如当前打新行情火热,AI并没有考虑此因子,只是考虑了基石投资者,保荐机构,横向对比同行业的奈雪,茶百道等同行,推断出此次不值得申购。
投资是一群人的博弈游戏,如果根据AI平台得出的意见想法都趋同一致,
对于同一标的都看好,或者都不看好,大家都去追捧,可能会被顶到涨停;大家都抛弃,可能没有买量躺在跌停板。
显然,AI时代,需要投资者更异于常人的逆向思维能力。
港股新股 古茗 是否申购,问一问deepseek, chatGPT-4o, kimi, 元宝AI,谁最厉害
AI应用 • 李魔佛 发表了文章 • 0 个评论 • 773 次浏览 • 2025-02-06 17:44
古茗是行业领先、快速增长的中国现制饮品企业。按 2023 年的 GMV 及门店数量计,是中国最大的大众现制茶饮店品牌,也是全价格带下中国第二大现制茶饮品牌,市场份额约为 18%。
目前市场申购倍数为12倍,热度一般。
假设我们都是港股打新小白,零经验。那么我们来问问,目前市场几个主流的AI平台,对于这个新股,能否申购给出一个结论。
参赛选手有Deepseek-R1,chatGPT-4o,kimi,腾讯元宝AI
Deepseek-R1
首先是当下风头最热的Deepseek-R1
我们问的问题是:古茗IPO港股打新,要不要申购?
下面是它的分析结果:
Deepseek回答结果
Deepseek回答结论
最后它给出的结论是:
基本面稳健但估值偏高,短期上涨空间有限,需权衡市场情绪与风险。对于打新套利者,性价比不高;
chatGPT 4o
同样勾上搜索功能,使其可以分析当下的互联网实时内容。
chatgpt 4ochatGPT-4o的回复有点打太极的意思,“
是否申购古茗新股因根据您的风险承受能力与投资目标进行评估”,分析资料不如Deepseek丰富,最后的结论属于正确的废话,有点在应付敷衍我的意思。
kimi
刚开始出来的时候,kimi以其联网搜索分析功能著称,所以这里也试问一下,看看kimi的效果。
kimikimi分析过程也是很有条理,分别列出了有利因素和不利因素。
最后的结论是是偏向于谨慎对待,也就是不太建议大额资金去申购。
腾讯AI 元宝
在前面几个AI平台里面腾讯AI元宝的知名度最低。
不过考虑到腾讯系的AI平台,使用各大公众号自媒体的数据进行建模,语料会更为丰富一下,所以也纳入测试范围。
腾讯元宝
腾讯元宝它的分析过程没有Deepseek和kimi面面俱到,只分析了Deepseek和kimi里的某一部分因素。
最后它给出的结论也是:考虑到当前市场环境和古茗的具体情况,建议投资者谨慎申购。偏向于谨慎申购。
于是,笔者我看完上面的这些AI分析文章,觉得还是不申购这个古茗港股新股了。因为看完它们的描述,会发现奈雪,茶百道,这几家已经在港股上市的,无论上市首日还是后续的交易日,也都跌跌不休,更别说这个我没听过的古茗奶茶了….
比较出乎意外的是,chatGPT-4o的结果反而是这4个AI平台里最简陋,且信息量最低的,感慨..
仅从这次提问体验进行排序,deepseek > kimi > 元宝AI > chatGPT-4o
查看全部

古茗新股申购港股新股古茗4号开始申购。
古茗是行业领先、快速增长的中国现制饮品企业。按 2023 年的 GMV 及门店数量计,是中国最大的大众现制茶饮店品牌,也是全价格带下中国第二大现制茶饮品牌,市场份额约为 18%。
目前市场申购倍数为12倍,热度一般。
假设我们都是港股打新小白,零经验。那么我们来问问,目前市场几个主流的AI平台,对于这个新股,能否申购给出一个结论。
参赛选手有Deepseek-R1,chatGPT-4o,kimi,腾讯元宝AI
Deepseek-R1
首先是当下风头最热的Deepseek-R1
我们问的问题是:古茗IPO港股打新,要不要申购?
下面是它的分析结果:

