
通知设置 新通知
使用量化程序获取ETF的成分股与实时净值
QMT • 李魔佛 发表了文章 • 0 个评论 • 1870 次浏览 • 2024-04-11 12:22
# coding:gbk
def init(C):
pass
def handlebar(C):
iopv = get_etf_iopv("159928.SZ")
print(f'基金净值为{iopv}')
info = get_etf_info('513520.SH')
print(f'基金申购信息: {info}')
得到的数据如下:
需要开通低门槛量化QMT的朋友,可以扫码关注公众号开通: 查看全部
# coding:gbk
def init(C):
pass
def handlebar(C):
iopv = get_etf_iopv("159928.SZ")
print(f'基金净值为{iopv}')
info = get_etf_info('513520.SH')
print(f'基金申购信息: {info}')
得到的数据如下:

需要开通低门槛量化QMT的朋友,可以扫码关注公众号开通:

QMT回测会跳过当前的周六日和节假日吗
QMT • 李魔佛 发表了文章 • 0 个评论 • 1627 次浏览 • 2024-04-09 13:13
比如回测日期选择 2024年3月28日到2024年4月2日。
其中3月30日和31日是周六日。
下面回测的数据是不执行这两天的数据。从3月30日 15:00的数据,下一个bar就是4月1日09:30了
需要低门槛开通量化QMT,Ptrade,可以扫码联系。
开通后可加入技术交流群。 查看全部
比如回测日期选择 2024年3月28日到2024年4月2日。
其中3月30日和31日是周六日。
下面回测的数据是不执行这两天的数据。从3月30日 15:00的数据,下一个bar就是4月1日09:30了

需要低门槛开通量化QMT,Ptrade,可以扫码联系。
开通后可加入技术交流群。

qmt下载完数据之后,记得重启一次qmt,不然get_market_data_ex依然还是获取不到数据的
QMT • 李魔佛 发表了文章 • 0 个评论 • 1862 次浏览 • 2024-04-01 13:38
qmt下载完数据之后,get_market_data_ex依然还是获取不到数据。
其实主要数据没有刷新。
只需要你手动关闭QMT,再打开一次就好了。
反正呢,这些问题,QMT也不会告诉你,要靠自己摸索了。
欢迎收藏网站哦! 查看全部
qmt下载完数据之后,get_market_data_ex依然还是获取不到数据。
其实主要数据没有刷新。
只需要你手动关闭QMT,再打开一次就好了。

反正呢,这些问题,QMT也不会告诉你,要靠自己摸索了。
欢迎收藏网站哦!
QMT每次自动升级,都会把改过的配置文件给覆盖掉
QMT • 李魔佛 发表了文章 • 0 个评论 • 1735 次浏览 • 2024-03-31 14:23
感觉设计模式有问题。
本来我配置了缩进用的4个空格,(这是pep8的标准好吧)
而qmt默认是用tab做缩进。
导致从vs code或者pycharm上的代码迁移迁移过来qmt的编辑器,你按tab键,是制表符,而不是4个空格。
运行或者回测就会报错。
每次升级都把我的配置给改了。
难道不覆盖config文件不行吗? 每次类似全量升级,一点点bug fix都在全量升级
查看全部
感觉设计模式有问题。
本来我配置了缩进用的4个空格,(这是pep8的标准好吧)
而qmt默认是用tab做缩进。
导致从vs code或者pycharm上的代码迁移迁移过来qmt的编辑器,你按tab键,是制表符,而不是4个空格。
运行或者回测就会报错。

每次升级都把我的配置给改了。
难道不覆盖config文件不行吗? 每次类似全量升级,一点点bug fix都在全量升级
不同券商的数据质量简单对比:国金QMT vs 国信QMT(iquant)
QMT • 李魔佛 发表了文章 • 0 个评论 • 3688 次浏览 • 2024-03-31 11:57
点击打开大图
上面的amount字段(成交额),返回的是0。
看了一下对应的转债,没有停牌,是有正常数据交易的。
然后用国金的QMT记性交叉验证。同样的代码
点击打开大图
国金的是正常的。只是成交量的小数浮点位是不是有点多了? 可能用的numy的默认9位,没有做处理而已。
【在写这个文章的时候发现国信的qmt的volume成交量是有数据的,那么其实可以用价格x成交量=成交额,间接获取成交额,大坑】
点击打开大图
附测试源码:
# coding:gbk
# 公众号:可转债量化分析
DEBUG = True
import time
def get_datetime(ContextInfo):
# 获取当前时间
index = ContextInfo.barpos
realtime = ContextInfo.get_bar_timetag(index)
date = timetag_to_datetime(realtime, "%Y-%m-%d %H:%M:%S")
if DEBUG:
print('当前日期 ', date)
return date
def init(ContextInfo):
print("==============start==========")
ContextInfo.start = '2024-03-27 10:00:00'
ContextInfo.end = '2024-03-29 10:00:00'
#
#ContextInfo.end = '2023-01-05'
#ContextInfo.start = '2023-01-16'
print('init')
def handlebar(ContextInfo):
# 回测的时候不需要
#if not ContextInfo.is_last_bar():
# print('return')
# return
get_datetime(ContextInfo)
print('handlebar')
data = ContextInfo.get_market_data(['quoter'], stock_code = ['123167.SZ'], skip_paused = True, period = 'tick', dividend_type = 'front')
#data = ContextInfo.get_market_data(['close'], stock_code = ['113567.SH'], skip_paused = True, period = '1d', dividend_type = 'front')
#print(type(data))
print(data)
def stop(ContextInfo):
print( 'strategy is stop !') 查看全部
点击打开大图

上面的amount字段(成交额),返回的是0。
看了一下对应的转债,没有停牌,是有正常数据交易的。
然后用国金的QMT记性交叉验证。同样的代码
点击打开大图

国金的是正常的。只是成交量的小数浮点位是不是有点多了? 可能用的numy的默认9位,没有做处理而已。
【在写这个文章的时候发现国信的qmt的volume成交量是有数据的,那么其实可以用价格x成交量=成交额,间接获取成交额,大坑】
点击打开大图

附测试源码:
# coding:gbk
# 公众号:可转债量化分析
DEBUG = True
import time
def get_datetime(ContextInfo):
# 获取当前时间
index = ContextInfo.barpos
realtime = ContextInfo.get_bar_timetag(index)
date = timetag_to_datetime(realtime, "%Y-%m-%d %H:%M:%S")
if DEBUG:
print('当前日期 ', date)
return date
def init(ContextInfo):
print("==============start==========")
ContextInfo.start = '2024-03-27 10:00:00'
ContextInfo.end = '2024-03-29 10:00:00'
#
#ContextInfo.end = '2023-01-05'
#ContextInfo.start = '2023-01-16'
print('init')
def handlebar(ContextInfo):
# 回测的时候不需要
#if not ContextInfo.is_last_bar():
# print('return')
# return
get_datetime(ContextInfo)
print('handlebar')
data = ContextInfo.get_market_data(['quoter'], stock_code = ['123167.SZ'], skip_paused = True, period = 'tick', dividend_type = 'front')
#data = ContextInfo.get_market_data(['close'], stock_code = ['113567.SH'], skip_paused = True, period = '1d', dividend_type = 'front')
#print(type(data))
print(data)
def stop(ContextInfo):
print( 'strategy is stop !')
国金证券的融券数量多吗?什么是专项券源?
股票 • 李魔佛 发表了文章 • 0 个评论 • 1778 次浏览 • 2024-03-30 17:13
那么融券呢?
今天特意问了下经理,他发了一个融券的表格给我。
目前国金里面一般开通了融资融券的投资者,可用的券源有290个左右,随借随还的。说实话,这个数量不算太多。
而且里面的个股,部分也只能融100股,几百股的。所以即使被你融到券,实际下来的绝对收益也不会太高。
不过它也有一个专项券源。
它有资金要求,前20个交易日日均资产不低于300万元,才能够申请。
发现里面的券,主要是深圳交易所的为主,占了90%以上。
而且专项券源里面的可融券数量也比普通券源的要多很多,几千股,上万股的。
公共券源 :
实时可借 ,随时可融券卖出, 随借随还,融券卖出开仓后最快下一交易日方可归还融券负债 信用账户融券费率 按使用天数计息,算头不算尾
操作步骤: 融券卖出(所有客户端)
专项券源:
实时可借 ,审批划拨成功后当日专项融券卖出, 固定期限(一般28天以内),不可提前归还 ;
专项融券头寸占用费率 : 按专项头寸合约期限计息,不论合约期限内客户是否使用券源,均需支付专项头寸合约占用利息,算头算尾
操作步骤:
第1步:专项融券头寸申请(佣金宝APP/国金太阳至强版)
第2步:专项融券卖出(佣金宝APP/国金太阳至强版)
查看全部
那么融券呢?
今天特意问了下经理,他发了一个融券的表格给我。

目前国金里面一般开通了融资融券的投资者,可用的券源有290个左右,随借随还的。说实话,这个数量不算太多。
而且里面的个股,部分也只能融100股,几百股的。所以即使被你融到券,实际下来的绝对收益也不会太高。
不过它也有一个专项券源。
它有资金要求,前20个交易日日均资产不低于300万元,才能够申请。
发现里面的券,主要是深圳交易所的为主,占了90%以上。

而且专项券源里面的可融券数量也比普通券源的要多很多,几千股,上万股的。
公共券源 :
实时可借 ,随时可融券卖出, 随借随还,融券卖出开仓后最快下一交易日方可归还融券负债 信用账户融券费率 按使用天数计息,算头不算尾
操作步骤: 融券卖出(所有客户端)
专项券源:
实时可借 ,审批划拨成功后当日专项融券卖出, 固定期限(一般28天以内),不可提前归还 ;
专项融券头寸占用费率 : 按专项头寸合约期限计息,不论合约期限内客户是否使用券源,均需支付专项头寸合约占用利息,算头算尾
操作步骤:
第1步:专项融券头寸申请(佣金宝APP/国金太阳至强版)
第2步:专项融券卖出(佣金宝APP/国金太阳至强版)

程序自动获取限购-溢价LOF基金套利,并推送到微信消息
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 1678 次浏览 • 2024-03-23 23:32
如前面的印度基金LOF,嘉实原油LOF,全球芯片LOF,到现在的标普500LOF。
如果平时工作繁忙,没有时间每天翻看基金的公告,或者没时间看大V们公众号消息推送。
或者自己想要遍历所有限购状态的LOF基金,并自动筛选出溢价的可套利标的,提前埋伏。
那么可以自己动手,写个简单的监控推送程序。
微信推送电脑安装必要的python环境,和pandas,akshare库。
获取所有基金的数据
import akshare as ak
fund_purchase_em_df = ak.fund_purchase_em()
得到大概2万个基金数据。
然后剩下的就是过滤条件了,因为这里面包含了很多货基,债基等我们不需要的基金类型。
用value_counts 就知道有多少种类型:
平时我们做套利的,一般以QDII基金为主,大部分的情况是因为外汇额度用完而导致的限购。
所以监控的品种可以选择QDII类型或者海外股票等。
示例里笔者选一个 指数型-海外股票
然后过来条件按照个人喜好来设定:
比如选择限购1万以下的LOF:
def filter_func(df,type='指数型-海外股票'):
df = df[~df['基金代码'].str.startswith('0')]
condition1 = df['申购状态']=='限大额'
condition2 = df['基金类型']==type
df = df[condition1 & condition2]
df= df[~df['基金简称'].str.contains('ETF')]
df = df[(df['日累计限定金额']>0) & (df['日累计限定金额']<=10000)]
df['基金代码'] = df['基金代码'].map(lambda x: 'SH'+x if x.startswith('5') else 'SZ'+x)
return df
得到下面的结果:
因为上面的返回数据没有溢价率,所以我们就需要自己写个获取溢价率的函数去处理一下:
import requests
cookies = # 雪球上获取,不一定需要登录状态
headers = {
'authority': 'stock.xueqiu.com',
'origin': 'https://xueqiu.com',
'user-agent': 'Mozilla/5.0 (iPhone; U; CPU like Mac OS X; en) AppleWebKit/420+ (KHTML, like Gecko) Version/3.0 Mobile/1C28 Safari/419.3',
}
def fund_premium_rate(code):
params = {
'symbol': code,
'extend': 'detail',
}
response = requests.get('https://stock.xueqiu.com/v5/stock/quote.json', params=params,
cookies=cookies,
headers=headers)
try:
rate = response.json()['data']['quote']['premium_rate']
except Exception as e:
return None
else:
return rate
上面循环里会自动把没有对应场内基金的数据过滤掉。
运行2秒就得到了数据:
然后我们发现这几只限购的是处于轻微折价状态,只有易方达标普500LOF是溢价26%,只有它可以开拖拉机去套的。
微信推送
最后是发消息通知自己。早期开通的个人企业微信API,可以直接使用微信的API发送消息。如果现在申请,需要有自己的个人域名和备案。
可以设定溢价率大于某个阈值才发送消息。比如溢价率大于4以上才发送。
for code,name in code_name_mapper.items():
rate = fund_premium_rate(code)
if rate is not None:
print(f'{code} - {name}的溢价率是: {rate}')
if rate > 4:
send_message_via_wechat(f'{code} - {name}的溢价率是: {rate}, 可以关注套利。 公众号:可转债量化分析')
为了演示,去掉这个条件,把全部数据的都发送吧。
效果图
然后就可以把全部代码放在一起,用windows的定时任务或者linux的crontab自动运行了。
目前QMT,Ptrade不支持拖拉机账号,所以自动化拖拉机的功能就实现不了了哈。
PS:顺便附录一份全部限购1万以下的基金全表。
需要的关注公众号后台回复:基金限购名单
获取即可。
查看全部
如前面的印度基金LOF,嘉实原油LOF,全球芯片LOF,到现在的标普500LOF。
如果平时工作繁忙,没有时间每天翻看基金的公告,或者没时间看大V们公众号消息推送。
或者自己想要遍历所有限购状态的LOF基金,并自动筛选出溢价的可套利标的,提前埋伏。
那么可以自己动手,写个简单的监控推送程序。

微信推送电脑安装必要的python环境,和pandas,akshare库。
获取所有基金的数据
import akshare as ak
fund_purchase_em_df = ak.fund_purchase_em()

得到大概2万个基金数据。
然后剩下的就是过滤条件了,因为这里面包含了很多货基,债基等我们不需要的基金类型。
用value_counts 就知道有多少种类型:

