
通知设置 新通知
【量化分析】到底谁在买乐视网?2018年1月26日
股票 • 李魔佛 发表了文章 • 2 个评论 • 3719 次浏览 • 2018-01-26 17:02
本来没有持有这一只股票,不过雪球上不时地出现一些文章,根据龙虎榜推测到底谁在接盘。 于是今天收盘,打开jupyter notebook来简单地分析一下。 大家也可以跟着学习一些分析的思路。因为今天的龙虎榜还没出来,等待会龙虎榜出来了可以再比较一下。
首先导入今天的分时数据
volume列就是我们感兴趣的成交量。单位是手(100股)
先计算一下今天的总成交量:
1021800股,额,比不少中小创的小股的成交量还大呢,瘦死的骆驼比马大。
去对比一下雪球或者东财的数据,看看数据是否准确。
嗯,1.02万手,数据一致。
接着我们来看看排序,按照成交量的大小排序,可以看到最大和最小的差别:
大单都集中在开盘和收盘阶段(其实开盘和收盘严格来说不算大单,因为同一时刻太多人一起买,所以掺杂在一起,如果把收盘和开盘的数据拿掉,其实真的没多少大单。。。)
然后剩下的都是些零零散散的1手的成交:
可以统计一下每个单数出现的频率:
出现最多的是1手,2手。这个很正常,如果出现较多的是超过100手的大单,那么也说明跌停很快被打开(后续如果有打算冒风险去撸一把乐视翘班的,可以自己写一个检测程序)
接着做一些统计:
定义大于100手的为大单。
然后计算100手大单占成交的比例:
嗯,有28%的比例呢。
然后计算一下小于10手的占成交比例。
有30%的比例。
再统计一下中位数和各分位数:
中位数是3,说明整个交易中,一半的成交是在等于或小于3手的,而分位数看到,1手的可以排到25%的位置,而8手则排到了75%的位置。
结论:
其实在买的都是小散,不知道是乐粉还是赌徒了。
原文地址:
http://30daydo.com/article/267
源码:https://github.com/Rockyzsu/stock/blob/master/levt_notebook.ipynb
查看全部

本来没有持有这一只股票,不过雪球上不时地出现一些文章,根据龙虎榜推测到底谁在接盘。 于是今天收盘,打开jupyter notebook来简单地分析一下。 大家也可以跟着学习一些分析的思路。因为今天的龙虎榜还没出来,等待会龙虎榜出来了可以再比较一下。
首先导入今天的分时数据

volume列就是我们感兴趣的成交量。单位是手(100股)
先计算一下今天的总成交量:

1021800股,额,比不少中小创的小股的成交量还大呢,瘦死的骆驼比马大。
去对比一下雪球或者东财的数据,看看数据是否准确。

嗯,1.02万手,数据一致。
接着我们来看看排序,按照成交量的大小排序,可以看到最大和最小的差别:

大单都集中在开盘和收盘阶段(其实开盘和收盘严格来说不算大单,因为同一时刻太多人一起买,所以掺杂在一起,如果把收盘和开盘的数据拿掉,其实真的没多少大单。。。)

然后剩下的都是些零零散散的1手的成交:
可以统计一下每个单数出现的频率:

出现最多的是1手,2手。这个很正常,如果出现较多的是超过100手的大单,那么也说明跌停很快被打开(后续如果有打算冒风险去撸一把乐视翘班的,可以自己写一个检测程序)
接着做一些统计:
定义大于100手的为大单。
然后计算100手大单占成交的比例:

嗯,有28%的比例呢。
然后计算一下小于10手的占成交比例。

有30%的比例。
再统计一下中位数和各分位数:

中位数是3,说明整个交易中,一半的成交是在等于或小于3手的,而分位数看到,1手的可以排到25%的位置,而8手则排到了75%的位置。
结论:
其实在买的都是小散,不知道是乐粉还是赌徒了。
原文地址:
http://30daydo.com/article/267
源码:https://github.com/Rockyzsu/stock/blob/master/levt_notebook.ipynb
coinegg上哪些虚拟币不能碰
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 6352 次浏览 • 2018-01-14 00:22
那么coinegg中哪些币是用了tokens发行的呢? 把两个网站的币都爬下来,然后做个交集就可以了。
#-*-coding=utf-8-*-
import requests,datetime
from lxml import etree
import pandas as pd
from sqlalchemy import create_engine
import random,time
user_agent='Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/37.0.2062.120 Chrome/37.0.2062.120 Safari/537.36'
headers={'User-Agent':user_agent}
def getWebContent(url):
# url=url.format(kind)
r=requests.get(url,headers=headers)
if r.status_code==200:
return r.text
else:
return None
def getCoinList():
content=getWebContent(url='https://coinmarketcap.com/tokens/views/all/'
)
tree=etree.HTML(content)
# table=tree.xpath()
# if not table:
# reutrn None
df=pd.DataFrame()
# for coin in table:
df['currency-symbol']=tree.xpath('//tbody/tr//span[@class="currency-symbol"]/a/text()')
df['currency-name']=tree.xpath('//tbody/tr//a[@class="currency-name-container"]/text()')
df['platformsymbol']=tree.xpath('//tbody/tr/@data-platformsymbol')
df['platform-name']=tree.xpath('//tbody/tr//td[@class="no-wrap platform-name"]/a/text()')
df['price(->bct)']=tree.xpath('//tbody/tr//td[@class="no-wrap text-right"]/a/@data-btc')
df['datetime']=datetime.datetime.now()
return df
def getBtcPrice():
btc_p_url='https://www.coinegg.com/index/pricebtc'
try:
r=requests.get(url=btc_p_url,headers=headers)
except Exception,e:
print e
return None
return r.json().get('data').get('cny')
def coinegg_coins():
url='https://www.coinegg.com/coin/btc/allcoin?t={}'.format(random.random())
print url
retry=3
for _ in range(retry):
text=getWebContent(url)
if not text:
continue
time.sleep(random.random())
if not text:
print 'failed to get web content'
return None
return map(lambda x:x.upper(),eval(text).keys())
def find_fake():
df=getCoinList()
coinegglist=set(coinegg_coins())
# print coinegglist
fakecoin=set(df['currency-symbol'].values)
print coinegglist & fakecoin
def main():
# datastore()
# print getBtcPrice()
# coinegg_coins()
find_fake()
if __name__ == '__main__':
main()
运行后,得到的结果是:
['TSL', 'QBT', 'AIDOC', 'EOS', 'TRX', 'PLC', 'INK', 'WIC']
所以就应该远离上面的那8种币。(君子不立于危墙,虽然都是投机,但最好都是要选择概率天平倾向于自己的那一边) 查看全部
那么coinegg中哪些币是用了tokens发行的呢? 把两个网站的币都爬下来,然后做个交集就可以了。
#-*-coding=utf-8-*-
import requests,datetime
from lxml import etree
import pandas as pd
from sqlalchemy import create_engine
import random,time
user_agent='Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/37.0.2062.120 Chrome/37.0.2062.120 Safari/537.36'
headers={'User-Agent':user_agent}
def getWebContent(url):
# url=url.format(kind)
r=requests.get(url,headers=headers)
if r.status_code==200:
return r.text
else:
return None
def getCoinList():
content=getWebContent(url='https://coinmarketcap.com/tokens/views/all/'
)
tree=etree.HTML(content)
# table=tree.xpath()
# if not table:
# reutrn None
df=pd.DataFrame()
# for coin in table:
df['currency-symbol']=tree.xpath('//tbody/tr//span[@class="currency-symbol"]/a/text()')
df['currency-name']=tree.xpath('//tbody/tr//a[@class="currency-name-container"]/text()')
df['platformsymbol']=tree.xpath('//tbody/tr/@data-platformsymbol')
df['platform-name']=tree.xpath('//tbody/tr//td[@class="no-wrap platform-name"]/a/text()')
df['price(->bct)']=tree.xpath('//tbody/tr//td[@class="no-wrap text-right"]/a/@data-btc')
df['datetime']=datetime.datetime.now()
return df
def getBtcPrice():
btc_p_url='https://www.coinegg.com/index/pricebtc'
try:
r=requests.get(url=btc_p_url,headers=headers)
except Exception,e:
print e
return None
return r.json().get('data').get('cny')
def coinegg_coins():
url='https://www.coinegg.com/coin/btc/allcoin?t={}'.format(random.random())
print url
retry=3
for _ in range(retry):
text=getWebContent(url)
if not text:
continue
time.sleep(random.random())
if not text:
print 'failed to get web content'
return None
return map(lambda x:x.upper(),eval(text).keys())
def find_fake():
df=getCoinList()
coinegglist=set(coinegg_coins())
# print coinegglist
fakecoin=set(df['currency-symbol'].values)
print coinegglist & fakecoin
def main():
# datastore()
# print getBtcPrice()
# coinegg_coins()
find_fake()
if __name__ == '__main__':
main()
运行后,得到的结果是:
['TSL', 'QBT', 'AIDOC', 'EOS', 'TRX', 'PLC', 'INK', 'WIC']
所以就应该远离上面的那8种币。(君子不立于危墙,虽然都是投机,但最好都是要选择概率天平倾向于自己的那一边)
10分钟发行虚拟币
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 24098 次浏览 • 2018-01-14 00:15
3 天前
我本来是不想写这个的,昨天看了曹政的文章《不要试图挑战人性》,感触挺深的,曹大说他2018绝不碰ICO,我恰恰相反,不但要碰我还要带你们一起碰。ICO现在简直是太火了,我平均每星期收到1-2篇whitepaper,绝大多数,可以说是100%都是忽悠人的,我不当韭菜也会有别人被收割,莫不如我今天就给你们指条路——干嘛参与别人的ICO啊?你可以自己搞啊!
废话不说,首先去以太坊下载一个钱包。Ethereum Project
下载完了安装,你的界面应该是这样的:
官方的这个钱包bug非常多!经常打不开,而且和网络sync区块链的时候经常会有各种各样的问题……不过,如果你能侥幸安装成功并且同步成功。
恭喜你,你已经成功克服了你ICO道路上最大的技术难关,胜利在望,会所嫩模在向你招手!
好,打开钱包,界面应该是下面这样:
看到右上角那个“CONTRACTS"按钮了吗?轻轻点一下:
再点这个Deploy New Contract:
然后,打开这个网站:Create a cryptocurrency contract in Ethereum
不懂英文?没问题
看不懂代码?无所谓
看到THE CODE了吗?
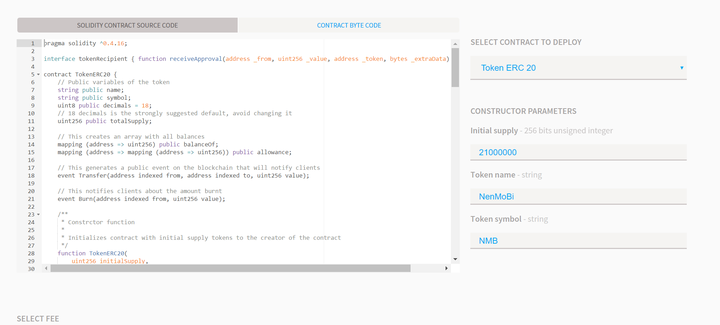
把下面的代码copy下来,然后粘贴到你的以太坊钱包里,再右边下来菜单里面选那个Token ERC 20 ,你会看到的界面大概是这个样子:
这个时候系统会让你输入三个参数:
Initial Supply:你要发行多少个币呢? 我填了2100万个,致敬比特币嘛!
Token Name:咱发行的币叫什么名字呢?我本来想叫刘易杰币……后来一想这太不中本聪了……不忘初衷,ICO骗钱为的就是会所嫩模,就叫嫩模币吧!
Token synbol:就是币的符号,比如比特币是BTC,以太坊是ETH,咱们嫩模币当然是NMB了!
然后下面有个蓝色的deploy,点了这个deploy,嫩模币就正式发布了————这里有个条件,就是钱包里要有少量的ETH,作为执行合约的Gas,大概是0.00几个ETH就够了,也就几美元到几十美元的事儿。
好了。
完成了。
如果你完成了如上所说的步骤的话,那么你成功的在这个世界上,基于以太坊网络,创造了一种新的加密货币————如果这破玩意儿能称为加密货币的话……
我大概解释一下啊这玩意儿是啥:以太坊网络和只能合约,支持一个use case就是用户可以通过以太坊来发行自己的"Token", Token是什么呢?
你可以理解为现实生活当中的“积分”,对,比如加油站洗车店会员卡积分,
楼下发廊Tony老师让你办的冲2000送1000的美发会员卡,奶茶点送你的盖满10个张送一杯的集戳卡,幼儿园老师给小朋友的小红花……
这一切的一切,都是可以在以太坊用很简单的只能合约代码搞成一个"token",然后Token可以通过以太坊网络转账, 转账的时候消耗少量的以太坊ETH做Gas。Token也不需要钱包——使用以太坊钱包就好,钱包地址也是以太坊的地址,钱包秘钥也是以太坊的秘钥,区块链用的就是以太坊的区块链……
说了这么多,就是想让你明白,Token这破玩意儿如此简单,发行如此容易,没有成本,完全是基于以太坊网络,没有任何自己的底层技术,基本上20分钟就能搞出来一个,供应量随便填。
我要说的是:现在有好多所谓的ICO,就是把这Token拿来当币卖……
如上所说创造出来的Token,跟比特币,以太坊,瑞波这些真的“加密货币"完全不是一个东西——我不是要给比特币以太坊这些数字货币站台——我一开始以为,要搞ICO,起码要像比特币那种,自己有区块链,有底层技术,分布账本,钱包,nodes都自己实现吧——虽然这也不是什么难事儿,毕竟都是开源的,但起码这还是有一定成本和壁垒的,结果,这帮骗钱骗疯了的,连这都不搞,直接像我上面发布嫩模币那样,利用小白韭菜们的无知,把Token拿来当成币卖……
打开 All Tokens | CoinMarketCap看看哪些你以为和比特币,以太坊一样的加密货币,其实是和嫩模币NMB一样的Token呢?
有没有很眼熟啊?有没有很心慌啊?你看Platform,就是平台,多数都是以太坊平台,估值……50多亿美金?80多亿美金?
你们觉得嫩模币NMB估值应该多少啊?这么搞下去会不会币太多了,嫩模都不够用了啊……
好,现在币有了,接下来就是ICO难度最大的部分了:
写白皮书啊!
有没有发现现在白皮书天马星空,包罗万象,无所不能?为啥?本质上这玩意儿就是”积分“,能用的上”积分“的地方都能给套进去啊!机械制造,生物制药,航天科技,基因工程,物流运输,文化创作,阴阳五行,一带一路……反正你想怎么写怎么写,这部分就非常考验ICO团队的吹牛逼功力,白皮书写的不好,给观众的想象空间不够,基本可以判断,这个团队平时缺乏诈骗经验……
有了币,有了白皮书,就可以拿去忽悠人了,基本上就是说ICO前期,让对方给你打以太坊ETH,然后你给他发你的嫩模币NMB……他给你以太坊,你给他嫩模币,他给你ETH,你给他NMB……他的以太坊得是1000美金一个真金白银买的,你的NMB可是上面随手填出来的。过不过瘾?爽不爽?
这玩意儿,薄利多销,骗到50算50,骗到100算100,团队别露脸,白皮书上不写名,写名也别写自己名,找两个外国人做adviser,反正韭菜们也不会去验证。核心团队叫基金会,比如咱们负责操作嫩模币的基金会,可以起名叫NMB FOUNDATION。收到ETH直接变现分钱走人,或者另起炉灶,NMB ICO成功完成了,再搞下一个呗,市场需要细分,嫩模有的丑有的俏,针对丑嫩模搞一个丑嫩模币CNMB,俏嫩模的叫QNMB,或者叫嫩模2.0币NM2B,听上去就有互联网时代感……
区块链确实是个好技术,有很多潜力和空间,但究竟有没有好到颠覆世界,有没有好到随便发个tokn就能值十亿八亿的美金,有没有好到能让人打着”区块链“,”智能合约“,”加密货币“的幌子搞诈骗和非法集资能逃脱法律责任,有没有好到能让你买一个Token就赚个几百几千倍。大家自己判断。
*上面说的NMB合约我没deploy,所以你们不用找我要NMB了,不给你们。
**可以把这篇文章转给身边哪些被ICO忽悠的人,或者下次有人拿白皮书来忽悠你,你可以反杀他:你那个币不行,还是来投我的NMB吧!
【手把手教程】空投币怎么领取,以ShiBZilla为例
腾讯云 centos 门罗币 XMR 挖矿 教程 附代码 查看全部
3 天前
我本来是不想写这个的,昨天看了曹政的文章《不要试图挑战人性》,感触挺深的,曹大说他2018绝不碰ICO,我恰恰相反,不但要碰我还要带你们一起碰。ICO现在简直是太火了,我平均每星期收到1-2篇whitepaper,绝大多数,可以说是100%都是忽悠人的,我不当韭菜也会有别人被收割,莫不如我今天就给你们指条路——干嘛参与别人的ICO啊?你可以自己搞啊!
废话不说,首先去以太坊下载一个钱包。Ethereum Project
下载完了安装,你的界面应该是这样的:

官方的这个钱包bug非常多!经常打不开,而且和网络sync区块链的时候经常会有各种各样的问题……不过,如果你能侥幸安装成功并且同步成功。
恭喜你,你已经成功克服了你ICO道路上最大的技术难关,胜利在望,会所嫩模在向你招手!

好,打开钱包,界面应该是下面这样:
看到右上角那个“CONTRACTS"按钮了吗?轻轻点一下:
再点这个Deploy New Contract:
然后,打开这个网站:Create a cryptocurrency contract in Ethereum
不懂英文?没问题
看不懂代码?无所谓
看到THE CODE了吗?

把下面的代码copy下来,然后粘贴到你的以太坊钱包里,再右边下来菜单里面选那个Token ERC 20 ,你会看到的界面大概是这个样子:
这个时候系统会让你输入三个参数:
Initial Supply:你要发行多少个币呢? 我填了2100万个,致敬比特币嘛!
Token Name:咱发行的币叫什么名字呢?我本来想叫刘易杰币……后来一想这太不中本聪了……不忘初衷,ICO骗钱为的就是会所嫩模,就叫嫩模币吧!
Token synbol:就是币的符号,比如比特币是BTC,以太坊是ETH,咱们嫩模币当然是NMB了!
然后下面有个蓝色的deploy,点了这个deploy,嫩模币就正式发布了————这里有个条件,就是钱包里要有少量的ETH,作为执行合约的Gas,大概是0.00几个ETH就够了,也就几美元到几十美元的事儿。
好了。
完成了。
如果你完成了如上所说的步骤的话,那么你成功的在这个世界上,基于以太坊网络,创造了一种新的加密货币————如果这破玩意儿能称为加密货币的话……
我大概解释一下啊这玩意儿是啥:以太坊网络和只能合约,支持一个use case就是用户可以通过以太坊来发行自己的"Token", Token是什么呢?
你可以理解为现实生活当中的“积分”,对,比如加油站洗车店会员卡积分,
楼下发廊Tony老师让你办的冲2000送1000的美发会员卡,奶茶点送你的盖满10个张送一杯的集戳卡,幼儿园老师给小朋友的小红花……
这一切的一切,都是可以在以太坊用很简单的只能合约代码搞成一个"token",然后Token可以通过以太坊网络转账, 转账的时候消耗少量的以太坊ETH做Gas。Token也不需要钱包——使用以太坊钱包就好,钱包地址也是以太坊的地址,钱包秘钥也是以太坊的秘钥,区块链用的就是以太坊的区块链……
说了这么多,就是想让你明白,Token这破玩意儿如此简单,发行如此容易,没有成本,完全是基于以太坊网络,没有任何自己的底层技术,基本上20分钟就能搞出来一个,供应量随便填。
我要说的是:现在有好多所谓的ICO,就是把这Token拿来当币卖……
如上所说创造出来的Token,跟比特币,以太坊,瑞波这些真的“加密货币"完全不是一个东西——我不是要给比特币以太坊这些数字货币站台——我一开始以为,要搞ICO,起码要像比特币那种,自己有区块链,有底层技术,分布账本,钱包,nodes都自己实现吧——虽然这也不是什么难事儿,毕竟都是开源的,但起码这还是有一定成本和壁垒的,结果,这帮骗钱骗疯了的,连这都不搞,直接像我上面发布嫩模币那样,利用小白韭菜们的无知,把Token拿来当成币卖……
打开 All Tokens | CoinMarketCap看看哪些你以为和比特币,以太坊一样的加密货币,其实是和嫩模币NMB一样的Token呢?
有没有很眼熟啊?有没有很心慌啊?你看Platform,就是平台,多数都是以太坊平台,估值……50多亿美金?80多亿美金?
你们觉得嫩模币NMB估值应该多少啊?这么搞下去会不会币太多了,嫩模都不够用了啊……
好,现在币有了,接下来就是ICO难度最大的部分了:
写白皮书啊!
有没有发现现在白皮书天马星空,包罗万象,无所不能?为啥?本质上这玩意儿就是”积分“,能用的上”积分“的地方都能给套进去啊!机械制造,生物制药,航天科技,基因工程,物流运输,文化创作,阴阳五行,一带一路……反正你想怎么写怎么写,这部分就非常考验ICO团队的吹牛逼功力,白皮书写的不好,给观众的想象空间不够,基本可以判断,这个团队平时缺乏诈骗经验……
有了币,有了白皮书,就可以拿去忽悠人了,基本上就是说ICO前期,让对方给你打以太坊ETH,然后你给他发你的嫩模币NMB……他给你以太坊,你给他嫩模币,他给你ETH,你给他NMB……他的以太坊得是1000美金一个真金白银买的,你的NMB可是上面随手填出来的。过不过瘾?爽不爽?
这玩意儿,薄利多销,骗到50算50,骗到100算100,团队别露脸,白皮书上不写名,写名也别写自己名,找两个外国人做adviser,反正韭菜们也不会去验证。核心团队叫基金会,比如咱们负责操作嫩模币的基金会,可以起名叫NMB FOUNDATION。收到ETH直接变现分钱走人,或者另起炉灶,NMB ICO成功完成了,再搞下一个呗,市场需要细分,嫩模有的丑有的俏,针对丑嫩模搞一个丑嫩模币CNMB,俏嫩模的叫QNMB,或者叫嫩模2.0币NM2B,听上去就有互联网时代感……
区块链确实是个好技术,有很多潜力和空间,但究竟有没有好到颠覆世界,有没有好到随便发个tokn就能值十亿八亿的美金,有没有好到能让人打着”区块链“,”智能合约“,”加密货币“的幌子搞诈骗和非法集资能逃脱法律责任,有没有好到能让你买一个Token就赚个几百几千倍。大家自己判断。
*上面说的NMB合约我没deploy,所以你们不用找我要NMB了,不给你们。
**可以把这篇文章转给身边哪些被ICO忽悠的人,或者下次有人拿白皮书来忽悠你,你可以反杀他:你那个币不行,还是来投我的NMB吧!
【手把手教程】空投币怎么领取,以ShiBZilla为例
腾讯云 centos 门罗币 XMR 挖矿 教程 附代码
运行python requests/urllib2/urllib3 需要sudo/root权限,为什么?
回复python • 李魔佛 回复了问题 • 1 人关注 • 1 个回复 • 6605 次浏览 • 2018-01-10 23:36
python模拟登录vexx.pro 获取你的总资产/币值和其他个人信息
python爬虫 • 李魔佛 发表了文章 • 0 个评论 • 3751 次浏览 • 2018-01-10 03:22
# -*-coding=utf-8-*-
import requests
session = requests.Session()
user = ''
password = ''
def getCode():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
url = 'http://vexx.pro/verify/code.html'
s = session.get(url=url, headers=headers)
with open('code.png', 'wb') as f:
f.write(s.content)
code = raw_input('input the code: ')
print 'code is ', code
login_url = 'http://vexx.pro/login/up_login.html'
post_data = {
'moble': user,
'mobles': '+86',
'password': password,
'verify': code,
'login_token': ''}
login_s = session.post(url=login_url, headers=header, data=post_data)
print login_s.status_code
zzc_url = 'http://vexx.pro/ajax/check_zzc/'
zzc_s = session.get(url=zzc_url, headers=headers)
print zzc_s.text
def main():
getCode()
if __name__ == '__main__':
main()
把自己的用户名和密码填上去,中途输入一次验证码。
可以把session保存到本地,然后下一次就可以不用再输入密码。
后记: 经过几个月后,这个网站被证实是一个圈钱跑路的网站,目前已经无法正常登陆了。希望大家不要再上当了
原创地址:http://30daydo.com/article/263
转载请注明出处。 查看全部

# -*-coding=utf-8-*-
import requests
session = requests.Session()
user = ''
password = ''
def getCode():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
url = 'http://vexx.pro/verify/code.html'
s = session.get(url=url, headers=headers)
with open('code.png', 'wb') as f:
f.write(s.content)
code = raw_input('input the code: ')
print 'code is ', code
login_url = 'http://vexx.pro/login/up_login.html'
post_data = {
'moble': user,
'mobles': '+86',
'password': password,
'verify': code,
'login_token': ''}
login_s = session.post(url=login_url, headers=header, data=post_data)
print login_s.status_code
zzc_url = 'http://vexx.pro/ajax/check_zzc/'
zzc_s = session.get(url=zzc_url, headers=headers)
print zzc_s.text
def main():
getCode()
if __name__ == '__main__':
main()
把自己的用户名和密码填上去,中途输入一次验证码。
可以把session保存到本地,然后下一次就可以不用再输入密码。
后记: 经过几个月后,这个网站被证实是一个圈钱跑路的网站,目前已经无法正常登陆了。希望大家不要再上当了
原创地址:http://30daydo.com/article/263
转载请注明出处。
python获取A股上市公司的盈利能力
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 6751 次浏览 • 2018-01-04 16:09
比如企业的盈利能力。
import tushare as ts
#获取2017年第3季度的盈利能力数据
ts.get_profit_data(2017,3)返回的结果:
按年度、季度获取盈利能力数据,结果返回的数据属性说明如下:
code,代码
name,名称
roe,净资产收益率(%)
net_profit_ratio,净利率(%)
gross_profit_rate,毛利率(%)
net_profits,净利润(百万元) #这里的官网信息有误,单位应该是百万
esp,每股收益
business_income,营业收入(百万元)
bips,每股主营业务收入(元)
例如返回如下结果:
code name roe net_profit_ratio gross_profit_rate net_profits \
000717 韶钢松山 79.22 9.44 14.1042 1750.2624
600793 宜宾纸业 65.40 13.31 7.9084 100.6484
600306 商业城 63.19 18.55 17.8601 114.9175
000526 *ST紫学 61.03 2.78 31.1212 63.6477
600768 宁波富邦 57.83 14.95 2.7349 88.3171
原创,转载请注明:
http://30daydo.com/article/260
查看全部
比如企业的盈利能力。
import tushare as ts返回的结果:
#获取2017年第3季度的盈利能力数据
ts.get_profit_data(2017,3)
按年度、季度获取盈利能力数据,结果返回的数据属性说明如下:
code,代码
name,名称
roe,净资产收益率(%)
net_profit_ratio,净利率(%)
gross_profit_rate,毛利率(%)
net_profits,净利润(百万元) #这里的官网信息有误,单位应该是百万
esp,每股收益
business_income,营业收入(百万元)
bips,每股主营业务收入(元)
例如返回如下结果:
code name roe net_profit_ratio gross_profit_rate net_profits \
000717 韶钢松山 79.22 9.44 14.1042 1750.2624
600793 宜宾纸业 65.40 13.31 7.9084 100.6484
600306 商业城 63.19 18.55 17.8601 114.9175
000526 *ST紫学 61.03 2.78 31.1212 63.6477
600768 宁波富邦 57.83 14.95 2.7349 88.3171
原创,转载请注明:
http://30daydo.com/article/260
scipy.misc.lena AttributeError: 'module' object has no attribute 'lena'
python • 李魔佛 发表了文章 • 0 个评论 • 10490 次浏览 • 2018-01-03 19:42
import scipy.misc
lena=scipy.misc.lena()
plt.gray()
plt.imshow(lena)
plt.colorbar()
plt.show()
Error:
lena=scipy.misc.lena()
AttributeError: 'module' object has no attribute 'lena'
定位到scipy包的位置
/usr/local/lib/python2.7/dist-packages/scipy/misc
然后根据文本查找一下: find -name '*.py' | xargs grep 'lena'
果然,没有返回相关的字段。 看样子在scipy 1.0.0版本上已经移除了lena图的数据了。
不过替换了一张其他的图片。 在misc目录下看到一个叫ascent的data, 替换这个函数后:
scipy.misc.ascent()
后,显示一个楼梯的图片。只能凑合着用吧。 lena图自己上网找一张然后数字化就好了。
查看全部
import scipy.misc
lena=scipy.misc.lena()
plt.gray()
plt.imshow(lena)
plt.colorbar()
plt.show()
Error:
lena=scipy.misc.lena()
AttributeError: 'module' object has no attribute 'lena'
定位到scipy包的位置
/usr/local/lib/python2.7/dist-packages/scipy/misc
然后根据文本查找一下: find -name '*.py' | xargs grep 'lena'
果然,没有返回相关的字段。 看样子在scipy 1.0.0版本上已经移除了lena图的数据了。
不过替换了一张其他的图片。 在misc目录下看到一个叫ascent的data, 替换这个函数后:
scipy.misc.ascent()
后,显示一个楼梯的图片。只能凑合着用吧。 lena图自己上网找一张然后数字化就好了。
python获取股票年涨跌幅排名
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 4 个评论 • 9293 次浏览 • 2017-12-30 23:11
作为年终回顾,首先看看A股市场2017的总体涨跌幅排名。
下面函数是用来获取个股某个时间段的涨跌幅。code是股票代码,start为开始时间段,end为结束时间段。def profit(code,start,end):
try:
df=ts.get_k_data(code,start=start,end=end)
except Exception,e:
print e
return None
try:
p=(df['close'].iloc[-1]-df['close'].iloc[0])/df['close'].iloc[0]*100.00
except Exception,e:
print e
return None
return round(p,2)
如果要获取华大基因的2017年涨幅,可以使用profit('300678','2016-12-31','2017-12-31')
需要注意的是,需要添加一个except的异常处理,因为部分个股停牌时间超过一年,所以该股的收盘价都是空的,这种情况就返回一个None值,在dataframe里就是NaN。
剩下了的就是枚举所有A股的个股代码了,然后把遍历所有代码,调用profit函数即可。def price_change():
basic=ts.get_stock_basics()
pro=
for code in basic.index.values:
print code
p=profit(code,'2016-12-31','2017-12-31')
pro.append(p)
basic['price_change']=pro
basic.to_csv('2017_all_price_change.xls',encoding='gbk')
df=pd.read_csv('2017_all_price_change.xls',encoding='gbk')
df.to_excel('2017_all_price_change.xls',encoding='gbk')
结果保存到2017_all_price_change.xls中,里面有个股的基本信息,还追加了一列2017年的涨跌幅,price_change
最后我们把price_change按照从高到低进行排序。 看看哪些个股排名靠前。def analysis():
df=pd.read_excel('2017_all_price_change.xls',encoding='gbk')
df=df.sort_values(by='price_change',ascending=False)
df.to_excel('2017-year.xls',encoding='gbk')
最终保存的文件为2017-year.xls,当然你也可以保存到mysql的数据库当中。engine=get_engine('stock')
df.to_sql('2017years',engine)
其中get_engine() 函数如下定义:def get_engine(db):
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, db))
return engine
只需要把你的mysql数据库的用户名密码等变量加上去就可以了。
最终的结果如下:
点击查看大图
附件是导出来的excel格式的数据,你们可以拿去参考。
下一篇我们来学习统计个股的信息,比如哪类股涨得好,哪类股具有相关性,哪类股和大盘走向类似等等。
原文链接:http://30daydo.com/article/258
转载请注明出处
附件
2017-year.zip
查看全部
作为年终回顾,首先看看A股市场2017的总体涨跌幅排名。
下面函数是用来获取个股某个时间段的涨跌幅。code是股票代码,start为开始时间段,end为结束时间段。
def profit(code,start,end):
try:
df=ts.get_k_data(code,start=start,end=end)
except Exception,e:
print e
return None
try:
p=(df['close'].iloc[-1]-df['close'].iloc[0])/df['close'].iloc[0]*100.00
except Exception,e:
print e
return None
return round(p,2)
如果要获取华大基因的2017年涨幅,可以使用
profit('300678','2016-12-31','2017-12-31')需要注意的是,需要添加一个except的异常处理,因为部分个股停牌时间超过一年,所以该股的收盘价都是空的,这种情况就返回一个None值,在dataframe里就是NaN。
剩下了的就是枚举所有A股的个股代码了,然后把遍历所有代码,调用profit函数即可。
def price_change():
basic=ts.get_stock_basics()
pro=
for code in basic.index.values:
print code
p=profit(code,'2016-12-31','2017-12-31')
pro.append(p)
basic['price_change']=pro
basic.to_csv('2017_all_price_change.xls',encoding='gbk')
df=pd.read_csv('2017_all_price_change.xls',encoding='gbk')
df.to_excel('2017_all_price_change.xls',encoding='gbk')
结果保存到2017_all_price_change.xls中,里面有个股的基本信息,还追加了一列2017年的涨跌幅,price_change
最后我们把price_change按照从高到低进行排序。 看看哪些个股排名靠前。
def analysis():
df=pd.read_excel('2017_all_price_change.xls',encoding='gbk')
df=df.sort_values(by='price_change',ascending=False)
df.to_excel('2017-year.xls',encoding='gbk')
最终保存的文件为2017-year.xls,当然你也可以保存到mysql的数据库当中。
engine=get_engine('stock')
df.to_sql('2017years',engine)
其中get_engine() 函数如下定义:
def get_engine(db):
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, db))
return engine
只需要把你的mysql数据库的用户名密码等变量加上去就可以了。
最终的结果如下:

点击查看大图
附件是导出来的excel格式的数据,你们可以拿去参考。
下一篇我们来学习统计个股的信息,比如哪类股涨得好,哪类股具有相关性,哪类股和大盘走向类似等等。
原文链接:http://30daydo.com/article/258
转载请注明出处
附件
dataframe reindex和reset_index区别
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 83347 次浏览 • 2017-12-30 15:58
df2 = pd.DataFrame({'A': [6], 'B': [60]})
print('df', df)
print('df2', df2)
df_x = [df, df2]
result = pd.concat(df_x)
print('first result ', result)
上面代码把df和df2合并为一个result,但是result的index是乱的。
那么执行result2= result.reset_index()
得到如下的result2: (默认只是返回一个copy,原来的result没有发生改变,所以需要副本赋值给result2)
可以看到,原来的一列index现在变成了columns之一,新的index为[0,1,2,3,4,5]
如果添加参数 reset_index(drop=True) 那么原index会被丢弃,不会显示为一个新列。result2 = result.reset_index(drop=True)
reindex的作用是按照原有的列进行重新生成一个新的df。
还是使用上面的代码
result目前是df和df2的合并序列。
如下:
可以看到index为[0,1,2,3,4,0]
执行 result3 = result.reindex(columns=['A','C'])
可以看到,原index并没有发生改变,而列变成了A和C,因为C是不存在的,所以使用了NaB填充,这个值的内容可以自己填充,可以改为默认填充0或者任意你想要的数据。reindex(columns=..)的作用类似于重新把列的顺序整理一遍, 而使用reindex(index=....) 则按照行重新整理一遍。
原文链接:http://30daydo.com/article/257
欢迎转载,注明出处
查看全部
df = pd.DataFrame({'A': [1, 2, 3, 4, 5], 'B': [10, 20, 30, 40, 50]})
df2 = pd.DataFrame({'A': [6], 'B': [60]})
print('df', df)
print('df2', df2)
df_x = [df, df2]
result = pd.concat(df_x)
print('first result ', result) 上面代码把df和df2合并为一个result,但是result的index是乱的。

那么执行
result2= result.reset_index()
得到如下的result2: (默认只是返回一个copy,原来的result没有发生改变,所以需要副本赋值给result2)

可以看到,原来的一列index现在变成了columns之一,新的index为[0,1,2,3,4,5]
如果添加参数 reset_index(drop=True) 那么原index会被丢弃,不会显示为一个新列。
result2 = result.reset_index(drop=True)

reindex的作用是按照原有的列进行重新生成一个新的df。
还是使用上面的代码
result目前是df和df2的合并序列。
如下:

可以看到index为[0,1,2,3,4,0]
执行
result3 = result.reindex(columns=['A','C'])
可以看到,原index并没有发生改变,而列变成了A和C,因为C是不存在的,所以使用了NaB填充,这个值的内容可以自己填充,可以改为默认填充0或者任意你想要的数据。reindex(columns=..)的作用类似于重新把列的顺序整理一遍, 而使用reindex(index=....) 则按照行重新整理一遍。
原文链接:http://30daydo.com/article/257
欢迎转载,注明出处
dataframe的index索引是否可以重复
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 11483 次浏览 • 2017-12-30 15:10
df = pd.DataFrame({'A': [1, 2, 3, 4, 5], 'B': [10, 20, 30, 40, 50]})
df2 = pd.DataFrame({'A': [6], 'B': [60]})
print 'df\n', df
print 'df2\n', df2输出如下:
df1
df2
然后进行合并: df_x = [df, df2]
result = pd.concat(df_x)
print 'first result\n', result
合并后的结果:
合并后的index是[0,1,2,3,4,0] 所以index集合是一个类似list的结构,而非set结构,允许重复数据的存在。
原文链接:http://30daydo.com/article/256
转载请注明
查看全部
df = pd.DataFrame({'A': [1, 2, 3, 4, 5], 'B': [10, 20, 30, 40, 50]})
df2 = pd.DataFrame({'A': [6], 'B': [60]})
print 'df\n', df
print 'df2\n', df2输出如下:df1

df2

然后进行合并:
df_x = [df, df2]
result = pd.concat(df_x)
print 'first result\n', result
合并后的结果:

合并后的index是[0,1,2,3,4,0] 所以index集合是一个类似list的结构,而非set结构,允许重复数据的存在。
原文链接:http://30daydo.com/article/256
转载请注明
tushare使用get_stock_basic()保存为excel会因为乱码出错而无法保存
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 7404 次浏览 • 2017-12-30 13:11
basic=ts.get_stock_basics()
print basic.info()
print basic.head(10)
basic.to_excel('basic2017.xls',encoding='gbk')
运行后会出错:
'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
很明显的是编问题。
然后尝试使用解决编码的步骤。
1. reload(sys) 设置default为utf-8: 失败
2. to_excel('stock.xls',encoding='gbk') : 失败,encoding参数换了几个都是失败,utf-8,gb2312,cp1252
最后解决的办法是,先把df保存为csv,然后再从csv从读取出来,然后再存储为excel。 整个过程的encoding参数都是用'gbk'.
basic.to_csv('2017_all_price_change.xls',encoding='gbk')
df=pd.read_csv('2017_all_price_change.xls',encoding='gbk')
df.to_excel('2017_all_price_change.xls',encoding='gbk')
查看全部
basic=ts.get_stock_basics()
print basic.info()
print basic.head(10)
basic.to_excel('basic2017.xls',encoding='gbk')
运行后会出错:
'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
很明显的是编问题。
然后尝试使用解决编码的步骤。
1. reload(sys) 设置default为utf-8: 失败
2. to_excel('stock.xls',encoding='gbk') : 失败,encoding参数换了几个都是失败,utf-8,gb2312,cp1252
最后解决的办法是,先把df保存为csv,然后再从csv从读取出来,然后再存储为excel。 整个过程的encoding参数都是用'gbk'.
basic.to_csv('2017_all_price_change.xls',encoding='gbk')
df=pd.read_csv('2017_all_price_change.xls',encoding='gbk')
df.to_excel('2017_all_price_change.xls',encoding='gbk')pandas to_excel函数参数中的文件名需要为.xls
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 11398 次浏览 • 2017-12-29 18:10
会报错。
ValueError: No engine for filetype: ''
需要把文件名也命名为'2017-analysis.xls' 才能过正常运行。
不同于其他本文格式,可以随意命名后缀,然后生成文件后再修改后缀。
查看全部
会报错。
ValueError: No engine for filetype: ''
需要把文件名也命名为'2017-analysis.xls' 才能过正常运行。
不同于其他本文格式,可以随意命名后缀,然后生成文件后再修改后缀。
Dataframe中的plot函数绘图会把日期index自动补全
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 6011 次浏览 • 2017-12-26 14:49
df=pd.read_excel('600050.xls',dtype={'datetime':np.datetime64})
df=df.set_index('datetime')
df['close'].plot(use_index=True,grid=True)
plt.show()
df为中国联通的日线数据,跨度为2016年到2017年底,中间有过一段时间的停牌。 用上面的代码绘制出来的曲线图,回发现,横坐标是日期,可是图中居然会把停牌的日子也插进去,这样导致了图形中间出现了一条长长的折线。
因为停牌后,股价是是不会变化的。
查看全部
df=pd.read_excel('600050.xls',dtype={'datetime':np.datetime64})
df=df.set_index('datetime')
df['close'].plot(use_index=True,grid=True)
plt.show()df为中国联通的日线数据,跨度为2016年到2017年底,中间有过一段时间的停牌。 用上面的代码绘制出来的曲线图,回发现,横坐标是日期,可是图中居然会把停牌的日子也插进去,这样导致了图形中间出现了一条长长的折线。
因为停牌后,股价是是不会变化的。
pandas dataframe read_excel读取的列设置为日期类型datetime
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 22081 次浏览 • 2017-12-25 17:53
如果使用函数 pd.read_excel('xxx.xls') 读入,那么日期列实际会被认为是一个non-null object 类型,虽然可以后期对这个格式进行转换,但其实可以加入一个参数dtype, 就可以在读excel的时候就指定某列的数据类型。
pd.read_excel('xxx.xls',dtype={'出生日期':np.datetime64}
注意np中的datetime类型是datetime64. 查看全部

