
通知设置 新通知
哪些淘宝店铺被你列入了黑名单? 让我们一起来曝光
闲聊 • 李魔佛 发表了文章 • 0 个评论 • 4897 次浏览 • 2018-08-25 20:59
1. 以尚牛仔
转至知乎的:
让我来一个。
买了一条牛仔裤,收到货没及时拆开,过了一个多星期再拆发现拉链是坏的,于是就去找卖家。
上来就说我买的时间太久了,一句道歉的话都没说。后面再回她干脆不鸟我了...然后我就给了差评“坏了就是坏了,态度还那么差!连句道歉都没有,现在鸟都不鸟了”。接着又过十天,也就是今天下午,打电话给我让我删了差评,然后再给我退20块赔偿,当时刚睡醒,听她态度还行就同意了。然后挂完电话想说晚点再删,没想到她就开始在淘宝上连环call!我就给她删了。
当时也想过会不会删了就被拉黑名单,但想说刚刚态度不错就没继续怀疑!但是!果然!删完以后态度依旧很十多天前一个样!依旧是保持高冷的态度鸟都不鸟,打电话也不接了!呵呵!然后百度了一下,说这是许多卖家惯用的手段,让你先删了评论给你赔偿,然后等你删了就不理你。
告诫各位下次在淘宝上买的东西不好就是不好,该差评就差评,别被卖家骗了!
告诫各位下次在淘宝上买的东西不好就是不好,该差评就差评,别被卖家骗了!
告诫各位下次在淘宝上买的东西不好就是不好,该差评就差评,别被卖家骗了! 查看全部
1. 以尚牛仔

转至知乎的:
让我来一个。
买了一条牛仔裤,收到货没及时拆开,过了一个多星期再拆发现拉链是坏的,于是就去找卖家。
上来就说我买的时间太久了,一句道歉的话都没说。后面再回她干脆不鸟我了...然后我就给了差评“坏了就是坏了,态度还那么差!连句道歉都没有,现在鸟都不鸟了”。接着又过十天,也就是今天下午,打电话给我让我删了差评,然后再给我退20块赔偿,当时刚睡醒,听她态度还行就同意了。然后挂完电话想说晚点再删,没想到她就开始在淘宝上连环call!我就给她删了。
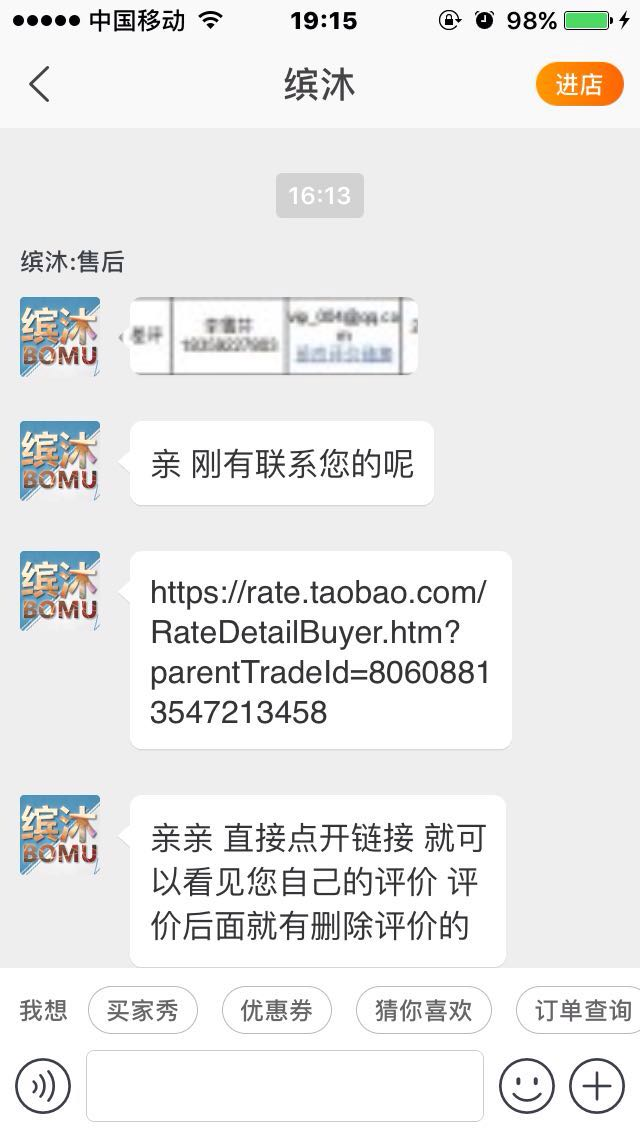
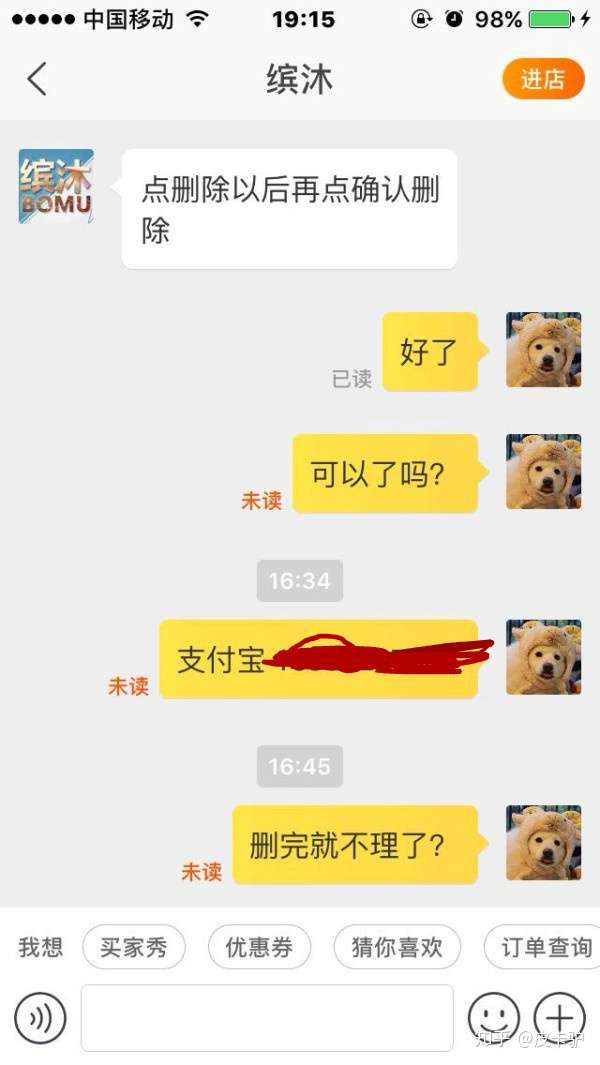
当时也想过会不会删了就被拉黑名单,但想说刚刚态度不错就没继续怀疑!但是!果然!删完以后态度依旧很十多天前一个样!依旧是保持高冷的态度鸟都不鸟,打电话也不接了!呵呵!然后百度了一下,说这是许多卖家惯用的手段,让你先删了评论给你赔偿,然后等你删了就不理你。
告诫各位下次在淘宝上买的东西不好就是不好,该差评就差评,别被卖家骗了!