平时我们做套利的,一般以QDII基金为主,大部分的情况是因为外汇额度用完而导致的限购。
所以监控的品种可以选择QDII类型或者海外股票等。
示例里笔者选一个 指数型-海外股票
然后过来条件按照个人喜好来设定:
比如选择限购1万以下的LOF:
def filter_func(df,type='指数型-海外股票'):
df = df[~df['基金代码'].str.startswith('0')]
condition1 = df['申购状态']=='限大额'
condition2 = df['基金类型']==type
df = df[condition1 & condition2]
df= df[~df['基金简称'].str.contains('ETF')]
df = df[(df['日累计限定金额']>0) & (df['日累计限定金额']<=10000)]
df['基金代码'] = df['基金代码'].map(lambda x: 'SH'+x if x.startswith('5') else 'SZ'+x)
return df
得到下面的结果:

因为上面的返回数据没有溢价率,所以我们就需要自己写个获取溢价率的函数去处理一下:
import requests
cookies = # 雪球上获取,不一定需要登录状态
headers = {
'authority': 'stock.xueqiu.com',
'origin': 'https://xueqiu.com',
'user-agent': 'Mozilla/5.0 (iPhone; U; CPU like Mac OS X; en) AppleWebKit/420+ (KHTML, like Gecko) Version/3.0 Mobile/1C28 Safari/419.3',
}
def fund_premium_rate(code):
params = {
'symbol': code,
'extend': 'detail',
}
response = requests.get('https://stock.xueqiu.com/v5/stock/quote.json', params=params,
cookies=cookies,
headers=headers)
try:
rate = response.json()['data']['quote']['premium_rate']
except Exception as e:
return None
else:
return rate
上面循环里会自动把没有对应场内基金的数据过滤掉。
运行2秒就得到了数据:

然后我们发现这几只限购的是处于轻微折价状态,只有易方达标普500LOF是溢价26%,只有它可以开拖拉机去套的。
微信推送
最后是发消息通知自己。早期开通的个人企业微信API,可以直接使用微信的API发送消息。如果现在申请,需要有自己的个人域名和备案。
可以设定溢价率大于某个阈值才发送消息。比如溢价率大于4以上才发送。
for code,name in code_name_mapper.items():
rate = fund_premium_rate(code)
if rate is not None:
print(f'{code} - {name}的溢价率是: {rate}')
if rate > 4:
send_message_via_wechat(f'{code} - {name}的溢价率是: {rate}, 可以关注套利。 公众号:可转债量化分析')
为了演示,去掉这个条件,把全部数据的都发送吧。
效果图
然后就可以把全部代码放在一起,用windows的定时任务或者linux的crontab自动运行了。
目前QMT,Ptrade不支持拖拉机账号,所以自动化拖拉机的功能就实现不了了哈。
PS:顺便附录一份全部限购1万以下的基金全表。
需要的关注公众号后台回复:基金限购名单
获取即可。
108个AI工具,写作、翻译、设计、音视频、代码、文件处理大全集
AI应用 • 马化云 发表了文章 • 0 个评论 • 1847 次浏览 • 2024-03-21 00:16
https://yiyan.baidu.com
·简介:综合型AI:内容生成、文档分析、图像分析、图表制作、脑图……
·通义千问
https://tongyi.aliyun.com
·综合型AI:内容生成、文档分析、图像分析……
·Kimi(月之暗面)
https://kimi.moonshot.cn
· 综合型AI:内容生成、文档分析、灵感推荐……
·腾讯混元
https://hunyuan.tencent.com/bot/chat
·综合型AI:内容生成、文档分析、灵感推荐……
·讯飞星火
https://xinghuo.xfyun.cn
·综合型AI:内容生成……
抖音豆包
https://www.doubao.com
综合型AI:内容生成,偏互联网运营方向……
智谱AI
https://open.bigmodel.cn
综合型AI:内容生成、知识问答……
百川智能
https://www.baichuan-ai.com/chat
综合型AI:内容生成、文档分析、互联网搜索……
360智脑
https://ai.360.com
综合型AI:360智脑全家桶……
字节小悟空
https://wukong.com/tool
综合型AI:字节跳动内容生成工具集
达观数据曹植
http://www.datagrand.com/
行业垂域大模型
02
聊天/内容生成
360数字员工
https://ai.360.com
团队协作共享,企业知识库、AI文档分析、AI营销文案、AI文书写作等智能工具
有道AI
https://ai.youdao.com
文档、翻译、视觉、语音、教育……
03
AI办公-Office
AiPPT
https://www.aippt.cn
自动生成PPT大纲、模板、Word-PPT……
iSlide
https://www.islide.cc
AI 一键设计 PPT
WPS AI
https://ai.wps.cn
WPS的AI插件(智能PPT、表格、文档整理……)
ChatPPT
http://www.chat-ppt.com
AI插件,支持Office、WPS,自动文档生成
360苏打办公
https://bangong.360.cn
AI办公工具集:文档、视频、设计、开发……
酷表ChatExcel
https://chatexcel.com
智能Excel公式
商汤办公小浣熊
https://raccoon.sensetime.com
智能图表
04
AI办公-会议纪要
讯飞听见
https://www.iflyrec.com
音视频转文字,实时录音转文字,同传,翻译……
阿里通义听悟
https://tingwu.aliyun.com
实时转录,音视频转文字,互联网内容提炼……
飞书妙记
https://www.feishu.cn/product/ ... e.com
飞书文档中的会议纪要工具,实时转录,音视频转文字
腾讯会议AI
https://meeting.tencent.com/ai/index.html
腾讯会议录制后会议纪要整理
05
AI办公-脑图
ProcessOn
https://www.processon.com
AI思维导图
亿图脑图
https://www.edrawsoft.cn/mindmaster
AI思维导图
GitMind思乎
https://gitmind.cn/
AI思维导图
boardmix 博思白板
https://boardmix.cn/ai-whiteboard
实时协作的智慧白板上,一键生成PPT、用AI协助创作思维导图、AI绘画、AI写作,共享资源素材
妙办画板
https://imiaoban.com
生成流程图、思维导图
06
AI办公-文档
司马阅AI文档
https://smartread.cc/
每天免费100次提问,AI文档阅读分析工具,通过聊天互动形式,精准地从复杂文档提取并分析信息
360AI浏览器
https://ai.360.com
智能摘要、文章脉络、思维导图等
07
AI写作
有道云笔记AI
https://note.youdao.com
有道云笔记写作插件,改写扩写润色……
腾讯 Effidit
https://effidit.qq.com
智能纠错、文本补全、文本改写、文本扩写、词语推荐、句子推荐与生成等功能
讯飞写作
https://huixie.iflyrec.com
AI对话写作、模板写作、素材、润色……
深言达意
https://www.shenyandayi.com
根据模糊描述,找词找句的智能写作工具
阿里悉语
https://login.taobao.com
淘宝专用的商品文案生成,输入商品的淘宝链接即可获得文案
字节火山写作
https://www.writingo.net
全文润色的AI智能写作
秘塔写作猫
https://xiezuocat.com
AI写作模板,AI写作工具,指令扩写润色……
光速写作
https://guangsuxie.com
作业帮旗下:全文生成、PPT生成、问答助手、写作助手
WriteWise
https://www.ximalaya.com/gatek ... ot.cn
喜马拉雅小说创作工具
笔灵AI
https://ibiling.cn
一键生成工作计划、文案方案……
易撰
https://www.yizhuan5.com
自媒体内容
Giiso写作机器人
https://www.giiso.com
写作、文配图、风格转换、文生图……
5118 SEO优化精灵
https://www.5118.com/seometa
快速生成高质量SEO标题、Meta描述和关键字,轻松提升网站搜索引擎排名
08
AI翻译
沉浸式翻译
https://immersivetranslate.com
翻译外语网页,PDF翻译,EPUB电子书翻译,视频双语字幕翻译等
彩云小译
https://fanyi.caiyunapp.com
多种格式文档的翻译、同声传译、文档翻译和网页翻译。
网易见外
https://sight.youdao.com
字幕、音频转写、同传、文档翻译……
09
AI搜索引擎
天工AI搜索(昆仑万维)
https://search.tiangong.cn
找资料、查信息、搜答案、搜文件,还会对海量搜索结果做AI智能聚合
360AI搜索
https://ai.360.com
AI搜索能够从海量的网站中主动寻找、提炼精准答案
秘塔AI搜索
https://metaso.cn
没有广告,直达结果
perplexity.ai
www.perplexity.ai
黄仁勋带货的AI搜索引擎
sciphi.ai
https://search.sciphi.ai
AI搜索引擎
devv.ai
https://devv.ai
为开发人员打造的人工智能驱动的搜索引擎
10
聊天/内容生成
通义万相
https://tongyi.aliyun.com
AI生成图片,人工智能艺术创作大模型
文心一格
https://yige.baidu.com
文生图像
剪映AI
https://www.capcut.cn
剪映一键生成AI绘画
腾讯ARC
https://arc.tencent.com
人像修复、人像抠图、动漫增强
360智绘
https://ai.360.com
风格化AI绘画、Lora训练
无限画
https://588ku.com/ai/wuxianhua/Home
智能图像设计,整合千库网的设计行业知识经验、资源数据
美图设计室
https://www.x-design.com
图像智能处理,海报设计……
liblib.ai
https://www.liblib.ai
AI 模型分享平台-各种风格的图像微调模型
Tusi.Art
https://tusiart.com
AI 模型分享平台
标小智Logo生成
https://www.logosc.cn
在线LOGO设计,生成企业VI
佐糖
https://picwish.cn
丰富的图像处理工具
Vega AI
https://vegaai.net
文生图,图生图,姿态生图,文生视频,图生视频……
美图WHEE
https://www.whee.com
文生图,图生图,文生视频,扩图改图超清……
无界AI
https://www.wujieai.com
文生图
BgSub
https://bgsub.cn
抠图
阿里PicCopilot
https://www.piccopilot.com
阿里巴巴国际,AI驱动图片优化工具,专门为电商领域提供服务
搜狐简单AI
https://ai.sohu.com 智能图片生成平台和社区
6pen
https://6pen.art
文本描述生成绘画艺术作品
11
AI设计
阿里堆友
https://d.design
面向设计师群体的AI设计社区
稿定AI
https://www.gaoding.com
图像设计
墨刀AI
https://modao.cc
产品设计协作平台
莫高设计MasterGo AI
https://mastergo.com
AI时代的企业级产品设计平台,界面设计、交互设计……
创客贴AI
https://www.chuangkit.com
图形图像设计
即时AI
https://js.design/ai
文生UI,文生图,图生UI……
PixsO AI
https://pixso.cn
新生代UI设计工具
抖音即创
https://aic.oceanengine.com
抖音电商智能创作平台,提供AI视频创作、图文创作和直播创作
腾讯 AIDesign
https://ailogo.qq.com
腾讯的logo设计
美间
https://www.meijian.com
AI软装设计、海报和提案生成工具
12
AI音频
度加创作工具
https://aigc.baidu.com
热搜一键成稿,文稿一键成片
魔音工坊
https://www.moyin.com
AI配音工具
网易天音
https://tianyin.music.163.com
智能编曲,海量风格
TME Studio
https://y.qq.com/tme_studio
腾讯音乐智能音乐生成工具
讯飞智作
https://www.xfzhizuo.cn
配音、声音定制、虚拟主播、音视频处理……
13
AI视频
PixVerse
https://pixverse.ai
文生视频
绘影字幕
https://huiyingzimu.com
AI字幕,翻译、配音……
万彩微影
https://www.animiz.cn/microvideo
真人手绘视频、翻转文字视频、文章转视频、相册视频工具……
芦笋AI提词器
https://tcq.lusun.com
持AI写稿、隐形提词效果、支持智能跟读
360快剪辑
https://kuai.360.cn 专业视频剪辑
万彩AI
https://ai.kezhan365.com
高效、好用的AI写作和短视频创作平台
14
数字人
腾讯智影
https://zenvideo.qq.com
数字人、文本配音、文章转视频……
来画
https://www.laihua.com
动画、数字人智能制作
一帧秒创
https://aigc.yizhentv.com
AI视频,数字人、AI作画……
万兴播爆
https://virbo.wondershare.cn
数字人,真人营销视频
15
AI写代码
昇思MindSpore
https://www.mindspore.cn
面向开发者的一站式AI开发平台,提供海量数据预处理及半自动化标注、大规模分布式Training、自动化模型生成
百度飞桨PaddlePaddle AI Code assistant https://www.paddlepaddle.org.cn
在线编程,海量数据集
ZelinAI
https://www.zelinai.com
零代码构建AI应用
aiXcoder
https://www.aixcoder.com
基于深度学习代码生成技术的智能编程机器人