Deepseek回答结果


Deepseek回答结论
最后它给出的结论是:
基本面稳健但估值偏高,短期上涨空间有限,需权衡市场情绪与风险。对于打新套利者,性价比不高;
chatGPT 4o
同样勾上搜索功能,使其可以分析当下的互联网实时内容。

chatgpt 4ochatGPT-4o的回复有点打太极的意思,“
是否申购古茗新股因根据您的风险承受能力与投资目标进行评估”,分析资料不如Deepseek丰富,最后的结论属于正确的废话,有点在应付敷衍我的意思。
kimi
刚开始出来的时候,kimi以其联网搜索分析功能著称,所以这里也试问一下,看看kimi的效果。

kimikimi分析过程也是很有条理,分别列出了有利因素和不利因素。
最后的结论是是偏向于谨慎对待,也就是不太建议大额资金去申购。
腾讯AI 元宝
在前面几个AI平台里面腾讯AI元宝的知名度最低。
不过考虑到腾讯系的AI平台,使用各大公众号自媒体的数据进行建模,语料会更为丰富一下,所以也纳入测试范围。

腾讯元宝

腾讯元宝它的分析过程没有Deepseek和kimi面面俱到,只分析了Deepseek和kimi里的某一部分因素。
最后它给出的结论也是:考虑到当前市场环境和古茗的具体情况,建议投资者谨慎申购。偏向于谨慎申购。
于是,笔者我看完上面的这些AI分析文章,觉得还是不申购这个古茗港股新股了。因为看完它们的描述,会发现奈雪,茶百道,这几家已经在港股上市的,无论上市首日还是后续的交易日,也都跌跌不休,更别说这个我没听过的古茗奶茶了….
比较出乎意外的是,chatGPT-4o的结果反而是这4个AI平台里最简陋,且信息量最低的,感慨..
仅从这次提问体验进行排序,deepseek > kimi > 元宝AI > chatGPT-4o
聚宽打板策略代码转为ptrade代码
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1343 次浏览 • 2025-02-02 17:42
根据昨日涨停 或最近N天的股票出现连板的数量,然后选股。
高开X之后进入股票池。
然后加入均线,热度,板块等因子,盘中买入。
PS: 现在的ptrade回测速度是越来越慢的了。 估计是用户越来越多的缘故了。。。
比我刚开始用的那个时候,简直慢了有100倍.....
查看全部
根据昨日涨停 或最近N天的股票出现连板的数量,然后选股。
高开X之后进入股票池。
然后加入均线,热度,板块等因子,盘中买入。

PS: 现在的ptrade回测速度是越来越慢的了。 估计是用户越来越多的缘故了。。。
比我刚开始用的那个时候,简直慢了有100倍.....
ptrade一个策略里可以同时执行多少个run_daily?
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1021 次浏览 • 2025-01-17 10:28
run_daily 可以在0-24小时都能够执行,并没有限制要求交易时间09:30到15:00.
因此如果需要执行集合竞价的部分,那么就需要用run_daily 去操作了。
比如开盘打新,尾盘逆回购,
而ptrade里面也对run_daily做了限制,就是一个策略里面同时只能设置5个run_daily
对于一般人而已,应该够用的了。如果不够,那么就用handle_data处理,也是可以。handle_data,里面可以加一个时间判断的语句,那么你可以一天在指定时间执行多少个任务都没有问题,随意突破5个。
更多技术问题,可以关注公众号:可转债量化分析 查看全部
run_daily 可以在0-24小时都能够执行,并没有限制要求交易时间09:30到15:00.
因此如果需要执行集合竞价的部分,那么就需要用run_daily 去操作了。
比如开盘打新,尾盘逆回购,