告诫各位下次在淘宝上买的东西不好就是不好,该差评就差评,别被卖家骗了!
告诫各位下次在淘宝上买的东西不好就是不好,该差评就差评,别被卖家骗了!
how to use proxy in scrapy_splash ?
python爬虫 • 李魔佛 发表了文章 • 3 个评论 • 3852 次浏览 • 2018-08-24 21:44
yield scrapy.Request(
url=self.base_url.format(i),
meta={'page':str(i),
'splash': {
'args': {
'images':0,
'wait': 15,
'proxy': self.get_proxy(),
},
'endpoint': 'render.html',
},
},
)
其中get_proxy() 返回的是 字符创,类似于 http://8.8.8.8.8:8888 这样的格式代理数据。
这个方式自己试过是可以使用的。
当然也可以使用 scrapy_splash 中的 SplashRequest方法进行调用,参数一样,只是位置有点变化。
方法二是写中间件,不过自己试了很多次,没有成功。 感觉网上的都是忽悠。
就是在 process_request中修改 request['splash']['args']['proxy']=xxxxxxx
无效,另外一个朋友也沟通过,也是说无法生效。
如果有人成功了的话,可以私信交流交流。
查看全部
yield scrapy.Request(
url=self.base_url.format(i),
meta={'page':str(i),
'splash': {
'args': {
'images':0,
'wait': 15,
'proxy': self.get_proxy(),
},
'endpoint': 'render.html',
},
},
)
其中get_proxy() 返回的是 字符创,类似于 http://8.8.8.8.8:8888 这样的格式代理数据。
这个方式自己试过是可以使用的。
当然也可以使用 scrapy_splash 中的 SplashRequest方法进行调用,参数一样,只是位置有点变化。
方法二是写中间件,不过自己试了很多次,没有成功。 感觉网上的都是忽悠。
就是在 process_request中修改 request['splash']['args']['proxy']=xxxxxxx
无效,另外一个朋友也沟通过,也是说无法生效。
如果有人成功了的话,可以私信交流交流。
python mongodb大数据(>3GB)转移Mysql数据库
python • 李魔佛 发表了文章 • 0 个评论 • 5019 次浏览 • 2018-08-20 15:44
于是使用了分段遍历的方法.# -*-coding=utf-8-*-
import pandas as pd
import json
import pymongo
from sqlalchemy import create_engine
# 将mongo数据转移到mysql
client = pymongo.MongoClient('xxx')
doc = client['spider']['meituan']
engine = create_engine('mysql+pymysql://xxx:xxx@xxx:/xxx?charset=utf8')
def classic_method():
temp =
start = 0
# 数据太大还是会爆内存,或者游标丢失
for i in doc.find().batch_size(500):
start += 1
del i['_id']
temp.append(i)
print(start)
print('start to save to mysql')
df = pd.read_json(json.dumps(temp))
df = df.set_index('poiid', drop=True)
df.to_sql('meituan', con=engine, if_exists='replace')
print('done')
def chunksize_move():
block = 10000
total = doc.find({}).count()
iter_number = total // block
for i in range(iter_number + 1):
small_part = doc.find({}).limit(block).skip(i * block)
list_data =
for item in small_part:
del item['_id']
del item['crawl_time']
item['poiid'] = int(item['poiid'])
for k, v in item.items():
if isinstance(v, dict) or isinstance(v, list):
item[k] = json.dumps(v, ensure_ascii=False)
list_data.append(item)
df = pd.DataFrame(list_data)
df = df.set_index('poiid', drop=True)
try:
df.to_sql('meituan', con=engine, if_exists='append')
print('to sql {}'.format(i))
except Exception as e:
print(e)
chunksize_move()
速度比一次批量的要快不少. 查看全部
for i in doc.find({})进行逐行遍历的话,游标就会超时,而且越到后面速度越慢.于是使用了分段遍历的方法.
# -*-coding=utf-8-*-
import pandas as pd
import json
import pymongo
from sqlalchemy import create_engine
# 将mongo数据转移到mysql
client = pymongo.MongoClient('xxx')
doc = client['spider']['meituan']
engine = create_engine('mysql+pymysql://xxx:xxx@xxx:/xxx?charset=utf8')
def classic_method():
temp =
start = 0
# 数据太大还是会爆内存,或者游标丢失
for i in doc.find().batch_size(500):
start += 1
del i['_id']
temp.append(i)
print(start)
print('start to save to mysql')
df = pd.read_json(json.dumps(temp))
df = df.set_index('poiid', drop=True)
df.to_sql('meituan', con=engine, if_exists='replace')
print('done')
def chunksize_move():
block = 10000
total = doc.find({}).count()
iter_number = total // block
for i in range(iter_number + 1):
small_part = doc.find({}).limit(block).skip(i * block)
list_data =
for item in small_part:
del item['_id']
del item['crawl_time']
item['poiid'] = int(item['poiid'])
for k, v in item.items():
if isinstance(v, dict) or isinstance(v, list):
item[k] = json.dumps(v, ensure_ascii=False)
list_data.append(item)
df = pd.DataFrame(list_data)
df = df.set_index('poiid', drop=True)
try:
df.to_sql('meituan', con=engine, if_exists='append')
print('to sql {}'.format(i))
except Exception as e:
print(e)
chunksize_move()

速度比一次批量的要快不少.