商汤代码小浣熊
https://raccoon.sensetime.com/code
代码生成补全翻译重构……
CodeArtsSnap https://www.huaweicloud.com/pr ... .html
覆盖代码生成、研发知识问答、单元测试用例生成、代码解释、代码注释、代码翻译、代码调试、代码检查等八大研发场景
天工智码
https://sky-code.singularity-ai.com/index.html#/
基于昆仑天工模型的AI代码工具
16
模型训练/部署
火山方舟
https://www.volcengine.com/product/ark 模型训练、推理、评测、精调等全方位功能与服务
魔搭社区
https://modelscope.cn
阿里达摩院,提供模型探索体验、推理、训练、部署和应用的一站式服务
文心大模型
https://wenxin.baidu.com
产业级知识增强大模型
17
AI提示词
提示工程指南
www.promptingguide.ai
如何使用提示词来完成不同的任务
词魂
https://icihun.com/
AIGC精品提示词库
查看全部
https://yiyan.baidu.com
·简介:综合型AI:内容生成、文档分析、图像分析、图表制作、脑图……
·通义千问
https://tongyi.aliyun.com
·综合型AI:内容生成、文档分析、图像分析……
·Kimi(月之暗面)
https://kimi.moonshot.cn
· 综合型AI:内容生成、文档分析、灵感推荐……
·腾讯混元
https://hunyuan.tencent.com/bot/chat
·综合型AI:内容生成、文档分析、灵感推荐……
·讯飞星火
https://xinghuo.xfyun.cn
·综合型AI:内容生成……
抖音豆包
https://www.doubao.com
综合型AI:内容生成,偏互联网运营方向……
智谱AI
https://open.bigmodel.cn
综合型AI:内容生成、知识问答……
百川智能
https://www.baichuan-ai.com/chat
综合型AI:内容生成、文档分析、互联网搜索……
360智脑
https://ai.360.com
综合型AI:360智脑全家桶……
字节小悟空
https://wukong.com/tool
综合型AI:字节跳动内容生成工具集
达观数据曹植
http://www.datagrand.com/
行业垂域大模型
02
聊天/内容生成
360数字员工
https://ai.360.com
团队协作共享,企业知识库、AI文档分析、AI营销文案、AI文书写作等智能工具
有道AI
https://ai.youdao.com
文档、翻译、视觉、语音、教育……
03
AI办公-Office
AiPPT
https://www.aippt.cn
自动生成PPT大纲、模板、Word-PPT……
iSlide
https://www.islide.cc
AI 一键设计 PPT
WPS AI
https://ai.wps.cn
WPS的AI插件(智能PPT、表格、文档整理……)
ChatPPT
http://www.chat-ppt.com
AI插件,支持Office、WPS,自动文档生成
360苏打办公
https://bangong.360.cn
AI办公工具集:文档、视频、设计、开发……
酷表ChatExcel
https://chatexcel.com
智能Excel公式
商汤办公小浣熊
https://raccoon.sensetime.com
智能图表
04
AI办公-会议纪要
讯飞听见
https://www.iflyrec.com
音视频转文字,实时录音转文字,同传,翻译……
阿里通义听悟
https://tingwu.aliyun.com
实时转录,音视频转文字,互联网内容提炼……
飞书妙记
https://www.feishu.cn/product/ ... e.com
飞书文档中的会议纪要工具,实时转录,音视频转文字
腾讯会议AI
https://meeting.tencent.com/ai/index.html
腾讯会议录制后会议纪要整理
05
AI办公-脑图
ProcessOn
https://www.processon.com
AI思维导图
亿图脑图
https://www.edrawsoft.cn/mindmaster
AI思维导图
GitMind思乎
https://gitmind.cn/
AI思维导图
boardmix 博思白板
https://boardmix.cn/ai-whiteboard
实时协作的智慧白板上,一键生成PPT、用AI协助创作思维导图、AI绘画、AI写作,共享资源素材
妙办画板
https://imiaoban.com
生成流程图、思维导图
06
AI办公-文档
司马阅AI文档
https://smartread.cc/
每天免费100次提问,AI文档阅读分析工具,通过聊天互动形式,精准地从复杂文档提取并分析信息
360AI浏览器
https://ai.360.com
智能摘要、文章脉络、思维导图等
07
AI写作
有道云笔记AI
https://note.youdao.com
有道云笔记写作插件,改写扩写润色……
腾讯 Effidit
https://effidit.qq.com
智能纠错、文本补全、文本改写、文本扩写、词语推荐、句子推荐与生成等功能
讯飞写作
https://huixie.iflyrec.com
AI对话写作、模板写作、素材、润色……
深言达意
https://www.shenyandayi.com
根据模糊描述,找词找句的智能写作工具
阿里悉语
https://login.taobao.com
淘宝专用的商品文案生成,输入商品的淘宝链接即可获得文案
字节火山写作
https://www.writingo.net
全文润色的AI智能写作
秘塔写作猫
https://xiezuocat.com
AI写作模板,AI写作工具,指令扩写润色……
光速写作
https://guangsuxie.com
作业帮旗下:全文生成、PPT生成、问答助手、写作助手
WriteWise
https://www.ximalaya.com/gatek ... ot.cn
喜马拉雅小说创作工具
笔灵AI
https://ibiling.cn
一键生成工作计划、文案方案……
易撰
https://www.yizhuan5.com
自媒体内容
Giiso写作机器人
https://www.giiso.com
写作、文配图、风格转换、文生图……
5118 SEO优化精灵
https://www.5118.com/seometa
快速生成高质量SEO标题、Meta描述和关键字,轻松提升网站搜索引擎排名
08
AI翻译
沉浸式翻译
https://immersivetranslate.com
翻译外语网页,PDF翻译,EPUB电子书翻译,视频双语字幕翻译等
彩云小译
https://fanyi.caiyunapp.com
多种格式文档的翻译、同声传译、文档翻译和网页翻译。
网易见外
https://sight.youdao.com
字幕、音频转写、同传、文档翻译……
09
AI搜索引擎
天工AI搜索(昆仑万维)
https://search.tiangong.cn
找资料、查信息、搜答案、搜文件,还会对海量搜索结果做AI智能聚合
360AI搜索
https://ai.360.com
AI搜索能够从海量的网站中主动寻找、提炼精准答案
秘塔AI搜索
https://metaso.cn
没有广告,直达结果
perplexity.ai
www.perplexity.ai
黄仁勋带货的AI搜索引擎
sciphi.ai
https://search.sciphi.ai
AI搜索引擎
devv.ai
https://devv.ai
为开发人员打造的人工智能驱动的搜索引擎
10
聊天/内容生成
通义万相
https://tongyi.aliyun.com
AI生成图片,人工智能艺术创作大模型
文心一格
https://yige.baidu.com
文生图像
剪映AI
https://www.capcut.cn
剪映一键生成AI绘画
腾讯ARC
https://arc.tencent.com
人像修复、人像抠图、动漫增强
360智绘
https://ai.360.com
风格化AI绘画、Lora训练
无限画
https://588ku.com/ai/wuxianhua/Home
智能图像设计,整合千库网的设计行业知识经验、资源数据
美图设计室
https://www.x-design.com
图像智能处理,海报设计……
liblib.ai
https://www.liblib.ai
AI 模型分享平台-各种风格的图像微调模型
Tusi.Art
https://tusiart.com
AI 模型分享平台
标小智Logo生成
https://www.logosc.cn
在线LOGO设计,生成企业VI
佐糖
https://picwish.cn
丰富的图像处理工具
Vega AI
https://vegaai.net
文生图,图生图,姿态生图,文生视频,图生视频……
美图WHEE
https://www.whee.com
文生图,图生图,文生视频,扩图改图超清……
无界AI
https://www.wujieai.com
文生图
BgSub
https://bgsub.cn
抠图
阿里PicCopilot
https://www.piccopilot.com
阿里巴巴国际,AI驱动图片优化工具,专门为电商领域提供服务
搜狐简单AI
https://ai.sohu.com 智能图片生成平台和社区
6pen
https://6pen.art
文本描述生成绘画艺术作品
11
AI设计
阿里堆友
https://d.design
面向设计师群体的AI设计社区
稿定AI
https://www.gaoding.com
图像设计
墨刀AI
https://modao.cc
产品设计协作平台
莫高设计MasterGo AI
https://mastergo.com
AI时代的企业级产品设计平台,界面设计、交互设计……
创客贴AI
https://www.chuangkit.com
图形图像设计
即时AI
https://js.design/ai
文生UI,文生图,图生UI……
PixsO AI
https://pixso.cn
新生代UI设计工具
抖音即创
https://aic.oceanengine.com
抖音电商智能创作平台,提供AI视频创作、图文创作和直播创作
腾讯 AIDesign
https://ailogo.qq.com
腾讯的logo设计
美间
https://www.meijian.com
AI软装设计、海报和提案生成工具
12
AI音频
度加创作工具
https://aigc.baidu.com
热搜一键成稿,文稿一键成片
魔音工坊
https://www.moyin.com
AI配音工具
网易天音
https://tianyin.music.163.com
智能编曲,海量风格
TME Studio
https://y.qq.com/tme_studio
腾讯音乐智能音乐生成工具
讯飞智作
https://www.xfzhizuo.cn
配音、声音定制、虚拟主播、音视频处理……
13
AI视频
PixVerse
https://pixverse.ai
文生视频
绘影字幕
https://huiyingzimu.com
AI字幕,翻译、配音……
万彩微影
https://www.animiz.cn/microvideo
真人手绘视频、翻转文字视频、文章转视频、相册视频工具……
芦笋AI提词器
https://tcq.lusun.com
持AI写稿、隐形提词效果、支持智能跟读
360快剪辑
https://kuai.360.cn 专业视频剪辑
万彩AI
https://ai.kezhan365.com
高效、好用的AI写作和短视频创作平台
14
数字人
腾讯智影
https://zenvideo.qq.com
数字人、文本配音、文章转视频……
来画
https://www.laihua.com
动画、数字人智能制作
一帧秒创
https://aigc.yizhentv.com
AI视频,数字人、AI作画……
万兴播爆
https://virbo.wondershare.cn
数字人,真人营销视频
15
AI写代码
昇思MindSpore
https://www.mindspore.cn
面向开发者的一站式AI开发平台,提供海量数据预处理及半自动化标注、大规模分布式Training、自动化模型生成
百度飞桨PaddlePaddle AI Code assistant https://www.paddlepaddle.org.cn
在线编程,海量数据集
ZelinAI
https://www.zelinai.com
零代码构建AI应用
aiXcoder
https://www.aixcoder.com
基于深度学习代码生成技术的智能编程机器人
商汤代码小浣熊
https://raccoon.sensetime.com/code
代码生成补全翻译重构……
CodeArtsSnap https://www.huaweicloud.com/pr ... .html
覆盖代码生成、研发知识问答、单元测试用例生成、代码解释、代码注释、代码翻译、代码调试、代码检查等八大研发场景
天工智码
https://sky-code.singularity-ai.com/index.html#/
基于昆仑天工模型的AI代码工具
16
模型训练/部署
火山方舟
https://www.volcengine.com/product/ark 模型训练、推理、评测、精调等全方位功能与服务
魔搭社区
https://modelscope.cn
阿里达摩院,提供模型探索体验、推理、训练、部署和应用的一站式服务
文心大模型
https://wenxin.baidu.com
产业级知识增强大模型
17
AI提示词
提示工程指南
www.promptingguide.ai
如何使用提示词来完成不同的任务
词魂
https://icihun.com/
AIGC精品提示词库
chatGPT一键生成漫画故事!| 手把手保姆教程
AI应用 • 马化云 发表了文章 • 0 个评论 • 2734 次浏览 • 2024-03-12 15:43
鲨鱼与美女
上面的漫画图是通过一句话描述生成的漫画图片。
下面小编手把手带大家来使用chatGPT生成属于你的漫画。
首先打开网站:
https://dashtoon.com/
官网根据提示注册账号,用邮箱注册就可以了,或者如果你有Google账号,直接用Google账号关联登录。[注册]
注册然后就可以开始创作属于你的漫画故事。
点击顶部的“Create new dashtoon"
开始创作
填入故事情节在故事描述栏里面,详细描述你的故事情节。可以用中文去写。
比如上面的例子是:一个年轻的亚洲姑娘,因为炒股失败,没有钱,沦落到去KTV做陪唱小姐然后它会自动帮你生成一段有具体情节的故事。
生成情节生成的情节是用英文描述的,你可以根据其中的细节修改润色。然后直接点击“Next” 下一步。
风格选择漫画色调和风格。
人物选择人物角色风格,我选一个清纯的中国妹子风格。
点击下一步,进入生成漫画过程:
生成中这一步比较慢,要等个1-2分钟。
生成之后点击右下角的“Publish"发布
发布然后会生成一张长长的漫画大图。[效果图]
效果图
效果图你可以不用点击publish发布。直接点击手机里面的图片,右键,另存为图片。
然后图片就可以下载下来了。
沦落到KTV陪唱还这么开心?因为小编是直接一步生成,中间没有微调,所以故事看起来差强人意。
中间还有很多细节可以调节,比如故事情节,人脸细节,服饰等等。
篇幅有限,接下来读者朋友可以自己上去网站动手创作,属于你的漫画集吧
中间还有很多细节可以调节,比如故事情节,人脸细节,服饰等等。 查看全部