而ptrade里面也对run_daily做了限制,就是一个策略里面同时只能设置5个run_daily
对于一般人而已,应该够用的了。如果不够,那么就用handle_data处理,也是可以。handle_data,里面可以加一个时间判断的语句,那么你可以一天在指定时间执行多少个任务都没有问题,随意突破5个。
更多技术问题,可以关注公众号:可转债量化分析
不同券商的ptrade实盘客户端的回测时间
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1633 次浏览 • 2024-12-03 15:41
而券商的实盘客户端的回测时间会有做限制。
1. 国金:实盘客户端不允许回测。
2. 国盛:实盘客户端回测时间为收盘后15:30之后
3. 湘财:实盘客户端回测时间为收盘后15:30之后
需要开通量化账号的读者朋友,可以关注公众号:
查看全部
而券商的实盘客户端的回测时间会有做限制。
1. 国金:实盘客户端不允许回测。
2. 国盛:实盘客户端回测时间为收盘后15:30之后
3. 湘财:实盘客户端回测时间为收盘后15:30之后
需要开通量化账号的读者朋友,可以关注公众号:
python django3 跨域问题解决
python • 李魔佛 发表了文章 • 0 个评论 • 1148 次浏览 • 2024-11-22 11:53
然后react范围django api,会有跨域问题,所以需要额外配置一下。
网上很多教程都是基于最新的django4或者更新。
本文只针对django3 解决。
如果用的django3.10
需要对应的版本的cors库:
pip install django-cors-headers==3.10.0不然大概率是装不上的。
然后在setting里面配置这个
CORS_ORIGIN_ALLOW_ALL = True
INSTALLED_APPS = [
'corsheaders',
]
MIDDLEWARE = [
'corsheaders.middleware.CorsMiddleware',
]
然后就OK了。
如果需要更加细致的配置,比如只要求某个IP的机子才能访问,或者只能某个GET方法运行跨域。
# 允许跨域源
CORS_ORIGIN_ALLOW_ALL = True
CORS_ALLOW_CREDENTIALS = True
CORS_ORIGIN_WHITELIST = (
'*'
)
# 允许的请求方式
CORS_ALLOW_METHODS = (
'DELETE',
'GET',
'OPTIONS',
'PATCH',
'POST',
'PUT',
'VIEW',
)
# 允许的请求头
CORS_ALLOW_HEADERS = (
'XMLHttpRequest',
'X_FILENAME',
'accept-encoding',
'authorization',
'content-type',
'dnt',
'origin',
'user-agent',
'x-csrftoken',
'x-requested-with',
'Pragma',
# 额外允许的请求头
'token',
)
就可以了 查看全部
然后react范围django api,会有跨域问题,所以需要额外配置一下。
网上很多教程都是基于最新的django4或者更新。
本文只针对django3 解决。
如果用的django3.10不然大概率是装不上的。
需要对应的版本的cors库:
pip install django-cors-headers==3.10.0
然后在setting里面配置这个
然后就OK了。
CORS_ORIGIN_ALLOW_ALL = True
INSTALLED_APPS = [
'corsheaders',
]
MIDDLEWARE = [
'corsheaders.middleware.CorsMiddleware',
]
如果需要更加细致的配置,比如只要求某个IP的机子才能访问,或者只能某个GET方法运行跨域。
# 允许跨域源
CORS_ORIGIN_ALLOW_ALL = True
CORS_ALLOW_CREDENTIALS = True
CORS_ORIGIN_WHITELIST = (
'*'
)
# 允许的请求方式
CORS_ALLOW_METHODS = (
'DELETE',
'GET',
'OPTIONS',
'PATCH',
'POST',
'PUT',
'VIEW',
)
# 允许的请求头
CORS_ALLOW_HEADERS = (
'XMLHttpRequest',
'X_FILENAME',
'accept-encoding',
'authorization',
'content-type',
'dnt',
'origin',
'user-agent',
'x-csrftoken',
'x-requested-with',
'Pragma',
# 额外允许的请求头
'token',
)
就可以了
ptrade上的get_cb_info函数无法使用
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1126 次浏览 • 2024-11-20 10:32
def initialize(context):
pass
def handle_data(context, data):
df = get_cb_info()
log.info(df)
最后跑出来的结果如下:
2024-11-20 10:22:00 - ERROR - 用户策略执行异常
2024-11-20 10:22:00 - ERROR - Exception: Traceback (most recent call last):
File /home/fly/sim_backtest/result/29fa7074-a6e6-11ef-b05b-c40778d9af27/user_strategy.py, line 6 in handle_data
df = get_cb_info()
--> data = BarDict(600570.SS)
--> context = <StrategyContext {'recorded_vars': {}, 'commission': <Commission {'cost': 0.0003, 'min_trade_cost': 5.0, 'tax': 0.001}>, 'blotter': <Blotter {'current_dt': date ...
NameError: name 'get_cb_info' is not defined
说明这个函数就根本没有做进去了。
目前我试的券商,国盛ptrade是无法使用的。
所以如果需要获取可转债的数据,需要自己写一个接口获取。我之前的很多文章里面也有写过类似的api接口。可以参考参考。
查看全部
def initialize(context):
pass
def handle_data(context, data):
df = get_cb_info()
log.info(df)
最后跑出来的结果如下:
2024-11-20 10:22:00 - ERROR - 用户策略执行异常
2024-11-20 10:22:00 - ERROR - Exception: Traceback (most recent call last):
File /home/fly/sim_backtest/result/29fa7074-a6e6-11ef-b05b-c40778d9af27/user_strategy.py, line 6 in handle_data
df = get_cb_info()
--> data = BarDict(600570.SS)
--> context = <StrategyContext {'recorded_vars': {}, 'commission': <Commission {'cost': 0.0003, 'min_trade_cost': 5.0, 'tax': 0.001}>, 'blotter': <Blotter {'current_dt': date ...
NameError: name 'get_cb_info' is not defined
说明这个函数就根本没有做进去了。
目前我试的券商,国盛ptrade是无法使用的。
所以如果需要获取可转债的数据,需要自己写一个接口获取。我之前的很多文章里面也有写过类似的api接口。可以参考参考。
QMT获取市场可转债代码
可转债 • 李魔佛 发表了文章 • 0 个评论 • 1294 次浏览 • 2024-11-14 11:12
#encoding:gbk
def init(ContextInfo):
pass
def handlebar(ContextInfo):
index = ContextInfo.barpos
realtime = ContextInfo.get_bar_timetag(index)
print(ContextInfo.get_stock_list_in_sector('沪深转债', realtime))
欢迎关注公众号:可转债量化分析 查看全部
#encoding:gbk
def init(ContextInfo):
pass
def handlebar(ContextInfo):
index = ContextInfo.barpos
realtime = ContextInfo.get_bar_timetag(index)
print(ContextInfo.get_stock_list_in_sector('沪深转债', realtime))