python 把mongodb的数据迁移到mysql
python • 李魔佛 发表了文章 • 0 个评论 • 4523 次浏览 • 2018-08-20 11:02
import pymongo
from setting import get_engine
# 将mongo数据转移到mysql
client = pymongo.MongoClient('10.18.6.101')
doc = client['spider']['meituan']
engine = create_engine('mysql+pymysql://localhost:1234@10.18.4.211/spider?charset=utf8')
temp=[]
for i in doc.find({}):
del i['_id']
temp.append(i)
print('start to save to mysql')
df = pd.read_json(json.dumps(temp))
df = df.set_index('poiid',drop=True)
df.to_sql('meituan',con=engine,if_exists='replace')
print('done')
居然CPU飙到了90%
查看全部
import pymongo
from setting import get_engine
# 将mongo数据转移到mysql
client = pymongo.MongoClient('10.18.6.101')
doc = client['spider']['meituan']
engine = create_engine('mysql+pymysql://localhost:1234@10.18.4.211/spider?charset=utf8')
temp=[]
for i in doc.find({}):
del i['_id']
temp.append(i)
print('start to save to mysql')
df = pd.read_json(json.dumps(temp))
df = df.set_index('poiid',drop=True)
df.to_sql('meituan',con=engine,if_exists='replace')
print('done')

居然CPU飙到了90%
python json.loads 文件中的字典不能用单引号
python • 李魔佛 发表了文章 • 0 个评论 • 5280 次浏览 • 2018-08-20 09:28
只能改成双引号,或者使用
with open('cookies', 'r') as f:
# js = json.load(f)
js=eval(f.read())
# cookie=js.get('Cookie','')
headers = js.get('headers', '')
#content为文件的内容 查看全部
python json.loads 文件中的字典不能用单引号
只能改成双引号,或者使用
with open('cookies', 'r') as f:
# js = json.load(f)
js=eval(f.read())
# cookie=js.get('Cookie','')
headers = js.get('headers', '')
#content为文件的内容
有道云笔记经常会保存丢失
闲聊 • 李魔佛 发表了文章 • 0 个评论 • 3178 次浏览 • 2018-08-19 16:58
## 更新 2019-01-19
今天再次发生,保存的一个网页链接在笔记里,结果3天后居然找不到了,果然神奇。(公司电脑和家里笔记本同步过)
## 更新 2019-01-19
今天再次发生,保存的一个网页链接在笔记里,结果3天后居然找不到了,果然神奇。(公司电脑和家里笔记本同步过)
scrapy记录日志的最新方法
python爬虫 • 李魔佛 发表了文章 • 0 个评论 • 4167 次浏览 • 2018-08-15 15:01
log.msg("This is a warning", level=log.WARING)
在Spider中添加log
在spider中添加log的推荐方式是使用Spider的 log() 方法。该方法会自动在调用 scrapy.log.start() 时赋值 spider 参数。
其它的参数则直接传递给 msg() 方法
scrapy.log模块scrapy.log.start(logfile=None, loglevel=None, logstdout=None)启动log功能。该方法必须在记录任何信息之前被调用。否则调用前的信息将会丢失。
但是运行的时候出现警告:
[py.warnings] WARNING: E:\git\CrawlMan\bilibili\bilibili\spiders\bili.py:14: ScrapyDeprecationWarning: log.msg has been deprecated, create a python logger and log through it instead
log.msg
原来官方以及不推荐使用log.msg了
最新的用法:# -*- coding: utf-8 -*-
import scrapy
from scrapy_splash import SplashRequest
import logging
# from scrapy import log
class BiliSpider(scrapy.Spider):
name = 'ordinary' # 这个名字就是上面连接中那个启动应用的名字
allowed_domain = ["bilibili.com"]
start_urls = [
"https://www.bilibili.com/"
]
def parse(self, response):
logging.info('====================================================')
content = response.xpath("//div[@class='num-wrap']").extract_first()
logging.info(content)
logging.info('====================================================') 查看全部
from scrapy import log
log.msg("This is a warning", level=log.WARING)
在Spider中添加log
在spider中添加log的推荐方式是使用Spider的 log() 方法。该方法会自动在调用 scrapy.log.start() 时赋值 spider 参数。
其它的参数则直接传递给 msg() 方法
scrapy.log模块scrapy.log.start(logfile=None, loglevel=None, logstdout=None)启动log功能。该方法必须在记录任何信息之前被调用。否则调用前的信息将会丢失。
但是运行的时候出现警告:
[py.warnings] WARNING: E:\git\CrawlMan\bilibili\bilibili\spiders\bili.py:14: ScrapyDeprecationWarning: log.msg has been deprecated, create a python logger and log through it instead
log.msg
原来官方以及不推荐使用log.msg了
最新的用法:
# -*- coding: utf-8 -*-
import scrapy
from scrapy_splash import SplashRequest
import logging
# from scrapy import log
class BiliSpider(scrapy.Spider):
name = 'ordinary' # 这个名字就是上面连接中那个启动应用的名字
allowed_domain = ["bilibili.com"]
start_urls = [
"https://www.bilibili.com/"
]
def parse(self, response):
logging.info('====================================================')
content = response.xpath("//div[@class='num-wrap']").extract_first()
logging.info(content)
logging.info('====================================================')
adbapi查询语句 -- python3
python • 李魔佛 发表了文章 • 0 个评论 • 4010 次浏览 • 2018-08-12 19:40
Abstract
Twisted is an asynchronous networking framework, but most database API implementations unfortunately have blocking interfaces -- for this reason, twisted.enterprise.adbapi was created. It is a non-blocking interface to the standardized DB-API 2.0 API, which allows you to access a number of different RDBMSes.
What you should already know
Python :-)
How to write a simple Twisted Server (see this tutorial to learn how)
Familiarity with using database interfaces (see the documentation for DBAPI 2.0 or this article by Andrew Kuchling)
Quick Overview
Twisted is an asynchronous framework. This means standard database modules cannot be used directly, as they typically work something like:# Create connection... db = dbmodule.connect('mydb', 'andrew', 'password') # ...which blocks for an unknown amount of time # Create a cursor cursor = db.cursor() # Do a query... resultset = cursor.query('SELECT * FROM table WHERE ...') # ...which could take a long time, perhaps even minutes.Those delays are unacceptable when using an asynchronous framework such as Twisted. For this reason, twisted provides twisted.enterprise.adbapi, an asynchronous wrapper for any DB-API 2.0-compliant module. It is currently best tested with the pyPgSQL module for PostgreSQL.
enterprise.adbapi will do blocking database operations in seperate threads, which trigger callbacks in the originating thread when they complete. In the meantime, the original thread can continue doing normal work, like servicing other requests.
How do I use adbapi?
Rather than creating a database connection directly, use the adbapi.ConnectionPool class to manage a connections for you. This allows enterprise.adbapi to use multiple connections, one per thread. This is easy:# Using the "dbmodule" from the previous example, create a ConnectionPool from twisted.enterprise import adbapi dbpool = adbapi.ConnectionPool("dbmodule", 'mydb', 'andrew', 'password')Things to note about doing this:
There is no need to import dbmodule directly. You just pass the name to adbapi.ConnectionPool's constructor.
The parameters you would pass to dbmodule.connect are passed as extra arguments to adbapi.ConnectionPool's constructor. Keyword parameters work as well.
You may also control the size of the connection pool with the keyword parameters cp_min and cp_max. The default minimum and maximum values are 3 and 5.