如果使用函数 pd.read_excel('xxx.xls') 读入,那么日期列实际会被认为是一个non-null object 类型,虽然可以后期对这个格式进行转换,但其实可以加入一个参数dtype, 就可以在读excel的时候就指定某列的数据类型。
pd.read_excel('xxx.xls',dtype={'出生日期':np.datetime64}
注意np中的datetime类型是datetime64.
ubuntu python matplotlib绘图不显示图形
python • 李魔佛 发表了文章 • 0 个评论 • 5697 次浏览 • 2017-12-25 16:37
python 2.7
matplotlib (最新,通过pip安装的)
绘制任何图形都会输出下面的错误:
TypeError: Couldn't find foreign struct converter for 'cairo.Context'
cairo这个依赖库我已经通过apt安装的了。
通过调试,最后发现需要安装这个库:
sudo apt-get install python-gi-cairo
安装后就可以看到图像能够正常显示了。(不然会显示一片空白,其实如果你选择保存的话,然后打开图像,是可以看到绘制出来的图像的) 查看全部
python 2.7
matplotlib (最新,通过pip安装的)
绘制任何图形都会输出下面的错误:
TypeError: Couldn't find foreign struct converter for 'cairo.Context'
cairo这个依赖库我已经通过apt安装的了。
通过调试,最后发现需要安装这个库:
sudo apt-get install python-gi-cairo
安装后就可以看到图像能够正常显示了。(不然会显示一片空白,其实如果你选择保存的话,然后打开图像,是可以看到绘制出来的图像的)
vmware虚拟机在i7 4核8线程的电脑上为什么会很卡
网络安全 • 李魔佛 发表了文章 • 0 个评论 • 9098 次浏览 • 2017-12-24 16:16
cpu性能算很猛的了,虽然内存只有4GB,但怎么也不至于开一个vmware,里面运行ubuntu,会卡成翔。
电脑是32位的win7。CPU的虚拟化被禁止了。
后面经过不断的调整参数,发现问题出现在虚拟机的CPU核心数的设置上。 默认选择了2个CPU核心,当时认为虚拟机占用的CPU核心越少,那么主机host就会不那么卡。 结果发现不是这么一回事。 把CPU数目设置为4后,发现主机host的一点也不卡了。 查看全部

cpu性能算很猛的了,虽然内存只有4GB,但怎么也不至于开一个vmware,里面运行ubuntu,会卡成翔。
电脑是32位的win7。CPU的虚拟化被禁止了。
后面经过不断的调整参数,发现问题出现在虚拟机的CPU核心数的设置上。 默认选择了2个CPU核心,当时认为虚拟机占用的CPU核心越少,那么主机host就会不那么卡。 结果发现不是这么一回事。 把CPU数目设置为4后,发现主机host的一点也不卡了。
微信 支付宝都无法在wp8.1上登录了
网络安全 • 李魔佛 发表了文章 • 0 个评论 • 2992 次浏览 • 2017-12-21 00:39
sign,WP系统算是彻底完蛋了吧。
sign,WP系统算是彻底完蛋了吧。
树莓派安装mongodb服务器
网络 • 李魔佛 发表了文章 • 0 个评论 • 7583 次浏览 • 2017-12-18 16:57
不过安装的是32bit 的mongodb,数据库的大小会被限制在2GB。
树莓派启动mongodb
修改/etc/mongodb.config,
把里面的bind=127.0.0.1 注释掉,前面加一个#即可,因为这样其他主机也可以访问这台树莓派的mongodb服务器。
修改dbpath和dblog的路径,因为默认的路径你需要root权限
然后运行 mongod --config /etc/mongodb.config , 然后远程使用mongo ip地址就可以远程连接了。 查看全部
不过安装的是32bit 的mongodb,数据库的大小会被限制在2GB。
树莓派启动mongodb
修改/etc/mongodb.config,
把里面的bind=127.0.0.1 注释掉,前面加一个#即可,因为这样其他主机也可以访问这台树莓派的mongodb服务器。
修改dbpath和dblog的路径,因为默认的路径你需要root权限
然后运行 mongod --config /etc/mongodb.config , 然后远程使用mongo ip地址就可以远程连接了。
使用官网下载的mongodb,如何设置远程连接mongodb服务器
网络安全 • 李魔佛 发表了文章 • 0 个评论 • 5030 次浏览 • 2017-12-17 23:10
解压后在mongo的bin目录下运行 mongod --dbpath ~/mongo/db
可以看到mongodb服务被正常启动了。
在局域网其他电脑上使用mongodb客户端尝试连接这个mongo服务器,发现无法连接上。
因为官网下载的mongo问价解压后并没有mongo.conf配置文件。
在本机运行命令: mongo
可以看到输出:
Server has startup warnings:
2017-12-17T22:56:19.702+0800 I STORAGE [initandlisten]
2017-12-17T22:56:19.702+0800 I STORAGE [initandlisten] ** WARNING: Using the XFS filesystem is strongly recommended with the WiredTiger storage engine
2017-12-17T22:56:19.702+0800 I STORAGE [initandlisten] ** See http://dochub.mongodb.org/core ... ystem
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten]
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database.
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted.
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten]
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** WARNING: This server is bound to localhost.
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** Remote systems will be unable to connect to this server.
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** Start the server with --bind_ip <address> to specify which IP
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** addresses it should serve responses from, or with --bind_ip_all to
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** bind to all interfaces. If this behavior is desired, start the
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** server with --bind_ip 127.0.0.1 to disable this warning.
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten]
2017-12-17T22:56:20.601+0800 I CONTROL [initandlisten]
2017-12-17T22:56:20.601+0800 I CONTROL [initandlisten] ** WARNING: /sys/kernel/mm/transparent_hugepage/defrag is 'always'.
2017-12-17T22:56:20.601+0800 I CONTROL [initandlisten] ** We suggest setting it to 'never'
2017-12-17T22:56:20.601+0800 I CONTROL [initandlisten]
从上面的信息可以看到,如果需要远程的机子连接到本机,需要添加一个选项: --bind_ip_all
运行下面命令后:
mongod --dbpath ~/mongo/db --bind_ip_all
远程的机子就能够连上mongo服务器了。
原文地址:http://30daydo.com/article/247
转载请注明出处 查看全部
解压后在mongo的bin目录下运行 mongod --dbpath ~/mongo/db
可以看到mongodb服务被正常启动了。
在局域网其他电脑上使用mongodb客户端尝试连接这个mongo服务器,发现无法连接上。
因为官网下载的mongo问价解压后并没有mongo.conf配置文件。
在本机运行命令: mongo
可以看到输出:
Server has startup warnings:
2017-12-17T22:56:19.702+0800 I STORAGE [initandlisten]
2017-12-17T22:56:19.702+0800 I STORAGE [initandlisten] ** WARNING: Using the XFS filesystem is strongly recommended with the WiredTiger storage engine
2017-12-17T22:56:19.702+0800 I STORAGE [initandlisten] ** See http://dochub.mongodb.org/core ... ystem
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten]
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database.
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted.
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten]
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** WARNING: This server is bound to localhost.
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** Remote systems will be unable to connect to this server.
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** Start the server with --bind_ip <address> to specify which IP
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** addresses it should serve responses from, or with --bind_ip_all to
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** bind to all interfaces. If this behavior is desired, start the
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten] ** server with --bind_ip 127.0.0.1 to disable this warning.
2017-12-17T22:56:20.600+0800 I CONTROL [initandlisten]
2017-12-17T22:56:20.601+0800 I CONTROL [initandlisten]
2017-12-17T22:56:20.601+0800 I CONTROL [initandlisten] ** WARNING: /sys/kernel/mm/transparent_hugepage/defrag is 'always'.
2017-12-17T22:56:20.601+0800 I CONTROL [initandlisten] ** We suggest setting it to 'never'
2017-12-17T22:56:20.601+0800 I CONTROL [initandlisten]
从上面的信息可以看到,如果需要远程的机子连接到本机,需要添加一个选项: --bind_ip_all
运行下面命令后:
mongod --dbpath ~/mongo/db --bind_ip_all
远程的机子就能够连上mongo服务器了。
原文地址:http://30daydo.com/article/247
转载请注明出处
python多线程出现错误 thread.error: can't start new thread
python • 李魔佛 发表了文章 • 0 个评论 • 16012 次浏览 • 2017-12-14 17:58
解决办法就是加锁或者合理退出一些占用资源的线程。
解决办法就是加锁或者合理退出一些占用资源的线程。
[scrapy]修改爬虫默认user agent的多种方法
python爬虫 • 李魔佛 发表了文章 • 0 个评论 • 10011 次浏览 • 2017-12-14 16:22
3. 目标站点:
https://helloacm.com/api/user-agent/
这一个站点直接返回用户的User-Agent, 这样你就可以直接查看你的User-Agent是否设置成功。
尝试用浏览器打开网址
https://helloacm.com/api/user-agent/,
网站直接返回:
"Mozilla\/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit\/537.36 (KHTML, like Gecko) Chrome\/62.0.3202.94 Safari\/537.36"
3. 配置scrapy
在spider文件夹的headervalidation.py 修改为一下内容。class HeadervalidationSpider(scrapy.Spider):
name = 'headervalidation'
allowed_domains = ['helloacm.com']
start_urls = ['http://helloacm.com/api/user-agent/']
def parse(self, response):
print '*'*20
print response.body
print '*'*20
项目只是打印出response的body,也就是打印出访问的User-Agent信息。
运行:scrapy crawl headervalidation会发现返回的是503。 接下来,我们修改scrapy的User-Agent
方法1:
修改setting.py中的User-Agent# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Hello World'
然后重新运行scrapy crawl headervalidation
这个时候,能够看到正常的scrapy输出了。2017-12-14 16:17:35 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-12-14 16:17:35 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://helloacm.com/api/us
er-agent/> from <GET http://helloacm.com/api/user-agent/>
2017-12-14 16:17:36 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://helloacm.com/api/user-agent/> (referer: None)
[b]********************
"Hello World"
********************
[/b]2017-12-14 16:17:37 [scrapy.core.engine] INFO: Closing spider (finished)
2017-12-14 16:17:37 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 406,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 796,
'downloader/response_count': 2,
'downloader/response_status_count/200': 1,
'downloader/response_status_count/301': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 12, 14, 8, 17, 37, 29000),
'log_count/DEBUG': 3,
'log_count/INFO': 7,
'response_received_count': 1,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2017, 12, 14, 8, 17, 35, 137000)}
2017-12-14 16:17:37 [scrapy.core.engine] INFO: Spider closed (finished)
正确设置了User-Agent
方法2.
修改setting中的
DEFAULT_REQUEST_HEADERS# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Hello World'
}
运行后也能够看到上面的输出。
方法3.
在代码中修改。class HeadervalidationSpider(scrapy.Spider):
name = 'headervalidation'
allowed_domains = ['helloacm.com']
def start_requests(self):
header={'User-Agent':'Hello World'}
yield scrapy.Request(url='http://helloacm.com/api/user-agent/',headers=header)
def parse(self, response):
print '*'*20
print response.body
print '*'*20
运行后也能够看到下面的输出。2017-12-14 16:17:35 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-12-14 16:17:35 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://helloacm.com/api/us
er-agent/> from <GET http://helloacm.com/api/user-agent/>
2017-12-14 16:17:36 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://helloacm.com/api/user-agent/> (referer: None)
********************
"Hello World"
********************
2017-12-14 16:17:37 [scrapy.core.engine] INFO: Closing spider (finished)
2017-12-14 16:17:37 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
方法4.
在中间件中自定义Header
在项目目录下添加一个目录:
customerMiddleware,在目录中新建一个自定义的中间件文件:
文件名随意为 customMiddleware.py
文件内容为修改request User-Agent#-*-coding=utf-8-*-
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware
class CustomerUserAgent(UserAgentMiddleware):
def process_request(self, request, spider):
ua='HELLO World?????????'
request.headers.setdefault('User-Agent',ua)
在setting中添加下面一句,以便使中间件生效。DOWNLOADER_MIDDLEWARES = {
'headerchange.customerMiddleware.customMiddleware.CustomerUserAgent':10
# 'headerchange.middlewares.MyCustomDownloaderMiddleware': 543,
}
然后重新运行,同样能够得到一样的效果。
原创文章,转载请注明:http://30daydo.com/article/245
附上github的源码:https://github.com/Rockyzsu/base_function/tree/master/scrapy_demo/headerchange
欢迎star和点赞。
如果你觉得文章对你有用,可以视乎你心情来打赏,以支持小站的服务器网络费用。
你的支持是我最大的动力!
PS:谢谢下面朋友的打赏
A Keung
阿贾克斯
白驹过隙
Che Long 查看全部
scrapy startproject headerchange2. 创建爬虫文件
scrapy genspider headervalidation helloacm.com
3. 目标站点:
https://helloacm.com/api/user-agent/
这一个站点直接返回用户的User-Agent, 这样你就可以直接查看你的User-Agent是否设置成功。
尝试用浏览器打开网址
https://helloacm.com/api/user-agent/,
网站直接返回:
"Mozilla\/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit\/537.36 (KHTML, like Gecko) Chrome\/62.0.3202.94 Safari\/537.36"
3. 配置scrapy
在spider文件夹的headervalidation.py 修改为一下内容。
class HeadervalidationSpider(scrapy.Spider):
name = 'headervalidation'
allowed_domains = ['helloacm.com']
start_urls = ['http://helloacm.com/api/user-agent/']
def parse(self, response):
print '*'*20
print response.body
print '*'*20
项目只是打印出response的body,也就是打印出访问的User-Agent信息。
运行:
scrapy crawl headervalidation会发现返回的是503。 接下来,我们修改scrapy的User-Agent
方法1:
修改setting.py中的User-Agent
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Hello World'
然后重新运行
scrapy crawl headervalidation
这个时候,能够看到正常的scrapy输出了。
2017-12-14 16:17:35 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-12-14 16:17:35 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://helloacm.com/api/us
er-agent/> from <GET http://helloacm.com/api/user-agent/>
2017-12-14 16:17:36 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://helloacm.com/api/user-agent/> (referer: None)
[b]********************
"Hello World"
********************
[/b]2017-12-14 16:17:37 [scrapy.core.engine] INFO: Closing spider (finished)
2017-12-14 16:17:37 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 406,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 796,
'downloader/response_count': 2,
'downloader/response_status_count/200': 1,
'downloader/response_status_count/301': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 12, 14, 8, 17, 37, 29000),
'log_count/DEBUG': 3,
'log_count/INFO': 7,
'response_received_count': 1,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2017, 12, 14, 8, 17, 35, 137000)}
2017-12-14 16:17:37 [scrapy.core.engine] INFO: Spider closed (finished)
正确设置了User-Agent
方法2.
修改setting中的
DEFAULT_REQUEST_HEADERS
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Hello World'
}
运行后也能够看到上面的输出。
方法3.
在代码中修改。
class HeadervalidationSpider(scrapy.Spider):
name = 'headervalidation'
allowed_domains = ['helloacm.com']
def start_requests(self):
header={'User-Agent':'Hello World'}
yield scrapy.Request(url='http://helloacm.com/api/user-agent/',headers=header)
def parse(self, response):
print '*'*20
print response.body
print '*'*20
运行后也能够看到下面的输出。
2017-12-14 16:17:35 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-12-14 16:17:35 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://helloacm.com/api/us
er-agent/> from <GET http://helloacm.com/api/user-agent/>
2017-12-14 16:17:36 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://helloacm.com/api/user-agent/> (referer: None)
********************
"Hello World"
********************
2017-12-14 16:17:37 [scrapy.core.engine] INFO: Closing spider (finished)
2017-12-14 16:17:37 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
方法4.
在中间件中自定义Header
在项目目录下添加一个目录:
customerMiddleware,在目录中新建一个自定义的中间件文件:
文件名随意为 customMiddleware.py
文件内容为修改request User-Agent
#-*-coding=utf-8-*-
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware
class CustomerUserAgent(UserAgentMiddleware):
def process_request(self, request, spider):
ua='HELLO World?????????'
request.headers.setdefault('User-Agent',ua)
在setting中添加下面一句,以便使中间件生效。
DOWNLOADER_MIDDLEWARES = {
'headerchange.customerMiddleware.customMiddleware.CustomerUserAgent':10
# 'headerchange.middlewares.MyCustomDownloaderMiddleware': 543,
}然后重新运行,同样能够得到一样的效果。
原创文章,转载请注明:http://30daydo.com/article/245
附上github的源码:https://github.com/Rockyzsu/base_function/tree/master/scrapy_demo/headerchange
欢迎star和点赞。