欢迎关注公众号:可转债量化分析
ptrade:登录请求失败,服务器状态400
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1054 次浏览 • 2024-11-11 10:03
ptrade:登录请求失败,服务器状态400
用户数多,占用了资源多了,服务器没有扩容,导致资源不够用了。
周一一大早就崩了。
券商ptrade的运营工作人员只能重启。 但不增加资源,不优化隔离资源分配,一旦内存不够,cpu负载占满,全部人一起陪葬,这样好么?
查看全部
ptrade:登录请求失败,服务器状态400

用户数多,占用了资源多了,服务器没有扩容,导致资源不够用了。
周一一大早就崩了。
券商ptrade的运营工作人员只能重启。 但不增加资源,不优化隔离资源分配,一旦内存不够,cpu负载占满,全部人一起陪葬,这样好么?
特朗普和拜登在任期间,上证指数的涨幅是多少?
股票 • 李魔佛 发表了文章 • 0 个评论 • 1086 次浏览 • 2024-11-06 12:31
2017-1-20 - 3123
2021-1-20 - 3583
涨幅为14.7%
而拜登在任期间,截至到今天为止:
2021-1-20 - 3583
2024-11-06 - 3392
涨幅为 -5.3%
#美国大选#
欢迎关注公众号: 查看全部