So, now you need to be able to dispatch queries to your ConnectionPool. We do this by subclassing adbapi.Augmentation. Here's an example:class AgeDatabase(adbapi.Augmentation): """A simple example that can retrieve an age from the database""" def getAge(self, name): # Define the query sql = """SELECT Age FROM People WHERE name = ?""" # Run the query, and return a Deferred to the caller to add # callbacks to. return self.runQuery(sql, name) def gotAge(resultlist, name): """Callback for handling the result of the query""" age = resultlist[0][0] # First field of first record print "%s is %d years old" % (name, age) db = AgeDatabase(dbpool) # These will *not* block. Hooray! db.getAge("Andrew").addCallbacks(gotAge, db.operationError, callbackArgs=("Andrew",)) db.getAge("Glyph").addCallbacks(gotAge, db.operationError, callbackArgs=("Glyph",)) # Of course, nothing will happen until the reactor is started from twisted.internet import reactor reactor.run()This is straightforward, except perhaps for the return value of getAge. It returns a twisted.internet.defer.Deferred, which allows arbitrary callbacks to be called upon completion (or upon failure). More documentation on Deferred is available here.
Also worth noting is that this example assumes that dbmodule uses the qmarks paramstyle (see the DB-API specification). If your dbmodule uses a different paramstyle (e.g. pyformat) then use that. Twisted doesn't attempt to offer any sort of magic paramater munging -- runQuery(query, params, ...) maps directly onto cursor.execute(query, params, ...).
And that's it!
That's all you need to know to use a database from within Twisted. You probably should read the adbapi module's documentation to get an idea of the other functions it has, but hopefully this document presents the core ideas. 查看全部
Abstract
Twisted is an asynchronous networking framework, but most database API implementations unfortunately have blocking interfaces -- for this reason, twisted.enterprise.adbapi was created. It is a non-blocking interface to the standardized DB-API 2.0 API, which allows you to access a number of different RDBMSes.
What you should already know
Python :-)
How to write a simple Twisted Server (see this tutorial to learn how)
Familiarity with using database interfaces (see the documentation for DBAPI 2.0 or this article by Andrew Kuchling)
Quick Overview
Twisted is an asynchronous framework. This means standard database modules cannot be used directly, as they typically work something like:# Create connection... db = dbmodule.connect('mydb', 'andrew', 'password') # ...which blocks for an unknown amount of time # Create a cursor cursor = db.cursor() # Do a query... resultset = cursor.query('SELECT * FROM table WHERE ...') # ...which could take a long time, perhaps even minutes.Those delays are unacceptable when using an asynchronous framework such as Twisted. For this reason, twisted provides twisted.enterprise.adbapi, an asynchronous wrapper for any DB-API 2.0-compliant module. It is currently best tested with the pyPgSQL module for PostgreSQL.
enterprise.adbapi will do blocking database operations in seperate threads, which trigger callbacks in the originating thread when they complete. In the meantime, the original thread can continue doing normal work, like servicing other requests.
How do I use adbapi?
Rather than creating a database connection directly, use the adbapi.ConnectionPool class to manage a connections for you. This allows enterprise.adbapi to use multiple connections, one per thread. This is easy:# Using the "dbmodule" from the previous example, create a ConnectionPool from twisted.enterprise import adbapi dbpool = adbapi.ConnectionPool("dbmodule", 'mydb', 'andrew', 'password')Things to note about doing this:
There is no need to import dbmodule directly. You just pass the name to adbapi.ConnectionPool's constructor.
The parameters you would pass to dbmodule.connect are passed as extra arguments to adbapi.ConnectionPool's constructor. Keyword parameters work as well.
You may also control the size of the connection pool with the keyword parameters cp_min and cp_max. The default minimum and maximum values are 3 and 5.
So, now you need to be able to dispatch queries to your ConnectionPool. We do this by subclassing adbapi.Augmentation. Here's an example:class AgeDatabase(adbapi.Augmentation): """A simple example that can retrieve an age from the database""" def getAge(self, name): # Define the query sql = """SELECT Age FROM People WHERE name = ?""" # Run the query, and return a Deferred to the caller to add # callbacks to. return self.runQuery(sql, name) def gotAge(resultlist, name): """Callback for handling the result of the query""" age = resultlist[0][0] # First field of first record print "%s is %d years old" % (name, age) db = AgeDatabase(dbpool) # These will *not* block. Hooray! db.getAge("Andrew").addCallbacks(gotAge, db.operationError, callbackArgs=("Andrew",)) db.getAge("Glyph").addCallbacks(gotAge, db.operationError, callbackArgs=("Glyph",)) # Of course, nothing will happen until the reactor is started from twisted.internet import reactor reactor.run()This is straightforward, except perhaps for the return value of getAge. It returns a twisted.internet.defer.Deferred, which allows arbitrary callbacks to be called upon completion (or upon failure). More documentation on Deferred is available here.
Also worth noting is that this example assumes that dbmodule uses the qmarks paramstyle (see the DB-API specification). If your dbmodule uses a different paramstyle (e.g. pyformat) then use that. Twisted doesn't attempt to offer any sort of magic paramater munging -- runQuery(query, params, ...) maps directly onto cursor.execute(query, params, ...).
And that's it!
That's all you need to know to use a database from within Twisted. You probably should read the adbapi module's documentation to get an idea of the other functions it has, but hopefully this document presents the core ideas.
python判断身份证的合法性
python • 李魔佛 发表了文章 • 0 个评论 • 6086 次浏览 • 2018-08-10 13:56
验证原理
将前面的身份证号码17位数分别乘以不同的系数, 从第一位到第十七位的系数分别为: 7 9 10 5 8 4 2 1 6 3 7 9 10 5 8 4 2
将这17位数字和系数相乘的结果相加.
用加出来和除以11, 看余数是多少?
余数只可能有<0 1 2 3 4 5 6 7 8 9 10>这11个数字, 其分别对应的最后一位身份证的号码为<1 0 X 9 8 7 6 5 4 3 2>.
通过上面得知如果余数是2,就会在身份证的第18位数字上出现罗马数字的Ⅹ。如果余数是10,身份证的最后一位号码就是2.
例如: 某男性的身份证号码是34052419800101001X, 我们要看看这个身份证是不是合法的身份证.
首先: 我们得出, 前17位的乘积和是189.
然后: 用189除以11得出的余数是2.
最后: 通过对应规则就可以知道余数2对应的数字是x. 所以, 这是一个合格的身份证号码.