如果你觉得文章对你有用,可以视乎你心情来打赏,以支持小站的服务器网络费用。
你的支持是我最大的动力!
PS:谢谢下面朋友的打赏
A Keung
阿贾克斯
白驹过隙
Che Long
[读后笔记] python网络爬虫实战 (李松涛)
书籍 • 李魔佛 发表了文章 • 0 个评论 • 3424 次浏览 • 2017-12-14 11:28
前面4章是基础的python知识,有基础的同学可以略过。
scrapy爬虫部分,用了实例给大家说明scrapy的用法,不过如果之前没用过scrapy的话,需要慢慢上机敲打代码。
其实书中的例子都是很简单的例子,基本没什么反爬的限制,书中一句话说的非常赞同,用scrapy写爬虫,就是做填空题,而用urllib2写爬虫,就是作文题,可以自由发挥。
书中没有用更为方便的requests库。 内容搜索用的最多的是beatifulsoup, 对于xpah或者lxml介绍的比较少。 因为scrapy自带的response就是可以直接用xpath,更为方便。
对于scrapy的中间和pipeline的使用了一个例子,也是比较简单的例子。
书中没有对验证码,分布式等流行的反爬进行讲解,应该适合爬虫入门的同学去看吧。
书中一点很好的就是代码都非常规范,而且即使是写作文的使用urllib2,也有意模仿scrapy的框架去写, 需要抓取的数据 独立一个类,类似于scrapy的item,数据处理用的也是叫pipleline的方法。
这样写的好处就是, 每个模块的功能都一目了然,看完第一个例子的类和函数定义,后面的例子都是大同小异,可以加快读者的阅读速度,非常赞。(这一点以后自己要学习,增加代码的可复用性)
很多页面url现在已经过期了,再次运行作者的源码会返回很多404的结果。
失效的项目:
金逸影城
天气预报
获取代理:http://proxy360.com
本书的一些错误的地方:
1. 获取金逸影城的spider中,所有关于movie的拼写都拼错为moive了。这个属于英语错误。
2. 在testProxy.py 代码中, 由于在同一个类中,一直在产生线程,最后导致线程过多,不能再产生线程。程序会中途退出。
File "C:\Python27\lib\threading.py", line 736, in start
_start_new_thread(self.__bootstrap, ())
thread.error: can't start new thread
可以修改成独立函数的形式,而不是类函数。
待续。 查看全部

用了大概一个早上的时间,就把这本书看完了。
前面4章是基础的python知识,有基础的同学可以略过。
scrapy爬虫部分,用了实例给大家说明scrapy的用法,不过如果之前没用过scrapy的话,需要慢慢上机敲打代码。
其实书中的例子都是很简单的例子,基本没什么反爬的限制,书中一句话说的非常赞同,用scrapy写爬虫,就是做填空题,而用urllib2写爬虫,就是作文题,可以自由发挥。
书中没有用更为方便的requests库。 内容搜索用的最多的是beatifulsoup, 对于xpah或者lxml介绍的比较少。 因为scrapy自带的response就是可以直接用xpath,更为方便。
对于scrapy的中间和pipeline的使用了一个例子,也是比较简单的例子。
书中没有对验证码,分布式等流行的反爬进行讲解,应该适合爬虫入门的同学去看吧。
书中一点很好的就是代码都非常规范,而且即使是写作文的使用urllib2,也有意模仿scrapy的框架去写, 需要抓取的数据 独立一个类,类似于scrapy的item,数据处理用的也是叫pipleline的方法。
这样写的好处就是, 每个模块的功能都一目了然,看完第一个例子的类和函数定义,后面的例子都是大同小异,可以加快读者的阅读速度,非常赞。(这一点以后自己要学习,增加代码的可复用性)
很多页面url现在已经过期了,再次运行作者的源码会返回很多404的结果。
失效的项目:
金逸影城
天气预报
获取代理:http://proxy360.com
本书的一些错误的地方:
1. 获取金逸影城的spider中,所有关于movie的拼写都拼错为moive了。这个属于英语错误。
2. 在testProxy.py 代码中, 由于在同一个类中,一直在产生线程,最后导致线程过多,不能再产生线程。程序会中途退出。
File "C:\Python27\lib\threading.py", line 736, in start
_start_new_thread(self.__bootstrap, ())
thread.error: can't start new thread
可以修改成独立函数的形式,而不是类函数。
待续。
shield tablet 英伟达神盾平板变砖修复
Android • 李魔佛 发表了文章 • 7 个评论 • 13199 次浏览 • 2017-12-12 00:24
结果就坑爹了 (因为是因为系统是从安卓5.0直接OTA到7.0,系统的一些分区信息作了比较大的改动,导致启动分区数据丢失)。
重启后一直卡在启动logo,无法再进入系统。 按着音量+和电源键, 可以进入到BootLoader模式,然后选择recovery模式,等待进入recovery模式,结果看到的是一个躺着的安卓机器人。 Org!
然后准备尝试用fastboot的方式重新刷入一个新的系统。
ROM选择英伟达官方的:https://developer.nvidia.com/gameworksdownload#?search=SHIELD%20Tablet%20WiFi%20Recovery%20OS%20Image&tx=$additional,shield
然后安装官方教程进行刷机。以下步骤:
1. 按着音量上键和电源键进入BootLoader,如果你的系统是第一次进入BootLoader,那么第一次需要解锁BootLoader。
连接平板到电脑,然后安装fastboot的驱动, 下载连接 https://developer.nvidia.com/shield-open-source
运行命令 fastboot devices
如果驱动成功的话,会显示你的平板序列号。然后才能进行以下的操作。
fastboot oem unlock
解锁oem锁,需要你在平板上再次按下电源键 进行确认。 几秒钟后,平板的BootLoader就会被解锁。
2. 然后按照ROM的说明文件readme,进行刷机:
fastboot flash recovery recovery.img
fastboot flash boot boot.img
fastboot flash system system.img
fastboot erase userdata
fastboot flash staging blob
3. 刷完后,使用fastboot reboot 进行重启设备。
设备重启后第一次需要大概几分钟的时间进行初始化设置。
经过漫长的等待后,居然发现系统还是卡在那个nvidia的logo那里。
感觉自己应该是刷错ROM了,因为官方那里有WIFI版,有LTE版,有美版和欧版,而且也分Shield Tablet K1 和非K1的, 我应该用了K1的rom,所以失败了。因为我的机子应该是非K1的,虽然二者硬件没什么大的区别。
然后重新按照上面的步骤,重新刷入非K1的ROM。 重启后,发现问题依然没有解决。
没办法,只能上国外的论坛去找办法。
尝试刷入第三方的recovery,用recovery来恢复系统。
首先,下载一个第三方的recovery,TWRP image。 具体链接百度一下就可以了。
下载后刷入到平板 : fastboot flash recovery xxxxx.img
xxxx.img就是下载的recovery文件名。
刷好后再次进入BootLoader,选择recovery mode,可以看到很多的选项,这个时候看到了希望了。
不过进入到TWRP recovery后,也无法看到系统的内置存储。不过里面有一个adb sideload的功能。
这个时候连上USB线,在电脑端输入 adb sideload xxxx.zip, zip为你的OTA的单独文件包,这里你可以去下载一个第三方的ROM文件,不过我试过之后,发现居然可以开机了,但是开完机会有一个加密的密码,随便输入一个密码,居然能够进去,然后需要重启进行恢复出厂设置。 等待重启完成之后,却又见到这个加密的选项。看来没有进行出厂设置成功。
重试几次,发现问题依然存在。
那么只能重新尝试刷入官方的rom,但是不刷官方的recovery rom。
fastboot flash boot boot.img
fastboot flash system system.img
fastboot erase userdata
然后重启,发现能够开机并且初始化,也没有那个加密的菜单了。
问题得到解决。 查看全部
结果就坑爹了 (因为是因为系统是从安卓5.0直接OTA到7.0,系统的一些分区信息作了比较大的改动,导致启动分区数据丢失)。
重启后一直卡在启动logo,无法再进入系统。 按着音量+和电源键, 可以进入到BootLoader模式,然后选择recovery模式,等待进入recovery模式,结果看到的是一个躺着的安卓机器人。 Org!
然后准备尝试用fastboot的方式重新刷入一个新的系统。
ROM选择英伟达官方的:https://developer.nvidia.com/gameworksdownload#?search=SHIELD%20Tablet%20WiFi%20Recovery%20OS%20Image&tx=$additional,shield
然后安装官方教程进行刷机。以下步骤:
1. 按着音量上键和电源键进入BootLoader,如果你的系统是第一次进入BootLoader,那么第一次需要解锁BootLoader。
连接平板到电脑,然后安装fastboot的驱动, 下载连接 https://developer.nvidia.com/shield-open-source
运行命令 fastboot devices
如果驱动成功的话,会显示你的平板序列号。然后才能进行以下的操作。
fastboot oem unlock
解锁oem锁,需要你在平板上再次按下电源键 进行确认。 几秒钟后,平板的BootLoader就会被解锁。
2. 然后按照ROM的说明文件readme,进行刷机:
fastboot flash recovery recovery.img
fastboot flash boot boot.img
fastboot flash system system.img
fastboot erase userdata
fastboot flash staging blob
3. 刷完后,使用fastboot reboot 进行重启设备。
设备重启后第一次需要大概几分钟的时间进行初始化设置。
经过漫长的等待后,居然发现系统还是卡在那个nvidia的logo那里。
感觉自己应该是刷错ROM了,因为官方那里有WIFI版,有LTE版,有美版和欧版,而且也分Shield Tablet K1 和非K1的, 我应该用了K1的rom,所以失败了。因为我的机子应该是非K1的,虽然二者硬件没什么大的区别。
然后重新按照上面的步骤,重新刷入非K1的ROM。 重启后,发现问题依然没有解决。
没办法,只能上国外的论坛去找办法。
尝试刷入第三方的recovery,用recovery来恢复系统。
首先,下载一个第三方的recovery,TWRP image。 具体链接百度一下就可以了。
下载后刷入到平板 : fastboot flash recovery xxxxx.img
xxxx.img就是下载的recovery文件名。
刷好后再次进入BootLoader,选择recovery mode,可以看到很多的选项,这个时候看到了希望了。
不过进入到TWRP recovery后,也无法看到系统的内置存储。不过里面有一个adb sideload的功能。
这个时候连上USB线,在电脑端输入 adb sideload xxxx.zip, zip为你的OTA的单独文件包,这里你可以去下载一个第三方的ROM文件,不过我试过之后,发现居然可以开机了,但是开完机会有一个加密的密码,随便输入一个密码,居然能够进去,然后需要重启进行恢复出厂设置。 等待重启完成之后,却又见到这个加密的选项。看来没有进行出厂设置成功。
重试几次,发现问题依然存在。
那么只能重新尝试刷入官方的rom,但是不刷官方的recovery rom。
fastboot flash boot boot.img
fastboot flash system system.img
fastboot erase userdata
然后重启,发现能够开机并且初始化,也没有那个加密的菜单了。
问题得到解决。
菜鸟侦探挑战数据分析R源代码
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 2955 次浏览 • 2017-12-11 17:45
百度网盘下载链接:
https://pan.baidu.com/s/1miiScDM
数字货币量化揭秘-简单暴力但高效的高频交易机器人
量化交易-Ptrade-QMT • littleDream 发表了文章 • 1 个评论 • 6904 次浏览 • 2017-12-05 16:23
这个策略是我做虚拟货币以来的主要策略,后面经过不断完善和修改,复杂了很多,但主要思想并没有改变,分享的这个版本是无明显bug的 最初版本,最为简单清晰,没有仓位管理,每次交易都是满仓,没有卡死后重启等等,但也足够说明问题。
策略从2014年8月运行,直到今年年初交易所收手续费。期间运行的还算很好,亏损的时间很少。资金从最初的200元跑到了80比特币。具体的过程可以看[小草的新浪博客](小草_新浪博客)里[虚拟货币自动化交易之路](虚拟货币自动化交易之路(五)_小草_新浪博客)系列文章。
下图是总资产折合币的曲线:
为什么分享这个策略
1.交易所收取手续费后,几乎杀死了所有的高频策略,我的也不例外。但策略改改也许还能用,大家可以研究一下。
2.好久没有分享东西了,这篇文章早就想写了。
3.和大家共同交流学习。
策略的原理
这个策略原理极为简单,可以理解为准高频的做市策略,各位看了之后可能想打人,这都能赚钱,当时几乎谁都能写出来。我开始也没预料到它能这么有效,可见心中有想法要赶紧付出实践,说不一定有意外之喜。在比特币机器人初兴的2014年,写出赚钱的策略太容易了。
和所有的高频策略一样,本策略也是基于orderbook,下图就是一个典型的比特币交易所的订单分布,
可以看到左侧是买单,显示了不同价格的挂单数量,右侧是卖单。可以想象如果一个人要买入比特币,如果不想挂单等待的话,只能选择吃单,如果他的单子比较多,会使得卖单挂单大量成交,对价格造成冲击,但是这种冲击一般不会一直持续,还有人想吃单卖出,价格在极短时间很可能还会恢复,反过来理解有人要卖币也类似。
以图中的挂单为例,如果要直接买入5个币,那么价格会达到10377,在这时如果有人要直接卖出5个币,价格会达到10348,这个空间就是利润空间.策略会在稍低于10377的价格挂单,如10376.99,同时会以稍高于10348的价格买入,如10348.01,这是如果刚才的情况发生了,显然就会赚到其中的差价。虽然不会每次都如此完美,但在概率的作用下,赚钱的几率实际高得惊人。
以现在策略的参数讲解一下具体操作,这个参数当然无法使用了,仅作一个说明。它会向上寻找累计卖挂单量为8个币的价格,这里是10377,那么此时的卖价就是这个价格减去0.01(减去多少可以是随机的),同理向下寻找累计买挂单为8个币,这里是10348,那么此时的卖价就是10348.01,此时买卖价的差价是10376.99-10348.01=28.98,大于策略预设的差价1.5,就以这两个价格挂单等待成交,如果价差小于1.5,也会找一个价格进行挂单,如盘口价格加减10,等待捡漏(更合适的应该是继续往下找跟多的深度)。
进一步的说明
1. 没有钱或币了怎么办?
这种情况在我的钱较少是十分普遍,大多数时候只挂一边的单子,但不是大问题。其实可以加入币钱平衡的逻辑,但在平衡的过程难免产生损失,毕竟每一次的成交都是概率的垂青,我选择保持单边等待成交,当然这样也浪费了另一边的成交机会。
2. 仓位是如何管理的?
刚开始都是满仓买入卖出,后来根据不同的参数分为不同的组,不会一次完全成交。
3. 没有止损吗?
策略有完整的买卖挂单的逻辑,我认为不需要止损(可以讨论),还有就是概率的垂青,成交就是机会,止损可惜了。
4. 如何调整为赚币的策略?
此时的参数是对称的,即向上8个币的累计卖单,向下8个币的累计买单,稍微不平衡一下,比如向上改为15个币的累计卖单,使得卖币机会更难得,有更大的几率会以更低的价格接回来,这样就会赚币,反过来就赚钱。实际上前期策略如此有效,币和钱都是增加的。
代码讲解
完整的代码可以见我在http://www.botvs.com得策略分享,这里只讲解核心逻辑函数。在没有改动的情况下,在botvs自带的模拟盘竟然运转完全正常,这是一个3年多前的策略,平台还支持到现在,太让人感动了。
首先是获取买卖价函数GetPrice(),需要获取订单深度信息,注意不同平台的订单深度信息长度不同,以及即使遍历了所有订单仍然没有所需要的量的情况(在后期许多0.01的网格挂单会导致这种情况),调用是GetPrice('Buy')就是获取买价。
function GetPrice(Type) {
//_C()是平台的容错函数
var depth=_C(exchange.GetDepth);
var amountBids=0;
var amountAsks=0;
//计算买价,获取累计深度达到预设的价格
if(Type=="Buy"){
for(var i=0;i<20;i++){
amountBids+=depth.Bids[i].Amount;
//参数floatamountbuy是预设的累计深度
if (amountBids>floatamountbuy){
//稍微加0.01,使得订单排在前面
return depth.Bids[i].Price+0.01;}
}
}
//同理计算卖价
if(Type=="Sell"){
for(var j=0; j<20; j++){
amountAsks+=depth.Asks[j].Amount;
if (amountAsks>floatamountsell){
return depth.Asks[j].Price-0.01;}
}
}
//遍历了全部深度仍未满足需求,就返回一个价格,以免出现bug
return depth.Asks[0].Price
}
// 每个循环的主函数onTick(),这里定的循环时间3.5s,每次循环都会把原来的单子撤销,重新挂单,越简单越不会遇到bug.
function onTick() {
var buyPrice = GetPrice("Buy");
var sellPrice= GetPrice("Sell");
//diffprice是预设差价,买卖价差如果小于预设差价,就会挂一个相对更深的价格
if ((sellPrice - buyPrice) <= diffprice){
buyPrice-=10;
sellPrice+=10;}
//把原有的单子全部撤销,实际上经常出现新的价格和已挂单价格相同的情况,此时不需要撤销
CancelPendingOrders()
//获取账户信息,确定目前账户存在多少钱和多少币
var account=_C(exchange.GetAccount);
//可买的比特币量,_N()是平台的精度函数
var amountBuy = _N((account.Balance / buyPrice-0.1),2);
//可卖的比特币量,注意到没有仓位的限制,有多少就买卖多少,因为我当时的钱很少
var amountSell = _N((account.Stocks),2);
if (amountSell > 0.02) {
exchange.Sell(sellPrice,amountSell);}
if (amountBuy > 0.02) {
exchange.Buy(buyPrice, amountBuy);}
//休眠,进入下一轮循环
Sleep(sleeptime);
}
尾巴
整个程序也就40多行,看上去十分简单,但当时也花了我一个多星期,这还是在botvs平台上情况下。最大的优势还是起步早,在2014年,市场上以搬砖为主,网格和抢盘口的高频也不多,使得策略如鱼得水,后来竞争不可避免越来越激烈,我的钱也越来越多,面临的挑战很多,每隔一段时间都要进行较大的改动来应对,但总体还算顺利。在交易平台不收取手续费的情况下,是程序化交易的天堂,散户因为不收手续费跟倾向于操作,为高频和套利提供了空间,这一切也基本随着动辄0.1-0.2%的双向手续费终结了,不仅是自己被收费的问题,而是整个市场活跃度下降。
但不需要高频的量化策略任然有很大的空间。
作者 小草 查看全部
这个策略是我做虚拟货币以来的主要策略,后面经过不断完善和修改,复杂了很多,但主要思想并没有改变,分享的这个版本是无明显bug的 最初版本,最为简单清晰,没有仓位管理,每次交易都是满仓,没有卡死后重启等等,但也足够说明问题。
策略从2014年8月运行,直到今年年初交易所收手续费。期间运行的还算很好,亏损的时间很少。资金从最初的200元跑到了80比特币。具体的过程可以看[小草的新浪博客](小草_新浪博客)里[虚拟货币自动化交易之路](虚拟货币自动化交易之路(五)_小草_新浪博客)系列文章。