特朗普上一次在任期间,上证指数的点位:
2017-1-20 - 3123
2021-1-20 - 3583
涨幅为14.7%
而拜登在任期间,截至到今天为止:
2021-1-20 - 3583
2024-11-06 - 3392
涨幅为 -5.3%
#美国大选#
欢迎关注公众号:
oracle免费主机 忘记用户账户和密码,没有ssh private key 怎么恢复登录?
Linux • 李魔佛 发表了文章 • 0 个评论 • 1299 次浏览 • 2024-11-02 00:38
现在已经很难申请到的了,且行且珍惜。
因为太久没有登录oracle的网站,导致账户邮箱都忘记了。不知道是不是被账户被清理了,还是什么原因了。
但云主机的实例还在的。
因为很早之前在本地的电脑上,我一直都是用本地的私钥自动登录的,也不需要用密码。
但,目前也只能在这个电脑上做到自动登录。
以前申请的private key也不知道放到哪里去了。
按照教程因为是
ssh -i /path/to/your/private_key.key ubuntu@your_instance_public_ip
这样导进来的。
关键现在的private_key.key 文件不见了。。。
悲催
于是在本地可以登录oracle的主机上,先登录进去oracle主机上,进入 .ssh 目录,查看 里面的authorized_keys 文件,
里面有一条记录, 就是 但是记录的免密码登录的sha256的记录。
记住这个sha256的值,然后到本地的电脑上的.ssh 里面,找到对应 idXXXX 和 idXXXX.pub 里面的内容要和oracle主机上的sha256
如果找到了,那就恭喜你,你直接复制idXXXX 和 idXXXX.pub 到其他主机 的 .ssh/ 目录 上,然后直接ssh opc@IP,就可以不用任何密码登录oracle的主机了。实现多个本地主机连接到oracle的免费主机上了。
查看全部
现在已经很难申请到的了,且行且珍惜。
因为太久没有登录oracle的网站,导致账户邮箱都忘记了。不知道是不是被账户被清理了,还是什么原因了。
但云主机的实例还在的。
因为很早之前在本地的电脑上,我一直都是用本地的私钥自动登录的,也不需要用密码。
但,目前也只能在这个电脑上做到自动登录。
以前申请的private key也不知道放到哪里去了。
按照教程因为是
ssh -i /path/to/your/private_key.key ubuntu@your_instance_public_ip
这样导进来的。
关键现在的private_key.key 文件不见了。。。
悲催
于是在本地可以登录oracle的主机上,先登录进去oracle主机上,进入 .ssh 目录,查看 里面的authorized_keys 文件,
里面有一条记录, 就是 但是记录的免密码登录的sha256的记录。
记住这个sha256的值,然后到本地的电脑上的.ssh 里面,找到对应 idXXXX 和 idXXXX.pub 里面的内容要和oracle主机上的sha256
如果找到了,那就恭喜你,你直接复制idXXXX 和 idXXXX.pub 到其他主机 的 .ssh/ 目录 上,然后直接ssh opc@IP,就可以不用任何密码登录oracle的主机了。实现多个本地主机连接到oracle的免费主机上了。
Ptrade获取历史涨停的股票|python代码
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 1434 次浏览 • 2024-11-01 18:41
下面的程序用于监控可转债的正股,在过去10天里是否出现涨停。
下面的ptrade的代码片段。需要完整代码,可关注公众号私信获取。
def hit_limit_recent():
# 选出最近N天正股有涨停的可转债
N =10
scale = 5
latest_price = 160
bond_name_dict, bond_zg_dict = get_all_bond_info(scale=scale,latest_price=latest_price)
zg_list = list(bond_zg_dict.values())
panel_info = get_history(N, frequency='1d', field=['close','high_limit'], security_list=zg_list, fq='pre', include=False, fill='nan')
df = panel_info.swapaxes("minor_axis", "items")
target_list = []
for code in zg_list:
stock_df = df[code]
hit_high = stock_df[stock_df['close']==stock_df['high_limit']]
if len(hit_high) > 0:
# print(hit_high.index)
target_list.append(code)
zz_target_list = []
for code,zg_code in bond_zg_dict.items():