代码如下:#!/bin/env python
# -*- coding: utf-8 -*-
from sys import platform
import json
import codecs
with codecs.open('data.json', 'r', encoding='utf8') as json_data:
city = json.load(json_data)
def check_valid(idcard):
# 城市编码, 出生日期, 归属地
city_id = idcard[:6]
print(city_id)
birth = idcard[6:14]
city_name = city.get(city_id,'Not found')
# 根据规则校验身份证是否符合规则
idcard_tuple = [int(num) for num in list(idcard[:-1])]
coefficient = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
sum_value = sum([idcard_tuple[i] * coefficient[i] for i in range(17)])
remainder = sum_value % 11
maptable = {0: '1', 1: '0', 2: 'x', 3: '9', 4: '8', 5: '7', 6: '6', 7: '5', 8: '4', 9: '3', 10: '2'}
if maptable[remainder] == idcard[17]:
print('<身份证合法>')
sex = int(idcard[16]) % 2
sex = '男' if sex == 1 else '女'
print('性别:' + sex)
birth_format="{}年{}月{}日".format(birth[:4],birth[4:6],birth[6:8])
print('出生日期:' + birth_format)
print('归属地:' + city_name)
return True
else:
print('<身份证不合法>')
return False
if __name__=='__main__':
idcard = str(input('请输入身份证号码:'))
check_valid(idcard)[/i]
github源码:https://github.com/Rockyzsu/IdentityCheck
原创文章,转载请注明
http://30daydo.com/article/340
查看全部
验证原理
将前面的身份证号码17位数分别乘以不同的系数, 从第一位到第十七位的系数分别为: 7 9 10 5 8 4 2 1 6 3 7 9 10 5 8 4 2
将这17位数字和系数相乘的结果相加.
用加出来和除以11, 看余数是多少?
余数只可能有<0 1 2 3 4 5 6 7 8 9 10>这11个数字, 其分别对应的最后一位身份证的号码为<1 0 X 9 8 7 6 5 4 3 2>.
通过上面得知如果余数是2,就会在身份证的第18位数字上出现罗马数字的Ⅹ。如果余数是10,身份证的最后一位号码就是2.
例如: 某男性的身份证号码是34052419800101001X, 我们要看看这个身份证是不是合法的身份证.
首先: 我们得出, 前17位的乘积和是189.
然后: 用189除以11得出的余数是2.
最后: 通过对应规则就可以知道余数2对应的数字是x. 所以, 这是一个合格的身份证号码.
代码如下:
#!/bin/env python
# -*- coding: utf-8 -*-
from sys import platform
import json
import codecs
with codecs.open('data.json', 'r', encoding='utf8') as json_data:
city = json.load(json_data)
def check_valid(idcard):
# 城市编码, 出生日期, 归属地
city_id = idcard[:6]
print(city_id)
birth = idcard[6:14]
city_name = city.get(city_id,'Not found')
# 根据规则校验身份证是否符合规则
idcard_tuple = [int(num) for num in list(idcard[:-1])]
coefficient = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
sum_value = sum([idcard_tuple[i] * coefficient[i] for i in range(17)])
remainder = sum_value % 11
maptable = {0: '1', 1: '0', 2: 'x', 3: '9', 4: '8', 5: '7', 6: '6', 7: '5', 8: '4', 9: '3', 10: '2'}
if maptable[remainder] == idcard[17]:
print('<身份证合法>')
sex = int(idcard[16]) % 2
sex = '男' if sex == 1 else '女'
print('性别:' + sex)
birth_format="{}年{}月{}日".format(birth[:4],birth[4:6],birth[6:8])
print('出生日期:' + birth_format)
print('归属地:' + city_name)
return True
else:
print('<身份证不合法>')
return False
if __name__=='__main__':
idcard = str(input('请输入身份证号码:'))
check_valid(idcard)[/i]
github源码:https://github.com/Rockyzsu/IdentityCheck
原创文章,转载请注明
http://30daydo.com/article/340
想写一个爬取开奖数据并预测下一期的py
python爬虫 • 李魔佛 回复了问题 • 2 人关注 • 1 个回复 • 5103 次浏览 • 2018-08-10 00:22
pymysql.err.InternalError: Packet sequence number wrong - got 4 expected 1
网络安全 • 李魔佛 发表了文章 • 0 个评论 • 13563 次浏览 • 2018-07-19 13:59
PyMySQL is not thread safty to share connections as we did (we shared the class instance between multiple files as a global instance - in the class there is only one connection), it is labled as 1:
threadsafety = 1
According to PEP 249:
1 - Threads may share the module, but not connections.
One of the comments in PyMySQL github issue:
you need one pysql.connect() for each process/thread. As far as I know that's the only way to fix it. PyMySQL is not thread safe, so the same connection can't be used across multiple threads.
Any way if you were thinking of using other python package called MySQLdb for your threading application, notice to MySQLdb message:
Don't share connections between threads. It's really not worth your effort or mine, and in the end, will probably hurt performance, since the MySQL server runs a separate thread for each connection. You can certainly do things like cache connections in a pool, and give those connections to one thread at a time. If you let two threads use a connection simultaneously, the MySQL client library will probably upchuck and die. You have been warned. For threaded applications, try using a connection pool. This can be done using the Pool module.
Eventually we managed to use Django ORM and we are writing only for our specific table, managed by using inspectdb. 查看全部
PyMySQL is not thread safty to share connections as we did (we shared the class instance between multiple files as a global instance - in the class there is only one connection), it is labled as 1:
threadsafety = 1
According to PEP 249:
1 - Threads may share the module, but not connections.
One of the comments in PyMySQL github issue:
you need one pysql.connect() for each process/thread. As far as I know that's the only way to fix it. PyMySQL is not thread safe, so the same connection can't be used across multiple threads.
Any way if you were thinking of using other python package called MySQLdb for your threading application, notice to MySQLdb message:
Don't share connections between threads. It's really not worth your effort or mine, and in the end, will probably hurt performance, since the MySQL server runs a separate thread for each connection. You can certainly do things like cache connections in a pool, and give those connections to one thread at a time. If you let two threads use a connection simultaneously, the MySQL client library will probably upchuck and die. You have been warned. For threaded applications, try using a connection pool. This can be done using the Pool module.
Eventually we managed to use Django ORM and we are writing only for our specific table, managed by using inspectdb.
mongodb sort: Executor error during find command: OperationFailed: Sort operation used more than
网络 • 李魔佛 发表了文章 • 0 个评论 • 7595 次浏览 • 2018-07-09 10:31
Error: error: {
"ok" : 0,
"errmsg" : "Executor error during find command: OperationFailed: Sort operation used more than the maximum 33554432 bytes of RAM. Add an index, or specify a smaller limit.",
"code" : 96,
"codeName" : "OperationFailed"
}
使用limit函数限制其输出就可以了:
db.getCollection('老布').find({}).sort({'created_at':-1}).limit(1000) 查看全部
Error: error: {
"ok" : 0,
"errmsg" : "Executor error during find command: OperationFailed: Sort operation used more than the maximum 33554432 bytes of RAM. Add an index, or specify a smaller limit.",
"code" : 96,
"codeName" : "OperationFailed"
}使用limit函数限制其输出就可以了:
db.getCollection('老布').find({}).sort({'created_at':-1}).limit(1000) 每天给小孩子看英语视频可以让小孩学到什么?