鲨鱼与美女
上面的漫画图是通过一句话描述生成的漫画图片。
下面小编手把手带大家来使用chatGPT生成属于你的漫画。
首先打开网站:
https://dashtoon.com/

官网根据提示注册账号,用邮箱注册就可以了,或者如果你有Google账号,直接用Google账号关联登录。[注册]
注册然后就可以开始创作属于你的漫画故事。
点击顶部的“Create new dashtoon"
开始创作

填入故事情节在故事描述栏里面,详细描述你的故事情节。可以用中文去写。
比如上面的例子是:一个年轻的亚洲姑娘,因为炒股失败,没有钱,沦落到去KTV做陪唱小姐然后它会自动帮你生成一段有具体情节的故事。

生成情节生成的情节是用英文描述的,你可以根据其中的细节修改润色。然后直接点击“Next” 下一步。

风格选择漫画色调和风格。

人物选择人物角色风格,我选一个清纯的中国妹子风格。
点击下一步,进入生成漫画过程:

生成中这一步比较慢,要等个1-2分钟。
生成之后点击右下角的“Publish"发布
发布然后会生成一张长长的漫画大图。[效果图]
效果图

效果图你可以不用点击publish发布。直接点击手机里面的图片,右键,另存为图片。
然后图片就可以下载下来了。

沦落到KTV陪唱还这么开心?因为小编是直接一步生成,中间没有微调,所以故事看起来差强人意。
中间还有很多细节可以调节,比如故事情节,人脸细节,服饰等等。
篇幅有限,接下来读者朋友可以自己上去网站动手创作,属于你的漫画集吧
中间还有很多细节可以调节,比如故事情节,人脸细节,服饰等等。
Ptrade|QMT|银行股息率轮动 实盘自动化交易
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 1632 次浏览 • 2024-03-05 09:33
miniQMT安装包路径 | 下载地址
QMT • 李魔佛 发表了文章 • 0 个评论 • 2762 次浏览 • 2024-02-29 20:09
等待几分钟,python文件下载好了之后。
找到qmt的安装目录,
进去这里面
\bin.x64\Lib\site-packages\xtquant
把这个目录复制到你的python路径的site-package 下面, 就可以在你的python环境下运行miniQMT了。
当然首先还是要启动你的QMT客户端,勾选极速模式。 (不开的话连不到券商服务器,这以为这无法再linux上单独跑,wine额外另说)
比如下面的获取行情的示例代码,还有直接下单代码
# 用前须知
## xtdata提供和MiniQmt的交互接口,本质是和MiniQmt建立连接,由MiniQmt处理行情数据请求,再把结果回传返回到python层。使用的行情服务器以及能获取到的行情数据和MiniQmt是一致的,要检查数据或者切换连接时直接操作MiniQmt即可。
## 对于数据获取接口,使用时需要先确保MiniQmt已有所需要的数据,如果不足可以通过补充数据接口补充,再调用数据获取接口获取。
## 对于订阅接口,直接设置数据回调,数据到来时会由回调返回。订阅接收到的数据一般会保存下来,同种数据不需要再单独补充。
# 代码讲解
# 从本地python导入xtquant库,如果出现报错则说明安装失败
from xtquant import xtdata
import time
# 设定一个标的列表
code_list = ["000001.SZ"]
# 设定获取数据的周期
period = "1d"
# 下载标的行情数据
if 1:
## 为了方便用户进行数据管理,xtquant的大部分历史数据都是以压缩形式存储在本地的
## 比如行情数据,需要通过download_history_data下载,财务数据需要通过
## 所以在取历史数据之前,我们需要调用数据下载接口,将数据下载到本地
for i in code_list:
xtdata.download_history_data(i,period=period,incrementally=True) # 增量下载行情数据(开高低收,等等)到本地
xtdata.download_financial_data(code_list) # 下载财务数据到本地
xtdata.download_sector_data() # 下载板块数据到本地
# 更多数据的下载方式可以通过数据字典查询
# 读取本地历史行情数据
history_data = xtdata.get_market_data_ex(,code_list,period=period,count=-1)
print(history_data)
print("=" * 20)
# 如果需要盘中的实时行情,需要向服务器进行订阅后才能获取
# 订阅后,get_market_data函数于get_market_data_ex函数将会自动拼接本地历史行情与服务器实时行情
# 向服务器订阅数据
for i in code_list:
xtdata.subscribe_quote(i,period=period,count=-1) # 设置count = -1来取到当天所有实时行情
# 等待订阅完成
time.sleep(1)
# 获取订阅后的行情
kline_data = xtdata.get_market_data_ex(,code_list,period=period)
print(kline_data)
# 获取订阅后的行情,并以固定间隔进行刷新,预期会循环打印10次
for i in range(10):
# 这边做演示,就用for来循环了,实际使用中可以用while True
kline_data = xtdata.get_market_data_ex(,code_list,period=period)
print(kline_data)
time.sleep(3) # 三秒后再次获取行情
# 如果不想用固定间隔触发,可以以用订阅后的回调来执行
# 这种模式下当订阅的callback回调函数将会异步的执行,每当订阅的标的tick发生变化更新,callback回调函数就会被调用一次
# 本地已有的数据不会触发callback
# 定义的回测函数
## 回调函数中,data是本次触发回调的数据,只有一条
def f(data):
# print(data)
code_list = list(data.keys()) # 获取到本次触发的标的代码
kline_in_callabck = xtdata.get_market_data_ex(,code_list,period = period) # 在回调中获取klines数据
print(kline_in_callabck)
for i in code_list:
xtdata.subscribe_quote(i,period=period,count=-1,callback=f) # 订阅时设定回调函数
# 使用回调时,必须要同时使用xtdata.run()来阻塞程序,否则程序运行到最后一行就直接结束退出了。
xtdata.run()
异步下单#coding:utf-8
import time, datetime, traceback, sys
from xtquant import xtdata
from xtquant.xttrader import XtQuantTrader, XtQuantTraderCallback
from xtquant.xttype import StockAccount
from xtquant import xtconstant
#定义一个类 创建类的实例 作为状态的容器
class _a():
pass
A = _a()
A.bought_list =
A.hsa = xtdata.get_stock_list_in_sector('沪深A股')
def interact():
"""执行后进入repl模式"""
import code
code.InteractiveConsole(locals=globals()).interact()
xtdata.download_sector_data()
def f(data):
now = datetime.datetime.now()
for stock in data:
if stock not in A.hsa:
continue
cuurent_price = data[stock]['lastPrice']
pre_price = data[stock]['lastClose']
ratio = cuurent_price / pre_price - 1 if pre_price > 0 else 0
if ratio > 0.09 and stock not in A.bought_list:
print(f"{now} 最新价 买入 {stock} 200股")
async_seq = xt_trader.order_stock_async(acc, stock, xtconstant.STOCK_BUY, 200, xtconstant.LATEST_PRICE, -1, 'strategy_name', stock)
A.bought_list.append(stock)
class MyXtQuantTraderCallback(XtQuantTraderCallback):
def on_disconnected(self):
"""
连接断开
:return:
"""
print(datetime.datetime.now(),'连接断开回调')
def on_stock_order(self, order):
"""
委托回报推送
:param order: XtOrder对象
:return:
"""
print(datetime.datetime.now(), '委托回调', order.order_remark)
def on_stock_trade(self, trade):
"""
成交变动推送
:param trade: XtTrade对象
:return:
"""
print(datetime.datetime.now(), '成交回调', trade.order_remark)
def on_order_error(self, order_error):
"""
委托失败推送
:param order_error:XtOrderError 对象
:return:
"""
# print("on order_error callback")
# print(order_error.order_id, order_error.error_id, order_error.error_msg)
print(f"委托报错回调 {order_error.order_remark} {order_error.error_msg}")
def on_cancel_error(self, cancel_error):
"""
撤单失败推送
:param cancel_error: XtCancelError 对象
:return:
"""
print(datetime.datetime.now(), sys._getframe().f_code.co_name)
def on_order_stock_async_response(self, response):
"""
异步下单回报推送
:param response: XtOrderResponse 对象
:return:
"""
print(f"异步委托回调 {response.order_remark}")
def on_cancel_order_stock_async_response(self, response):
"""
:param response: XtCancelOrderResponse 对象
:return:
"""
print(datetime.datetime.now(), sys._getframe().f_code.co_name)
def on_account_status(self, status):
"""
:param response: XtAccountStatus 对象
:return:
"""
print(datetime.datetime.now(), sys._getframe().f_code.co_name)
if __name__ == '__main__':
print("start")
#指定客户端所在路径
path = r'D:\qmt\sp3\迅投极速交易终端 睿智融科版\userdata_mini'
# 生成session id 整数类型 同时运行的策略不能重复
session_id = int(time.time())
xt_trader = XtQuantTrader(path, session_id)
# 开启主动请求接口的专用线程 开启后在on_stock_xxx回调函数里调用XtQuantTrader.query_xxx函数不会卡住回调线程,但是查询和推送的数据在时序上会变得不确定
# 详见: http://docs.thinktrader.net/vip/pages/ee0e9b/#开启主动请求接口的专用线程
# xt_trader.set_relaxed_response_order_enabled(True)
# 创建资金账号为 800068 的证券账号对象
acc = StockAccount('800068', 'STOCK')
# 创建交易回调类对象,并声明接收回调
callback = MyXtQuantTraderCallback()
xt_trader.register_callback(callback)
# 启动交易线程
xt_trader.start()
# 建立交易连接,返回0表示连接成功
connect_result = xt_trader.connect()
print('建立交易连接,返回0表示连接成功', connect_result)
# 对交易回调进行订阅,订阅后可以收到交易主推,返回0表示订阅成功
subscribe_result = xt_trader.subscribe(acc)
print('对交易回调进行订阅,订阅后可以收到交易主推,返回0表示订阅成功', subscribe_result)
#这一行是注册全推回调函数 包括下单判断 安全起见处于注释状态 确认理解效果后再放开
# xtdata.subscribe_whole_quote(["SH", "SZ"], callback=f)
# 阻塞主线程退出
xt_trader.run_forever()
# 如果使用vscode pycharm等本地编辑器 可以进入交互模式 方便调试 (把上一行的run_forever注释掉 否则不会执行到这里)
interact()
需要开通miniQMT(低门槛,低费率)的朋友,
可以扫码联系:或者添加 技术公众号:
公众号:
查看全部
等待几分钟,python文件下载好了之后。
找到qmt的安装目录,
进去这里面
\bin.x64\Lib\site-packages\xtquant
把这个目录复制到你的python路径的site-package 下面, 就可以在你的python环境下运行miniQMT了。
当然首先还是要启动你的QMT客户端,勾选极速模式。 (不开的话连不到券商服务器,这以为这无法再linux上单独跑,wine额外另说)
比如下面的获取行情的示例代码,还有直接下单代码
# 用前须知
## xtdata提供和MiniQmt的交互接口,本质是和MiniQmt建立连接,由MiniQmt处理行情数据请求,再把结果回传返回到python层。使用的行情服务器以及能获取到的行情数据和MiniQmt是一致的,要检查数据或者切换连接时直接操作MiniQmt即可。
## 对于数据获取接口,使用时需要先确保MiniQmt已有所需要的数据,如果不足可以通过补充数据接口补充,再调用数据获取接口获取。
## 对于订阅接口,直接设置数据回调,数据到来时会由回调返回。订阅接收到的数据一般会保存下来,同种数据不需要再单独补充。
# 代码讲解
# 从本地python导入xtquant库,如果出现报错则说明安装失败
from xtquant import xtdata
import time
# 设定一个标的列表
code_list = ["000001.SZ"]
# 设定获取数据的周期
period = "1d"
# 下载标的行情数据
if 1:
## 为了方便用户进行数据管理,xtquant的大部分历史数据都是以压缩形式存储在本地的
## 比如行情数据,需要通过download_history_data下载,财务数据需要通过
## 所以在取历史数据之前,我们需要调用数据下载接口,将数据下载到本地
for i in code_list:
xtdata.download_history_data(i,period=period,incrementally=True) # 增量下载行情数据(开高低收,等等)到本地
xtdata.download_financial_data(code_list) # 下载财务数据到本地
xtdata.download_sector_data() # 下载板块数据到本地
# 更多数据的下载方式可以通过数据字典查询
# 读取本地历史行情数据
history_data = xtdata.get_market_data_ex(,code_list,period=period,count=-1)
print(history_data)
print("=" * 20)
# 如果需要盘中的实时行情,需要向服务器进行订阅后才能获取
# 订阅后,get_market_data函数于get_market_data_ex函数将会自动拼接本地历史行情与服务器实时行情
# 向服务器订阅数据
for i in code_list:
xtdata.subscribe_quote(i,period=period,count=-1) # 设置count = -1来取到当天所有实时行情
# 等待订阅完成
time.sleep(1)
# 获取订阅后的行情
kline_data = xtdata.get_market_data_ex(,code_list,period=period)
print(kline_data)
# 获取订阅后的行情,并以固定间隔进行刷新,预期会循环打印10次
for i in range(10):
# 这边做演示,就用for来循环了,实际使用中可以用while True
kline_data = xtdata.get_market_data_ex(,code_list,period=period)
print(kline_data)
time.sleep(3) # 三秒后再次获取行情
# 如果不想用固定间隔触发,可以以用订阅后的回调来执行
# 这种模式下当订阅的callback回调函数将会异步的执行,每当订阅的标的tick发生变化更新,callback回调函数就会被调用一次
# 本地已有的数据不会触发callback
# 定义的回测函数
## 回调函数中,data是本次触发回调的数据,只有一条
def f(data):
# print(data)
code_list = list(data.keys()) # 获取到本次触发的标的代码
kline_in_callabck = xtdata.get_market_data_ex(,code_list,period = period) # 在回调中获取klines数据
print(kline_in_callabck)
for i in code_list:
xtdata.subscribe_quote(i,period=period,count=-1,callback=f) # 订阅时设定回调函数
# 使用回调时,必须要同时使用xtdata.run()来阻塞程序,否则程序运行到最后一行就直接结束退出了。
xtdata.run()
异步下单
#coding:utf-8
import time, datetime, traceback, sys
from xtquant import xtdata
from xtquant.xttrader import XtQuantTrader, XtQuantTraderCallback
from xtquant.xttype import StockAccount
from xtquant import xtconstant
#定义一个类 创建类的实例 作为状态的容器
class _a():
pass
A = _a()
A.bought_list =
A.hsa = xtdata.get_stock_list_in_sector('沪深A股')
def interact():
"""执行后进入repl模式"""
import code
code.InteractiveConsole(locals=globals()).interact()
xtdata.download_sector_data()
def f(data):
now = datetime.datetime.now()
for stock in data:
if stock not in A.hsa:
continue
cuurent_price = data[stock]['lastPrice']
pre_price = data[stock]['lastClose']
ratio = cuurent_price / pre_price - 1 if pre_price > 0 else 0
if ratio > 0.09 and stock not in A.bought_list:
print(f"{now} 最新价 买入 {stock} 200股")
async_seq = xt_trader.order_stock_async(acc, stock, xtconstant.STOCK_BUY, 200, xtconstant.LATEST_PRICE, -1, 'strategy_name', stock)
A.bought_list.append(stock)
class MyXtQuantTraderCallback(XtQuantTraderCallback):
def on_disconnected(self):
"""
连接断开
:return:
"""
print(datetime.datetime.now(),'连接断开回调')
def on_stock_order(self, order):
"""
委托回报推送
:param order: XtOrder对象
:return:
"""
print(datetime.datetime.now(), '委托回调', order.order_remark)
def on_stock_trade(self, trade):
"""
成交变动推送
:param trade: XtTrade对象
:return:
"""
print(datetime.datetime.now(), '成交回调', trade.order_remark)
def on_order_error(self, order_error):
"""
委托失败推送
:param order_error:XtOrderError 对象
:return:
"""
# print("on order_error callback")
# print(order_error.order_id, order_error.error_id, order_error.error_msg)
print(f"委托报错回调 {order_error.order_remark} {order_error.error_msg}")
def on_cancel_error(self, cancel_error):
"""
撤单失败推送
:param cancel_error: XtCancelError 对象
:return:
"""
print(datetime.datetime.now(), sys._getframe().f_code.co_name)
def on_order_stock_async_response(self, response):
"""
异步下单回报推送
:param response: XtOrderResponse 对象
:return:
"""
print(f"异步委托回调 {response.order_remark}")
def on_cancel_order_stock_async_response(self, response):
"""
:param response: XtCancelOrderResponse 对象
:return:
"""
print(datetime.datetime.now(), sys._getframe().f_code.co_name)
def on_account_status(self, status):
"""
:param response: XtAccountStatus 对象
:return:
"""
print(datetime.datetime.now(), sys._getframe().f_code.co_name)
if __name__ == '__main__':
print("start")
#指定客户端所在路径
path = r'D:\qmt\sp3\迅投极速交易终端 睿智融科版\userdata_mini'
# 生成session id 整数类型 同时运行的策略不能重复
session_id = int(time.time())
xt_trader = XtQuantTrader(path, session_id)
# 开启主动请求接口的专用线程 开启后在on_stock_xxx回调函数里调用XtQuantTrader.query_xxx函数不会卡住回调线程,但是查询和推送的数据在时序上会变得不确定
# 详见: http://docs.thinktrader.net/vip/pages/ee0e9b/#开启主动请求接口的专用线程
# xt_trader.set_relaxed_response_order_enabled(True)
# 创建资金账号为 800068 的证券账号对象
acc = StockAccount('800068', 'STOCK')
# 创建交易回调类对象,并声明接收回调
callback = MyXtQuantTraderCallback()
xt_trader.register_callback(callback)
# 启动交易线程
xt_trader.start()
# 建立交易连接,返回0表示连接成功
connect_result = xt_trader.connect()
print('建立交易连接,返回0表示连接成功', connect_result)
# 对交易回调进行订阅,订阅后可以收到交易主推,返回0表示订阅成功
subscribe_result = xt_trader.subscribe(acc)
print('对交易回调进行订阅,订阅后可以收到交易主推,返回0表示订阅成功', subscribe_result)
#这一行是注册全推回调函数 包括下单判断 安全起见处于注释状态 确认理解效果后再放开
# xtdata.subscribe_whole_quote(["SH", "SZ"], callback=f)
# 阻塞主线程退出
xt_trader.run_forever()
# 如果使用vscode pycharm等本地编辑器 可以进入交互模式 方便调试 (把上一行的run_forever注释掉 否则不会执行到这里)
interact()
需要开通miniQMT(低门槛,低费率)的朋友,
可以扫码联系:或者添加 技术公众号:
公众号:
银河证券1拖7
股票 • 李魔佛 发表了文章 • 0 个评论 • 2447 次浏览 • 2024-02-23 15:16
基本大家都用的银河证券或者华宝证券的1拖6,也就是一个证券账户,加挂 3个 深A,3个场内基金,6个账号可以同时申购 100元的印度基金。因为印度基金目前是限购状态,限购100元。
所以1拖6就可以申购600元。
目前每天稳定的溢价率为6-7%,一次的收益率为 6-7%,也就是30-40元一个账户一天。一周下来就有150-200元
这个看起来是个蚊子肉。
但如果你的证券账户足够多,比如你有10个证券账户(你女友,家人,亲戚,同事,朋友)
一周就有2000元。
所以限购套利的核心是 拖拉机+多账号
而很少人知道,其实可以1拖7,再多一个申购途径,就是场外申购。
比如支付宝,天天基金等渠道申购。不过要转入场内比较麻烦,而银河证券,华宝证券,内置了场外基金,可以很方便在券商app里面的场外基金买入(申购)。
步骤也很简单,
申购完成之后:
然后绑定场内和场外关系
然后要等T+2 之后,再在银河证券app里面 把印度基金从场外转到场内:
然后T+2之后,你的基金要继续等T+2之后才能到达你的证券账户。然后才能够在场内卖出。
所以通过场外转场内进行套利,要比场内支持申购,要晚2天到账的哦。
目前银河证券 低费率多多, 万0.854 免五,0.1元起,申购LOF基金1折,LOF卖出费率为万0.5,0.1元起。
逆回购1折。各个费率基本在同样档位里面是最低的了。
需要的朋友可以扫码联系开通: 查看全部
基本大家都用的银河证券或者华宝证券的1拖6,也就是一个证券账户,加挂 3个 深A,3个场内基金,6个账号可以同时申购 100元的印度基金。因为印度基金目前是限购状态,限购100元。
所以1拖6就可以申购600元。
目前每天稳定的溢价率为6-7%,一次的收益率为 6-7%,也就是30-40元一个账户一天。一周下来就有150-200元