if zg_code in target_list:
print(code, bond_name_dict[code])
zz_target_list.append(code)
return zz_target_list当然,会有一个情形,就是实际最后是开板状态,但是收盘价格和涨停价格一样。
这种属于涨停开板状态,需要利用tick的委卖买来判断。
查看全部
下面的程序用于监控可转债的正股,在过去10天里是否出现涨停。
下面的ptrade的代码片段。需要完整代码,可关注公众号私信获取。
def hit_limit_recent():当然,会有一个情形,就是实际最后是开板状态,但是收盘价格和涨停价格一样。
# 选出最近N天正股有涨停的可转债
N =10
scale = 5
latest_price = 160
bond_name_dict, bond_zg_dict = get_all_bond_info(scale=scale,latest_price=latest_price)
zg_list = list(bond_zg_dict.values())
panel_info = get_history(N, frequency='1d', field=['close','high_limit'], security_list=zg_list, fq='pre', include=False, fill='nan')
df = panel_info.swapaxes("minor_axis", "items")
target_list = []
for code in zg_list:
stock_df = df[code]
hit_high = stock_df[stock_df['close']==stock_df['high_limit']]
if len(hit_high) > 0:
# print(hit_high.index)
target_list.append(code)
zz_target_list = []
for code,zg_code in bond_zg_dict.items():
if zg_code in target_list:
print(code, bond_name_dict[code])
zz_target_list.append(code)
return zz_target_list
这种属于涨停开板状态,需要利用tick的委卖买来判断。
可转债不下修名单 - 铁公鸡一览表
可转债 • 李魔佛 发表了文章 • 0 个评论 • 1180 次浏览 • 2024-11-01 08:15
对于笔者而言,建仓标的会选择排除这些公告了不下修的转债,且对应的转股价值低于70-80的转债。
上市公司为何不下修转股价?
摘录网上比较官方的原因:
第一,下修转股价会稀释现有股东的股权,公司不希望现有股东权益被稀释,选择不下修转股价;
第二,公司可能有长期的战略规划,不希望因为短期的财务压力下修转股价而改变资本结构;
第三,下修转股价可能会被市场解读为公司财务状况不佳或未来盈利前景不明朗,公司为了避免这种负面反应而选择不下修转股价。
“上市公司选择不下修转股价,实际上也是在向市场传递公司对股价的信心。” 业内人士表示,公司不下修转股价,一方面说明公司现金流状况良好,有到期偿还负债的意愿;另一方面,公司可能认为当前的转股价已经反映了公司的合理价值,不需要通过下修来吸引投资者。
不下修转债数据更新至2024-10-30日晚。
文末附原始数据获取方法。
省略若干....
后台回复关键字:不下修列表202410 获取原始excel表格数据
因为文章更新并不频繁,微信并不会把最新的公众号文章及时推送在读者最新的列表中,可以将***公众号设为*****星标,这样就能第一时间收到笔者的最新文章啦。**
获取数据不易,喜欢本文的记得点“**赞”和“在看”哦,欢迎转载本文。**
查看全部
对于笔者而言,建仓标的会选择排除这些公告了不下修的转债,且对应的转股价值低于70-80的转债。
上市公司为何不下修转股价?
摘录网上比较官方的原因:
第一,下修转股价会稀释现有股东的股权,公司不希望现有股东权益被稀释,选择不下修转股价;
第二,公司可能有长期的战略规划,不希望因为短期的财务压力下修转股价而改变资本结构;
第三,下修转股价可能会被市场解读为公司财务状况不佳或未来盈利前景不明朗,公司为了避免这种负面反应而选择不下修转股价。
“上市公司选择不下修转股价,实际上也是在向市场传递公司对股价的信心。” 业内人士表示,公司不下修转股价,一方面说明公司现金流状况良好,有到期偿还负债的意愿;另一方面,公司可能认为当前的转股价已经反映了公司的合理价值,不需要通过下修来吸引投资者。
不下修转债数据更新至2024-10-30日晚。
文末附原始数据获取方法。




省略若干....
后台回复关键字:不下修列表202410 获取原始excel表格数据
因为文章更新并不频繁,微信并不会把最新的公众号文章及时推送在读者最新的列表中,可以将***公众号设为*****星标,这样就能第一时间收到笔者的最新文章啦。**
获取数据不易,喜欢本文的记得点“**赞”和“在看”哦,欢迎转载本文。**