下图是总资产折合币的曲线:

为什么分享这个策略
1.交易所收取手续费后,几乎杀死了所有的高频策略,我的也不例外。但策略改改也许还能用,大家可以研究一下。
2.好久没有分享东西了,这篇文章早就想写了。
3.和大家共同交流学习。
策略的原理
这个策略原理极为简单,可以理解为准高频的做市策略,各位看了之后可能想打人,这都能赚钱,当时几乎谁都能写出来。我开始也没预料到它能这么有效,可见心中有想法要赶紧付出实践,说不一定有意外之喜。在比特币机器人初兴的2014年,写出赚钱的策略太容易了。
和所有的高频策略一样,本策略也是基于orderbook,下图就是一个典型的比特币交易所的订单分布,

可以看到左侧是买单,显示了不同价格的挂单数量,右侧是卖单。可以想象如果一个人要买入比特币,如果不想挂单等待的话,只能选择吃单,如果他的单子比较多,会使得卖单挂单大量成交,对价格造成冲击,但是这种冲击一般不会一直持续,还有人想吃单卖出,价格在极短时间很可能还会恢复,反过来理解有人要卖币也类似。
以图中的挂单为例,如果要直接买入5个币,那么价格会达到10377,在这时如果有人要直接卖出5个币,价格会达到10348,这个空间就是利润空间.策略会在稍低于10377的价格挂单,如10376.99,同时会以稍高于10348的价格买入,如10348.01,这是如果刚才的情况发生了,显然就会赚到其中的差价。虽然不会每次都如此完美,但在概率的作用下,赚钱的几率实际高得惊人。
以现在策略的参数讲解一下具体操作,这个参数当然无法使用了,仅作一个说明。它会向上寻找累计卖挂单量为8个币的价格,这里是10377,那么此时的卖价就是这个价格减去0.01(减去多少可以是随机的),同理向下寻找累计买挂单为8个币,这里是10348,那么此时的卖价就是10348.01,此时买卖价的差价是10376.99-10348.01=28.98,大于策略预设的差价1.5,就以这两个价格挂单等待成交,如果价差小于1.5,也会找一个价格进行挂单,如盘口价格加减10,等待捡漏(更合适的应该是继续往下找跟多的深度)。
进一步的说明
1. 没有钱或币了怎么办?
这种情况在我的钱较少是十分普遍,大多数时候只挂一边的单子,但不是大问题。其实可以加入币钱平衡的逻辑,但在平衡的过程难免产生损失,毕竟每一次的成交都是概率的垂青,我选择保持单边等待成交,当然这样也浪费了另一边的成交机会。
2. 仓位是如何管理的?
刚开始都是满仓买入卖出,后来根据不同的参数分为不同的组,不会一次完全成交。
3. 没有止损吗?
策略有完整的买卖挂单的逻辑,我认为不需要止损(可以讨论),还有就是概率的垂青,成交就是机会,止损可惜了。
4. 如何调整为赚币的策略?
此时的参数是对称的,即向上8个币的累计卖单,向下8个币的累计买单,稍微不平衡一下,比如向上改为15个币的累计卖单,使得卖币机会更难得,有更大的几率会以更低的价格接回来,这样就会赚币,反过来就赚钱。实际上前期策略如此有效,币和钱都是增加的。
代码讲解
完整的代码可以见我在http://www.botvs.com得策略分享,这里只讲解核心逻辑函数。在没有改动的情况下,在botvs自带的模拟盘竟然运转完全正常,这是一个3年多前的策略,平台还支持到现在,太让人感动了。
首先是获取买卖价函数GetPrice(),需要获取订单深度信息,注意不同平台的订单深度信息长度不同,以及即使遍历了所有订单仍然没有所需要的量的情况(在后期许多0.01的网格挂单会导致这种情况),调用是GetPrice('Buy')就是获取买价。
function GetPrice(Type) {
//_C()是平台的容错函数
var depth=_C(exchange.GetDepth);
var amountBids=0;
var amountAsks=0;
//计算买价,获取累计深度达到预设的价格
if(Type=="Buy"){
for(var i=0;i<20;i++){
amountBids+=depth.Bids[i].Amount;
//参数floatamountbuy是预设的累计深度
if (amountBids>floatamountbuy){
//稍微加0.01,使得订单排在前面
return depth.Bids[i].Price+0.01;}
}
}
//同理计算卖价
if(Type=="Sell"){
for(var j=0; j<20; j++){
amountAsks+=depth.Asks[j].Amount;
if (amountAsks>floatamountsell){
return depth.Asks[j].Price-0.01;}
}
}
//遍历了全部深度仍未满足需求,就返回一个价格,以免出现bug
return depth.Asks[0].Price
}
// 每个循环的主函数onTick(),这里定的循环时间3.5s,每次循环都会把原来的单子撤销,重新挂单,越简单越不会遇到bug.
function onTick() {
var buyPrice = GetPrice("Buy");
var sellPrice= GetPrice("Sell");
//diffprice是预设差价,买卖价差如果小于预设差价,就会挂一个相对更深的价格
if ((sellPrice - buyPrice) <= diffprice){
buyPrice-=10;
sellPrice+=10;}
//把原有的单子全部撤销,实际上经常出现新的价格和已挂单价格相同的情况,此时不需要撤销
CancelPendingOrders()
//获取账户信息,确定目前账户存在多少钱和多少币
var account=_C(exchange.GetAccount);
//可买的比特币量,_N()是平台的精度函数
var amountBuy = _N((account.Balance / buyPrice-0.1),2);
//可卖的比特币量,注意到没有仓位的限制,有多少就买卖多少,因为我当时的钱很少
var amountSell = _N((account.Stocks),2);
if (amountSell > 0.02) {
exchange.Sell(sellPrice,amountSell);}
if (amountBuy > 0.02) {
exchange.Buy(buyPrice, amountBuy);}
//休眠,进入下一轮循环
Sleep(sleeptime);
}尾巴
整个程序也就40多行,看上去十分简单,但当时也花了我一个多星期,这还是在botvs平台上情况下。最大的优势还是起步早,在2014年,市场上以搬砖为主,网格和抢盘口的高频也不多,使得策略如鱼得水,后来竞争不可避免越来越激烈,我的钱也越来越多,面临的挑战很多,每隔一段时间都要进行较大的改动来应对,但总体还算顺利。在交易平台不收取手续费的情况下,是程序化交易的天堂,散户因为不收手续费跟倾向于操作,为高频和套利提供了空间,这一切也基本随着动辄0.1-0.2%的双向手续费终结了,不仅是自己被收费的问题,而是整个市场活跃度下降。
但不需要高频的量化策略任然有很大的空间。
作者 小草
怀孕妈妈 深港1年学车路
量化交易 • 绫波丽 发表了文章 • 0 个评论 • 3307 次浏览 • 2017-11-29 14:57
接下来开始走流程,准备交资料,拍照,等待了10几天,才有了流水号,8月4日,参加了理论培训
生产完,就去考了科一,还好幸运的是10月份科一98分通过了~ 计划美美的,以为可以在产假期间顺利练完,考完所谓的最难的科二,科三就不在话下了,然后就坐等拿驾照了,可是,没有这么多可是,艰辛的学车路才拉开帷幕啊~
11月中旬,在深港客服那边拿到了科二教练的电话号码,兴致满满,谦逊的和教练通了电话,顺利约到了第二天下午2点练车
为了避免迟到,早早的去到练车场,去到时和教练打了招呼,他就说“今天先练习打方向盘”,他教了一次,就让我打者,那个方向盘是一根柱子上套了一个方向盘,左一圈,右一圈打了2个小时,只能观望真车,却不能上车的心情一下有点落寞。。。
后面2个小时过后,教练试图建议我加300练自动档,我还是没有答应,他就说 那今天先到这吧,下次再约
为了能在假期争取多练车,我就抓住机会问教练,下次什么时候可以过来,他没有正面回复我,只是说有时间我会安排你,我知道无法争取了,就说 那好吧。在第二次约车时直接回复 人太多练不了,当时我就开始体会到,原来有时间练车,也很难约到车。
心情又一下子沮丧了
又过了一周多,后面学习其他学员采取送烟送礼的方式,成功约到了车,也成功上了车练了前进后退
通过和其他学员了解,深深明白了学车的风气及约车的困难,教练的脾气后,对自己美好的计划再也没有了期待
时间一天天过去
偶尔可以去练车的日子也变得平常,一直到了2017年中旬,进入深圳酷热的夏天
在科二最难的项目“倒车入库”上挣扎学习了一个多月,某天约车时,教练回复我说“他不再带我们这个班了,说我们这个班有新的教练带我们”
这消息来得突然,霎时间不知道自己分到了什么教练,分在哪个练车场,赶紧问深港客服
后来经过几天了解才得知要去宝安那边学车,想到一下子又要跑到这么远的地方练车,太浪费时间,所以索性自己争取换教练。
又过了一周,才换号教练,重新投入练习
此时假期已用完,不能随叫随到了,由于平时要上班,只有周末有空,练车路变得更加艰辛(周末练车人太多了)
新教练风气脾气依旧,不过心里已有准备,再也不像刚开始那样寄予美好愿望了
不过新教练是一个快到斩乱麻的人,5月底,在我去练习不到一周的时间,就帮我加入了科二报考
考前顶着热辣辣的太阳,在端午三天假期强化训练了3天,教练也带我们去社会考场(交了200大洋)进行模拟考试,模拟也失败了,回家哭得一塌糊涂
果然,很可惜,第一次科二还是失败了;沮丧,灰心,内疚充斥着那个夏天,过了一个月又重新越考,7月份 天气更热了,即使穿了防晒衣,那太阳足以晒得通红脱皮,黑白分明,最后搞到发烧中暑~
又回到科二考场,第一把由于太过紧张,脚抖,败在了自己平时练得还不错的“直角转弯” ;顶着巨大的压力,开始了第二把考试,慢慢的走完了全程,终于拿下科二,开心到感觉整个人要飞起来~
科三,大家都说很简单,心里又开始美起来了,等啊等啊,终于在10月底约到了科三教练
也许是太久没摸车了,也许是科二的练习方法不适合科三,也许是自己毫无车感,也许是第一次在大马路开车,不管有多少个 也许,直接的结果是,手脚不协调,眼睛无法关注远方,无法把车修直,完全不会开啊,天也渐渐的黑了,教练在一旁也完全对我失去了信心,语重心长停下车来对我说“现在科三有新规了,要带油门走的,不是那么简单的,你还是加300改报自动档吧”
我听完也很难过,心里无比的自卑和落寞
但是,我还是意志坚定和教练说“好的,我知道自己开得很差,我接下来回去在模拟机上好好练, 如果还是练不好,我会考虑您的建议的“
就这样,安排了自己一个星期在模拟机上练习,终于找到了一点开车的感觉,毕竟模拟机还是模拟机,所以当自己再次重新投入真车练习时,由于实际路况比较复杂,油门还是不敢轻易踩上去,不过,教练还是夸了我一句”比以前进步很大“
相对比科二来说,科三约车练习容易很多,所以此次内心更多的戒掉了科二时对驾校的迷茫,更多是关注了自己技巧的不足。哪里不足哪里自己课后在模拟机上有针对性的强加练习开始,慢慢的终于开得比较好了。
1个月后,成功了约到考试(白石洲考场)据说白石洲考场在12月就不对外考试了,所以我此次考试更加要努力,不然又要重新训练及适应其他考场,压力会更加大。
考前是紧张的,因为深深知道自己并不是很有把握。 重点讲下考试当天吧。
考试时间是安排在10-11点那一场。早上8点,再次按教练所说的到练车场练了一圈,考前练习,这是很好的经验。
虽然按照计划10点前赶到了考场,但是足足焦急万分的等到了中午12点才轮到自己,那会又饿又不安
看到前面很多学员 直接起步后就挂在了靠边停车那个项目,还没来得及走完整个考场~越看越紧张
直到自己真的上到了车上,也许是紧张的心情,感觉位置怎么做怎么不舒服,离合踩下去很滑,一会就松开
我一直在念念叨叨,怎么办,离合这么滑,离合这么滑,一直在试车,或许试了几分钟吧,但感觉已经像过了几个世纪
貌似都觉得安全员已对我不耐烦了,可是我还是觉得自己没有准备好,终于按下了第一次指纹,模拟夜考后,开始起步了,果然第一把也同样挂在了”靠边停车“ ,拉起手刹后,系统立即播报考试结束,天啊,当时的心情足以差到极点,就这样,我只剩下一次机会了啊,已完全没有退路了
车又被安全员开回起点,绕车一圈后,重新试车,只有最后一次机会的我,真的不敢再起步,我害怕失败,害怕就这样回家
可是,无法后退,只能跟自己说,没事的,慢慢来
鼓起所有勇气,再次按下指纹,认真完成了模拟夜考,小心翼翼的起步,慢慢的完成了靠边停车,悬着的心稍微有点放松,再缓缓的起步,完成了直线形势,每走一个项目,都和自己说一遍,接下来是变更车道,需要打灯,2挡超车,3挡进入学校区域,人行横道,停车换1挡起步,3挡进入公交车站前进行点刹,打灯,1挡掉头,继续2挡上3挡学校区域,路口直行,1挡起步。上2上3,公交车站提前点刹,打灯右转,最后进行加档操作,顺利完成所有项目,当时内心已激动不已,但是一刻没有到停止线时,都不能掉以轻心,当听到考试结束,成绩合格,所有紧张不安,换成了无以言表的喜悦和激动。。。
科三过了,心就定了,也顺利当天考完了科四,当发信息给教练传送战绩时,教练的回复时“啊,你确定你过了吗 你这么差都能过?不要搞错哦,把成绩单发来看看吧“ 我突然觉得空气夹杂着尴尬,原来一直以来自己竟然教练心目中最差的学员。不过庆幸地是,自己没有辜负所有帮助过自己的人。顺利拿到驾照。 查看全部