这个看起来是个蚊子肉。
但如果你的证券账户足够多,比如你有10个证券账户(你女友,家人,亲戚,同事,朋友)
一周就有2000元。
所以限购套利的核心是 拖拉机+多账号
而很少人知道,其实可以1拖7,再多一个申购途径,就是场外申购。
比如支付宝,天天基金等渠道申购。不过要转入场内比较麻烦,而银河证券,华宝证券,内置了场外基金,可以很方便在券商app里面的场外基金买入(申购)。
步骤也很简单,

申购完成之后:

然后绑定场内和场外关系

然后要等T+2 之后,再在银河证券app里面 把印度基金从场外转到场内:

然后T+2之后,你的基金要继续等T+2之后才能到达你的证券账户。然后才能够在场内卖出。
所以通过场外转场内进行套利,要比场内支持申购,要晚2天到账的哦。
目前银河证券 低费率多多, 万0.854 免五,0.1元起,申购LOF基金1折,LOF卖出费率为万0.5,0.1元起。
逆回购1折。各个费率基本在同样档位里面是最低的了。
需要的朋友可以扫码联系开通:
开通银河拖拉机,申购一折,申购套利,印度基金LOF
券商万一免五 • 李魔佛 发表了文章 • 0 个评论 • 2120 次浏览 • 2024-02-22 01:31
虽然资金不多,申购100元。
但如果你的账号多,那么假如你有10个账号,那么一轮套利下来,你的盈利有 122 * 6 * 10 = 7200
而且因为有限购,所以套利算风险比较小。 只要点点手指头,就能够获得几千元的收益,何乐而不为?
但是1拖6,只有少数几个券商支持。 并且如果没有申购1折的话,也会有不少的损耗。
银河证券就是满足上面的条件。 但不一定全部的营业部都支持申购1折。
笔者这边合作的一个银河证券,支持万一免五,0.1起步。基金申购1折,逆回购1折,支持1拖6股东账号。
需要的可以扫码联系: 查看全部

1拖6,可以实现在限购的情况下,申购6次。 让你的绝对收益扩大6倍。
虽然资金不多,申购100元。
但如果你的账号多,那么假如你有10个账号,那么一轮套利下来,你的盈利有 122 * 6 * 10 = 7200
而且因为有限购,所以套利算风险比较小。 只要点点手指头,就能够获得几千元的收益,何乐而不为?
但是1拖6,只有少数几个券商支持。 并且如果没有申购1折的话,也会有不少的损耗。
银河证券就是满足上面的条件。 但不一定全部的营业部都支持申购1折。
笔者这边合作的一个银河证券,支持万一免五,0.1起步。基金申购1折,逆回购1折,支持1拖6股东账号。
需要的可以扫码联系:
QMT获取全市场股票,排除ST退市风险股票
QMT • 李魔佛 发表了文章 • 0 个评论 • 2565 次浏览 • 2024-02-07 22:25
def get_all_market_code(ContextInfo):
all_market_codes = [item for item in ContextInfo.get_stock_list_in_sector('沪深A股') if not item.endswith('BJ')]
return filter_ST_stock(ContextInfo, all_market_codes)
def filter_ST_stock(ContextInfo, code_list):
result =
for code in code_list:
if re.search('(st)|(ST)|(\*st)|(\*ST)|(退)',ContextInfo.get_stock_name(code)):
print('排除 : ',ContextInfo.get_stock_name(code),code)
continue
result.append(code)
return result
global_dict = {}
def init(ContextInfo):
now = time.ctime()
print('策略初始化{}'.format(now))
need_download = 1
global_dict['start_date'] = '20231201'
global_dict['end_date'] = ''
global_dict['code_list'] = get_all_market_code(ContextInfo)
有问题可以咨询公众号或者知识星球
提供策略代写服务
查看全部
def get_all_market_code(ContextInfo):
all_market_codes = [item for item in ContextInfo.get_stock_list_in_sector('沪深A股') if not item.endswith('BJ')]
return filter_ST_stock(ContextInfo, all_market_codes)
def filter_ST_stock(ContextInfo, code_list):
result =
for code in code_list:
if re.search('(st)|(ST)|(\*st)|(\*ST)|(退)',ContextInfo.get_stock_name(code)):
print('排除 : ',ContextInfo.get_stock_name(code),code)
continue
result.append(code)
return result
global_dict = {}
def init(ContextInfo):
now = time.ctime()
print('策略初始化{}'.format(now))
need_download = 1
global_dict['start_date'] = '20231201'
global_dict['end_date'] = ''
global_dict['code_list'] = get_all_market_code(ContextInfo)
有问题可以咨询公众号或者知识星球
提供策略代写服务
QMT实时获取涨停股,筛选流通盘大于X的股票
QMT • 李魔佛 发表了文章 • 0 个评论 • 3038 次浏览 • 2024-02-07 18:28
直接上代码:# coding:gbk
import time
class G():
pass
g = G()
def init(ContextInfo):
g.hsa = [item for item in ContextInfo.get_stock_list_in_sector('沪深A股') if not item.endswith('BJ')]
g.vol_dict = {}
for stock in g.hsa:
g.vol_dict[stock] = ContextInfo.get_last_volume(stock)
ContextInfo.run_time("execution", "1nSecond", "2019-10-14 13:20:00")
def execution(ContextInfo):
t0 = time.time()
full_tick = ContextInfo.get_full_tick(g.hsa)
total_market_value = 0
total_ratio = 0
count = 0
for stock in g.hsa:
if full_tick[stock]['lastClose'] == 0:
continue
ratio = full_tick[stock]['lastPrice'] / full_tick[stock]['lastClose'] - 1
rise_price = round(full_tick[stock]['lastClose'] * 1.2, 2) if stock[0] == '3' or stock[:3] == '688' else round(
full_tick[stock]['lastClose'] * 1.1, 2)
# 如果要打印涨停品种
if abs(full_tick[stock]['lastPrice'] - rise_price) <0.01:
print(f"涨停股票 {stock} {ContextInfo.get_stock_name(stock)}")
market_value = full_tick[stock]['lastPrice'] * g.vol_dict[stock]
total_ratio += ratio * market_value
total_market_value += market_value
count += 1
# print(count)
total_ratio /= total_market_value
total_ratio *= 100
print(f'A股加权涨幅 {round(total_ratio, 2)}% 函数运行耗时{round(time.time() - t0, 5)}秒')
欢迎关注公众号:
可转债量化分析 查看全部
直接上代码:
# coding:gbk
import time
class G():
pass
g = G()
def init(ContextInfo):
g.hsa = [item for item in ContextInfo.get_stock_list_in_sector('沪深A股') if not item.endswith('BJ')]
g.vol_dict = {}
for stock in g.hsa:
g.vol_dict[stock] = ContextInfo.get_last_volume(stock)
ContextInfo.run_time("execution", "1nSecond", "2019-10-14 13:20:00")
def execution(ContextInfo):
t0 = time.time()
full_tick = ContextInfo.get_full_tick(g.hsa)
total_market_value = 0
total_ratio = 0
count = 0
for stock in g.hsa:
if full_tick[stock]['lastClose'] == 0:
continue
ratio = full_tick[stock]['lastPrice'] / full_tick[stock]['lastClose'] - 1
rise_price = round(full_tick[stock]['lastClose'] * 1.2, 2) if stock[0] == '3' or stock[:3] == '688' else round(
full_tick[stock]['lastClose'] * 1.1, 2)
# 如果要打印涨停品种
if abs(full_tick[stock]['lastPrice'] - rise_price) <0.01:
print(f"涨停股票 {stock} {ContextInfo.get_stock_name(stock)}")
market_value = full_tick[stock]['lastPrice'] * g.vol_dict[stock]
total_ratio += ratio * market_value
total_market_value += market_value
count += 1
# print(count)
total_ratio /= total_market_value
total_ratio *= 100
print(f'A股加权涨幅 {round(total_ratio, 2)}% 函数运行耗时{round(time.time() - t0, 5)}秒')

欢迎关注公众号:
可转债量化分析
迅投QMT投研版 有必要开吗?
QMT • 李魔佛 发表了文章 • 0 个评论 • 2343 次浏览 • 2024-02-06 15:03
处处透出一股割韭菜的味道。
到处拉人进群,然后群里问问题,他们会让你私聊,加你,说服你开通投研版。
投研版无非多一些数据,你用tushare或者自己爬虫就可以获取,他们非要放到投研版里面,付费使用。
价格是一年8,9千,感觉没有一点性价比。
qmt,minniqmt有交易功能,有数据获取功能,也可以自己接入外部数据。没必要花那些冤枉钱去按年付费买一个不实用的数据。
真的没有数据,或者没有能力获取,付费找人写个api接口,爬虫数据,也不贵。 可以终身使用。 不好过按年付费???
关键那群qmt的人水平也不咋地,看他们的文档就知道,变量用A,B,C,D,人品也不咋地,星球上还抄袭我的星球文章,足以说明水平和人品。
群里问点问题,就让你开个投研版咨询哈。 还不如来我的qmt ptrade技术群的,free且有求必应哈。
查看全部
处处透出一股割韭菜的味道。
到处拉人进群,然后群里问问题,他们会让你私聊,加你,说服你开通投研版。
投研版无非多一些数据,你用tushare或者自己爬虫就可以获取,他们非要放到投研版里面,付费使用。
价格是一年8,9千,感觉没有一点性价比。
qmt,minniqmt有交易功能,有数据获取功能,也可以自己接入外部数据。没必要花那些冤枉钱去按年付费买一个不实用的数据。
真的没有数据,或者没有能力获取,付费找人写个api接口,爬虫数据,也不贵。 可以终身使用。 不好过按年付费???
关键那群qmt的人水平也不咋地,看他们的文档就知道,变量用A,B,C,D,人品也不咋地,星球上还抄袭我的星球文章,足以说明水平和人品。

群里问点问题,就让你开个投研版咨询哈。 还不如来我的qmt ptrade技术群的,free且有求必应哈。
qmt获取北交所实时行情数据
QMT • 李魔佛 发表了文章 • 0 个评论 • 2541 次浏览 • 2024-01-24 13:39
首先试试获取实时的行情:
我获取的是这个北交所股票的数据:
获取北交所行情数据如下:
#-*-coding:gbk-*-
import datetime
code = '838402.BJ'
def init(ContextInfo):
now = datetime.datetime.now()
print(now)
def handlebar(ContextInfo):
index = ContextInfo.barpos
realtime = ContextInfo.get_bar_timetag(index)
date = timetag_to_datetime(realtime, "%Y-%m-%d %H:%M:%S")
info = ContextInfo.get_full_tick(stock_code=["838402.BJ"])
print(info)
返回下面的数据:
对了下时间戳,是正确的。
然后试了下获取北交所的历史数据行情:
#-*-coding:gbk-*-
import datetime
code = '838402.BJ'
def init(ContextInfo):
now = datetime.datetime.now()
print(now)
download_history_data(code,"1d","20240105","")
def handlebar(ContextInfo):
index = ContextInfo.barpos
realtime = ContextInfo.get_bar_timetag(index)
date = timetag_to_datetime(realtime, "%Y-%m-%d %H:%M:%S")
print(date)
hist = ContextInfo.get_market_data_ex(['close'],[code], period = "1d",count = 1)
print(hist)
代码里面我想用 download_history_data(code,"1d","20240105","") 下载历史数据。
在数据目录里面也能够获取到这个股票的历史数据文件。
可是在qmt里面却输出的是个空的dataframe。
数据目录下面是有数据的。。
感觉是qmt里面的功能还没有完善对北交所股票的支持。
查看全部
首先试试获取实时的行情:
我获取的是这个北交所股票的数据:

获取北交所行情数据如下:
#-*-coding:gbk-*-
import datetime
code = '838402.BJ'
def init(ContextInfo):
now = datetime.datetime.now()
print(now)
def handlebar(ContextInfo):
index = ContextInfo.barpos
realtime = ContextInfo.get_bar_timetag(index)
date = timetag_to_datetime(realtime, "%Y-%m-%d %H:%M:%S")
info = ContextInfo.get_full_tick(stock_code=["838402.BJ"])
print(info)
返回下面的数据:

对了下时间戳,是正确的。
然后试了下获取北交所的历史数据行情:
#-*-coding:gbk-*-
import datetime
code = '838402.BJ'
def init(ContextInfo):
now = datetime.datetime.now()
print(now)
download_history_data(code,"1d","20240105","")
def handlebar(ContextInfo):
index = ContextInfo.barpos
realtime = ContextInfo.get_bar_timetag(index)
date = timetag_to_datetime(realtime, "%Y-%m-%d %H:%M:%S")
print(date)
hist = ContextInfo.get_market_data_ex(['close'],[code], period = "1d",count = 1)
print(hist)
代码里面我想用 download_history_data(code,"1d","20240105","") 下载历史数据。
在数据目录里面也能够获取到这个股票的历史数据文件。
可是在qmt里面却输出的是个空的dataframe。

数据目录下面是有数据的。。

感觉是qmt里面的功能还没有完善对北交所股票的支持。
华泰matic能在虚拟机运行吗?
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 1519 次浏览 • 2024-01-05 09:36
但matic却可以在hyper X虚拟机上运行。笔者在win11家庭版的hyper x测试过的。
但matic却可以在hyper X虚拟机上运行。笔者在win11家庭版的hyper x测试过的。

ptrade调试经验分享(坑) 委托成交回调函数
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 2238 次浏览 • 2023-12-22 10:30
之前的代码里面,由于少了一个if,导致如果code不在
g.start_buy_sell_queue
这个集合里面的话,就会报错。(但正常情况下都会有值,但问题就出现在一些特殊情况下)
不然你试试在
on_trade_response
里面直接raise一个Exception出来,日志里也不会有任何显示。
切近!!
on_trade_response 里面做好安全防护!! 最好是有些业务逻辑完成了在里面print一下,以确保是执行到后面的。 查看全部

之前的代码里面,由于少了一个if,导致如果code不在
g.start_buy_sell_queue
这个集合里面的话,就会报错。(但正常情况下都会有值,但问题就出现在一些特殊情况下)
不然你试试在
on_trade_response
里面直接raise一个Exception出来,日志里也不会有任何显示。
切近!!
on_trade_response 里面做好安全防护!! 最好是有些业务逻辑完成了在里面print一下,以确保是执行到后面的。
免费部署自己的Google大模型Gemini在线服务!白嫖!【手把手保姆教程】
AI应用 • 马化云 发表了文章 • 0 个评论 • 2806 次浏览 • 2023-12-17 21:11
谷歌表示,该公司备受期待的人工智能模型名为Gemini,对比之前的技术,能够进行更复杂的推理,理解更加细微的信息。它通过阅读、过滤和理解信息,可以从数十万份文件中提取要点,将有助于在从科学到金融的许多领域实现新的突破。
谷歌首席执行官桑达尔·皮查伊在一篇博文中写道:“这个新模型代表了我们作为一家科技公司所做的最大的科学和工程努力之一,它也是一个多模态基础模型,可以概括和理解不同类型的信息,包括文本、代码、音频、图像和视频。”
好了,听起来好像很牛的样子。今天笔者带大家免费部署一个免费的基于Gemini的免费在线网站!不需要GPU,不需要花钱!
注意:本教程需要有Github账户和Vercel账户,没有的话需要先去注册一个哦。反正都是免费的,不花钱哟
fork github项目
github 克隆或者fork一个基于个gemini的前端页面:
https://github.com/Rockyzsu/GeminiChat
申请Google Gemini API Key
申请google gemini api key
https://makersuite.google.com/app/apikey
这里有个要注意的地方,目前这个API是免费申请的,但仅限于美国IP,所以需要有科学家上网方式哟,而且要选择美帝的IP。
申请后会拿到一个KEY,如:
AIza***************************
后面要用到。
vercel部署
fork这个项目之后,在README里面有个“Deploy with Vercel”
Vercel是啥?
【Vercel 是知名的网站托管平台,可以高效创建和部署 Web 应用程序,类似于Github pages 和 Netlify. 但远为更加强大,速度也很快。与Github账号连接可以无缝衔接对网站进行构建和部署,并且每次提交commit之后会自动更新网站。】
不知道也没有关系。直接按照步骤操作就可以了。
点击了Deploy按钮之后,会跳转到vercel的网站,你需要提前注册并登录好哦,不然会跳转到注册页面。
然后会让你输入一个repository name,它需要在你的github里面创建一个新仓库来部署这个新应用,名字随意填。
然后填入刚刚申请的Google Gemini key
点击Deploy,等待大概一分钟左右,你的程序就可以部署好了。
耐心等待1分钟后,你会看到这个页面,恭喜你,代表部署成功了!
然后点击右上角的Continue to dashboard。
这里你可以看到你上面部署好的域名了。
因为用的是vercel免费服务,所以vercel会提供一个二级域名给你。你可以用这个二级域名直接访问你的网站,比如上面的:
https://geminiweb.vercel.app/
它是直接用可以用浏览器打开。(如果访问不到,可能需要用科学家访问哟)
它是直接用可以用浏览器打开。(如果访问不到,可能需要用科学家访问哟)
看起来,效果还是不错的哟。
而且全程白嫖不花钱!
好了,下次再带大家部署更多好玩好用的AI应用,我是AI应用全栈工程师。
查看全部

谷歌表示,该公司备受期待的人工智能模型名为Gemini,对比之前的技术,能够进行更复杂的推理,理解更加细微的信息。它通过阅读、过滤和理解信息,可以从数十万份文件中提取要点,将有助于在从科学到金融的许多领域实现新的突破。
谷歌首席执行官桑达尔·皮查伊在一篇博文中写道:“这个新模型代表了我们作为一家科技公司所做的最大的科学和工程努力之一,它也是一个多模态基础模型,可以概括和理解不同类型的信息,包括文本、代码、音频、图像和视频。”
好了,听起来好像很牛的样子。今天笔者带大家免费部署一个免费的基于Gemini的免费在线网站!不需要GPU,不需要花钱!

注意:本教程需要有Github账户和Vercel账户,没有的话需要先去注册一个哦。反正都是免费的,不花钱哟
fork github项目
github 克隆或者fork一个基于个gemini的前端页面:
https://github.com/Rockyzsu/GeminiChat

申请Google Gemini API Key
申请google gemini api key
https://makersuite.google.com/app/apikey

这里有个要注意的地方,目前这个API是免费申请的,但仅限于美国IP,所以需要有科学家上网方式哟,而且要选择美帝的IP。
申请后会拿到一个KEY,如:
AIza***************************
后面要用到。
vercel部署
fork这个项目之后,在README里面有个“Deploy with Vercel”

Vercel是啥?
【Vercel 是知名的网站托管平台,可以高效创建和部署 Web 应用程序,类似于Github pages 和 Netlify. 但远为更加强大,速度也很快。与Github账号连接可以无缝衔接对网站进行构建和部署,并且每次提交commit之后会自动更新网站。】
不知道也没有关系。直接按照步骤操作就可以了。
点击了Deploy按钮之后,会跳转到vercel的网站,你需要提前注册并登录好哦,不然会跳转到注册页面。
然后会让你输入一个repository name,它需要在你的github里面创建一个新仓库来部署这个新应用,名字随意填。

然后填入刚刚申请的Google Gemini key

点击Deploy,等待大概一分钟左右,你的程序就可以部署好了。

耐心等待1分钟后,你会看到这个页面,恭喜你,代表部署成功了!

然后点击右上角的Continue to dashboard。

这里你可以看到你上面部署好的域名了。
因为用的是vercel免费服务,所以vercel会提供一个二级域名给你。你可以用这个二级域名直接访问你的网站,比如上面的:
https://geminiweb.vercel.app/
它是直接用可以用浏览器打开。(如果访问不到,可能需要用科学家访问哟)

它是直接用可以用浏览器打开。(如果访问不到,可能需要用科学家访问哟)

看起来,效果还是不错的哟。
而且全程白嫖不花钱!
好了,下次再带大家部署更多好玩好用的AI应用,我是AI应用全栈工程师。
ptrade精确参与集合竞价交易 时间设置问题
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 2537 次浏览 • 2023-11-16 10:10
查了下日志。run_daily 设置的9:25运行,下单委托的时间在9:25:01 这个时间就被推到9:30开盘去成交了。
所以实际没有参与到9:25的集合竞价。
所以要参与集合竞价,需要设定在9:24分开始,然后不断在一个循环里面,用更小的时间颗粒,比如100ms去监听。
等到9:24:59的时间,才去下单。
import datetime
import time
RUN_TIME = '09:24'
def execution(context):
while 1:
current_second = datetime.datetime.now().strftime('%S')
if current_second >= '58':
break
time.sleep(0.1)
do_something()
def initialize(context):
# 初始化策略
run_daily(context, execution, RUN_TIME)
def handle_data(context, data):
pass
具体代码可以参照我的知识星球
查看全部
查了下日志。run_daily 设置的9:25运行,下单委托的时间在9:25:01 这个时间就被推到9:30开盘去成交了。
所以实际没有参与到9:25的集合竞价。
所以要参与集合竞价,需要设定在9:24分开始,然后不断在一个循环里面,用更小的时间颗粒,比如100ms去监听。
等到9:24:59的时间,才去下单。
import datetime
import time
RUN_TIME = '09:24'
def execution(context):
while 1:
current_second = datetime.datetime.now().strftime('%S')
if current_second >= '58':
break
time.sleep(0.1)
do_something()
def initialize(context):
# 初始化策略
run_daily(context, execution, RUN_TIME)
def handle_data(context, data):
pass


具体代码可以参照我的知识星球

迅投官网的示例代码真的无眼看。。。
QMT • 李魔佛 发表了文章 • 0 个评论 • 2191 次浏览 • 2023-11-10 01:17
变量名,类名用A ,B,C 噗, 没有一点含义,做什么鬼
class a():
pass
A = a()而且也不符合python风格。。。python类名推荐的大写字母开头,实例化对象用小写字母。
所以退一万步讲,上面的代码正常点的程序员写也应该是这样的。
class A():
pass
a = A()
其实正确的应该class GlobalCls():
pass
g = GlobalCls()
其他地方也是有这个毛病。
把代码喂给GPT,让它来分析一下:
得到如下结果:文件编码声明: #coding:gbk 是指定源文件的编码格式为GBK。在Python 3中,通常使用UTF-8作为文件编码格式,因此可以将该行删除或更改为#coding:utf-8。
类名和函数名: 根据PEP 8命名约定,类名应该使用大写字母开头的驼峰命名法(例如A改为A)。同样,函数名应该使用小写字母开头的小写命名法(例如init改为init,f改为f)。
类和实例: 在代码中定义了一个空类a,但没有给它任何属性或方法。如果不需要这个类,可以将其删除。
缩进和代码格式: Python非常依赖于正确的缩进,以指示代码块的层次结构。请确保代码的缩进是一致的,并使用适当的缩进级别(通常是4个空格)。
代码注释: 代码中有一些注释,但是大部分是被注释掉的。良好的注释可以增加代码的可读性和可维护性,建议在关键部分添加更多有用的注释。
异常处理: 代码中没有包含任何异常处理机制。在实际应用中,建议对可能引发异常的操作进行适当的异常处理,以提高代码的健壮性。
然后里面计算涨停是这样的: rise_price = round(full_tick[stock]['lastClose'] *1.2,2) if stock[0] == '3' or stock[:3] == '688' else round(full_tick[stock]['lastClose'] *1.1,2)
用昨收价* 1.2和1.1判断当前是否涨跌停。 首先,没有考虑到ST股,部分ST是5%涨停的。
其次,是直接用的昨收价,如果当天是分红除权日,昨收价没有做除权处理,得到的涨跌幅也是不准的。
当然这个文档最大的问题是,很多示例代码运行是直接报错的!!
查看全部