闲聊 • 绫波丽 发表了文章 • 0 个评论 • 3269 次浏览 • 2018-07-07 11:10
没有互动,没有实际使用,语言没有用武之地,最终只是当做一种娱乐消遣。
那么多看美剧的,问问他们的英语水平,会不会比7岁的在国外长大的小孩的英语水平高? 不会,至少他们连流畅沟通都做不到。
没有互动,没有实际使用,语言没有用武之地,最终只是当做一种娱乐消遣。
那么多看美剧的,问问他们的英语水平,会不会比7岁的在国外长大的小孩的英语水平高? 不会,至少他们连流畅沟通都做不到。
最新版的chrome中info lite居然不支持了
python爬虫 • 李魔佛 发表了文章 • 0 个评论 • 3065 次浏览 • 2018-06-25 18:58
只好降级......
版本 65.0.3325.162(正式版本) (64 位)
这个版本最新且支持info lite的。
只好降级......
版本 65.0.3325.162(正式版本) (64 位)
这个版本最新且支持info lite的。
python sqlalchemy ORM 添加注释
python • 李魔佛 发表了文章 • 0 个评论 • 3976 次浏览 • 2018-06-25 16:17
在定义ORM对象的时候,
class CreditRecord(Base):
__tablename__ = 'tb_PersonPunishment'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(180),comment='名字')
添加一个comment参数即可。
查看全部
在定义ORM对象的时候,
class CreditRecord(Base):
__tablename__ = 'tb_PersonPunishment'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(180),comment='名字')
添加一个comment参数即可。
新股开板后五日均线上穿10日均线
股票 • 李魔佛 回复了问题 • 2 人关注 • 1 个回复 • 3151 次浏览 • 2018-06-24 09:25
windows 7 python3 安装MySQLdb 库
python • 李魔佛 发表了文章 • 0 个评论 • 2773 次浏览 • 2018-06-20 18:04
工行的app实在是烂到家了,怎么点击都打不开
闲聊 • 量化大师 发表了文章 • 0 个评论 • 2693 次浏览 • 2018-06-20 00:12
赢呗DDW转账失败,一直显示 0 of 12 确认区块
量化交易 • 量化大师 发表了文章 • 0 个评论 • 4961 次浏览 • 2018-06-17 14:39
刚开始是可以转账成功的,可是后面最近今天却一直卡在0 of 12 确认区块, 无论你选择了多转账费用还是选择少的转账费用,都无法转账成功。
点击查看大图
后来咨询了客户后才知道,原来最近斐讯在打击黄牛(刷天天牛),所以天天链的邀请码系统关闭了,而且转账是因为网络拥堵的原因,导致转账卡住了。 而且客服说了,当前转账失败的金额,等到DDW网络正常后会正常转入到天天牛的账号。所以不用担心金额会消失,只需要耐心等待网络修复。
查看全部
刚开始是可以转账成功的,可是后面最近今天却一直卡在0 of 12 确认区块, 无论你选择了多转账费用还是选择少的转账费用,都无法转账成功。

点击查看大图
后来咨询了客户后才知道,原来最近斐讯在打击黄牛(刷天天牛),所以天天链的邀请码系统关闭了,而且转账是因为网络拥堵的原因,导致转账卡住了。 而且客服说了,当前转账失败的金额,等到DDW网络正常后会正常转入到天天牛的账号。所以不用担心金额会消失,只需要耐心等待网络修复。
python量化分析: 股票涨停后该不该卖, 怕砸板还是怕卖飞 ?
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 1 个评论 • 7567 次浏览 • 2018-06-14 19:34
那么触及涨停板的个股我们应该继续持有,还是卖掉,还是卖掉做T接回来呢?
接下来用数据说话。【数据使用通联实验室的数据源】
首先获取当前市场上所有股票all_stocks = DataAPI.SecTypeRegionRelGet(secID=u"",ticker=u"",typeID=u"",field=u"",pandas="1")
然后获取每一个股票的日k线数据,可以设定一个时间段,我抓取了2012年到今天(2018-06-14)的所有数据,如果是次新股,那么数据就是上市当天到今天的数据。
抓取到的数据包含以下的字段:
点击查看大图
但是实际用到的字段只有几个, 开盘价,最高价,涨幅,昨天收盘价。
这里我排除了一字板开盘的个股,因为里面含有新股,会导致数据不精确,【后续我会统计,一字板开盘盘中被砸开的概率】,而且数据也排除了ST的个股,因为本人从来不买ST股,所以不会对ST进行统计。fbl =
for code in all_stocks['secID']:
df = DataAPI.MktEqudGet(secID=code,ticker=u"",tradeDate=u"",beginDate=u"20120101",endDate=u"",isOpen="",field=u"",pandas="1")
df['ztj']=map(lambda x:round(x,2),df['preClosePrice']*1.1)
df['chgPct']=df['chgPct']*100
# 非一字板
zt = df[(df['ztj']==df['highestPrice']) & (df['openPrice']!=df['highestPrice'])]
fz= df[(df['ztj']==df['highestPrice']) & (df['openPrice']!=df['highestPrice'])&(df['closePrice']==df['highestPrice'])]
try:
f = len(fz)*1.00/len(zt)*100
fbl.append((code,f))
except Exception,e:
print e
print code
fbl就是封板率的一个列表,包含了每只股票的触及涨停价后封板的概率。 然后对整体的数据取平均值:dx= dict(fbl)
x = np.array(dx.values())
print x.mean()
最后得到的结果是:
64.0866513726
所以保持住涨停的概率还是大一些。所以站在概率大的一边上,触及涨停的时候应该继续持有,会有62.5%会到收盘保持涨停价。
(待续)
原创文章,转载请注明出处:
http://30daydo.com/article/331
查看全部
那么触及涨停板的个股我们应该继续持有,还是卖掉,还是卖掉做T接回来呢?
接下来用数据说话。【数据使用通联实验室的数据源】
首先获取当前市场上所有股票
all_stocks = DataAPI.SecTypeRegionRelGet(secID=u"",ticker=u"",typeID=u"",field=u"",pandas="1")
然后获取每一个股票的日k线数据,可以设定一个时间段,我抓取了2012年到今天(2018-06-14)的所有数据,如果是次新股,那么数据就是上市当天到今天的数据。
抓取到的数据包含以下的字段:

点击查看大图
但是实际用到的字段只有几个, 开盘价,最高价,涨幅,昨天收盘价。
这里我排除了一字板开盘的个股,因为里面含有新股,会导致数据不精确,【后续我会统计,一字板开盘盘中被砸开的概率】,而且数据也排除了ST的个股,因为本人从来不买ST股,所以不会对ST进行统计。
fbl =
for code in all_stocks['secID']:
df = DataAPI.MktEqudGet(secID=code,ticker=u"",tradeDate=u"",beginDate=u"20120101",endDate=u"",isOpen="",field=u"",pandas="1")
df['ztj']=map(lambda x:round(x,2),df['preClosePrice']*1.1)
df['chgPct']=df['chgPct']*100
# 非一字板
zt = df[(df['ztj']==df['highestPrice']) & (df['openPrice']!=df['highestPrice'])]
fz= df[(df['ztj']==df['highestPrice']) & (df['openPrice']!=df['highestPrice'])&(df['closePrice']==df['highestPrice'])]
try:
f = len(fz)*1.00/len(zt)*100
fbl.append((code,f))
except Exception,e:
print e
print code
fbl就是封板率的一个列表,包含了每只股票的触及涨停价后封板的概率。 然后对整体的数据取平均值:
dx= dict(fbl)
x = np.array(dx.values())
print x.mean()
最后得到的结果是:
64.0866513726
所以保持住涨停的概率还是大一些。所以站在概率大的一边上,触及涨停的时候应该继续持有,会有62.5%会到收盘保持涨停价。
(待续)
原创文章,转载请注明出处:
http://30daydo.com/article/331
为啥抖音这些那么火 ?