这几年几乎都听到身边的人都在考驾照(特别是亲眼见证自己的妹妹在半年多就拿到驾照)当自己怀孕7个月时,想到马上临近为期5至6个月产假,难得有假期(不过新手妈妈忽略了有娃后再也没有自由的概念啊)一股冲动及热流涌上心头后,我要报考驾照! 对学车路没有任何了解的情况下,就这样在2016年7月选择了深圳知名度最广的深港报了名·(将近6k大洋)
接下来开始走流程,准备交资料,拍照,等待了10几天,才有了流水号,8月4日,参加了理论培训
生产完,就去考了科一,还好幸运的是10月份科一98分通过了~ 计划美美的,以为可以在产假期间顺利练完,考完所谓的最难的科二,科三就不在话下了,然后就坐等拿驾照了,可是,没有这么多可是,艰辛的学车路才拉开帷幕啊~
11月中旬,在深港客服那边拿到了科二教练的电话号码,兴致满满,谦逊的和教练通了电话,顺利约到了第二天下午2点练车
为了避免迟到,早早的去到练车场,去到时和教练打了招呼,他就说“今天先练习打方向盘”,他教了一次,就让我打者,那个方向盘是一根柱子上套了一个方向盘,左一圈,右一圈打了2个小时,只能观望真车,却不能上车的心情一下有点落寞。。。
后面2个小时过后,教练试图建议我加300练自动档,我还是没有答应,他就说 那今天先到这吧,下次再约
为了能在假期争取多练车,我就抓住机会问教练,下次什么时候可以过来,他没有正面回复我,只是说有时间我会安排你,我知道无法争取了,就说 那好吧。在第二次约车时直接回复 人太多练不了,当时我就开始体会到,原来有时间练车,也很难约到车。
心情又一下子沮丧了
又过了一周多,后面学习其他学员采取送烟送礼的方式,成功约到了车,也成功上了车练了前进后退
通过和其他学员了解,深深明白了学车的风气及约车的困难,教练的脾气后,对自己美好的计划再也没有了期待
时间一天天过去
偶尔可以去练车的日子也变得平常,一直到了2017年中旬,进入深圳酷热的夏天
在科二最难的项目“倒车入库”上挣扎学习了一个多月,某天约车时,教练回复我说“他不再带我们这个班了,说我们这个班有新的教练带我们”
这消息来得突然,霎时间不知道自己分到了什么教练,分在哪个练车场,赶紧问深港客服
后来经过几天了解才得知要去宝安那边学车,想到一下子又要跑到这么远的地方练车,太浪费时间,所以索性自己争取换教练。
又过了一周,才换号教练,重新投入练习
此时假期已用完,不能随叫随到了,由于平时要上班,只有周末有空,练车路变得更加艰辛(周末练车人太多了)
新教练风气脾气依旧,不过心里已有准备,再也不像刚开始那样寄予美好愿望了
不过新教练是一个快到斩乱麻的人,5月底,在我去练习不到一周的时间,就帮我加入了科二报考
考前顶着热辣辣的太阳,在端午三天假期强化训练了3天,教练也带我们去社会考场(交了200大洋)进行模拟考试,模拟也失败了,回家哭得一塌糊涂
果然,很可惜,第一次科二还是失败了;沮丧,灰心,内疚充斥着那个夏天,过了一个月又重新越考,7月份 天气更热了,即使穿了防晒衣,那太阳足以晒得通红脱皮,黑白分明,最后搞到发烧中暑~
又回到科二考场,第一把由于太过紧张,脚抖,败在了自己平时练得还不错的“直角转弯” ;顶着巨大的压力,开始了第二把考试,慢慢的走完了全程,终于拿下科二,开心到感觉整个人要飞起来~
科三,大家都说很简单,心里又开始美起来了,等啊等啊,终于在10月底约到了科三教练
也许是太久没摸车了,也许是科二的练习方法不适合科三,也许是自己毫无车感,也许是第一次在大马路开车,不管有多少个 也许,直接的结果是,手脚不协调,眼睛无法关注远方,无法把车修直,完全不会开啊,天也渐渐的黑了,教练在一旁也完全对我失去了信心,语重心长停下车来对我说“现在科三有新规了,要带油门走的,不是那么简单的,你还是加300改报自动档吧”
我听完也很难过,心里无比的自卑和落寞
但是,我还是意志坚定和教练说“好的,我知道自己开得很差,我接下来回去在模拟机上好好练, 如果还是练不好,我会考虑您的建议的“
就这样,安排了自己一个星期在模拟机上练习,终于找到了一点开车的感觉,毕竟模拟机还是模拟机,所以当自己再次重新投入真车练习时,由于实际路况比较复杂,油门还是不敢轻易踩上去,不过,教练还是夸了我一句”比以前进步很大“
相对比科二来说,科三约车练习容易很多,所以此次内心更多的戒掉了科二时对驾校的迷茫,更多是关注了自己技巧的不足。哪里不足哪里自己课后在模拟机上有针对性的强加练习开始,慢慢的终于开得比较好了。
1个月后,成功了约到考试(白石洲考场)据说白石洲考场在12月就不对外考试了,所以我此次考试更加要努力,不然又要重新训练及适应其他考场,压力会更加大。
考前是紧张的,因为深深知道自己并不是很有把握。 重点讲下考试当天吧。
考试时间是安排在10-11点那一场。早上8点,再次按教练所说的到练车场练了一圈,考前练习,这是很好的经验。
虽然按照计划10点前赶到了考场,但是足足焦急万分的等到了中午12点才轮到自己,那会又饿又不安
看到前面很多学员 直接起步后就挂在了靠边停车那个项目,还没来得及走完整个考场~越看越紧张
直到自己真的上到了车上,也许是紧张的心情,感觉位置怎么做怎么不舒服,离合踩下去很滑,一会就松开
我一直在念念叨叨,怎么办,离合这么滑,离合这么滑,一直在试车,或许试了几分钟吧,但感觉已经像过了几个世纪
貌似都觉得安全员已对我不耐烦了,可是我还是觉得自己没有准备好,终于按下了第一次指纹,模拟夜考后,开始起步了,果然第一把也同样挂在了”靠边停车“ ,拉起手刹后,系统立即播报考试结束,天啊,当时的心情足以差到极点,就这样,我只剩下一次机会了啊,已完全没有退路了
车又被安全员开回起点,绕车一圈后,重新试车,只有最后一次机会的我,真的不敢再起步,我害怕失败,害怕就这样回家
可是,无法后退,只能跟自己说,没事的,慢慢来
鼓起所有勇气,再次按下指纹,认真完成了模拟夜考,小心翼翼的起步,慢慢的完成了靠边停车,悬着的心稍微有点放松,再缓缓的起步,完成了直线形势,每走一个项目,都和自己说一遍,接下来是变更车道,需要打灯,2挡超车,3挡进入学校区域,人行横道,停车换1挡起步,3挡进入公交车站前进行点刹,打灯,1挡掉头,继续2挡上3挡学校区域,路口直行,1挡起步。上2上3,公交车站提前点刹,打灯右转,最后进行加档操作,顺利完成所有项目,当时内心已激动不已,但是一刻没有到停止线时,都不能掉以轻心,当听到考试结束,成绩合格,所有紧张不安,换成了无以言表的喜悦和激动。。。
科三过了,心就定了,也顺利当天考完了科四,当发信息给教练传送战绩时,教练的回复时“啊,你确定你过了吗 你这么差都能过?不要搞错哦,把成绩单发来看看吧“ 我突然觉得空气夹杂着尴尬,原来一直以来自己竟然教练心目中最差的学员。不过庆幸地是,自己没有辜负所有帮助过自己的人。顺利拿到驾照。
TypeError: reduction operation 'argmin' not allowed for this dtype
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 11374 次浏览 • 2017-11-19 18:48
date = date + '-01-01'
cmd = 'select * from `{}` where datetime > \'{}\''.format(code, date)
try:
df = pd.read_sql(cmd, history_engine,index_col='index')
except Exception,e:
print e
return None
# 不知道为啥,这里的类型发生改变
idx= df['low'].idxmin()
TypeError: reduction operation 'argmin' not allowed for this dtype
把df的每列数据类型打印出来看看。
print df.dtypes
datetime datetime64[ns]
code object
name object
open object
close object
high object
low object
vol float64
amount float64
dtype: object
晕,居然把low这些float类型全部转为了object,所以解决办法就是把这些列的数据转为float64.
df['low']=df['low'].astype('float64')
这样之后,问题就解决了。
查看全部
date = date + '-01-01'
cmd = 'select * from `{}` where datetime > \'{}\''.format(code, date)
try:
df = pd.read_sql(cmd, history_engine,index_col='index')
except Exception,e:
print e
return None
# 不知道为啥,这里的类型发生改变
idx= df['low'].idxmin()
TypeError: reduction operation 'argmin' not allowed for this dtype
把df的每列数据类型打印出来看看。
print df.dtypes
datetime datetime64[ns]
code object
name object
open object
close object
high object
low object
vol float64
amount float64
dtype: object
晕,居然把low这些float类型全部转为了object,所以解决办法就是把这些列的数据转为float64.
df['low']=df['low'].astype('float64')
这样之后,问题就解决了。
matplotlib pie饼图 lable设置中文乱码 解决办法
python • 李魔佛 发表了文章 • 0 个评论 • 13239 次浏览 • 2017-11-03 17:10
labels = [u'百度',u'京东',u'陆金所',u'工行',u'招行',u'华泰',u'国金',u'广发',u'QQ']
plt.figure()
p = plt.pie(X,labels=labels)
(实际X的数据为其他数据,这里只是简单的设为1的列表)
google了些资料,找到以下可行的解决办法:
找一个系统自带的中文字体文件的路径
比如这一个:C:\Windows\winsxs\amd64_microsoft-windows-font-truetype-simfang_31bf3856ad364e35_6.1.7600.16385_none_e417159f3b4eb1b7\simfang.ttf
把路径拷贝下来。
然后在代码中设置: for front in p[1]:
front.set_fontproperties(mpl.font_manager.FontProperties(
fname='C:\Windows\winsxs\amd64_microsoft-windows-font-truetype-simfang_31bf3856ad364e35_6.1.7600.16385_none_e417159f3b4eb1b7\simfang.ttf'))
把 p中的font属性强制改为指向我们想要的字体路径,这样就可以达到修改饼图上的中文乱码问题了。
正常显示中文了。
在linux下同理,只需要下载一个字体文件,放在某个目录,然后在代码中指定字体的位置。
字体文件下载: https://fontzone.net/download/simhei
然后运行: $locate -b '\mpl-data'
看看mpl目录的位置,把字体文件放到fonts/ttf这个目录下面,
如果使用代码设定,如下:#!/usr/bin/env python
#coding:utf-8
"""a demo of matplotlib"""
import matplotlib as mpl
from matplotlib import pyplot as plt
mpl.rcParams[u'font.sans-serif'] = ['simhei']
mpl.rcParams['axes.unicode_minus'] = False
years = [1950, 1960, 1970, 1980, 1990, 2000, 2010]
gdp = [300.2, 543.3, 1075.9, 2862.5, 5979.6, 10289.7, 14958.3]
#创建一副线图,x轴是年份,y轴是gdp
plt.plot(years, gdp, color='green', marker='o', linestyle='solid')
#添加一个标题
plt.title(u'名义GDP')
#给y轴加标记
plt.ylabel(u'十亿美元')
plt.show()
PS:
在树莓派上回出现的问题:
UserWarning: findfont: Font family [u'sans-serif'] not found. Falling back to DejaVu Sanspi@raspb DejaVu Sans^CserWarning: findfont: Font family [u'sans-serif'] not found. Falling back to
这个时候只要安装一个font-manager就可以了:
sudo apt install font-manager
OK ! 查看全部
X=[1,1,1,1,1,1,1]
labels = [u'百度',u'京东',u'陆金所',u'工行',u'招行',u'华泰',u'国金',u'广发',u'QQ']
plt.figure()
p = plt.pie(X,labels=labels)