如果拿去做code review,估计会被喷的体无完肤。
变量名,类名用A ,B,C 噗, 没有一点含义,做什么鬼
class a():而且也不符合python风格。。。python类名推荐的大写字母开头,实例化对象用小写字母。
pass
A = a()
所以退一万步讲,上面的代码正常点的程序员写也应该是这样的。
class A():
pass
a = A()
其实正确的应该
class GlobalCls():
pass
g = GlobalCls()
其他地方也是有这个毛病。
把代码喂给GPT,让它来分析一下:
得到如下结果:
文件编码声明: #coding:gbk 是指定源文件的编码格式为GBK。在Python 3中,通常使用UTF-8作为文件编码格式,因此可以将该行删除或更改为#coding:utf-8。
类名和函数名: 根据PEP 8命名约定,类名应该使用大写字母开头的驼峰命名法(例如A改为A)。同样,函数名应该使用小写字母开头的小写命名法(例如init改为init,f改为f)。
类和实例: 在代码中定义了一个空类a,但没有给它任何属性或方法。如果不需要这个类,可以将其删除。
缩进和代码格式: Python非常依赖于正确的缩进,以指示代码块的层次结构。请确保代码的缩进是一致的,并使用适当的缩进级别(通常是4个空格)。
代码注释: 代码中有一些注释,但是大部分是被注释掉的。良好的注释可以增加代码的可读性和可维护性,建议在关键部分添加更多有用的注释。
异常处理: 代码中没有包含任何异常处理机制。在实际应用中,建议对可能引发异常的操作进行适当的异常处理,以提高代码的健壮性。
然后里面计算涨停是这样的:
rise_price = round(full_tick[stock]['lastClose'] *1.2,2) if stock[0] == '3' or stock[:3] == '688' else round(full_tick[stock]['lastClose'] *1.1,2)
用昨收价* 1.2和1.1判断当前是否涨跌停。 首先,没有考虑到ST股,部分ST是5%涨停的。
其次,是直接用的昨收价,如果当天是分红除权日,昨收价没有做除权处理,得到的涨跌幅也是不准的。
当然这个文档最大的问题是,很多示例代码运行是直接报错的!!
hongkongdoll 玩偶姐 炒币破产的真相原来是。。
闲聊 • 马化云 发表了文章 • 0 个评论 • 4623 次浏览 • 2023-11-08 11:22
关于你们的玩偶姐姐破产一事
和成人内容生产者相比,你们这些炒市赌狗都是垃圾
不要以为换个投资、加密...这种词汇就不是赌博了
我来把故事完整地说一遍
一个成人内容自媒体小姐姐,P站TOP5占了2年时间,仅广告分成部分就收入
颇丰,加上影片零售,比你创建一个科技公司融的资还要多。
纽约时报给P站干到不能直接卖片之后开通Onlyfans,继续获得稳定收入。
后来....
小姐姐还是有点儿才情,爱画像素点阵图,彼时加密艺术盛行,在一席子的帮助
合作下发布了自已的NFT,但还是太慢,NFT哪有炒币快?慢慢开始尝试交易,
有赚有赔,赚的多,赔的少,甚是兴奋。遂步将现金资产全部投入到加密市场。
在这过程中,内容生产业务懈意,近乎停滞。
所谓日久生情,这两年时间,有合作,有情,说不清。成人内容换得的进项趋
缓、停滞,市场又低迷,磨损甚多,所谓的交易损失,是合作者悄悄的春了还是
镇的亏了,也是不得而知。
带她接触并深入加密领域的屌子觉得是时候抽身离去,直接扫走现存加密资产,
这和银行的现金存储比,差别在于难以追查、追责,而她的钱几乎全在里面。
可怜的玩偶姐姐甚至不知道自已的钱到底是怎么没了的,是不是受骗上当了?还
是真的被盗了?还是真的爆仓亏光了?她找不到真实线索的答案。
你们瞻猜的
1.直播泄露私钥-要操作多少步才能泄露私钥可能性近乎为零
2.爆仓号完-她三四年的积累一时半伙亏不完
3.炒作F.T-但凡有点儿见识也能知道炒作这个炒一死也不如卖蔓荣
只是一个骗子连哄带骗偷偷掌走了姑娘的辛苦钱
查看全部
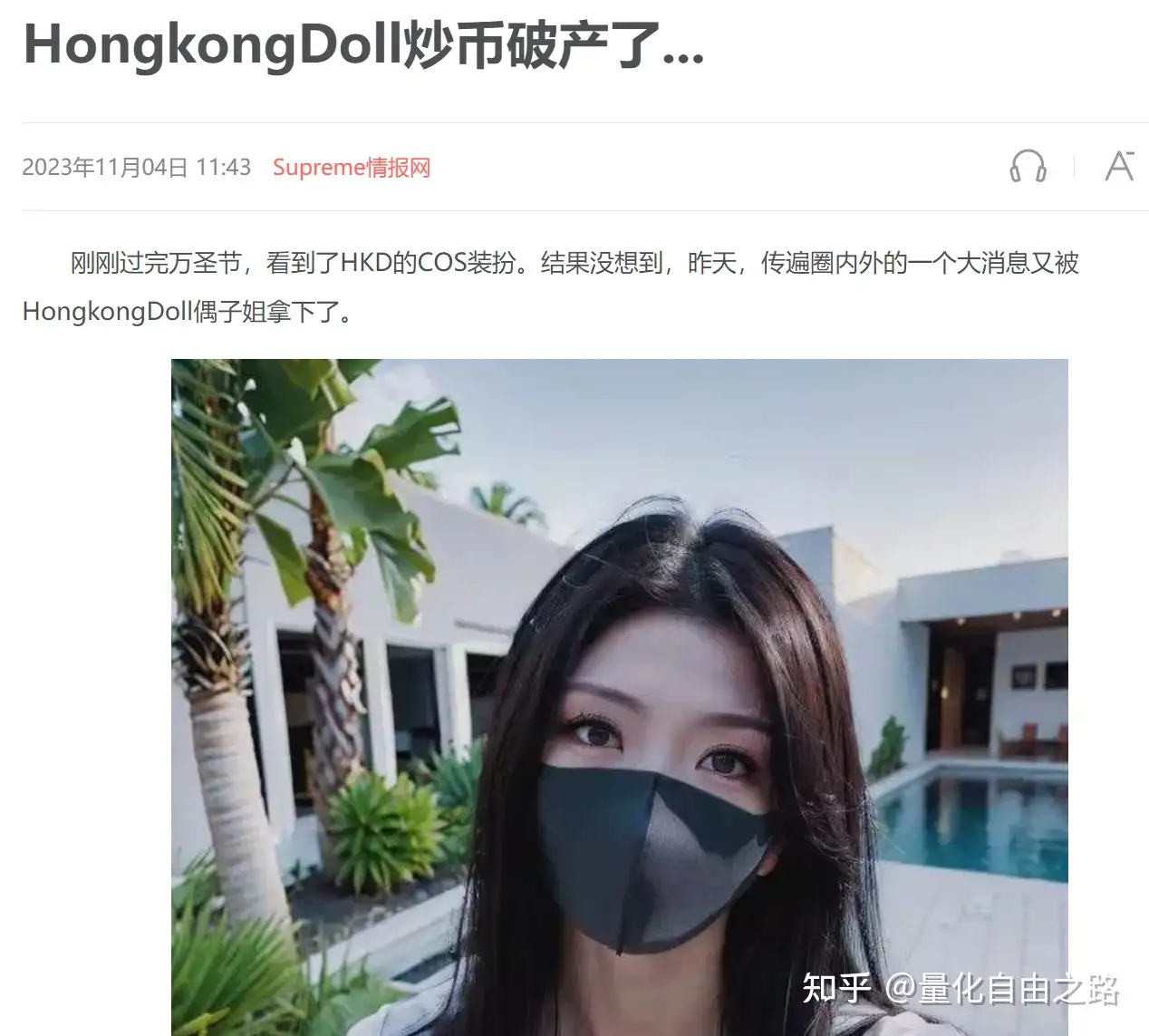
关于你们的玩偶姐姐破产一事
和成人内容生产者相比,你们这些炒市赌狗都是垃圾
不要以为换个投资、加密...这种词汇就不是赌博了
我来把故事完整地说一遍
一个成人内容自媒体小姐姐,P站TOP5占了2年时间,仅广告分成部分就收入
颇丰,加上影片零售,比你创建一个科技公司融的资还要多。
纽约时报给P站干到不能直接卖片之后开通Onlyfans,继续获得稳定收入。
后来....
小姐姐还是有点儿才情,爱画像素点阵图,彼时加密艺术盛行,在一席子的帮助
合作下发布了自已的NFT,但还是太慢,NFT哪有炒币快?慢慢开始尝试交易,
有赚有赔,赚的多,赔的少,甚是兴奋。遂步将现金资产全部投入到加密市场。
在这过程中,内容生产业务懈意,近乎停滞。
所谓日久生情,这两年时间,有合作,有情,说不清。成人内容换得的进项趋
缓、停滞,市场又低迷,磨损甚多,所谓的交易损失,是合作者悄悄的春了还是
镇的亏了,也是不得而知。
带她接触并深入加密领域的屌子觉得是时候抽身离去,直接扫走现存加密资产,
这和银行的现金存储比,差别在于难以追查、追责,而她的钱几乎全在里面。
可怜的玩偶姐姐甚至不知道自已的钱到底是怎么没了的,是不是受骗上当了?还
是真的被盗了?还是真的爆仓亏光了?她找不到真实线索的答案。
你们瞻猜的
1.直播泄露私钥-要操作多少步才能泄露私钥可能性近乎为零
2.爆仓号完-她三四年的积累一时半伙亏不完
3.炒作F.T-但凡有点儿见识也能知道炒作这个炒一死也不如卖蔓荣
只是一个骗子连哄带骗偷偷掌走了姑娘的辛苦钱
阿里云双十一主机优惠 2核2G内存,3M带宽云主机,99一年,而且续费不涨价
网络 • 马化云 发表了文章 • 0 个评论 • 1868 次浏览 • 2023-11-08 02:27
关键这个活动是新老用户都可以参加。 而且续费价格依然是99。 用过腾讯云的用户就知道,对于新用户优惠力度很大,可是到了到期要续费的时候,腾讯就是市值开大口,原来300块3年的新客服务器,续费要1500以上的价格。
正所谓老用户不如狗。
这次阿里云特意写明,老用户也可以参与这个优惠购买活动,而且续费也还可以原价续费。
这个2CPU,2G内存,40GBSSD存储,3M带宽的服务器,配置如何?
点击购买链接:
https://www.aliyun.com/minisite/goods?userCode=nebb965s
进去后看到价格的确是99元。(是的,上面的是我的推广链接,阿里云应该会返现几个点给我吧哈哈,当作给我现在这个网站的服务器托管费用吧,还能坚持给你们持续输出高质量原创内容哈哈)
这个活动持续到 2026年3月31日 ! 所以如果你手上有其他服务器 还没有到期的话,可以不用着急买哈,可以等等哈,反正有2年半的时候,你喜欢什么时候去买都可以哈。
所以看好的朋友可以放到收藏夹,等需要的时候再买。 不过提前买也行,里面可以安装个windows系统,把QMT部署到上面,一年才99块,网络稳定性可能要好过你本地的电脑。而且随时随地都可以上去看看QMT当前的运行状态。只要用windows的远程桌面就可以连上去了。
反正到期了,续费也只要99元。
顺便给你看看腾讯云现在的续费策略:
3年前买的一台轻量云服务器,费用只要199。
而现在续费,续费一年就要1500了呀。
当年买入的价格:
点击查看大图
现在续费的价格:
只能说对新用户的时候就是良心云。 对着老用户就是一顿割韭菜了。
反正需要的99元一年,且续费不涨价的阿里云服务器朋友,可以使用下面的链接购买哟。
https://www.aliyun.com/minisite/goods?userCode=nebb965s
查看全部
关键这个活动是新老用户都可以参加。 而且续费价格依然是99。 用过腾讯云的用户就知道,对于新用户优惠力度很大,可是到了到期要续费的时候,腾讯就是市值开大口,原来300块3年的新客服务器,续费要1500以上的价格。
正所谓老用户不如狗。
这次阿里云特意写明,老用户也可以参与这个优惠购买活动,而且续费也还可以原价续费。
这个2CPU,2G内存,40GBSSD存储,3M带宽的服务器,配置如何?



点击购买链接:
https://www.aliyun.com/minisite/goods?userCode=nebb965s
进去后看到价格的确是99元。(是的,上面的是我的推广链接,阿里云应该会返现几个点给我吧哈哈,当作给我现在这个网站的服务器托管费用吧,还能坚持给你们持续输出高质量原创内容哈哈)

这个活动持续到 2026年3月31日 ! 所以如果你手上有其他服务器 还没有到期的话,可以不用着急买哈,可以等等哈,反正有2年半的时候,你喜欢什么时候去买都可以哈。

所以看好的朋友可以放到收藏夹,等需要的时候再买。 不过提前买也行,里面可以安装个windows系统,把QMT部署到上面,一年才99块,网络稳定性可能要好过你本地的电脑。而且随时随地都可以上去看看QMT当前的运行状态。只要用windows的远程桌面就可以连上去了。
反正到期了,续费也只要99元。
顺便给你看看腾讯云现在的续费策略:
3年前买的一台轻量云服务器,费用只要199。
而现在续费,续费一年就要1500了呀。
当年买入的价格:

点击查看大图
现在续费的价格:

只能说对新用户的时候就是良心云。 对着老用户就是一顿割韭菜了。
反正需要的99元一年,且续费不涨价的阿里云服务器朋友,可以使用下面的链接购买哟。
https://www.aliyun.com/minisite/goods?userCode=nebb965s
QMT | Ptrade 量化策略代写服务
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 3458 次浏览 • 2023-11-01 10:43
多年交易经验,量化交易与开发经验。所以很多策略,其实用户大体描述,就知道要注意哪些地方,会提出一些建议,用户要注意,需不需要添加一些判读条件等等。(当然,策略的具体参数都是设置可以调节的,你不需要把实际的参数告诉我,代码给你后,你自己运行策略的时候把你策略的真正参数填上去就好了。)
有偿,收费,价格美丽。根据策略实际的复杂程度与预估的工时,收费。(不根据代码数量,因为我写代码很精简)
我也帮你们咨询过了迅投的客服。 因为他们官网也有提供策略代写服务。他们是不问你策略,直接是5000起步哦。然后根据策略,在5000的基础上不断加。
咨询完,我都感觉我自己以前的报价太低了,呜。
PS: 之前还有迅投的前员工私底下接单写策略,然后到我的星球里面白嫖我的代码,调用我接口数据,被我发现后举报到星球的。后面那个客户发现代码里面藏有我的公众号信息哈,找到我让我修改接口数据哈。
需要的代写策略的盆友,可以关注公众号,在菜单栏那里的“代写量化程序”或者 后台回复:策略代写,获取联系方式哦
扫码关注公众号:
查看全部

迅投的QMT和恒生电子的Ptrade, 还有掘金, 量化策略编程, 实盘和回测都行。只要你的需求明确,白纸黑字描述清楚,都可以做。股票,ETF,可转债都行。
多年交易经验,量化交易与开发经验。所以很多策略,其实用户大体描述,就知道要注意哪些地方,会提出一些建议,用户要注意,需不需要添加一些判读条件等等。(当然,策略的具体参数都是设置可以调节的,你不需要把实际的参数告诉我,代码给你后,你自己运行策略的时候把你策略的真正参数填上去就好了。)
有偿,收费,价格美丽。根据策略实际的复杂程度与预估的工时,收费。(不根据代码数量,因为我写代码很精简)
我也帮你们咨询过了迅投的客服。 因为他们官网也有提供策略代写服务。他们是不问你策略,直接是5000起步哦。然后根据策略,在5000的基础上不断加。