闲聊 • 李魔佛 发表了文章 • 2 个评论 • 3045 次浏览 • 2018-06-13 15:59
为什么大家不喜欢看书和学习,因为看书和学习不能获得即可的精神快感,需要时间沉淀。而玩游戏和抖音不一样,你马上就能获得精神上的快感。
为什么大家不喜欢看书和学习,因为看书和学习不能获得即可的精神快感,需要时间沉淀。而玩游戏和抖音不一样,你马上就能获得精神上的快感。
斐讯 天天牛绑定教程
量化交易 • 量化大师 发表了文章 • 7 个评论 • 7801 次浏览 • 2018-06-12 13:37
最近斐讯推出了天天牛养成计划。 不过官方没有任何的指示教程,所以个人分享一个教程给大家。
1. 先把把旧的钱包备份一下 ,切记!! 而且一定要记得自己设的密码,官方的说法是,如果钱包文件不见了(重装系统),那么里面的币就找不到了,或者你忘记了自己设的密码,那么里面的币也同样没了。
备份很简单,点击 赢呗钱包菜单的 账户-》备份-》账户, 这是会看到一个 keystore 的文件夹,把这个额文件夹拷贝出来就可以了。
2. 升级电脑版的赢呗钱包。 因为旧版的钱包没有转出DDW币这个功能。
点击查看大图
有这个转币功能才能转币到天天牛的官方账号进行绑定
下载地址: http://www.phicomm.com/cn/index.php/Products/none_details.html
拉到最底下,就可以看到下载链接了。 最好到这个官方网站下载。
安装后,设置赢呗钱包的数据包文件夹,最好新建一个,不要和旧的公用一个文件夹,不然很容易吧你旧的钱包给覆盖了,假如你忘记了备份。
安装完成后,点击 账户, 备份,我的账户, 这个时候会弹出一个keystore的文件夹, 这时,就需要把上面第一步备份的keystore文件夹替换这个新的文件夹就可以了。 这样就备份完成了。
然后重新打开赢呗钱包,这个时候会同步数据,刚开始显示的账户余额是0的,不要紧,慢慢等数据同步完成了就会看到你的新钱包余额了。 记住你的钱包地址,下一步要用到。
点击查看大图
3. 然后打开斐讯商城app,进入到天天牛游戏页面, 会提示绑定页面:
首先填入你自己的赢呗钱包的地址,上一步记下的地址。
然后需要转币到天天牛的官方账户, 记住你要转的币的数目,这个数目每个人都不一样。
点击下一步。
4. 然后到电脑上,点击转出 按钮。 然后出现的转出页面中会看到转出页面有一个天天牛的下拉菜单
点击查看大图
在转出金额那里填入第3部需要转币的金额,一般就零点几个,不会很多。 然后点击转出。 注意,实际转出的币数会多一点,因为每次转需要少量的手续费。
转币完成后,需要等待1,2分钟,等待区域链网络同步。
一定同步完成了,最底下就会显示你的交易记录了。
点击查看大图
这是app上会显示你已经绑定成功了。
这里提供一个邀请码给大家: 8vozbf
填了后可以领取一只6代牛或者4代牛。 算给我一点写文章的动力吧。
或者你有不要DDW,尽管转给我我哈。 地址:0x2f92eF844DBAa9981b54817FfDc56b778dcA99f3
点击查看大图
如果遇到其他问题,可以在下面留言。
最近又出现了新问题:
赢呗DDW转账失败,一直显示 0 of 12 确认区块
可以点击进去看详情。
原创文章,转账请注明:
http://30daydo.com/article/329
查看全部
最近斐讯推出了天天牛养成计划。 不过官方没有任何的指示教程,所以个人分享一个教程给大家。
1. 先把把旧的钱包备份一下 ,切记!! 而且一定要记得自己设的密码,官方的说法是,如果钱包文件不见了(重装系统),那么里面的币就找不到了,或者你忘记了自己设的密码,那么里面的币也同样没了。
备份很简单,点击 赢呗钱包菜单的 账户-》备份-》账户, 这是会看到一个 keystore 的文件夹,把这个额文件夹拷贝出来就可以了。
2. 升级电脑版的赢呗钱包。 因为旧版的钱包没有转出DDW币这个功能。

点击查看大图
有这个转币功能才能转币到天天牛的官方账号进行绑定
下载地址: http://www.phicomm.com/cn/index.php/Products/none_details.html
拉到最底下,就可以看到下载链接了。 最好到这个官方网站下载。
安装后,设置赢呗钱包的数据包文件夹,最好新建一个,不要和旧的公用一个文件夹,不然很容易吧你旧的钱包给覆盖了,假如你忘记了备份。
安装完成后,点击 账户, 备份,我的账户, 这个时候会弹出一个keystore的文件夹, 这时,就需要把上面第一步备份的keystore文件夹替换这个新的文件夹就可以了。 这样就备份完成了。
然后重新打开赢呗钱包,这个时候会同步数据,刚开始显示的账户余额是0的,不要紧,慢慢等数据同步完成了就会看到你的新钱包余额了。 记住你的钱包地址,下一步要用到。

点击查看大图
3. 然后打开斐讯商城app,进入到天天牛游戏页面, 会提示绑定页面:
首先填入你自己的赢呗钱包的地址,上一步记下的地址。
然后需要转币到天天牛的官方账户, 记住你要转的币的数目,这个数目每个人都不一样。
点击下一步。
4. 然后到电脑上,点击转出 按钮。 然后出现的转出页面中会看到转出页面有一个天天牛的下拉菜单

点击查看大图
在转出金额那里填入第3部需要转币的金额,一般就零点几个,不会很多。 然后点击转出。 注意,实际转出的币数会多一点,因为每次转需要少量的手续费。
转币完成后,需要等待1,2分钟,等待区域链网络同步。
一定同步完成了,最底下就会显示你的交易记录了。

点击查看大图
这是app上会显示你已经绑定成功了。
这里提供一个邀请码给大家: 8vozbf
填了后可以领取一只6代牛或者4代牛。 算给我一点写文章的动力吧。
或者你有不要DDW,尽管转给我我哈。 地址:0x2f92eF844DBAa9981b54817FfDc56b778dcA99f3

点击查看大图
如果遇到其他问题,可以在下面留言。
最近又出现了新问题:
赢呗DDW转账失败,一直显示 0 of 12 确认区块
可以点击进去看详情。
原创文章,转账请注明:
http://30daydo.com/article/329
CDR最近风头火势
股票 • 量化大师 发表了文章 • 0 个评论 • 3053 次浏览 • 2018-06-10 22:48
当年成立的南方全球,到现在,净值都低于1。现在,证监会又推出CDR。
银行和券商卖力吆喝,号称1元起售,普惠金融。农民都明白,指导种啥就亏啥。
China Southern Fund's QDII products still lose money after 11 years.