(实际X的数据为其他数据,这里只是简单的设为1的列表)
google了些资料,找到以下可行的解决办法:
找一个系统自带的中文字体文件的路径
比如这一个:C:\Windows\winsxs\amd64_microsoft-windows-font-truetype-simfang_31bf3856ad364e35_6.1.7600.16385_none_e417159f3b4eb1b7\simfang.ttf
把路径拷贝下来。
然后在代码中设置:
for front in p[1]:
front.set_fontproperties(mpl.font_manager.FontProperties(
fname='C:\Windows\winsxs\amd64_microsoft-windows-font-truetype-simfang_31bf3856ad364e35_6.1.7600.16385_none_e417159f3b4eb1b7\simfang.ttf'))
把 p中的font属性强制改为指向我们想要的字体路径,这样就可以达到修改饼图上的中文乱码问题了。

正常显示中文了。
在linux下同理,只需要下载一个字体文件,放在某个目录,然后在代码中指定字体的位置。
字体文件下载: https://fontzone.net/download/simhei
然后运行: $locate -b '\mpl-data'
看看mpl目录的位置,把字体文件放到fonts/ttf这个目录下面,
如果使用代码设定,如下:
#!/usr/bin/env python
#coding:utf-8
"""a demo of matplotlib"""
import matplotlib as mpl
from matplotlib import pyplot as plt
mpl.rcParams[u'font.sans-serif'] = ['simhei']
mpl.rcParams['axes.unicode_minus'] = False
years = [1950, 1960, 1970, 1980, 1990, 2000, 2010]
gdp = [300.2, 543.3, 1075.9, 2862.5, 5979.6, 10289.7, 14958.3]
#创建一副线图,x轴是年份,y轴是gdp
plt.plot(years, gdp, color='green', marker='o', linestyle='solid')
#添加一个标题
plt.title(u'名义GDP')
#给y轴加标记
plt.ylabel(u'十亿美元')
plt.show()
PS:
在树莓派上回出现的问题:
UserWarning: findfont: Font family [u'sans-serif'] not found. Falling back to DejaVu Sanspi@raspb DejaVu Sans^CserWarning: findfont: Font family [u'sans-serif'] not found. Falling back to
这个时候只要安装一个font-manager就可以了:
sudo apt install font-manager
OK !
You must either define the environment variable DJANGO_SETTINGS_MODULE
python • 李魔佛 发表了文章 • 0 个评论 • 5227 次浏览 • 2017-10-08 12:41
from django import template
def template_usage():
t = template.Template('My name is {{ name }}')
c = template.Context({'name':'Rocky'})
print t.render(c)
template_usage()
就出错了。
这个原因一般就是直接使用python或者ipython交互解析器造成的。
你需要切换到你的django目录,然后使用python manager.py shell 运行, 然后执行上面的函数或者代码, 就不会再出现这个错误了
django.core.exceptions.ImproperlyConfigured: Requested setting TEMPLATES, but settings are not configured. You must either define the environment variable DJANGO_SETTINGS_MODULE or call settings.configure() before accessing settings.
查看全部
from django import template
def template_usage():
t = template.Template('My name is {{ name }}')
c = template.Context({'name':'Rocky'})
print t.render(c)
template_usage()
就出错了。
这个原因一般就是直接使用python或者ipython交互解析器造成的。
你需要切换到你的django目录,然后使用python manager.py shell 运行, 然后执行上面的函数或者代码, 就不会再出现这个错误了
django.core.exceptions.ImproperlyConfigured: Requested setting TEMPLATES, but settings are not configured. You must either define the environment variable DJANGO_SETTINGS_MODULE or call settings.configure() before accessing settings.
儿歌多多 下载全部儿歌视频文件
python爬虫 • 李魔佛 发表了文章 • 0 个评论 • 15871 次浏览 • 2017-09-28 23:44
http://30daydo.com/article/236
更新 ******** 2018-01-09*************
最近才发现以前曾经挖了这个坑,现在来完成它吧。
儿歌多多在爱奇艺的视频网站上也有全集,所以目标转为抓取iqiyi的儿歌多多视频列表。
github上有一个现成的下载iqiyi的第三方库,可以通过python调用这个库来实现下载功能。
代码使用python3来实现。
1. 打开网页 http://www.iqiyi.com/v_19rrkwcx6w.html#curid=455603300_26b870cbb10342a6b8a90f7f0b225685
这个是第一集的儿歌多多,url后面的curid只是一个随机的字符串,可以直接去掉。
url=“http://www.iqiyi.com/v_19rrkwcx6w.htm”
浏览器直接查看源码,里面直接包含了1-30集的视频url,那么要做的就是提取这30个url
先抓取网页内容:session = requests.Session()
def getContent(url):
try:
ret = session.get(url)
except:
return None
if ret.status_code==200:
return ret.text
else:
return None
然后提取内容中的url
点击查看大图
提取div标签中的属性 data-current-count=1的。然后选择子节点中的li标签,提取li中的a中的href链接即可。 content = getContent(url)
root = etree.HTML(content)
elements=root.xpath('//div[@data-current-count="1"]//li/a/@href')
for items in elements:
song_url = items.replace('//','')
song_url=song_url.strip()
print(song_url)
2. 有了url,就可以下载这个页面的中的内容了。
这里我使用的是一个第三方的视频下载库,you-get。(非常好用,fork到自己仓库研究 https://github.com/Rockyzsu/you-get)
使用方法:
python you-get -d --format=HD url
you-get 需要下载一个ffmpeg.exe的文件来解码视频流的,去官网就可以免费下载。
url就是你要下载的url地址,format可以选择高清还是其他格式的,我这里选择的是HD。
在python脚本里面调用另外一个python脚本,可以使用subprocess来调用。 p=subprocess.Popen('python you-get -d --format=HD {}'.format(song_url),stderr=subprocess.PIPE,stdout=subprocess.PIPE,shell=True)
output,error = p.communicate()
print(output)
print(error)
p.wait()
上面的song_url 就是接着最上面那个代码的。
完整代码如下:#-*-coding=utf-8-*-
import requests
from lxml import etree
import subprocess
session = requests.Session()
def getContent(url):
# url='http://www.iqiyi.com/v_19rrkwcx6w.html'
try:
ret = session.get(url)
# except Exception,e:
except:
# print e
return None
if ret.status_code==200:
return ret.text
else:
return None
def getUrl():
url='http://www.iqiyi.com/v_19rrkwcx6w.html'
url2='http://www.iqiyi.com/v_19rrl2td7g.html' # 31-61
content = getContent(url)
root = etree.HTML(content)
elements=root.xpath('//div[@data-current-count="1"]//li/a/@href')
for items in elements:
song_url = items.replace('//','')
song_url=song_url.strip()
print(song_url)
p=subprocess.Popen('python you-get -d --format=HD {}'.format(song_url),stderr=subprocess.PIPE,stdout=subprocess.PIPE,shell=True)
output,error = p.communicate()
print(output)
print(error)
p.wait()
def main():
getUrl()
if __name__ == '__main__':
main()
上面的是1-30集的,全部集数现在是120集,31-60的在url
http://www.iqiyi.com/v_19rrl2td7g.html
这个url只要你选择iqiyi视频的右边栏,就会自动变化。 同理也可以找到61-120的url,然后替换到上面代码中最开始的url就可以了。(这里因为页码少,所以就没有用循环去做)
最终的下载结果:
后面修改了下代码,判断文件是不是已经存在,存在的会就不下载,对于长时间下载100多个文件很有用,如果掉线了,重新下载就不会去下载那些已经下好的。#-*-coding=utf-8-*-
import sys,os
import requests
from lxml import etree
import subprocess
session = requests.Session()
def getContent(url):
# url='http://www.iqiyi.com/v_19rrkwcx6w.html'
try:
ret = requests.get(url)
ret.encoding='utf-8'
# except Exception,e:
except:
# print e
return None
if ret.status_code==200:
return ret.text
else:
return None
def getUrl():
url='http://www.iqiyi.com/v_19rrkwcx6w.html'
url2='http://www.iqiyi.com/v_19rrl2td7g.html' # 31-61
content = getContent(url)
if not content:
print "network issue, retry"
exit(0)
root = etree.HTML(content,parser=etree.HTMLParser(encoding='utf-8'))
elements=root.xpath('//div[@data-current-count="1"]//li')
for items in elements:
url_item=items.xpath('.//a/@href')[0]
song_url = url_item.replace('//','')
song_url=song_url.strip()
print(song_url)
# name=items.xpath('.//span[@class="item-num"]/text()')[0]
name=items.xpath('.//span[@class="item-num"]/text()')[0].encode('utf-8').strip()+\
' '+items.xpath('.//span[@class="item-txt"]/text()')[0].encode('utf-8').strip()+'.mp4'
name= '儿歌多多 '+name
name=name.decode('utf-8')
filename=os.path.join(os.getcwd(),name)
print filename
if os.path.exists(filename):
continue
p=subprocess.Popen('python you-get -d --format=HD {}'.format(song_url),stderr=subprocess.PIPE,stdout=subprocess.PIPE,shell=True)
output,error = p.communicate()
print(output)
print(error)
p.wait()
def main():
getUrl()
if __name__ == '__main__':
main()
下载下来大概300多集,直接拷贝到平板上离线播放,再也不卡了。
原创地址:http://30daydo.com/article/236
转载请注明出处
查看全部
http://30daydo.com/article/236
更新 ******** 2018-01-09*************
最近才发现以前曾经挖了这个坑,现在来完成它吧。
儿歌多多在爱奇艺的视频网站上也有全集,所以目标转为抓取iqiyi的儿歌多多视频列表。
github上有一个现成的下载iqiyi的第三方库,可以通过python调用这个库来实现下载功能。
代码使用python3来实现。
1. 打开网页 http://www.iqiyi.com/v_19rrkwcx6w.html#curid=455603300_26b870cbb10342a6b8a90f7f0b225685
这个是第一集的儿歌多多,url后面的curid只是一个随机的字符串,可以直接去掉。
url=“http://www.iqiyi.com/v_19rrkwcx6w.htm”
浏览器直接查看源码,里面直接包含了1-30集的视频url,那么要做的就是提取这30个url
先抓取网页内容:
session = requests.Session()
def getContent(url):
try:
ret = session.get(url)
except:
return None
if ret.status_code==200:
return ret.text
else:
return None
然后提取内容中的url

点击查看大图
提取div标签中的属性 data-current-count=1的。然后选择子节点中的li标签,提取li中的a中的href链接即可。
content = getContent(url)
root = etree.HTML(content)
elements=root.xpath('//div[@data-current-count="1"]//li/a/@href')
for items in elements:
song_url = items.replace('//','')
song_url=song_url.strip()
print(song_url)
2. 有了url,就可以下载这个页面的中的内容了。
这里我使用的是一个第三方的视频下载库,you-get。(非常好用,fork到自己仓库研究 https://github.com/Rockyzsu/you-get)
使用方法:
python you-get -d --format=HD url
you-get 需要下载一个ffmpeg.exe的文件来解码视频流的,去官网就可以免费下载。
url就是你要下载的url地址,format可以选择高清还是其他格式的,我这里选择的是HD。
在python脚本里面调用另外一个python脚本,可以使用subprocess来调用。
p=subprocess.Popen('python you-get -d --format=HD {}'.format(song_url),stderr=subprocess.PIPE,stdout=subprocess.PIPE,shell=True)
output,error = p.communicate()
print(output)
print(error)
p.wait()上面的song_url 就是接着最上面那个代码的。
完整代码如下:
#-*-coding=utf-8-*-
import requests
from lxml import etree
import subprocess
session = requests.Session()
def getContent(url):
# url='http://www.iqiyi.com/v_19rrkwcx6w.html'
try:
ret = session.get(url)
# except Exception,e:
except:
# print e
return None
if ret.status_code==200:
return ret.text
else:
return None
def getUrl():
url='http://www.iqiyi.com/v_19rrkwcx6w.html'
url2='http://www.iqiyi.com/v_19rrl2td7g.html' # 31-61
content = getContent(url)
root = etree.HTML(content)
elements=root.xpath('//div[@data-current-count="1"]//li/a/@href')
for items in elements:
song_url = items.replace('//','')
song_url=song_url.strip()
print(song_url)
p=subprocess.Popen('python you-get -d --format=HD {}'.format(song_url),stderr=subprocess.PIPE,stdout=subprocess.PIPE,shell=True)
output,error = p.communicate()
print(output)
print(error)
p.wait()
def main():
getUrl()
if __name__ == '__main__':
main()
上面的是1-30集的,全部集数现在是120集,31-60的在url
http://www.iqiyi.com/v_19rrl2td7g.html
这个url只要你选择iqiyi视频的右边栏,就会自动变化。 同理也可以找到61-120的url,然后替换到上面代码中最开始的url就可以了。(这里因为页码少,所以就没有用循环去做)
最终的下载结果:

后面修改了下代码,判断文件是不是已经存在,存在的会就不下载,对于长时间下载100多个文件很有用,如果掉线了,重新下载就不会去下载那些已经下好的。
#-*-coding=utf-8-*-
import sys,os
import requests
from lxml import etree
import subprocess
session = requests.Session()
def getContent(url):
# url='http://www.iqiyi.com/v_19rrkwcx6w.html'
try:
ret = requests.get(url)
ret.encoding='utf-8'
# except Exception,e:
except:
# print e
return None
if ret.status_code==200:
return ret.text
else:
return None
def getUrl():
url='http://www.iqiyi.com/v_19rrkwcx6w.html'
url2='http://www.iqiyi.com/v_19rrl2td7g.html' # 31-61
content = getContent(url)
if not content:
print "network issue, retry"
exit(0)
root = etree.HTML(content,parser=etree.HTMLParser(encoding='utf-8'))
elements=root.xpath('//div[@data-current-count="1"]//li')
for items in elements:
url_item=items.xpath('.//a/@href')[0]
song_url = url_item.replace('//','')
song_url=song_url.strip()
print(song_url)
# name=items.xpath('.//span[@class="item-num"]/text()')[0]
name=items.xpath('.//span[@class="item-num"]/text()')[0].encode('utf-8').strip()+\
' '+items.xpath('.//span[@class="item-txt"]/text()')[0].encode('utf-8').strip()+'.mp4'
name= '儿歌多多 '+name
name=name.decode('utf-8')
filename=os.path.join(os.getcwd(),name)
print filename
if os.path.exists(filename):
continue
p=subprocess.Popen('python you-get -d --format=HD {}'.format(song_url),stderr=subprocess.PIPE,stdout=subprocess.PIPE,shell=True)
output,error = p.communicate()
print(output)
print(error)
p.wait()
def main():
getUrl()
if __name__ == '__main__':
main()
下载下来大概300多集,直接拷贝到平板上离线播放,再也不卡了。
原创地址:http://30daydo.com/article/236
转载请注明出处