咨询完,我都感觉我自己以前的报价太低了,呜。
PS: 之前还有迅投的前员工私底下接单写策略,然后到我的星球里面白嫖我的代码,调用我接口数据,被我发现后举报到星球的。后面那个客户发现代码里面藏有我的公众号信息哈,找到我让我修改接口数据哈。
需要的代写策略的盆友,可以关注公众号,在菜单栏那里的“代写量化程序”或者 后台回复:策略代写,获取联系方式哦
扫码关注公众号:
QMT获取A股全市场股票代码
QMT • 李魔佛 发表了文章 • 0 个评论 • 2304 次浏览 • 2023-10-25 15:23
"沪深A股"
完整代码:#-*-coding:gbk-*-
import time
start = False
ACCOUNT = ''
def init(ContextInfo):
now = time.ctime()
print(now)
ContextInfo.run_time("execution","30nSecond","2023-04-14 13:20:00")
def execution(ContextInfo):
data = ContextInfo.get_stock_list_in_sector('沪深A股')
print(len(data))
def handlebar(ContextInfo):
pass
当前共有5047只股票【2023-10-25 15:18:45.533】 start trading mode
【2023-10-25 15:18:45.533】 Wed Oct 25 15:18:45 2023
【2023-10-25 15:18:45.533】 5074
['000001.SZ', '000002.SZ', '000004.SZ', '000005.SZ', '000006.SZ', '000007.SZ', '000008.SZ', '000009.SZ', '000010.SZ', '000011.SZ', '000012.SZ', '000014.SZ', '000016.SZ', '000017.SZ', '000019.SZ', '000020.SZ', '000021.SZ', '000023.SZ', '000025.SZ', '000026.SZ', '000027.SZ', '000028.SZ', '000029.SZ', '000030.SZ', '000031.SZ', '000032.SZ', '000034.SZ', '000035.SZ', '000036.SZ', '000037.SZ', '000039.SZ', '000040.SZ', '000042.SZ', '000045.SZ', '000046.SZ', '000048.SZ', '000049.SZ', '000050.SZ', '000055.SZ', '000056.SZ', '000058.SZ', '000059.SZ', '000060.SZ', '000061.SZ', '000062.SZ', '000063.SZ', '000065.SZ', '000066.SZ', '000068.SZ', '000069.SZ', '000070.SZ', '000078.SZ', '000088.SZ', '000089.SZ', '000090.SZ', '000096.SZ', '000099.SZ', '000100.SZ', '000151.SZ', '000153.SZ', '000155.SZ', '000156.SZ', '000157.SZ', '000158.SZ', '000159.SZ', '000166.SZ', '000301.SZ', '000333.SZ', '000338.SZ', '000400.SZ', '000401.SZ', '000402.SZ', '000403.SZ', '000404.SZ', '000407.SZ', '000408.SZ', '000409.SZ', '000410.SZ', '000411.SZ', '000413.SZ', '000415.SZ', '000416.SZ', '000417.SZ', '000419.SZ', '000420.SZ', '000421.SZ', '000422.SZ', '000423.SZ', '000425.SZ', '000426.SZ',省略若干...
点击查看大图
是否遇到QMT或Ptrade的问题, 无从入手? 或者咨询无门 ?
来加入 知识星球 , 获取专业的技术解答, 量化实盘代码, 技术交流群
查看全部
"沪深A股"
完整代码:
#-*-coding:gbk-*-
import time
start = False
ACCOUNT = ''
def init(ContextInfo):
now = time.ctime()
print(now)
ContextInfo.run_time("execution","30nSecond","2023-04-14 13:20:00")
def execution(ContextInfo):
data = ContextInfo.get_stock_list_in_sector('沪深A股')
print(len(data))
def handlebar(ContextInfo):
pass
当前共有5047只股票
【2023-10-25 15:18:45.533】 start trading mode省略若干...
【2023-10-25 15:18:45.533】 Wed Oct 25 15:18:45 2023
【2023-10-25 15:18:45.533】 5074
['000001.SZ', '000002.SZ', '000004.SZ', '000005.SZ', '000006.SZ', '000007.SZ', '000008.SZ', '000009.SZ', '000010.SZ', '000011.SZ', '000012.SZ', '000014.SZ', '000016.SZ', '000017.SZ', '000019.SZ', '000020.SZ', '000021.SZ', '000023.SZ', '000025.SZ', '000026.SZ', '000027.SZ', '000028.SZ', '000029.SZ', '000030.SZ', '000031.SZ', '000032.SZ', '000034.SZ', '000035.SZ', '000036.SZ', '000037.SZ', '000039.SZ', '000040.SZ', '000042.SZ', '000045.SZ', '000046.SZ', '000048.SZ', '000049.SZ', '000050.SZ', '000055.SZ', '000056.SZ', '000058.SZ', '000059.SZ', '000060.SZ', '000061.SZ', '000062.SZ', '000063.SZ', '000065.SZ', '000066.SZ', '000068.SZ', '000069.SZ', '000070.SZ', '000078.SZ', '000088.SZ', '000089.SZ', '000090.SZ', '000096.SZ', '000099.SZ', '000100.SZ', '000151.SZ', '000153.SZ', '000155.SZ', '000156.SZ', '000157.SZ', '000158.SZ', '000159.SZ', '000166.SZ', '000301.SZ', '000333.SZ', '000338.SZ', '000400.SZ', '000401.SZ', '000402.SZ', '000403.SZ', '000404.SZ', '000407.SZ', '000408.SZ', '000409.SZ', '000410.SZ', '000411.SZ', '000413.SZ', '000415.SZ', '000416.SZ', '000417.SZ', '000419.SZ', '000420.SZ', '000421.SZ', '000422.SZ', '000423.SZ', '000425.SZ', '000426.SZ',
点击查看大图

是否遇到QMT或Ptrade的问题, 无从入手? 或者咨询无门 ?
来加入 知识星球 , 获取专业的技术解答, 量化实盘代码, 技术交流群
国金证券 国盛证券 QMT仿真客户端 PTrade仿真客户端 QMT测试版 Ptrade测试版
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 4014 次浏览 • 2023-10-22 12:54
国金证券 - QMT测试账号信息: 登录账号:*********** 登录密码:**********
QMT交易测试客户端下载链接 链接:
https://download.gjzq.com.cn/temp/organ/gjzqqmt_ceshi.rar
国金证券 - ptrade测试账号信息: 登录账号:********* 登录密码:********
ptrade交易测试客户端下载链接 链接:
https://download.gjzq.com.cn/temp/organ/gjzqptrade_ceshi.rar
测试时间10:00--17:00 如有什么问题,请和我们联系。谢谢!
下面是国盛证券提供的试用账户:
国盛证券 - 国盛智投软件下载(测试版)Ptrade
https://download.gszq.com/ptrade/PTrade1.0-Client-V201906-00-000.zip
仿真账户:******* / ********
量化回测:支持1分钟、日线回测。
量化交易:支持LEVEL1 tick股票交易。
量化研究:提供云Ipython Notebook研究环境、行情数据2005年至今、可使用全市场金融数据。
国盛证券-迅投QMT软件下载(测试版)
https://download.gszq.com/xt/XtItClient_x64_QMT_test_1.0.0.22650.exe
仿真账户:*******/********
支持VBA、Python开发策略 可以安装第三方库 软件帮助有文档,测试版历史数据不是很准确,以熟悉界面为主。
如果需要测试账号, 需要开通券商账号后找券商经理获取.
可以扫码联系开通
查看全部

下面是国金证券提供的试用账户:
国金证券 - QMT测试账号信息: 登录账号:*********** 登录密码:**********
QMT交易测试客户端下载链接 链接:
https://download.gjzq.com.cn/temp/organ/gjzqqmt_ceshi.rar
国金证券 - ptrade测试账号信息: 登录账号:********* 登录密码:********
ptrade交易测试客户端下载链接 链接:
https://download.gjzq.com.cn/temp/organ/gjzqptrade_ceshi.rar
测试时间10:00--17:00 如有什么问题,请和我们联系。谢谢!
下面是国盛证券提供的试用账户:
国盛证券 - 国盛智投软件下载(测试版)Ptrade
https://download.gszq.com/ptrade/PTrade1.0-Client-V201906-00-000.zip
仿真账户:******* / ********
量化回测:支持1分钟、日线回测。
量化交易:支持LEVEL1 tick股票交易。
量化研究:提供云Ipython Notebook研究环境、行情数据2005年至今、可使用全市场金融数据。
国盛证券-迅投QMT软件下载(测试版)
https://download.gszq.com/xt/XtItClient_x64_QMT_test_1.0.0.22650.exe
仿真账户:*******/********
支持VBA、Python开发策略 可以安装第三方库 软件帮助有文档,测试版历史数据不是很准确,以熟悉界面为主。
如果需要测试账号, 需要开通券商账号后找券商经理获取.
可以扫码联系开通
ptrade 全局对象g持久化对象保存失败
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 2153 次浏览 • 2023-10-18 09:36
File "./fly_docker/IQEngine/utils/global_variable.py", line 50, in save
_pickle.PicklingError: Can't pickle <class 'IQEngine.user_module.PositionManager'>: attribute lookup PositionManager on IQEngine.user_module failed
原因是全局变量g 不能被持久化, 需要前面加__, 比如g.Name 要改成 g.__Name
全局变量g中不能被序列化的变量将不会被保存。您可在initialize中初始化该变量时名字以'__'开头;
涉及到IO(打开的文件,实例化的类对象等)的对象是不能被序列化的;
全局变量g中以'__'开头的变量为私有变量,持久化时将不会被保存;
具体可以参加 API文档:
https://ptradeapi.com 查看全部
2023-10-18 09:25:12 - ERROR - 全局对象g持久化对象保存失败,对象名:TARGET_STOCK_CODE,错误原因:Traceback (most recent call last):
File "./fly_docker/IQEngine/utils/global_variable.py", line 50, in save
_pickle.PicklingError: Can't pickle <class 'IQEngine.user_module.PositionManager'>: attribute lookup PositionManager on IQEngine.user_module failed
原因是全局变量g 不能被持久化, 需要前面加__, 比如g.Name 要改成 g.__Name
全局变量g中不能被序列化的变量将不会被保存。您可在initialize中初始化该变量时名字以'__'开头;
涉及到IO(打开的文件,实例化的类对象等)的对象是不能被序列化的;
全局变量g中以'__'开头的变量为私有变量,持久化时将不会被保存;

具体可以参加 API文档:
https://ptradeapi.com
ptrade/qmt 判断股票是否涨停
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 2989 次浏览 • 2023-10-09 11:03
以ptrade为例:
先通过 get_snapshot - 取行情快照
其中里面有2个字段:
up_px:涨停价格(str:float);
down_px:跌停价格(str:float);用当前的最新价格和涨停跌停价格比较:
last_px:最新成交价(str:float);
if last_px>=up_px 就是达到涨停价,
还有判断此时的卖一上是否有挂单. 如果还有卖单, 说明此时的涨停板并没有封住, 被人砸开了.
跌停板的判断也是如此.
2. 使用现有的API函数, 更加简单方便, 这个方法只适用于ptrade, qmt没有类似的函数.
check_limit - 代码涨跌停状态判断
使用场景
该函数仅在交易模块可用。
接口说明
该接口用于标识当日股票的涨跌停情况。
注意事项:
无
参数
security:单只股票代码或者多只股票代码组成的列表,必填字段(list[str]/str);
返回
正常返回一个dict类型数据,包含每只股票代码的涨停状态。多只股票代码查询时其中部分股票代码查询异常则该代码返回既不涨停也不跌停状态0。(dict[str:int])
涨跌停状态说明:
2:触板涨停(已经是涨停价格,但还有卖盘);
1:涨停;
0:既不涨停也不跌停;
-1:跌停;
-2:触板跌停(已经是跌停价格,但还有买盘);
示例代码:
def initialize(context):
g.security = '600570.SS'
set_universe(g.security)
def handle_data(context, data):
# 代码涨跌停状态
stock_flag = check_limit(g.security)
log.info(stock_flag)
公众号: 可转债量化分析
查看全部
以ptrade为例:
先通过 get_snapshot - 取行情快照
其中里面有2个字段:
up_px:涨停价格(str:float);用当前的最新价格和涨停跌停价格比较:
down_px:跌停价格(str:float);
last_px:最新成交价(str:float);
if last_px>=up_px 就是达到涨停价,
还有判断此时的卖一上是否有挂单. 如果还有卖单, 说明此时的涨停板并没有封住, 被人砸开了.
跌停板的判断也是如此.
2. 使用现有的API函数, 更加简单方便, 这个方法只适用于ptrade, qmt没有类似的函数.
check_limit - 代码涨跌停状态判断
使用场景
该函数仅在交易模块可用。
接口说明
该接口用于标识当日股票的涨跌停情况。
注意事项:
无
参数
security:单只股票代码或者多只股票代码组成的列表,必填字段(list[str]/str);
返回
正常返回一个dict类型数据,包含每只股票代码的涨停状态。多只股票代码查询时其中部分股票代码查询异常则该代码返回既不涨停也不跌停状态0。(dict[str:int])
涨跌停状态说明:
2:触板涨停(已经是涨停价格,但还有卖盘);
1:涨停;
0:既不涨停也不跌停;
-1:跌停;
-2:触板跌停(已经是跌停价格,但还有买盘);
示例代码:
def initialize(context):
g.security = '600570.SS'
set_universe(g.security)
def handle_data(context, data):
# 代码涨跌停状态
stock_flag = check_limit(g.security)
log.info(stock_flag)
公众号: 可转债量化分析
小市值轮动-量化交易-程序化交易-Ptrade实盘
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 3321 次浏览 • 2023-10-07 14:14
当前策略持有30只。
点击查看大图
点击查看大图
基于股票的策略不敢多买,属于试验阶段,后期仍然会不断根据市场调仓; 主仓依然在可转债。
公众号:可转债量化分析
如果需要策略代写,(ptrade、qmt,其他量化平台)
可以公众号后台回复:
策略代写
查看全部
当前策略持有30只。


基于股票的策略不敢多买,属于试验阶段,后期仍然会不断根据市场调仓; 主仓依然在可转债。
公众号:可转债量化分析
如果需要策略代写,(ptrade、qmt,其他量化平台)
可以公众号后台回复:
策略代写