查看全部
当年成立的南方全球,到现在,净值都低于1。现在,证监会又推出CDR。
银行和券商卖力吆喝,号称1元起售,普惠金融。农民都明白,指导种啥就亏啥。
China Southern Fund's QDII products still lose money after 11 years.



python3中定义抽象类的方法在python2中不兼容
python • 李魔佛 发表了文章 • 0 个评论 • 4534 次浏览 • 2018-06-10 20:54
class Server(metaclass=ABCMeta):
@abstractmethod
def __init__(self):
pass
def __str__(self):
return self.name
@abstractmethod
def boot(self):
pass
@abstractmethod
def kill(self):
pass
但是这个方法在python2中会提示语法错误。
在python2中只能像下面这种方式定义抽象类:
from abc import ABCMeta,abstractmethod
class Server(object):
__metaclass__=ABCMeta
@abstractmethod
def __init__(self):
pass
def __str__(self):
return self.name
@abstractmethod
def boot(self):
pass
@abstractmethod
def kill(self):
pass
这种方式不仅在python2中可以正常运行,在python3中也可以。但是python3的方法只能兼容python3,无法在python2中运行。
原创地址:
http://30daydo.com/article/326
欢迎转载,请注明出处。 查看全部
from abc import ABCMeta,abstractmethod
class Server(metaclass=ABCMeta):
@abstractmethod
def __init__(self):
pass
def __str__(self):
return self.name
@abstractmethod
def boot(self):
pass
@abstractmethod
def kill(self):
pass
但是这个方法在python2中会提示语法错误。
在python2中只能像下面这种方式定义抽象类:
from abc import ABCMeta,abstractmethod
class Server(object):
__metaclass__=ABCMeta
@abstractmethod
def __init__(self):
pass
def __str__(self):
return self.name
@abstractmethod
def boot(self):
pass
@abstractmethod
def kill(self):
pass
这种方式不仅在python2中可以正常运行,在python3中也可以。但是python3的方法只能兼容python3,无法在python2中运行。
原创地址:
http://30daydo.com/article/326
欢迎转载,请注明出处。
sklearn中的Bunch数据类型
深度学习 • 李魔佛 发表了文章 • 0 个评论 • 15733 次浏览 • 2018-06-07 19:10
那么这个
<class 'sklearn.utils.Bunch'>
是什么数据格式 ?
打印一下:
好吧,原来就是一个字典结构。可以像调用字典一样使用Bunch。
比如 data['image'] 就获取 key为image的内容。
原创地址:http://30daydo.com/article/325
欢迎转载,请注明出处。 查看全部

那么这个
<class 'sklearn.utils.Bunch'>
是什么数据格式 ?
打印一下:

好吧,原来就是一个字典结构。可以像调用字典一样使用Bunch。
比如 data['image'] 就获取 key为image的内容。
原创地址:http://30daydo.com/article/325
欢迎转载,请注明出处。
招行信用卡的账单日当天消费算下一个月还吗?
闲聊 • 量化大师 发表了文章 • 0 个评论 • 5993 次浏览 • 2018-06-07 17:50
举个例子:
5月20日是账单日,那么根据招行的规定,那么在6月9就是还款日。
如果在5月20日当天用信用卡消费了,那么这一笔是算入到下个月的还款周期,也就是到7月9日还款。
因为这一笔会记到6月20的月账单里面。而6月20的账单是到7月9日才还款的。 查看全部
举个例子:
5月20日是账单日,那么根据招行的规定,那么在6月9就是还款日。
如果在5月20日当天用信用卡消费了,那么这一笔是算入到下个月的还款周期,也就是到7月9日还款。
因为这一笔会记到6月20的月账单里面。而6月20的账单是到7月9日才还款的。
sklearn中SGDClassifier分类器每次得到的结果都不一样?
深度学习 • 李魔佛 发表了文章 • 0 个评论 • 7404 次浏览 • 2018-06-07 17:14
sgdc.fit(X_train,y_train)
sgdc_predict_y = sgdc.predict(X_test)
print 'Accuary of SGD classifier ', sgdc.score(X_test,y_test)
print classification_report(y_test,sgdc_predict_y,target_names=['Benign','Malignant'])
每次输出的结果都不一样? WHY
因为你使用了一个默认参数:
SGDClassifier(random_state = None)
所以这个随机种子每次不一样,所以得到的结果就可能不一样,如果你指定随机种子值,那么每次得到的结果都是一样的了。
原创地址:http://30daydo.com/article/323
欢迎转载,请注明出处。 查看全部
sgdc = SGDClassifier()
sgdc.fit(X_train,y_train)
sgdc_predict_y = sgdc.predict(X_test)
print 'Accuary of SGD classifier ', sgdc.score(X_test,y_test)
print classification_report(y_test,sgdc_predict_y,target_names=['Benign','Malignant'])
每次输出的结果都不一样? WHY
因为你使用了一个默认参数:
SGDClassifier(random_state = None)
所以这个随机种子每次不一样,所以得到的结果就可能不一样,如果你指定随机种子值,那么每次得到的结果都是一样的了。
原创地址:http://30daydo.com/article/323
欢迎转载,请注明出处。
求港股数据获取PYTHON代码
股票 • 李魔佛 回复了问题 • 3 人关注 • 1 个回复 • 9851 次浏览 • 2018-06-07 16:09
可转债2018 下半年策略
股票 • 李魔佛 发表了文章 • 0 个评论 • 2619 次浏览 • 2018-06-05 01:28
我现在只建了一成仓,跌到88以下开始慢慢摊,不急!!
不要被表象所迷,转债毕竟是债,是有底的东西 跟那时的A类也一样,吐弃不等于烂!
慢慢吃!! 查看全部
我现在只建了一成仓,跌到88以下开始慢慢摊,不急!!
不要被表象所迷,转债毕竟是债,是有底的东西 跟那时的A类也一样,吐弃不等于烂!
慢慢吃!!
